


RAGシステム開発のためのVertex AI vs LlamaIndex
生成AIの急速な進化によって、膨大な情報から適切な知識を抽出し、高品質な回答を提供するRAG(Retrieval Augmented Generation)システムへの注目が高まっています。
企業や開発者は独自のデータを活用した生成AI基盤の構築を模索していますが、その実装アプローチには複数の選択肢が存在します。
本記事では、RAGシステム開発のための二大ツール「Google Cloud Vertex AI RAG Engine」と「LlamaIndex」について、それぞれの特徴、アーキテクチャ、適用シナリオを徹底比較します。
RAGシステムの構築を検討している方々の意思決定に役立つ情報を提供します。
参考)Vertex AIとGemini 2.5を使った最先端のRAGシステム構築方法はこちらにまとめてます。
【2025年最新】Vertex AI Search / Agent Builder × Gemini 2.5 で作る超高速RAGシステム
RAGシステムの基本と企業導入のメリット
Retrieval Augmented Generation(RAG)は、大規模言語モデル(LLM)の出力品質を向上させるアプローチです。
RAGは以下の3つのプロセスで動作します。
- ユーザーからの質問を受け取る
- 関連情報を外部データソースから検索・抽出する
- 検索結果を基にLLMが回答を生成する
この方法により、以下のような利点が得られます。
- 最新かつ正確な情報に基づく回答
- ハルシネーション(誤った情報の生成)の減少
- 企業固有の知識を活用した回答の提供
- コンプライアンス要件への適合性向上
Vertex AI RAG Engine: マネージド型エンタープライズソリューションの実装ガイド
概要と特徴
Vertex AI RAG Engineは、Google Cloudが提供する完全マネージド型のRAGソリューションです。
エンタープライズグレードの検索技術と最先端の生成AIモデルを組み合わせ、企業のプライベートデータを活用したAIアプリケーション開発を支援します。
主な特徴は次のとおりです。
- 完全マネージドサービス: インフラストラクチャ管理が不要
- エンドツーエンドのソリューション: データ取り込みから回答生成まで統合環境
- 高度な検索技術: Google検索の技術を活用した高精度な情報検索
- エンタープライズグレードのセキュリティ: コンプライアンス認証と強固なデータ保護
- 自動スケーリング: 処理量に応じた自動リソース割り当て
- 組み込みのダッシュボード: 使用状況と性能の視覚化
- Geminiモデルとの最適化: GoogleのLLMとの緊密な統合
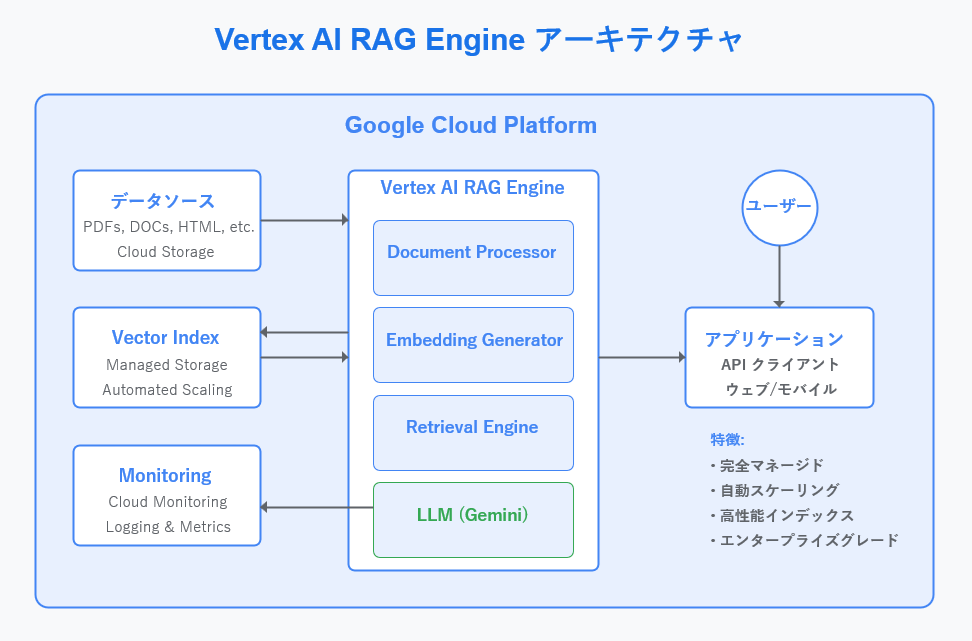
【図1・解説】アーキテクチャとワークフロー
Vertex AI RAG Engineのアーキテクチャは、Google Cloud Platform内に完全に統合されています。
図1で示されているように、以下のコンポーネントで構成されています。
- データソース層: 様々な形式のドキュメントがCloud Storageに保存されます
- 処理層:
- Document Processor: ドキュメントの解析と構造化
- Embedding Generator: テキストをベクトル表現に変換
- Retrieval Engine: クエリに関連する情報の検索
- LLM (Gemini): 検索結果を基にした回答生成
- ベクターインデックス層: 効率的な検索のためのベクトルインデックスを管理
- モニタリング層: システムの健全性とパフォーマンスを監視
- アプリケーション層: APIを通じたクライアントアプリケーションとの連携
