【2026年技術トレンド】巨大モデル依存からの脱却!「SLM×エッジAI」が賢いコスト戦略になる理由
「ちょっとしたメールの要約に、なぜ毎回数円のコストを払うのですか?」
2025年末、クラウド破産を恐れる多くのCTOやCFOが、この素朴な疑問に直面し、社内では「AIの使い過ぎか、使わなさ過ぎか」という静かな論争が始まっています。
GPT-5やGemini 3といった「巨大戦艦(LLM)」は確かに高性能ですが、すべての業務にそれを使うのは、コンビニに行くのにF1カーを使うようなものです。
今、賢い企業がこぞって採用し始めているのが、「SLM(Small Language Models:小規模言語モデル)」と、それを自社デバイス内で動かす「エッジAI(オンデバイスAI/ローカルLLM)」戦略です。
本記事では、性能を維持したままAIコストを劇的に最適化し、機密データをクラウドに出さないことでセキュリティリスクを大幅に抑える「小さくて賢いAI」の活用法を解説します。
「とりあえず何でもクラウドLLMに投げる」という時代は終わりつつあります。2026年の勝ち筋は、汎用的な巨大モデルから知識を蒸留し、特定のタスクに特化した「軽量モデル(SLM)」を自社環境(エッジ)で走らせるハイブリッド運用です。
超ざっくり言うと:クラウド上の巨大AIは「先生役」として使い、実務はそこで教育された軽量な「生徒役(SLM)」に任せましょう。これにより、「クラウドへの通信コストほぼゼロ」「クラウド往復がない超低遅延」「機密情報を外部に出さない設計」の3つを同時にねらえます。
業界で厳密な基準が決まっているわけではありませんが、おおよそ10B未満程度のモデルをSLMと呼ぶことが多いです。ChatGPT(数千億〜兆パラメータ)に比べて知識の幅は狭いですが、特定のタスク(要約、翻訳、分類など)に限れば、同等の精度をPCやスマホ単体で高速に出すことができます。
ただし、長文のRAGや大規模な並列処理など、すべてをローカルで賄うのはまだ現実的でないケースも多く、「どこまでをエッジに寄せ、どこからをクラウドに残すか」の線引きが2025〜26年時点の実務的なテーマになっています。
従量課金のクラウドAIは使えば使うほど赤字になりますが、SLMなら自社サーバーやPCで動くため、主なコストはサーバーやAI PCの設備費と電気代・保守費用といった固定費寄りになり、API従量課金よりも予算コントロールがしやすくなります。また、データを社外クラウドに出さずに処理できるため、クラウド経由の漏洩リスクは大きく抑えられます。
実際、海外の市場調査会社の一部試算では、SLM関連市場は2020年代後半〜2030年前後にかけて数倍規模に拡大し、年平均成長率(CAGR)も2桁台の伸びが続くと見込まれています。
もちろん、レポートによって具体的なドルの桁や数字には違いがありますが、重要なのはそこではありません。「小さなモデルに対して、本気の投資と人材シフトが始まっている」という方向性そのものが、ほぼ共通認識になりつつある、という点です。
巨大モデルの知識をSLMに教え込む「蒸留(Distillation)」という技術や、良質なデータを学習させることで、特定業務では「より大きなモデルと同等か、それに近い水準」の性能を示すケースも出てきています。一部のベンチマークでは、小さなモデルが特定タスクでより大きなモデルを上回る例も報告されています。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
この記事の構成:
- 「LLM一択」の時代が終わった経済的理由
- SLM × エッジAI がもたらす「3つの革命」
- 巨大モデルから知識を移す「蒸留(Distillation)」の技術
なぜ今、「巨大モデル(LLM)」離れが起きているのか

2023年から2024年にかけては、「より大きく、より賢い」モデル(GPT-4やClaude 3.5など)を競う時代でした。これはScaling Laws(規模の法則)により、モデルサイズを大きくすればするほど賢くなることが証明されていたためです。
この時期、企業にとっては「自前でサーバーを持つ(CapEx)」よりも、進歩の速い技術を「クラウドで借りる(OpEx)」方が、リスクが低く合理的でした。
しかし、2025年後半にかけて潮目は明確に変わりつつあります。
多くの企業で、「性能一辺倒」から「ROI(費用対効果)と運用コスト」を重視するフェーズに移行してきました。
LLM(大規模言語モデル)には、ビジネス実装における致命的な弱点が3つあります。
- コストが高い: APIの従量課金は、全社員が毎日使い始めると膨大な額になります。
