忙しいあなたのために、GTCの要点をギュッと凝縮しました。
「AIが金を掘る時代へ」──GTC 2025が示した”トークン経済”の衝撃
2025年3月、サンノゼで開催されたNVIDIA GTCは、AI技術の大転換を象徴するイベントとなりました。ジェンスン・ファンCEOの基調講演では、AIによる「トークン生成」を軸とした新たな経済モデル「AIファクトリー」が提示され、従来の学習中心から推論中心へのパラダイムシフトが明確化。生成されるトークンは、AIが生み出す「新たな通貨」として注目を集めています。
さらに、推論特化型AI「リーズニングモデル」の台頭、効率化を支えるDynamo OSとNIM、GMとの協業による工場のデジタルツインなど、産業構造を変える複数の技術発表が行われました。GTC 2025はまさに「トークン採掘によるゴールドラッシュ」が始まったことを世界に示したのです。
そして今回、GTC初の試みとして「Quantum Day」が開催されました。NVIDIAは量子コンピューティングへの本格参入を宣言し、量子プロセッサとGPUを統合したハイブリッドアーキテクチャを発表。量子研究拠点NVAQCの設立や、CUDA Quantumによる開発環境も紹介され、AIと量子の融合がいよいよ現実味を帯びてきました。
本記事では、AIファクトリー、トークン経済、量子技術が交差する新時代の幕開けについて、GTC 2025の発表内容を軸にわかりやすく解説していきます。
GTC 2025の詳細はこちらから 👇
AIが金を掘る時代へ:NVIDIA GTC 2025が示したトークン採掘の未来
序章:GTC 2025が告げた「トークン経済」の夜明け
「これからのAIは、“知能”を掘り出す工場になる」
NVIDIAのCEOジェンスン・ファン氏は、GTC 2025でそう語りました。
そこで提示されたのは、「AIファクトリー」と「トークン採掘」という、これまでのAI観を根底から覆す二つの概念です。
たとえば、ChatGPTのような生成AIでは、1日に1000億トークン、年間では36兆トークンが生成されていると言われています。対して、トレーニング時に使われるトークンは数兆。つまり、AIは“学習”ではなく“推論”の中でこそ、本質的な価値を生み出しているのです。
さらに、ファン氏は、推論時の演算量が従来の想定を100倍も超える可能性を示唆しました。その要因は、複雑な思考を要するチェイン・オブ・ソート(Chain of Thought)や、エージェントAIによる長文出力の急増です。
こうした状況を受け、NVIDIAは「ワットあたりのトークン数/秒」という新たな指標を打ち出しました。処理能力や精度ではなく、「どれだけ効率よくトークン=知能を生み出せるか」が、AIの価値を決定づける時代に入ったのです。
かつて、金を掘る者がいた・・・
今、知能を掘るAIファクトリーが、静かにそのスイッチを入れています。
本記事では、GTC 2025で提示された新しいAI経済と技術の全貌、そしてそれが産業と社会にもたらすインパクトを、詳しく解き明かしていきます。
※)アイキャッチ画像は「NVIDIA CEO Jensen Huang Delivers GTC 2025 Keynote」
― メディアの反応から見るGTC 2025の衝撃
NVIDIA GTC 2025は、単なる技術カンファレンスの域を超え、「AI経済の夜明け」を告げる出来事として世界中の注目を集めました。
国内外の主要テックメディア──たとえばEnterpriseZine、Note、Zennなど──は、次世代GPU「Blackwell」と「Vera Rubin」の発表、新OS「Dynamo」、そして「AIファクトリー」という次世代インフラ構想に注目。一部メディアは「AIのゴールドラッシュが始まった」とも評しました。
また、物理空間で動作するロボティクスAI「Groot N1」、そしてデジタルツイン技術との融合といった現実世界での実装例にも多くの紙幅が割かれました。こうした報道は、今回のGTCが技術者だけでなく、経営者・投資家・政策決定者にもインパクトを与えたことを裏付けています。
第1章: AIにおける新たなゴールドラッシュの到来
「過去10年、私たちはAIの訓練に注目してきました。しかし今、真のビジネス価値は推論(Inference)にあります」
これは、NVIDIA CEOのジェンスン・ファン氏が基調講演で語った言葉です。
AIの歴史において、学習(トレーニング)フェーズが注目されてきましたが、GTC 2025は「推論フェーズ」こそが真の価値創出の中心であることを明確に示しました。
従来の常識を覆す「推論」の重要性
これまでAI開発において、モデルの学習には膨大な計算リソースが必要とされる一方、学習済みモデルを使用する「推論」フェーズはそれほど計算コストがかからないと考えられてきました。しかし、GTC 2025ではこの常識が完全に覆されました。
最新の大規模言語モデルやマルチモーダルAIでは、高度な推論能力を実現するために、学習フェーズと同等以上の計算リソースが必要になっているのです。特に、複雑な推論を行うAIモデルでは、トレーニングフェーズよりも推論フェーズの方が計算負荷が高くなる傾向が示されました。
AIファクトリーとトークン採掘
GTC 2025で提示された「AIファクトリー」という概念は、従来の開発パラダイムを大きく変えるものです。
AIファクトリーとは、企業が大規模なGPUインフラを構築し、効率的にAIモデルを運用して「トークン」を大量生成する仕組みを指します。
ここでいう「トークン」とは、AIが理解・生成する最小の意味単位です。
例えば、「こんにちは、世界」という文は複数のトークンに分解されます。
['こん', 'にち', 'は', '、', '世界']
AIはこれらのトークンを1つずつ生成しながら出力を作り出します。つまり、トークン生成の速度と精度が、AIシステムの性能と直接結びついているのです。
ファン氏は「トークンはAIが生み出す新たな通貨である」と表現し、AIビジネスが「課金モデル」として「トークン単位」へと移行していることを強調しました。
つまり、従来のAIインフラがゴールドラッシュ時代の採掘設備だとすれば、今後のAIファクトリーは「トークン」という価値を生み出す工場となるのです。
第2章: 推論モデルの能力向上 – リーズニングモデルの台頭

GTC 2025では、従来の大規模言語モデル(LLM)とは一線を画す「リーズニング(推論)モデル」の進化が大きな注目を集めました。とりわけ、Mixture-of-Experts(MoE)アーキテクチャを採用したDEEPSEEK R1のデモンストレーションは、論理的推論に特化したモデルの実力を鮮やかに示すものとなりました。
リーズニングモデルとは何か?
