


2025年AI最前線:AIは「現場」で賢くなる。自己進化の秘密とは?
この記事の信頼性の源泉(クリックで開閉)
現場経験を生かし、最新情報を噛み砕いてお届けします。
はじめに:AIが「現場」で進化する、その秘密とは?
「一度学んだら終わり」──これまでのAIの常識が、いま根本から覆されようとしています。2025年、AIは学習を終えた後も、現場で遭遇する予期せぬ状況から学び続け、リアルタイムで自らを進化させる時代に突入しました。
- 学習フェーズ: まず、膨大なデータ(教科書)から知識を徹底的に「学ぶ」。
- 推論フェーズ: 次に、学んだ知識を使い、質問に「答える」。
つまり、「一度学んだら、その知識は固定される」のが当たり前だったのです。しかし、この方法では、刻一刻と変化する現実世界の予測不可能な状況に対応できません。まるで、教科書通りの知識しかない新人が、いきなり予期せぬトラブルが多発する「現場」に放り込まれたようなものです。
AIが「推論する(答える)まさにその瞬間」にも、新しい状況から学び、自らを賢く微調整していく――。これは単なる弱点の補完ではありません。
AIは「一度覚えたら終わり」から、「現場で成長し続ける知能」へ──これこそTTAの核心です。
この “現場での微調整” を支える仕組みが TTA(テストタイムアダプテーション)です。
この記事では、AIが「現場」で賢くなる自己進化の秘密、TTAの仕組みからビジネスへの応用までを、誰にでも分かるように徹底解説します。
AIの「学習」と「推論」の基本(料理のたとえ話で)
学習は「レシピを覚える」、推論は「料理を作る」、TTAは「目の前の食材に合わせて味を整える」——この三つで AI の流れが一気にイメージできます。
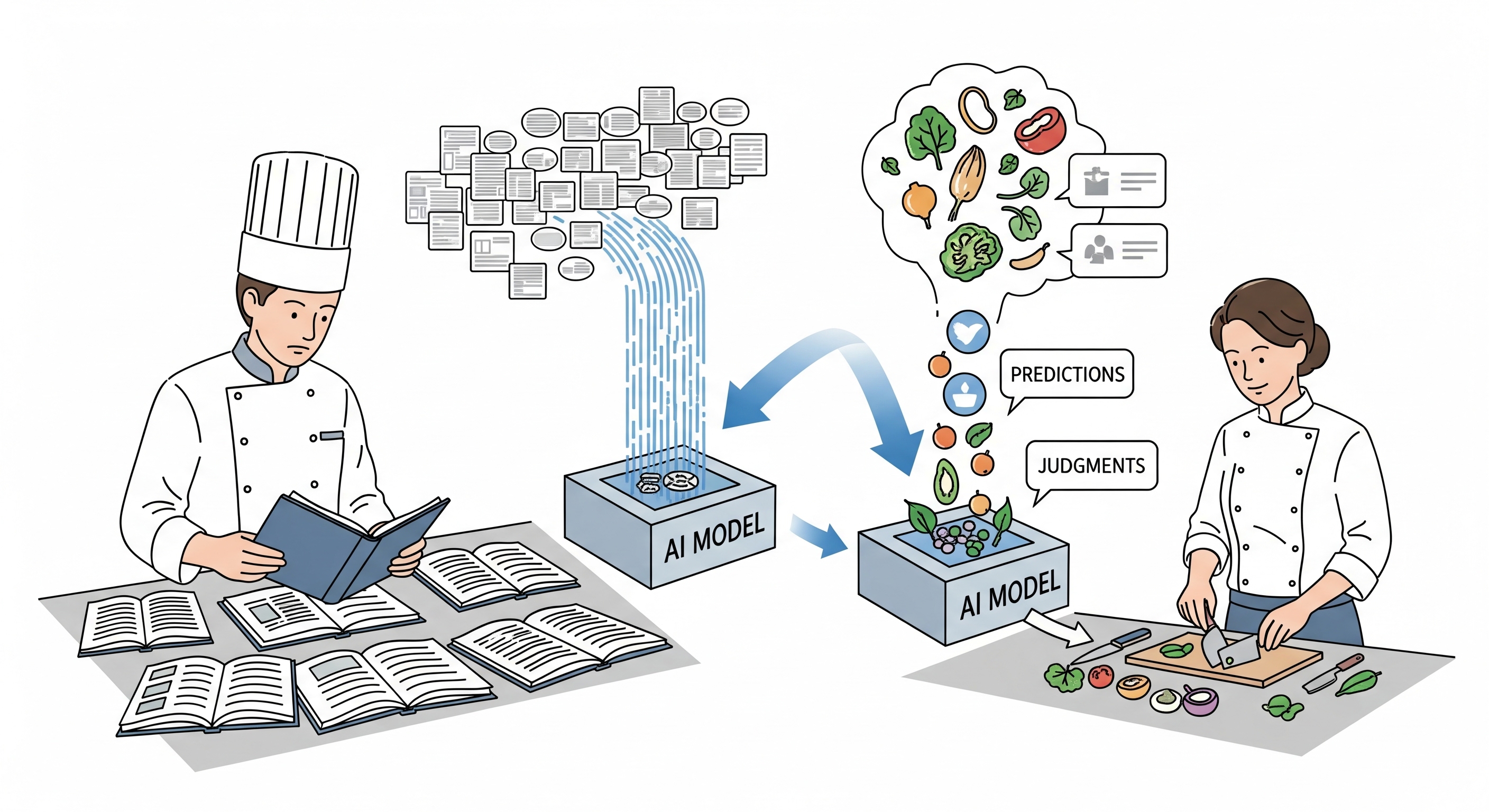
