


ウェブサイト大反転|2025年AI時代のSEO戦略と収益モデル完全ガイド
この記事を読むとAI時代のウェブサイト戦略と新しい収益モデルがわかり、データ経済圏で競争力を持つサイト運営ができるようになります。
ウェブサイトは「解説」から「証拠提供」と「APIトランザクション」へと役割転換し、AIエージェントとの共生による新たな収益モデルを構築する必要がある
- 要点1:AIが解説を代替するため、一次情報とAPIファーストの設計が価値の源泉となる
- 要点2:構造化データ(schema.org)とC2PA(コンテンツ来歴証明)による信頼性証明が必須要件に変化
- 要点3:robots.txtがAIとのデータ利用に関する規約として機能し、新たな収益モデルを生み出す
Q1. AIエージェント時代でもSEOは必要ですか?
A. はい、ただし従来の「解説型コンテンツ」から「一次情報と構造化データ」への転換が必要です。
Q2. アフィリエイト収益はどう変わりますか?
A. 送客型から「APIトランザクション手数料」モデルへと進化し、より直接的な収益構造になります。
Q3. 構造化データの実装は必須ですか?
A. はい、AIエージェントに正確に情報を理解させるための「デジタル住所」として不可欠です。
この記事の著者・監修者

プロローグ:ある朝、インターネットが別人になっていた
要約:2025年8月、インターネットは人間向けの図書館からAIエージェント専門家チームが活動する協働プラットフォームへと、新たな段階に突入しました。
検証ポイント:GoogleのAI Overviewsや、主要IT企業が開発する新世代AIアシスタントがもたらす具体的な変化

この変化の核心は、検索が「人間向け」から「AI向け」へと完全に舵を切った点にあります。
ある朝あなたが目覚めると、インターネットはすっかり様変わりしていました。
昨日まで、ウェブは人間が情報を探すための巨大な「図書館」でした。あなたのサイトも、その図書館で多くの人に読まれる人気の本だったかもしれません。
しかし、今朝のインターネットは違います。
図書館の主役は、もはや一人の司書ではありません。そこには、それぞれが異なる専門性を持つ「AIエージェントの自律型専門家チーム」がいます。
リサーチ担当エージェントがあなたのサイトから最新の実験データを引き出し、分析担当が競合データと比較検証し、そして実行担当がAPIを通じてシームレスに購入を完了させる。しかも彼らは、先週あなたと交わした会話の内容を完璧に記憶しているのです。
これはSFではありません。
Googleの「AI Overviews」(検索結果のAI要約表示機能)や、主要IT企業が開発する新世代AIアシスタントの登場が告げる、ウェブの「大反転」の始まりです。
📌AI Overviewsの登場により、従来の検索結果へのCTR(クリック率)が大幅に減少しており、Ahrefsの最新調査(2025年6月)では最大34.5%の減少が確認されています。
検索トラフィックの量で一喜一憂する時代は終わりを告げ、私たちのサイトは、この高度に連携する専門家集団から「仕事相手」として選ばれるかどうかの岐路に立たされています。
👨🏫 かみ砕きポイント
これまでのウェブサイトは「人間に読まれるための情報提供」が目的でした。しかし今後は「AIエージェントが活用できる信頼性の高いデータソース」として機能することが求められます。単なる集客から、AIとの協働によるビジネス価値創出へのパラダイムシフトです。
