


この記事を読むと自己進化型AIの仕組みや将来性がわかり、技術トレンドやビジネスへの影響を多角的に理解できるようになります。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
自己進化型AIとは何か?ChatGPTの次に来る知性の形
本章では、自己進化型AIの基本的な定義を解説します。人間の介入なしに自らの性能を自律的に改善する能力を持ち、従来のAIとは一線を画す「自己改善能力」が最大の特徴です。ChatGPTの次に来るのは、自ら学び、自ら進化するAIなのです。
自己進化型AI(Self-improving AI)は、人工知能(AI)の中でも特に注目される分野です。これは、人間の直接的な介入なしに、自身のプログラム、アルゴリズム、さらには学習能力そのものを継続的に改善できる、次世代のAIシステムを指します。従来のAIの多くは、人間の開発者による更新や改善に依存しています。しかし、自己進化型AIは、AIが自らの性能を客観的に分析・評価します。そして、弱点を特定して自律的に改良を加える「自己改善能力」を持つ点が異なります。
この能力は、人間が持つ「メタ認知」(自分の思考や学習プロセスについて考える能力)に似ています。そのため、AIはより効率的に学習し、未知の課題に適応できるようになります。さらに、人間が予期しないような革新的な解決策を生み出す可能性も秘めているのです。本記事では、この自己進化型AIの基本概念から仕組み、アーキテクチャ、応用、そして未来について、詳しく解説していきます。
自己進化型AIを駆動する4つのコア技術
本章では、自己進化型AIが自らを改善するための4つの主要な技術(メタ学習、構造の自動設計、自己プログラミング、自己評価)を解説します。これらの技術が連携し、AIが自律的に成長するサイクルを形成する仕組みを学びます。
自己進化型AIが自身を改善するためには、いくつかの主要な技術的アプローチがあります。そして、これらは互いに関連し合いながら、自己進化型AIの自律的な成長を支えています。
1. 学習方法の学習(メタ学習)
これは、「どのように学習すれば最も効果的か」をAI自身が学習する能力です。例えば、課題の種類やデータ特性に応じて、最適な学習戦略を見つけ出します。これにはアルゴリズムの選択やハイパーパラメータ調整などが含まれます。その結果、新しいタスクへの適応速度や学習効率が飛躍的に向上します。これは自己進化型AIの重要な要素の一つです。
2. AI構造の自動設計(ニューラルアーキテクチャ探索など)
これは、AIが自身のモデル構造やパラメータ設定をタスクの性能向上に向けて自動的に調整する能力を指します。内部構造とは、例えばニューラルネットワークの層の数、接続方法、ノード数などです。従来、この設計作業はAI専門家が試行錯誤して行っていました。しかし、自己進化型AIではアーキテクチャ設計を自動化します。これにより、より高性能なモデルを自律的に構築できるのです。
👨🏫 かみ砕きポイント
ニューラルアーキテクチャ探索(Neural Architecture Search, NAS)とは、ニューラルネットワークの構造を自動的に設計する技術です。従来、ネットワークの設計は専門家が手動で行っていましたが、NASはこのプロセスを自動化し、最適な構造を見つけ出します。これにより、画像認識や自然言語処理などの分野で、人間が設計したモデルを上回る性能を持つネットワークが実現されています。NASは、探索空間、探索戦略、評価戦略の3つの要素で構成され、強化学習や進化的アルゴリズムなどの手法が用いられます。この技術は、機械学習の自動化(AutoML)の一環として、今後さらに重要性を増すと期待されています。
3. 自己プログラミング能力
これは、AIが自身のプログラムコードを分析し、問題解決のためにコードを書き換えたり、新しい機能を生成したりする能力です。近年は、自己改善コーディングエージェントの研究が進展し、ベンチマーク実験を通じて“自分自身のエージェント基盤コードを反復的に編集・改善”して性能を引き上げる手法が報告されています(例:Self-Improving Coding Agent / SICA はSWE-bench系タスクで反復改善の有効性を示す)[^sica]。また、AI×進化的探索で新しい最適化手法や訓練アルゴリズム自体を発見し、実システムの効率化に還元する取り組みも登場しています(例:AlphaEvolve)[^alphaevolve]。
一方で、自己編集の自由度が増すほど暴走防止や観測可能性(Observability)の設計が重要になります。研究では、アーカイブ管理・監視エージェント・安全制約などを組み合わせ、改善プロセスをトレース可能に保つ設計指針が提案されています[^sica].