- 遅い(レイテンシ): クラウドへデータを往復させるため、リアルタイム応答には不向きです。
- データが出せない: 機密情報や顧客データを外部クラウドに送信することへの抵抗感は根強いままです。
そこで登場した救世主が、GoogleのGemma 3ファミリー(とくに 1B/4B/12B の軽量版)、MicrosoftのPhi-4-mini(3.8B)を含む Phi-4 シリーズ、MetaのLlama 3.2(1B/3B)などに代表される「SLM(小規模言語モデル)」です。
これらはパラメータ数を極限まで削ぎ落としつつ、推論能力を維持することに成功しました。さらに、Apple Intelligence や Copilot+ PC に象徴される「オンデバイスAI/AI PC」の潮流も、この「小さくて賢いモデルを手元で動かす」という方向性を後押ししています。
SLM × エッジAI がもたらす「3つの革命」

少しだけ、あなたの会社の1日を思い浮かべてみてください。
朝イチの経営会議。CFOがこう言います。
「チャットボットやメール要約のクラウド料金、じわじわじゃなくてドカンと増えていませんか?」
昼には、情報システム部門から報告が上がります。
「クラウドに出せない機密データが増えていて、『AIに投げられない仕事』がまだまだ残っています。」
夕方、工場やコールセンターの現場からはこう聞こえてきます。
「AIの返事があと0.1秒早ければ、お客様との会話がもっと自然になるのに…」
この3つの悩み――コスト・セキュリティ・速度――を、一気にまとめて解決しようとするのが「SLM × エッジAI」という考え方です。
ここでは、難しい専門用語は一旦忘れて、「会社の日常」を舞台にしながら、3つの革命を順番に見ていきます。
1. コスト革命:「サブスク(変動費)」から「資産(固定費)」への回帰
まずは、朝イチの経営会議のシーンからです。
これまで多くの企業は、「AIはクラウドで使うのが当たり前」という前提で動いてきました。
確かに最初は楽です。サーバーを買う必要もなく、使った分だけ月額で払えばいい。いわば、レンタカーでF1カーを借りている状態です。
ところが、社内でAI利用が当たり前になると状況が変わります。
メールの下書き、議事録の要約、コードレビュー、FAQ回答……。
「社員が24時間、当たり前のようにAIを使う」ようになると、従量課金は一気に「青天井のコスト」に変わります。
このときに発想を切り替えるのが、SLM × エッジAI のコスト革命です。
- これまで:クラウドLLMの従量課金(OpEx=変動費)
┗ 使えば使うほど請求額が増える。「止めたくても止められないサブスク地獄」状態。 - これから:NPU搭載PCやエッジサーバーを買って、SLMを自社で動かす(CapEx=固定費)
┗ 最初に設備を買い、その後の推論コストはほぼ電気代のみ。減価償却も可能。
イメージとしては、「レンタカーを卒業して社用車を買う」ようなものです。
頻繁に乗るようになると、ずっとレンタカーを借り続けるのはもったいない。
AIも同じで、毎日使うなら“買ってしまった方が安い”ラインを超えつつある、というのが今の状況です。
もちろん、最初の投資は必要です。しかし一度、AI PC+SLMの基盤を整えてしまえば、
日々のメール要約やマニュアル検索などの「定型業務」は、ほぼゼロ円に近いコストで回せるようになります。
CFOの立場から見ると、「読めない従量課金」から「読みやすい固定費」へと原価構造を作り替えられるわけです。
2. セキュリティ革命:「防御」から「遮断」へ
次は、昼のセキュリティ報告のシーンです。
クラウドAIを使うということは、一度、社外にデータを出すことを意味します。
契約や技術的な対策は進んでいるとはいえ、「そもそも外に出したくないデータ」も増えてきました。例えば、未発表の製品情報、M&Aの検討資料、個人情報を含む相談履歴などです。
従来の発想では、「外に出すのだから、とにかく強固な“城”をつくる」という方向に進みがちでした。
高価なセキュリティ製品、SOC、監視ツール……。
もちろん重要ですが、やろうと思えばいくらでも投資が膨らみます。
ここでSLM × エッジAIが提案するのは、発想の転換です。
- これまで:データをクラウドに出す前提で、「どうやって守るか」を考える(守備強化型)
- これから:そもそもデータを社外に出さないようにし、攻撃対象そのものを減らす(遮断型)
具体的には、SLMをローカルPCやエッジサーバー、あるいはエアギャップ環境に閉じ込めるイメージです。
社員は普段通り、AIに文書を投げたり、コードを貼り付けたりしますが、そのデータは社内ネットワークから一歩も外に出ません。