第1章:「解説」の終わりと「証拠」の始まり ― あなたのサイトが持つべき新たな価値
要約:AIが解説機能を完全代替する中、ウェブサイトの価値は一次情報・構造化データ・APIアクセスへと転換する
かつて、ウェブサイトの価値は「いかに分かりやすく解説するか」にありました。
しかし、その役割はAIが完全に代替します。LLM(大規模言語モデル)は、世界中の情報を要約し、再構成する達人だからです。
AIが作れない「一次情報」こそが宝の山
AIは既存の情報を統合するのは得意ですが、ゼロから何かを創り出すことはできません。ここに、私たちの活路があります。AIの学習元となる、根源的で検証可能な「証拠」の提供です。
具体的には、以下のようなものが挙げられます。
- 独自の実験データ:あなたが実際に製品をテストした結果、その温度変化のグラフ。
- 現地取材の記録:あなたが直接インタビューして得た、専門家の生の声。
- リアルタイムの在庫・価格情報:あなたの店でしか確認できない、今この瞬間の商品データ。
- 失敗の記録:「この方法ではうまくいかなかった」という、成功談より価値のある試行錯誤のプロセス。
これらは、AIが答えを生成するための「根拠」や「証拠」となります。これからのウェブサイトは、百科事典ではなく、「実験ノート」であり「証拠保管庫」になるのです。
AIにサイトの情報を正しく理解させる技術:構造化データという共通言語
ただ一次情報をサイトに置くだけでは不十分です。
AIエージェントに、その情報が「何であり」「誰のもので」「いつの情報か」を正確に理解させる必要があります。
そのための共通言語が、schema.orgを用いた構造化データです。
構造化データがないウェブサイトは、住所も番地も書かれていない家のようなものです。AIという名の超優秀な郵便配達員は、その家に重要な手紙(参照や引用という評価)を届けたくても、届け先が分からず素通りしてしまいます。
ちなみにSchema.orgは2025年5月にバージョン29.2が公開され、金融インセンティブ(`financialIncentive`)や配送関連の語彙が追加されるなど、常に進化しています。
構造化データは従来のSEOだけでなく、AIエージェントにビジネスの文脈を正確に理解させるための基盤として、その重要性を増しています。
| Year | Key Update |
|---|---|
| 2011 | Schema.org launched (Google, Bing, Yahoo, Yandex) |
| 2020 | FAQ & HowTo markup expansion |
| 2023 | AI-related metadata extensions |
| 2025 | v29.2 released (Financial incentives, Delivery terms) |
| Future | Standardization for AI agent integration |
アクションの最終地点となる:APIファーストという発想
AIエージェントがあなたのサイトの情報を「最良の選択肢」としてユーザーに提示した後、次に来るのは「予約する」「購入する」といった具体的なアクションです。
このとき、ユーザーをあなたのサイトに誘導し、もう一度情報を入力させる手間をかけさせてはいけません。
ここで重要になるのが「APIファースト」という考え方です。