| 項目 | メタ学習 | 自己プログラミング |
|---|---|---|
| 主な目的 | 学習方法そのものを最適化し、学習効率を高めること。 | AI自身がコードを直接書き換え、機能や構造を改善・拡張すること。 |
| 代表的な手法 | MAML, Reptile | AutoGPT, 進化的なアプローチ |
| 実行単位 | 学習フェーズごと | 自律的エージェント全体 |
| リスク・課題 | 過適合、収束が遅い場合がある | 動作の安定性確保、予期せぬ行動の制御 |
4. 継続的な自己評価とフィードバック
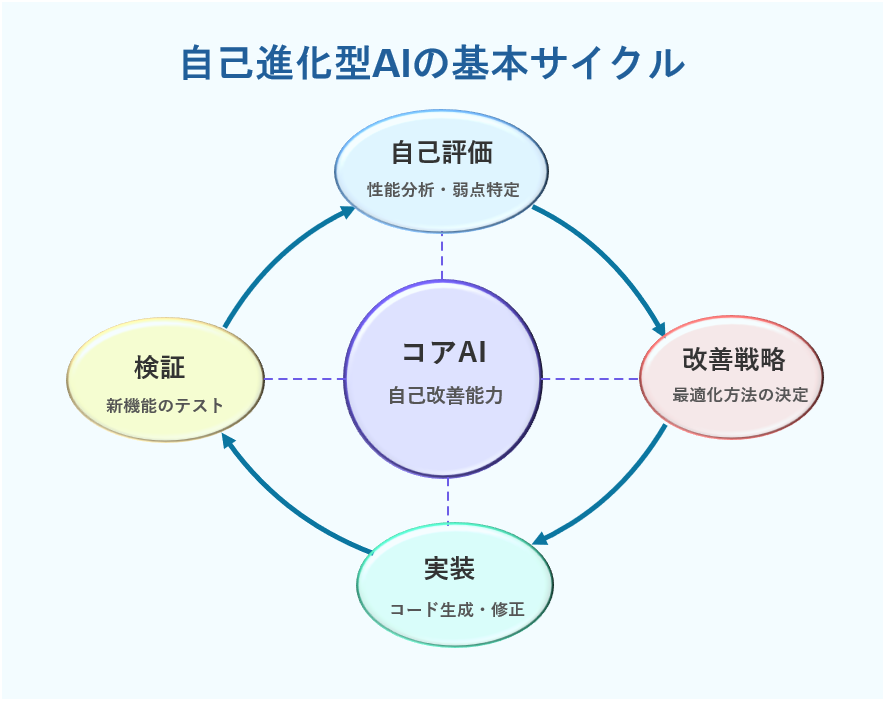
【図1の解説】
自身のパフォーマンス(精度、速度、効率など)を常にモニタリングすることが重要です。そして、設定された目標や基準と比較して評価します。弱点や改善点を特定し、それを次の改善サイクルにフィードバックします。これにより、継続的な進化が促されるのです。
この図は自己進化型AIの基本サイクルを示しています。中央にあるコアAIが起点となります。そして、「自己評価」→「改善戦略」→「実装」→「検証」→「自己評価」という継続的なフィードバックループが形成されます。このサイクルが自律的に繰り返されることで、人間の介入なしに自己進化型AIが自己改善を続けることができるのです。
Key Takeaways(持ち帰りポイント)
- 自己進化は主に4つの技術(メタ学習、構造設計、自己プログラミング、自己評価)で行われます。
- 「メタ学習」は学習方法そのものを学習し、進化の効率を高めます。
- 「ニューラルアーキテクチャ探索」はAIの構造自体をタスクに最適化します。
- 「自己評価とフィードバック」のループが、継続的な改善サイクルを駆動します。
自己進化型AI研究の最前線
本章では、自己参照や自己対戦、LLMによる自己評価など、AIの自己改善メカニズムをさらに高度化させる最先端の研究アプローチを5つ紹介します。これらの研究が、AIの自律性と効率性をどこまで高める可能性があるのかを探ります。
上記の基本的なアプローチに加えて、自己進化型AIを実現するためのさらに高度な自己改善メカニズムの研究も進められています。
❶自己参照とメタ推論:
例えば、ゲーデルの不完全性定理に触発されたアプローチがあります。これは、AIが自身の論理的基盤や推論プロセス自体を対象として分析・改善する研究です。
❷自己対戦と強化学習:
また、AIエージェント同士を競わせたり協力させたりする方法も研究されています。これにより、より洗練された戦略や能力を獲得させるフレームワーク(例:AlphaGo)が生まれています。さらに、評価基準自体もAIが生成・改善する試みも含まれます。
❸LLMによる自己評価・改善:
大規模言語モデル(LLM)が自身の生成した出力の品質を評価することも可能です。そして、そのフィードバックに基づいてプロンプトや内部モデルを改善する研究(例:LLM-as-Judge)が行われています。
❹記号的推論と統計的学習の融合:
プログラム合成のような記号的なアプローチと、深層学習ような統計的なアプローチを組み合わせる研究もあります。これらは、より汎用的でデータ効率の良い学習・自己改善能力を目指しています。
➎生涯学習と忘却抑制:
新しい知識を学習する際、過去の知識を忘れてしまう「壊滅的忘却」という問題があります。これを防ぎながら継続的に能力を向上させる技術(例:Progressive Neural Networks)も重要です。
これらの研究は、自己進化型AIがより自律的かつ効率的に進化していく可能性を示唆しています。場合によっては、人間が予期しない方法での進化もあり得るでしょう。
2025年の自己進化型AI:注目のブレイクスルー3選
本章では、2025年に公表された自己改善・自己進化の重要成果を、一次情報に基づき簡潔に整理します。
❶ Self-Improving Coding Agent(ICLR 2025 Workshop)
エージェントが自らのコード基盤を反復編集→評価→採択で改善する手法。SWE-bench系課題などで反復改善の有効性を示し、アーカイブ管理や監視エージェントによる安全策も議論されています。[^sica]
❷ Google DeepMind「AlphaEvolve」(2025年5月)
AI×進化的探索で新しいアルゴリズムや設定を継続的に発見し、社内の複数ユースケース(モデル訓練効率、クラスタ・スケジューリング等)に還元。“継続的に良いものを見つけ続ける仕組み”として自己進化の実運用像を提示。[^alphaevolve]
❸ 「経験の時代(Era of Experience)」の提唱(2025年6月)
Sutton氏・Silver氏が“静的データ依存から、経験駆動の自己改善へ”というパラダイム転換を論じ、エージェントが環境と相互作用して成長する方向性を明確化。自己進化・自己改善の理論的背景として重要。
自己進化型AIの構成要素|進化モジュールと評価ループとは?
