


LangGraphで極めるRAG型AIエージェント開発
本記事では、AIエージェント開発の新潮流として注目される「LangGraph」について詳しく解説します。LangChainの限界を克服し、複雑なワークフローやRAGシステム、マルチエージェントの実装を可能にするLangGraphの基本概念・特徴・実装例を豊富なコードと図解で紹介。
スマートRAGフローの実践では、構築条件付きエッジやステート管理など、実践に役立つ設計ポイントも網羅しています。
LangChainで構築するAIエージェントの基本構造
AIエージェントの概念と進化
AIエージェントとは、特定の目標に向かって自律的に行動し、環境と相互作用しながら問題を解決する知的なシステムです。従来のチャットボットが単一の入力に対して回答を返すだけだったのに対し、AIエージェントは複数のステップを経て目標達成を目指します。
AIエージェントの最大の利点は、複雑なタスクを自律的にこなせる点にあります。例えば、情報収集、分析、意思決定、そして行動といった一連のプロセスを自動化できるため、人間の作業効率を飛躍的に向上させる可能性を秘めています。
近年のAIエージェントの進化により、以下のような発展が見られます:
- 単純な反応型から計画型へ: 単に刺激に反応するだけでなく、将来を見据えた計画を立てられるようになりました
- 専門特化から汎用性へ: 特定のタスクだけでなく、様々な領域で活用できるエージェントが登場しています
- 単独行動から協調行動へ: 複数のエージェントが協力して複雑な問題を解決するマルチエージェントシステムへと発展しています
LangChainの全体像と主要コンポーネント
LangChainは、大規模言語モデル(LLM)を活用したアプリケーション開発のためのオープンソースフレームワークです。2022年末に登場して以来、LLMベースのアプリケーション開発において最も広く使われているフレームワークの一つとなっています。
LangChainについて詳しく知りたい方は、筆者の技術ブログ「LangChain入門:GPT-APIを活用した次世代アプリ開発ガイド」もご参照ください。このブログでは、LangChainの基本から応用までを詳しく解説しています。
LangChainは、以下の主要コンポーネントで構成されています:
- 言語モデル(LLMs): OpenAI、Anthropic、Google、LLaMAなど様々な言語モデルを統一的なインターフェースで利用可能にします。これにより、モデルの切り替えが容易になります。
- プロンプトテンプレート(Prompts): 言語モデルへの指示を動的に構築するためのテンプレート機能を提供します。変数を埋め込んだ再利用可能なプロンプトを作成できます。
- チェーン(Chains): 複数のコンポーネントを連携させて一連の処理を行う仕組みです。例えば「プロンプト生成→LLM呼び出し→結果解析」といった流れを1つのチェーンとして定義できます。
- メモリ(Memory): 会話の履歴や状態を保持する機能です。これにより、コンテキストを維持した対話が可能になります。
- ツール(Tools): 外部API、データベース、検索エンジンなど外部リソースを活用するための機能です。言語モデルの能力を拡張します。
- 検索(Retrieval): ドキュメント検索や情報取得のための機能です。RAG(検索拡張生成)の実装に必須のコンポーネントです。