実装プロセス
Vertex AI RAG Engineを使用したRAGシステムの構築は、以下のステップで進行します。
- Google Cloudプロジェクトの設定とVertex AIの有効化
- データソースの準備とCloud Storageへのアップロード
- コンソールまたはAPIを通じたコーパス(大量のテキストデータを集めた“言語DB)の定義
- インデックス作成の設定と実行
- クエリエンドポイントの構成
- クライアントアプリケーションの開発と統合
- モニタリングとパフォーマンスチューニング
Vertex AI RAG Engineを利用したサンプルコード
from google.cloud import aiplatform
# 1. Vertex AIの初期化
aiplatform.init(
project="your-project-id",
location="us-central1"
)
# 2. コーパスの作成(GCS上のファイルを使用)
corpus = aiplatform.RagCorpus.create(
display_name="financial-corpus",
description="財務レポートなどの文書",
source_uris=["gs://your-bucket-name/financial_reports/"], # GCSにアップロード済みの文書
chunking_strategy="automatic" # 自動チャンク分割(セクションごとに分けて処理)
)
# 3. コーパスのインデックス化(検索に使えるようにする)
corpus.wait() # インデックス化が終わるまで待機
# 4. RAGエンジンの作成
rag_engine = aiplatform.RagEngine()
# 5. クエリを投げる
response = rag_engine.query(
corpus_name="financial-corpus", # 作成したコーパス名
query="財務報告書の最新情報は?",
max_documents=5
)
# 6. AIが実際に生成した自然文の回答を表示
print("AIによる回答:")
print(response.generated_answer)
print("")
# 7. 結果の出力
for result in response.results:
print(f"ソース: {result.document.name}")
print(f"内容: {result.content}")
【サンプルコードの逐次解説】
このサンプルコードでは、「財務報告書の最新情報」に関連する文書を検索して表示しています。
1,インポートと初期化:
from google.cloud import aiplatform
# 1. Vertex AIの初期化
aiplatform.init(
project="your-project-id",
location="us-central1"
)目的:Google Cloud の Vertex AI ライブラリをインポートした後、プロジェクトID(”your-project-id”)と場所(”us-central1″)を指定して初期化しています。
これを最初にしないと、以後の操作(コーパス作成、クエリなど)が使えません。
2,コーパスの作成
corpus = aiplatform.RagCorpus.create(
display_name="financial-corpus",
description="財務レポートなどの文書",
source_uris=["gs://your-bucket-name/financial_reports/"],