本章では、自己進化型AIシステムの全体像をアーキテクチャ図と共に解説します。頭脳となる「コアAIエンジン」から、実行部隊である「コード生成モジュール」、学習方法を改善する「学習最適化モジュール」まで、各構成要素の役割を詳解します。
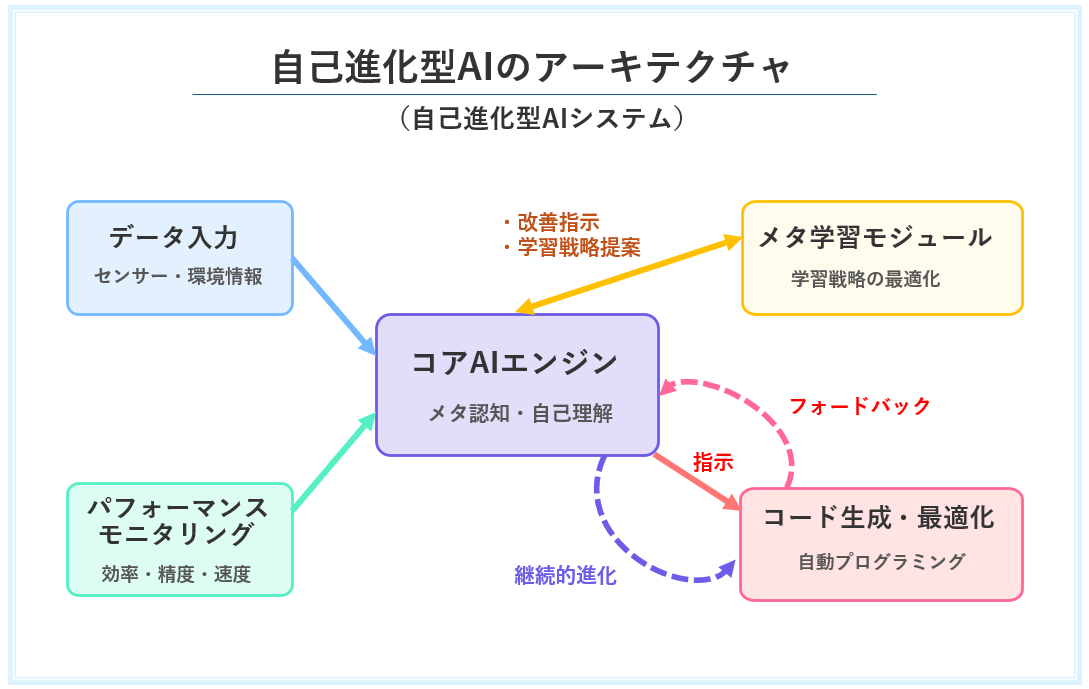
【図2の解説】
自己進化型AIシステムは、前述した様々な技術的アプローチを統合します。そのため、複雑なアーキテクチャを持つと考えられます。ここでは、自己進化型AIの一例となる構成要素を紹介します。
❶コアAIエンジン:
これはシステム全体の「脳」として機能します。主に、自己認識、自己評価、改善計画の立案、戦略決定などを担当します。具体的には、自身の状態や能力を把握します(メタ認知層)。そして、パフォーマンスを評価し(自己評価層)、改善策を計画・最適化します(計画最適化層)。最後に、実行する改善戦略を決定します(戦略決定層)。
❷コード生成・最適化モジュール:
次に、コアAIエンジンからの指示に基づき、実際のプログラムコード等を生成・修正する「実行部隊」があります。これは、自己プログラミング能力やAI構造の自動設計を担います。
❸学習最適化モジュール(メタ学習モジュール):
さらに、「学習の仕方」そのものを最適化する専門モジュールも重要です。データ収集戦略や学習アルゴリズム、ハイパーパラメータなどを改善します。これにより、AIの進化速度を加速させます。
❹フィードバック評価モジュール:
また、改善策の実行結果を分析・評価する「品質管理部門」も存在します。実行結果とは、例えば生成されたコードの性能や新しい学習戦略の効果などです。その評価結果はコアAIエンジンにフィードバックされ、継続的自己評価ループの重要な一部となります。
➎データ入力モジュール:
最後に、外部環境からの情報などを取り込む「感覚器官」が必要です。センサーデータやユーザーからのフィードバックも含まれます。これは、AIが自己評価や学習を行うために必要な情報を提供します。
👨🏫 かみ砕きポイント
この関係を理解するために、仮想的なAIシステムを例に考えてみましょう。以下は概念的な理解を助けるための例示であり、特定のシステムの実際の構造を表すものではありません。
- コアAIエンジンは、ユーザーの要求を理解し、全体の計画を立てる「思考プロセス」に相当します。
- コード生成・最適化モジュールは、計画に基づき成果物を作る「実行」部分に相当します。
- フィードバック評価モジュールは、出来上がった成果物の品質を判定する「品質判定」機能に相当します。
自己進化型AIにおける学習最適化モジュールの役割
学習最適化モジュール(メタ学習モジュール)は特殊な役割を持ちます。それは、「学習の仕方を学ぶ」能力を担当することです。具体的には、以下のような機能があります。
❶学習戦略の最適化:
例えば、どの種類のデータからより効果的に学習できるかを分析します。そして、学習速度や精度を向上させるパラメータを調整します。
❷効率的な知識獲得パターンの発見:
また、どのような順序で学習すると効率が良いかを発見します。具体的には、簡単な概念から複雑な概念へと学習を進める方法などです。
❸学習アルゴリズム自体の改良提案:
さらに、現在の学習方法の弱点を特定します。その上で、新しいアプローチを提案することもあります。
このように、この学習最適化は「点の改善」ではありません。むしろ、「改善方法自体の改善」を担当します。そのため、自己進化型AIの進化速度を加速させる重要な役割を持っているのです。
自己進化型AIが自分を評価して学ぶ仕組み
フィードバック評価モジュールは、自己進化型AIシステムの「品質管理部門」ような役割を果たします。具体的には、このモジュールは以下のタスクを実行します。
❶生成されたコードやアルゴリズムの実行結果を分析します。
❷効率性、正確性、速度などの観点から総合的に評価します。
❸改善すべき点を特定し、コアAIに報告します。
例えば、新しく生成されたコードが予想よりも処理速度が遅い場合があります。その場合、このモジュールはその原因を分析します。そして、次回の改善サイクルでの最適化ポイントとしてコアAIに伝えます。このようなフィードバックループによって、AIシステムは継続的に自己改善していくことができるのです。
一方で、データ入力モジュールは、AIが自身を改善するために必要な情報を取り込みます。環境情報やユーザーからのフィードバックなどがこれにあたります。このモジュールは「感覚器官」として機能し、パフォーマンスを客観的に評価するための基準を提供します。
自己進化型AIのプログラム実装(Pythonコード)
本章では、自己進化型AIの概念を具体的なPythonコードで示します。AIが自身の構造(アーキテクチャ)を過去の性能に基づいて変更していく、簡略化された自己改善ループを実装。コードを通じて、進化のプロセスを体験的に理解します。
自己進化型AIの概念をより具体的に理解するために、簡略的なPythonコード実装を紹介します。ただし、このコードは自己進化型AIの本質的なメカニズムを示す教育的な実装イメージです。実際のシステムはより複雑であることを理解しておきましょう。
# 事前準備: pip install -U scikit-learn numpy
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