これは、家の外壁を何重にもするのではなく、そもそも「大事な金庫は地下室に置いて、家の外には出さない」という考え方に近いです。
つまり、
- 攻撃者から見える「入口」を減らす(Attack Surface の極小化)
- クラウド経由の情報漏洩リスクを構造的に下げる
- すべてをSOC任せにするのではなく、アーキテクチャそのものを安全側に寄せる
結果として、「守るためのお金」も「万が一のリスク」も一緒に下げられるのが、
SLM × エッジAIによるセキュリティ革命です。
3. 速度革命:「通信」の物理的限界を超える
最後は、夕方の現場の声です。
AIチャットがどれだけ賢くても、返事に1〜2秒かかると、会話としては微妙にストレスを感じます。
ましてや、工場のロボットアーム制御や自動運転、対話型アバターなど、0.1秒を争う世界では、「クラウドに投げて結果を待つ」という構成そのものが限界に来ています。
ここで立ちはだかるのが、「光の速さ」と「クラウド側の待ち行列」という物理的な壁です。どれだけ回線を太くしても、クラウドと行ったり来たりしている限り、一定以上は速くなりません。
そこで、SLM × エッジAIの出番です。
- 推論処理そのものを、ユーザーの手元のPCやスマホ、工場内サーバーで完結させる
- クラウドとの「往復」をなくし、入力 → 推論 → 出力をローカルで完結させる
これにより、ユーザーから見ると、「押した瞬間に返事が返ってくる」ような体感速度が実現しやすくなります。
とくに、
- 工場のロボットアーム制御
- 自動運転・ドローン制御
- 店舗やコールセンターでの対話型アバター
といった、少しの遅れが事故や不満につながる領域では、
クラウドLLMよりも、オンデバイスで動かすSLMの方が「安全かつ快適」な選択肢になります。
要するに、「頭のいいAIを、できるだけ人や機械の近くに置く」ことで、
速度に関するストレスを根本から取り除こう、というのが速度革命の本質です。
こうして、朝の経営会議ではコスト、昼のセキュリティ報告ではデータ主権、夕方の現場からはレイテンシの不満が上がる――そんな1日を何度か繰り返したあとで、ようやく経営と現場の視点が交わる瞬間が訪れます。
その日の最後、CTOとCFOは同じ結論にたどり着きます。
「もう“何でもクラウドLLM”はやめよう。先生役はクラウドに残しつつ、日々の仕事は社内の“小さな生徒(SLM)”に任せよう。」
この「先生はクラウド、働くのはエッジの生徒」という役割分担こそが、SLM × エッジAIという新しい常識への第一歩になっていきます。
ここまで見てきたように、SLM × エッジAIは決して「小さいモデルだから安くてショボい」戦略ではありません。
むしろ、
- 「毎日使うなら“買った方が安い”」というコストの常識
- 「外に出さない方が安全」というセキュリティ設計
- 「そばに置けば速い」という物理法則
といった、ビジネスと物理の当たり前をベースにした、とても地に足のついた戦略です。
その戦略の“エンジン”を担うのが、まさにSLM × エッジAIなのです。
「蒸留(Distillation)」:巨人の肩に乗る技術

ここまで見てきた「コスト・セキュリティ・速度」の3つの革命は、実は“モデルの中身”の工夫によって支えられています。 小さなモデルに大きな役割を担ってもらうためには、「どうやって賢さをコンパクトに詰め込むか」という工夫が欠かせません。
「でも、小さいモデルは頭が悪いんでしょ?」
多くの方が最初にこう感じます。しかし実は、「巨大モデル(LLM)は現場で直接使うため」ではなく、「小さいモデル(SLM)の先生になるため」にも存在しています。
この「先生の頭の中だけを、生徒にうまくコピーする技術」が、知識の蒸留(Knowledge Distillation)です。
1. 要は「賢いモデルの“考え方”だけを小さく移す技術」
ふつうの学習では、AIは「正解ラベル」だけを学びます。
例:「このメールは『クレーム』です」 のように、最終結果だけを教えるイメージです。
一方、蒸留では「巨大モデル(教師)」が出した、よりリッチな情報をそのまま学習に使います。
- 正解ラベルだけでなく
- 「他の選択肢をどれくらいあり得ると考えたか」という確率分布(Soft Label)
- 場合によっては、途中の思考プロセス(CoT: Chain of Thought)
といった情報まで、小さいモデルに渡します。
つまり、「最終的な答え」だけでなく、「どのように迷ったか」「どんな基準で判断したか」という 思考の筋道ごとコピーして覚えさせる のが蒸留です。
その結果、小さいモデルでも、かなり大きなモデルに近い判断ができるようになります。
Chain of Thought(CoT)って何?