chunking_strategy="automatic"
)
目的:GCS(Google Cloud Storage)に保存された文書を元に、RAG用のコーパスを新規作成します。
| パラメータ | 意味 |
|---|---|
display_name |
表示用のコーパス名(後でクエリ実行時に使う) |
description |
管理用の説明文 |
source_uris |
GCSのファイルパスのリスト。PDF, TXTなど |
chunking_strategy |
文書を検索用に自動で分割する方式(通常はautomaticでOK) |
3.インデックス化を待つ
corpus.wait()
目的:コーパスをベクトル検索可能にするための処理(インデックス作成)を待ちます。
非同期で実行されるため、.wait() で終了を待つのが安全とされてます。
4,RAGエンジンの作成
rag_engine = aiplatform.RagEngine()
目的:クエリを実行するためのエンジンインスタンスを生成します。
インスタンスには特別な設定は不要です(認証済みであればOK)。
5. クエリ実行
response = rag_engine.query(
corpus_name="financial-corpus",
query="財務報告書の最新情報は?",
max_documents=5
)
目的:RAGエンジンに質問を投げて、関連文書と生成回答を得ます。
具体的には
- 「financial-corpus」という名前のコーパス(データの集合体)に対して
- 「財務報告書の最新情報は?」というクエリを実行します
- 最大5つのドキュメントを結果として取得するよう指定しています
| パラメータ | 意味 |
|---|---|
corpus_name |
使用するコーパスの名前 |
query |
ユーザーからの自然文の質問 |
max_documents |
最大いくつの関連文書を返すか(多いほど情報量も増える) |
6.AIによる生成回答の表示
print("AIによる回答:")
print(response.generated_answer 目的:AIが質問に対して生成した回答を自然文で表示します。
これは検索された文書の抜粋をもとに作られたもので、人間が読みやすい形で要約されています。
7. 回答の根拠となったソース文書の情報を表示
for result in response.results:
print(f"ソース: {result.document.name}")
print(f"内容: {result.content}")
目的:この部分では、AIが回答を生成する際に参照した文書の情報を表示します。
result.document.name: 文書の名前(例:Cloud Storage 上のファイルパス)result.content: その文書の中で、AIが参考にした具体的な抜粋内容
これにより、AIの回答の根拠がどこにあるかを人間が確認できます。信頼性や透明性を確保するために重要な要素です。
実行結果イメージ(出力例)
AIによる回答:
2023年の財務報告書によると、売上高は前年比15%増加し、純利益も過去最高を記録しました。
根拠となったソース文書:
ソース: gs://your-bucket/financial_reports/q4_summary.pdf
内容: 売上高は前年比15%の増加を記録し、2023年は過去最高となった。
—————————————-
ソース: gs://your-bucket/financial_reports/annual_overview.pdf
内容: 純利益は前年の2倍に達し、事業の効率化が大きく貢献した。
—————————————-