np.random.seed(42) # 乱数の再現性(外すと世代ごとに変動します)
class SelfImprovingAI:
def __init__(self, max_layers: int = 3):
# 初期ネットワーク構造(隠れ層ユニット数のリスト)
self.current_architecture = [64]
# パフォーマンス履歴(各世代の val 精度とアーキテクチャを保持)
self.performance_history = []
# スケーラ(学習時に fit、評価/推論時に transform のみ)
self.scaler = StandardScaler()
# レイヤーの上限(デモ用に控えめ)
self.max_layers = max_layers
# 現在のモデル
self.model = self._create_model()
def _create_model(self) -> MLPClassifier:
"""現在のアーキテクチャで MLPClassifier を構築"""
return MLPClassifier(
hidden_layer_sizes=tuple(self.current_architecture),
max_iter=300,
random_state=42,
early_stopping=True, # 収束安定と過学習抑制
n_iter_no_change=10,
validation_fraction=0.1 # 内部 early stopping 用の検証割合
)
def train_and_evaluate(self, X_train, y_train, X_val, y_val) -> float:
"""学習して検証精度を返す(履歴にも保存)"""
# スケーリング(学習データで fit、検証は transform のみ)
X_train_scaled = self.scaler.fit_transform(X_train)
X_val_scaled = self.scaler.transform(X_val)
# 学習
self.model.fit(X_train_scaled, y_train)
# 検証セットで評価
y_pred = self.model.predict(X_val_scaled)
accuracy = accuracy_score(y_val, y_pred)
# 履歴へ保存
self.performance_history.append({
"architecture": self.current_architecture.copy(),
"accuracy": accuracy
})
return accuracy
def self_improve(self):
"""直近2回の性能を比較し、アーキテクチャを微調整"""
if len(self.performance_history) < 2:
# 初期は探索を進める(層を増やす)
if len(self.current_architecture) < self.max_layers: self.current_architecture.append(32) else: # 上限に達している場合はユニット数だけ増やす idx = np.random.randint(len(self.current_architecture)) self.current_architecture[idx] += 16 else: current_perf = self.performance_history[-1]["accuracy"] previous_perf = self.performance_history[-2]["accuracy"] if current_perf > previous_perf:
# 性能向上: 同方向で強化
if (np.random.random() > 0.5) and (len(self.current_architecture) < self.max_layers): # 新レイヤー追加 self.current_architecture.append(32) else: # 既存レイヤーのユニット数を増やす idx = np.random.randint(len(self.current_architecture)) self.current_architecture[idx] += 16 else: # 性能低下: 方向転換 if (len(self.current_architecture) > 1) and (np.random.random() > 0.5):
# レイヤー削減
self.current_architecture.pop()
else:
# ユニット数削減(下限 8)
idx = np.random.randint(len(self.current_architecture))
self.current_architecture[idx] = max(8, self.current_architecture[idx] - 16)
# 新アーキテクチャでモデルを再構築(重みはリセット)
self.model = self._create_model()
return self.current_architecture