- エージェント(Agents): 自律的に行動し、ツールを適切に選択・利用する機能です。特定の目標に向かって複数のステップを実行します。
これらのコンポーネントを組み合わせることで、単純なチャットボットから複雑な意思決定システムまで、様々なAIアプリケーションを構築できます。
従来のLangChainの限界と課題
LangChainは多くの強力な機能を提供していますが、複雑なワークフローやエージェントの実装においては、以下のような限界と課題がありました:
❶線形的なチェーン構造:
従来のLangChainは主に線形的な処理の流れ(A→B→C)を想定しており、条件分岐や複雑なフローの実装が難しいという課題がありました。例えば「もしこの条件ならAへ、そうでなければBへ」といった分岐処理を簡潔に表現する方法が限られていました。
❷状態管理の複雑さ:
複数のコンポーネント間での状態の共有や管理が煩雑でした。特に長いチェーンやループを含むフローでは、状態の受け渡しや更新が複雑になりがちでした。
❸エージェントの柔軟性不足:
より複雑な意思決定や自律的な行動を実装するための仕組みが不十分でした。特に「思考-行動-観察」のループを自然に表現する方法が限られていました。
❹デバッグの難しさ:
複雑なチェーンやエージェントの挙動を理解し、デバッグすることが難しいという課題がありました。処理の流れが視覚的に把握しづらく、問題の特定が困難でした。
➎コードの可読性とメンテナンス性:
複雑なアプリケーションになると、コードの可読性が低下し、メンテナンスが困難になる傾向がありました。特に多段階の処理や条件分岐を含むフローは表現が冗長になりがちでした。
LangGraphが変えるAIエージェント設計の最前線
LangGraphの基本概念とグラフ構造
LangGraphは、LangChainのエコシステムの一部として開発された、AIエージェントの動作フローを効率的に設計・実装するためのツールです。LangChainが提供する基本的なコンポーネントをグラフ構造で接続することで、より柔軟で高度なAIエージェントの構築を可能にします。
開発元とライセンス情報
LangGraphは、LangChainを開発するLangChain, Inc.によって開発・提供されています。LangChainと同様に、LangGraphもオープンソースソフトウェアとして公開されており、MIT ライセンスの下で配布されています。このライセンスにより、商用・非商用を問わず自由に利用・改変が可能です。
LangGraphの核心は、グラフ構造によって処理の流れを表現する点にあります。
グラフ理論を応用することで、AIエージェントの行動や意思決定のプロセスを直感的に設計し、管理することが可能になります。
LangGraphをレストランの運営に例えると、次のようになります:
- ノード(Node) は「調理ステーション」のようなもの。それぞれが具体的な作業(食材の下処理、調理、盛り付けなど)を担当します。
- エッジ(Edge) は「料理の流れ」を示し、ステーション間の受け渡しルートです。
- ステート(State) は「注文票」のようなもの。顧客情報、注文内容、調理状況など、処理に必要な情報が記載されています。
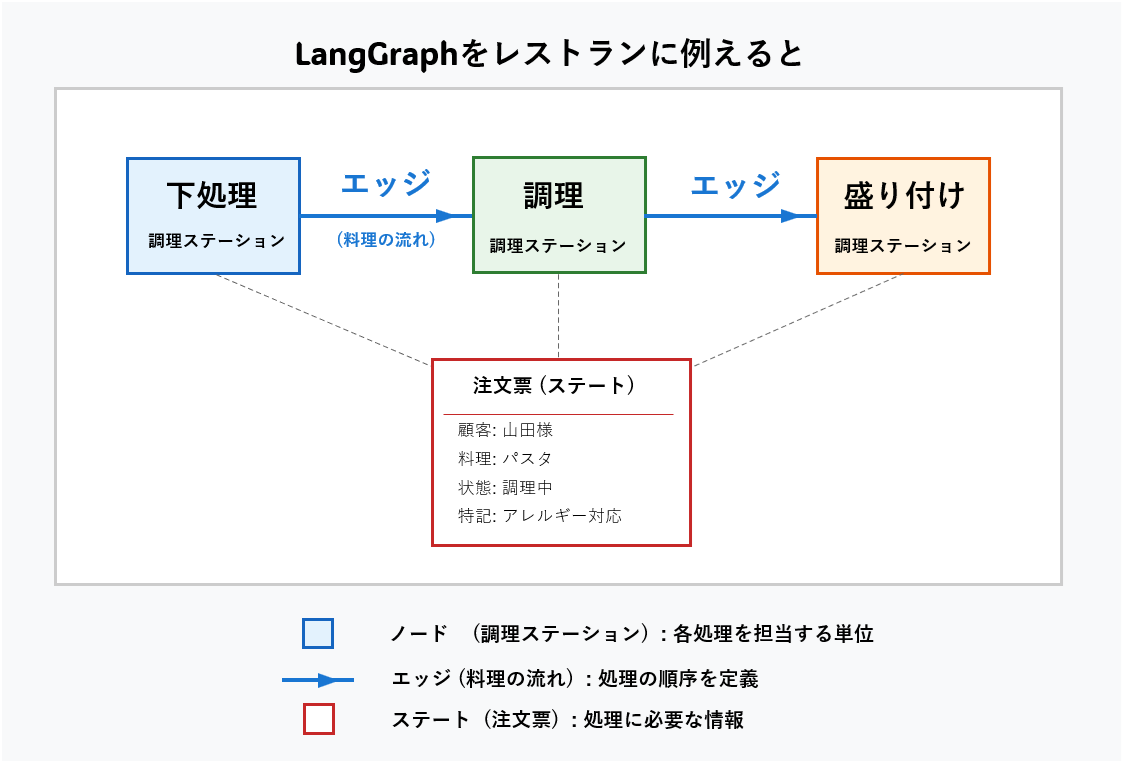 図1 LangGraphをレストランると。こんな感じ?
