


※本記事は継続的に「最新情報にアップデート、読者支援機能の強化」を実施しています(履歴は末尾参照)。
【CES2026速報】ジェンスン・フアン基調講演|物理AIとVera Rubinが定義する産業の再設定
この記事を読むと、CES 2026で提示されたNVIDIAの包括的戦略について「何が産業のルールを変え、どの技術が自社のロードマップに直結するか」が整理でき、インフラ投資とAI実装の最初の一手を決めるための羅針盤を得られます。
超要約:
これは「馬車から車」への変化ではなく、道路、燃料、運転手、そして都市構造そのものが一斉に作り変えられる、コンピューティング産業全体の「再設定(Reset)」です。
講演の主旨:
- コンピューティング産業全体の「再設定(Reset)」:AIアプリへの移行と計算基盤の再発明が同時に発生。5層構造(5-layer cake)の全レイヤーが再設定される産業史上稀に見る全方位的な再発明である。
- Vera Rubinによる物理限界の突破:6つの主要コンポーネントを同時に再設計する「Extreme Co-design」により、Blackwell比で推論トークンコストを最大1/10に、またMoE学習で必要なGPU数を1/4にできる。
- 「物理AI」による新産業革命:工場を「巨大なロボット」と定義。Cosmosによる物理法則に基づいた合成データ生成が、デジタルと物理世界の境界を消滅させ、全産業の「知能化」を加速させる。
- 一次情報: NVIDIA CES 2026 Special Address / Rubin Platform / Cosmos / Open Model Strategy / NVIDIA Alpamayo
- 確認日:
- 注記: 数値・固有名詞は公式発表を優先し、随時アップデートを実施。
この記事の構成:
- 産業全体の「再設定(Reset)」とスタック構造の全レイヤーにおける再発明の全貌
- AIが「回答」から「熟考し、道具を使い、物理世界で働く熟練労働者」へと変貌を遂げるプロセス
- オープンモデルの台頭がもたらす「民主化されたイノベーション」とNVIDIAの青写真戦略のメカニズム
- 知能に肉体を与える「フィジカルAI」と世界モデルCosmos、そして「工場=巨大ロボット」のパラダイム
- 物理法則の限界に挑む次世代基盤「Vera Rubin」の6つの技術革新とシステムレベルの再設計
- NVIDIAが描く「フルスタック・オープン・物理世界」という産業支配の三本の柱と戦略的結論
1. 巨大な再発明:コンピューティング産業全体の再設定(Reset)
.jpg)
「馬車から車へ」を超える、都市構造の一斉刷新
ジェンスン・フアンCEOのアナロジーを借りれば、道路、燃料、運転手、そして都市構造そのものが一斉に作り変えられる瞬間が今です。
CES 2026でジェンスン・フアンCEOは、AI時代の到来を単なる「新製品の発表」レベルの話ではなく コンピューティング産業全体の再設定(Reset)が始まったと語りました。
本稿は、(1)AIアプリ化(2)開発・実行基盤の再発明(3)物理世界への拡張、および(4)それを支えるVera Rubinの設計思想を整理し、NVIDIAがAI時代の産業インフラをいかにしてゼロから定義しようとしているのか、その戦略的ポジショニングを解き明かします。
1.1. 二つの同時多発的なプラットフォームシフト

ジェンスン・フアンCEOが指摘するように、今回は以下の2つのシフトが同時に起きており、コンピューティングスタック全体、すなわち彼が言うところの「5層のケーキ(five layer cake)」の全レイヤーが再発明されるという、巨大な変革が進行しています。
※)フアンCEOが「5層のケーキ」と呼ぶ構造は、チップ/インフラ/システムソフトウェア/基盤モデル/アプリケーションの5層を指します。
❶ AIアプリへの移行(AI上でのアプリケーション構築):
アプリケーション自体がAIの上に構築されるようになるシフトです。かつてモバイルOSが登場しその上で無数のアプリが生まれたのと同様の構造的変化が、AIという「基盤(プラットフォーム)」そのもので起きています。
そして、この“AIアプリ”の主戦場は、製造・医療・金融など現場の業務に深く入り込むバーティカルAI(業界特化AI)へと急速に移っていきます。
❷ コンピューティングの基礎の再発明(ソフトウェア開発・実行のパラダイムシフト):
ジェンスン・フアンCEOは、「コンピューティングの5層構造(5-layer cake)の全てのレイヤーが再発明されている」と述べています。
バーティカルAIでは、推論が“思考”へ移って計算量が増え、ロングテールと安全要件に耐えるデータ・検証が必要になり、低遅延・監査・更新まで運用がシステム化するため、従来の延長のスタックでは回らないからです。
1.2 ムーアの法則の終焉と「100倍の需要」への挑戦
コンピューティング業界が直面している最大の課題は、半導体物理の限界です 。これまで業界を牽引してきた「ムーアの法則」は限界に近づいており、トランジスタ数の増加は世代比で約1.6倍の線形的な伸びに留まっています 。