① 学習フェーズ:AIが「知識を蓄える」段階
この段階は、料理人がたくさんのレシピ本を読み込み、材料の下準備の仕方、加熱の温度、調味料の配合といった調理の基本を学ぶことに似ています。AIはこのフェーズで、膨大なデータ(まるでレシピ本!)を取り込み、その中に隠されたパターンや関係性を徹底的に学習します。
② 推論フェーズ:AIが「知識を使い、そして進化する」段階
【従来の推論】:学んだ知識を「使う」だけの段階
推論フェーズは、仕込み済みのレシピを使って実際に料理する段階です。
従来のAIでは、この段階で新たな学習は行われず、ただ覚えたレシピを忠実に再現するだけでした。
【TTAが加わった推論】:現場で学び、「進化する」段階
TTAは “答えを出すだけ” だった推論を、“答えを出しながら学ぶ” プロセスに変えます。
AIは推論の真っ最中でも、目の前のデータ(初めて見る食材)の特性を瞬時に見抜き、モデル(レシピ)をその場で微調整します。 これにより、予期せぬ状況でも、より正確で柔軟な判断が可能になるのです。
| フェーズ名 | 目的 | 料理のたとえ | 特徴 |
|---|---|---|---|
| 学習フェーズ | 大量のデータからパターンやルールを学ぶ | レシピを読み、調理の工程を覚える | 知識の蓄積、AIモデルの構築 |
| 推論フェーズ (TTA) | 学習知識を適用し、同時に現場の状況に適応する | 料理を作りながら、食材や環境に合わせて調理法を改善する | 知識の活用+自己進化、問題解決 |
このように、従来のAIは「学習」と「推論」が完全に分離していましたが、TTAはこの垣根を越え、「推論時の改善」を可能にします。この進化こそが、AIが実世界で継続的に適応し、性能を向上させるための核心なのです。
なぜAIは「推論」時に更に賢くなる必要があるの?
