


※本記事は継続的に最新情報へアップデートしています。
Agentic RAGとは?RAG構築で使うAIエージェントツールの役割と選び方【2026年版】
RAGを作ったものの、「検索が外れる」「根拠が弱い」「再検索や評価を自動化できない」と悩む現場が増えています。
Agentic RAGとは、単にRAGへAIエージェントを足す技術ではありません。研究コミュニティでは、エージェントが「検索=Retrieval」をひとつのツールとして呼び出しながら、計画・検索・評価・再検索を自律的に繰り返すRAGアーキテクチャを指すことが多くなっています。
本記事ではこの流れを踏まえつつ、検索・評価・再検索・ツール実行・監視をどのコンポーネントに担わせるかを設計する実務上の考え方としてAgentic RAGを扱い、LangGraph、LlamaIndex、CrewAI、Microsoft Agent Framework、Ragasなどを、いつ・どう使うべきかを整理します。
✅ 先に結論
Agentic RAGは、通常のRAGをすべて置き換える上位互換ではありません。まずはClassic RAGやHybrid RAGで検索品質と評価基盤を固め、なお残る検索失敗・意図誤解・根拠不一致に対して、Corrective RAG、Self-RAG、Agentic RAGを段階的に導入する設計パターンです。
- ポイント1(順番):最初からAgentic RAGに飛びつくのではなく、ETL、チャンキング、Hybrid Search、Reranker、Evalsを先に整える。
- ポイント2(使い分け):検索失敗を直したいならCorrective RAG、根拠を自己評価したいならSelf-RAG、複数ステップの調査・業務実行まで任せたいならAgentic RAGを検討する。
- ポイント3(ツール選定):LangGraphは状態管理と制御、LlamaIndexはデータ接続と検索、CrewAIは役割分担、Microsoft Agent Frameworkは企業統制、Ragasは評価に使う。

何が変わったのか:一発検索型RAGから、評価・再検索できるRAGへ
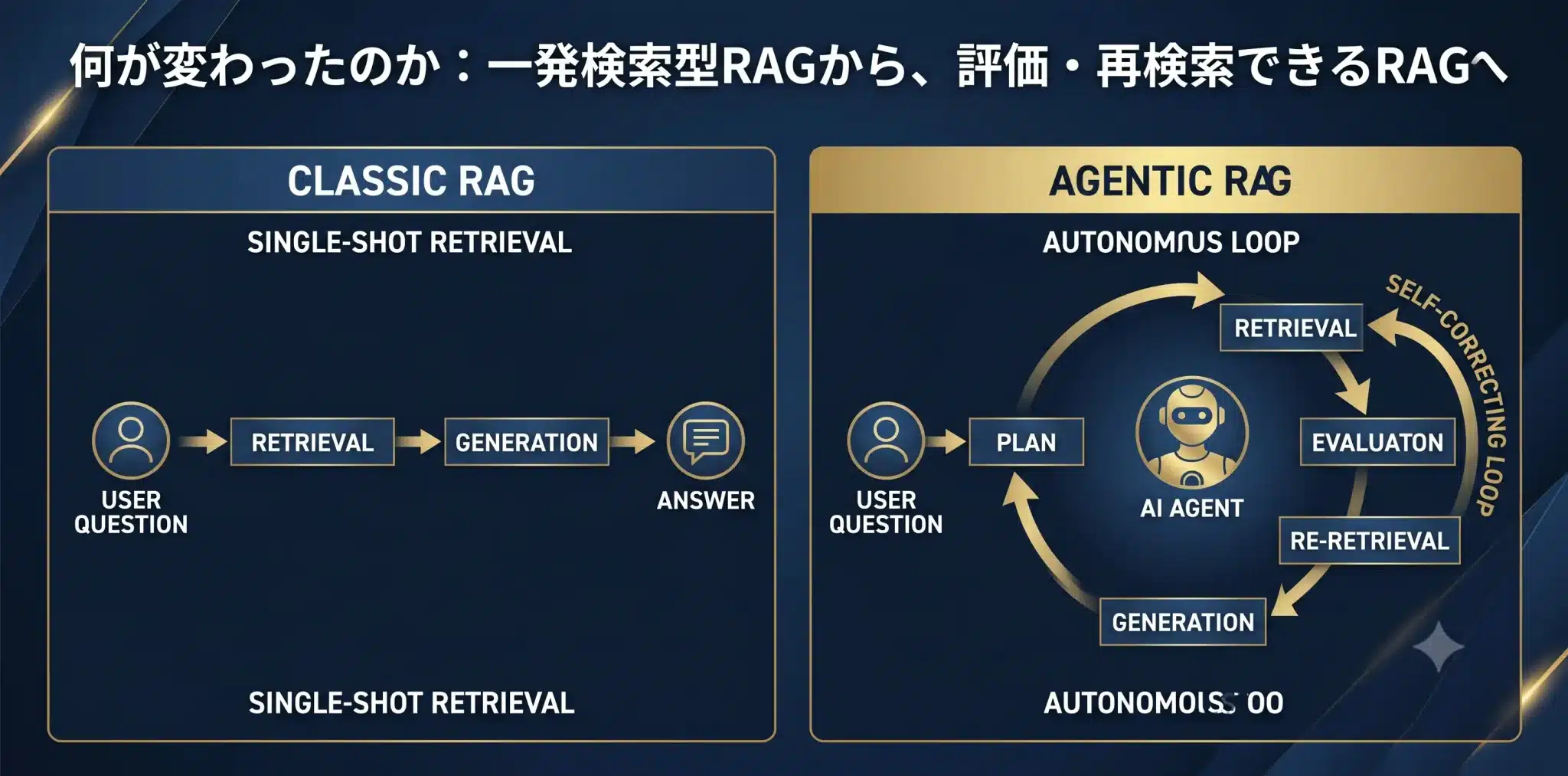
Agentic RAGの本質は、RAGを「検索して終わり」から「評価して直す」仕組みに変えることです。
従来のRAGは、ユーザーの質問に対して文書を検索し、その検索結果をLLMに渡して回答を生成する、比較的シンプルな構造でした。この構成は、社内FAQ、規程検索、技術文書検索のような用途では今でも有効です。
しかし、実務でRAGを使うと、次のような問題が起きます。
- 最初の検索クエリが外れると、必要な根拠にたどり着けない
- 検索結果にノイズが混ざっても、そのまま回答生成に使われる
- ユーザーの意図を読み違えたまま、もっともらしい回答を返す
- 回答が正しいか、根拠と整合しているかを自動で評価できない
Agentic RAGは、ここにAIエージェントの計画、判断、評価、再試行を組み込みます。つまり、RAGを一回きりの検索パイプラインではなく、「計画→検索→評価→再検索→生成」という反復型ワークフローとして設計する考え方です。
従来のRAGとAgentic RAGの違い
👨🏫 図1の解説ポイント
この図は、従来のRAGとAgentic RAGの根本的な違いを示しています。
- 従来のRAGは、ユーザーの質問に対して「検索→生成」という一方向のプロセスを一度だけ実行します。最初の検索が失敗すると、そのまま回答品質が落ちます。
- Agentic RAGは、AIエージェントが介在し、「計画→検索→評価→再計画」というサイクルを回します。結果が不十分なら、検索戦略を練り直して再検索する自己修正ループを持ちます。
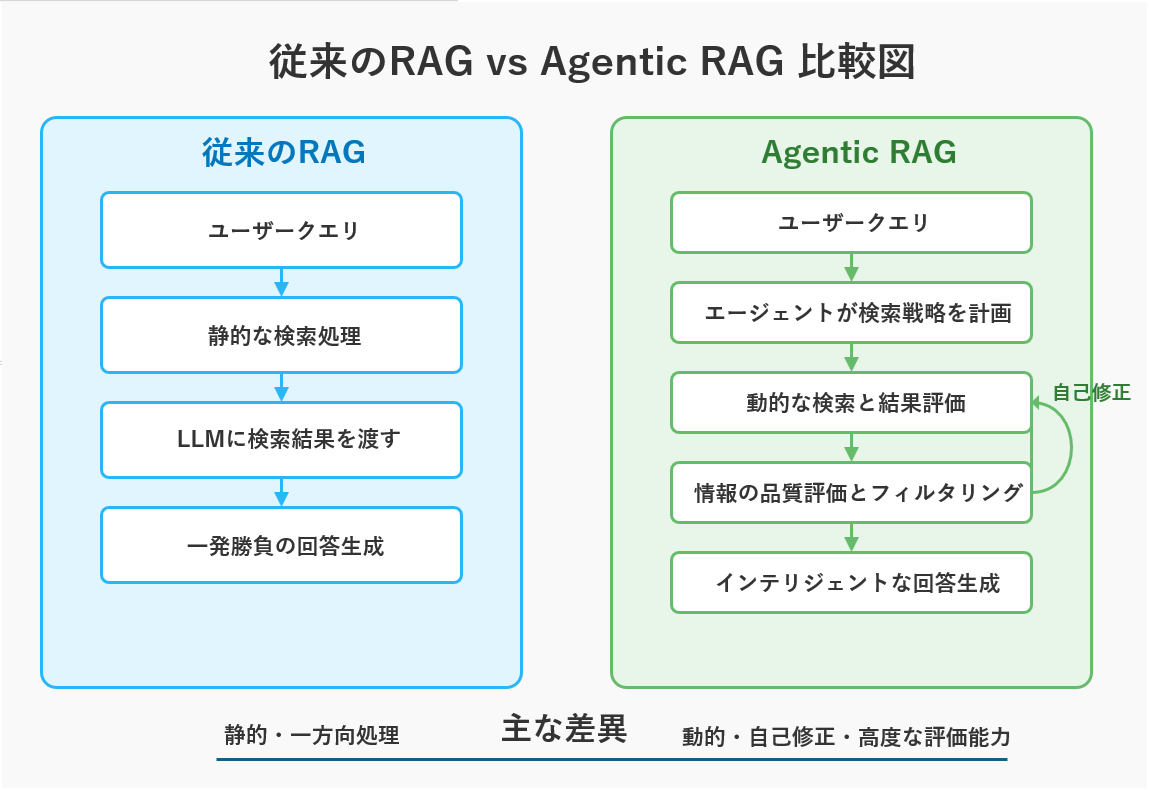
なぜ今重要なのか:RAGのPoCを本番運用へ進めるため

Agentic RAGは、RAGのPoCを本番運用へ進めるときに残る「検索失敗・評価不能・運用不能」の壁を越えるための考え方です。
RAGの基本構造は、すでに多くの企業で知られるようになりました。しかし、本番運用で問題になるのは「RAGを作れるか」ではなく、検索失敗を検知し、改善し続けられるかです。
RAG全体の基礎構造、ETL、チャンキング、Embedding、Vector DB、Reranking、評価設計については、まず RAG完全ガイド で整理しています。本記事は、その応用編として、RAGをどこまで自律化し、どのツールで支えるかを扱います。
Agentic RAGが重要になるのは、特に次のような場面です。
- 検索結果が外れたときに、自動でクエリを作り直したい
- 回答生成前に、取得した根拠が十分かどうかを評価したい
- 複数の検索先やデータソースを、質問内容に応じて使い分けたい
- 調査、要約、レビュー、承認などを複数エージェントに分担させたい
- 本番運用で、評価ログ、失敗検知、人間レビューを組み込みたい