このサンプルコードでは、生成された自然な回答と、それを支える文書の具体的な抜粋をセットで表示することで、ユーザーは「何をもとに答えが導かれたか」を明確に把握できるようにしてます。
LlamaIndex: オープンソースで実現する柔軟なRAGフレームワーク
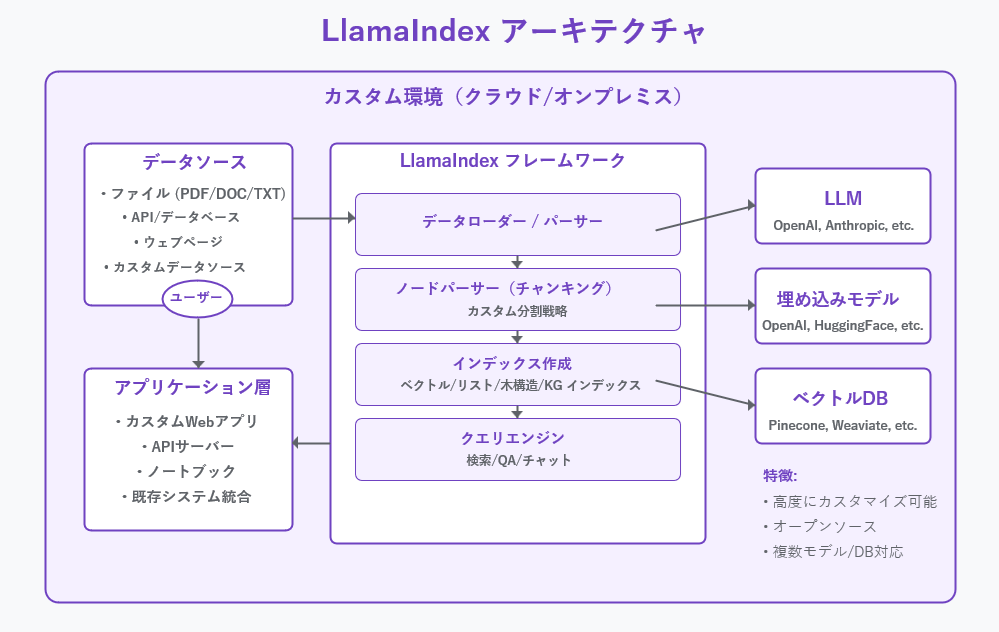
概要と特徴
LlamaIndexは、開発者が独自のデータソースを大規模言語モデルと効果的に連携させるためのオープンソースフレームワークです。高い柔軟性とカスタマイズ性を特徴とし、多様なデータソース、LLM、ベクトルデータベースとの連携をサポートしています。
主な特徴は次のとおりです:
- オープンソース: 無料で利用可能、コミュニティによる継続的な改良
- 高度なカスタマイズ性: 処理パイプラインの各段階で詳細な調整が可能
- 多様なデータソース対応: 様々な形式やAPIからのデータ取り込みをサポート
- 複数のインデックスタイプ: ベクトル、リスト、木構造、知識グラフなど
- 多様なLLM/埋め込みモデル対応: OpenAI、Anthropic、HuggingFaceなど
- 複数のベクトルDBとの連携: Pinecone、Weaviate、Chroma、Milvusなど
- 柔軟なデプロイメント: クラウド、オンプレミス、ローカル環境での実行が可能
アーキテクチャとワークフロー
LlamaIndexのアーキテクチャは図に示されているように、高度にモジュール化されています。以下のコンポーネントで構成されています:
- データソース層: ファイル、API、データベース、ウェブページなど多様なソース
- LlamaIndexフレームワーク:
- データローダー/パーサー: 様々なソースからのデータ取り込み
- ノードパーサー: カスタマイズ可能なテキスト分割戦略
- インデックス作成: 多様なインデックス構造の構築
- クエリエンジン: 検索、質問応答、チャットなどの機能提供
- 外部サービス連携:
- LLM: OpenAI、Anthropicなどの複数のプロバイダー
- 埋め込みモデル: データのベクトル表現生成
- ベクトルデータベース: 高速な類似性検索のための外部ストレージ
- アプリケーション層: カスタムWebアプリ、APIサーバー、ノートブックなど
実装プロセス
LlamaIndexを使用したRAGシステムの構築は、以下のステップで進行します:
- Pythonパッケージと依存関係のインストール
- データソースの特定とローダーの選択
- チャンキング戦略の設計とノードパーサーの構成
- インデックスタイプの選択と構築
- クエリエンジンの設定と最適化
- アプリケーションとの統合
- 必要に応じたスケーリングソリューションの実装
LlamaIndexを利用したサンプルコード
# LlamaIndexを使用したシンプルな実装例
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import StorageContext, load_index_from_storage
# データの読み込み
documents = SimpleDirectoryReader("./financial_reports").load_data()
# インデックスの構築
index = VectorStoreIndex.from_documents(documents)
# 永続化(オプション)
index.storage_context.persist("./financial_index")
# クエリエンジンの作成とクエリの実行
query_engine = index.as_query_engine()
response = query_engine.query("財務報告書の最新情報は?")
