


最終更新:※本記事は継続的に「最新情報にアップデート」を実施しています。
LangGraphとは?StateGraphで実現するAIエージェント開発の実践ガイド
📢 2026年最新情報(v1.0α対応)
LangGraph/LangChainのv1.0αは2025年9月2日に公開され、その後LangGraph v1.0(安定版)は2025年10月22日に一般公開(GA)されました。本記事はv1系の仕様に基づいて解説します。
- StateGraph中心の設計方針がv1.0で正式に確立
- LangSmith UIでのデプロイ監視(2025年7月10日告知)でボトルネック特定が迅速化
- StudioのTrace Mode(2025年8月15日告知)でリアルタイムトレース表示が可能に
- Revision Queueing(2025年8月27日)で新バージョンをキュー管理し、デプロイの重複や衝突を防止。段階的な展開(ロールアウト)の運用を安定化
LangGraphとは、AIエージェントの状態管理と処理フローをグラフ構造で設計できるフレームワークです。「LangChainで複雑な条件分岐やループを実装しようとして、コードが複雑になり挫折した…」そんな経験はありませんか?
この記事では、その限界を打ち破るLangGraphの核心を徹底解説。グラフ構造を用いて、柔軟で強力なAIエージェントを構築する具体的な手順を、豊富な図解とコードでマスターできます。
✅ この記事の結論(TLDR)
LangGraphは、エージェントの状態を共有する「StateGraph」を中核に、条件分岐・ループ・HITL(人手介入)・永続化まで一貫管理できる実運用志向のフレームワークです。
- StateGraphが基本:複数ステップや条件分岐、長期対話・中断/再開が想定されるなら、まずStateGraphから設計するのが定石
- Graphは軽量フローに:共有Stateが不要な軽量ワークフローならGraph、状態管理が要る複雑系はStateGraph
- MessageGraphは非推奨:LangGraph.jsではStateGraph+Messages系Annotationへ移行推奨。Pythonでも新規はStateGraph前提
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
LangChainで構築するAIエージェントの基本構造
AIエージェントの基本概念から、その開発を支えるフレームワークLangChainの主要コンポーネントと従来の課題までを解説。AI開発の前提知識を整理します。
AIエージェントの概念と進化
AIエージェントとは、特定の目標に向かって自律的に行動し、環境と相互作用しながら問題を解決する知的なシステムです。従来のチャットボットが単一の入力に対して回答を返すだけだったのに対し、AIエージェントは複数のステップを経て目標達成を目指します。
AIエージェントの最大の利点は、複雑なタスクを自律的にこなせる点にあります。例えば、情報収集、分析、意思決定、そして行動といった一連のプロセスを自動化できるため、人間の作業効率を飛躍的に向上させる可能性を秘めています。
近年のAIエージェントの進化により、以下のような発展が見られます:
- 単純な反応型から計画型へ:単に刺激に反応するだけでなく、将来を見据えた計画を立てられるようになりました
- 専門特化から汎用性へ:特定のタスクだけでなく、様々な領域で活用できるエージェントが登場しています
- 単独行動から協調行動へ:複数のエージェントが協力して複雑な問題を解決するマルチエージェントシステムへと発展しています
LangChainの全体像と主要コンポーネント
LangChainは、大規模言語モデル(LLM)を活用したアプリケーション開発のためのオープンソースフレームワークです。2022年末に登場して以来、LLMベースのアプリケーション開発において最も広く使われているフレームワークの一つとなっています。
