


【2025年最新】4大LLMとの付き合い方|思想・戦略・活用で選ぶ最適解
AI(大規模言語モデル、LLM)が多すぎて、結局どれを使えばいいか分からない… そんなあなたのための、データに基づいたAIパートナー選び完全ガイド。
▶ この記事の信頼性の源泉(クリックで開閉)
はじめに:私たちはなぜ「どのLLMを使うべきか」で迷うのか?
本記事は、単なる機能比較や机上の空論ではありません。筆者自身が、市場をリードする以下の**主要LLM(大規模言語モデル)**の有料版をすべて契約し、日々数時間、実業務の中で「専門家チーム」として使い倒すことで得た実践的な知見に加え、信頼できる第三者機関のベンチマークデータを統合しています。
- ChatGPT (GPT-4o / Codex-1)
- Gemini (2.5 Pro / Flash)
- Claude (Opus 4 / Sonnet 4)
- Perplexity (Deep Research)
この記事を読めば、あなたが本当に必要としている「AIパートナー」としてのLLMが誰なのか、その客観的な根拠と共に見つかるはずです。
4大LLMの思想とポジショニング【データで補強】
なぜLLMによって回答の質や方向性が違うのか?それは、開発企業の「DNA」が性能に色濃く反映されているからです。
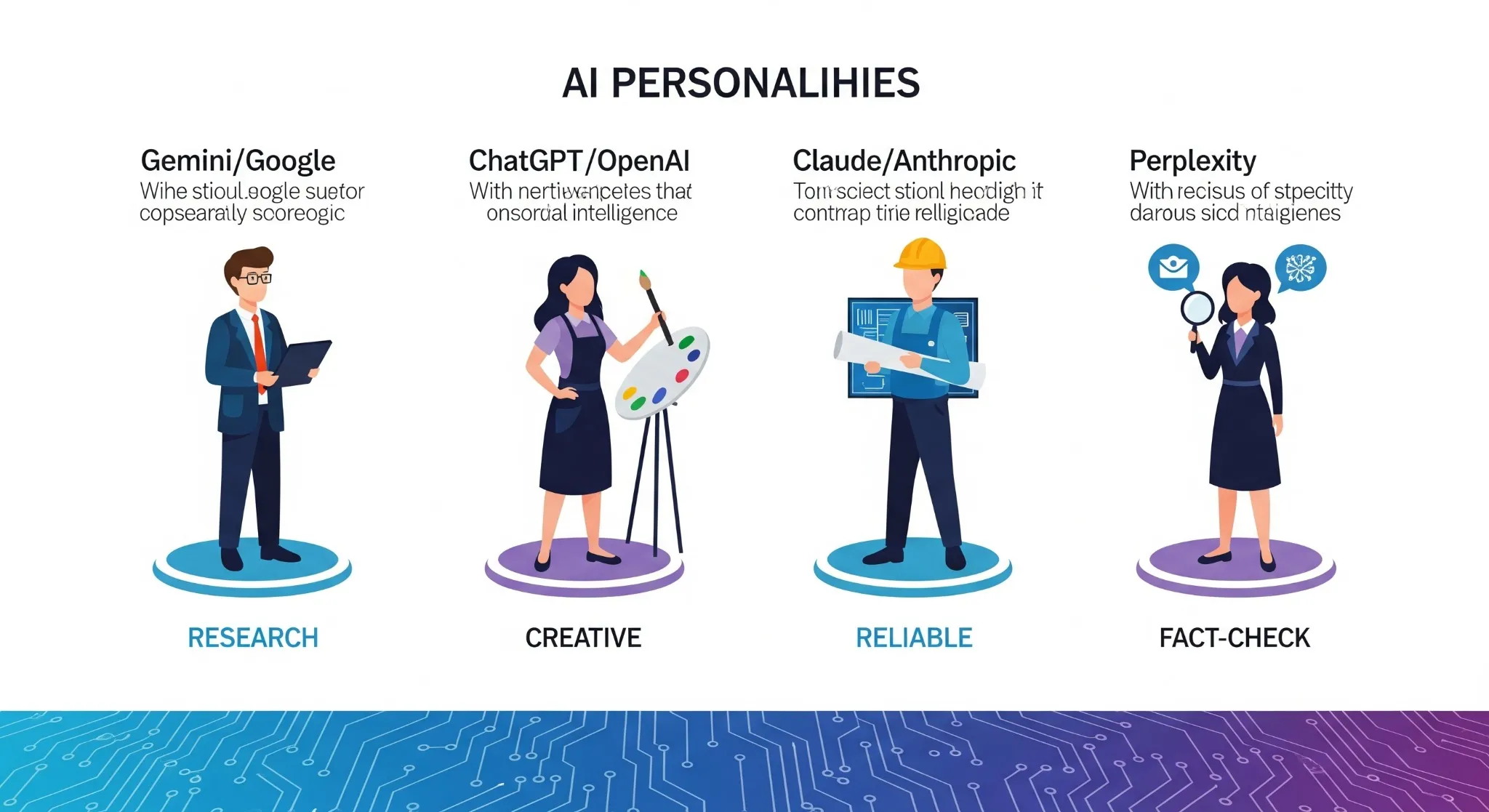 図1 4つのLLMの特徴とは?