print(response)【サンプルコードの解説】
1. モジュールのインポート
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import StorageContext, load_index_from_storage
目的: LlamaIndexの基本機能(文書の読み込み、インデックス作成、ストレージの読み書き)に必要なクラスや関数をインポートします。
VectorStoreIndex: ベクトル検索インデックスの構築用クラスSimpleDirectoryReader: フォルダ内のファイルをまとめて読み込むユーティリティStorageContext,load_index_from_storage: 永続化されたインデックスの再読み込み用
2. データの読み込み
documents = SimpleDirectoryReader("./financial_reports").load_data()
目的: 指定されたディレクトリ(ここでは ./financial_reports)にある文書ファイルを読み込んで、LlamaIndexで処理可能な形式(Document オブジェクト)に変換します。
.load_data()を呼ぶと、対象ディレクトリ内の.txt,.pdf,.mdファイルなどが自動的に読み込まれます。- 読み込まれた各文書はメモリ上に格納され、後のインデックス構築に使われます。
3. インデックスの構築
index = VectorStoreIndex.from_documents(documents)
目的: 読み込んだ文書をベクトル化し、検索可能なインデックス(VectorStoreIndex)を作成します。
- LlamaIndex内部では、各文書のテキストを分割し、それぞれのチャンクをベクトルに変換(埋め込み)します。
- このベクトル表現をもとに、ユーザーからの質問との類似性を計算して、関連する文書を検索します。
4. インデックスの永続化(オプション)
index.storage_context.persist("./financial_index")
目的: 作成したインデックスを指定フォルダ(ここでは ./financial_index)に保存し、次回以降の再利用を可能にします。
.persist()により、ベクトル情報やメタデータがディスクに保存されます。- この処理は必須ではありませんが、大規模データや複数回の検索において再構築の手間を省くのに有効です。
5. クエリエンジンの作成とクエリの実行
query_engine = index.as_query_engine()
response = query_engine.query("財務報告書の最新情報は?")
目的: 作成したインデックスをもとに、自然言語クエリに対応する検索・生成エンジンを作り、質問を実行して回答を得ます。
.as_query_engine()は、インデックスをラップしてクエリ用エンジンを返します。.query()に質問文を渡すと、関連文書を検索し、それを元に大規模言語モデル(LLM)が回答を生成します。
6. 回答の出力
print(response)
目的: 生成された回答(自然文)をコンソールに出力します。
responseはResponseオブジェクトですが、print()で自動的に自然文として表示されるように設計されています。- 必要に応じて、
response.responseで純粋なテキストだけを取り出すことも可能です。
徹底比較: Vertex AI vs LlamaIndex – コスト・運用・スケーラビリティ
RAG(Retrieval-Augmented Generation)システムの構築において、Vertex AI RAG EngineとLlamaIndexのどちらを選択するかは、ビジネス要件、技術的要件、コスト、運用負荷など多岐にわたる要素を総合的に検討する必要があります。以下に、判断基準となる主要なポイントを整理します。
1. コスト構造の比較
Vertex AI RAG Engine:
- 初期費用: データの取り込みやインデックス作成に伴う埋め込み生成コスト、インデックス構築コストが発生します。
- 運用費用: 選択するバックエンド(Vertex AI SearchまたはVertex AI Vector Search)により、ストレージコスト、クエリ実行コスト、サービングコストが変動します。
- 無料枠: Vertex AI Searchでは、毎月最初の10 GiBのインデックスストレージが無料で提供されます。
LlamaIndex:
- 初期費用: ソフトウェア自体は無料ですが、環境構築や必要なインフラのセットアップに関連するコストが発生します。
- 運用費用: クラウドサービス(例:Compute Engine、Cloud Storage、サードパーティのベクトルデータベース)の利用に伴うコストが発生します。
2. 技術的要件と運用負荷
Vertex AI RAG Engine:
- 利便性: マネージドサービスとして提供されるため、インフラ管理の負担が軽減されます。