LangChainについて詳しくは、「LangChain使い方完全ガイド|OpenAI API連携」もご参照ください。
LangChainは、以下の主要コンポーネントで構成されています:
- 言語モデル(LLMs):OpenAI、Anthropic、Google、LLaMAなど様々な言語モデルを統一的なインターフェースで利用可能
- プロンプトテンプレート(Prompts):言語モデルへの指示を動的に構築するためのテンプレート機能
- チェーン(Chains):複数のコンポーネントを連携させて一連の処理を行う仕組み
- メモリ(Memory):会話の履歴や状態を保持する機能
- ツール(Tools):外部API、データベース、検索エンジンなど外部リソースを活用するための機能
- 検索(Retrieval):ドキュメント検索や情報取得のための機能。RAG(検索拡張生成)の実装に必須
- エージェント(Agents):自律的に行動し、ツールを適切に選択・利用する機能
従来のLangChainの限界と課題
LangChainは多くの強力な機能を提供していますが、複雑なワークフローやエージェントの実装においては、以下のような限界と課題がありました:
❶ 限定的な非線形処理:従来のLangChain(特に初期のChains)は線形的な処理の流れ(A→B→C)を前提とする設計が主流でした。バージョン0.2以降のLCEL(LangChain Expression Language)により分岐やループも表現可能になりましたが、複雑な状態主導の分岐を直感的に設計・管理するのは依然として煩雑でした。
❷ 状態管理の複雑さ:複数のコンポーネント間での状態の共有や管理が煩雑でした。特に長いチェーンやループを含むフローでは、状態の受け渡しや更新が複雑になりがちでした。
❸ デバッグの難しさ:複雑なチェーンやエージェントの挙動を理解し、デバッグすることが難しいという課題がありました。処理の流れが視覚的に把握しづらく、問題の特定が困難でした。
LangGraphの基本概念:StateGraphで変わるAIエージェント設計【v1.0対応】
LangChainの限界を克服するLangGraphの核心、グラフ構造の概念を解説。ノード・エッジ・ステートといった基本要素と、動的な処理分岐を実現する手法を学びます。
LangGraphの基本概念とグラフ構造
LangGraphは、LangChainのエコシステムの一部として開発された、AIエージェントの動作フローを効率的に設計・実装するためのライブラリです。LangChainが提供するコンポーネントをグラフ構造で接続することで、より柔軟で高度なAIエージェントの構築を可能にします。採用事例も、Klarna、LinkedIn、Uber、Elasticといった先進的な企業で増加しています。
開発元とライセンス情報
LangGraphは、LangChainを開発するLangChain, Inc.によって開発・提供されています。MITライセンスの下で配布されており、商用・非商用を問わず自由に利用・改変が可能です。
LangGraphの核心は、グラフ構造による「処理の可視化」にあります。これにより、仕様と実装の乖離が減り、チーム全体でプロセスを共有しながら改善サイクルを回しやすくなります。
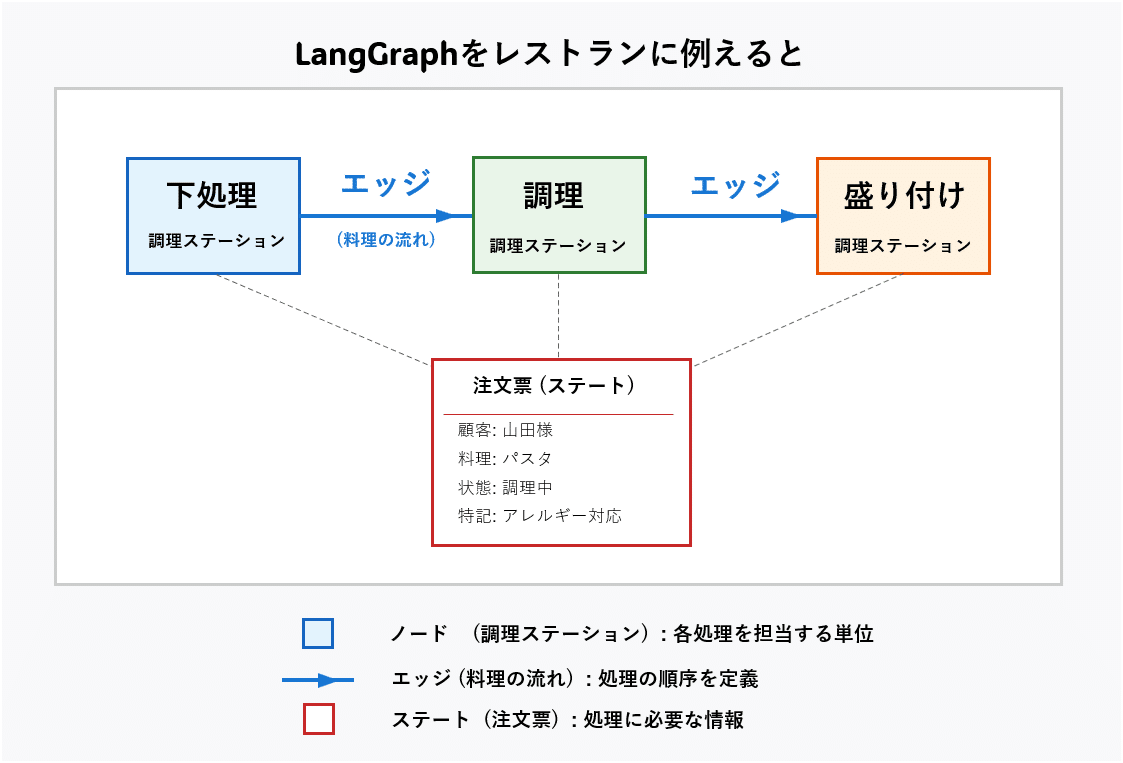
LangGraphをレストランの運営に例えると、次のようになります:
- ノード(Node)は「調理ステーション」のようなもの。それぞれが具体的な作業を担当します
- エッジ(Edge)は「料理の流れ」を示し、ステーション間の受け渡しルートです
- ステート(State)は「注文票」のようなもの。処理に必要な情報が記載されています
👨🏫 AI専門家が解説:かみ砕きポイント