一方で、AIモデルのパラメータ数は毎年10倍、推論プロセスにおけるトークン生成量は毎年5倍という指数関数的なペースで増大しています 。
絶望的なギャップ:
- 半導体の進化:世代比 1.6倍(線形成長)
- AIの計算需要:毎年 10倍〜100倍(指数関数的成長)
この「1.6倍」と「100倍」の間に横たわる巨大なギャップを埋めるには、単一チップの改良だけでは到底追いつけません 。コンピューティングスタック全体、すなわち「5層のケーキ」の全レイヤーを同時に再設計する「エクストリーム・コデザイン」こそが、NVIDIAが導き出した唯一の回答なのです 。
1.3. ソフトウェア開発・実行方法の根本的な変化
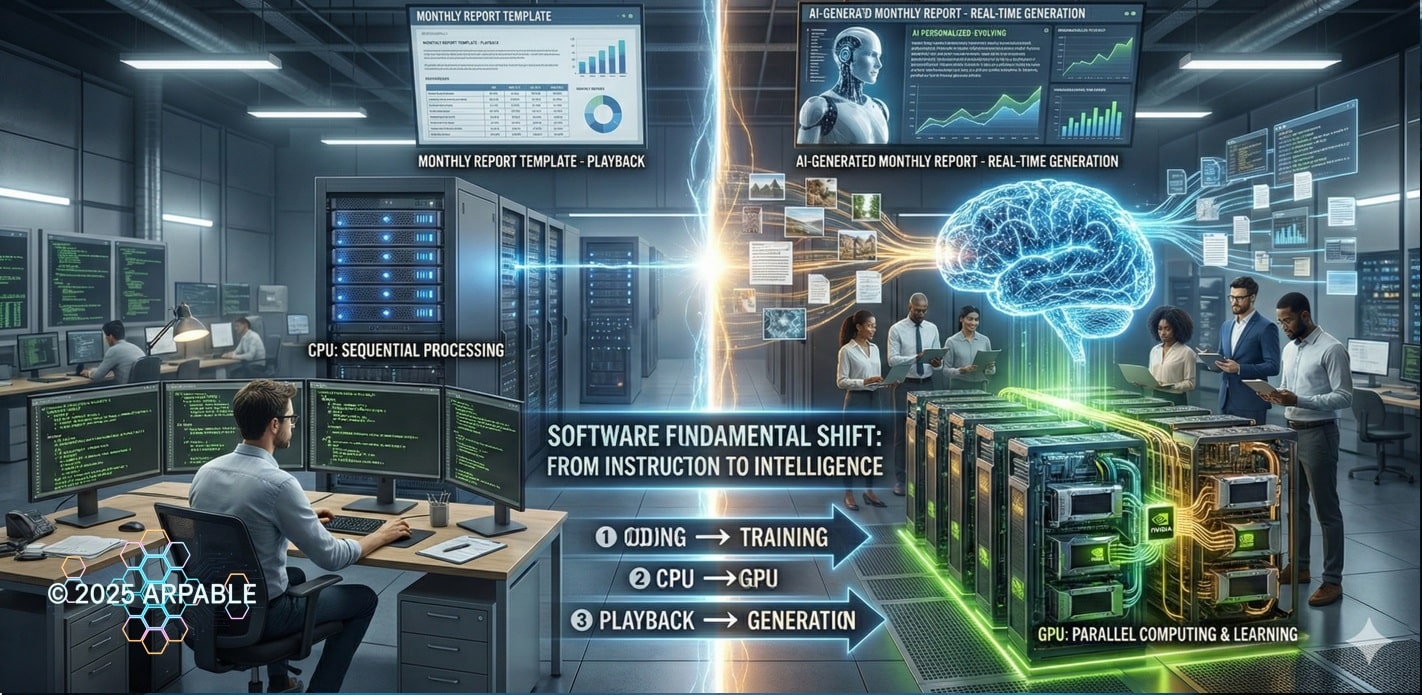
言い換えると、コンピュータは “命令を処理する機械” から “学習して考える工場” になりました。
❶ コーディング(プログラミング)からトレーニング(学習)へ:
これまでの価値は「正しい手順を書けること」でしたが、これからの価値は 「良いデータで、良い振る舞いを学習させられること」 です。
たとえば、不正検知なら「if文を積み上げる」のではなく、過去ログや取引文脈から“怪しさ”のパターンを学習させ、状況に応じて判断させます。
❷ CPUからGPUへ:
CPUは「少数の仕事を順番に速くこなす」のが得意ですが、AIは「膨大な計算を同時に回す」ことが中心になります。そこでAIの計算基盤の主役がCPUからGPU(並列計算)へ移行します。
たとえば、学習も推論も 大規模な行列演算を大量に回すため、CPUだけでは追いつかずGPUの並列性能が効いてきます。
❸ 再生(Playback)から生成(Generation)へ:
従来アプリは「決められた画面・決められた処理」を呼び出す“再生装置”でした。
一方AIは、文脈に合わせて 文章・コード・画像・手順そのものをその場で組み立てる“生成装置” です。
たとえば同じ「月次レポート」でも、AIは担当者の意図や社内ルール、最新データを踏まえて “その会社専用の答え”をその場で生成します。
つまり、ソフトウェアは「決め打ちの手順」から「学習した知能のふるまい」へ移り、実行基盤はCPU中心からGPU中心へ、従来のアプリは再生型から生成型へと置き換わっていきます。
1.4 10兆ドル規模のインフラ近代化
ジェンスン・フアンCEOが「約10兆ドル規模の近代化」と呼んだのは、世界中のデータセンターや企業ITが“AI前提”に作り直されるという話です。
さらに重要なのは、これは「IT更新」だけでなく、R&D予算そのものがAIへ傾くという資本配分の転換でもある点です。世界の研究開発費(R&D)は年間“数兆ドル規模”と言われ、その資金がAI手法へ急速に流れ込むことで、インフラ更新(CPU中心→GPU中心)まで連鎖的に加速します。
ポイントは、新しい予算が湧くのではなく、これまでCPU中心に投じられてきた既存の巨額投資が、GPU中心のAIインフラへと行き先を変えることにあります。R&Dも同様に、従来型の開発手法からAI手法へ比重が移り、結果としてインフラ更新の波が加速します。
だからこそNVIDIAの急成長は「偶然のブーム」などではなく、計算インフラという既存資産の大移動にうまく噛み合ったことが背景にあります。
2. AIモデルの進化:知識から推論、そしてエージェントシステムへ

「レシピ本」から「シェフ」へ、そして「現場で働くチーム」へ
初期のAIは「知識を答えるレシピ本」でした。
推論モデルは「答えの前に段取りを組むシェフ」になり、エージェントシステムは「道具・記憶・監視・評価まで束ねて、現場で成果を出す“実働チーム”」になります。
つまり、進化の軸は 知識(答える)→推論(考える)→行動(実行して改善する) です。
NVIDIAが示しているのは、モデル性能の伸びだけではありません。
AIが「知識を持つ存在」→「思考する存在」→「行動する存在」へ変貌するにつれ、アプリケーションの形も、必要なインフラも、運用の常識も一段ずつ作り替わっていく――という段階的な革命です。
この章の結論:
- 知識型:「覚えた範囲で答える」ため、未知や曖昧さで不確実になりやすい
- 推論型:「答える前に考える(多段の思考)」ことで、精度と信頼性を上げる
- エージェント型:「考える」だけでなく、道具を使い、計画し、実行し、結果を見て修正する
2.1. 「回答(Answer)」から「思考(Reasoning)」への進化
最大の転換点は、AIが質問に即答するだけの存在から、答える前に“手順を組んで考える”存在へ移行したことです。
言い換えると、AIは「それっぽい一発回答」ではなく、多段で検討しながら結論に到達する方向へ進化しています。
これは人間が難問に直面したとき、問題を分解し、仮説を立て、検証しながら一歩ずつ前に進むのと同じです。
「考える時間」を与えるほど賢くなる一方で、思考の途中経過(中間状態)や参照情報が増えるため、推論インフラ(文脈メモリ)の設計が決定的になります。
そしてこの“検証しながら進む”設計が、一発回答の弱点=ハルシネーションを実務で抑え込む鍵になります。
❶ 推論は「多段の問題解決」になります:
これからのAIは、単発のQ&Aよりも、長い文脈の中で処理→推論→行動を繰り返すことが中心になります。
