


※本記事は継続的に「最新情報にアップデート」を実施しています。
【2026最新】富岳NEXT×量子計算が拓く2030年革命:NVIDIA・富士通の日米連合が創る次世代インフラ
2030年、ある製薬企業のR&D部門の一日——
朝8時:富岳NEXT上の生成AIが数億通りの新薬の候補分子をスクリーニングし終える。
午前10時:絞り込まれた候補は自動的に量子クラウドへ転送され、極低温のQPU(量子プロセッサ)が分子のエネルギー準位を精密に計算。
午後3時:HPCがその結果を統合解析し、経営陣のダッシュボードに「承認確率92%」の文字を躍らせる。
これは空想ではありません。富岳NEXTと量子コンピュータの「協奏」が本格化する2030年代前半には、研究開発投資を積極的に行う製薬・素材企業では十分に現実的なシナリオだと、私たちは見ています。
「次世代計算基盤への投資判断が下せない」「量子技術をどう事業に組み込むべきか」。2030年の富岳NEXT稼働を控え、2026年の今こそが戦略的転換点となります。本記事では、自社の生存を左右するHPC-QC協奏の全貌と、3カ年の実践ロードマップを提示します。
✅ この記事の結論(TLDR)
- ポイント1:富岳NEXTと誤り訂正量子技術の協奏が2030年の計算インフラを再定義し、HPCの「広さ」と量子の「深さ」を融合させる。
- ポイント2:同一電力枠で現行比最大100倍のアプリ実効性能を目指す国家プロジェクトが、NVIDIAとの連携で世界標準(CUDA)の覇権を盤石にする。
- ポイント3:量子誤り訂正は「閾値以下」の動作実証フェーズへ。2026年からの3カ年投資計画の策定が企業の生死を分ける。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
日米ハイブリッド同盟の必然──NVIDIAが富岳NEXTに賭ける理由