図1 LangGraphをレストランると。こんな感じ?
LangGraphには3つの基本種類があり、それぞれ異なる用途に適しています:
❶基本グラフ(Graph):
- 例え: シンプルな食堂の調理ライン
- 特徴: 一方通行の決まったルートで食材が調理される
- 用途: 単純な処理フローで、入出力の型が明確な場合
- 例: テキスト翻訳→要約→フォーマット調整といった一連の流れ
❷メッセージグラフ(MessageGraph):
- 例え: カフェでの接客とオーダー処理
- 特徴: 常に顧客との会話履歴を保持し、それに基づいて応答
- 用途: チャットボットなど会話形式のアプリケーション
- 例: ユーザーの質問に対する応答生成や会話の継続
❸ステートグラフ(StateGraph):
- 例え: フルサービスレストランの複雑なオペレーション
- 特徴: 顧客情報、料理の進捗状況、在庫状況など複数の情報を管理
- 用途: 複雑な状態を持つAIエージェント
- 例: ユーザーの質問に基づいて検索、分析、回答生成などを行うエージェント
それぞれの種類は処理の複雑さや管理すべき情報量に応じて選択します。シンプルな処理なら基本グラフ、会話管理が主ならメッセージグラフ、複雑な状態管理が必要ならステートグラフと、状況に応じて最適なものを使い分けることで、効率的で保守性の高いAIエージェントを構築できます。
グラフ構造の主な利点は以下の通りです:
- 処理の流れの視覚化: 複雑なフローでも直感的に理解・設計できます
- 非線形処理の自然な表現: 条件分岐やループを含む複雑なフローを簡潔に表現できます
- モジュール性とコードの再利用: 個々のノードを独立して開発・テストし、再利用できます
- 柔軟な拡張性: 新しいノードやエッジを追加してグラフを拡張しやすいです
ノード、エッジ、ステートの活用法
 図2 ノード、エッジ、ステートのイメージ図
図2 ノード、エッジ、ステートのイメージ図
LangGraphにおけるグラフ構造は主に以下の要素で構成されます。
❶ノード (Node):
各処理の単位を表します。例えば「ユーザー入力の解析」「情報検索」「回答生成」などの機能をノードとして定義します。LangChainの各種コンポーネント(LLMチェーン、ツール、プロンプトなど)を、ノードとして配置できます。
ノードは基本的に関数として定義され、入力を受け取って処理し、結果を出力します。
def process_input(state):
# 入力の処理
processed_data = some_processing(state)
return processed_data
❷エッジ (Edge):
ノード間の接続関係を表し、処理の流れや順序を定義します。従来のLangChainでは単純な線形チェーンしか作れませんでしたが、LangGraphではノード間の複雑な接続関係を表現できます。
エッジは以下のように定義します。
# ノードAからノードBへのエッジ
builder.add_edge("node_a", "node_b")
❸ステート (State):
処理の途中経過や状態を保持する仕組みです。会話履歴やコンテキスト情報などを保存します。LangChainでは状態管理が煩雑でしたが、LangGraphではグラフ全体で統一された状態管理が可能になりました。
ステートは通常、TypedDictを使って型安全に定義します。
class AgentState(TypedDict):
messages: List[BaseMessage] # 会話履歴
context: Dict[str, Any] # コンテキスト情報
tools_used: List[str] # 使用したツールのリスト
LangGraphのルーティング設計:条件分岐の最適化
LangGraphで特に重要な概念が条件付きエッジ (Conditional Edge)とルーター (Router)です。これらにより、条件に応じて処理の流れを分岐させることができます。
❶条件付きエッジ:
条件に応じて実行するノードを動的に決定する仕組みです。これは従来のLangChainには無かった機能で、動的な処理フローを実現する上で非常に重要です。
❷ルーター:
条件分岐を実現するための関数です。入力された状態(State)を分析し、次に実行すべきノードを決定します。例えば、「ユーザーの質問に答えるために外部情報が必要かどうか」を判断し、必要であれば「検索ノード」へ、そうでなければ「回答生成ノード」へと処理を振り分けるような使い方をします。
from langgraph.graph import StateGraph
# 1. ステート定義
class AgentState(TypedDict):
messages: List[str]
# 2. グラフビルダー初期化
builder = StateGraph(AgentState)
# 3. ノードの追加
builder.add_node("search_node", search_func)
builder.add_node("summarize_node", summarize_func)
builder.add_node("respond_node", respond_func)
builder.add_node("decision_node", decide_func) # 分岐ノード(ルーターの直前)
# 4. 条件付きエッジを追加
def router(state: AgentState) -> str:
"""次のノードを決定するルーター"""
# 状態を分析
last_message = state["messages"][-1]
# 条件に基づいて次のノードを決定
if "検索" in last_message.content:
return "search_node"
elif "要約" in last_message.content:
return "summarize_node"
else:
return "respond_node"
# 条件付きエッジの追加
builder.add_conditional_edges(
"decision_node", # 分岐元のノード
router, # ルーター関数
{
"search_node": "search_node", # 検索ノードへ
"summarize_node": "summarize_node", # 要約ノードへ
"respond_node": "respond_node" # 応答ノードへ
}
)
# 5. 入出力や終了ノードを設定してビルド
builder.set_entry_point("decision_node")
graph = builder.compile()図3 条件付きエッジの構造
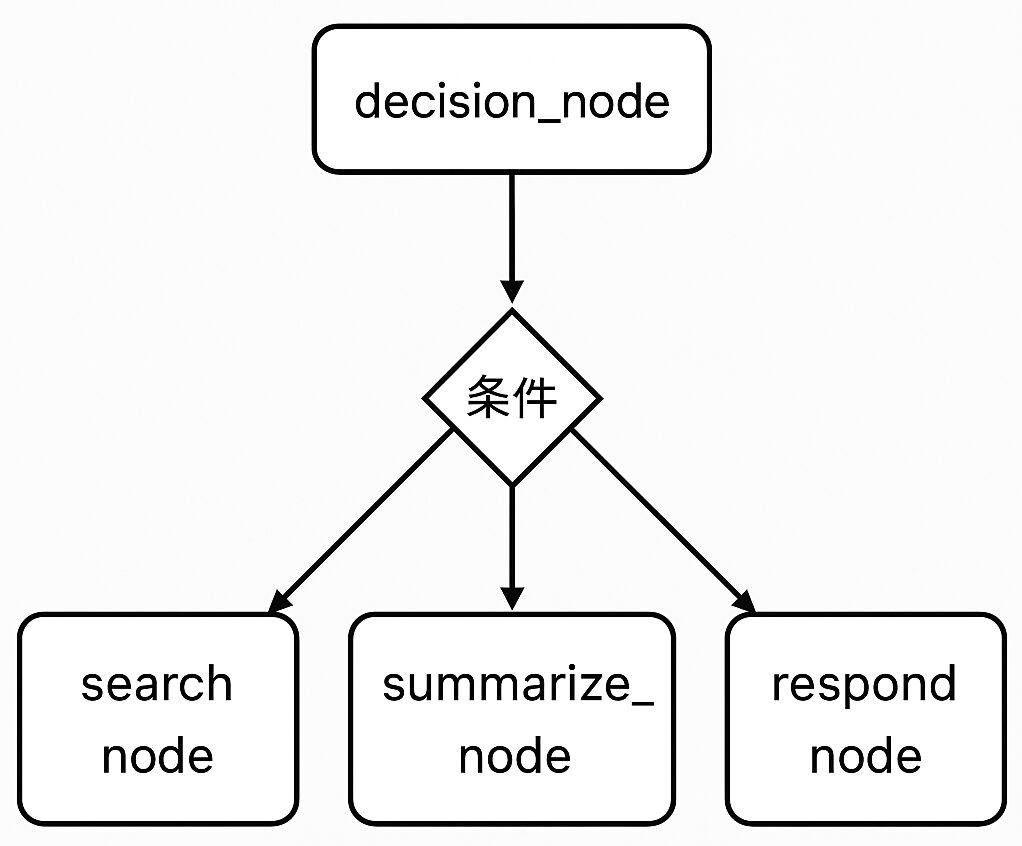
ルーターと条件付きエッジの組み合わせにより、AIエージェントは状況に応じた柔軟な意思決定が可能になります。例えば「情報が不足していればツールを使って情報を集める」「十分な情報があれば直接回答する」といった判断ができるようになります。
LangGraphの種類と特性
基本グラフ、メッセージグラフ、ステートグラフの違い
LangGraphには、用途に応じて複数の種類が用意されています。主要なものは以下の3つです:
1. 基本グラフ (Graph)
最もシンプルな形式のグラフで、任意の型の入力と出力を持つノードを接続できます。単純な処理フローを構築するのに適しています。
from langgraph.graph import Graph
# 入力と出力の型が文字列のグラフを作成
builder = Graph()
# ノードの追加
builder.add_node("node_a", node_a_function)
builder.add_node("node_b", node_b_function)
# エッジの設定
builder.add_edge("node_a", "node_b")基本グラフは、シンプルなデータ変換パイプラインや、明確な入出力型を持つ処理を実装する場合に適しています。
2. メッセージグラフ (MessageGraph)
LangChainのメッセージ型(HumanMessage、AIMessageなど)を扱うための特化型グラフです。チャットボットなど、会話形式のアプリケーションを構築する際に便利です。
from langgraph.graph import MessageGraph