これまでのプログラムが一本道だったのに対し、LangGraphは交差点や分岐路のある地図のようなものです。「ノード」が地点、「エッジ」が道、「ステート」が現在地や持ち物を記録したメモ帳にあたります。この地図とメモ帳があるおかげで、AIは「もしA地点が混んでいたらB地点へ行こう」といった複雑な判断を、迷うことなく実行できるのです。
ノード、エッジ、ステートの活用法
LangGraphにおけるグラフ構造は主に以下の要素で構成されます。
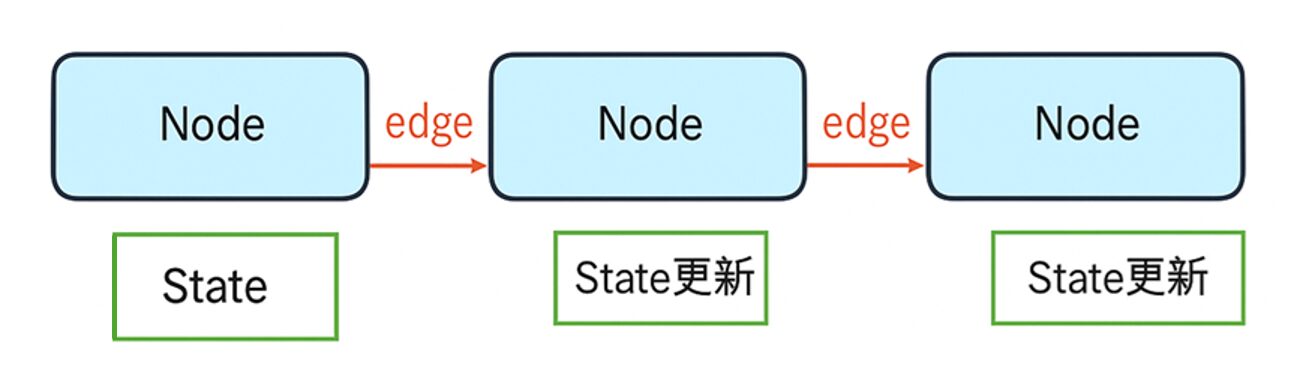
❶ ノード (Node):各処理の単位を表します。「ユーザー入力の解析」「情報検索」「回答生成」などの機能をノードとして定義します。
❷ エッジ (Edge):ノード間の接続関係を表し、処理の流れを定義します。
❸ ステート (State):グラフ全体で共有される状態を保持する仕組みです。会話履歴や中間結果などを保存します。通常、TypedDictを使って型安全に定義します。
from typing import TypedDict, Dict, Any
from typing import Annotated
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
# LangGraphでやり取りされる状態(State)を定義
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages] # 上書きではなく「追加」で履歴を蓄積
context: Dict[str, Any] # コンテキスト情報
tools_used: list[str] # 使用したツールのリスト
LangGraphのルーティング設計:条件分岐の最適化
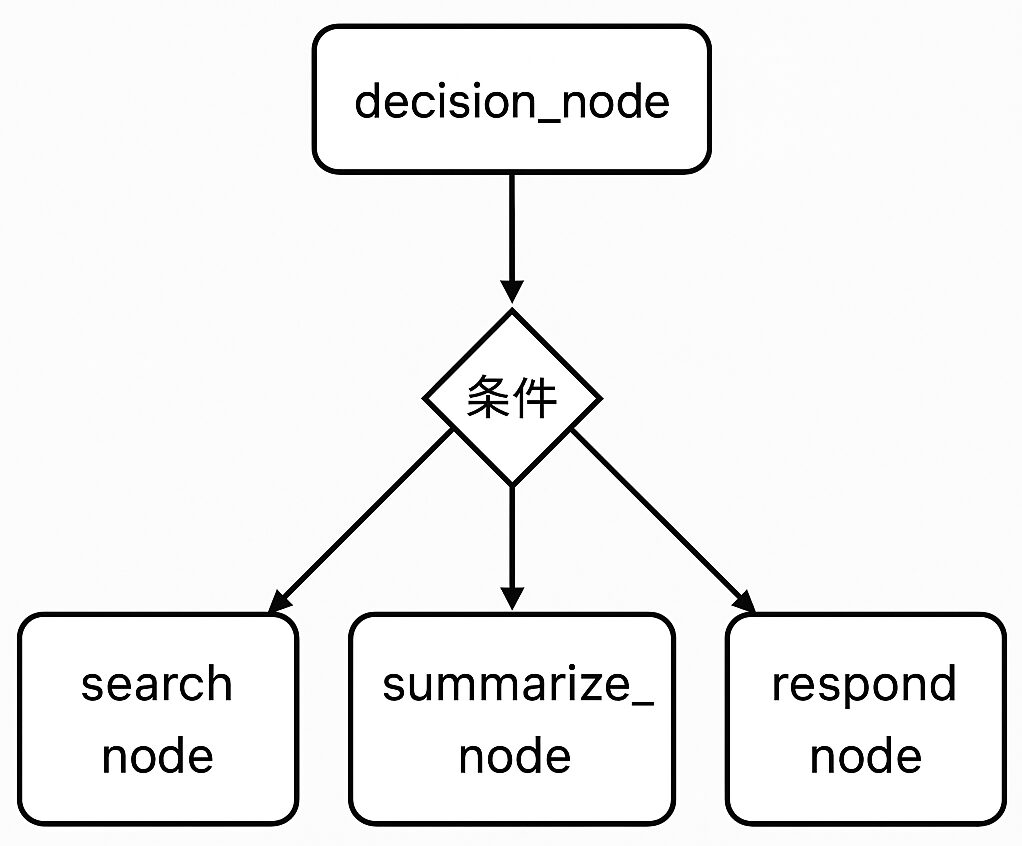
LangGraphで特に重要な概念が条件付きエッジ (Conditional Edge)とルーター (Router)です。これらにより、状態に応じて処理の流れを動的に分岐させることができます。
from langgraph.graph import StateGraph, END
from langchain_core.messages import BaseMessage
from typing import TypedDict, List
# 1. ステート定義
class AgentState(TypedDict):
messages: List[BaseMessage]
# (search_func, summarize_func, respond_func, decide_func は別途定義済みとする)
# 2. グラフビルダー初期化
builder = StateGraph(AgentState)
# 3. ノードの追加
builder.add_node("search_node", search_func)
builder.add_node("summarize_node", summarize_func)
builder.add_node("respond_node", respond_func)
builder.add_node("decision_node", decide_func)
# 4. 条件分岐を定義するルーター関数
def router(state: AgentState) -> str:
"""最後のメッセージの内容に応じて次に進むノードを決定する"""
last_message = state["messages"][-1]
if "検索" in last_message.content:
return "search_node"
elif "要約" in last_message.content:
return "summarize_node"