AIが真の知能へと進化するために、「その場で学ぶ」能力は、もはや選択肢ではなく必須の要件です。その理由は、単に予期せぬデータ変化に対応するという守りの発想だけではありません。むしろ、AIの性能を次のレベルへ引き上げるための、積極的な進化戦略なのです。
理由1:現実世界の変化に対応する(ドメインシフト問題)
AIは、訓練されたデータに基づいて判断を下すように設計されていますが、現実世界は常に変化し、学習時には見られなかった新しい状況が頻繁に現れます。これを「データ分布のズレ」、あるいは「ドメインシフト」と呼びます。
 図2 ドメインシフトのイメージ
図2 ドメインシフトのイメージ具体例として、晴天下の道路データで学習した自動運転車のドメイン(Training Distribution)が夜間の雨天環境(Test Distribution)に遭遇した場合を想定してください。
このようなドメインシフトが発生しても、TTAにより路面反射や視認性低下に動的に適応し、従来手法では認識困難だった状況でも安全な走行判断を継続できるようになります。

図3: ドメインシフトの概念図
理由2:「事前学習」だけでは越えられない壁がある
近年のAIの目覚ましい進化は、モデルサイズや学習データ量を増やす「スケールメリット」によって牽引されてきました。しかし、この戦略にも限界が見え始めています。
教科書を増やしても、未知の応用問題は解けません。AIも同じで、データ量を増やすだけでは限界が来ます。
これと同じで、AIも事前学習を大規模化するだけでは、本質的な汎化性能(未知の状況に対応する能力)はいずれ頭打ちになります。
専門用語では「スケール則の限界」や「OOD(Out-of-Distribution)」問題と言いますが、要は “見たことのない状況に弱い” という課題です。
特に、AIの真の「賢さ」を問うようなタスクでは、この限界が顕著になります。
理由3:「本当の賢さ」が問われる(ARCベンチマークの教訓)
TTAの重要性を理解するために、AI推論能力の評価指標であるARC(AI Reasoning Challenge)ベンチマークの結果を見てみましょう。ARCが求めるのは「学習データのパターンを暗記する能力」ではなく、「初めて見る問題でも、原理原則から考えて正解を導き出す能力」です。この能力こそが、TTAが目指す「現場での適応的推論」の本質なのです。
この「現場での適応的推論」能力の重要性は、最新のARCベンチマークの結果が示しています。ARCは単なる知識の暗記ではなく、初見の問題に対する推論能力を評価するため、TTAが目指す適応的知能の指標として参考になります。
2024年12月に発表されたOpenAIのo3モデルは、ARC-AGI-1ベンチマークのSemi-Private Evalで75.7%、高リソース設定で87.5%のスコアを公式達成。(ARC Prize 2024公式発表)。これは従来のAIモデルの性能を大幅に上回る結果です。
一方、より難度の高い新ベンチマークである「ARC-AGI-2(ARC-2)」においては、人間が平均60%の正答率を記録しているのに対し、現状の最先端AI(o3モデル含む)は1%から数%台に留まります。
| ベンチマーク | 人間平均正答率 | OpenAI o3(参考値) | 他AIモデル(参考値) |
|---|---|---|---|
| ARC-AGI-1 | 約85% | 75.7~87.5% | ~55% |
| ARC-AGI-2 | 約60% | 1~3% | 1~4% |
参考にしたサイト
TTA(テストタイムアダプテーション)って何?
TTA(Test-Time Adaptation)は、推論中にバッチ正規化層だけを微調整し、未知環境でも即座に精度を保つ手法です。
調整するのは主に次の部分です
- バッチ正規化層で使われる「平均」や「分散」といった統計値
- バッチ正規化層で使われる「スケール」や「バイアス」といったパラメータ(アフィン変換パラメータ)
ポイント
