


CoreWeaveが拓くAIクラウド新時代:MFU最大化戦略の全貌
- 要点1:MFU最大化の要因(通信/I/O/スケジューリング最適化)
- 要点2:NVL72最適化×液冷×トポロジで実効スループット向上
- 要点3:GPUファイナンス+Take-or-Payでキャパ確保と価格安定
→ 技術は「MFUを最大化する技術的な堀」へ/契約・財務は「成長の秘密」へ。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
はじめに:AI効率性の最前線「ネオクラウド」の登場
 近年、人工知能(AI)の進化、特に大規模言語モデル(LLM)の爆発的な普及は、その基盤となるインフラストラクチャにも革命的な変化をもたらしています。この巨大な地殻変動の中心にいるのが、CoreWeave(コアウィーブ)という企業です。
近年、人工知能(AI)の進化、特に大規模言語モデル(LLM)の爆発的な普及は、その基盤となるインフラストラクチャにも革命的な変化をもたらしています。この巨大な地殻変動の中心にいるのが、CoreWeave(コアウィーブ)という企業です。
設立からわずか数年で、彼らはAWS(Amazon Web Services)やGCP(Google Cloud Platform)、Azureといった既存の巨大ハイパースケーラーが支配するAIインフラ市場に、鋭く食い込んでいます。
CoreWeaveは、従来の汎用クラウドとは一線を画します。彼らは、Webサーバーやデータベースといった一般的なワークロードではなく、AIとHPC(高性能コンピューティング)に不可欠なGPU(Graphics Processing Unit)に100%特化したサービスを運営しています。こうした新興の専門クラウドは「ネオクラウド(Neo-Cloud)」と呼ばれ、AI時代の新たなインフラ標準を定義しようとしています。
彼らの成功と競争力を測る最も重要な鍵、それがMFU(Model FLOPs Utilization:モデル演算効率)です。これは、GPUが持つ理論上の最大演算能力(FLOPs)のうち、実際にAIモデルの学習にどれだけ使えたかを示す割合です。
CoreWeaveは、Hopper世代のGPUでMFU 50%以上という数値を達成したと公表しており、これは一般的な公開ファンデーションモデルのトレーニング指標(概ね35~45%)と比較して最大+20%もの効率優位を誇る(CoreWeave自社分析)ことを示唆しています。
この「わずか10〜20%」の差が、AI開発の経済性に決定的な影響を与えます。例えば、GPT-4クラスのモデル学習には数億ドル(数百億円)のコストがかかると言われています。もしMFUが10%向上すれば、それは単純計算で数千万ドル(数十億円)のコスト削減、あるいは学習期間の大幅な短縮を意味します。この効率性こそが、AI開発の市場投入までの時間(Time-to-Market)を直接左右する、現代の経済的な主戦場なのです。そして、これこそがネオクラウドが巨大ハイパースケーラーに真っ向から挑戦する最大の根拠となっています。
本稿では、CoreWeaveがどのようにして金融畑からAIインフラの巨人へと変貌を遂げたのか、その劇的なストーリーと、汎用クラウドでは達成困難な驚異的MFUを実現する独自の技術スタック、そしてNVIDIAとの戦略的な共生関係について、深く掘り下げて解説します。
1. 意外な起源:ヘッジファンドと熱暴走したGPUマイニング

創業者のマイケル・イントレーター(Michael Intrator)、ブライアン・ヴェントゥーロ(Brian Venturo)、そしてブランニン・マクビー(Brannin McBee)の3人は、いずれも金融業界出身。
彼らは元々、天然ガス市場におけるアルゴリズム取引を手掛けるヘッジファンドを運営しており、データ処理と計算資源を武器にして利益を上げていました。
2017年、暗号資産市場が急拡大するなかで、彼らはGPUを使ったイーサリアム(Ethereum)マイニングに興味を持ちます。
最初は実験的な趣味として、数台のGPUを購入し、自分たちのトレーディングオフィスの一角で稼働させていました。