else:
return "respond_node"
# 5. 条件付きエッジを追加
builder.add_conditional_edges(
"decision_node",
router,
{
"search_node": "search_node",
"summarize_node": "summarize_node",
"respond_node": "respond_node"
}
)
# 6. エントリーポイントを設定
builder.set_entry_point("decision_node")
# 7. 各処理後の遷移先を定義(ループ構造)
builder.add_edge("search_node", "decision_node") # 検索後は再判断
builder.add_edge("summarize_node", "decision_node") # 要約後も再判断
builder.add_edge("respond_node", END) # 応答したら処理完了
# 8. グラフをビルド
graph = builder.compile()
LangGraphの種類と特性
LangGraphの主要なグラフタイプである「基本グラフ」「メッセージグラフ」「ステートグラフ」それぞれの特徴と用途を比較。最適なグラフ選択の指針を得られます。
基本グラフ、メッセージグラフ、ステートグラフの違い
LangGraphには用途に応じて複数のグラフがありますが、v1系ではStateGraph+messages(MessagesState相当)を起点に設計するのが、公式ドキュメント上も事実上のベストプラクティスになっています。
1. ステートグラフ (StateGraph) ─【推奨】
最も強力で汎用性が高いグラフ型です。TypedDictを用いて型安全な状態定義が可能で、AIエージェントのような複雑なアプリケーション構築に最適です。会話履歴、ツール使用状況、中間結果など、あらゆる情報を一元管理できます。現在の新規開発では、まずStateGraphを選択するのが定石です。
2. 基本グラフ (Graph)
任意の型の入出力を持つノードを接続できるシンプルなグラフです。一直線の単純なデータ変換パイプラインなど、用途が限定される場合に適しています。
3. メッセージグラフ (MessageGraph) ─【非推奨(Deprecated)/レガシー】
LangGraph v1系では、MessageGraphはDeprecatedとして位置づけられ、StateGraph+messagesキー(MessagesState相当)を起点に設計する方針が明確になっています。既存コードの互換は当面維持されますが、新規開発はStateGraph前提で組み立てるのが安全です。将来の扱いは公式アナウンスを参照してください。
| グラフ種類 | 推奨度 | 用途 | 状態管理 |
|---|---|---|---|
| StateGraph | ◎ 推奨 | 複雑なエージェント、RAG、マルチステップ処理 | TypedDictで型安全 |
| Graph | ○ 限定用途 | 単純なデータ変換パイプライン | 任意型 |
| MessageGraph | △ 非推奨 | レガシー互換 | メッセージリスト固定 |
| ※ 出典: LangGraph公式ドキュメント(2026年2月時点) | |||
🎯 Key Takeaways(持ち帰りポイント)
- StateGraphが基本:条件分岐や複数ステップが少しでも想定されるなら、迷わずStateGraphから設計を始める
- Graphは軽量フローに:共有Stateが不要な軽量ワークフローや明確な入出力変換が中心ならGraph
- MessageGraphは旧式:LangGraph.jsで非推奨傾向。Pythonでも新規はStateGraph推奨
グラフのコンパイルと実行