# メッセージを処理するグラフを作成
builder = MessageGraph()
# メッセージ処理ノードの追加
builder.add_node("process", process_message_function)メッセージグラフの特徴は、入出力が常にメッセージのリスト(List[BaseMessage])である点です。会話履歴の管理が自動化されており、チャットアプリケーションの開発が容易になります。
3. ステートグラフ (StateGraph)
最も高度なグラフ型で、複雑な状態を扱えます。TypedDictを使って型安全な状態定義が可能で、AIエージェントのような複雑なアプリケーションの構築に適しています。
from langgraph.graph import StateGraph
# 状態の型を指定してグラフを作成
builder = StateGraph(CustomStateType)
# ステート処理ノードの追加
builder.add_node("agent", agent_function)ステートグラフでは、複数の情報(会話履歴、ツールの使用状況、中間結果など)を統合的に管理できます。これにより、複雑な状態遷移を伴うエージェントの実装が容易になります。
状態管理とデータの受け渡し
LangGraphにおける状態管理とデータの受け渡しは、グラフの種類によって異なります。
❶基本グラフでの状態管理:
基本グラフでは、各ノードが前のノードの出力を入力として受け取ります。状態は明示的に受け渡される必要があります。
def node_a(input_data: str) -> str:
return input_data + " processed by A"
def node_b(input_data: str) -> str:
return input_data + " processed by B"
# node_a の出力が node_b の入力になる
❷メッセージグラフでの状態管理:
メッセージグラフでは、メッセージの履歴(List[BaseMessage])が自動的に管理されます。各ノードは現在のメッセージリストを受け取り、更新されたメッセージリストを返します。
def process_messages(messages: List[BaseMessage]) -> List[BaseMessage]:
# 最後のメッセージを取得
last_message = messages[-1]
# 新しいメッセージを追加
return messages + [AIMessage(content="応答")]
❸ステートグラフでの状態管理: ステートグラフでは、TypedDictで定義された複雑な状態を管理できます。各ノードは現在の状態を受け取り、更新された状態を返します。
from typing import TypedDict, List, Dict, Any
from langchain.schema import BaseMessage # LLMのメッセージ型(HumanMessage/AIMessageの親)
# LangGraphでやり取りされる状態(State)を定義
class AgentState(TypedDict):
# LLMとユーザーのやりとり履歴(チャット履歴)
messages: List[BaseMessage]
# プロンプト変数や補足データなどの共有情報(例:ユーザー名、ステータス、フラグなど)
context: Dict[str, Any]
# LangGraphのノード(処理ステップ)として使う関数
def agent_node(state: AgentState) -> AgentState:
# 現在の状態から、チャット履歴と共有情報を取り出す
messages = state["messages"]
context = state["context"]
# ↓↓↓ ここに処理内容を実装する(例:LLM呼び出し、contextの更新など)↓↓↓
# 仮に新しいメッセージ(LLMからの返答)を生成したとする
new_message = ... # 例: AIMessage(content="〜〜です!")