重要なのは、Agentic RAGを「すごい新技術」として見ることではありません。RAG構築において、どの失敗を、どのツールで、どの順番で直すのかを設計することです。
Agentic RAG / Self-RAG / Corrective RAG / Adaptive RAG の違い
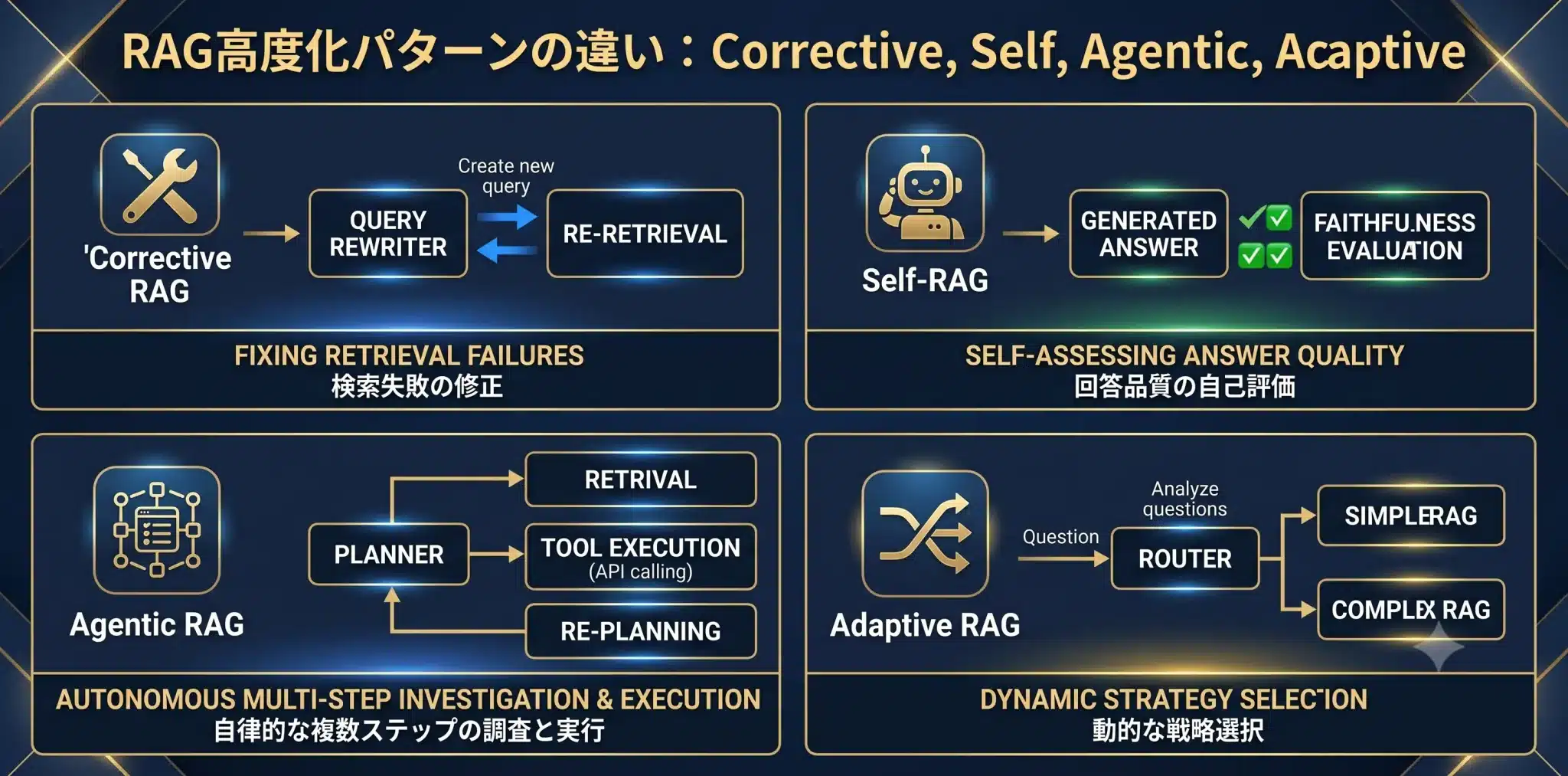
Agentic RAG周辺の用語は似ていますが、解決する課題は異なります。まず役割を分けて理解することが重要です。
Agentic RAGを理解するには、Classic RAG、Hybrid RAG、Corrective RAG、Self-RAG、Adaptive RAGとの違いを押さえる必要があります。これらは競合する概念ではなく、RAGを段階的に高度化するための設計パターンです。
| パターン | 何を解決するか | 使う場面 | 主なツール・要素 |
|---|---|---|---|
| Classic RAG | LLMに外部知識を参照させる | FAQ、社内規程検索、単純な文書検索 | LlamaIndex / LangChain / Vector DB |
| Hybrid RAG | 検索漏れや固有名詞の取りこぼしを減らす | 型番、顧客名、規程番号、専門用語が多い業務 | Vector DB / BM25 / Metadata Filter / Reranker |
| Corrective RAG | 検索失敗を検知し、クエリ修正や再検索を行う | 最初の検索が外れやすい業務 | LangGraph / Ragas / Evals / Query Rewriter |
| Self-RAG | 取得根拠や回答品質を自己評価する | 回答の根拠整合性を安定させたい業務 | LangGraph / Evals / Faithfulness評価 |
| Agentic RAG | 計画、検索、評価、ツール実行、再試行をつなぐ | 複数ステップの調査、比較、業務実行 | LangGraph / CrewAI / Microsoft Agent Framework |
| Adaptive RAG | 質問の難易度や種類に応じて検索戦略を変える | 単純質問と複雑質問が混在する業務 | Router / LlamaIndex / LangGraph |
| ※ 出典:Arpable Tech TeamによるRAG高度化パターン整理(2026年5月時点) | |||
RAG高度化の段階モデル
Classic RAG(まず検索して答える) → Hybrid RAG(検索漏れを減らす) → Corrective RAG(検索失敗を直す) → Self-RAG(根拠を自己評価する) → Agentic RAG(計画・ツール実行まで自律化する)
この順番は「必ずすべて導入する」という意味ではありません。業務上の失敗パターンに応じて、必要な段階だけを追加します。
この表とロードマップから分かるように、Agentic RAGは「RAGを全部置き換える方式」ではありません。むしろ、Classic RAGやHybrid RAGで土台となる検索品質を固め、その上にCorrective RAG(検索失敗の修正)→ Self-RAG(根拠の自己評価)→ Agentic RAG(計画・ツール実行まで含む自律化)を必要な範囲だけ積み上げていく段階モデルだと考えると、設計と議論がスムーズになります。
Agentic RAGが解決する3つの課題
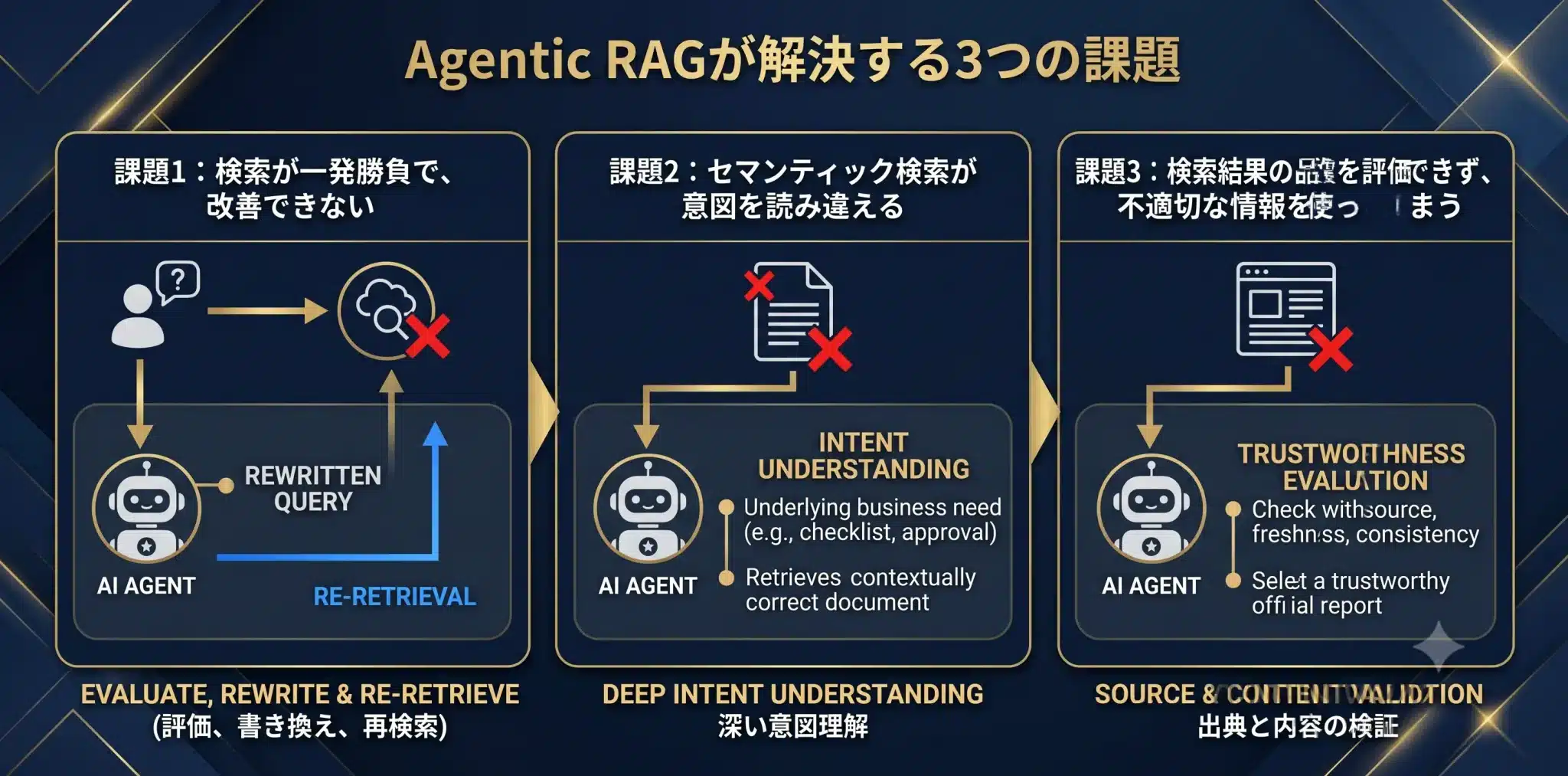
Agentic RAGが本当に効くのは、検索失敗、意図誤解、根拠不一致を運用上の失敗として検知し、修正したい場面です。
現行のRAGが抱える主な課題と、Agentic RAGによる解決アプローチを、代表的な3つのシナリオで見ていきます。
課題1:検索が一発勝負で、改善できない
【従来の失敗シナリオ】
ユーザーが「社内のパスワードポリシー、特に文字数について教えて」と質問しても、従来のRAGはキーワード「パスワード」「ポリシー」で一般的な文書しか見つけられず、具体的な答えを返せないことがあります。最初の検索が的外れでも、通常のRAGでは自動修正が難しいのです。
【Agentic RAGによる解決】
Agentic RAGでは、AIエージェントが初期検索結果を評価し、「ユーザーの要求に対して具体性が不足している」と判断します。次に、検索戦略を修正し、「パスワード ポリシー 文字数」「認証ルール 最小文字数」「情報セキュリティ規程 パスワード」など、より具体的なクエリに変換して再検索します。
このような検索→評価→クエリ修正→再検索の流れは、Corrective RAGに近い設計です。実装では、LangGraphで状態と分岐を管理し、Ragasや自社Evalsで検索結果の十分性を評価する構成が有効です。
課題2:セマンティック検索が意図を読み違える
【従来の失敗シナリオ】
