


※コードは学習ループのロジック理解が目的の疑似コードです(実行前提ではありません)。
NVIDIA Alpamayoで学ぶ論理推論型AV:「監視と検証」で成立させる設計手法
夜の雨。対向車のライトが滲み、路面は鏡みたいに光る――。
そんな“いつもの道”でさえ、自動運転には想定外が紛れ込みます。
人間なら無意識にやっている「気づく」「疑う」「止まる」を、機械にどう持たせるのか。
ここで勝負になるのは、モデルの賢さ“だけ”ではありません。
異常・遅延・想定外が必ず起きる現場で、監視して、検証して、安全に倒す――つまり運用中心(監視と検証=運用OS)の設計です。
「The ChatGPT moment for physical AI is here」――NVIDIA CEO Jensen Huang氏がCES 2026で投げ込んだこの言葉は、自動運転やロボットの“知能”が、特定シナリオの暗記から、物理法則の理解に基づく汎用的な推論へ移る転換点を指していました。
そこで発表されたのが、推論型自動運転の開発基盤「Alpamayo」です。
Alpamayoは、論理推論(Reasoning)を備えたVLA(Vision-Language-Action)モデル「Alpamayo 1」(約100億パラメータ)、オープンソースの自動運転シミュレーション基盤「AlpaSim」、計1,727時間の走行データセット(25カ国・2,500以上の都市で収録、7カメラ・LiDAR・最大10レーダーの360°同期収録)を揃えた、自動運転向けAI開発プラットフォームです。
本稿では、この思想を「難しい概念」で終わらせず、止まらない学習ループとして回る形に落とします。
具体的には、モデルの中身を語る前に、監視と検証を軸にした「運用の設計図(運用OS)」を先に固めます。その考え方を、現場で再現できる最小の形として、疑似コードで整理します。
NVIDIAがCES 2026で発表した「Alpamayo」は、E2E自動運転の開発を加速するために、次の“3点セット”をまとめた開発基盤です。
- 論理推論(Reasoning)を備えたオープンVLAモデル「Alpamayo 1」(約100億パラメータ)
- オープンソースの自動運転シミュレーション基盤「AlpaSim」
- ヒヤリハットを再現し、学習→評価→改善ループに戻すための基礎データとして、計1,727時間の走行データセット(25カ国・2,500以上の都市で収録、Hugging Faceで公開)を用意しています。
この3つを組み合わせることで、「仮想空間での大量シミュレーション → モデル学習 → 実車での検証」を、一つのループとして高速に回せるように設計されています。
📖 読了 18分|🎯対象:開発統括/エンジニア(中心)+CxO(運用判断)|🛠 難易度:★★★★☆
🔙 ピラー記事に戻る(全体戦略) Physical AI 2026:仮想と現実が溶け合う「双方向循環」が産業を支配する
この記事はスポーク(各論)です。全体像・市場・勝ち筋はピラーに集約しています。
この記事の結論: 推論型自動運転の勝負は「賢いモデル」ではなく、異常・遅延・想定外を前提にした「監視と検証(運用OS)」で成立させる設計です。
- 最重要は契約(Contract):残すログ、評価KPI、介入ルールを仕様として固定し、Sim・学習・本番で同じ言葉を使う。
- 学習は“出しっぱなし”にしない:評価ゲートで合格だけを成果物(artifact)化し、段階展開へ回す。
- 二重ガードレールが主役:推論系(判断)と監視系(検証)を分離し、危険時は安全動作へ強制する。
Key Takeaways:
- PoC止まりの主因:精度不足ではなく、ログ契約・評価ゲート・段階展開/ロールバックが欠けること。
- 差が出る場所:シナリオ数より、ヒヤリハットが学習へ戻る速度と、本番で止まらない運用。
- OSS活用の意味:OSSは土台にできる。差が出るのは「契約・検証・運用」を接続し、学習ループを回す設計。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