これは、人間が見るためのウェブページ(HTML)を設計するのと同等かそれ以上に、AIやプログラムが機能を利用するための接続口(API)の設計を優先する開発思想を指します。
例えばホテル予約サイトの場合、AIエージェントはユーザーとの会話から得た「明日2名で予約」という情報を使い、サイトの予約APIを直接呼び出して処理を完結させます。
ユーザーは予約サイトの画面を開くことなく、AIとの対話だけで予約を終えられるのです。
あなたのサイトが、AIにとっての「アクションの最終地点」となるために、APIの提供は不可欠になります。
第2章:信頼性の証明 ― 合成コンテンツの海で「本物」であり続ける方法
要約:AI生成コンテンツが氾濫する中、C2PAとタイムスタンプによる信頼性証明が必須要件となる
比較条件:C2PA実装サイト vs 非実装サイトの信頼性評価/データ源:C2PA標準仕様とEU AI法
AIがコンテンツを無限に生成できるようになった世界では、「この情報は本物か?」という問いが、これまで以上に重要になります。信頼こそが、新しい時代の通貨です。

デジタル世界の「市民権」:C2PAという必須要件
C2PA (Content Credentials) とは、コンテンツの「来歴」を証明するための国際標準技術であり、いわば“デジタル署名”です。
写真や記事が「いつ、誰によって、どのツールで作成・編集されたか」という情報を改ざん不可能な形で埋め込むため、これを持たない情報は今後、信頼を失い淘汰されます。
C2PAは、もはや単に推奨される技術ではありません。
EU AI法は2024年に成立し、2025年8月2日から段階的に施行されています。
AI生成コンテンツの透明性要件(第50条)は2026年8月2日から本格適用予定です。
国内事業者も、欧州市場でのサービス展開を行う場合はC2PA対応が実質必須となり、日本でも同様の議論が進む可能性があります。
C2PAは、この来るべき規制社会における「デジタル市民権の証明書」とも言える重要な技術です。これを持たないコンテンツは、信頼できないどころか、主要プラットフォームでの流通が困難になる未来がすぐそこまで来ています。
「いつ」を証明する力:更新履歴の見える化
AIにとって、「いつの時点の事実か」は極めて重要です。
1年前の価格情報や、昨日覆された研究結果に価値はありません。サイトマップの最終更新日時(lastmod)もちろん、記事の修正履歴、データのバージョン情報などを、人間と機械の両方が読み取れる形で公開することが標準になります。
これは、あなたの情報が「今も生きている、最新の事実」であることを証明する「信頼性の証」となります。
第3章:ラストワンマイルの攻防 ― AIエージェントのためのUX設計「AX」
要約:従来のUXに加え、AIエージェント向けの「Agent Experience (AX)」最適化が新たな競争軸となる
AIのタスク自律完了能力は、最新の研究データが証明するように、もはやSFではありません。このように高度に進化したエージェントが情報収集と吟味を代行した結果、あなたのサイトを訪れる人間は、数こそ減るかもしれません。しかし、その一人ひとりは極めて意図の濃いユーザーです。この貴重な訪問を逃してはなりません。
UXの新基準「Agent Experience (AX)」の誕生

GoogleのUX指標「Core Web Vitals」は、2024年3月に重要な更新がありました。
これまでの指標の初回入力遅延FID(First Input Delay )に代わり、ユーザーのクリックやタップに対するサイトの「応答性」をより正確に測る新しい指標INP(Interaction to Next Paint)が正式に採用されたのです。