たとえば「社内データを調べて根拠付きで提案する」「条件が変わったら結論を更新する」といった“仕事の流れ”そのものが対象になります。
❷ “考えるほどトークン(計算)が増える”問題が前面化します:
多段推論は賢さを引き上げる一方で、途中の思考や参照、やり直しで扱う情報量が増えます。
その結果、推論のボトルネックはモデルだけでなく、推論時の文脈(コンテキスト)をどう保持・共有するかに広がります。
❸ だから「推論向けインフラ」が要ります:
AIが“考える時間”を持つほど、推論時に生まれる中間状態(例:KVキャッシュ)の扱いが重要になります。
これを効率よく再利用・共有できるようにする発想が、エージェント時代のスケールの鍵になります。
- 実務で何が変わるか:「要約するAI」から、「根拠を集めて、比較して、結論を出し、必要ならやり直す AI」へ変わります。
- 経営/現場で効く点:“一発回答”の品質競争から、業務フロー全体(調査→判断→実行→監査)を回せるかが競争になります。
2.2. アプリケーションの定義:「エージェントシステム(Agentic Systems)」
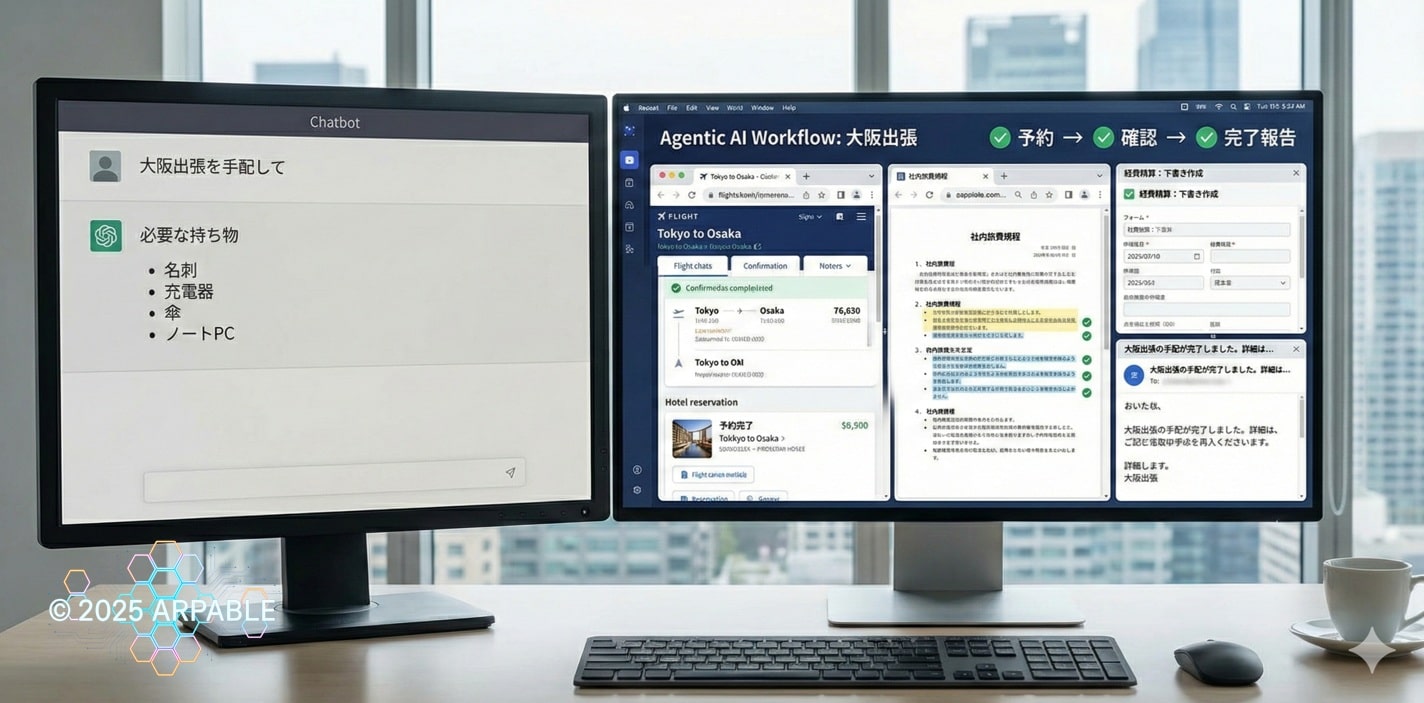
エージェントは、予約サイト・社内規程・経費精算などのツールや手順を横断し、予約→確認→完了報告まで実行します。
つまりエージェントは、「答える存在」ではなく 目的のために実行して完了させる存在です。
推論が多段化すると、AIは「モデル」ではなく“システム”として設計されます。
ここで言うエージェントシステムとは、単に自律っぽく振る舞うAIではなく、目的達成のための構成要素を束ねた実行基盤です。
直感的に言えば、シェフ(モデル)だけでは料理は出せません。
食材庫(データ)、調理器具(ツール)、衛生管理(ガバナンス)、タイムキーパー(スケジューラ)、味見(評価)が揃って初めて、安定して提供できます。
それが“アプリケーション”の新しい姿です。
- エージェントがインターフェースになります:
画面操作やコマンド入力ではなく、対話で「やりたいこと」を渡し、AIが裏側で段取りを回す形が主流になります。 - 未来のアプリは「組み合わせ」で動きます:
1つの巨大モデルですべてを解くのではなく、意図を理解するルーターが、専門モデル・検索・社内ツールを使い分けて成果を出します。

これらの中核能力は3つです。
❶推論:複雑な問題を解けるサイズに分解します。
❷ツール活用:検索、DB、業務SaaS、コード実行などを呼び出して外部能力を使います。
❸計画と修正:段取りを組み、結果を見てやり直し、品質を上げます。
そして、この「システム化」が進むほど、インフラ側は“推論の文脈を大規模に扱う”方向へ進化します。
つまり、AIの進化はモデル競争で終わらず、アプリ設計とインフラ設計を同時に塗り替えるところまで来ています。
エージェント時代のアプリは、“意図”に応じてモデルや実行場所を振り分けるのが基本形になります。
たとえば、機密を含む処理は手元(エッジ)のオープンモデルへ、重い分析はクラウドの巨大モデルへ――という具合に、最適な知能を自動で呼び分けます。
これが、今後のアプリ開発の「型」になります。
3. オープンモデルの台頭:産業革命を加速させる共同プラットフォーム
「開かれた知能」がもたらすイノベーションの民主化
ジェンスン・フアンCEOは、オープンモデルの台頭を、AIによる産業革命を世界中へ広げ、進化を爆発的に加速させるための「必須条件」として描いています。
NVIDIAの中核戦略は、自社を「フロンティアAIモデルビルダー」と位置づけ、モデルや参照実装をオープンに提供することで、業界の標準基盤を自社エコシステム側へ引き寄せる点にあります。
ここで重要なのは、「モデル(知能そのもの)」だけでなく、「使える形(参照実装)」までをセットで差し出すことです。
3.1. フロンティアへの「民主化されたアクセス」と独自性
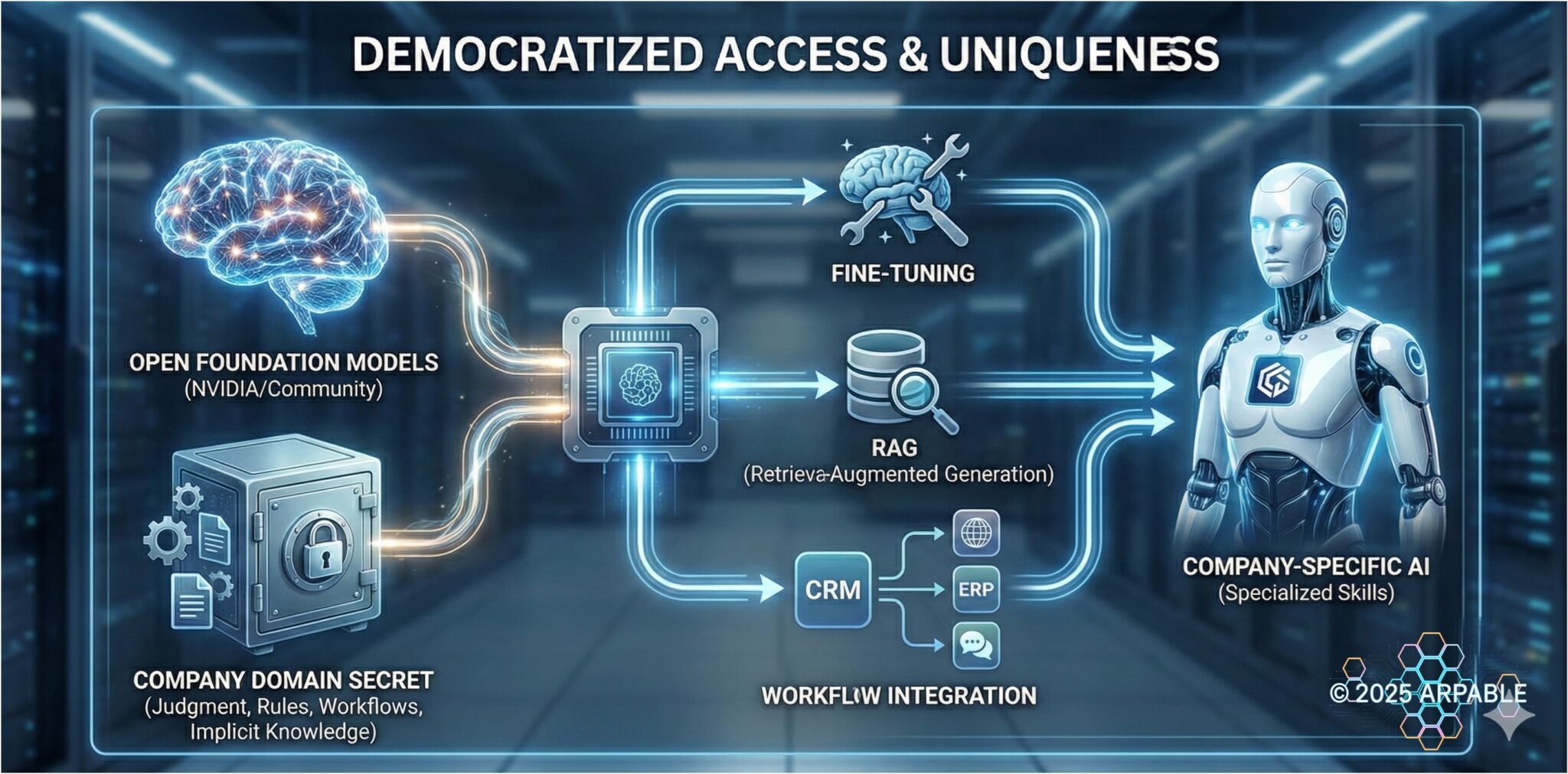
かつて最先端のAI能力は一部の巨大企業だけのものでしたが、状況は劇的に変化しました。
ジェンスン・フアンCEOが語った「新しいモデルが次々に出てくる」スピード感の通り、最先端の知能がオープン側にも降りてくるようになり、スタートアップから大企業、国家規模まで、誰もが“強い知能”を使える状態に近づいています。
ただし、勝負の軸は「モデルの入手」から「自社の現場知を注入して育てる」へ移ります。
ジェンスン・フアンCEOは、その“自社の現場知”を Domain Secret(ドメイン・シークレット) と呼んでいます。
オープンモデルを使う価値は、このDomain Secretを注入して、“自社だけのスキルを持つAI”に比較的容易に育てられる点にあります。
注入の方法は主に3つです。追加学習・微調整(ファインチューニング)、社内知識をつなぐRAG、そして業務ツール連携によるワークフロー化です。
これらを組み合わせることで、「汎用モデル」から「現場で勝てるモデル」へと変換できます。
3.2. NVIDIAのオープンモデル群:企業に効く「Nemotron」

冒頭で以下を明確にしておくと、以降の話がスムーズに入ります。