0. まず全体像:推論型自動運転をどう“接続”して成立させるか
 本稿の目的は、推論型自動運転(Reasoning AV)を「モデル中心」ではなく「運用中心」で設計することです。 推論モデルは賢くなりました。しかし現場では、異常・遅延・想定外が必ず起きます。そこで必要なのが、監視と検証(運用OS)です。
本稿の目的は、推論型自動運転(Reasoning AV)を「モデル中心」ではなく「運用中心」で設計することです。 推論モデルは賢くなりました。しかし現場では、異常・遅延・想定外が必ず起きます。そこで必要なのが、監視と検証(運用OS)です。
Alpamayoは、NVIDIAがCES 2026で発表した自動運転向けAI開発基盤であり、論理推論(Reasoning)を備えたVLA(Vision-Language-Action)モデル「Alpamayo 1」ファミリー、オープンソースの自動運転シミュレーション基盤「AlpaSim」、計1,727時間の走行データセット(25カ国・2,500以上の都市で収録、7カメラ・LiDAR・最大10レーダーの360°同期収録)から構成されています。
Alpamayo 1の開発には、CES 2025で発表された世界基盤モデル「NVIDIA Cosmos」が活用されており、人間による走行データとCosmosで生成した物理世界ベースの合成データの両方を学習に用いていると説明されています。
Cosmosは、物理世界の動画をもとに学習したWorld Foundation Models(世界基盤モデル)群であり、テキストやセンサー入力から“物理法則を守った世界”を生成できるため、Alpamayo向けの合成走行データ生成にも活用されています。
本稿では、その考え方をContract→Gate→Opsの一本線に落とし、止まらない学習ループとして説明します。
- Contract:残すログ(近接・介入・危険判定など)と、評価KPI(安全・遅延・成功率)を仕様として固定
- Sim(AlpaSim):オープンソースのシミュレーション基盤「AlpaSim」で再現可能な条件で走らせ、Contract形式でログ化
- Training:学習→評価→合格だけを成果物化(artifact)
- Ops:二重ガードレール(監視系)で検証し、段階展開・ロールバックで止めない
- Feedback:ヒヤリハットをContract形式で蓄積し、次のSim/学習へ戻す
読み方:以降は「ツール紹介」ではなく、各工程がループ上で何を渡すべきか(Contract)に集中します。
1. なぜ推論型AVは「監視と検証(運用OS)」が主戦場なのか
1.1. 推論は“正しい時もある”が、“外す時”が致命的
推論型AVは、レアな状況でも「筋の通った判断」を返せます。しかし、現場では外れ方が危険です。 だから設計の中心は「賢くする」だけでなく、外れた時に安全へ倒す運用になります。
1.2. ループを止めない3つの契約(Contract)
- ログ契約:何を残すか(介入・近接・危険推定・遅延・根拠)を最初に固定
- 評価契約:何をKPIにするか(安全停止/介入率/遅延p95/成功率)を固定
- 運用契約:段階展開・監視・ロールバックの条件(誰が止めるか)を固定
2. 最小アーキテクチャ:Reasoning AVを成立させる「6つの箱」
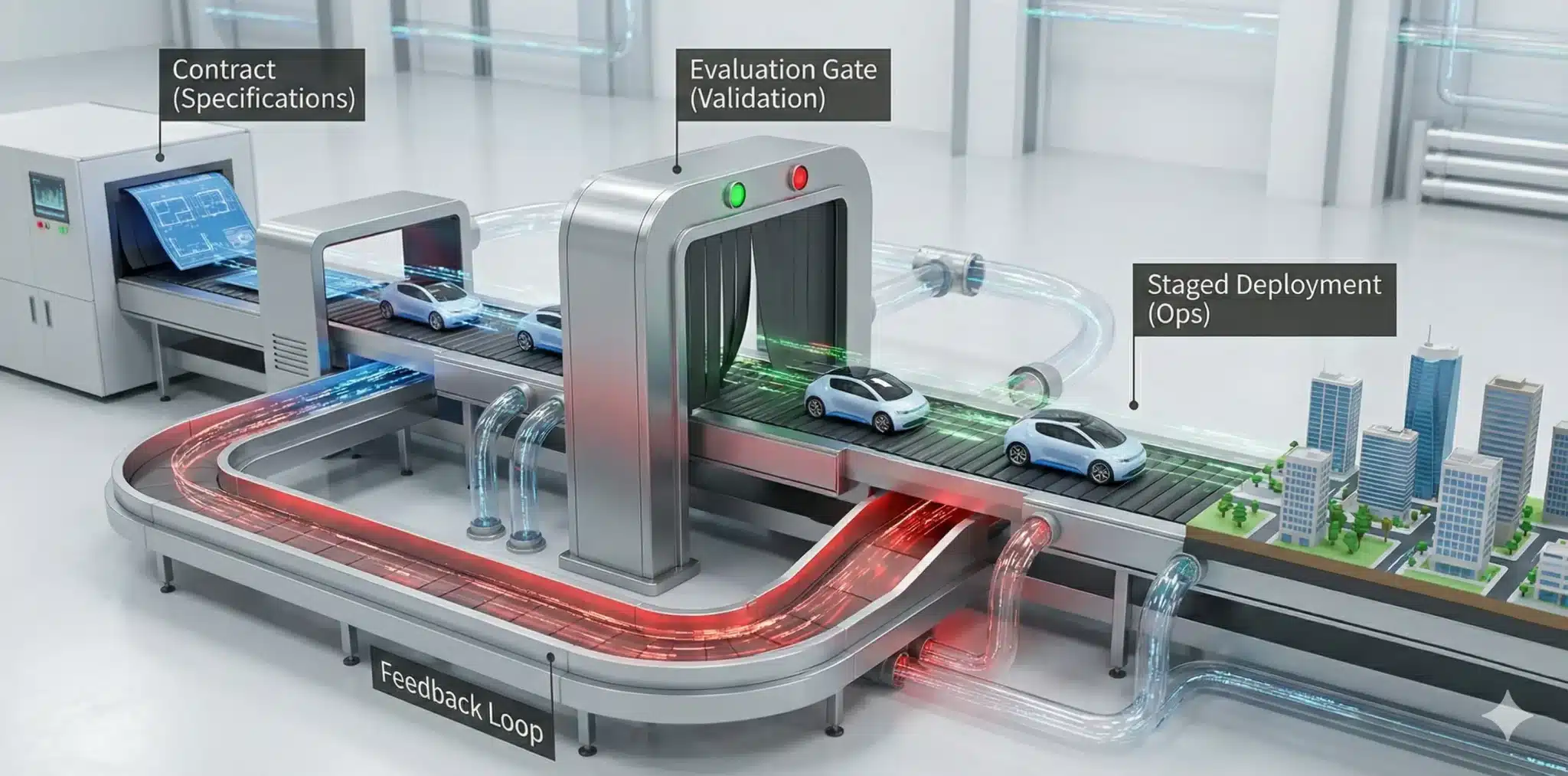 現場で迷子になりやすいので、まず“箱”を固定します。
現場で迷子になりやすいので、まず“箱”を固定します。
NVIDIAは、推論モデルだけでなくオープンソースの自動運転シミュレーション基盤「AlpaSim」と、計1,727時間の走行データセット(25カ国・2,500以上の都市で収録)も公開しており、「6つの箱」をそのまま回す土台が既に用意されています。
- Contract:ログ・KPI・介入ルール(仕様)
- Scenario:レア/危険/境界条件を作る(回帰試験の種)
- Sim:再現可能な条件で走らせ、Contract形式でログ化
- Train+Gate:学習→評価→合格だけartifact化