INPの基準値は200ms未満とされ、特にモバイルでの応答性最適化が重要ですが、これはもはや出発点に過ぎません。
このように、2025年のウェブサイト設計において注目を集めているのが「Agent Experience (AX)」という専門家の間で議論が始まっている新しい概念です。
これは、AIエージェントにとっての使いやすさを測る指標として、専門家の間で議論が始まっている考え方です。
AIの能力は、もはや人間の専門家チームと遜色ないレベルに達しつつあります。
例えば、本記事執筆時点の2025年8月に公開された最新モデル「Claude Opus 4.1」は、SWE-bench Verified(実用的なソフトウェア開発タスクのベンチマーク)において、74.5%という驚異的なスコアを記録しました。
これは、AIが単体でコードを生成するだけでなく、ツールを駆使して自律的に問題を解決する「エージェント」として機能することで達成された画期的な成果です。
このように人間のように振る舞う高性能なAIエージェントがスムーズにタスクを完遂できるかどうかは、ウェブサイトのAPI応答速度やデータ構造の明確さ(AX)に大きく依存するのです。
👨🏫 かみ砕きポイント
AX(Agent Experience)は、AIエージェントがサイト上でタスクを効率的に実行できるかを測ることを目的とした専門家の間で議論中の新概念です。公式な評価指標ではありませんが、今後の標準化に向けた議論が進んでいます。
第4章:新たな交渉のテーブル ― robots.txtが「契約書」へ進化する可能性が議論されている
要約:robots.txtはアクセス制御に加え、将来的にAIのデータ利用条件を定義する「契約書」へ進化する可能性が議論されている
検証ポイント:各種AI学習用クローラーの実装と、Fairly Trainedのようなデータライセンス遵守を認証する試み
かつてrobots.txtは、クローラーの立ち入りを許可・禁止する単純な「交通標識」でした。しかし、AI学習用のクローラーであるGoogle-Extended(Gemini学習用)、GPTBot(OpenAI学習用)、ClaudeBot(Anthropic学習用)などが登場したことで、その役割は大きく変わりました。
Google、OpenAI、Anthropicなどの公式サイトで最新情報を確認することが重要です。
これらのクローラーへのアクセスを許可しても、直接的な検索順位の向上は見込めません。では、なぜ許可するのか?それは、新たな経済圏への参加チケットを手に入れるためです。
パラダイムシフト:トラフィック経済からデータ経済へ
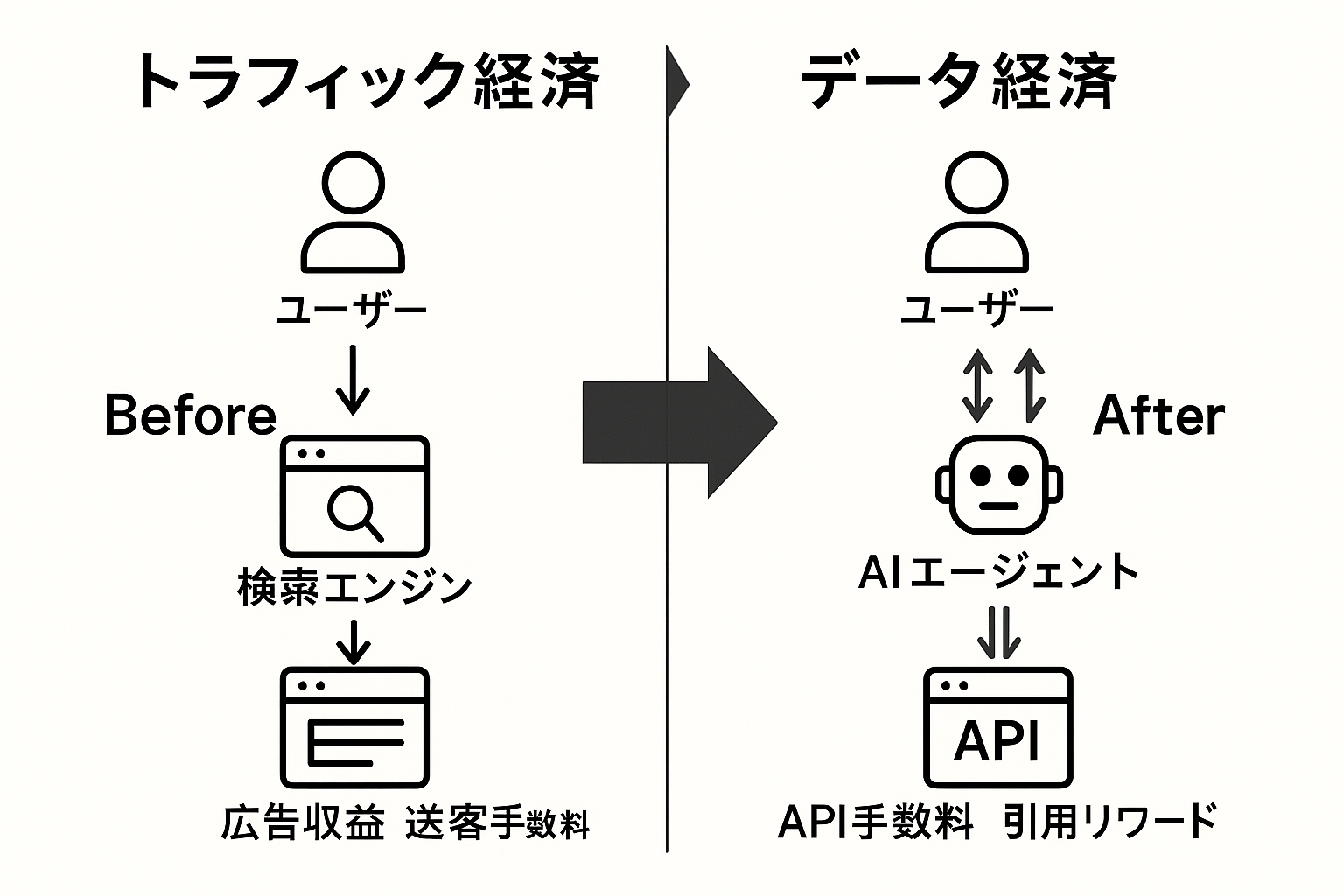
これまでのウェブは、Googleに無料でクロールさせる代わりに「トラフィック」を得る「トラフィック経済」でした。これからのウェブは、AIに高品質なデータを提供し、その見返りに「引用」や新たな形での価値創出を得る「データ経済」へと移行する可能性が議論されています。この変化は段階的に進むと考えられ、従来のトラフィック経済と並存しながら発展していく見込みです。
robots.txtは従来のアクセス制御を超えて、将来的にAIデータ利用に関する条件を定義するプロトコルへ進化する可能性が議論されています。