Nemotronは「3点セット」で理解すると速い
(A)中核LLM(Nemotron / Llama Nemotron)
文章生成・推論・コーディング・長文コンテキストなど、エージェント型アプリの“主役”になる基盤LLMです。
(B)RAG部品群(Nemotron RAG)
社内文書・DB・ログなどをつなぎ、検索→抽出→再ランキングなどを“部品”として整備し、RAG品質を上げやすくします。
(C)安全・ガードレール(Nemotron Safety)
逸脱・幻覚・不正な指示への耐性や、安全運用のための仕組みを含み、現場投入時のリスクを下げます。
Nemotronは、強いオープンモデルを土台にしつつ、NVIDIAが企業運用で破綻しにくい振る舞い(指示追従・有用性・安全性・評価)へ寄せて整備したモデル群です。
ここで重要なのは「土台モデルの入手」ではなく、土台+運用前提の整備があるからこそ、Domain Secretの注入で“現場仕様”に最短で到達できる点です。
オープンモデル時代の差は「モデルを入手できるか」ではなく、
業務に乗る形(RAG・評価・安全運用)まで整った土台を起点に、Domain Secret(企業独自データ)を注入して最短で“現場仕様”へ寄せられるかで決まります。
なぜ「Nemotron」が企業に効くのか
企業側は「強いLLMを手に入れた」だけでは成果に直結しません。
現場で必要なのは、①社内知識をつなぐRAG品質、②継続的に良くする評価の仕組み、③安全運用(ガードレール)、④自社要件に合わせた調整です。
Nemotronは、この“業務投入に必要な周辺”を同じ思想で揃えることで、PoCで終わらず運用に乗る距離を縮めます。
Nemotronが「Domain Secret注入」を速くする理由
Nemotronは「汎用モデルを配る」だけではなく、RAG・Safetyなどの周辺まで含めて最初から“運用の型”が揃っているため、企業はゼロから設計する負担を大きく減らせます。
その結果、差別化の作業は Domain Secret(判断基準・業務ルール・例外処理・暗黙知)を追加学習/RAG/ワークフロー連携で注入し、“現場で勝てる振る舞い”へ寄せることに集中できます。
NVIDIAが提供する「Nemotron 3点セット」(企業実装に必要な部品まで揃える)
Nemotronは「中核LLM」「RAG部品群」「Safety(ガードレール)」をセットで揃えることで、Domain Secretの注入と現場投入を速めます。
| 評価軸 | (A)中核LLM Nemotron / Llama Nemotron |
(B)RAG部品群 Nemotron RAG |
|---|---|---|
| ひとことで | 文章生成・推論・コーディングまで担う「主役の頭脳」 | 検索→抽出→再ランキングなど「社内知識を使える形にする部品」 |
| 何を解決する? | 汎用知能を“仕事で使えるLLM”として動かす | 社内文書・DB・ログをつないだ時の精度低下や不安定さを抑える |
| 企業で効く理由 | 「まず動く」基盤が手に入り、Domain Secret注入の土台になる | RAGで詰まりやすい工程が部品化され、品質改善ループを回しやすい |
| どこを自社で差別化? | 指示設計/追加学習/業務フローへの寄せ(現場の流儀) | 社内データ整備(鮮度・粒度・権限)/評価指標・再学習の回し方 |
| 代表的な使い方 | エージェントの中核モデル(対話→推論→計画→実行) | 社内ナレッジ接続(検索・根拠提示・再現性の担保) |
| (C)安全・ガードレール | Nemotron Safety:逸脱・幻覚・不正指示への耐性や安全運用の仕組みを含み、現場投入時のリスクを下げます。 ※ 監査・権限設計・社内ルール適合とセットで設計すると効果が出ます。 |
|
| 判定根拠 | Nemotronは「モデル名」ではなく、LLM(A)+RAG部品群(B)+Safety(C)をまとめて提供する発想がポイント。 そのため企業は、ゼロから周辺設計(RAG品質・評価・安全運用)を作り込む負担を減らし、Domain Secret注入に集中しやすくなります。 |
|
※ 表は「Nemotronを3点セット(A/B/C)で理解する」ための整理です。個別モデル名や提供範囲は一次情報の更新に合わせて追記・調整してください。
なぜNemotron 3は「効率」で差別化できるのか — KVキャッシュとSSMのハイブリッド

Nemotron 3は、従来のTransformerアーキテクチャとSSM(State Space Model、Mamba系)を組み合わせたハイブリッドMoE構造(Mixture of Experts)を採用しています。
Transformerは長い文脈を扱う際、過去のトークン情報をKVキャッシュとして保持するため、文脈が長くなるほどメモリ消費が線形に増大します。これは「毎日別の瓶にタレを保存する」ようなもので、過去の味を正確に取り出せる反面、棚(メモリ)がすぐに埋まります。
一方、SSM(State Space Model)は状態を固定サイズで圧縮して保持します。
つまり「秘伝のタレを一つの壺に継ぎ足す」ように、過去の情報は「溶け込んで」いるため、個別に取り出すことは難しくなりますが、場所(メモリ)を取りません。