- Runtime Guardrails:監視と検証で危険時は安全動作へ
- Ops+Feedback:段階展開、監視、ロールバック、ヒヤリハット回収→再学習
3. 実装で詰まる論点:推論型AVがPoCで止まる典型パターン
ここから先は、技術の話というより「現場が止まる理由」の話です。
自動運転は、デモでは動きます。でもPoCで止まるのはたいてい「精度」ではなく「運用」です。
例えるなら、いくつもの担当がバケツリレーで水を運ぶ開発から、一本の太い配管で学習→評価→改善を回す開発へ――。
Alpamayoが狙っているのは、まさにこの“配管化”です(認識・判断・操作までをAIが一気通貫で扱う構成=E2Eと呼ばれます)。
そして重要なのは、これは研究の話ではなく、量産とフリート運用の話になってきたことです。NVIDIAの公式発表では、次のプレイヤーがAlpamayoに関心を示しています。
- JLR、Lucid、Uber、Berkeley DeepDrive など:推論型AVスタック開発・研究の加速
- Mercedes-Benz:AlpamayoベースのAVスタックを新型CLAに搭載し、2026年Q1に米国、Q2に欧州で展開予定
- Uber:2025年10月発表の提携で、2027年から最大10万台規模のL4ロボタクシー/配送フリート構想に言及
この流れの核心は、「ヒヤリハットを回収して、学習へ戻す速度」です。
NVIDIAはCosmosを用いた「データファクトリー」を共同構築し、フリートから得られるログを自動でキュレーションして学習へ戻す構想を示しています。
つまり、ここで整理する「Contract→Gate→Ops」は概念ではなく、量産車・フリートで“止めない”ための運用OSそのものです。
3.1. PoCが止まる「3つの落とし穴」
テスト走行ではうまくいく。 ところが本番に近づくほど、現場はこう言い始めます。「次に同じ状況が来たら、同じ判断ができるのか?」
PoCが止まる理由は、モデルの賢さよりも“戻せない・判定できない・止められない”運用設計の欠落にあります。
❶ ログが戻らない:介入やヒヤリハットが文章のままだと学習に使えない。
機械が読める形(構造化)が必要。たとえば──現場日報が「大変でした」だけだと、次の改善会議で何も決められないのと同じですね。
❷ 評価ゲートがない:「良さそう」で出すと事故る。
合否をコードで固定し、NG理由を返す。たとえば──稟議に“なんとなく期待”しか書かれていない投資は、あとで誰も責任を取れない。
❸ 段階展開とロールバックがない:100%展開は止まる。
まず小さく出し、監視し、戻せるようにする。たとえば──全社一斉の基幹システム切替は、戻せないと炎上するから段階移行が常識。
この3つが揃うと、4章のContract→Gate→Opsが「概念」ではなく「実装」になります。
3.2. “オープン”の落とし穴:コード・モデル・データは別物
CxO向け
NVIDIAは「オープン」と言いますが、全部がOSSではありません。コード/モデル重み/データは別物で、許される範囲(商用・再配布・クラウド提供)が違います。導入判断は「使えるか」より、どこまで出せるか(提供形態)で決まります。
エンジニア向け
混乱しやすいので、Alpamayoは三分割で把握してください(ここを誤るとPoC後に止まります)。
- コード(OSS):AlpaSim
シミュレータ本体はOSSとして公開されています(例:リポジトリのLICENSEでApache-2.0等を確認)。 - モデル重み(Open Model):Alpamayo 1 / R1
“公開=自由に再配布/商用OK”とは限りません。モデルカードとライセンス条項で、用途・再配布・派生物の扱いを確認します。 - データ(Open Dataset):Physical AI AV Dataset(1,727時間)
取得できても利用条件は別です。学習・評価・共有・再配布の可否はデータカードとDataset Licenseに従います。