しかしすぐに、GPUの並列計算能力が生み出す収益に気づき、この“副業”が本業を上回る勢いを見せ始めます。
やがて彼らはニュージャージー州で「Atlantic Crypto」というマイニング企業を設立し、数百台規模のGPUファームを運営。
電力効率、冷却、運用自動化といった「高密度コンピューティング」のノウハウを短期間で蓄積していきました。
この経験が、後のCoreWeaveを支える技術基盤の原点となります。
当時のオフィスは、サーバーの排熱でまるでサウナのような環境だったといいます。
「朝出社すると、室内が灼熱になっていて、サーバーのファンが叫んでいるように回っていた」とヴェントゥーロは振り返っています。
この“熱暴走”事件をきっかけに、彼らはマンハッタンのオフィスを離れ、ニュージャージー郊外のガレージへと移転しました。
皮肉にも、金融街出身の彼らが、テクノロジー神話の象徴である“ガレージスタートアップ”の道を歩むことになったのです。

2019年、暗号通貨の冬が訪れると、多くのマイニング事業者が撤退していきました。
しかし彼らは、GPUの真価がAIやVFXレンダリング、科学シミュレーションなどの高性能計算(HPC)用途にあることを見抜きます。
ここで「Atlantic Crypto」は姿を変え、AI特化型クラウドインフラ企業「CoreWeave」として再出発しました。
イントレーターはCEOとして企業戦略を描き、ヴェントゥーロは後にCSO(Chief Strategy Officer)としてテクノロジーの方向性を担い、マクビーはChief Development Officerとしてビジネス開発を指揮。
彼らの組織体制は、かつての金融ヘッジファンド時代のロールをそのまま再構成したものです。
ウォール街仕込みのリスク管理とデータ駆動の意思決定が、AIクラウド時代の“GPUファイナンス”へと昇華しました。
今では、CoreWeaveはNVIDIAの戦略的パートナーとして知られ、AIトレーニングに最適化されたGPUクラスタを提供するまでに成長。
その始まりは、一つのガレージと、熱暴走したGPUたちだったのです。
2. クライシスからの戦略的転換:AIへのフルベット
 CoreWeaveの真の非凡さは、クリプトバブルの熱狂の真っ只中にありながら、市場の終焉を冷静に予測し、次の大きな波に備えて行動した点にあります。
CoreWeaveの真の非凡さは、クリプトバブルの熱狂の真っ只中にありながら、市場の終焉を冷静に予測し、次の大きな波に備えて行動した点にあります。
2018年、市場が過熱する中、彼らは「クリプトの冬」(市場の暴落)が来ることを予見していました。彼らはこのタイミングでシード資金を調達しましたが、その資金を事業拡大や人件費に使うことはしませんでした。代わりに、その資金を温存するという、投資家から見ればクレイジーな戦略を取りました。
彼らの狙いはただ一つ。暴落時に経営破綻する同業マイナーから、不良債権化したGPUや関連ハードウェアを二束三文で買い叩くことでした。
この逆張り戦略は見事に成功します。市場が暴落し、多くのマイナーが撤退を余儀なくされる中、彼らは貯め込んだ資金を放出し、わずか4億円弱(当時のレート)で約4万台もの中古GPUを手に入れたのです。これにより、CoreWeaveは極めて安価に、巨大なコンピューティング能力をその手に収めました。
このとき既に、彼らの視線はクリプトの先を見据えていました。彼らがASICではなく、あえてGPUを使うイーサリアムに注力していたのは、「GPUは汎用的な計算リソースであり、マイニングが終わっても、AI、機械学習、VFXレンダリング、創薬シミュレーションなど、他の領域に転用できる」という確信があったからです。
こうして、彼らは事業の焦点をエンタープライズ向けの「エンタメ(VFX)」、「創薬(ライフサイエンス)」、そして「AI」の3つに定め、社名を「CoreWeave」に変更。暗号通貨マイナーからの脱皮を宣言しました。

「儲かっているコンシューマー向けGPU(マイニング用)をすべて売却し、その資金でデータセンター向けのハイスペックGPU(NVIDIA A100など)を購入し直す」