「進行中のプロジェクトAの終了手順」を質問すると、意味が近いというだけで「プロジェクト完了報告書の書き方」や「過去プロジェクトの振り返り資料」など、文脈に合わない情報を提示してしまうことがあります。
【Agentic RAGによる解決】
この場合、必要なのは単なる意味検索ではありません。ユーザーの「終了手順」という言葉の裏にある、「チェックリスト」「承認フロー」「完了条件」「アカウント停止」「ドキュメント保管」といった業務意図を推測し、検索戦略を再構成する必要があります。
実務では、LlamaIndexやLangChainを使ってRetrieverを構成し、メタデータフィルタ、Reranker、Query Plannerを組み合わせます。さらにLangGraphで「検索結果が手順書ではない場合は再検索する」といった条件分岐を設計すると、意図誤解に強いRAGになります。
課題3:検索結果の品質を評価できず、不適切な情報を使ってしまう
【従来の失敗シナリオ】
Web検索や社外情報を含むRAGでは、信頼性の高い公式レポートと、不確かなフォーラム投稿や古いブログ記事が混在することがあります。従来のRAGは、それらを十分に区別できず、信頼性の低い情報を根拠として回答してしまうリスクがあります。
【Agentic RAGによる解決】
Agentic RAGでは、収集した情報に対して、出典の信頼性、情報の鮮度、他情報との整合性、社内ルールとの矛盾を評価します。必要に応じて、人間レビューや承認フローを挟むことも重要です。
これはSelf-RAGやEvals、Observabilityの領域と深く関係します。本番運用では、検索結果、参照チャンク、回答、引用、ユーザー評価、失敗理由をログとして残し、どこで品質が落ちたのかを追跡できるようにします。
Key Takeaways(持ち帰りポイント)
- 従来のRAGは一発勝負の静的検索になりやすく、検索失敗に弱い。
- Agentic RAGは、AIエージェントによる検索・評価・再検索の自己修正ループを加える。
- 重要なのは、Agentic化そのものではなく、どの失敗をどのツールで直すかを設計すること。
RAGと長文コンテキストLLMはどう使い分けるか
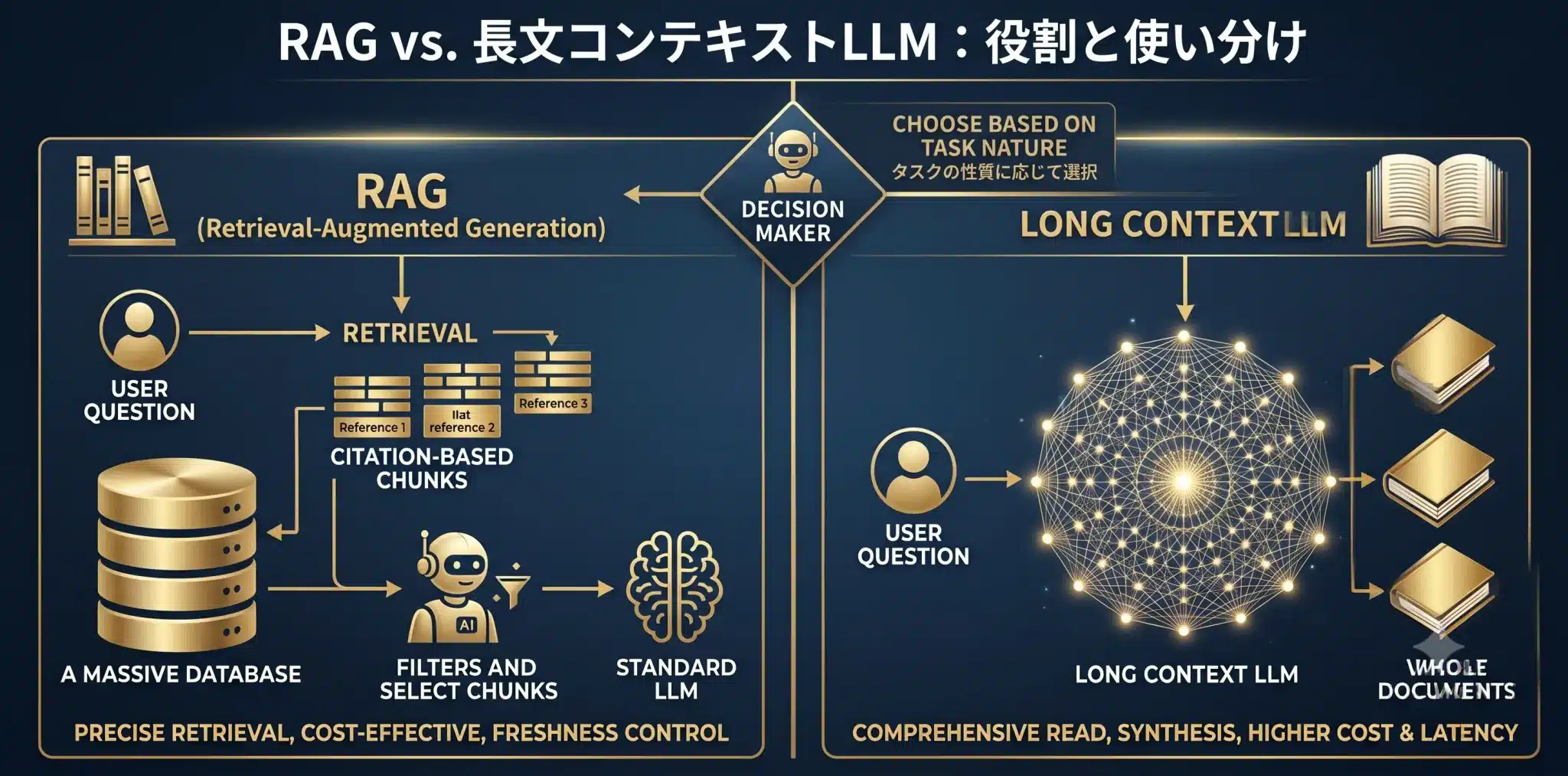
長文コンテキストLLMが進化しても、RAGは不要になりません。両者は役割が異なります。
長文コンテキストLLMの進化により、数十万トークン以上を一度に投入できるモデルが増えています。そのため、「大量の文書をそのままLLMに読ませればRAGは不要になるのではないか」という議論があります。しかし、実務ではRAGと長文コンテキストLLMは対立関係ではなく、補完関係です。
RAGは、必要な情報を検索・選別し、根拠、権限、鮮度、コストを制御する仕組みです。一方、長文コンテキストLLMは、選別済みの複数文書を横断的に読み解き、要約や統合判断を行う場面で強みを持ちます。
| 観点 | RAGが得意なこと | 長文コンテキストLLMが得意なこと |
|---|---|---|
| 情報選別 | 必要な文書だけを検索して絞り込む | 与えられた大量文書をまとめて読む |
| 根拠提示 | チャンクや出典を引用しやすい | 根拠管理は設計次第で曖昧になりやすい |
| 権限制御 | 文書単位・ユーザー単位で制御しやすい | 投入前の制御設計が重要 |
| 鮮度 | データ更新を反映しやすい | 投入する文書セットに依存する |
| コスト | 必要情報だけを渡せるため制御しやすい | 大量投入ではコストや遅延が増えやすい |
Agentic RAGは、この両者の使い分けを制御する役割を担います。たとえば、まずRAGで関連情報を絞り込み、必要に応じて長文コンテキストLLMへ渡し、回答前に根拠整合性を評価する、といった設計が考えられます。
RAG構築で使う主要ツールの役割
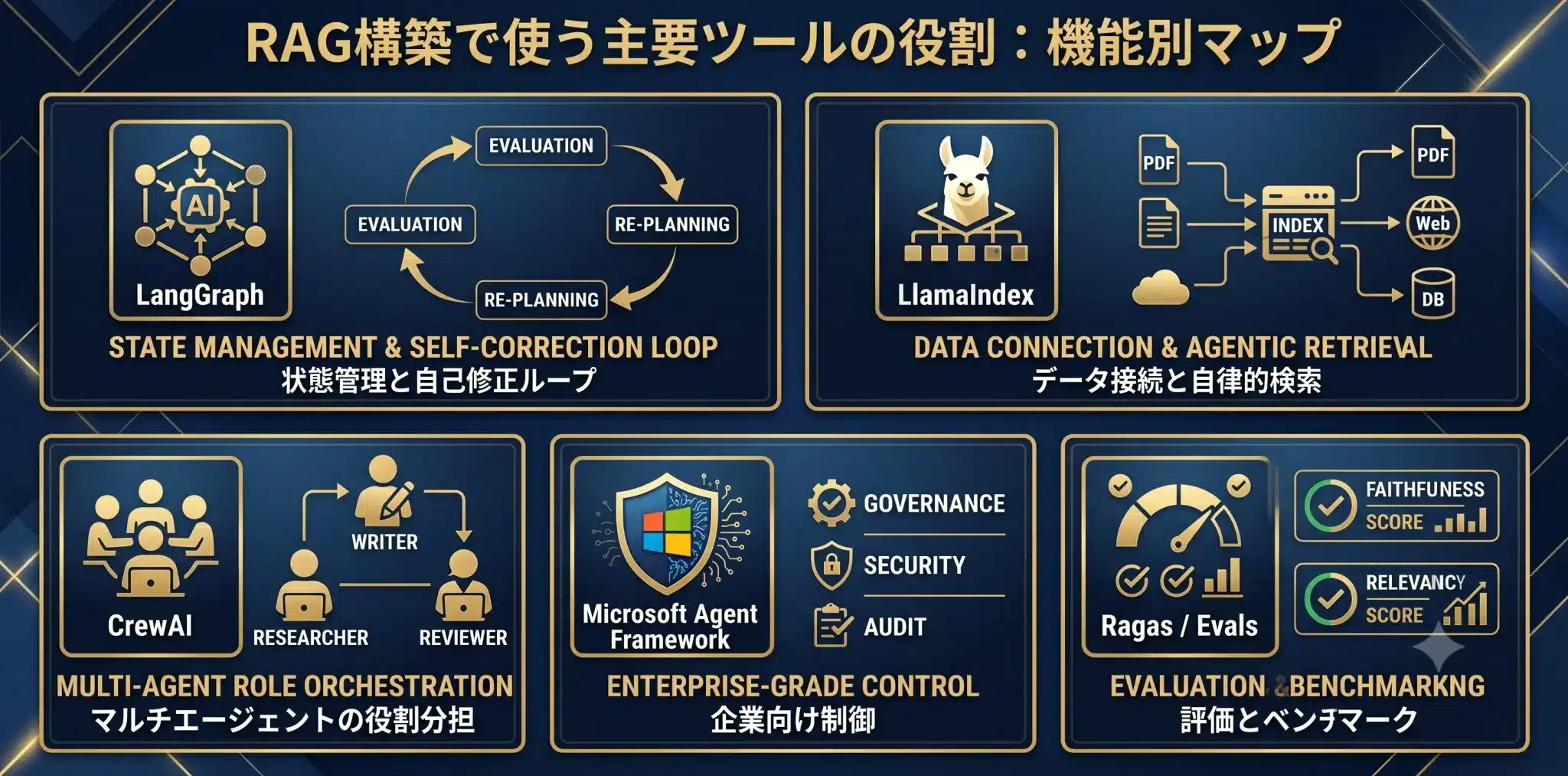
ツール選定で重要なのは、有名かどうかではなく、RAGパイプラインのどの課題を担わせるかです。
Agentic RAG構築では、複数のツールが登場します。しかし、それぞれの役割は異なります。ここでは、RAG構築の実務で使う主要ツールを、役割別に整理します。
| ツール・領域 | RAG構築での主な役割 | 使う場面 | 注意点 |
|---|---|---|---|
| LangGraph | 状態管理、条件分岐、再検索、HITL、自己修正ループ | Agentic RAGの中核制御を設計したいとき | ワークフローが複雑になりすぎないよう、停止条件とログを設計する |
| LlamaIndex | データ接続、Index、Retriever、文書処理、Agentic Retrieval、Workflows | 社内文書、PDF、複数データソースを扱うRAG。Workflowsはイベント駆動型で、文書処理や複数ステップの検索パイプラインに向く。 | データ品質、メタデータ、チャンク設計が弱いと性能が出にくい |