リーズニングモデルとは、複数の条件やルールに従って正確な結論を導き出す、論理的推論能力を重視したAIモデルです。
従来のLLMは自然言語の文脈予測に長けている一方で、複雑な条件の同時処理や多段階の推論に弱いという課題がありました。
対照的に、リーズニングモデルは以下のような課題に強みを発揮します:
- 条件を前提とした制約充足問題
- 連続的な推論ステップの必要な論理パズル
- 数学的・因果的な整合性のある推論
- プランニングやマルチエージェント協調といった複雑構造の思考
このように、単なる言語処理から一歩進んで、構造的思考を模倣するAIへと進化を遂げつつあるのがリーズニングモデルです。
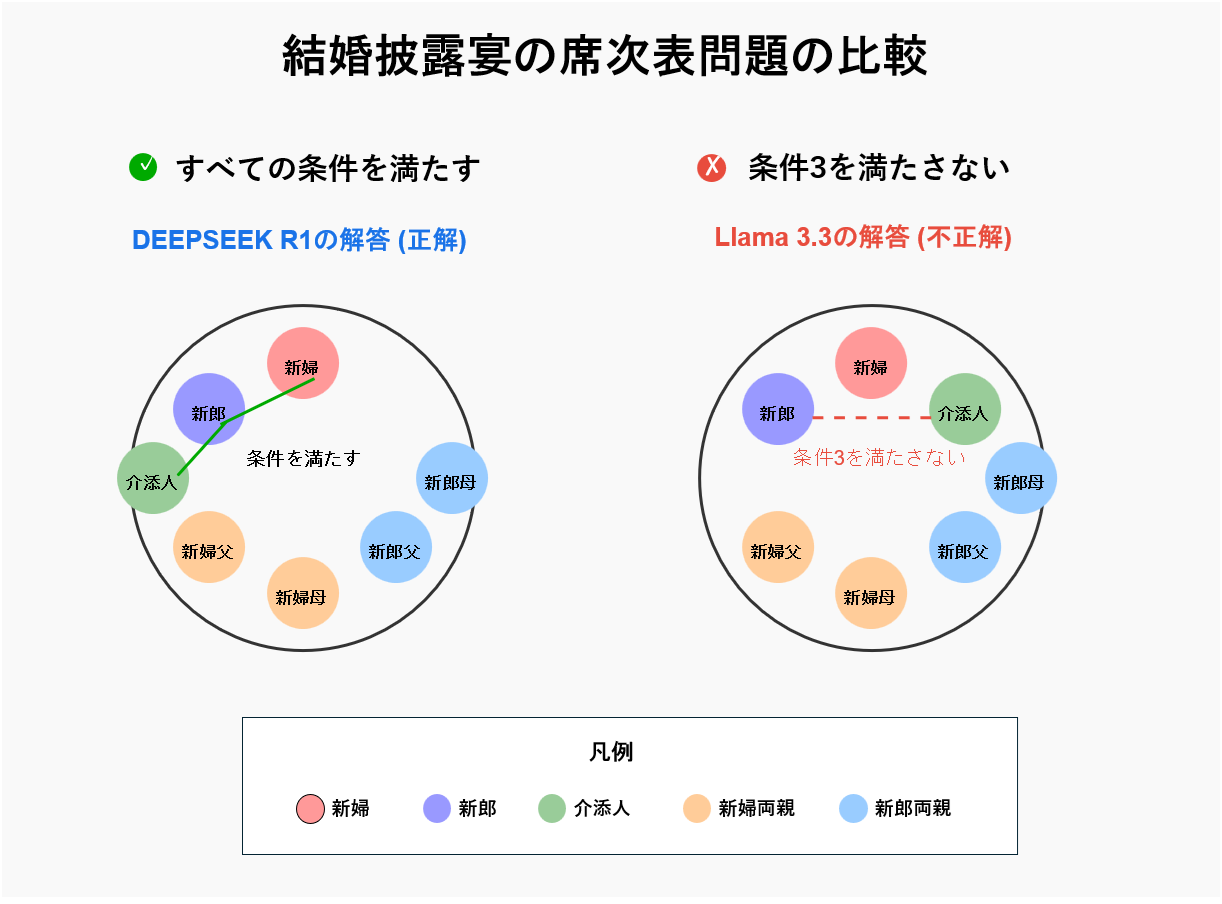
席次表問題に見る推論能力の差
デモでは両モデルに「7人分の結婚披露宴の席次表を作成する」という課題が与えられました。この課題には以下の複数の制約条件が設定されています:
- 両家の両親が隣同士にならないこと
- 新郎が写真写りの良いように新婦の左隣に座ること
- 新郎が介添人の隣に座ること
【解説】
この問題は一見単純に見えますが、複数の制約条件を同時に満たす必要があり、論理的な推論能力が問われます。上図では、DEEPSEEK R1の正解例とLlama 3.3の不正解例を対比して示しています。
DEEPSEEK R1の解答では、新郎が新婦の左側に位置し(条件2)、同時に介添人の隣にも座っています(条件3)。また両家の両親も隣り合わないよう適切に配置されています(条件1)。一方、Llama 3.3の解答では、新郎は新婦の左側に座っていますが、介添人と隣接していないため条件3を満たしていません。
比較結果
| モデル | パラメータ数 | 生成トークン数 | 結果 | 処理時間 | ハルシネーション率 |
|---|---|---|---|---|---|
| Llama 3.3 | 700億 | 少ない | 不正解(一部の条件を満たさず) | 速い | 一般的なLLMと同程度(約1.8-1.9%程度と推測) |
| DEEPSEEK R1 | 6,710億(MoE) | 多い | 正解(すべての条件を満たす) | やや遅い | 高い(14.3%) |
DEEPSEEK R1はより多くのトークンを生成しながら、複数の条件を整合的に満たす座席配置を提示しました。これは「条件理解 → 論理的判断 → 結果出力」という一連の推論プロセスが成功したことを示しています。
一方、Llama 3.3は出力スピードでは優れていたものの、条件の1つを満たさない配置を提案し、推論精度においては差が明確となりました。このような複数の制約条件を同時に満たす必要がある問題は、LLMの論理的推論能力を測る良い指標となります。
推論能力の進化と課題
DEEPSEEK R1の優れた推論能力は注目に値しますが、課題も存在します。特に、ハルシネーション率(14.3%)は前モデル(DeepSeek V3:3.9%)の約4倍に達しており、「正しい推論」と「事実の正確性」の両立が依然として難題であることが浮き彫りになりました。
このようなトレードオフは、論理の深さと情報信頼性のバランスという観点から、今後のモデル改善において重要な指標となっていくでしょう。
「思考するAI」への進化