当時は世界的なGPU不足の最中であり、マイニングを続ければ濡れ手に粟の状態でした。当然、社内や関係者からは猛反対されましたが、創業者たちはAIインフラへの完全移行を断行します。これにより、彼らは単なる「GPUの又貸し屋」から、本格的な「クラウドインフラ企業」へと完全に舵を切ったのです。
このAIへの確信を強めたのが、2つの重要な出来事でした。一つは、AIアプリケーション企業であるAI Dungeon(現Latitude)との導入事例で、AWSと比較してレイテンシが半減するなどの効果が公式に紹介され、彼らの技術的優位性が示されたこと。もう一つは、彼らのGPU運用能力に目をつけたNVIDIAから、直接声がかかったことでした。
そして2022年、まだChatGPTが登場し、世界が生成AIの熱狂に包まれる前夜。AI需要が本当に爆発するかは誰にも分からない状況下で、CoreWeaveは1億ドル(約100億円超)という巨額の資金を、データセンター向けGPUのさらなる調達にフルベットします。
この決断が運命を呼び寄せます。画像生成AI「Stable Diffusion」の開発元であるStability AIが、推論API(サービス提供用のインフラ)の構築を依頼しに来たのです。CoreWeaveが短期間で推論基盤を立ち上げ、Stable Diffusionが一般公開されると、事態は彼らの想像を超えました。急増する需要に対応する強力なオートスケーリング能力を実証し、彼らはAI需要が「本物」であることを、その目で捉えたのです。
3. MFUを最大化する技術的な堀

汎用クラウドは、もともとWebサイトのホスティング、データベース、データ保存など、多種多様な顧客のあらゆるニーズに応えるために構築されています。そのアーキテクチャは「柔軟性」と「マルチテナント性(リソースの共有)」を最優先としており、AIの分散学習のように「数千台のGPUが一つの巨大な計算機として、超低遅延で同期する」という特殊な要件には最適化されていません。
これは、汎用クラウドが持つ「イノベーションのジレンマ」と言えます。既存の巨大な顧客ベースと、それに最適化されたインフラ資産(仮想化技術、Ethernetネットワークなど)が足かせとなり、AI特化型の大胆なアーキテクチャ変更に踏み切れないのです。
| 評価軸 | 汎用クラウド(AWS, GCP, Azure等) | ネオクラウド(CoreWeave) |
|---|---|---|
| 主要ターゲット | 多様なITワークロード全般 | AI / HPC(大規模学習・推論)特化 |
| 最適化の優先順位 | 柔軟性、多用途性、リソース共有 | パフォーマンス、MFU(演算効率)最大化 |
| ネットワーク | Ethernet (汎用、一部RoCE対応) | InfiniBand (AI特化、超低遅延) |
| コンピュート基盤 | 仮想マシン (VM) が標準 | ベアメタル (Kubernetes) が標準 |
| アーキテクチャ | 既存資産の拡張(技術的負債) | AI専用にゼロから設計 |
| 判定根拠 | AI学習のような超並列・同期型ワークロードには、ネオクラウドの専用設計がMFU向上に直結する。 | |
CoreWeaveは、このジレンマを逆手に取り、GPU性能を100%引き出すことだけを目的とした、極めて専門的な技術スタックを統合しました。
3.1 ベアメタルとトポロジー認識スケジューラ
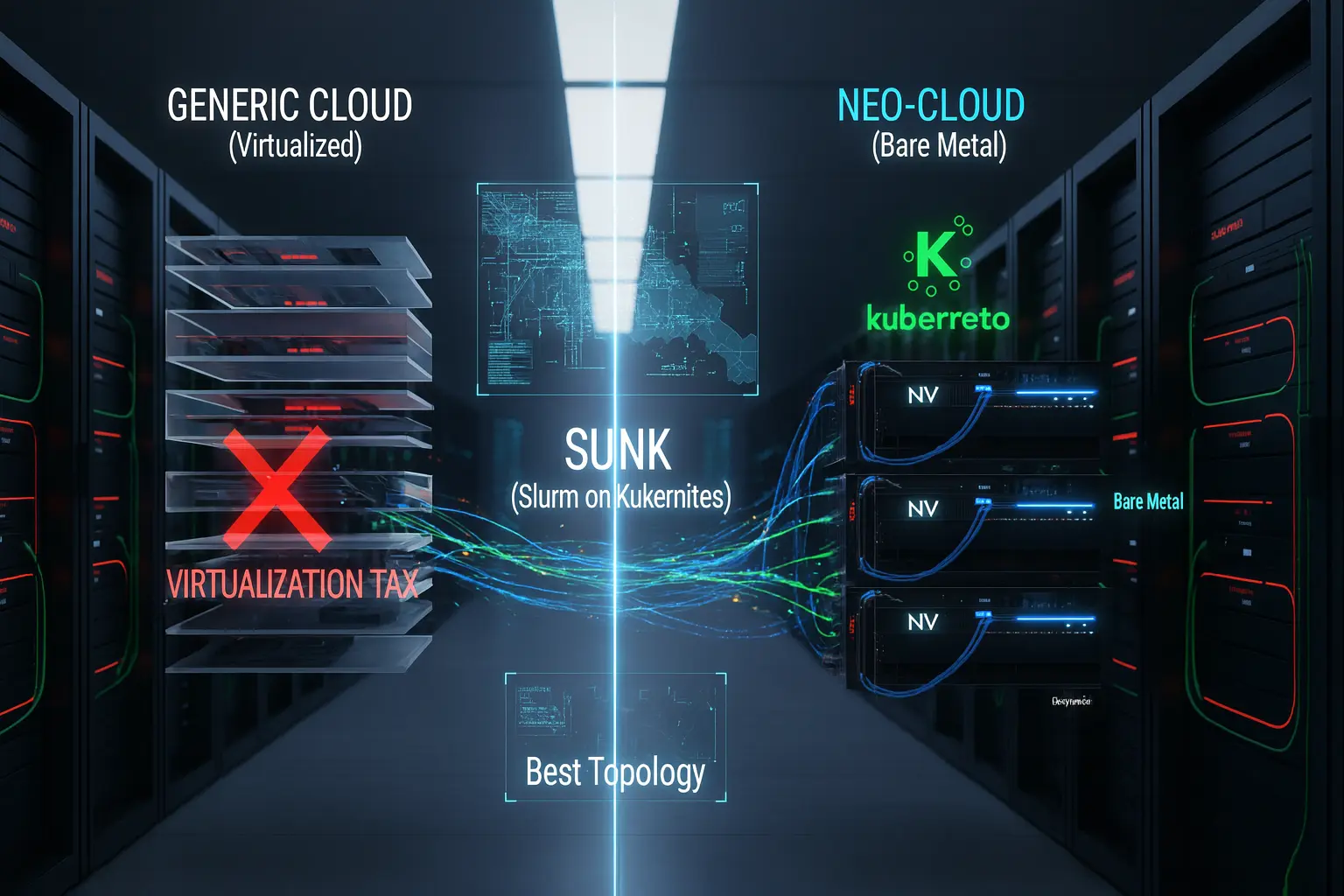 一般的なクラウドが採用する仮想化レイヤー(ハイパーバイザー)は、OSとハードウェアの間に介在し、リソースの分割やセキュリティを担保します。しかし、この抽象化レイヤーは、GPUのような高性能ハードウェアへのアクセスにおいて、ワークロードによってはオーバーヘッド、いわゆる「仮想化税(Virtualization Tax)」を発生させることがあります。
一般的なクラウドが採用する仮想化レイヤー(ハイパーバイザー)は、OSとハードウェアの間に介在し、リソースの分割やセキュリティを担保します。しかし、この抽象化レイヤーは、GPUのような高性能ハードウェアへのアクセスにおいて、ワークロードによってはオーバーヘッド、いわゆる「仮想化税(Virtualization Tax)」を発生させることがあります。