| LangChain Agents | ツール呼び出し、簡易エージェント化、プロトタイピング | 小さくAgentic RAGの挙動を試すとき | 本番運用では状態管理、評価、監査を別途設計する |
| CrewAI | 役割分担型マルチエージェント、調査・要約・レビュー分担 | 複数ロールで業務プロセスを自動化したいとき | 本番ではFlowで状態と実行順序を管理し、Crewは特定作業に使う |
| Microsoft Agent Framework | 企業向けエージェント開発フレームワーク、状態管理、テレメトリ、ワークフロー制御 | Microsoft / Azure / .NET / Python 環境でAgentic RAGを開発したいとき | Foundry Agent Serviceなどのホスティング・運用基盤とは役割を分けて理解する |
| Microsoft Foundry Agent Service | エージェントのホスティング、デプロイ、スケーリング、運用基盤 | Agent FrameworkやLangGraphで作ったエージェントをマネージド基盤で運用したいとき | SDKではなく、ホスティング・運用基盤として捉える |
| Ragas / Evals | 検索品質、回答品質、根拠整合性の評価 | Agentic化の前後で品質を測りたいとき | 公式の絶対基準ではなく、自社ユースケースごとの評価基準を作る |
| Observability基盤 | ログ、失敗検知、コスト、レイテンシ監視 | 本番運用で改善ループを回したいとき | 質問、検索結果、回答、引用、失敗理由を記録する |
| Vector DB / Hybrid Search | 検索基盤、意味検索、キーワード検索、メタデータ検索 | そもそも検索精度を高めたいとき | Agentic化より前に検索基盤を整えることが多い |
LangGraph:状態管理と自己修正ループの中核
LangGraphは、Agentic RAGにおける状態管理、分岐、再試行、人間介在を設計するための中核候補です。検索結果が不十分な場合に再検索する、回答前に評価を挟む、人間の承認が必要な処理で止める、といった流れをグラフ構造で表現できます。
詳しくは LangGraphとは?LangChain・CrewAI・MAFとの使い分けと本番設計 でも解説しています。
LlamaIndex:データ接続とRetrieverの中核
LlamaIndexは、RAGのデータ連携、Index、Retriever、文書処理に強いツールです。社内文書、PDF、ナレッジベース、複数データソースを扱う場合、まずLlamaIndexで検索基盤を整え、その上にAgentic Retrievalや再検索制御を重ねる構成が有効です。
さらに、LlamaIndex Workflowsは、イベント駆動型で複数ステップの処理を制御する仕組みとして使えます。文書処理、検索パイプライン、評価、再検索のように、RAGの前後処理を段階的に組み立てたい場合に相性がよい選択肢です。
LangChain Agents:小さく試すプロトタイピング
LangChain Agentsは、ツール呼び出しや簡易的なエージェント化を試す際に便利です。既存のRAGにWeb検索、計算、API呼び出しなどを追加し、Agenticな挙動を小さく検証する用途に向いています。
ただし、本番運用では、状態管理、停止条件、評価ログ、監査設計を明示的に追加する必要があります。
CrewAI:役割分担型のマルチエージェント
CrewAIは、調査担当、要約担当、レビュー担当、承認担当のように、役割を分けたマルチエージェント構成に向いています。RAG構築では、複数文書を調査し、要約し、レビューするような業務プロセスで力を発揮します。
本番アプリケーションでは、Flowで状態と実行順序を管理し、Crewを特定の複雑な作業ステップに使う設計が現実的です。詳しくは CrewAIとは?AIチームで業務PoCを高速化する実践ガイド を参照してください。
Microsoft Agent Framework:企業統制を重視する開発フレームワーク
Microsoft Agent Frameworkは、AutoGenとSemantic Kernelを統合した後継フレームワークで、2026年4月3日に .NET / Python 向けの1.0が発表されました。状態管理、テレメトリ、グラフベースのワークフロー制御、マルチエージェントオーケストレーション、MCP / A2A連携を含む本番向けSDKとして位置づけられています。
なお、Microsoftのエージェント関連スタックは、Agent Framework、Microsoft Foundry Agent Service、Semantic Kernel、AutoGen由来の概念が近接しているため、名称や境界が変動しやすい領域です。本記事では、Microsoft Agent Frameworkを「MicrosoftスタックでAgentic RAGを本番運用するための開発フレームワーク」として扱い、Foundry Agent Serviceはホスティング・運用基盤として区別します。