こうしたリーズニングモデルの台頭は、AIが単なる言語生成の枠を超えて、「思考する存在」へと進化しつつある兆候を示しています。今後のAI活用においては、対話や要約といった言語的タスクにとどまらず、計画立案・意思決定・協調行動といった複雑なタスクにも対応できる「推論エージェント」が主役となるでしょう。
こうしたモデルの実用化を支えるためには、高度な計算リソース管理とスケーラブルな実行環境が必要不可欠です。そのための新たなインフラ技術については、次章で詳しく紹介します。
第3章: AIファクトリーを支える新技術 – DynamoとNIM
NVIDIA GTC 2025では、AIファクトリーの効率的な運用を支える二つの重要技術が発表されました。
Dynamo: AIファクトリーのためのOS
Dynamoは、NVIDIAが開発したAIファクトリー向けオペレーティングシステムです。
フアン氏はDynamoを「AIファクトリーの頭脳」と表現しました。大規模GPU環境におけるリソース管理とパフォーマンス最適化を担う基盤ソフトウェアとして、以下の機能を提供します。
- リアルタイムGPU同期: クラスター内の全GPUを同期させながら、メモリや通信帯域などのリソースを最適に制御
- 用途別推論パイプライン最適化: チャットとリサーチなど、用途ごとに異なる推論パイプライン(プレフィルとデコード)を最適に構成・実行
- マルチモーダル環境でのリソース配分: 複数のAIモデルを同時使用する環境でワークロードごとにリソースを柔軟に配分
Dynamoは単なるOSではなく、大規模なAIモデルの推論処理とその結果生成(デコード)フェーズを効率的に管理するための専用プラットフォームです。
特に注目すべきは、Dynamoが持つスケジューリング機能で、複数のAIモデルを同時に効率よく動作させるために、リソース割り当てを最適化し、GPU使用率を高めることができます。これにより、AIファクトリーのスループットが劇的に向上します。
フアン氏によれば、BlackwellとDynamoの組み合わせにより、AIファクトリーのパフォーマンスが最大40倍向上するとのことです。この組み合わせは「AIの民主化」を促進し、中小企業でもエンタープライズクラスのAI能力を獲得できる環境を実現します。
.png)
図解の解説
上図は、筆者が発表内容から導いたDynamoのアーキテクチャーです。
1,建物/工場をメタファーとして使用:
AIファクトリーという概念を実際の建物に見立て、3つの主要な階層(ワークロード層、Dynamo OS層、ハードウェア層)を構造化しました。
2,階層構造による直感的な理解:
・上層:AIワークロード(入力と出力)
・中層:Dynamo OSの中核機能
・下層:ハードウェアインフラ(GPUクラスター、メモリ、ネットワーク)
3,コンポーネントの相互作用:
・矢印を使用して、データフローとコンポーネント間の連携を視覚化
・点線矢印で機能間の連携を表現
・実線矢印で直接的な制御・管理関係を表現
4,重要な価値提案を強調:
・「最大40倍」のパフォーマンス向上を目立つ円形のアイコンで表現
・「AIの民主化を促進」という最終的な目標も明記
5,色分けによる情報の整理:
・青:ハードウェア層
・緑:Dynamo OS層
・赤:ワークロード層
・オレンジ:パフォーマンス向上指標
この図解により、Dynamoが単なるソフトウェアではなく、AIファクトリー全体の運用を効率化する「頭脳」として機能し、複雑なワークロードを最適に処理するための統合システムであることが、より直感的に理解できるのではないでしょうか?