LangGraphは「定義」「コンパイル」「実行」の3ステップで動作します。コンパイルされたグラフはinvokeで最終結果を、streamで中間結果をリアルタイムに取得できます。
from langchain_core.messages import HumanMessage
# (builderで定義・ビルド済みとする)
graph = builder.compile()
# 実行
initial_state = {"messages": [HumanMessage(content="東京の天気と、おすすめの服装を検索して")]}
result = graph.invoke(initial_state)
# 中間状態を逐次取得(更新のみ)
for chunk in graph.stream(initial_state, stream_mode="updates"):
print(chunk)
print("----")
※ stream_mode="updates"はv1.0αドキュメント準拠。将来の変更は公式ドキュメントを参照してください。
graph.stream()は、ワークフローの途中経過をユーザーに提示したり、詳細なデバッグを行ったりする際に非常に強力です。
LangGraphによるスマートRAGフローの実践
検索拡張生成(RAG)をLangGraphで実装する具体的な手法をコードで紹介。毎回検索する非効率をなくし、より賢く、低コストなRAGシステムを構築します。
高度なRAG実装:必要なときだけ検索する
応答を高速化し、無駄なAPIコストを削減するために、ユーザーの質問に応じて「検索が必要か、LLMの内部知識だけで答えられるか」を判断するスマートなRAGを構築します。
from typing import TypedDict, List, Dict
from langchain_core.messages import BaseMessage, AIMessage, HumanMessage
from langchain_core.documents import Document
# (query_extractor_llm, vector_db, llm, search_necessity_llm は外部で定義済みのオブジェクトとする)
# ===========================
# ✅ RAGシステムの状態定義
# ===========================
class RAGState(TypedDict):
messages: List[BaseMessage]
query: str
search_results: List[Document]
context: str
# ===========================
# 🔍 RAGの各処理ノード (関数として定義)
# ===========================
def extract_query(state: RAGState) -> Dict:
# (実装は省略)
pass
def perform_search(state: RAGState) -> Dict:
# (実装は省略)
pass
def prepare_context(state: RAGState) -> Dict:
# (実装は省略)
pass
def generate_answer(state: RAGState) -> Dict:
# (実装は省略)
pass
def direct_answer(state: RAGState) -> Dict:
# (LLMの知識だけで回答するノード)
pass
# ===========================
# 🔁 検索の必要性を判断するルーター関数
# ===========================
def search_router(state: RAGState) -> str:
last_message = state["messages"][-1].content
needs_search_response = search_necessity_llm.invoke(
f"この質問に答えるために外部情報の検索が必要ですか? はい/いいえ で答えてください: {last_message}"
)
# LLMの応答の揺らぎを考慮する
if "はい" in needs_search_response.content or "必要" in needs_search_response.content:
print(">>> 判断: 検索が必要")
return "extract_query" # → クエリ抽出から始まるRAGフローへ
else:
print(">>> 判断: 検索は不要")
return "direct_answer" # → LLMの知識だけで直接回答するフローへ
【プロの視点】判断コストとRAG品質向上の定石
このスマートな構成は強力ですが、いくつか実運用上のポイントがあります。
- 判断コストとのトレードオフ:検索の必要性を判断するためにもLLMコールが発生します。この判断用LLMには、メインのLLMより軽量で高速なモデル(例: Claude 3 Haiku, Gemini 1.5 Flash)を使い、コストと速度のバランスを取るのが定石です
- 高度な検索技術:検索精度を高めるため、従来のベクトル検索に加えて、キーワードベースのBM25を組み合わせるハイブリッド検索や、一度取得した検索結果を別のLLMで並べ替える再ランキング(Re-ranking)が有効です
- 引用と信頼性:生成した回答に、どの情報を参照したかの引用(Attribution)を明記することで、回答の信頼性が向上し、ハルシネーションを抑制できます
Agentic RAGのベンチマーク設計:品質×速度×コスト
実運用では、回答品質(人手評価/自動評価)、レイテンシ、推論/検索コストの三点を指標化し、回帰テストをLangSmith等で継続評価するのが定石です。AutoRAGや再ランキング、ハイブリッド検索の導入可否もこの指標で意思決定します。
📦 長期記憶の実装
2025年8月19日に公開されたMongoDB Store for LangGraphにより、エージェントがセッションを跨いで情報を記憶する長期メモリを実装できます。短期メモリ(スレッド単位のCheckpointer)を補完し、クロススレッドな永続化を実現。
公式手順:pip install langgraph-store-mongodb
※ 公式ブログ(2025/8/20)でクロスセッション永続化などを解説。
実運用を見据えたAgentic Workflowの要点
開発したエージェントを本番環境で安定稼働させるために不可欠な、永続化、監視、安全性の考え方を解説します。
Checkpointer:エージェントの状態を永続化する
AIエージェントが長時間のタスクを実行する場合や、ユーザーとの対話を中断・再開できるようにするためには、処理の途中の状態(ステート)を保存する仕組みが不可欠です。これを実現するのがCheckpointer(チェックポインター)です。
Checkpointerを使うことで、以下のようなメリットがあります。
- 中断と再開:ユーザーがブラウザを閉じても、後から対話を再開できます
- 耐障害性:処理中にエラーが発生しても、最後の状態から処理を再実行できます
- 監査とデバッグ:過去の任意の状態を復元し、エージェントの挙動を再現・分析できます
LangGraphでは、インメモリのMemorySaverのほか、SqliteSaverや各種クラウドストレージに対応したCheckpointerが提供されており、本番環境ではデータベースなどへの永続化が必須となります。