- 柔軟性: バックエンドの選択肢が限られるため、特定の要件に対する柔軟性は制約される可能性があります。
LlamaIndex:
- 柔軟性: オープンソースであるため、カスタマイズや特定の要件に応じた調整が可能です。
- 運用負荷: 環境構築、スケーリング、メンテナンスなど、インフラ管理の責任が伴います。
3. スケーラビリティとパフォーマンス
Vertex AI RAG Engine:
- スケーラビリティ: Google Cloudのインフラ上で動作するため、高いスケーラビリティが期待できます。
- パフォーマンス: 最適化されたサービスとして、高いパフォーマンスを提供します。
LlamaIndex:
- スケーラビリティ: 使用するインフラや設定に依存し、適切な設計と管理が必要です。
- パフォーマンス: 環境や設定により変動し、最適なパフォーマンスを得るためには調整が必要です。
4. セキュリティとコンプライアンス
Vertex AI RAG Engine:
- セキュリティ: Google Cloudのセキュリティ基準に準拠しており、高いセキュリティレベルが期待できます。
- コンプライアンス: 各種規制やコンプライアンス要件に対応するための機能が提供されています。
LlamaIndex:
- セキュリティ: 自社でのセキュリティ対策が必要であり、適切な設定と管理が求められます。
- コンプライアンス: 使用するインフラやデータの取り扱いに応じて、適切な対策が必要です。
企業要件別・最適なRAGツール選定ガイド
| 項目 | Vertex AI RAG Engine | LlamaIndex |
|---|---|---|
| 初期費用 | 埋め込み生成、インデックス構築に伴うコストが発生 | ソフトウェアは無料だが、環境構築に関連するコストが発生 |
| 運用費用 | バックエンド選択により変動(ストレージ、クエリ実行、サービングコスト) | クラウドサービス利用に伴うコストが発生 |
| 無料枠 | Vertex AI Searchで毎月最初の10 GiBのインデックスストレージが無料 | なし |
| 利便性 | マネージドサービスでインフラ管理の負担が軽減 | 環境構築、スケーリング、メンテナンスの責任が伴う |
| 柔軟性 | バックエンドの選択肢が限られる | オープンソースでカスタマイズが可能 |
| スケーラビリティ | 高いスケーラビリティが期待できる | インフラや設定に依存し、適切な設計が必要 |
| パフォーマンス | 最適化された高いパフォーマンスを提供 | 環境や設定により変動し、調整が必要 |
| セキュリティ | Google Cloudのセキュリティ基準に準拠 | 自社での適切なセキュリティ対策が必要 |
| コンプライアンス | 各種規制や要件に対応する機能を提供 | インフラやデータ取り扱いに応じた |
2025年以降のRAG技術トレンドと展望
Vertex AI RAG EngineとLlamaIndexは、それぞれ異なる強みを持つRAG構築ツールです。
Vertex AI RAG Engineは、エンタープライズグレードの信頼性、スケーラビリティ、セキュリティを提供するマネージドソリューションとして、大企業や迅速な展開を求める組織に適しています。その一方で、サービス依存性とカスタマイズの制限があります。
LlamaIndexは、高度な柔軟性、カスタマイズ性、多様なコンポーネント統合を提供するオープンソースフレームワークとして、研究開発、特殊ユースケース、コスト効率を重視する組織に適しています。ただし、実装の複雑さと運用負荷が増大します。
最適な選択は、組織の具体的な要件、リソース、技術スタック、および長期的な目標に基づいて行うべきです。時には、両方のアプローチを組み合わせることで、最大の価値を引き出せる場合もあるでしょう。
RAG技術は急速に進化しており、両方のツールも継続的に機能強化されています。定期的に最新の機能と制限を評価し、組織のニーズに最適なソリューションを選択することが重要です。
今後の展望
RAGシステムは企業のAI戦略において今後ますます重要な位置を占めていくでしょう。Vertex AI RAG EngineとLlamaIndexの進化に加え、新たなツールやフレームワークも登場しています。
また、マルチモーダルRAGやエージェント型RAGといった新しい概念も注目を集めています。組織はRAGの技術的進化を理解し、自社に最適な形で導入することで、データの価値を最大化し、競争優位性を確立できるでしょう。
さらに、RAGの精度や効率を評価する指標の確立、業界別ベストプラクティスの共有など、RAGエコシステム全体の成熟も期待されます。
参考情報
- Google CloudとRAG | LlamaIndex on Vertex AI編
- LlamaIndexとは?RAGの構築を実現するライブラリの機能やメリット
- LlamaIndexとVertex AI Vector Searchで手を動かしながらRAGの実装
ここに本文を入力
以上