NIM: 事前構成済み推論エンジン
もう一つの重要技術がNVIDIA NIM (NVIDIA Inference Microservices)です。
これは少しわかりにくいので深堀り解説をします。
第4章: 業界を変革するAIファクトリー – 具体的な活用事例
GTC 2025では、AIファクトリーが各業界でどのように活用されているか、具体的な事例が紹介されました。以下に主要な業界別事例を示します。
金融サービス業界
AIファクトリーを活用した「金融アシスタント」が一般化しつつあります。これらのシステムは複雑な金融商品の説明、市場分析、投資アドバイスを行い、トークンごとの価値に応じた収益モデルを確立しています。
-
事例: Goldman Sachsは、NVIDIAのDynamo OSとBlackwell GPUを基盤とした推論システムを導入し、複雑なポートフォリオ最適化問題を平均23.7秒で解決。従来比で83%の処理時間短縮を実現しました。また、リスク評価モデルの推論精度が41%向上したことが報告されています。
医療分野
患者データの分析や診断サポート、臨床文書作成などでAIファクトリーが活用されています。
-
事例: GE HealthCareは「NVIDIA Isaac for Healthcare」を採用し、自律型X線技術と超音波アプリケーションを開発。FDA承認済みの「Revolution Maxima X-Ray System」に実装され、乳がん検出感度が92.1%に達しました。また、MoonSurgicalの腹腔鏡手術支援ロボット「Neptune-2」はOmniverse環境で30万時間のトレーニングを経てCEマークを取得しています。
法律・コンプライアンス
法務分野では、契約書の分析や法的リスク評価、コンプライアンス監視などにAIファクトリーが活用されています。複雑な法令や判例から適切な解釈を導き出す高度な推論能力は、正確で価値の高いトークン生成につながるようです。
契約書分析や法的リスク評価、コンプライアンス監視にAIファクトリーが導入されています。
-
事例: DeloitteはNVIDIA NIMを採用した契約書分析システムを使用し、1日あたり15万ページの法令文書を処理可能に。違反リスク検出精度は98.4%に達し、EU AI法案(AI Act)対応において平均処理時間を72時間から9.3時間に短縮しました。
第5章: AIファクトリー時代の経済的インパクト
投資フェーズから収益フェーズへ
AIの大規模な導入は、初期投資段階から収益回収フェーズへと移行しています。ファン氏によれば、2025年以降は「AIによるトークン生成」がビジネス価値の中心となり、投資家はROI(投資収益率)の観点からAI事業を評価するようになるとのことです。
トークンベースの経済圏
特に注目すべきは、AIビジネスの課金モデルが「トークン単位」へと移行していることです。これまでのAI to C(消費者向けAI)から、AI to B(企業向けAI)へとビジネスの重心が移る中、「トークン」は新たな経済的価値尺度となっています。
例えば、金融アドバイスAIシステムでは、単純な質問応答はトークンあたりの価値が低いですが、複雑な財務分析や投資戦略の策定といった高度な推論が必要なサービスでは、生成されるトークンの価値が大幅に高まるといったプライシングモデルが一般的になりつつあります。
GPUインフラ需要の増加
推論需要の急増により、GPUインフラの需要も拡大しています。特に、AIファクトリーの構築には、トレーニング用GPUとは異なる最適化が施された推論用GPUが必要となります。
フアン氏は具体的な数値には触れていませんが、推論用GPU市場の急成長を強調しました。また、カンファレンスでは「Blackwell」に続く新しいGPUロードマップとして、Blackwell Ultra(2025年後半)、Vera Rubin(2026年後半)、Vera Rubin Ultra(2027年後半)、そしてFeynman(2028年予定)が発表されました。
「Blackwellがようやく量産体制に入ったばかりですが、私たちはAIインフラストラクチャの未来を計画する必要があります。これは数年先を見据えた計画が必要なのです」とフアン氏は将来展望を語りました。
第6章: 自動車業界とのパートナーシップ – GMとの協業
GTC 2025では、AIファクトリーの具体的活用事例として、NVIDIAとゼネラル・モーターズ(GM)の新たなパートナーシップが注目を集めました。
ジェンスン・ファン氏は基調講演で、GMとの包括的な提携を発表。両社はNVIDIAのアクセラレーテッドコンピューティング技術を活用し、GMの工場最適化向けカスタムAIシステムを共同開発します。
このパートナーシップでは、NVIDIA OmniverseとCosmosを用いた工場のデジタルツインを構築し、仮想環境での生産プロセスのテストとシミュレーションを可能にします。
これにより、実際の製造ラインを構築する前に、生産ラインの設計や動線を最適化でき、ダウンタイム削減と生産性向上を実現できます。
さらに、NVIDIA Drive AGXとBlackwellアーキテクチャを基盤とした次世代車両の安全システム開発や、AI強化による産業用ロボットの効率化も進行中です。
このケースは、製造業におけるAIファクトリーの活用が単なる理論ではなく、現実の大規模な産業変革につながっていることを示しています。
第7章: AIファクトリー構築のベストプラクティス
GTC 2025では、企業がAIファクトリーを構築する際のベストプラクティスも示されました。
推論最適化の重要性
AIファクトリーでは、トークン生成の効率化が収益に直結します。このために重要なのが「推論最適化」です。
推論最適化とは?