図1 4つのLLMの特徴とは?画像解説文: 各LLMの「個性」を可視化した相関図。
GoogleのGeminiは学術的正確性、OpenAIのChatGPTは創造性、AnthropicのClaudeは信頼性、Perplexityは事実調査力をそれぞれ武器とする。
この記事では客観的ベンチマークデータを基に、あなたの目的に最適な「AIパートナー」を見つける方法を解説します。
1. Google (Gemini):世界中の情報を整理し、あなたの日常に溶け込む「万能アシスタント」
Googleの使命は「世界中の情報を整理し、世界中の人々がアクセスできて使えるようにすること」です。Geminiもその思想を継承し、Googleサービスとの深い連携を武器にしています。特に理数系の専門的な問題解決で強みを発揮し、Gemini 2.5 Proは高難度QAベンチマーク「GPQA Diamond」で84%というトップクラスのスコアを記録しています (Reddit)。
Googleは「情報の整理」という原点に基づき、既存サービスとの連携と、学術的な正確性を追求しています。専門的なリサーチやデータ分析で頼れるLLMです。
2. OpenAI (ChatGPT):AGIを目指し、人類の創造性を拡張する「クリエイティブ・パートナー」
OpenAIのミッションは「人類全体に利益をもたらす汎用人工知能(AGI)の構築」です。その汎用性は言語能力にも表れており、最新のGPT-4oは多言語・推論タスク(MMLU)で88%級のスコアを達成 (OpenAI)。コーディング分野では、後述のClaudeが公式トップですが、OpenAIも開発特化のCodex-1がSWE-Benchで72.1%*(社内計測値・非公式)という肉薄した性能 (OpenAI) を示すなど、幅広い分野で高い能力を発揮するLLMです。
3. Anthropic (Claude):安全性を第一に、専門業務を支える「信頼できる推論エンジン」
「AIの安全性」を最重要視するAnthropicが開発したClaudeは、長文の論理的一貫性に定評があります。その実力は、実際のGitHub上のバグを修正する能力を測るSWE-Benchにおいて、Claude 4 Opusが現在公式リーダーボードトップの72.7%というスコアを記録している点にも表れています (forgecode.dev)。複雑なコード修正や契約書の読解で絶大な信頼性を誇るLLMです。
4. Perplexity AI (Sonar):ハルシネーションを撲滅し、根拠のある真実だけを届ける「知識の探求者」
Perplexityは「もっともらしい嘘(ハルシネーション)」をなくすため、すべての回答に情報源を明記する設計思想を徹底しています。その精度は客観的にも証明されており、事実調査タスク(SimpleQA)で93.9%という驚異的な正答率を達成 (Perplexity AI)。最新情報のファクトチェックやリサーチにおいて、他のLLMの追随を許しません。
【機能・性能】主要LLMプラットフォーム徹底比較表
思想だけでなく、具体的な機能や客観的性能データで各LLMを比較します。
| Perplexity | ChatGPT (OpenAI) | Claude (Anthropic) | Gemini (Google) | |
|---|---|---|---|---|
| コンセプト | 知識の探求者 | クリエイティブ・パートナー | 信頼できる専門家 | 万能アシスタント |
| 客観的性能と得意タスク | 事実調査・引用付き検索 (SimpleQA 93.9%) |
多言語・推論 (GPT-4o: MMLU 88%級) コード生成 (Codex-1: SWE-Bench 72.1%* [非公式]) |
コード修正 (Opus: SWE-Bench 72.7%公式) |
STEM高難度QA (2.5 Pro: GPQA Diamond 84%) |
| 長文処理能力 (コンテキスト長) | △ | ○ | ◎ (200kトークン超) | ○ |
| ユニーク機能 | Deep Research, Pages | GPTs, Voice Mode, Codex-1 | Artifacts機能, 長文コンテキスト | Workspace連携, 拡張機能 |
* 注:Codex-1 の 72.1% は、OpenAI が自社ブログで公表した社内測定値であり、SWE-Bench Verified の公式リーダーボードには掲載されていません(社内計測値・非公式)。
【目的別】あなたの最強LLMパートナーはどれだ?