つまり、「考える時間が増えるほどKVキャッシュが爆発する」問題に対し、Nemotron 3はアーキテクチャレベルで解を提示しています。これが「Nano/Super/Ultra」のスケーラビリティと、4倍のスループット向上を支える設計思想です。
3.3. NVIDIAの役割:「モデル × ブループリント × ツール」で“使える形”まで落とします

NVIDIAは「モデル(知能そのもの)」→「ブループリント(実装の型)」→「ツール(回し続ける仕組み)」までを3点セットで揃え、企業が現場投入に到達する距離を一気に縮めています。
ブループリントとは、モデルの配布ではなく、「データ準備 → 推論 → 評価 → 運用」までを一本の流れにした実装手順付きの参照ワークフローを指します。
ツールとして NeMo が運用の現実を支え、PoCで終わらず、現場で育て続けるための“仕組み”を提供します。
4. フィジカルAI:デジタル画面から飛び出し、物理世界と相互作用する知能

「マトリックス」のような仮想世界での修行
ロボットはいきなり現実で動くのではなく、仮想世界で過酷なシナリオを経験し、物理法則を体得してから現実へ実装されます。
ジェンスン・フアンCEOは、「フィジカルAI(Physical AI)」を「AI革命の次なる波」と位置づけています。知能(AI)に肉体を与え、産業全体をロボット化するプロセスが幕を開けました。
4.1. 核心的な課題:AIに「物理の常識」を教える
現在のAIは言葉を知っていますが、物理世界の「摩擦」「重力」「慣性」といった概念をゼロから学ばなければなりません。
本質はロングテールです。稀な事故・異常・例外ほど現実では集まりにくく、集めようとすると時間もコストも無限に膨らみます。
だからこそCosmos+シミュレーションで、現実では一生かかっても遭遇しないシナリオを仮想空間で大量に経験させ、「計算をデータに変える」ことが決定的な価値になります。
4.2. フィジカルAIを実現する「3つのコンピュータ」

NVIDIAはフィジカルAIの開発を支える3種類のコンピュータが重要だと説明しています。
- トレーニング用:ロボット基盤モデルを学習させるAIスーパーコンピュータ(NVIDIA DGX)。
- シミュレーション用:Omniverse上でデジタルツイン検証を回しつつ、Cosmosなどで合成データを生成します。
- 推論・実行用:現場で制御を回すオンボード計算機(Jetson AGX Thor)。
❶ NVIDIA DGX:大規模AI学習のための統合サーバ群。GPUと高速ネットワークを最適化し、基盤モデルやロボ学習を“短期間で回す”計算工場になる。
❷ Jetson AGX Thor:ロボや車載など現場側で推論を回す組込みAI計算機。低遅延でセンサー処理と制御を動かし、“その場で判断して動く”を支える。
4.2.1. Omniverse / Isaac Sim / Cosmos:ロボが現実に出る前に“仮想で鍛える”
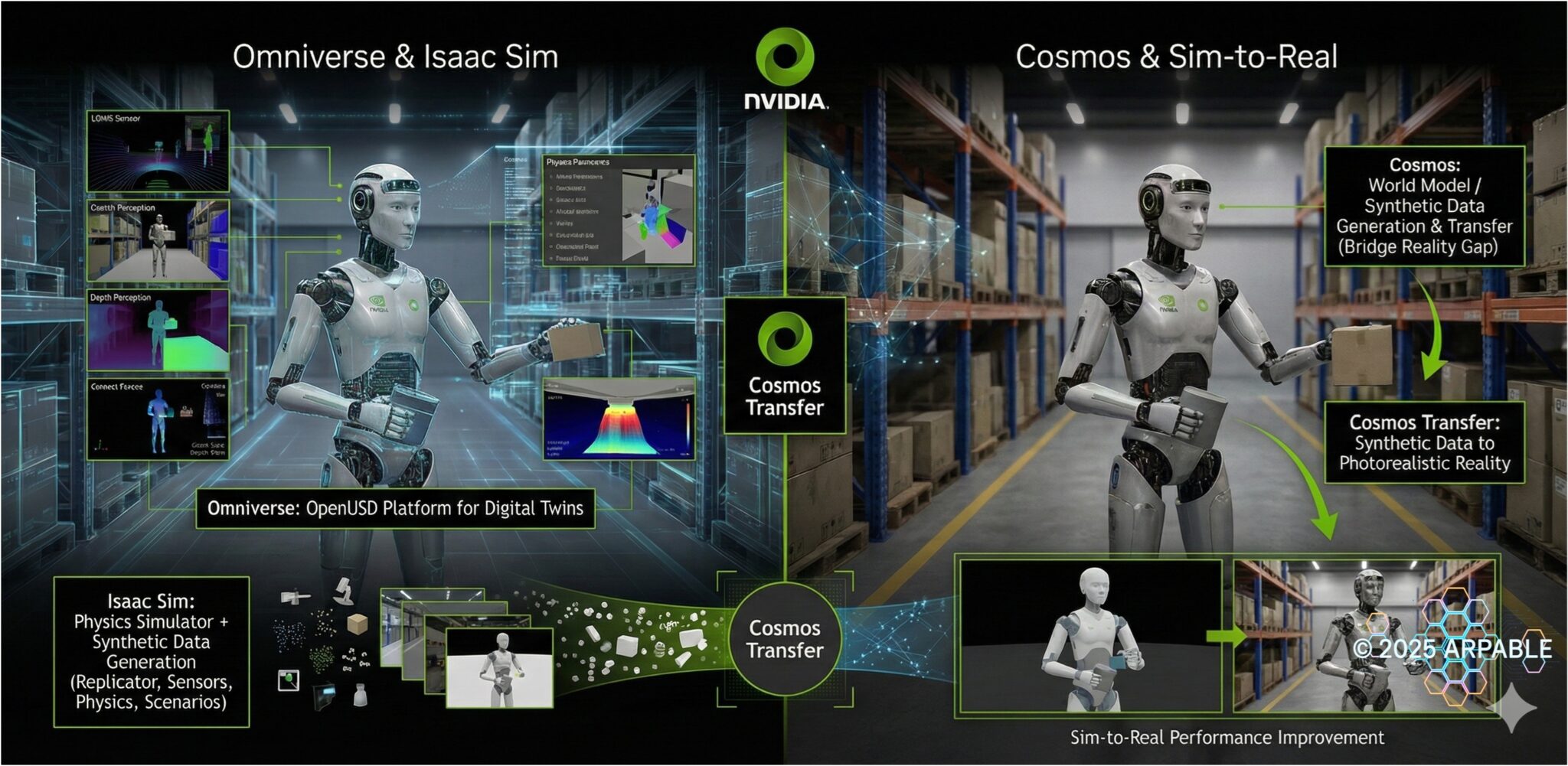
ポイント:NVIDIAは「ロボ開発の訓練場」を丸ごと用意している
- Omniverse:OpenUSDを核に、工場・倉庫・街などをデジタルツイン(3D世界)として作って運用する“土台(プラットフォーム)”。
- Isaac Sim:Omniverse上で動く、ロボティクス向けの物理シミュレータ+合成データ生成ツール(センサー、物理、シナリオ、Replicator等)。
- Cosmos:Physical AI向けの世界モデル/合成データ生成・変換(Transfer)などで、“現実データの不足やギャップ”を埋めにいく側。
sim-to-real:仮想で学んだ“動き”を現場で壊さない
ただし、シミュレーションで学習したポリシーをそのまま現場投入すると、現実との差(照明、摩耗、滑り、個体差、死角など)で破綻しがちです。そこで重要なのがsim-to-realです。
流れ:Omniverse × Isaac Sim × Cosmosで「現実投入の確度」を上げる
- ①(再現) Isaac Simは、Omniverse上で現場に近い環境・ロボット・センサーを再現し(デジタルツイン)、検証の土台を作る。
- ②(量産) その上でReplicator等を使い、学習・評価に必要な大量の合成データを作って回せる。
- ③(ギャップ低減) さらにCosmos側が、合成データを“現実の見え方”に寄せる(Cosmos Transfer等)ことで、ドメインギャップを縮め、sim-to-real性能の改善を狙う。
- 環境ゆらぎ(ドメインランダム化):照明・材質・ノイズ・摩擦などを意図的に揺らし、現実のブレに強い動きを作る。
- 校正と段階導入:現場のセンサー/機体差を測定して補正し、まずは限定条件で運用→ログで改善を回す。
- 安全評価:失敗のパターンを仮想で潰し、現場ではガードレール(停止条件・監視)とセットで運用する。
つまり、ロボは「現場で学ぶ」のではなく、まず“仮想で修行”し、現実では壊れない形に仕上げてから働かせる──この開発様式が、フィジカルAI時代の標準になります。