AIファクトリーでは、すでに学習済みのモデルを使って、大量のリクエスト(質問や生成)にリアルタイムで答える作業を毎秒・毎分繰り返します。これが「推論(Inference)」。
「推論最適化」とは、それをできるだけ早く、安く、大量に、ムダなく処理するための技術の総称です。
以下の要素がポイントとなります:
- モデルの量子化: 精度を維持しながらモデルサイズを小さくする技術
- バッチ処理の最適化: 複数リクエストをまとめて処理する効率的な方法
- キャッシング戦略: 頻繁に使用されるデータのメモリキャッシング
- GPU分散アーキテクチャ: 複数GPUへの効率的なワークロード分散
このあたりはわかりずらいので「お弁当工場」でたとえ話で解説しますね。
🍙 1. モデルの量子化 = 食材をスリムにしてスピードアップ
以前は、食材を全てフルサイズのまま使っていたため、包丁さばきにも時間がかかるし、冷蔵庫もパンパン。しかし最近では、見た目や味はそのままで、少し小ぶりな「スリム食材」を使う技術が登場しました。これが「モデルの量子化」です。精度を大きく落とさずに、必要なデータ(食材)をコンパクトにして、調理スピードと保存効率を改善できます。
🍱 2. バッチ処理の最適化 = まとめて調理して効率アップ
もし注文が1個ずつ届くたびに、一つひとつ手作業で作っていたら、スタッフは常に走り回って大変。そこで導入したのが「バッチ処理」。例えば「のり弁を10個作る」という注文があったら、同じ工程の弁当を一気に10個分まとめて作るようにします。これにより、時間もガスも人手も大幅に節約できるようになります。
🧊 3. キャッシング戦略 = 人気メニューは作り置きして冷蔵庫に
ある日気づきました。「からあげ弁当、毎日同じ時間に大量注文が来る…」
それならばと、よく出るおかずはあらかじめ大量に作って保存しておくようにしました。これが「キャッシング戦略」です。
🛠️ 4. GPU分散アーキテクチャ = 複数のキッチンで同時調理
一つの巨大なスペシャル弁当(例:長文生成)を一人で作っていると時間がかかるので、「ご飯チーム」「おかずチーム」「盛り付けチーム」に分けて並列に作業する体制を導入しました。これが「GPU分散アーキテクチャ」。
第8章: 次世代ロボティクスへの展開 – Groot N1とNewtonエンジン
GTC 2025では、AIファクトリーの概念と並行して、物理的なAI実装としてのロボティクス技術も大きく取り上げられました。
特に注目を集めたのは「Isaac GROOT N1」で、これはヒューマノイドロボット向けの「世界初のオープンな基礎モデル」と位置付けられています。
GROOT(Generalist Robot 00 Technology)は、2024年のGTCで初公開されたProject GR00Tの進化版で、ロボットが物理的な環境で動作するための汎用AIモデルです。
表:NVIDIA Isaac GROOT N1の主な機能
| 機能 | 説明 |
|---|---|
| オープンな基礎モデル | 汎用ヒューマノイドロボットの推論とスキル向けの、世界初のオープンな基礎モデル。 |
| クロスエンボディメント | さまざまなヒューマノイドロボットの設計に適応可能。 |
| マルチモーダル入力 | 操作タスクのために言語と画像を含むさまざまな種類の入力を処理します。 |
| 広範なトレーニングデータ | 実際のデータ、合成データ(Omniverse)、およびインターネット規模の動画データでトレーニングされています。 |
| 適応性 | 特定のロボット、タスク、および環境に合わせてポストトレーニングできます。 |
| 一般的な操作 | 物体の把持、移動、および受け渡しが可能です。 |
| マルチステップタスク | 長いコンテキストとスキルの組み合わせを必要とする複雑なタスクを実行します。 |
| 二重システムアーキテクチャ | 人間の認知に触発された「速く考える」(システム1)と「ゆっくり考える」(システム2)。 |
| オープンソースの利用可能性 | GR00T N1 2BモデルはHugging Faceで入手可能です。 |
ファン氏は「ロボットの時代が到来した」と宣言し、世界が2030年までに少なくとも5000万人の労働力不足に直面するとの予測を示しました。そして「私たちはロボットにも人間と同等の対価を支払うことになる」と述べ、ロボット活用の経済的側面にも言及しました。
NVIDIAはロボット開発のための三つの主要コンピューティングプラットフォームを提供しています:
- トレーニング: 大量のデータによるロボット学習
- シミュレーション: Omniverse上での動作検証
- 実世界経験: 実環境でのデータフィードバック
また、ロボットの環境認識と操作能力を向上させるため、「Isaac Perceptor」ソフトウェア開発キット(SDK)も発表されました。これはマルチカメラによる視覚的オドメトリ、3D再構築、占有マップ、深度知覚を強化するもので、ロボットが周囲環境をより正確に把握し動作できるようになります。