人間でいう「メモ書きしながら考える」「途中計算を書く」に相当する
モデルの内部では、
- 問題の分解
- 条件整理
- 式の展開
- 選択肢の比較
…みたいな“中間ステップの文章”を、トークン列として生成しながら考えています。これが Chain of Thought(思考の連鎖) と呼ばれるものです。
2. 天才数学者と受験生のたとえ
ここで、よくある「天才数学者と受験生」の例でイメージしてみましょう。
パターンA:答えだけ教える(通常の学習)
- 天才(LLM):「この難問の答えは『5』だ。」
- 生徒(SLM):「へぇ、5なんだ。(理由は分からないけど、丸暗記しておこう)」
これでは、生徒は問題の意味を理解していないので、少し問題文が変わると解けなくなります。
パターンB:解き方を教える(知識の蒸留)
- 天才(LLM):「答えは『5』だけど、『4.8』もかなり惜しい。『100』は論外だ。なぜなら、途中のこの計算で…という流れになるからだ。」
- 生徒(SLM):「なるほど。5という結果だけでなく、『どう考えれば5に辿り着くか』という思考パターンが分かったぞ。」
蒸留とは、このパターンBを大量の問題で繰り返すイメージです。
天才が持っている「解き方のクセ」「迷い方」「ここは重要、ここは無視してよい」という感覚を、
小さなモデルに圧縮してコピーする作業だと考えると分かりやすくなります。
3. 実際の蒸留プロセスを4ステップでざっくり
- データを用意する
自社のFAQ、マニュアル、ログなど、モデルに覚えさせたいデータを集めます。 - 巨大モデル(教師)にすべて解かせる
GPT-5やGeminiなどのLLMにそのデータを投げて、
・最終的な答え(テキスト)
・各候補に対する自信度(Soft Label)
を記録します。 - 小さいモデル(生徒)に「先生の答え方」を真似させる
生徒モデル(SLM)は、人間のラベルではなく、
教師モデルが出した答え+自信度を見ながら学習します。
これにより、「先生ならこう迷って、最終的にこう答える」というパターンを吸収できます。 - テストして、足りない部分を追加で教える
実際の業務データで試し、精度が足りないところは、
追加で教師モデルに質問 → 生徒モデルを再学習、というループを回します。
ポイントは、「人間が1問ずつラベルを手作業で付ける」のではなく、巨大モデルに一気に先生役をしてもらえることです。
これにより、学習コストを抑えながら、高性能なSLMを育てることができます。
4. 蒸留で得られるメリット(ビジネス視点)
- 小さくても“現場タスク”では十分賢い
世界の歴史やマニアックな雑学は捨てても、「自社マニュアルに沿って回答する」「特定ドメインのFAQに答える」といった範囲なら、巨大モデルと遜色ない精度に届くケースが増えています。 - オンデバイス運用に向いたサイズになる
教師モデルそのものをPCに載せるのは現実的ではありませんが、蒸留済みSLMなら、AI PCやエッジサーバーでサクサク動くようになります。 - クラウド利用を「学習フェーズ」に限定できる
教師としてクラウドLLMを使うのは学習時だけ。
本番の推論は、社内のSLMで完結できるため、コストもセキュリティリスクも大きく下げられます。