4.3. 実装事例:Alpamayo
は、単なる反射的な操作プログラムではなく、高度な推論能力を備えた「思考する自動運転システム」.jpg)
さらに重要なのは、Alpamayoが「走れる」だけでなく、“なぜ今その判断をしたか”を人間に説明できる設計(Explainability)へ向かっている点です。これは安全性への確信を与えるだけでなく、運用者がシステム挙動を理解し改善できる「インサイト」となり、社会実装における信頼の源泉になります。
メルセデス・ベンツによる世界初の実装と安全性
この思考するAI「Alpamayo」を世界で初めて市販車に採用するのが、メルセデス・ベンツの次期CLAクラスです。これは単なる技術デモではなく、極めて高い安全性と商用基準をクリアした実用システムです。
- 世界最高の安全評価: Alpamayo技術を中核に据えたメルセデス・ベンツの次世代スタックは、NCAP(新車アセスメントプログラム)によって「世界で最も安全な車」と評価される水準に達しています。
- 二重のガードレール設計: 思考・推論を行う「ニューラルスタック」を、既存ルールを重視する「古典的AVスタック(例えば交通ルール等)」が常に見守る仕組みです。AIが未知の状況で迷っても、確実なシステムが即座にカバーし絶対的な安全を保ちます。最新の知能と伝統的な監視を組み合わせた「二重のガードレール」で命を守る設計です。
ジェンスン・フアンCEOは、この「思考する脳」を搭載した車両のグローバルな展開ロードマップについても明確に言及しました。
2026年 Alpamayo搭載車両 グローバル展開スケジュール:
- 第1四半期 (Q1): 米国市場でのローンチ(サンフランシスコ等でのデモ走行の実装)
- 第2四半期 (Q2): 欧州市場への展開開始
- 第3・第4四半期 (Q3-Q4): アジア市場(日本を含むグローバル展開の加速)
この自動運転で培われた「推論・説明・安全監視」の仕組みは、そのまま人型ロボットや産業オートメーションへと応用可能な「物理AIの共通基盤」となります。
NVIDIAはこのAlpamayoをオープンソースとしても提供することで、Tesla等の垂直統合モデルに対抗する「オープンな自動運転エコシステム」の構築を狙っています。
4.4. 産業の再発明:「工場=巨大なロボット」

工場を「設備の集合」ではなく、“1つの意思決定する機械”として見る
ジェンスン・フアンCEOが言う「工場は本質的に巨大なロボット」とは、工場をロボットアームの寄せ集めとしてではなく、センサーで状況を読み取り、最適な段取りを考え、現場を動かし続ける“1つのシステム”として捉え直す、という意味です。
たとえば工場では、設備の状態、材料の遅延、人員の空き、品質のばらつき、電力制約などが同時に起こり続けます。
ここに必要なのは、単発の自動化ではなく、「見て(認識)→考えて(計画)→動かして(実行)→学んで(改善)」を回し続ける仕組みです。
これを工場全体でやる──それが「巨大なロボット」という再定義です。
高コストな手戻りを、仮想空間で先に潰してから現実に反映する
ここで登場するのが、デジタルツイン(現実の工場を仮想空間に再現したモデル)です。
工場を建ててから調整するのではなく、先に仮想空間で工場を建て、動かし、詰まる箇所を潰してから現実に反映する。これにより、立ち上げ期間と手戻りコストを大幅に削減できます。
バーティカルAIの拡張:製造だけで終わらない
ここまでの話は工場で最も分かりやすく見えますが、本質はもっと広いです。
物理AIとエージェントAIの波は、製造業に限らず、「物理的な価値を生む現場」全体に波及します。つまり、現実世界の制約(時間・安全・規制・品質・遅延)を背負ったAIが主役になる、ということです。
❶ デジタル生物学:研究を「エージェント化」する(NVIDIA Clara)
創薬や医療は、試行錯誤が高コストでサイクルが長いのが課題です。ここで重要なのは、AIが「答える」だけでなく、候補探索→評価→実験案→結果反映の流れを段取りとして回す(エージェント化する)点です。
ポイント:NVIDIAは「研究を回すための部品セット」を提供
NVIDIA Claraは、医療・ライフサイエンス向けのオープンなAI基盤(モデル/ツール/レシピ)群として整備されています。
企業・研究機関は、ここにDomain Secret(評価基準・手順・品質基準など)を足して、現場仕様へ寄せていけます。
❷ 自律型物流:状況が変わっても“回し続ける”最適化(NVIDIA cuOpt)
物流の本質は「最初の計画」よりも、渋滞・欠品・需要変動などに合わせて計画を更新し続けることです。エージェントが価値を出すのは、状況→制約更新→再計画→実行のループを回せるときです。
ポイント:cuOptが「再計画」を現実的な速度にする
NVIDIA cuOptは、配送ルートやスケジューリングなどの意思決定最適化(Decision Optimization)をGPUで高速化し、
変化に追随する再最適化を実運用に載せやすくします。
※「Clara」「cuOpt」は頭字語の“フルスペル”というより、NVIDIAの製品/スイート名として使われることが多い名称です。