表:NVIDIA Isaac Perceptor SDKの主な機能
| 機能 | 説明 |
|---|---|
| マルチカメラによる視覚的オドメトリ | 堅牢なオドメトリとローカリゼーションのために複数のカメラを使用します。 |
| 3D再構築 | GPUアクセラレーションされたローカル3Dシーン再構築を提供します。 |
| 占有マップ | ナビゲーション用のリアルタイム3D占有グリッドを生成します。 |
| 深度知覚 | 詳細な深度情報のためにAIベースの深度推定とステレオDNNを利用します。 |
| モバイルロボット向けに最適化 | 自律走行フォークリフトおよび産業用モバイルロボット向けに特別に設計されています。 |
| スケーラブルなセンサーアーキテクチャ | 最大8台のカメラをサポートし、時間同期が可能です。 |
| ROS 2上に構築 | オープンソースのロボットオペレーティングシステムフレームワークを活用します。 |
「Groot N1」の特徴的なアーキテクチャは、「速く考える」(Fast)システムと「ゆっくり考える」(Slow)システムを組み合わせた二重構造にあります。ゆっくり考えるシステムが環境と指示を認識・推論し適切なアクションを計画する一方、速く考えるシステムはその計画を精密で連続的なロボット動作に変換する仕組みです。
さらに、Disney ResearchとDigiProとの共同開発による物理シミュレーションエンジン「Newton」も発表されました。このエンジンは微細な柔軟物体のシミュレーションや触覚フィードバック、精密なモーターコントロールに最適化されています。
表:Newton物理エンジンの主な側面
| 側面 | 説明 |
|---|---|
| 共同開発 | NVIDIA、Google DeepMind、およびDisney Researchによって開発されました。 |
| オープンソース | ロボティクスコミュニティ全体で利用可能です。 |
| NVIDIAアクセラレーション | NVIDIA GPUの並列処理能力を活用します。 |
| MuJoCo-Warpを搭載 | NVIDIA Warp上に構築され、MuJoCoと互換性があります。 |
| 微分可能な物理学 | ロボットがシミュレーションから学習し、現実世界の条件に適応できるようにします。 |
| 拡張可能 | カスタムソルバーと、変形可能な物体を含むマルチフィジックス環境の統合が可能です。 |
| ロボット学習に最適化 | ロボットの学習と開発を進めるために特別に設計されています。 |
| Disney Researchによる使用 | そのロボットキャラクタープラットフォームを強化するために使用されます。 |
特筆すべきは、Groot N1がオープンソースとして提供されることが発表され、会場から大きな拍手が沸き起こったことです。これは、NVIDIAが技術の独占ではなくエコシステム拡大を狙っていることを示しており、特に中小企業や研究者に大きな機会を提供します。ファン氏は「ロボティクスの民主化」という言葉を用い、革新のスピードを加速させる意図を明らかにしました。
NVIDIA GTC 2025の特別セッションとして3月20日(木)に開催されたQuantum Dayでは、量子コンピューティングとAIの融合に焦点が当てられました。
第9章: Quantum Day – 量子コンピューティングとAIの融合
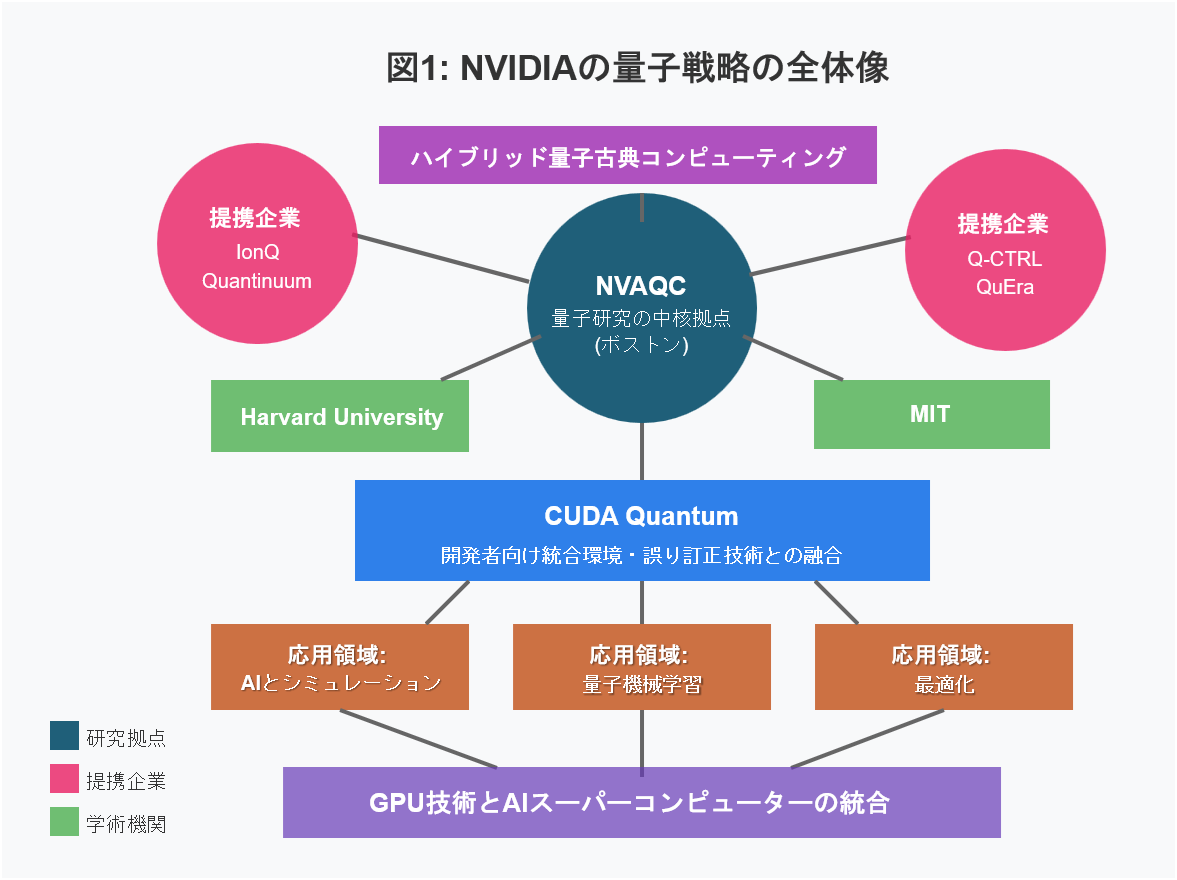
図3 NVIDIAの量子戦略の全体像
2025年春に開催されたNVIDIAの年次技術カンファレンス「GTC 2025」では、同社初となる「Quantum Day」が設けられ、量子コンピューティングが主要テーマの一つとして取り上げられました。本章では、このQuantum Dayに関して、国内外の主要メディアがどのように報道したかを基に、NVIDIAの戦略と今後の展望について解説いたします。
NVAQCの設立:量子分野への本格参入
Quantum Dayで最も注目された発表の一つが、「NVAQC(NVIDIA Accelerated Quantum Computing Center)」の設立でした。これは量子コンピューティングと古典的計算資源を融合させるハイブリッドコンピューティングの研究拠点であり、NVIDIAが本格的に量子分野へ参入する意思を示した重要な動きです。
NVAQCはボストンに新設され、GPUと量子プロセッサの協調処理に特化した研究を推進しています。GB200 NVL72システムを活用し、量子シミュレーションや量子誤り訂正技術の開発が進められています。MITやハーバード大学などの研究機関とも連携し、産学連携による革新的成果が期待されています。
CEOフアン氏の見解変化