Microsoft / Azure / .NET / Python を中心に本番運用する企業では、Agentic RAGを単体アプリではなく、権限・監査・運用を含む企業基盤として設計するうえで有力な選択肢です。詳しくは Microsoft Agent Frameworkとは?AutoGenとSemantic Kernelを統合する次世代AIエージェント基盤 を参照してください。
Microsoft Foundry Agent Service:ホスティング・運用基盤
Microsoft Foundry Agent Serviceは、エージェントを構築・デプロイ・スケールするためのマネージド基盤です。Agent Framework、LangGraph、または独自コードで構築したエージェントを、Hosted agentsとして運用する選択肢になります。
Agent Frameworkが「どう作るか」を担う開発フレームワークだとすれば、Foundry Agent Serviceは「どう運用するか」を担う基盤です。企業でAgentic RAGを本番運用する場合は、この2つを混同せず、開発フレームワークとホスティング・運用基盤を分けて設計することが重要です。
Ragas / Evals:Agentic化の前後で品質を測る
Agentic RAGで最も避けたいのは、「エージェント化したら賢くなった気がするが、実際に良くなったか分からない」という状態です。そのため、Ragasや自社Evalsで、検索品質、回答品質、根拠整合性、タスク成功率を測る必要があります。
本番運用では、Faithfulness、Answer Relevancy、Context Precisionなどを使って、自社ユースケースごとの評価基準を設定します。たとえば社内FAQや規程検索のように正確性が重視される用途では、Faithfulness 0.90以上、Answer Relevancy 0.85以上、Context Precision 0.80以上をArpableの実務上の参考ラインとして設定する考え方があります。これを下回る軸がある場合、Agentic化より前に、その軸の改善が優先されます。
※上記はRagas公式の固定基準ではなく、自社評価セットを設計する際の実務目安です。対象業務、データ品質、リスク水準によって適正値は変動します。
Evalsは、Agentic RAGの前後で改善効果を比較するための基盤です。重要なのは、汎用ベンチマークのスコアではなく、「自社でどんな失敗が減ったか」「どの業務KPIがどれだけ改善したか」を測ることです。評価基盤なしにAgentic化すると、コストやレイテンシだけが増え、品質改善が見えなくなるリスクがあります。
どういうときに何を使うか
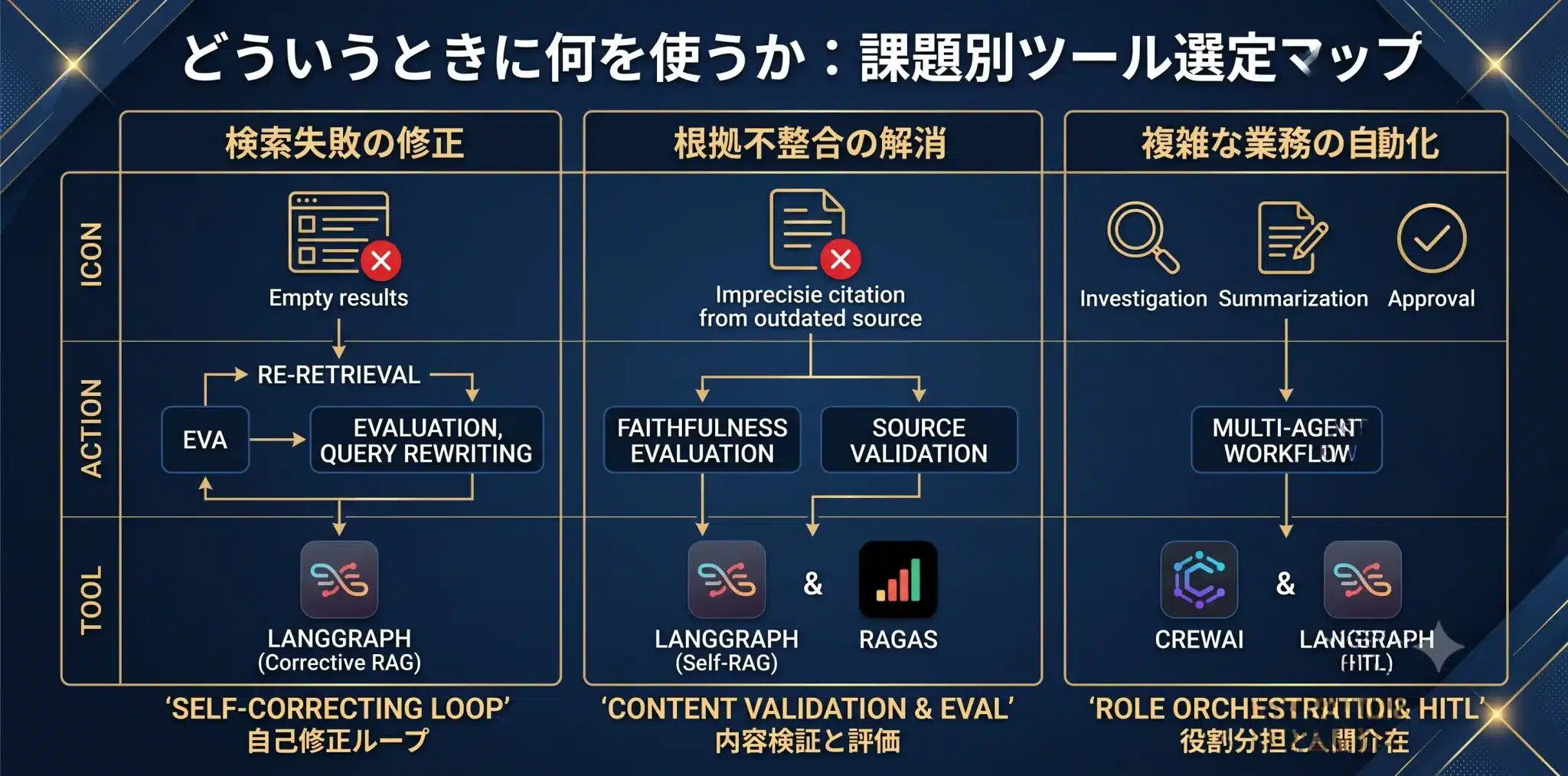
ここが本記事の中核です。RAG構築では、課題ごとに使うツールと順番が変わります。
以下の表は、RAG構築でよくある課題に対して、まず何を使い、Agentic化するなら何を追加すべきかを整理したものです。
| やりたいこと | まず使うもの | Agentic化するなら | 注意点 |
|---|---|---|---|
| 社内文書を検索して回答したい | LlamaIndex / LangChain + Vector DB | LangGraphで再検索・評価ループを追加 | まず検索品質と評価データを整える |
| 検索結果が外れるので再検索させたい | Hybrid Search + Reranker | LangGraphでCorrective RAGを構成 | 再検索条件と停止条件を曖昧にしない |
| 複数文書を調査してレポート化したい | LlamaIndex + LangGraph | CrewAIで調査・要約・レビュー役を分担 | 出典管理とレビュー工程が必要 |
| Microsoft環境で本番運用したい | Microsoft Agent Framework / Foundry Agent Service | Microsoft Agent Frameworkで開発し、Foundry Agent Serviceで運用する | 権限、監査、テレメトリを先に設計 |
| RAGの精度を継続改善したい | Ragas / Evals | 評価結果をもとにSelf-RAG化 | 公式基準ではなく自社基準を作る |
| 検索より先にデータ品質が悪い | ETL / Chunking / Metadata設計 | Agentic化より前に前処理を改善 | エージェント化しても元データ不良は解決しない |
| 外部ツールやAPIも使わせたい | LangChain Agents / Tool Calling | LangGraphやMAFで実行制御を追加 | 権限、失敗時処理、承認フローを設計する |
| 承認が必要な業務に使いたい | HITL設計 / Approval Policy | LangGraph / MAFで人間介在を組み込む | どこで止めるか、誰が承認するかを先に決める |