def fit_on(self, X, y):
"""指定データで再学習(最終評価用など)"""
X_scaled = self.scaler.fit_transform(X)
self.model.fit(X_scaled, y)
def score_on(self, X, y) -> float:
"""指定データで精度評価(最終評価用など)"""
X_scaled = self.scaler.transform(X)
y_pred = self.model.predict(X_scaled)
return accuracy_score(y, y_pred)
# 使用例(デモ)
def demonstrate_self_improving_ai(generations: int = 5):
# 合成データを作成
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=12,
n_redundant=4,
class_sep=1.2,
random_state=42
)
# train/val/test = 60/20/20 に分割(val で進化判断、test は最後にのみ使用)
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=0.25, random_state=42, stratify=y_temp
)
# ここまでで: train 60%, val 20%, test 20%
ai = SelfImprovingAI()
print("=== 自己改善サイクル開始 (評価は常に validation) ===")
for g in range(generations):
acc = ai.train_and_evaluate(X_train, y_train, X_val, y_val)
print(f"世代 {g+1:>2}: アーキテクチャ {ai.current_architecture} | val精度 {acc:.4f}")
new_arch = ai.self_improve()
print(f" → 進化: 新アーキテクチャ {new_arch}")
# バリデーション最高のアーキテクチャを採択
best = max(ai.performance_history, key=lambda x: x['accuracy'])
best_arch = best['architecture']
print("\n=== 最良アーキテクチャで最終学習(train+val)→ test 評価 ===")
print(f"採択アーキテクチャ: {best_arch} | 最高val精度: {best['accuracy']:.4f}")
# 採択アーキテクチャでモデルを作り直し、train+val で学習して test を評価
ai.current_architecture = best_arch.copy()
ai.model = ai._create_model()
ai.fit_on(np.vstack([X_train, X_val]), np.hstack([y_train, y_val]))
test_acc = ai.score_on(X_test, y_test)
print(f"最終 test 精度: {test_acc:.4f}")
if __name__ == "__main__":
demonstrate_self_improving_ai(generations=5)
コードの詳細解説
import numpy as np from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification from sklearn.metrics import accuracy_score
【解説】 準備
❶ import numpy as np– 科学計算用の NumPy ライブラリを「np」という別名でインポートします。
❷ from sklearn.neural_network import MLPClassifier – 多層パーセプトロン分類器をインポートします。
❸ train_test_split
・機能: データセットを訓練セットとテストセットに分割する関数。
❹ make_classification
・機能: 分類問題用の合成データセットを生成する関数。
➎ accuracy_score
・機能: 分類モデルの予測精度を評価する関数。
1. 基本構造と初期化 (`__init__`)
def __init__(self):
# 初期ネットワーク構造
self.current_architecture = [64]
# パフォーマンス履歴の保存
self.performance_history = []
# 現在のモデル
self.model = self._create_model()
【解説】
この部分は自己進化型AIの「基盤」を形成する重要な初期設定です。AIの「記憶」であるパフォーマンス履歴を記録し、どの変更が良かったかを判断する材料とします。
2. モデルの訓練と評価 (`train_and_evaluate`)
def train_and_evaluate(self, X_train, y_train, X_val, y_val):