- モデル全体を一から学習し直すわけではなく、「正規化層」に関する限られたパラメータだけを動的に更新します。
- これにより、新しいデータの特徴に素早く馴染むことができます。
かみ砕き解説:
バッチ正規化とは?バッチ正規化(Batch Normalization, BN)層は、各層への入力データを平均0、分散1に正規化する処理を行いますが、TTAではこの正規化に使用する統計量を、新しいテストデータの分布に基づいて動的に更新します。これにより、モデルが新しいデータ分布に適応できるようになります。
下図は “テストデータ → 適応ループ → 高精度予測” というTTAの流れを示しています。従来の学習済みモデル(左側)にテストデータが入力される際、新たに「適応ループ」が追加されます。この適応プロセスでは、歯車と調整ダイヤルで表現されているように、リアルタイムでモデルの内部パラメータが微調整され、最終的により精度の高い予測結果が得られます。
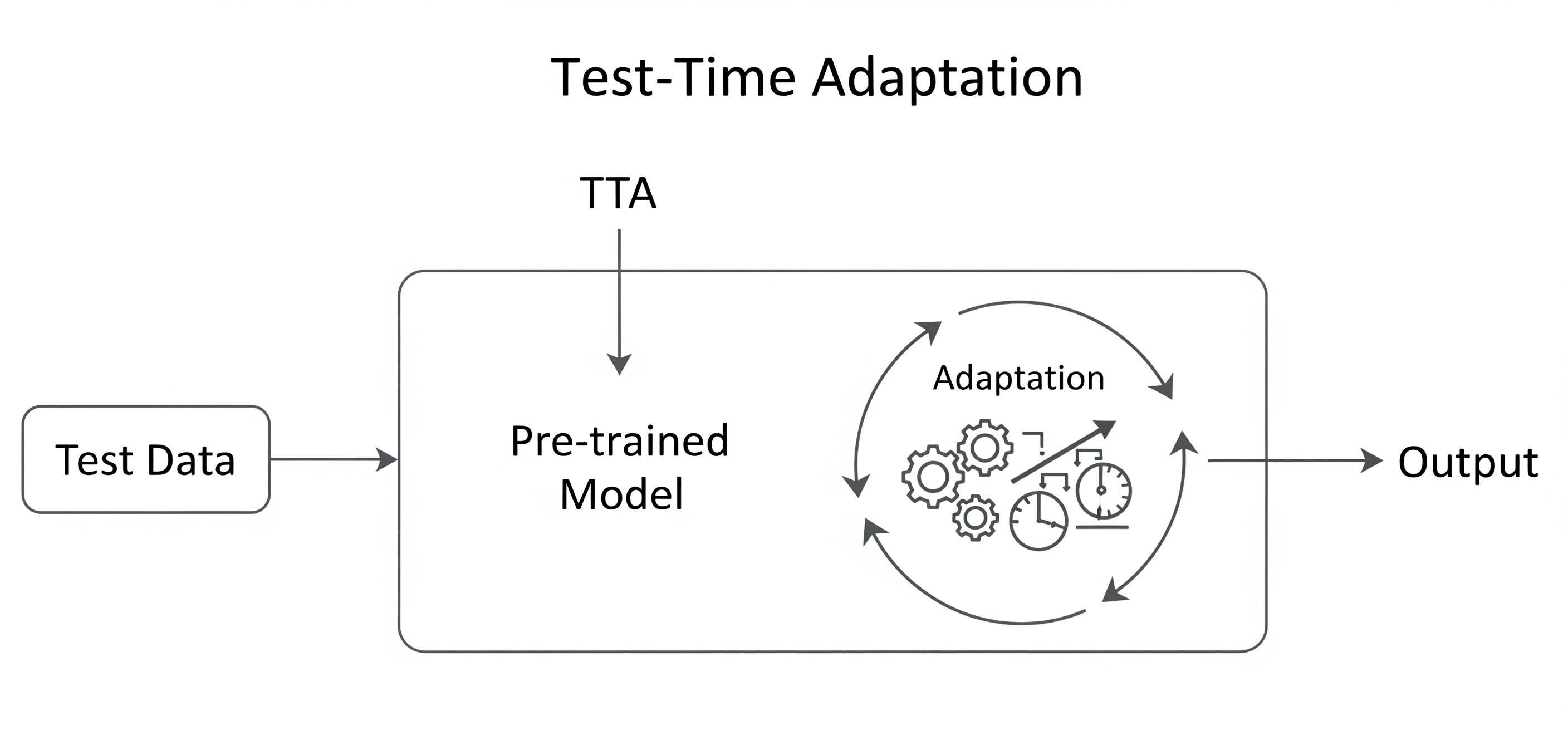
図4: テストタイムアダプテーション(TTA)の概念図
特に注目すべきは、TTAなら元の訓練データを読み直さなくても、その場の環境に合わせて賢くなれます。これは、個人情報保護や企業秘密といったデータプライバシーの観点からも非常に魅力的で、AIの活用範囲を広げる大きな利点となります。
TTAの実証効果(実際の研究結果)
TTAの効果は複数の研究で実証されており、代表的な成果として以下が挙げられます。
- Wang, D., et al. (2020)の研究では、CIFAR-10-Cベンチマークにおいて、TENT手法が従来のベースライン手法と比較して顕著な性能改善を示しています(具体的な改善幅は汚損の種類や強度により異なります)。
- Sun, Y., et al. (2020)の研究でも、様々なデータ分布シフトに対して自己教師あり学習を用いたTTAが有効であることが確認されています。
- 医療画像分野では、複数の病院間で撮影された画像の特性の違い(ドメインシフト)に対し、TTAが診断精度を維持する上で効果的であることが示されています。
※詳細な数値は各研究の実験設定により異なるため、実装時は最新の論文を参照することをお勧めします。
TTAの実装コード例
🎯 このセクションの目的
TTAの考え方を理解するために、PyTorchを用いたシンプルな実装例を段階的に解説します。これはTENT(Test-Time Entropy Minimization)という代表的な手法に基づいた学習用コードです。
🔄 処理全体の流れ(料理人の例で理解)
💡 TTAの処理フロー
レシピ本(学習済みモデル)と新しい食材(テストデータ)を用意
新しい食材を見て、どんな料理にするか予測
「この予測、確信度90%以上?」
✅ YES → 次へ進む ❌ NO → 次の食材へ
予測を元にレシピをほんの少し改良
すべての食材で同じプロセス
新しい環境に適応したレシピ本の完成!
📝 レベル1:基本理解(初心者向け)
「何をしているか」を理解しよう
# 🎯 このコードの目的:AIが現場で自分を賢くする仕組み def entropy_loss(outputs): """AIの「迷い」を数値化する関数""" # AIが「犬かも...猫かも...」と迷うほど、数値が大きくなる # 迷いが少ない = 確信がある = 良い状態 def test_time_adaptation(model, test_data, optimizer): """AIが現場で自分を改良する関数""" # 1. 新しいデータを見る # 2. 予測の確信度をチェック # 3. 確信があるなら、その予測を信じて自分を調整 # 4. 繰り返し
TTAは「AIが自分の予測に確信があるときだけ、その予測を手がかりに自分を改良する」シンプルな仕組みです。
🔧 レベル2:実装詳細(中級者向け)
「どうやっているか」を理解しよう