実務の結論:「OSSだからOK」ではなく、三層それぞれのライセンスを前提に運用設計(社内利用/製品同梱/クラウド提供)を決めます。細目は必ず公式サイト(モデルカード/データカード/LICENSE)を参照してください。
4. 実務テンプレ:監視と検証で成立させる「最小構成」
ここからは、各節の冒頭で「何のために何をしているか」を短く説明し、その後に15行程度の疑似コードを置きます。
Alpamayo 1(約100億パラメータ)は車両に直接搭載するのではなく、大規模な教師モデル(teacher model)として位置づけられており、開発者がfine-tuneおよびdistillして、要件(レイテンシや消費電力)に合わせたより小さなランタイムモデルとしてAVスタックに組み込む構成が想定されています。
そのため、ここでのコードはロジック理解が目的であり、実行前提ではありません。
4.1. Contract:残すログと評価KPIを“仕様として固定”する
目的:Sim・学習・本番が同じ言葉で会話できるように、ログ項目と評価KPIを最初に固定します。 ここが曖昧だと、改善が属人化してループが止まります。
Contract(疑似):ログ項目・KPI・介入ルールを固定
# 疑似コード:Contract(仕様)を最初に固定する contract = { "log_fields": ["t","pose","speed","decision","risk","lat_ms","intervene","fail_reason"], "kpi_gate": {"intervene_max":0.02, "lat_p95_max":80, "success_min":0.92, "near_miss_max":0}, "override": {"risk_gt":0.8, "fallback":"safe_stop"} # 危険なら安全動作へ強制 } save_json("av_contract.json", contract) # 以降は全工程がこの契約に従う
要点:あとで整形するのではなく、最初に“契約”で縛ると、Sim↔Realの往復が速くなります。
4.2. シナリオ回帰:レアケースを作り、再現可能に回す
目的:推論型AVは「レアで壊れる」ことが多いです。 そこで、レア/危険/境界条件を“シナリオ”として固定し、毎回同じ条件で回帰試験します。
シナリオ回帰(疑似):危険条件を固定してSimへ渡す
# 疑似コード:シナリオ(レアケース)を固定し、回帰試験として回す contract = load_json("av_contract.json") scenario = {"id":"cut_in_017", "weather":"rain", "light":"night", "npc":"cut-in", "seed":17} sim = new_sim(seed=scenario["seed"]) # 再現のためseed固定 sim.apply(scenario) # 条件を適用(天候/照明/NPC挙動など) runs = [] # Contract形式のログを貯める箱 for t in range(5): # 例:5ステップ(本番は長い) obs = sim.observe() decision, risk, lat = policy_stub(obs) # 推論(仮)+危険推定+遅延 sim.step(decision) runs.append({"t":t,"pose":obs.pose,"speed":obs.speed,"decision":decision, "risk":risk,"lat_ms":lat,"intervene":0,"fail_reason":""}) save_jsonl("sim_cut_in_017.jsonl", runs, contract=contract)
要点:「増やす」より「固定して回帰」が効きます。改善が“再現できる工程”になります。
4.3. 学習→評価ゲート:合格だけを成果物(artifact)にする
目的:学習したモデルを“出しっぱなし”にしないために、評価ゲートで合格したものだけを成果物化します。 NGなら落ちた理由(fail)を返し、改善ループに戻します。