# contextも更新する(例:新しい変数を追加、ステータス変更など)
updated_context = ... # 例: {**context, "last_response": "〜〜"}
# ↑↑↑ 処理ここまで ↑↑↑
# 新しいメッセージを履歴に追加し、contextも更新した状態を返す
return {
"messages": messages + [new_message],
"context": updated_context
}
グラフのコンパイルと実行の仕組み
LangGraphでは、グラフの定義(ビルド)、コンパイル、実行という3段階のプロセスがあります:
❶グラフの定義(ビルド)
まず、グラフのビルダーを作成し、ノードとエッジを追加していきます。
# ビルダーの作成
builder = StateGraph(AgentState)
# ノードの追加
builder.add_node("node_a", node_a_function)
builder.add_node("node_b", node_b_function)
# エッジの追加
builder.add_edge("node_a", "node_b")
# 条件付きエッジの追加
builder.add_conditional_edges("node_b", router_function, routes)
❷グラフのコンパイル:
定義したグラフを実行可能な形にコンパイルします。この段階で、グラフの整合性チェックが行われます。
# グラフのコンパイル
graph = builder.compile()コンパイル時には、以下のような検証が行われます:
- すべてのノードが到達可能か
- 条件付きエッジのルーターが適切な値を返すか
- 型の整合性が取れているか
❸グラフの実行
コンパイルされたグラフに初期状態を与えて実行します。
# グラフの実行
result = graph.invoke(initial_state)実行時には、以下のようなプロセスが行われます:
- エントリーポイントから実行を開始
- 各ノードが順番に実行され、状態が更新される
- 条件付きエッジがある場合、ルーター関数によって次のノードが決定される
- 終了条件(ENDノードに到達)まで実行が続く
- 最終的な状態が結果として返される
また、LangGraphはストリーミング実行もサポートしています:
# ストリーミング実行
for state in graph.stream(initial_state):
# 中間状態を処理
print(state)ストリーミング実行では、各ノードの実行後の状態がリアルタイムで取得できるため、進捗状況の表示や中間結果の確認に役立ちます。
LangGraphによるスマートRAGフローの実践
RAG(Retrieval-Augmented Generation、検索拡張生成)は、LLMの知識を外部データソースで拡張する手法です。LangGraphを使用すると、RAGシステムのフローを明示的に定義し、より効率的かつ制御可能な形で実装できます。
RAGの基本ステップ:
- クエリ理解: ユーザーの質問を分析して検索クエリを作成
- 検索実行: 関連文書やデータを取得
- コンテキスト選択: 最も関連性の高い情報を選択
- 回答生成: 検索結果をコンテキストとして回答を生成
LangGraphでのRAG実装:
from typing import TypedDict, List, Dict
from langchain.schema import BaseMessage, AIMessage
from langchain.docstore.document import Document # 検索結果の型(文書)
# 想定: query_extractor_llm, vector_db, llm は外部で定義済みのLangChainオブジェクト
# ===========================
# ✅ RAGシステムの状態定義
# ===========================
class RAGState(TypedDict):
# ユーザーとAIの対話履歴(チャットメッセージ)
messages: List[BaseMessage]
# 抽出された検索クエリ(ユーザーの質問を要約・変換したもの)
query: str
# ベクトルDBから取得した関連文書のリスト
search_results: List[Document]
# 検索結果から構築された回答用コンテキスト(文字列)
context: str
# ===========================
# 🔍 クエリ抽出ノード
# ===========================
def extract_query(state: RAGState) -> Dict:
# 最新のユーザー発言を取得
messages = state["messages"]
last_message = messages[-1].content
# LLMを使って検索用クエリを抽出する
query = query_extractor_llm.invoke(
f"以下の質問から検索クエリを抽出してください: {last_message}"
)
# 新しい状態として 'query' を返す(LangGraphがマージ)
return {"query": query}
# ===========================
# 🔍 検索実行ノード
# ===========================
def perform_search(state: RAGState) -> Dict:
# 抽出済みクエリを取得
query = state["query"]