CoreWeaveはこれを根本から排除しました。彼らは、コンテナオーケストレーション基盤として業界標準であるKubernetes(K8s)を、仮想マシン上ではなく、GPUノードのハードウェア上で直接(=ベアメタル)稼働させます。これにより、仮想化によるオーバーヘッドを最小化し、アプリケーションがGPUの性能を直接引き出せるようにしています。
さらに、彼らはHPC(高性能コンピューティング)の世界で標準的に使われるスケジューラであるSlurmとKubernetesを統合した、独自のスケジューラ「SUNK(Slurm on Kubernetes)」を開発しました。SUNKはSlurmをKubernetesに統合するCoreWeaveの実装で、物理トポロジーを意識した割当により通信集約が必要な学習ジョブを近接GPU群へ配置→All-Reduce待ちを短縮しMFUを押し上げる。
3.2 超高速ネットワークファブリック(InfiniBand/SHARP)
 大規模なAIモデルの分散トレーニングでは、数千台のGPUが協調して計算を行います。その際、各GPUが計算した結果(勾配)を集約し、全員で共有する「All-Reduce」という同期操作が頻繁に発生します。これは例えるなら、クラス全員が自分のテストの点を計算し、それを集めてクラス平均を算出し、全員に知らせるような作業です。この通信が遅れると、計算を終えたGPUが「待ち状態」となり、MFUが劇的に低下します。
大規模なAIモデルの分散トレーニングでは、数千台のGPUが協調して計算を行います。その際、各GPUが計算した結果(勾配)を集約し、全員で共有する「All-Reduce」という同期操作が頻繁に発生します。これは例えるなら、クラス全員が自分のテストの点を計算し、それを集めてクラス平均を算出し、全員に知らせるような作業です。この通信が遅れると、計算を終えたGPUが「待ち状態」となり、MFUが劇的に低下します。
従来の汎用クラウドが多用するEthernetネットワーク(特にRoCE)は、多様なトラフィックを扱うため、時折発生する輻輳(ふくそう:混雑)やテールレイテンシ(遅延の最悪値)が、AI学習のような超同期的なワークロードのボトルネックになりがちです。
対照的に、CoreWeaveはHPCグレードのネットワーク技術であるNVIDIA Quantum-2 InfiniBandを全面的に採用しています。InfiniBandは、極めて低いレイテンシと、輻輳を回避する高度な制御機能(クレジットベースのフロー制御など)を備えた、AI学習に最適化されたネットワークです。
特に重要なのが、SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)という技術です。SHARPは集団通信(All-Reduce等)をInfiniBandスイッチASICで集約し、GPU側の待ち時間とメモリアクセス負荷を低減。勾配同期のテール遅延が縮み、SMの空転が減る=MFUが上がる。
★かみ砕き解説
SHARPは、AI学習で行われる「All-Reduce(全GPUの勾配を集めて平均する)」処理をGPUではなくネットワークスイッチ内で代わりに計算する技術です。スイッチ内の専用チップが、通信の途中で部分的な合計をどんどん計算し、最終的な結果を全GPUに配ります。これにより、通信の待ち時間を大幅に減らし、GPUは本来の学習作業に集中できます。つまり、SHARPは「ネットワークが自分で計算を手伝う仕組み」で、AIの学習をより速く、効率的にします。
3.3 液体冷却システムの標準化

GPUは高温になると、自身を保護するために動作クロックを下げる「サーマルスロットリング」が発生します。これはMFUの直接的な低下を意味します。つまり、どれだけ高性能なGPUを並べても、「熱」という怪物を抑制できなければ、その性能を維持できないのです。
CoreWeaveは、この問題を解決するために、Direct-to-Chip(チップ直接)液体冷却を標準装備したデータセンターを設計・構築しています。2025年から新設されるデータセンターは、GB200 NVL72のような次世代機の高密度実装を想定し、液体冷却が前提となっています。冷却方式の継続的な更新こそが、MFU低下(サーマルスロットリング)を抑制する鍵となります。これは、冷却液をパイプでCPUやGPUのチップ表面まで運び、直接熱を奪い去る方式です。空冷よりも圧倒的に効率的に熱を除去できるため、GPU/CPUを常時安定した低温に保ち、長時間にわたってピーク性能を維持させることができます。