5. 現場でのイメージ:先生はクラウド、働くのはローカルの“生徒”
実務のイメージとしては、次のような役割分担になります。
- クラウドLLM(先生):最新知識を持つが、料金も高く、常時接続が必要。
- SLM(生徒):先生から教わった特定業務に特化し、社内PCやエッジサーバー上で安く・速く・安全に働き続ける存在。
こうして見ると、「小さいモデル=頭が悪い」というイメージは誤解で、「巨人の肩に乗った“小さくて賢い”モデル」をどう作るかが、これからのAI戦略の肝だと分かります。
実際、多くの企業で、まずは“最初の一人”のエンジニア(あるいはDX推進担当)が、小さなプロジェクトとしてこの取り組みを始めています。クラウドLLMを先生役にしながら、自社専用のSLMを少しずつ育てていく――そんな地道な試行錯誤です。
その小さな一歩が、数年後には全社のAIコスト構造やセキュリティポリシーを塗り替える物語の起点になるかもしれません。蒸留(Distillation)は、その物語を支えるための、静かで強力なエンジンなのです。
結論:ハイブリッド運用こそが正解
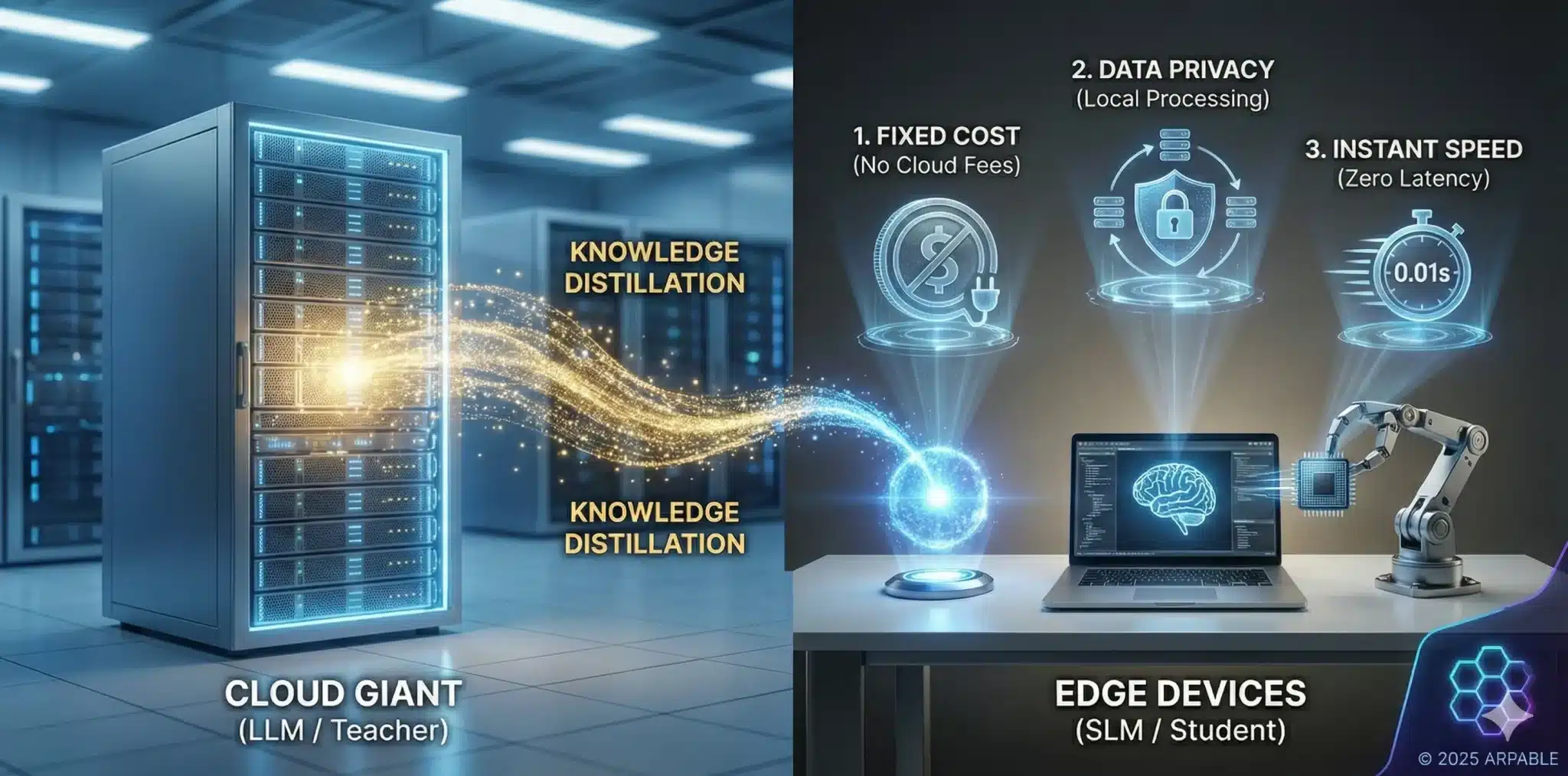
これからは「LLM か SLM か」の二者択一ではありません。クラウドLLMでRAGやAIエージェントを組みつつ、日常の定型業務はオンデバイスAIとしてのSLMに任せる――そんな「ハイブリッドAI運用」が、2026年の標準構成になっていくはずです。
図にすると、クラウド側に「少数の巨大な先生モデル」、社内ネットワークの内側に「多数の小さな生徒モデル」が並び、両者の間をデータではなく“ノウハウ”だけが行き来するような構成です。
2026年の会議室では、こんな会話がごく当たり前に交わされているかもしれません。
「このユースケースはクラウドの先生に頼む? それとも社内の生徒に任せる?」
AIモデルの選定が、サーバー構成の議論と同じくらい、日常的な意思決定プロセスの一部になっていきます。
まずは、社内のAIタスクの8割を占める「定型処理」をSLMに置き換えられないか、検討してみてください。それが、AIコスト削減の第一歩です。
具体的には、次の3ステップを踏むとスムーズです。
- Step 1:メール要約/議事録作成/FAQ回答など、「大量・定型・テキスト主体」の業務を洗い出す
- Step 2:その中から、クラウドLLMに投げる必要がない領域を選び、「SLM×エッジAI」でのPoC候補リストを作る
- Step 3:1〜2個のユースケースから、Ollama や LM Studio などのローカル環境で小さく試し、ROIとセキュリティ面の手応えを測る
「巨人をすべて置き換える」のではなく、「どこから小さく賢い生徒に任せるか」を決めること。それが、2026年に向けた現実的で賢い一歩になるはずです。
専門用語まとめ
- SLM(Small Language Model)
- 小規模言語モデル。パラメータ数が比較的少なく(数千万〜数十億、目安として1B〜10Bクラス)、PCやスマホなどのローカル環境でも動作するように設計されたAIモデル。