import torch import torch.optim as optim def entropy_loss(outputs: torch.Tensor) -> torch.Tensor: """ 🎯 目的:AIの予測の「あいまいさ」を測る 📊 仕組み: - 確率に変換 → ログ確率を計算 → エントロピー算出 - 値が小さい = 確信度が高い = 良い予測 """ probabilities = torch.softmax(outputs, dim=1) # 予測を確率に変換 log_probabilities = torch.log_softmax(outputs, dim=1) # ログ確率を計算 return -(probabilities * log_probabilities).sum(dim=1).mean() # エントロピー def test_time_adaptation( model: torch.nn.Module, test_loader: torch.utils.data.DataLoader, optimizer: torch.optim.Optimizer, adaptation_steps: int = 1, confidence_threshold: float = 0.9 ) -> torch.nn.Module: """ 🔄 TTAのメイン処理 """ model.train() # BN層を適応可能モードに for data, _ in test_loader: for _ in range(adaptation_steps): # 🔍 予測と確信度の計算 outputs = model(data) confidence = torch.max(torch.softmax(outputs, dim=1), dim=1)[0] # 🛡️ 安全チェック:確信度が閾値以上の場合のみ学習 if confidence.mean() >= confidence_threshold: optimizer.zero_grad() loss = entropy_loss(outputs) loss.backward() optimizer.step() model.eval() return model
📋 関数の引数説明
中心となるtest_time_adaptation関数で使う主な引数(設定項目)は以下の通りです。
| 引数名 | 役割 |
|---|---|
model |
適応させたい学習済みAIモデル |
test_loader |
現場で得られた新しいデータ(ラベルなし) |
optimizer |
モデルを更新するための道具(アルゴリズム) |
adaptation_steps |
1つのデータに対する自己修正の回数 |
confidence_threshold |
「自信がある」と判断するための基準値(例: 0.9) |
🧠 レベル3:理論背景(上級者向け)
「なぜそうするか」を理解しよう
def test_time_adaptation(model, test_loader, optimizer, adaptation_steps=1, confidence_threshold=0.9): """ 🧠 理論的背景: エントロピー最小化により、モデルが新しいドメインでも 高い確信度の予測を出せるよう自己調整する 🛡️ 安全機構: confidence_thresholdにより、不確実な予測での学習を防ぐ 📚 参考文献: Wang, D., et al. "Tent: Fully Test-time Adaptation by Entropy Minimization." ICLR 2021. """ model.train() # BN層を適応可能モードに変更 for data, _ in test_loader: for _ in range(adaptation_steps): optimizer.zero_grad() outputs = model(data) # 確信度ベースのフィルタリング confidence = torch.max(torch.softmax(outputs, dim=1), dim=1)[0] # 破滅的忘却を防ぐための安全装置 if confidence.mean() >= confidence_threshold: loss = entropy_loss(outputs) loss.backward() optimizer.step() # グラディエントの正規化(オプション) torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) model.eval() return model