3.4 I/Oボトルネックの排除
AIの学習プロセスは、「1. ストレージから学習データを読み込む」「2. GPUで計算する」「3. ネットワークで同期する」というサイクルで構成されます。このうち「1. データの読み込み」が遅れると、GPUは計算するデータがなくなり、アイドル状態(I/O待ち)になってしまいます。
汎用クラウドでは、S3のようなオブジェクトストレージやNFS(ネットワークファイルシステム)が使われますが、これらはネットワーク越しのアクセスとなるため、レイテンシが発生します。
CoreWeaveは、このI/Oボトルネックを排除するため、AI特化型のキャッシングレイヤーであるLOTA(Local Object Transport Accelerator)を独自に開発しました。これは各GPUノード常駐のS3互換ゲートウェイで、ノード内NVMeへの自動キャッシュにより構成により最大約7 GB/s/ GPUのスループットを実現する(CoreWeave製品ページ。環境により性能は変動)。
4. 成長の秘密:GPUファイナンスとNVIDIAとの共生関係
要約:核心は金融技術「GPUファイナンス」とNVIDIAとの強固なアライアンス。これが他を圧倒する成長の源泉です。
CoreWeaveが持つこれらの技術的な優位性は、従来のスタートアップとは一線を画す革新的な資金調達戦略と、NVIDIAとの深く戦略的なアライアンスによって、さらに強力に加速されています。
4.1 GPUファイナンスの発明
 AIインフラビジネスは、極めて資本集約的(=金食い虫)です。最新のGPUは1基数百万円もします。CoreWeaveが数万、数十万台規模でGPUを調達するには、数千億円、あるいは兆円単位の資金が必要となります。
AIインフラビジネスは、極めて資本集約的(=金食い虫)です。最新のGPUは1基数百万円もします。CoreWeaveが数万、数十万台規模でGPUを調達するには、数千億円、あるいは兆円単位の資金が必要となります。
しかし、創業間もないCoreWeaveには、AWSやGoogleのような信用力はありません。従来の銀行融資では、GPUのような急速に陳腐化するハードウェアを担保に巨額の融資を受けることは困難でした。かといって、エクイティ(株式発行)で兆円単位の資金を調達すれば、創業者の持分は極端に希薄化してしまいます。
ここで、彼らの金融畑の出自が活きました。彼らが発明したのが、通称「GPUファイナンス」と呼ばれる手法です。これは、ハードウェア(GPU)そのものではなく、「将来の計算能力に対する、信用力の高い顧客との長期契約」を担保として、巨額の負債(デット)を調達する手法です。
具体的には、まずOpenAI、Microsoft、(報道によれば)MetaやNVIDIAなど、信用力の高い大手AIラボとの間で、数年間にわたる数千億円、時には数兆円規模の「コンピューティング利用契約」を締結します。そして、その「契約書(=将来の安定したキャッシュフロー)」を担保として金融機関(Blackstone, Magnetar Capitalなど)に見せるのです。
金融機関からすれば、「CoreWeaveは小さくても、その顧客であるOpenAIやMicrosoftが契約不履行(倒産)する可能性は極めて低い」と判断できます。つまり、CoreWeaveの信用力ではなく、顧客の信用力を担保に資金を貸すのと同じ状態になるのです。
この革新的な手法により、CoreWeaveはエクイティ(株式)での希薄化を最小限に抑えながら、巨額の資金調達を可能にしました。例えば、2024年5月にはBlackstoneやMagnetarが主導する75億ドルのデット調達枠が報じられ、2024年末時点で総負債約$7.9B(S-1要約)。IPOは2025/3/31に$1.4Bネット調達を公表(Form 8-K/Q)。さらに2025年7月には26億ドルの追加デットも発表されており、この資金でライバルに先駆けて最新GPUを大量購入し、インフラを先行して構築するという、圧倒的なスピード感を手に入れています。