この表で重要なのは、すべてをAgentic化しないことです。RAGの失敗原因がデータ品質や検索基盤にあるなら、まずETL、チャンキング、メタデータ、Hybrid Search、Rerankerを改善すべきです。
Agentic RAGは、検索基盤がある程度整った後に、評価・再検索・ツール実行・人間レビューを組み込む段階で使います。
実装パターン:小さく始めて段階的に高度化する
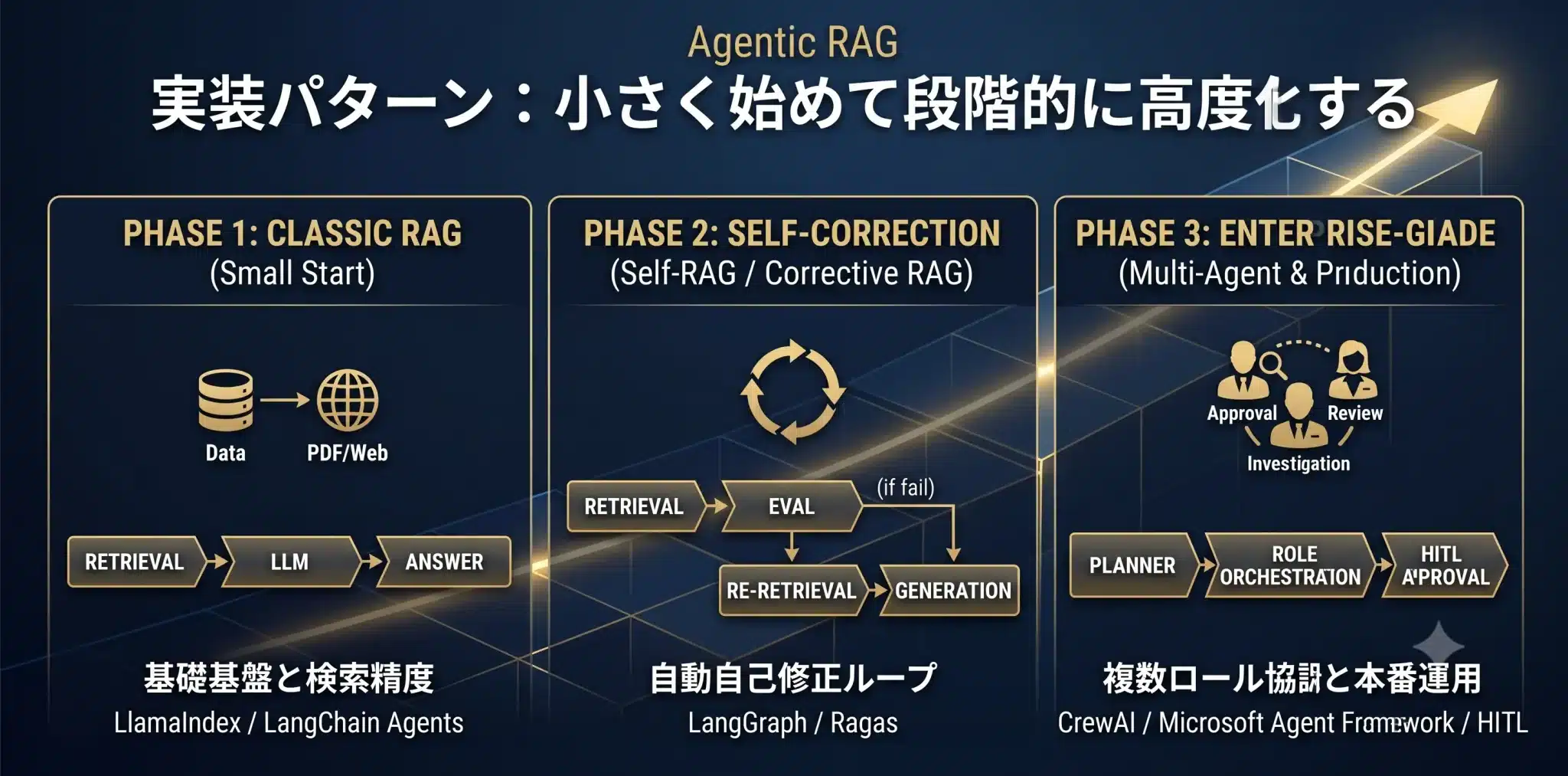
Agentic RAGは、最初から大規模に作るのではなく、失敗パターンに応じて段階的に追加するのが安全です。
パターン1:最小Agentic RAG
最小構成は、検索結果を評価し、不十分なら再検索するだけの構成です。
- ユーザー質問を受け取る
- Retrieverで検索する
- 検索結果が十分かを評価する
- 不十分ならクエリを書き換えて再検索する
- 十分なら回答を生成する
この構成では、LangGraphで状態と分岐を管理し、検索結果の評価にRagasや自社Evalsを使います。
パターン2:Corrective RAG
Corrective RAGは、検索結果が弱い場合に再検索・クエリ修正を行うパターンです。たとえば、検索結果に必要な規程番号や日付が含まれない場合、より具体的なクエリに変換して再検索します。
向いている用途は、社内規程検索、技術サポート、FAQ、手順書検索などです。
パターン3:Self-RAG
Self-RAGは、回答前に取得根拠や回答候補を評価するパターンです。回答が取得文書に忠実か、引用が正しいか、質問に対して十分かを確認します。
向いている用途は、法務、コンプライアンス、技術文書、顧客向けFAQなど、根拠整合性が重要な領域です。
パターン4:マルチエージェントRAG
マルチエージェントRAGでは、調査担当、要約担当、レビュー担当、承認担当のように役割を分担します。CrewAIやMicrosoft Agent Frameworkを使うと、複数ロールの協調を設計しやすくなります。
ただし、役割を増やすほどコスト、レイテンシ、失敗点も増えます。最初は2〜3ロールに絞り、出典管理とレビュー工程を明確にするのが安全です。
パターン5:本番運用RAG
本番運用では、Agentic RAGに加えて、Evals、Observability、HITL、権限制御、Approval Policy、Runbookが必要です。
特に重要なのは、以下のログです。
- ユーザー質問
- 検索クエリ
- 取得チャンク
- 回答内容
- 引用元
- 評価スコア
- 再検索回数
- 失敗理由
- 人間レビューの有無
これらが残らないAgentic RAGは、たとえPoCで動いても、本番では改善できません。
コスト・セキュリティ・運用上の注意点
Agentic RAGは強力ですが、推論回数、権限、ログ、承認を設計しないと、本番運用ではリスクになります。
Agentic RAGは、検索、評価、再検索、ツール実行を複数回行うため、通常のRAGよりもコストやレイテンシが増えやすい構造です。導入時は、回答品質の改善幅と運用コストをセットで評価する必要があります。
コストとレイテンシ
Agentic RAGでは、1つの質問に対して複数回の検索、評価、再検索、LLM呼び出しが発生します。そのため、PoC段階で次の指標を計測します。
- 1質問あたりのLLM呼び出し回数
- 再検索回数
- 平均応答時間
- 失敗時のリトライ回数
- 回答品質の改善幅
- ユーザー満足度
コストが上がっても、業務成果が上がるなら投資価値はあります。しかし、検索基盤が弱いままAgentic化すると、コストだけが増えて精度が上がらないことがあります。
セキュリティと権限
Agentic RAGでは、エージェントが外部ツール、社内DB、API、ファイル、Web検索を呼び出す場合があります。これは便利な一方で、誤操作や情報漏えいのリスクも高めます。
本番では、以下を必ず設計します。
- エージェントに与える権限を最小化する
- 外部送信してよい情報を制限する
- 書き込み系ツールには人間承認を挟む
- アクセス先をホワイトリスト化する
- 操作ログを監査可能な形で残す
- 失敗時の停止条件を明確にする
AIエージェントの接続・権限・監査については、AIエージェントセキュリティ や AIエージェントのゼロトラスト設計 と合わせて読むと理解しやすくなります。
HITLと人間レビュー
Agentic RAGを本番投入する場合、すべてを自動化するのではなく、重要な判断点で人間が介在できるようにします。これをHITL(Human-in-the-Loop)と呼びます。
たとえば、以下の処理は人間承認を挟む候補です。
- 顧客への正式回答
- 契約・法務判断
- 社外送信
- DB更新
- チケット起票
- 金額や納期に関わる判断
Agentic RAGの本番運用では、「どこまでAIに任せるか」ではなく、どこでAIを止め、人間に渡すかを設計することが重要です。