# モデルの訓練
self.model.fit(X_train, y_train)
# 検証セットでの性能評価
y_pred = self.model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
# 性能と現在のアーキテクチャを記録
self.performance_history.append({
'architecture': self.current_architecture.copy(),
'accuracy': accuracy
})
return accuracy
【解説】
この関数は、自己進化サイクルの「学習」と「自己評価」の段階を担当します。人間がテストで実力を測るように、AIも学習した内容を評価し、その結果を次の改善に活かすための履歴として記録します。
3. 自己改善メカニズム (`self_improve`)
この関数が自己進化の核心部分です。過去の性能に基づいてAIの構造を変更します。
def self_improve(self):
"""過去の性能に基づいてアーキテクチャを改善"""
if len(self.performance_history) < 2: # 初回は単純にノードを追加 self.current_architecture.append(32) else: # 過去2回分の性能比較 current_perf = self.performance_history[-1]['accuracy'] previous_perf = self.performance_history[-2]['accuracy'] if current_perf > previous_perf:
# 性能向上していれば同じ方向性で改善
if np.random.random() > 0.5 and len(self.current_architecture) < 3: # 新レイヤー追加 self.current_architecture.append(32) else: # 既存レイヤーのノード数増加 idx = np.random.randint(len(self.current_architecture)) self.current_architecture[idx] += 16 else: # 性能低下時は方向転換 if len(self.current_architecture) > 1 and np.random.random() > 0.5:
# レイヤー削減
self.current_architecture.pop()
else:
# ノード数削減
idx = np.random.randint(len(self.current_architecture))
self.current_architecture[idx] = max(8, self.current_architecture[idx] - 16)
# 新しいアーキテクチャでモデルを再構築
self.model = self._create_model()
return self.current_architecture
【解説】
ここが自己進化の心臓部です。直近の性能を過去と比較し、「改善したか」「悪化したか」を判断します。性能が向上していれば、その方向性(層を増やすなど)をさらに推し進め、逆に低下していれば、これまでとは違うアプローチ(層を減らすなど)を試みます。この試行錯誤のループが自己進化を実現します。
4. 実演部分 (`demonstrate_self_improving_ai`)
def demonstrate_self_improving_ai():
# (中略)
# 5世代にわたる自己改善サイクル
for generation in range(5):
# 訓練と評価
accuracy = ai.train_and_evaluate(X_train, y_train, X_test, y_test)
print(f"世代 {generation+1}: アーキテクチャ {ai.current_architecture}, 精度 {accuracy:.4f}")
# 自己改善
new_architecture = ai.self_improve()
print(f" → 進化: 新アーキテクチャ {new_architecture}")
# (中略)
【解説】
この関数は、自己進化型AIがどのように動作するかを実際に見せる「デモンストレーション」部分です。5世代にわたって「学習→評価→自己改善」のサイクルを繰り返し、AIが自らの構造を最適化していく様子を追跡します。
自己進化型AIが活躍する具体的なシーンとは?
本章では、自己進化型AIの応用分野を、科学研究、ソフトウェア開発、自動運転、ヘルスケアの4つの領域に分けて具体的に解説します。AlphaFoldの例などを交えながら、すでに実用化が始まっている最前線の活用事例を紹介します。
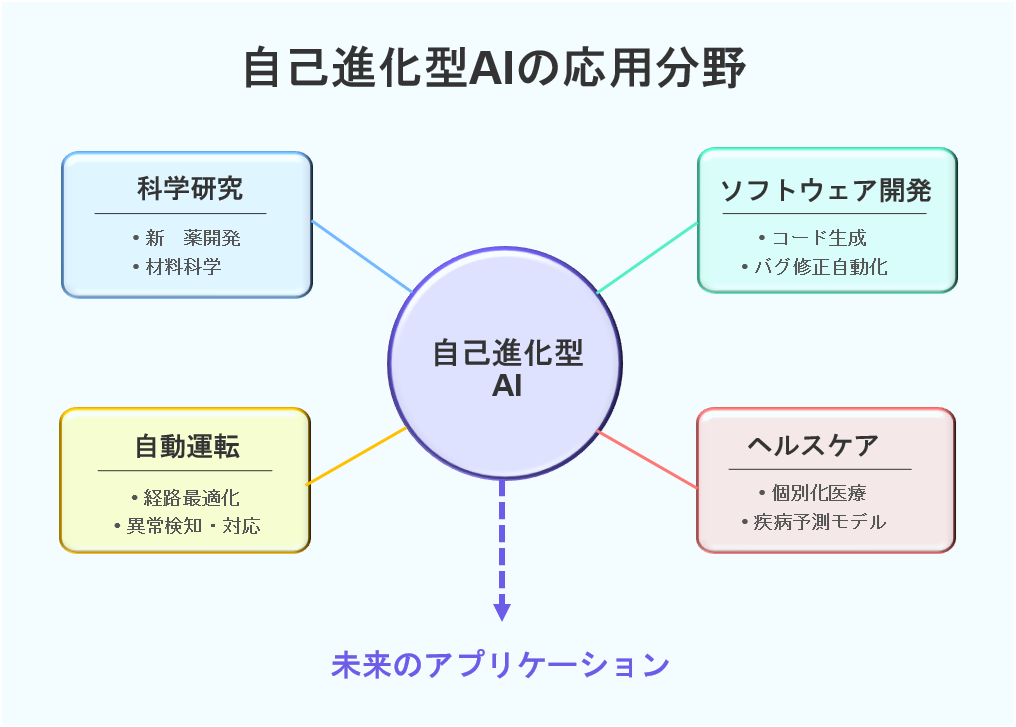
図3 自己進化型AIの応用分野
科学研究
例えば創薬や材料科学では、自己進化型AIが“どの実験を次に行うべきか”を自己評価で更新する循環的プロセスが導入され始めています。