from langgraph.checkpoint.sqlite import SqliteSaver
from langchain_core.messages import HumanMessage
# 本番は ":memory:" ではなく、"file:checkpoints.db" や実DB接続文字列を推奨
memory = SqliteSaver.from_conn_string("file:checkpoints.db")
graph = builder.compile(checkpointer=memory)
# configでスレッドIDを指定して実行することで、状態が保存・復元される
config = {"configurable": {"thread_id": "user_123"}}
result = graph.invoke(initial_state, config=config)
# 後から同じthread_idで実行すれば、前回の続きから再開できる
result_continued = graph.invoke({"messages": [HumanMessage(content="ありがとう")]}, config=config)
※ SQLiteを使う場合は別途pip install langgraph-checkpoint-sqliteを実行してください(詳細はPyPIを参照)。
LangSmithによる監視とツールの安全性
複雑なエージェントの挙動を把握し、問題の原因を特定するために、LangSmithのような観測プラットフォームの利用が推奨されます。LangSmithを使うと、エージェントの内部的な思考プロセス(どのノードを通り、どのツールを呼び出し、どのような結果を得たか)をステップバイステップで視覚的に追跡できます。
また、エージェントにファイル削除やAPI経由でのデータ更新など、リスクの高い操作を許可するツールを渡す場合は、安全策が不可欠です。具体的には、以下のような対策が考えられます。
- スコープの限定:ツールがアクセスできる範囲(ファイルやAPIエンドポイント)を最小限に絞ります
- 人間による承認:高リスクなツールを実行する直前に、必ず人間のオペレーターに承認を求めるステップをグラフ内に組み込みます
LangGraph Platform 最新機能(2025 Q3)
LangSmith監視・Studio Trace Mode・Revision Queueingなど、本番運用を支える最新機能を紹介します。詳細は公式Changelogを参照してください。
- LangSmith UIでのデプロイ監視(2025年7月10日告知):LangSmithからPlatformデプロイのCPU/メモリ、APIレイテンシ等を直接監視。ボトルネック特定を迅速化
- StudioのTrace Mode(2025年8月15日告知):Studio内でLangSmithトレースをリアルタイム表示/注釈・データセット登録まで一気通貫
- Revision Queueing(2025年8月27日):新バージョンをキュー管理し、デプロイの重複や衝突を防止。段階的な展開(ロールアウト)の運用を安定化
まとめ:LangGraphが切り拓くAIエージェント開発の新時代
本記事の要点を振り返り、LangGraphがAIエージェント開発にもたらす革新性を再確認。複雑なワークフローを直感的に実装できる本ツールの将来性を展望します。
LangGraphは、従来のLangChainが抱えていた状態管理の複雑さを「グラフ理論」によって打ち破る、革新的なフレームワークです。ノード、エッジ、そして特にStateGraphとCheckpointerを用いることで、条件分岐やループ、中断・再開を含む複雑なAIエージェントのワークフローを、驚くほど直感的かつ堅牢に実装できます。
本記事で解説したスマートRAGや実運用を見据えた設計は、皆さまのプロジェクトを次のレベルへ引き上げる確かな一手となるでしょう。