具体的な目的別に、データに基づいた最適なLLMを見ていきましょう。
Case 1:「最新の市場動動向を、信頼できる情報源を基にレポートしたい」
結論:Perplexity が最適
理由:事実調査のベンチマーク(SimpleQA)で93.9% (Perplexity AI)という圧倒的なスコアが示す通り、誤情報のリスクが極めて低いのが特徴です。常に参照元リンクを提示するため、ファクトチェックの時間を大幅に削減できます。
Case 2:「新しいサービスのキャッチコピーを、100個ブレストしたい」
結論:ChatGPT (GPT-4o) が最適
理由:創造性や発想の柔軟性はベンチマークで測りにくい部分ですが、多言語性能(MMLU 88%級) (OpenAI)に代表される高い言語能力が、クリエイティブなタスクでも強みを発揮します。思考の「ジャンプ」を助ける最高のパートナーです。
Case 3:「大規模システムの複雑なバグを修正したい」
結論:Claude (Opus 4) が最適
理由:実際のバグ修正能力を測るSWE-Benchで、公式リーダーボードトップ (72.7%) (forgecode.dev) のスコアを記録しています。既存の複雑なコードベースを正確に理解し、信頼性の高い修正パッチを生成する能力に長けています。
Case 4:「今日の会議の議事録(Googleドキュメント)を要約して、関係者への報告メールを作りたい」
結論:Gemini が最適
理由:Google Workspaceとのシームレスな連携はGemini最大の強みです。ドライブ内のドキュメントを直接参照し、Gmailの下書きを作成するといった一連の作業をスムーズに行えます。
【上級編】LLMを「チーム」として使いこなし、生産性を最大化する
基本的な役割分担を理解したら、次はLLMチームで成果を出すための、より高度な戦略を学びましょう。
1. 「LLMチーム編成」で最大40%の工数削減を目指す
単一のLLMに全てのタスクを任せるのは非効率です。ある調査では、タスクごとに「得意なLLM」を指名し、人間がレビューする“AIチーム編成”によって、最大30~40%もの工数削減が実証されています (TechCrunch)。
2. トップモデル同士を競わせる「A/Bテスト思考」
「この問題に対する最も論理的な答えは何か?」——重要な問いには、複数の専門家の意見を聞くべきです。
ノウハウ:例えば、ある戦略について、長文の論理性に優れるClaude Opusと、多角的な視点を持つGPT-4oの両方に同じ質問を投げかけます。それぞれの回答を比較検討することで、単一のLLMではたどり着けない、より深く、リスクの少ない結論を得ることができます。
3. 特化ツールを「専門家」として尊重する
LLMチームの監督として、各メンバーの専門性を最大限に尊重することが重要です。
- 事実調査と出典確認なら、迷わずPerplexity (SimpleQA 93.9%)に依頼する。
- コードのバグ修正は、公式ベンチマークトップのClaude Opus (SWE-Bench 72.7%)が第一人者。
- 対話的なコード生成やプロトタイピングでは、比較対象としてCodex-1 (SWE-Bench 72.1%* [非公式])も選択肢に入ります。
- 理数系の専門的なリサーチは、Gemini 2.5 Pro (GPQA Diamond 84%)という博士に任せる。
汎用モデルに専門外の仕事をさせて低い品質のアウトプットを得るより、最初からその道の専門家であるLLMに頼む方が、結果的に遥かに効率的です。
よくある質問(FAQ)
日本語の精度が一番高いLLMはどれですか?