4.2 NVIDIAとの密月関係
CoreWeaveの驚異的な成長は、GPUの生みの親であるNVIDIAとの共生関係なくして語れません。
NVIDIAは早期からCoreWeaveに出資し、強力なパートナーシップを結んでいます。現在、CoreWeaveは、NVIDIAの最上位パートナー資格の一つである「Elite Cloud Services Provider for Compute」に早期から認定されています(この認定社数は固定ではなく、NVIDIAの方針に基づき変動します)。
この地位により、CoreWeaveは、巨大なハイパースケーラーたちと(場合によっては彼らよりも)同等、あるいはそれ以上に優先的に、H100や次世代のBlackwell GB200 NVL72といった、世界中が奪い合う最新チップの供給を受けることができます。
さらに特筆すべきは、両社が結んだ「テイク・オア・ペイ(Take-or-Pay)」契約です。2023/4の枠組みの更新により、NVIDIAは未販売のCoreWeaveクラウド容量を 2032/4/13まで購入する条項を含む$6.3Bの契約に合意(公表は2025/9)。
これはCoreWeaveにとって、まさに究極のセーフティネットです。巨額のGPU購入資金を調達する上で、金融機関に対して「最悪でもNVIDIAが買い取ってくれる」という安定した収益予測(=返済原資)を示すことができます。事実上、AIコンピューティングの需要リスクをNVIDIAがヘッジしてくれているのです。
なぜNVIDIAはここまでCoreWeaveを優遇するのでしょうか。それは、NVIDIAにとってCoreWeaveが、AWSやGCPといったハイパースケーラーに対する強力な「牽制球」であり、交渉材料となるからです。もしハイパースケーラーがNVIDIAチップの購入を渋ったり、自社製AIチップ(GoogleのTPUやAmazonのTrainiumなど)への移行をちらつかせたりしても、NVIDIAには「CoreWeaveという、NVIDIAの最新技術を100%の効率で提供できる、忠実なクラウド部門」が存在します。この極めて深い関係性から、CoreWeaveは一部で「NVIDIAのクラウド部門」、あるいは「NVIDIAの息子」とまで揶揄されており、NVIDIAのAIエコシステム戦略において、欠くことのでない戦略的な存在として機能しているのです。
結論:AIインフラストラクチャの構造的再編
要約:MFU最大化を軸にしたフライホイールが完成。AI開発は汎用クラウドとネオクラウドの「ハイブリッド戦略」が賢明です。
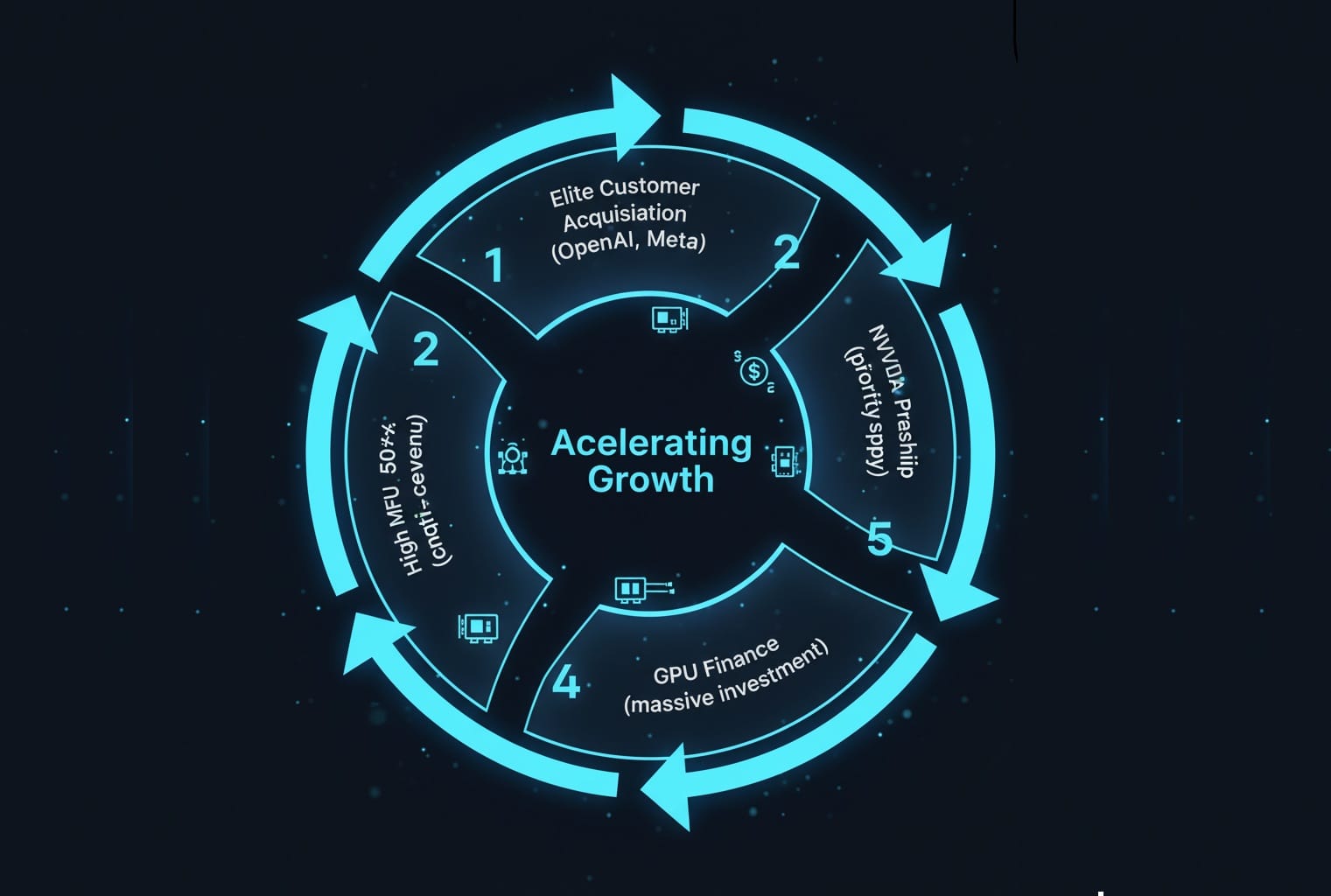
MFU(モデル演算効率)の最大化を組織原理の中心に据えたネオクラウドは、以下の要素からなる強力な「フライホイール効果」によって、その成長を自己強化させています。
- 高MFUの達成(50%超): AI特化の技術スタック(ベアメタル、InfiniBand、液体冷却)により、汎用クラウドを凌駕するコスト効率を実現。
- エリート顧客の獲得: 最高の効率を求めるOpenAIやMicrosoftなどのフロンティアAI企業が顧客となる。
- 長期契約による安定収益: 信用力の高い顧客との長期契約を確保。
- GPUファイナンスによる巨額投資: 安定収益を担保に、革新的なファイナンスで巨額の資金を調達し、最新GPUを先行導入。
- NVIDIAとの密月による優先供給: NVIDIAの戦略的パートナーとして、希少なGPUの供給を確保し、技術的優位性をさらに高める。(1.に戻る)
この専門的なアプローチは、汎用クラウドの「ワンサイズ・フィット・オール(One-size-fits-all)」モデルが持つ限界を浮き彫りにしました。もちろん、AWSやGCPがAI競争から脱落するわけではありません。彼らもまた、InfiniBandの導入やNVIDIAとの連携強化(例:NVIDIA DGX Cloudのホスティング)など、AI特化型インフラのキャッチアップを急いでいます。他方、OCIはNVL72対応を公表、AWSもIRHXなど独自液冷系で高密度GPUに対応するなど、汎用クラウドも高速に追随している。