# ベクトル検索を実行して関連文書を取得(top_k件)
search_results = vector_db.search(query, top_k=5)
return {"search_results": search_results}
# ===========================
# 🔍 コンテキスト準備ノード
# ===========================
def prepare_context(state: RAGState) -> Dict:
# 検索結果(文書オブジェクトのリスト)を取得
search_results = state["search_results"]
# 各文書の本文を取り出して、改行で連結
context = "\n\n".join([doc.content for doc in search_results])
return {"context": context}
# ===========================
# 🤖 回答生成ノード
# ===========================
def generate_answer(state: RAGState) -> Dict:
# チャット履歴と、コンテキスト、質問内容を取得
messages = state["messages"]
context = state["context"]
last_question = messages[-1].content
# コンテキストと質問を組み合わせてプロンプトを作成
prompt = f"""
次の情報に基づいて質問に答えてください:
情報:
{context}
質問: {last_question}
"""
# LLMを使って回答を生成
answer = llm.invoke(prompt)
# 回答を AIMessage として追加し、messages に加える
return {
"messages": messages + [AIMessage(content=answer)]
}
高度なRAG実装の解説
🎯 改善:毎回検索ではなく、本当に必要なときだけ検索を行う
✅ 応答を高速化し
✅ 無駄なコストを削減する、
よりスマートなRAG構成を目指します。
| 項目 | 内容 |
|---|---|
| 目的 | 不要な検索を省略し、効率的にRAG処理を進めるため |
| LLMの役割 | 「これは調べるべきか?」という“判断”にも使う(=検索エージェント化) |
| メリット | – 応答が速くなる – 費用(ベクトル検索のコスト)が下がる – 応答品質も安定 |
# 🔁 検索の必要性を判断するルーター関数
def search_router(state: RAGState) -> str:
# 現在のチャット履歴から、最新のユーザー発言を取得
messages = state["messages"]
last_message = messages[-1].content
# LLMに「外部情報(検索)が必要かどうか」を尋ねる
needs_search = search_necessity_llm.invoke(
f"この質問に答えるために外部情報が必要ですか?: {last_message}"
)
# LLMが「はい」と答えた場合は、検索プロセスに進む
if "はい" in needs_search:
return "extract_query" # → クエリ抽出 → 検索 → 回答
else:
return "direct_answer" # → LLMの知識だけで回答(検索しない)
まとめ
LangGraphは、LangChainの限界を克服し、AIエージェントの開発を新たな段階へと引き上げるフレームワークです。
グラフ構造を取り入れることで、従来では難しかった複雑な条件分岐や状態管理を直感的に実装できるようになりました。
基本グラフ、メッセージグラフ、ステートグラフという3つの種類を適切に選択することで、さまざまなユースケースに対応可能です。
特に条件付きエッジとルーターの仕組みは、AIエージェントの自律的な意思決定を実現する上で重要な役割を果たします。
今後、RAGシステムやマルチエージェント連携など、高度なアプリケーションの開発がさらに進むことが期待されます。LangGraphの登場により、AIエージェント開発はより効率的で保守性の高いものになるでしょう。
筆者の技術ブログ
- LangChain入門:GPT-APIを活用した次世代アプリ開発ガイド
– LangChainの基礎から応用までを詳しく解説 - AutoGen入門:マルチエージェントシステムで実現する高度なAI協調
– マルチエージェントシステムについての詳細解説 - CrewAI入門:次世代マルチエージェントフレームワーク解説
– チーム構造を持つマルチエージェントフレームワークの詳細
外部参考サイト
- LangGraph公式ドキュメント – LangGraphの基本概念と使用方法
- LangChain公式サイト – LangChainのエコシステム全体
- Harrison Chase氏のGitHubリポジトリ – LangChainの開発者による解説
- LangGraph: Beyond Sequential Chains in LangChain(英語) – LangGraphの設計思想と概要
ケニー狩野(中小企業診断士、PMP、ITコーディネータ)
キヤノン(株)でアーキテクト、プロマネとして多数のプロジェクトをリード。
現在、株式会社ベーネテック代表、株式会社アープ取締役、一般社団法人Society 5.0振興協会評議員ブロックチェーン導入評価委員長。
これまでの知見を活かしブロックチェーンや人工知能技術の推進に従事。趣味はダイビングと囲碁。2018年「リアル・イノベーション・マインド」を出版。