重要: AlphaFold は自己進化AIそのものではなく、極めて高精度な構造予測ツールです。その予測結果を入力として、上位の自己進化システム(実験計画・探索最適化)が方策を自動更新することで、候補探索の速度と確度が向上します。AlphaFold/AlphaFold-Multimerを用いた大規模スクリーニングから新規相互作用候補を導く研究報告は国内外に複数あり、大阪大学などの研究チームも、予測結果を活用した大規模スクリーニングや実験計画の自動最適化を報告しています(件数や条件は研究により異なる)。
さらに、アルゴリズム自体を継続的に見つけて改善する枠組み(例:AlphaEvolveのような「継続的探索」の概念)は、実験設計や探索戦略の最適化にも波及しつつあります。
ソフトウェア開発
また、GitHub Copilotのようなコード生成AIも関連技術です。これらは、自身の出力に対するフィードバックから学習します。そして、コード提案の質を向上させています。これは限定的ながらも自己改善の一形態と言えるでしょう。将来的には、自己進化型AIが自身のコードベースを改善する能力は、さらに高度化すると期待されます。
自動運転
自動運転技術においても、自己進化の考え方は重要です。車両は実世界での経験を通じて継続的に学習します。そして、走行アルゴリズムを改善していく仕組みが開発されています。特に、予測不可能な状況への対応能力を高めるためには、自己進化型AIのアプローチが不可欠と考えられています。
ヘルスケア
さらに、個別化医療の分野でも期待されています。患者個人のデータに基づいて治療法を最適化する自己進化型AIシステムが注目されています。これらのシステムは、患者の反応から学習します。そして、治療法を継続的に調整する能力を備えることを目指しています。
2030年に到達が予想される「自己進化型AIの3つの進化フェーズ」—再帰的自己改善・協調進化・価値学習
本章では、自己進化型AIが持つ大きな可能性と、私たちが向き合うべき倫理的・技術的課題を整理します。「暴走進化」のリスクを管理し、人類の福祉に貢献する形で進化させるための原則と、2030年までに実現しうる3つの変革を展望します。
| フェーズ | 技術的基盤 | 主な特徴 | 現状 |
|---|---|---|---|
| 初期 | AutoML, ニューラルアーキテクチャ探索 | ハイパーパラメータと構造の最適化 | 実用化済 |
| 中期 | プログラム合成, メタ学習 | 自身のコードを部分的に改良 | 研究段階 |
| 発展 | 再帰的自己改善 | 抽象的思考と独自アルゴリズムの生成 | 理論段階 |
| 完成 | 汎用的自己改善システム | 目標設定と価値観の自律的最適化 | 概念段階 |
| 超越 | 未知の技術パラダイム | 人間の理解を超えた改善メカニズム | 仮説段階 |
メリットと可能性
- 継続的な改善: まず、人間の介入なしに24時間365日自己改善を続けるため、技術進化を加速させます。
- 革新的な解決策: 次に、人間が思いつかない最適化や問題解決アプローチを発見する可能性があります。
- 人間の創造性の解放: さらに、繰り返し的なタスクをAIに委ねることができます。その結果、人間はより創造的な活動に集中できるようになります。
課題とリスク
一方で、自己進化型AIには克服すべき課題や潜在的なリスクも存在します。
制御と安全性の確保
AIが自律的に進化する過程では、予期せぬ動作や目標からの逸脱が発生するリスクがあります。したがって、暴走を防ぐための制御メカニズムや安全性の確保は最重要課題となります。
価値観との整合性 (Alignment)
また、自己進化型AIの進化の方向性や目的関数を考える必要があります。これらが常に人間の意図や倫理観と一致し続けるように設計・維持することは非常に困難です。
計算資源と環境負荷の問題
高度な自己進化には膨大な計算能力が必要です。そのため、それに伴うエネルギー消費や環境への影響も考慮しなければなりません。
説明可能性と透明性の欠如
さらに、AIがどのように自己改善したのか、なぜ特定の判断を下したのかを人間が理解・追跡することも困難になる可能性があります。
悪用のリスク
最後に、自己改善能力を持つ強力な自己進化型AIが悪意を持って利用される可能性も否定できません。
未来への展望
自己進化型AIは、AI研究開発におけるフロンティアと言えるでしょう。この強力な技術の恩恵を最大限に享受し、リスクを管理するためには、技術開発と並行した取り組みが不可欠です。具体的には、「進化と評価の分離原則」や「人間による選択性の保持」といった倫理的・社会的なガイドラインの策定、安全基準の確立、そして社会全体でのオープンな議論が求められます。
今後は、協調型マルチエージェントと自己進化メカニズムの融合が加速します。例えば MetaGPT のようなフレームワークは、公開以降継続的な機能拡張と商用展開が進み、複数の専門エージェントが役割分担して開発を進めます。次の焦点は、協調様式や役割分担そのものを自己改善で最適化する能力の統合です。
>>関連記事:MetaGPT完全ガイド:AIエージェント協調によるソフトウェア開発革命
AIが自律的に賢くなる未来においては、その進化が人類の福祉に貢献する方向へと導かれるよう、賢明な設計と運用が必要です。
Key Takeaways(持ち帰りポイント)
- メリット: 人間の介入なしに進化が加速し、人間にはない革新的な解決策を生み出す可能性がある。
- 課題とリスク: 進化の制御、人間の価値観とのズレ、説明責任の欠如、悪用のリスクなどが存在する。