しかし、今後、企業のインフラ戦略は明確に二極化していく可能性が高いでしょう。Webサービスや社内システム、小規模なAI推論といった汎用的なワークロードには、引き続きハイパースケーラーの多様なサービスを利用しつつ、MFUの1パーセントポイントが数億円のコスト削減に直結するような、フロンティアAIモデルの研究開発や大規模学習には、CoreWeaveのような専門的なネオクラウドを活用する——。そのような「ハイブリッド戦略」が、AI時代の賢明な選択となっていくはずです。
CoreWeaveは、単なる技術革新に留まらず、金融、サプライチェーン、そしてデータセンター設計の全てを「AIの効率最大化」という一点で再構築しました。GPUの供給が「麻薬を手に入れるより難しい」とまで言われる現代において、彼らは最も希少で、最も効率的なコンピューティング資源を供給する「AIファクトリー」としての地位を確立しました。
(2025年10月には、新興AI企業Poolsideとの提携が報じられ、西テキサスの“Project Horizon”で最大2 GW構想。初期250 MW→500 MW拡張を段階的に進め、GB300 NVL72を12月から4万枚規模で供給見込み(報道)。その勢いは留まることを知りません。)
AIの進化が続く限り、CoreWeaveの専門性と効率性に対する需要は、高まり続けるでしょう。
専門用語まとめ
- MFU (Model FLOPs Utilization)
- GPUの理論上の最大演算能力(FLOPs)に対し、AI学習で実際に利用できた演算の割合を示す効率指標。これが1%向上するだけで数億円のコスト削減に繋がるため、AI開発で最も重要視される。
- ネオクラウド (Neo-Cloud)
- AWSなどの汎用クラウド(ハイパースケーラー)とは対照的に、AIやHPCなど特定の高性能ワークロードに100%特化してゼロから設計された新興クラウド。CoreWeaveが代表例。
- GPUファイナンス
- CoreWeaveが編み出した資金調達手法。OpenAI等の大口顧客との将来の「クラウド利用契約書」を担保に、金融機関から巨額のデット(負債)を調達し、最新GPUへの先行投資を実現する。
- テイク・オア・ペイ (Take-or-Pay) 契約
- 「引き取るか、さもなくば支払え」という契約。CoreWeaveとNVIDIAの契約では、CoreWeaveのGPU容量が売れ残った場合、NVIDIAがその分を購入(または支払い)することを指す(報道ベース)。
- InfiniBand (インフィニバンド)
- AIの大規模分散学習に用いられる高性能ネットワーク規格。Ethernetと比べ、圧倒的な低遅延と高帯域幅を誇り、数千GPUの同期通信(All-Reduce)ボトルネックを解消する。
- SHARP (Scalable Hierarchical Aggregation and Reduction Protocol)
- NVIDIAのネットワーク技術。AI学習時の「All-Reduce」(全GPUの計算結果の集約)を、CPUではなくInfiniBandスイッチ自体が実行(オフロード)し、通信遅延を劇的に削減する。
- ベアメタル (Bare Metal)
- 仮想化レイヤー(ハイパーバイザー)を介さず、OSやアプリケーションが物理サーバーのハードウェアを直接利用する形態。仮想化による性能オーバーヘッド(仮想化税)を排除できる。
- SUNK (Slurm on Kubernetes)
- CoreWeaveが開発したスケジューラ。HPC界の標準「Slurm」とコンテナ標準「Kubernetes」を統合し、GPUの物理配置(トポロジー)を認識した最適なジョブ割り当てを実現する。
- LOTA (Local Object Transport Accelerator)
- CoreWeave独自のストレージ技術。S3互換のオブジェクトストレージから、AI学習データを各GPUノードの高速ローカルSSDに自動キャッシュし、I/O(読み込み)ボトルネックを排除する。
- サーマルスロットリング