まとめ:Agentic RAGは、RAGを賢くする前に「測れるようにする」技術である
Agentic RAGは、すべてのRAGを置き換えるものではありません。検索失敗を検知し、評価し、必要なときだけ自律化するための設計です。
Agentic RAGは、AIが自律的に思考し、検索し、評価し、再検索する新しいRAGの形です。しかし、その価値は「エージェント化すること」自体にあるわけではありません。
実務で重要なのは、次の順番です。
- Classic RAGで対象業務を絞る
- Hybrid Search、Reranker、メタデータで検索品質を高める
- Ragasや自社Evalsで評価基盤を作る
- 検索失敗が残るならCorrective RAGを導入する
- 根拠整合性を高めたいならSelf-RAGを導入する
- 複数ステップの調査や業務実行が必要ならAgentic RAGを導入する
- 本番ではObservability、HITL、権限制御、監査ログを組み込む
つまり、Agentic RAGとは、RAGをいきなり複雑にする技術ではありません。RAGを測れるようにし、直せるようにし、必要な範囲だけ自律化するための実務設計なのです。
Key Takeaways(持ち帰りポイント)
- Agentic RAGは、RAGの上位互換ではなく、段階的に導入する自律化パターン。
- LangGraphは制御、LlamaIndexは検索・データ接続、CrewAIは役割分担、MAFは企業統制、Ragasは評価に使う。
- 最初に作るべきなのは「エージェント」ではなく、評価データ、ログ、停止条件、改善ループ。
専門用語まとめ
- Agentic RAG
- AIエージェントが、計画、検索、評価、再検索、ツール実行を組み合わせてRAGを制御するアーキテクチャ。
- Self-RAG
- 取得した根拠や生成回答を自己評価し、必要に応じて再検索や回答修正を行うRAGの設計パターン。
- Corrective RAG
- 検索結果が不十分な場合に、検索クエリの修正、再検索、別Retrieverへの切り替えなどを行うRAGの設計パターン。
- Adaptive RAG
- 質問の難易度や種類に応じて、検索戦略、Retriever、回答生成手順を切り替えるRAGの設計パターン。
- 自己修正ループ
- エージェントが自身の行動結果を評価し、目標達成に不十分な場合は、計画や次の行動を自律的に修正するプロセス。
- マルチエージェント
- 調査、要約、レビュー、承認など、異なる役割を持つ複数のAIエージェントが協調してタスクを進めるシステム。
- ツール利用(Tool Use)
- AIエージェントが、検索、計算、API実行、ファイル操作などの外部機能を呼び出してタスクを遂行する能力。
- Evals
- AIシステムの回答品質、検索品質、根拠整合性、タスク成功率などを測定する評価設計。
- Observability
- AIシステムの挙動をログ、メトリクス、トレースで可視化し、失敗原因や改善点を把握できるようにする運用設計。
- HITL(Human-in-the-Loop)
- 重要な判断やリスクの高い操作において、人間の確認・承認をワークフローに組み込む設計。
- ReActフレームワーク
- Reasoning(推論)とActing(行動)を繰り返すことで、AIエージェントがタスクを解決するための考え方。
参考文献 / 出典
一次情報・公式ドキュメント
- LangGraph Overview – LangChain Documentation
- Human-in-the-loop – Docs by LangChain
- LlamaIndex Workflows – Developer Documentation
- LlamaIndex Workflows 1.0 – Lightweight framework for agentic systems
- Microsoft Agent Framework の概要
- Microsoft Agent Framework Version 1.0
- Microsoft Foundry Agent Service の概要
- CrewAI Quickstart
- CrewAI Flows
- Ragas Documentation
合わせて読みたい
- RAG完全ガイド|検索拡張生成の仕組み・設計・評価・導入ロードマップ(RAG全体の正典ハブ)
- RAGの精度を向上させる7つの技術|高度なチューニング戦略ガイド(検索精度・評価・改善の実務)
- LangGraphとは?LangChain・CrewAI・MAFとの使い分けと本番設計(状態管理・再検索・HITLの中核)
- Microsoft Agent Frameworkとは?AutoGenとSemantic Kernelを統合する次世代AIエージェント基盤(Microsoft環境の本番エージェント基盤)
- CrewAIとは?AIチームで業務PoCを高速化する実践ガイド(役割分担型マルチエージェント)