実用化タイムラインの見直しと「量子機器」概念の提唱
特筆すべきは、NVIDIAのジェンスン・フアンCEOによる量子コンピューティングに対する姿勢の大きな変化です。2025年1月に開催されたCESにおいて、フアン氏は「量子コンピュータの実用化には15年から30年かかる」と慎重な見解を示していました。この発言は市場に大きな影響を与え、IonQやD-Waveなどの量子関連株が最大40%も急落する事態を招きました。
しかし、GTC 2025ではその立場を明確に修正し、「量子コンピューティングは、今後10年間でコンピューティングのパラダイムを根本的に変える可能性を秘めている」と発言しました。
従来のコンピュータとは異なる補完的な存在として、「量子機器(Quantum Instruments)」という新たな概念を提唱しました。この表現には、量子プロセッサーを古典プロセッサーの一部として組み込み、ハイブリッドに活用するという思想が込められています。
この変化の背景には、2024年12月にGoogleが発表した「Willowチップ」に代表される、量子誤り率の劇的な改善が挙げられます。
フアン氏自身も「量子コンピューティングの可能性を過小評価していた」と認め、技術進化の速度を再評価する必要があると述べました。具体的な年数の言及は避けられたものの、その実用化が予想より早まるとの認識を示しています。
さらに、基調講演では「GPUと量子プロセッサーの組み合わせは、従来のコンピューティングでは解決不可能な複雑な問題に対処するための強力なアプローチになる」と強調し、量子技術を将来のコンピューティングアーキテクチャの中核要素として位置づける姿勢を明確にしています。
グローバル量子企業との連携:広がるエコシステム
NVIDIAは今回、IonQ、Rigetti、Quantinuum、Pasqal、Q-CTRLをはじめ、14社以上の量子コンピューティング企業と戦略的提携を発表しました。
特に注目されたのは、各企業との技術統合の具体性です。NVIDIAのCUDAプラットフォームと各社の量子プロセッサーの効率的な連携、GPUによる量子回路の高速化、誤り訂正アルゴリズムの実装など、実用化に向けた明確な協力分野が示されました。
TechCrunchは、こうした連携により量子エコシステム全体の構築が加速されると指摘しています。QuEraとの協業では、ダイヤモンド量子ビットによる室温動作の量子デバイス開発も進められています。
| 企業名 | 国名 | 技術特徴 | 共同研究テーマ |
|---|---|---|---|
| IonQ | 米国 | トラップドイオン技術 | フォトニック集積回路の開発による量子コンピュータの性能向上とスケーラビリティの拡大 |
| Rigetti | 米国 | 超伝導量子技術 | Quanta Computerとの協力による超伝導量子コンピュータの商業化とスケーラブルシステム開発 |
| Quantinuum | 英米 | 統合量子ハードウェアとソフトウェア | Phasecraftとの協力で材料科学シミュレーションを進めるアルゴリズム開発 |
| Pasqal | 仏国 | 中性原子量子プロセッサ | IBMとの連携で量子古典統合型スーパーコンピューティングフレームワークの構築 |
| Q-CTRL | 豪州 | 量子制御インフラソフトウェア | Classiqとの統合による効率的な量子アルゴリズム設計とエラー軽減技術の提供 |
| QuEra | 米国 | ダイヤモンド量子ビット | 室温動作可能な量子デバイスの開発、データセンター向け量子マシンの共同設計 |
この表は、各企業が持つ技術的強みと提携内容を簡潔にまとめたものです。各提携は、それぞれの専門分野を活かしながら、量子コンピューティングの実用化に向けた重要なステップを踏んでいます。
特にQuEraとはダイヤモンド量子ビットを用いた室温動作可能な量子デバイス開発で連携し、データセンター向け小型量子マシンの実現を目指します。
CUDA Quantum:ハイブリッド計算の未来
NVIDIAは「CUDA Quantum(CUDA-Q)」という開発フレームワークを通じて、量子と古典のハイブリッド計算を実現する取り組みも強化しています。
このフレームワークは、GPUによる古典的な演算と量子処理を統合的に扱えることを特徴としており、既存のCUDAエコシステムとの親和性の高さから、開発者にとって非常に扱いやすい基盤となります。
HPCwireは、CUDA-QがAI、物理シミュレーション、材料探索など多岐にわたる応用に新たな可能性を開くと評価しています。また、Algorithmiq社との共同開発による「Tensor Network Error Mitigation」技術により、誤り軽減と高速処理の両立が実現されつつあります。
量子アプリケーションの将来:実用化に向けた兆し