学習→評価→合否(疑似):NG理由を返す
# 疑似コード:train -> eval -> gate(合格だけ成果物にする) c = load_json("av_contract.json") dataset = load_jsonl("sim_cut_in_017.jsonl") model = train(dataset) # 学習(概念:OSS基盤の上で回す) m = eval_metrics(model, dataset) # KPI計測(介入/遅延/成功/near-miss) fail = [] # NG理由を貯める箱(落ちた原因の一覧) if m["intervene"] > c["kpi_gate"]["intervene_max"]: fail.append("intervene") if m["lat_p95_ms"] > c["kpi_gate"]["lat_p95_max"]: fail.append("latency") if m["success"] < c["kpi_gate"]["success_min"]: fail.append("success") if m["near_miss"] > c["kpi_gate"]["near_miss_max"]: fail.append("near_miss") if fail: print("REJECT", fail, m) # NGなら理由+数値を返して再学習へ else: artifact = save_artifact(model, m) # OKならモデル+指標を成果物化(監査/再現用) print("ACCEPT", artifact, m)
要点:fail(NG理由)があると、改善が「根性」ではなく「工程」になります。
4.4. 二重ガードレール:推論を“監視系”が検証し、危険なら安全へ倒す
 目的:推論系(意思決定)をそのまま信じません。 独立した監視系が「危険」「遅延」「想定外」を検証し、閾値を超えたら安全動作へ強制します。NVIDIAは、こうした二重ガードレールの考え方に対応する安全フレームワークとして「NVIDIA Halos」を公式に提供しており、クラシカルなルールベースのバックアップ層がAIの提案を監視し、危険な軌道を検出した場合にオーバーライドする構成が説明されています。
目的:推論系(意思決定)をそのまま信じません。 独立した監視系が「危険」「遅延」「想定外」を検証し、閾値を超えたら安全動作へ強制します。NVIDIAは、こうした二重ガードレールの考え方に対応する安全フレームワークとして「NVIDIA Halos」を公式に提供しており、クラシカルなルールベースのバックアップ層がAIの提案を監視し、危険な軌道を検出した場合にオーバーライドする構成が説明されています。
ガードレール(疑似):危険時は安全動作へ強制
# 疑似コード:二重ガードレール(推論の出力を監視系が検証する) c = load_json("av_contract.json") obs = read_runtime_observation() decision, risk, lat = policy_stub(obs) # 推論系(判断) fail = [] # 危険/異常の理由を貯める箱 if risk > c["override"]["risk_gt"]: fail.append("risk") # 危険推定が高い if lat > c["kpi_gate"]["lat_p95_max"]: fail.append("latency") # 遅延が悪い if is_out_of_distribution(obs): fail.append("ood") # 想定外入力(分布外) if fail: decision = c["override"]["fallback"] # 安全動作へ強制(例:安全停止) emit_event("GUARDRAIL_TRIGGER", fail) # 何が起きたかログに残す actuate(decision) # 最終的に車両へ出す
要点:推論型AVは「監視系が勝つ設計」にすると、現場で止まりにくくなります。