現時点では標準化は未確立ですが、W3Cや業界団体で実験的な試みが進行中です。この動きの背景には、Googleが開発者向けドキュメントでAIクローラーの制御方法を明記している事実や、コミュニティで機械可読なデータ利用許諾に関する議論が進んでいることがあります。
また、データの公正な利用に関するルール作りも具体化しています。Fairly Trainedは、元TikTok・Stability AIの幹部Ed Newton-Rexが設立した非営利団体で、Licensed Model (L) 認証を提供しています。
認証プログラムは非営利ベースで運営されています。具体的な認証条件や費用については、Fairly Trainedの公式サイトで詳細が公開されています。フェアユースに依存するモデルは認証対象外とする厳格な基準を採用しています。
Key Takeaways(持ち帰りポイント)
- ウェブサイトの価値は「解説」から「一次情報+構造化データ+API」へとシフト
- C2PAとタイムスタンプによる信頼性証明が競争上の必須要件に
- robots.txtがAIとのデータ利用条件を定義する重要なプロトコルへ
事例研究:旅行ブロガーBさんの進化 ― アフィリエイトからAPIトランザクションへ
要約:従来の送客型アフィリエイトから、独自API実装によるトランザクション手数料モデルへの進化事例
最後に、旅行ブロガーBさんの物語で、この新しい世界での進化の具体例を描いてみましょう。Bさんは「京都の隠れ家旅館」の体験記事を書き、大手予約サイトへ送客する従来型アフィリエイトを展開していました。
新世界のAPIトランザクションモデル
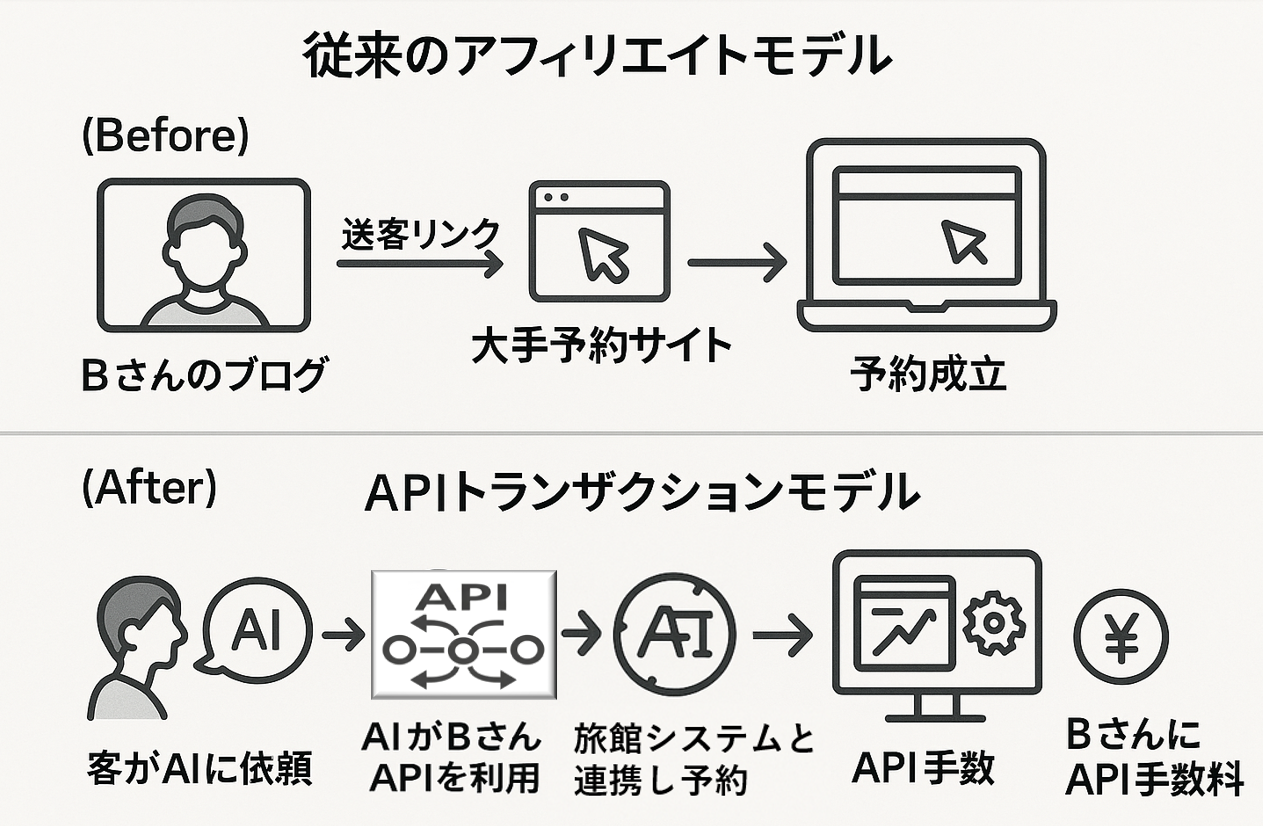
2025年、Bさんのサイトは単なるブログではありません。それは、提携する旅館の予約システムと連携する、自分自身の「予約API」を実装したプラットフォームです。
あるユーザーがAIに「Bさんおすすめの、玉子焼きが絶品の旅館を探して」と依頼します。AIエージェントはBさんの記事から「玉子焼き」という独自の一次情報を発見し、同時に彼女のサイトが予約APIを提供していることを認識します。
ユーザーが「はい」と答えた瞬間、AIはBさんのサイトの予約APIを直接呼び出し、予約を完了させます。このトランザクションが成功したことで、Bさんは旅館から「APIトランザクション手数料」を受け取ります。
まとめ
私たちは今、ウェブの歴史における最大の転換期に立っています。
目指すべきは、AIより優れた「解説」を書くことではありません。
AIには解説を任せ、私たちはAIが絶対に作れない「証拠」と、AIが実行したがる「行為」を提供することに特化するのです。共生ウェブの繁栄とは、単なる役割の変化ではありません。
それは、ウェブサイトの収益モデルが根底から変わる「グレート・リセット(AI時代の収益モデル再構築)」を意味します。
広告インプレッションに代わり、AIからの「引用リワード」(AIの生成回答で引用元として扱われることで発生する報酬)が収益の柱となり、アフィリエイトリンクに代わって「APIトランザクション手数料」が売上を支えるようになるでしょう。
もちろん、この変化への対応には具体的なチャレンジがあります。
技術面では、APIの設計・実装・保守に月額3万円〜30万円程度のコストが想定され(註:要件により大きく変動)、セキュリティ対策(認証・レート制限・DDoS防御)も必要です。法的面では、AIエージェントの自動取引における責任範囲や、データ利用契約の法的有効性についても検討が必要です。