A. 用途によって最適なモデルは異なります。以下に、日本語タスクにおける代表的なLLMの得意分野をまとめました。
- 汎用対話・翻訳:GPT-4o
日本の医師国家試験(JMLE)で正答率93.3% (arXiv)を記録するなど、専門的な語彙も正確に扱え、敬語や口語の切り替えも自然です。 - 法律・学術系の長文精読:Claude 4 Opus
長文でも論理の一貫性を保つ能力が高く、契約書や論文など、硬い文章の読解・生成で特に強みを発揮します。 - 検索付きリサーチ:Perplexity Deep Research
事実調査で93.9% (Perplexity AI)という高い正答率を誇り、日本語での情報収集でも誤情報リスクを低く抑えられます。
結論:日常的な対話や翻訳ならGPT-4o、専門的な長文を扱うならClaude 4 Opusを軸に、目的に応じて使い分けるのが最短ルートです。数値は常に変動するため、モデル名と日付を記録し、定期的な再評価をお勧めします。
結局、最初に試すべきLLMはどれですか?
LLMに入力した情報やデータのプライバシーは安全ですか?
A. 非常に重要な注意点です。結論から言うと、デフォルト設定のまま個人情報や会社の機密情報を入力するのは避けるべきです。
多くのLLMサービスでは、ユーザーが入力したデータをサービスの改善(AIの再学習)に利用することが利用規約に記載されています。しかし、主要なサービスには、このデータ学習を無効にする「オプトアウト」機能が用意されています。業務で利用する際は、必ず会社のセキュリティポリシーと各LLMのプライバシー設定を確認してください。
まとめ:単一の「最強」は存在しない。データに基づき「専門家チーム」としてのLLMを使いこなそう
ここまで見てきたように、2025年現在、すべてのタスクを完璧にこなす単一の「最強LLM」は存在しません。しかし、客観的なデータでそれぞれのLLMが持つ「個性」と「得意分野」を理解すれば、彼らはあなたの仕事を強力にサポートする「専門家チーム」になります。
- 事実を調査する「リサーチャー」としてのPerplexity
- アイデアを広げる「クリエイター」としてのChatGPT
- コード修正の「トップエンジニア」としてのClaude
- 日常業務を片付ける「秘書」としてのGemini
これからは、一つのLLMに固執するのではなく、解決したい課題に応じて最適な専門家(LLM)に協力を仰ぐ――。そんな「LLMチーム」をデータに基づいて率いる監督のような視点こそが、これからの時代に求められるスキルなのです。
主な専門用語解説
- LLM(大規模言語モデル)
- 膨大なテキストデータを学習することで、人間のように自然な文章を生成したり、要約したり、質問に答えたりできるAI技術。本記事で紹介しているAIの頭脳にあたる部分です。
- AGI(汎用人工知能)
- 特定のタスクに特化するのではなく、人間と同等かそれ以上に、幅広い知的作業をこなせるAIのこと。多くのAI開発企業が目指す最終的な目標の一つです。
- ハルシネーション
- AIが事実に基づかない、もっともらしい嘘の情報を生成してしまう現象のこと。AIの回答を鵜呑みにせず、特に正確性が求められる場面では出典の確認が重要です。
- コンテキスト長(Context Length)
- AIが一度に処理できる情報量(文脈の長さ)のこと。単位は「トークン」で表されます。この値が大きいほど、長文の資料を一度に読み込ませたり、長い会話の文脈を維持したりするのが得意になります。
- ベンチマーク
- AIの性能を客観的に測定するための標準的なテストや指標のこと。SWE-Bench(実際のGitHub上のバグに対し修正パッチを生成する能力を評価)、MMLU(言語理解)、GPQA(理数系QA)など、様々な種類があります。
- オプトアウト
- 「拒否する」「参加しない」という意味。LLMサービスにおいて、ユーザーが入力したデータをAIの学習に利用されることを拒否する設定を指します。プライバシー保護のために重要な機能です。
更新履歴
- 用語解説追加、比較表とFAQを新たに追加
- 全面的な内容改訂、上級者向けノウハウを追加
- 初版公開
主な参考公式サイト
- OpenAI Blog (ChatGPT開発元)
- The Keyword | Google AI (Gemini開発元)
- Anthropic News (Claude開発元)
- Perplexity Blog
- ITmedia AI+ (国内AI関連ニュース)
- WIRED.jp | AI (グローバルなAI動向)