NVIDIAは、デジタル空間の知能を、あらゆる「物理的な価値創造の現場」へと解き放とうとしているのです。
5. すべてを支えるエンジン:Vera Rubin コンピューティングプラットフォーム
物理限界を突破する統合プラットフォーム
爆発する計算需要を、チップ単体ではなくシステム全体の「極限の協調設計」で突破します。
Vera Rubinは、GPUという“エンジン”だけを速くする話ではありません。
F1カーのように、エンジン(GPU)・シャーシ(CPU)・空力(ネットワーク)・補給線(メモリ/ストレージ)を同時に最適化しないと、最高速は出ません。
それをシステム全体でやり切る思想が、Extreme Co-design(エクストリーム・コデザイン)です。
AIの処理が「回答」から「思考プロセス(Test Time Scaling)」へと進化したことで、生成トークン数は毎年5倍に増大、モデルサイズは毎年10倍になっています。
この物理的な壁を突破するため、NVIDIAは6つの主要コンポーネントを同時に再設計しました。その結果、Blackwell比で推論トークンコストを最大1/10に、またMoE学習で必要なGPU数を1/4に削減する圧倒的な経済性を実現したそうです。
5.1. Vera Rubinプラットフォームを構成する主要コンポーネント

各コンポーネントは、システム全体のデータフローを最大化するために共同設計されています。
- Vera CPU:
サーバの司令塔です。タスク配分とデータ供給を最適化し、GPUが待たされる時間を減らします。 - Rubin GPU:
AI計算の主役です。推論・学習の行列計算を担い、HBM(近接メモリ)の高帯域で“メモリの壁”を押し広げます。 - BlueField-4 DPU: 推論時に増える文脈データ(KVキャッシュ等)の入出力とデータ移動を最適化し、GPUが待たされる時間を減らします。結果として、長文脈・多段推論のスループットを押し上げる役割を担います。
- ConnectX-9 SuperNIC:
大規模クラスタのデータ移動を支える高速ネットワークです。低遅延通信で分散推論・分散学習の効率を上げます。 - NVLink 6 Switch:
GPU同士を高帯域で直結する“内部の大動脈”です。多数GPUを一体として扱えるようにし、巨大モデルを回しやすくします。 - Spectrum-X:
クラスタ全体をつなぐ“外部の幹線”です。スケールアウト通信の効率を上げ、電力あたりの性能を底上げします。
5.2. 推論の「作業机」:HBM・KVキャッシュ・外部メモリの関係
推論が「一発回答」から「多段で考える(Thinking)」へ移ると、ボトルネックはモデル性能だけでなく、“途中の思考や文脈(KVキャッシュ)をどこに置くか”に広がります。
ここを直感的に理解するために、メモリを「作業机」として捉えます。

ポイントは3つです。
- 近いメモリほど速いが小さい:
GPUのオンチップキャッシュやHBMは高速ですが容量に限りがあります。
推論が長くなるほど、途中の文脈(KVキャッシュ)が膨らみ、机が埋まりやすくなります。 - 文脈が膨らむと「机の渋滞」が起きる:
多段推論・長文脈・エージェント(検索→検証→再推論)では、同じGPUでも
“計算する時間”より“文脈を保持する都合”で詰まりやすくなります。 - だから外部の「共有メモリ(コンテキスト置き場)」が効く:
Rubin世代が示しているのは、HBMだけで全てを抱え込むのではなく、
外部に大容量の文脈置き場を作り、必要な文脈を高速に出し入れしてスループットを保つ発想です。
前節で解説したBlueField-4や高速NICは、この“出し入れ”を現実的にします。
推論が多段化すると、計算だけでなく「文脈(KVキャッシュ)の置き場と再利用」がボトルネックになり、Rubinはそれをシステム設計で解きにいくわけです。
5.3. 物理的な再発明:温水冷却と高密度化
.jpg)
図:NVIDIAのダイレクト・チップ冷却と通常の液浸との比較
註)これらは理解を助けるためのイメージ図で実際のものとは異なります。
ジェンスン・フアンCEOは基調講演で、Vera Rubin世代を「1ラックあたり220兆個のトランジスタ」という驚異的なスケールで提示しました。しかし、真の革新はその運用効率にあります。
❶ 冷却の革新(45℃温水運用):
45℃の温水でも稼働可能なダイレクト・チップ液冷をシステムレベルで統合しました。これにより、データセンターに不可欠だった巨大な冷却装置(チラー)を減らすことが可能になり、データセンター全体の電力に対して約6%の節電を実現します。これは「性能」の向上だけでなく、同じ電力枠内での収益性を押し上げる、経営直結の設計思想です。
❷ 物理的構造の刷新:
計算トレイは完全にケーブルレス設計へと刷新されました。これにより、ラックの組み立てや保守作業を最大18倍高速化。物理的な手戻りコストを排除しています。
❸ ビジネス上のインパクト:
ワットあたりの性能がBlackwell比で10倍向上したことにより、データセンターの投資対効果(ROI)は劇的に改善されます。推論コストが1/10になることで、これまでコスト面で見送られてきた高度なエージェントAIの全社導入が現実的な選択肢となります。