持ち帰りポイント
🎯 今日から実践できる3つのアクション
- StateGraphから始める:新規プロジェクトでは迷わずStateGraphを選択し、状態管理の設計から着手する
- Checkpointerを早期導入:開発初期からSqliteSaverなどで永続化を組み込み、デバッグと耐障害性を確保する
- LangSmithで可視化:エージェントの挙動をトレースし、問題の早期発見と改善サイクルを回す
専門用語まとめ
- LangGraph
- 処理の流れをグラフ構造で定義するAIエージェント開発用ライブラリ。複雑な条件分岐や状態管理を得意とする。
- Checkpointer
- エージェントの状態(ステート)をデータベースなどに保存(永続化)する仕組み。中断・再開や耐障害性を実現する。
- LangSmith
- LangChain/LangGraphで構築したアプリケーションの実行過程を可視化・デバッグ・評価するための観測プラットフォーム。
- RAG (Retrieval-Augmented Generation)
- 検索拡張生成。LLMが外部データベースを検索し、その情報を基に回答することで、より正確な応答を可能にする技術。
- ステート (State)
- グラフ全体で共有される「状態」や「データ」。会話履歴や中間結果などを保持するメモ帳の役割。
よくある質問(FAQ)
Q1. LangChainとLangGraphの最も大きな違いは何ですか?
A1. 状態管理とフロー制御の柔軟性です。LangChain(特にLCEL)でも分岐は可能ですが、LangGraphはエージェントの「状態」全体を管理しながら、その状態に応じて次のアクションを動的に決定する複雑なワークフローを、より直感的かつ堅牢に設計できます。
Q2. どのような場合にLangGraphを使うべきですか?
A2. 条件分岐が多数ある場合、処理を中断・再開する必要がある場合、複数のAIエージェントが連携するシステムを構築する場合に特に有効です。「もし〇〇ならA、△△ならB」といった動的なフロー制御が求められるシーンで真価を発揮します。
Q3. Checkpointerは必ず使うべきですか?
A3. 短時間で完了する単純な処理であれば必須ではありません。しかし、ユーザーとの対話が続くチャットボットや、完了までに数分以上かかる可能性があるタスクを実行するエージェントなど、状態を失いたくないアプリケーションでは実質的に必須の機能です。
Q4. LangGraph v1.0αで何が変わりますか?
A4. StateGraph中心の設計方針が明確化し、LangGraph.jsではStateGraph+Messages系Annotationへの移行が公式に推奨されています。加えてPlatformのTrace ModeやRevision Queueing、LangSmith監視が整い、Agentic RAGの本番運用(デバッグ/段階リリース/監視)が容易になります。
Q5. LangGraphとCrewAI、AutoGen、AutoRAGの違いは?
A5. LangGraphは制御フローの透明性・永続化・監視まで一貫した本番運用基盤です。CrewAIは役割ベースのチーム編成、AutoGenは対話駆動の協調、AutoRAGはRAG構成の自動最適化に特化。実務ではLangGraph(運用基盤)+AutoRAG(RAG評価/探索)の併用も有効です。
より詳しい情報は、Agentic RAGとは?AIエージェントでRAGを強化する実践ガイドをご覧ください。
参考サイト・出典
あわせて読みたい
更新履歴
- 2025年4月2日:初版公開
- 2025年9月26日:v1.0α対応、FAQ拡充、E-E-A-T強化を含む改訂
- 2026年2月17日:テンプレートv10.1.3適合化、情報アップデート
以上