- GPUやCPUが、高負荷による発熱で自身の許容温度を超えた際、故障を防ぐために動作クロック(速度)を自動的に低下させる保護機能。液体冷却はこれを防ぎ、MFUを高く維持するために不可欠。
よくある質問(FAQ)
Q1. MFU (モデル演算効率) とは何ですか? なぜ重要なのですか?
A1. MFU (Model FLOPs Utilization) は、GPUが持つ理論上の最大演算能力(FLOPs)のうち、実際にAIモデルの学習にどれだけ使えたかを示す割合です。例えばMFU 50%は、GPUの力の半分しか引き出せていないことを意味します。AIの学習には数億ドルのコストがかかるため、MFUを1%でも高めることが、開発コスト(数千万円単位)の削減と開発期間の短縮に直結するため、最も重要な指標とされています。
Q2. CoreWeaveのSHARP技術とは何ですか?
A2. SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) は、NVIDIAのネットワーク技術です。大規模なAI学習では、全GPUの計算結果を集約・平均化する「All-Reduce」という通信が頻繁に発生します。SHARPは、この集約計算をサーバー(CPU/GPU)で行う代わりに、ネットワークスイッチ自体がデータ通過中に行う(オフロードする)技術です。これにより通信の待ち時間を劇的に短縮し、GPUが計算に集中できる時間を増やし、結果としてMFUを向上させます。
Q3. なぜNVIDIA NVL72ラックには液体冷却が必要なのですか?
A3. NVIDIAのGB200 NVL72のような次世代AIシステムは、1ラックで120kWを超える(家庭用エアコン数十台分)膨大な電力を消費し、そのほとんどが熱になります。従来の空冷方式ではこの熱を効率的に除去できず、GPUが高温になり性能を落とす「サーマルスロットリング」が発生し、MFUが低下します。Direct-to-Chip(チップ直接)液体冷却は、この膨大な熱を効率的に除去し、GPUを低温に保ち、ピーク性能を維持するために不可欠な技術となっています。
Q4. 「GPUファイナンス」とは何ですか?
A4. CoreWeaveが編み出した革新的な資金調達手法です。通常、スタートアップが銀行から巨額の融資を受けるのは困難ですが、CoreWeaveはOpenAIやMicrosoftといった信用力の高い大口顧客との「将来のクラウド利用契約書」を担保にしました。金融機関は「CoreWeave」ではなく「契約相手のMicrosoft」の信用力を元に融資を判断できるため、CoreWeaveは巨額のデット(負債)を調達し、最新GPUを先行投資することが可能になりました。
主な参考サイト
- CoreWeave (Official): “NVIDIA H100 Benchmarks for Large-Scale Training”(2025)
- CoreWeave (Official): “CoreWeave Becomes NVIDIA’s First Elite Cloud Services Provider for Compute”(2021)
- SEC.gov: “CoreWeave, Inc. – Form S-1 Registration Statement”(2025)
- Barron’s: “Nvidia Has a New $6.3 Billion Deal With CoreWeave. What It Means.”(2025)
- Supermicro: “ARS-8422G-NVL (for GB200 NVL72) Data Sheet”(2025)
合わせて読みたい
- AIインフラ戦争2025|NVIDIA×OpenAI・45兆円契約の全貌
- NVLink vs Broadcom論争の真相|AIネットワークの力学を読み解く
- NVIDIA発・AIファクトリー横断「スケールアクロス」最前線2025
- Oracle Cloud AI戦略:タイタンの賭けと「Stargate」が拓くAIデータセンター
- AIが金を掘る時代へ:NVIDIA GTC 2025が示したトークン採掘の未来
更新履歴
- 初稿アップ
以上