業界で厳密な基準が決まっているわけではないが、おおよそ10B未満程度のモデルをSLMと呼ぶことが多い。
- エッジAI(Edge AI)
- クラウドサーバーではなく、ユーザーの手元にあるデバイス(エッジデバイス)側でAIの計算処理を行う仕組み。通信遅延がなく、プライバシー保護に優れる。最近ではAI PC やオンデバイスAIといった文脈で語られることも多い。
- 蒸留(Distillation)
- 巨大で高性能な「教師モデル」の知識(確率分布など)を、軽量な「生徒モデル」に効率的に学習させて移転する技術。モデルの小型化・高速化に不可欠なプロセス。
- オンプレミス(On-premises)
- サーバーやソフトウェアなどの情報システムを、使用者が管理する施設内に設置して運用すること。クラウドの対義語。
- Chain of Thought(CoT)
- 「思考の連鎖」と呼ばれる概念。AIにいきなり答えだけを出させるのではなく、中間的な推論ステップ(考え方のプロセス)を文章として出力させることで、複雑な問題の回答精度や説明可能性を高める手法・振る舞いのこと。
よくある質問(FAQ)
Q1. 私の会社のPCでもSLMは動きますか?
A1. 最近のPCなら動く可能性が高いです。 NVIDIA GPU 搭載機はもちろん、最新の「Copilot+ PC」など40TOPS以上のNPUを搭載したWindows AI PCや、Mac(M1〜M4チップ)であれば、Gemma や Phi-4-mini のようなSLMをオンデバイスAIとして実用的な速度で動かせます。
ただし、長文のRAGや大規模な並列処理など、すべてをローカルで賄うのはまだ現実的でないケースも多く、「どこまでをエッジに寄せ、どこからをクラウドに残すか」の線引きが2025〜26年時点の実務的なテーマになっています。
Q2. SLMの導入は難しいですか?
A2. かつてより遥かに簡単になっています。 「Ollama」や「LM Studio」といったツールを使えば、エンジニアでなくても数クリックでローカルLLM/SLMを導入し、チャットを開始できる環境が整っています。
今日のお持ち帰り3ポイント
- 「なんでもクラウドLLM」はコストとリスクの無駄遣い。「適材適所」への転換が必要
- SLM × エッジAIなら、「低コスト・高セキュリティ・爆速」が実現できる
- 巨大モデルの知識をSLMに移す「蒸留」技術が、現場活用の鍵を握る
主な参考サイト
- Gemma: Introducing new state-of-the-art open models(Google)
- Gemma 3 model overview(Google DeepMind)
- Phi: Small Language Models(Microsoft)
- Apple Intelligence(Apple)
- Distilling the Knowledge in a Neural Network(Hinton et al. / arXiv)
- The Case for Using Small Language Models(Harvard Business Review)
合わせて読みたい
更新履歴
- 初版公開