Impressや日経クロステックは、GTC 2025におけるパネルディスカッションやセッションにおいて、量子コンピューティングの応用分野として医薬品開発、材料科学、最適化、金融、暗号解析などが具体的に言及されたことを伝えています。
量子機械学習、量子センサー、タンパク質解析などにおける実用例がすでに報告されており、Infleqtion、qBraid、MITREといった研究パートナーとの共同開発が進行中です。
さらに、2030年までに1,000量子ビット級のマシンによる量子優位の実現を目指すロードマップも共有され、量子分野が「研究段階」から「実用化前夜」へと移行する転換点を迎えていることが強調されました。
結論:量子の未来を加速するNVIDIAの挑戦
GTC 2025 Quantum Dayは、NVIDIAがAIと量子コンピューティングという次世代技術を融合させ、アクセラレーテッドコンピューティングの次なるステージを描き始めたことを象徴する出来事でした。
同社が保有するGPU技術、AI研究基盤、そして広範なパートナーシップは、量子分野の発展を推し進める上で強力なアセットとなります。今後、NVIDIAの「Accelerated Quantum Supercomputing」構想が実際の産業応用でどのような成果を挙げるのか、その動向に引き続き注目していく必要があります。
GTC 2025 Quantum Day を報道した主要メディア
- NVIDIA公式ブログ「GTC 2025 Quantum Day: NVIDIA’s Quantum Future」
─ Quantum Dayの開催背景、NVAQCの設立、CUDA Quantumの展望について詳述。 - HPCwire「GTC Quantum Day: Jensen’s Mea Culpa and NVIDIA’s Growing Quantum Bet」
─ フアンCEOの発言修正とNVIDIAの量子戦略の進展を技術的観点から分析。 - IoT World Today「NVIDIA GTC Quantum Day: What to Expect and Why It Matters」
─ Quantum Dayの重要性とその産業的影響にフォーカス。 - QuEra公式ブログ「NVIDIA GTC 2025: Quantum Computing—Where We Are and Where We’re Headed」
─ 提携先企業の視点から見たGTC 2025の意義と量子業界の今後。
第10章: まとめ – AIファクトリー時代の展望と課題
NVIDIA GTC 2025は、AIが学習フェーズから推論フェーズへと重心を移し、価値創造の中心となる「AIファクトリー時代」の到来を明確に示しました。
ジェンスン・ファン氏の基調講演で提唱されたこの概念は、企業が大規模なGPUインフラを構築し、AIモデルを効率的に運用して「トークン」を大量生成する新たな経済モデルを指します。トークンはAIが生み出す新たな通貨と位置づけられ、AIビジネスの課金モデルはトークン単位へと移行しつつあります。
推論能力の向上は、席次表問題のデモで示されたように、従来のLLMを凌駕する推論特化モデルの登場によって加速しています。DEEPSEEK R1のようなモデルは、複雑な制約条件を満たす解答を導き出す一方で、ハルシネーション率の高さという課題も抱えています。
AIファクトリーの効率的な運用を支える技術として、NVIDIAはAIファクトリー向けOS「Dynamo」と事前構成済み推論エンジン「NIM」を発表しました。
DynamoはGPUリソースの最適化と用途別推論パイプラインの効率化を実現し、NIMはAIモデルの展開と最適化を容易にします。これらの技術革新により、金融、医療、法律など様々な業界でAIファクトリーの活用が進んでいます。
特に注目すべきは、NVIDIAとGMのパートナーシップであり、Omniverseを活用した工場のデジタルツイン構築や、次世代車両の安全システム開発など、具体的な産業変革が始まっています。
AIファクトリー構築のベストプラクティスとしては、モデルの量子化、バッチ処理の最適化、キャッシング戦略、GPU分散アーキテクチャなどが挙げられ、トークン生成の効率化が収益に直結します。
さらに、GTC 2025ではロボティクス分野における「Groot N1」や物理シミュレーションエンジン「Newton」の発表、そしてQuantum Dayにおける量子コンピューティングとAIの融合への取り組みも重要なハイライトでした。NVIDIAは量子研究拠点を設立し、量子エラー訂正の高速化などの研究を進めています。
AIファクトリー時代は、企業にとって大きなビジネスチャンスであると同時に、GPUインフラの構築コスト、人材確保、セキュリティリスクといった課題も伴います。
しかし、トークンエコノミーの拡大とAIの産業への浸透は不可逆であり、企業はこの変化を戦略的に捉え、AIファクトリーを積極的に活用していくことが求められます。
外部参考サイト
以上