- 未来への展望: 技術開発と並行し、「進化と評価の分離」などの安全性や倫理に関するガイドラインの確立と社会的な議論が不可欠である。
まとめ
本記事の核心を再確認します。自己進化型AIは、自律的な改善サイクルを通じて性能を向上させる革新的な概念です。その応用は多岐にわたる一方、制御や倫理といった課題も伴います。技術の健全な発展には、慎重な設計と社会的な議論が不可欠です。
自己進化型AIは、AIが自らの能力を継続的に改善する革新的な概念です。
具体的には、メタ学習、構造の自動設計、自己プログラミング、継続的な自己評価といったメカニズムがあります。これらを通じて、自己進化型AIは人間の介入なしに学習効率や性能を高めていきます。
したがって、この技術は、科学研究からソフトウェア開発、自動運転まで、幅広い分野での応用が期待されます。まさに、AIの可能性を大きく広げるものと言えるでしょう。しかし、その一方で、強力な能力ゆえの課題も存在します。制御の難しさ、安全性、人間の価値観との整合性といった倫理的・技術的課題です。
結論として、自己進化型AIの健全な発展のためには、技術開発と共に、安全性や倫理に関する深い議論と慎重な設計が不可欠です。そして、人類社会との調和を目指す必要があります。この技術は、遠い未来の話だけではありません。私たちが日々利用するソフトウェアの自動改善、より個別化された医療の提案、あるいは科学的発見の加速など、気づかないうちに私たちの生活や社会をより良く変えていく可能性を秘めているのです。その進化の行方を、共に見守っていく必要があるでしょう。
専門用語まとめ
- 自己進化型AI (Self-improving AI)
- 人間の直接的な介入なしに、自身のプログラムや学習能力そのものを継続的に改善できるAIシステム。自らの性能を評価し、弱点を自律的に改良する「自己改善能力」を持つ。
- メタ学習 (Meta-Learning)
- 「学習する方法」自体をAIが学習するアプローチ。タスクやデータに応じて最適な学習戦略を自ら見つけ出し、新しい課題への適応速度や学習効率を飛躍的に向上させる。
- ニューラルアーキテクチャ探索 (NAS)
- ニューラルネットワークの構造(層の数や接続方法など)を自動的に設計する技術。従来は専門家が手動で行っていた設計プロセスを自動化し、タスクに最適なモデル構造を発見する。
- MetaGPT
- 複数の専門AIエージェント(プログラマーAI、テスターAIなど)が協調し、一つのタスク(ソフトウェア開発など)を遂行するマルチエージェントフレームワークの一種。
- 自己改善コーディングエージェント(Self-Improving Coding Agent)
- エージェントが自分自身のコード基盤を反復的に編集・評価し、性能向上を目指すアプローチ。評価アーカイブ・監視機構など安全設計が重要。[^sica]
- AlphaEvolve
- Google DeepMindが2025年に公表。AIと進化的探索でアルゴリズムや設定を継続的に発見し、実システムに還元する自己進化フレーム。[^alphaevolve]
- 経験の時代(Era of Experience)
- 人手データ中心から、エージェントが環境と相互作用して学ぶ“経験駆動”への転換を説く概念(Sutton/Silver, 2025)。
よくある質問(FAQ)
Q1. 自己進化型AIと、AGI(汎用人工知能)の違いは何ですか?
A1. 自己進化型AIは「特定の能力を自ら改善し続けるAI」を指す技術的なアプローチです。一方、AGIは「人間のように幅広い知的作業をこなせるAI」という概念的な目標です。自己進化はAGIを実現するための一つの重要な要素技術と考えられますが、自己進化型AIが必ずしもAGIであるとは限りません。
Q2. 自己進化型AIとAutoMLはどう違うのですか?
A2. AutoML(自動機械学習)は、主にモデルの構造やハイパーパラメータの最適化を自動化する技術で、自己進化型AIの「AI構造の自動設計」の一形態と見なせます。自己進化型AIは、AutoMLの範囲を超え、学習戦略そのもの(メタ学習)やプログラムコード自体(自己プログラミング)まで改善対象に含む、より広範で自律的な概念です。
Q3. AIが勝手に進化するのは危険では? OECD・EU AI Act・日本(経産省WG)など、国際的なAI安全基準や最新ガイドラインは?
A. リスク管理は最重要課題です。EUはAI Actを採択し、リスク階層に応じた義務を段階的に適用予定です。OECDはAI原則(透明性・説明可能性・安全性など)を提示し、各国政策の基盤になっています。日本では経産省「AI事業者ガイドライン」等が改訂され、リスクベース運用とガバナンスが具体化。実務では 進化と評価の分離、Sandbox/人間の監督、ログ・監査設計、モデル更新時の影響評価 が要点です。
脚注
更新履歴
主な参考サイト
合わせて読みたい
- MetaGPT完全ガイド:AIエージェント協調によるソフトウェア開発革命
- CrewAI徹底ガイド:マルチエージェントがチームで働く時代へ
- AutoGen完全ガイド:AIエージェントが“自走する開発チーム”になる
- 生成AIは開発スタイルをどう変えるか? CopilotからDevinまで(SWE-bench最新比較つき)
- AI版OSがやって来る!インターネットの大変化と未来戦略
以上