また、ASP(アフィリエイトサービスプロバイダ)を利用している場合も、その仲介構造が永続的であるとは限りません。最終的にAIから評価される「一次情報」の価値を自社で高めていく視点が、今後のアフィリエイト戦略においても不可欠となるでしょう。
しかし、私たちはAIに奉仕するのではありません。AIという巨大な経済圏で正当な対価を得る、独立した「データ経済の主体」へと進化するのです。
専門用語まとめ
- Agent Experience (AX)
- AIエージェントがウェブサイト上でタスクを効率的に実行できるかを測るための新しいUX指標概念。公式な指標ではないが、AIとの連携を前提としたサイト設計の重要性を示す言葉として専門家の間で注目されている。
- C2PA (Content Credentials)
- コンテンツの作成者、作成日時、使用ツール、編集履歴などを改ざん不可能な形で記録する国際標準技術。EUのAI法が定めるAI生成コンテンツの出所開示義務への対応策として、その重要性が高まっている。
- データ経済
- 従来の「トラフィック経済」に代わる新しいウェブ収益モデル。サイト運営者がAIに高品質なデータを提供し、その見返りに引用料や APIトランザクション手数料を得る経済圏。robots.txtがその利用条件を定義する入口となり得る。
よくある質問(FAQ)
Q1. AIエージェント時代でもSEOは必要ですか?
A1. 必要です。ただしキーワード偏重よりも、一次情報と構造化データを基盤にした SEO へ進化させることが鍵となります。
Q2. API の実装にはどの程度の技術力が必要ですか?
A2. 基本的な REST API であればサーバーサイド開発経験で対応可能です。認証・レート制限まで考慮する本格実装には相応の知識が必要ですが、小規模事業者は外部サービスや既存プラットフォーム連携から始められます。
Q3. ASP(アフィリエイトサービスプロバイダ)利用サイトの今後は?
A3. 現時点で ASP は AI 連携に完全対応していませんが、将来的に API 提供へ移行する可能性があります。運営者は AI が参照したくなる一次情報を蓄積し、ASP の新スキームに備えることが必要です。
Q4. robots.txt で AI クローラーを制御できますか?
A4. 主な AI クローラー(Google-Extended, GPTBot, ClaudeBot 等)は robots.txt を尊重しますが、すべてではありません。将来はデータ利用条件も記述できる契約書的役割へ標準化が進む見込みです。
Q5. 小規模サイトでも対応が必要ですか?
A5. はい。むしろニッチな一次情報や専門性で差別化しやすいため、小規模サイトほど段階的導入によるメリットが大きいと言えます。
主な参考サイト
- Schema.org – 構造化データ標準仕様
- C2PA Alliance – Content Credentials公式サイト
- OpenAI – Web Crawling Bot Documentation
- Fairly Trained – 公式サイト
合わせて読みたい
- 2025年版:AIが奪えない仕事と人間の価値【IT業界の新常識】
- 気まぐれAI攻略法|プロンプト・テイミングの実践術
- 信頼と知能の融合:ブロックチェーンAI最前線
- AIが変えるセキュリティ|ゼロトラスト・RBVM・最新脅威を徹底解説
更新履歴
- 初版公開