TTAの有効性は「適切に学習されたモデルは新しいドメインでも低エントロピー(高確信度)の予測を出すべき」という仮定に基づいています。この仮定により、予測の確信度を高める方向にパラメータを調整することで、ドメイン適応が実現されます。
🎛️ パラメータ設定ガイド
| 値の範囲 | 評価 | 説明 |
|---|---|---|
| 0.0 – 0.7 | 要注意 | 確信度低い(破滅的忘却のリスクあり) |
| 0.7 – 0.9 | 慎重使用 | まあまあ(慎重に使用すること) |
| 0.9 – 1.0 | 推奨範囲 | 確信度高い(安全に学習可能) |
| 回数 | 評価 | 説明 |
|---|---|---|
| 1回 | 高速処理 | 処理は高速だが適応が浅い |
| 3-5回 | バランス型(推奨) | 処理速度と適応深度のバランスが良好 |
| 10回以上 | 慎重処理 | 適応は深いが時間とリスクが増加 |
🌟 実践的な使用例
ここまで料理人の例で説明しましたが、実際のビジネスでの活用例として、医療分野での応用を見てみましょう。
医療画像診断でのTTA適用例
# 🏥 実際の使用例:医療画像診断での適応 # 病院Aで学習したAIを病院Bで使用する場合 model = load_pretrained_medical_model() # 病院Aで学習済み hospital_b_data = load_hospital_b_images() # 病院Bの新しい画像 # BN層のパラメータのみを適応対象に指定 adaptable_params = [ p for name, p in model.named_parameters() if "bn" in name and p.requires_grad ] # TTAで病院Bの画像特性に適応 adapted_model = test_time_adaptation( model=model, test_loader=hospital_b_data, optimizer=optim.Adam(adaptable_params, lr=0.001), confidence_threshold=0.9, # 90%以上確信がある予測のみで学習 adaptation_steps=3 ) # 🎯 結果:病院Bでも高精度な診断が可能に!
💡 効果:撮影機器やプロトコルの違いによる画像特性の変化に対応し、診断精度を維持できます。
TTAの技術的限界と課題
以上のように、TTAは画期的な技術ですが、以下のような課題も存在します。
計算コストの増加
推論時にも最適化処理が必要となるため、従来の推論と比較して計算時間が増加します。リアルタイム処理が求められる用途では、この点を考慮した設計が重要です。
破滅的忘却
継続的な適応により、元の学習済み知識が失われる可能性があります。特に、大きく異なるドメインへの適応や、長期間の連続的な適応において顕著に現れます。
これを軽減するため、Elastic Weight Consolidation(EWC)やL2正則化などの手法が併用されることがあります。
適応の安定性
適応処理が不安定になり、かえって性能が低下する場合があります。
これは特に学習率が高すぎる場合や、ノイズの多いデータに対して顕著です。対策として、適応型学習率スケジューリングや、複数回の適応結果の平均化などが有効です。
よくある質問(FAQ)
▶ TTAは従来のAIの学習方法とどう違うの?