- LLMOps / LLM Observabilityとは?生成AIを本番運用する監視・評価・改善基盤(本番運用と可観測性)
- AIエージェントセキュリティ|MCP・A2A時代のリスクと対策(接続されたAIのセキュリティ)
- AIエージェントのゼロトラスト設計(権限・監査・承認の実務設計)
よくある質問(FAQ)
Q1.
Agentic RAGは最初から導入すべきですか?
A1.
いいえ。多くの場合、まずClassic RAGやHybrid RAGで検索品質を固める方が先です。
Agentic RAGは、検索失敗、意図誤解、根拠不一致が残る場合に段階的に導入します。評価データとログがないままAgentic化すると、コストや複雑性だけが増えるリスクがあります。
Q2.
Agentic RAGの導入コストは、通常のRAGと比べて高くなりますか?
A2.
はい。検索、評価、再検索、ツール実行を複数回行うため、通常のRAGより推論コストやレイテンシが増えやすくなります。
導入時は、コスト増だけでなく、回答品質、再検索成功率、ユーザー満足度、業務削減効果をセットで評価する必要があります。
Q3.
LangGraphとCrewAIはどう使い分けますか?
A3.
LangGraphは制御、CrewAIは役割分担に向きます。
LangGraphは状態管理、分岐、再検索、HITLなど、Agentic RAGの制御に向いています。CrewAIは、調査担当、要約担当、レビュー担当のように、複数ロールで業務プロセスを分担したい場合に向いています。
Q4.
LlamaIndexとLangChainはどう違いますか?
A4.
LlamaIndexは検索・データ基盤、LangChainはツール連携やプロトタイピングに強みがあります。
LlamaIndexは、データ接続、Index、Retriever、文書処理など、RAGの検索・データ基盤に強みがあります。LangChainは、ツール連携、プロトタイピング、エージェント実装のエコシステムに強みがあります。実務では両方を組み合わせることもあります。
Q5.
超長文コンテキストLLMが登場しても、Agentic RAGは必要ですか?
A5.
はい、必要です。長文コンテキストLLMとRAGは補完関係です。
長文コンテキストLLMは大量文書の読解に強みがありますが、権限制御、情報鮮度、根拠提示、コスト制御、検索ログの観点ではRAGが重要です。Agentic RAGは、必要な情報を選別し、評価し、場合によって長文コンテキストLLMに渡す制御役になります。
Q6.
Agentic RAGツールを選ぶ際のポイントは何ですか?
A6.
まず課題を切り分けることです。
検索品質が弱いならLlamaIndexやHybrid Search、再検索制御が必要ならLangGraph、役割分担が必要ならCrewAI、Microsoft環境で統制したいならMicrosoft Agent Framework、品質評価が必要ならRagas / Evalsを検討します。
Q7.
Webアクセスなどを行うエージェントの、データセキュリティ上の注意点は何ですか?
A7.
エージェントに与える権限を最小限にすることです。
社内情報が意図せず外部に送信されたり、エージェントが悪意のあるサイトにアクセスしたりするリスクがあります。サンドボックス環境、アクセス先のホワイトリスト管理、人間承認、監査ログが必要です。
Q8.
まず手軽にAgentic RAGを試すには、何から始めるべきですか?
A8.
既存のRAGに、検索結果の評価と再検索ループを1つ追加するところから始めるのが安全です。
たとえば、検索結果が不十分な場合にクエリを書き換えて再検索するだけでも、Corrective RAGの基本的な挙動を検証できます。
Q9.
「RAGはもう古くて、これからはAgentic RAGだけになる」というのは本当ですか?
A9.
いいえ。その見方は誇張されています。
最近は「RAGは終わり、Agentic RAGの時代だ」といった刺激的なメッセージも見られますが、実務ではまずClassic / Hybrid RAGの検索品質を固め、その上で必要な範囲だけCorrective / Self / Agenticを足していく流れが現実的です。Agentic RAGはRAGの代わりではなく、RAGを測り、直し、必要なところだけ自律化するための追加レイヤーだと考えた方が、長期的なアーキテクチャ設計として安定します。
更新履歴
- RAG関連記事群の再設計に合わせ、Agentic RAGを「RAG構築におけるツール選定・実務判断ガイド」として全面改版。Self-RAG、Corrective RAG、Adaptive RAG、LangGraph、LlamaIndex、CrewAI、Microsoft Agent Framework、Microsoft Foundry Agent Service、Evals / Observability の役割整理を追加。
- 最新情報アップデート、FAQ、専門用語等読者支援強化
- 初版公開