4.5. 段階展開とロールバック:止めない運用が“学習ループ”を成立させる
目的:最初から100%展開しません。 まず小さく出し(canary)、監視し、異常が出たら即ロールバックします。これが現場を止めず、ログを学習へ戻す前提です。
配信運用(疑似):canary→監視→OKなら拡大、NGならロールバック
# 疑似コード:段階展開(canary)とロールバック(止めない運用) artifact = load_artifact("av_model_ok_v5") # 4.3で合格した成果物 deploy("canary", artifact, traffic=0.05) # 5%だけに段階展開 ops = monitor(window_min=30) # 30分監視(介入/危険/遅延など) fail = [] # 運用異常の理由を貯める箱 if ops["error_rate"] > 0.01: fail.append("error_rate") if ops["intervene"] > 0.02: fail.append("intervene") if ops["lat_p95_ms"] > 80: fail.append("latency") if fail: rollback(to="prev_stable") # すぐ戻す(現場を止めない) emit_event("ROLLBACK", fail) # 理由を残す(次の改善の教師) else: scale(traffic=1.0) # 問題なければ全体へ拡大
要点:ロールバックがあると、現場ログが“学習燃料”として戻り続けます。
4.6. 事故/ヒヤリハット回収:RealログをContract形式で戻す
目的:現場で起きた「介入」「危険判定」「分布外」を、Contract形式で蓄積し、 次のシナリオ回帰と学習データへ戻します。ここが繋がると改善が“工程”になります。
フィードバック(疑似):RealログをContract形式に正規化して追記
# 疑似コード:Realログ -> 正規化 -> 学習コーパスへ追記 c = load_json("av_contract.json") raw = read_telemetry("fleet_last_24h") # 現場テレメトリ(例:24時間) norm = [] # Contract形式に揃える箱 for e in sample(raw, n=5): # 例:5件だけ(本番は大量) norm.append({"t":e.t,"pose":e.pose,"speed":e.speed,"decision":e.decision, "risk":e.risk,"lat_ms":e.lat_ms,"intervene":e.intervene,"fail_reason":e.fail_reason}) save_jsonl("real_norm_24h.jsonl", norm, contract=c) append_jsonl("train_corpus.jsonl", norm) # 次の学習へ戻す(ループを閉じる)
要点:Realログが“同じ形”で戻ると、改善が属人化せず回り始めます。
5. まとめ:推論型AVを成立させる最短チェックリスト
- Contract:ログ項目・KPI・介入ルールを仕様として固定したか
- シナリオ回帰:レアケースを固定し、同条件で再現できるか
- 評価ゲート:合否判定がコード化され、NG理由(fail)を返せるか
- 二重ガードレール:推論系と監視系を分離し、危険なら安全へ倒せるか
- 段階展開/ロールバック:止めない運用でログを回収できるか
結論:推論型自動運転は「賢いモデル」ではなく、監視と検証(運用OS)で成立します。 まずはContract→Gate→Opsの3点を固定してください。PoCで止まりにくくなります。
← 元の記事に戻る(Physical AI 2026:双方向循環の覇権)
よくある質問(FAQ)
Q1. なぜ最初にContract(契約)を固定するのですか?