6. 戦略的結論:NVIDIAが描く産業の未来
本章は、CES 2026の要点を「3本柱」に圧縮して結論化します。
NVIDIAのビジョンは、AIを社会の隅々まで行き渡らせるための、包括的かつ緻密に設計された産業戦略そのものです。
ムーアの法則の終焉という課題に対し、コンピューティングの再発明から物理世界との融合、次世代インフラに至るまで、AIが社会インフラとなる未来への体系的なロードマップが示されました。
NVIDIA戦略の三つの柱
- フルスタック・プラットフォーム: シリコンから基盤モデル、ライブラリまで垂直統合し、AI開発の全レイヤーで主導権を握る。
- オープン・エコシステムによる支配: 最先端モデルをオープン化し、プレイヤーを自社プラットフォームに引き込み、事実上の標準(デファクトスタンダード)を支配する。
- 物理世界への拡張: AIをデジタル空間から物理的な産業世界へと飛躍的に拡大させ、未来のコンピューティングと産業インフラを定義する。
専門用語まとめ
- Vera Rubin
- NVIDIAの2026年次世代AIインフラ。垂直統合設計(Extreme Co-design)により推論コストを1/10に削減する「知能の工場」。
- 再設定(Reset)
- ソフトウェアの作り方から実行、適用範囲までが同時に書き換わるコンピューティング産業全体の再発明プロセス。
- Test Time Scaling
- 回答前に「思考プロセス」を実行する手法。AIの嘘(ハルシネーション)を実務で抑え込む鍵となるが、計算需要を増大させる。
- フィジカルAI (Physical AI)
- 物理法則を理解し現実世界と相互作用する知能。デジタル空間(Omniverse)でのシミュレーションを経て現実へ実装される。
- Cosmos
- NVIDIAの世界基盤モデル。物理的に正しい合成映像データを生成し、AIに「修行」をさせるための世界モデルプラットフォーム。
- エージェンティック・システム
- 自律的に計画・行動するAI。推論、ツール活用、計画、修正のサイクルを自ら回す、次世代アプリケーションの標準的な「型」。
- Extreme Co-design
- チップから冷却、ネットワーク、ストレージまで、スタック全体を一斉に再設計し、物理的限界を突破するNVIDIAの設計思想。
よくある質問(FAQ)
Q1. コンピューティングの「5層構造」の再発明とは何を指しますか?
A1. [cite_start]チップ、インフラ、システムソフトウェア、基盤モデル、アプリケーションの全層が、AI前提でゼロから作り変えられることを指します。 [cite: 1]
Q2. オープンモデルを自社運用する際、データ漏洩のリスクはありますか?
A2. いいえ。NVIDIA NIM等を利用し、エッジや自社クラウド環境での完全なプライベート運用が可能になるため、機密情報(Domain Secret)を保持したままの活用が最大の利点です。
Q3. なぜNVIDIAはモデルを無料でオープンにするのですか?
A3. 自社ツールやアーキテクチャを標準化させることでハードウェア需要を最大化する戦略です。エコシステム全体を支配し、参入障壁を強固にする狙いがあります。
まとめ(終章)

CES 2026でジェンスン・フアンCEOが提示したのは、コンピューティング産業全体の「再設定(Reset)」です。AIが「レシピ本からシェフ」へ進化し、「物理法則を体得して現実世界へ進出する」この変革は、全産業インフラを一斉に刷新する巨大な潮流です。
NVIDIAは、この変革を支える基礎(物理法則・知能)をオープンな青写真として提供し、世界中の産業がその上に応用を築く、人類史上最大の共同作業プラットフォームを完成させました。
今日のお持ち帰り3ポイント
- AIは「知識」から「思考」へ進化し、その需要を支えるVera Rubinインフラが全産業近代化の生命線となる。
- オープンソースは産業革命の「必須条件」であり、NVIDIAの青写真の上に各産業が専門知能(Domain Secret)を築く時代が到来した。
- コンピューティング産業は「再設定(Reset)」され、インフラから産業全体がAI仕様へと一斉に刷新されている。
工場、都市、家庭のロボットが自ら推論し行動するようになったとき、私たちの社会や働き方、そして人間の役割はどう変わるのか――。
その“答え”を決めるのは、モデルではなく、あなたのDomain Secretと、実装・運用の設計です。
主な参考サイト
※本稿の主要主張(Reset / Rubin / Cosmos / Open Model)は以下の一次情報から検証できます。
- NVIDIA CES 2026 Special Address リプレイ
- NVIDIA Newsroom: Rubin Platform Announcement
- NVIDIA Alpamayo: Reasoning AV Development
- NVIDIA Cosmos: World Models for Physical AI
- NVIDIA Open Model Strategy and Blueprint
合わせて読みたい
更新履歴
- 初版公開