従来のAIは学習段階で知識を固定し、推論時にはその知識をそのまま使用します。一方、TTAは推論時にもAIが自分自身を調整し、新しいデータに適応する能力を持ちます。これにより、予期しない状況でも性能を維持できます。
▶ TTAはどのような分野で活用されているの?
TTAは自動運転、医療診断、画像認識、自然言語処理など、環境の変化に対応する必要がある分野で活用されています。特に、リアルタイムでの適応が求められる分野で効果を発揮します。
▶ TTAの実装は難しいの?
TTAの基本的な実装は比較的シンプルで、多くの場合はバッチ正規化層のパラメータを調整するだけで済みます。ただし、効果的な適応を行うためには、データの特性やタスクに応じた最適化が必要です。本記事のコード例も参考にしてください。
▶ なぜBN層だけを更新するの?
BN層は「データの分布」を正規化する層です。新しい環境ではデータの分布が変わるので、ここだけ調整すれば効率的に適応できます。全体を更新するより安全で高速です。
▶ confidence_thresholdが低すぎるとどうなる?
AIが「よく分からない」予測でも学習してしまい、元の知識が壊れる(破滅的忘却)リスクが高まります。特に0.7未満は危険です。
▶ adaptation_stepsは多いほど良い?
多すぎると過学習や元知識の破壊リスクが増加します。通常は1-3回程度が適切で、5回以上は慎重に検討することが推奨されてます。
▶ 計算コストはどの程度増加する?
通常の推論に比べて1.5-3倍程度の計算時間が必要です。ただし、更新するパラメータが限定的なため、フルファインチューニングより大幅に軽量です。
まとめ:TTAでAIはなぜ強くなる?
2025年の実践ポイントと将来展望
テストタイムアダプテーション(TTA)は、AIが事前に学習した知識を、予測不可能な現実世界の状況に「その場」で適応させるための重要な技術です。
しかし、その本質は単なるドメインシフトへの「やむを得ない対処法」ではありません。TTAは、AIが静的な知識の集合体から、動的に環境と相互作用する「生きた知能」へと進化するための、必然的なステップなのです。
- 「より賢いAI」への進化:
TTAは、AIの弱点を補う苦肉の策ではなく、知能の本質である「適応性」と「汎化性」を深めるための積極的な進化です。 - スケール則の限界を超える鍵:
ARCベンチマークが示すように、事前学習の規模だけでは到達できない「真の思考力」を獲得するためには、推論時に適応する能力が不可欠です。 - 未来のAIのかたち:
これからのAIは、大規模な「事前学習」と、リアルタイムの「推論時適応」を組み合わせたハイブリッドモデルとして進化していくでしょう。
TTAの進化は、AIが単なるツールから、より汎用的な「応用力」を持つ存在へと発展し、広範な分野で社会に貢献する可能性を広げています。
TTAの将来展望と最新動向
2025年7月現在、TTAは単なるドメインシフト対応技術に留まらず、さらに広範な応用に向けて進化を続けています。
- 連続学習(Continual Learning)との融合:
一度適応した後も、次々と現れる新しい環境に継続的に適応し続ける研究が進んでいます。これにより、AIは長期的に性能を維持・向上できるようになります。 - マルチモーダル対応:
従来は画像認識が中心でしたが、画像、テキスト、音声といった複数の異なる種類のデータを統合し、それら全てに同時に適応するTTAシステムの研究が活発化しています。 - エッジデバイスへの最適化:
スマートフォンやIoTデバイスといった計算資源の限られた環境でも、軽量かつ高速に動作するTTAの実装が進められており、より多くのアプリケーションでの活用が期待されます。
更新履歴
- Ver. 1.0 初版公開
主な参考文献
【主要論文】
- Wang, D., et al. (2020). “Tent: Fully Test-time Adaptation by Entropy Minimization.” ICLR 2021.
- Sun, Y., et al. (2020). “Test-time training with self-supervision for generalization under distribution shifts.” ICML 2020.
- Liang, J., et al. (2020). “Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation.” ICML 2020.
【サーベイ論文】
- Schneider, S., et al. (2020). “Improving Robustness Against Common Corruptions by Covariate Shift Adaptation.” NeurIPS 2020.
【基礎・関連技術】
【最新トレンド・実践】
以上