A1. ログの意味が工程ごとにズレると、学習にも検証にも戻らずループが止まるためです。最初にContractを固定すると、後工程の整形・議論・監査が一気に楽になります。
Q2. fail(NG理由)を返す意味は?
A2. 改善を「工程」にするためです。落ちた理由が分かると、次に直すべき場所が明確になり、学習ループが速く回ります。
Q3. いちばんPoCで止まりやすいのはどこですか?
A3. 評価ゲートと運用(監視/ロールバック)がないことです。精度が良くても現場で止まるとデータが戻らず改善が止まります。
Q4. AlpamayoはE2E自動運転専用ですか?
A4. AlpamayoはE2E自動運転(認識から操作までを一気通貫で処理する構成)を前提に設計されていますが、推論VLAモデル・AlpaSim・オープンデータセットという構成要素は、分割アーキテクチャや監視系の設計にも流用できます。
本記事で示した「Contract→Gate→Ops」は、E2Eかどうかに関わらず「止まらない学習ループ」を設計するための考え方です。
専門用語まとめ(最小3つ)
- 推論型自動運転(Reasoning AV)
- 状況を“推論”して判断する自動運転の設計思想。賢さよりも、外れた時に安全へ倒す運用設計が重要。
- VLAモデル(Vision-Language-Action Model)
- 視覚情報(Vision)と言語(Language)を入力し、動作(Action)を出力するAIモデル。Alpamayo 1は論理推論(Reasoning)能力を備えた自動運転向けVLAとしては業界初とされています。
- 二重ガードレール(監視と検証)
- 推論系(判断)と監視系(検証)を分離し、危険・遅延・分布外なら安全動作へ強制する設計。
- NVIDIA Halos(安全フレームワーク)
- 自動運転スタック全体を支えるNVIDIA公式の安全フレームワーク。クラシカルなルールベース層がAIの判断を監視し、危険な軌道を検出した場合にオーバーライドする。本稿で説明する「二重ガードレール」に対応する公式実装の一つ。
- Berkeley DeepDrive(研究コミュニティ)
- 米UC Berkeley発の自動運転研究コミュニティ。NVIDIAの公式発表では、AV研究コミュニティの一員としてAlpamayoに関心を示し、推論型レベル4開発ロードマップの加速に向けた取り組みが紹介されています。
- シナリオ回帰(Scenario Regression)
- レアケースを固定し、同条件で繰り返し再現・検証して改善を積む手法。改善が工程化しやすい。
主な参考サイト
本記事は一次情報を軸に執筆しています。公式発表・公式リポジトリ・一次論文・公式ドキュメントを優先し、外部リンクで検証可能性を担保します。
- NVIDIA Newsroom(公式):Alpamayo発表(JLR・Lucid・Uber・Berkeley DeepDriveからのコメント含む)
- NVIDIA Developer(公式):Alpamayo for Autonomous Vehicle Development(製品ページ)
- NVIDIA(公式):Alpamayo – Open AI for Level 4 Autonomous Vehicles(概要)
- NVlabs(公式GitHub):Alpamayo(公開情報/コード)
- GitHub(公式):AlpaSim(オープンソース自動運転シミュレーション基盤)
- Hugging Face(公式):NVIDIA Physical AI Open Datasets(自動運転:1,727時間/25カ国/2,500+都市)
- Hugging Face(公式):Alpamayo-R1-10B(モデルカード)
- arXiv:Alpamayo-R1(論文・詳細)
- NVIDIA(公式):NVIDIA Halos(安全フレームワーク)
- NVIDIA Newsroom(公式):NVIDIAとUberのパートナーシップ(2025年10月28日)
- Uber(公式):NVIDIAとの提携リリース(2025年10月28日)
- 日経クロステック:NVIDIA、E2E自動運転向け論理推論AI「Alpamayo」 ベンツが採用
- NVIDIA Omniverse Documentation(公式)
- NVIDIA NeMo Documentation(公式)
合わせて読みたい
更新履歴
- 初稿公開