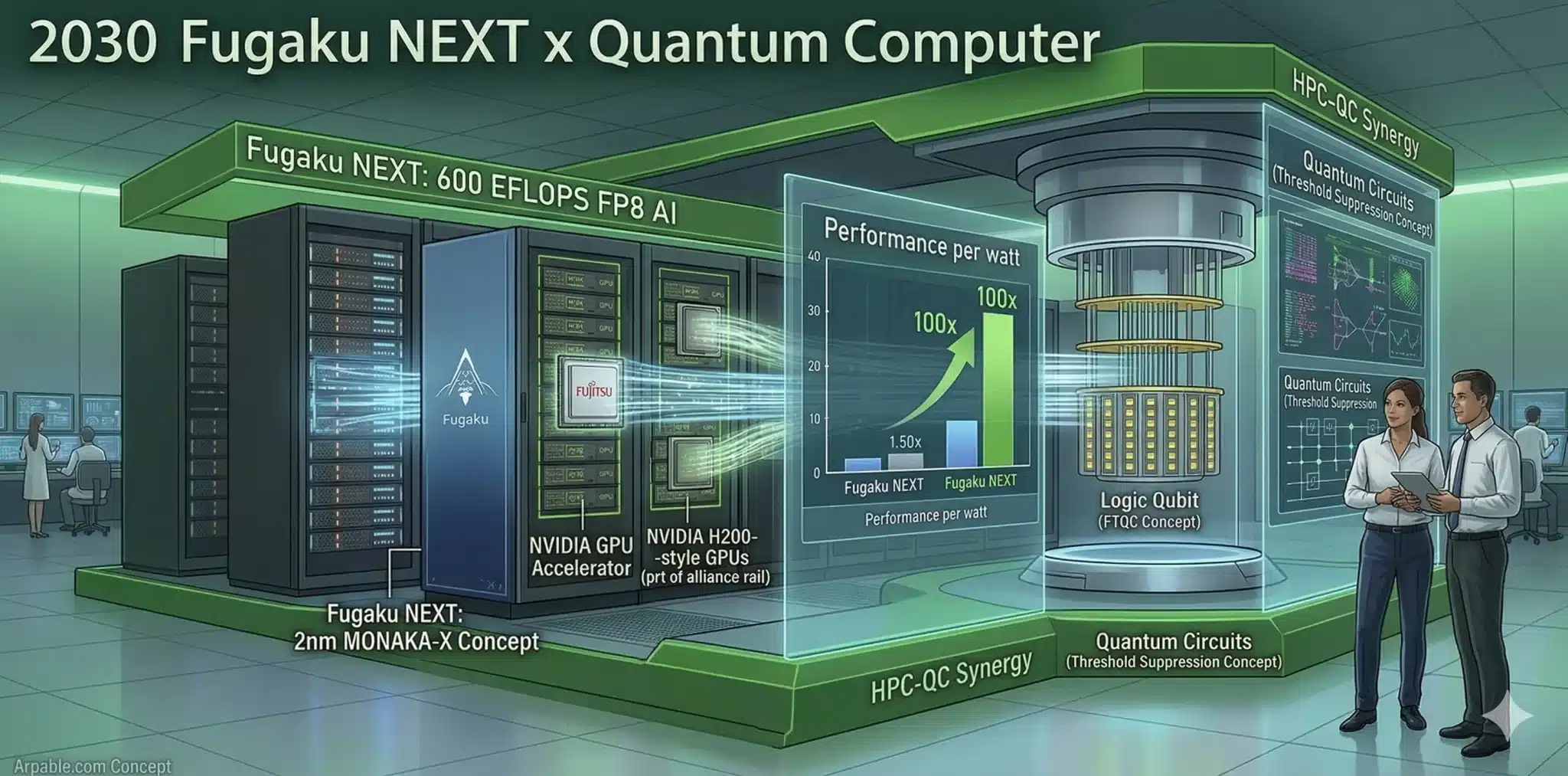 ExaScale制覇の米国と省電力実効性能を重視する日本が利害一致。NVIDIAが独自チップ勢力に対抗し、富岳NEXTを「AI-HPC世界標準」のリファレンスとして選定。
ExaScale制覇の米国と省電力実効性能を重視する日本が利害一致。NVIDIAが独自チップ勢力に対抗し、富岳NEXTを「AI-HPC世界標準」のリファレンスとして選定。
※)ExaScaleとは、毎秒10の18乗回(1エクサ)の浮動小数点演算を行える超大規模計算機(スーパーコンピュータ)の性能水準・世代のことです。
米国がFrontierとEl CapitanでExaScale(エクサスケール)を制覇した瞬間、次なる戦場は「電力効率あたりのAI実効性能」へと移行しました。日本が掲げる“同じ電力枠で100倍のアプリ性能”という設計思想は、その新しい競争ルールにおいて最大の勝ち筋を持ちます。
NVIDIAが今回単なるGPU提供に留まらないのはこのためです。NVIDIAのハイパースケール・HPC担当副社長、Ian Buck氏は開発体制始動式典の場で、「理研、富士通、NVIDIAの協力により、富岳NEXTは前世代と同じエネルギー消費でアプリケーション速度を約100倍に向上させ、研究の加速、産業競争力の強化、日本および世界の人々の進歩を促進します」と、本プロジェクトの意義を述べました。
同社が推進するAI・HPC融合の標準技術プラットフォーム(CUDA-X等)を日本のフラッグシップ機で共同構築することは、自社専用チップやクローズドなクラウド基盤を強化する巨大テック勢に対して、「誰もが乗れる計算の標準レール」を守り抜く一手だと私たちは捉えています。
NVIDIAはGPUハードだけでなく、ソフトウェアまで含めた「計算の世界共通OS」を作りたいと考えています。巨大テック企業が自社専用チップに囲い込みを図る中、オープンな産業クラスターと高い実用性を持つ富岳NEXTは、同社にとって「CUDAが最強であること」を示すための世界最大のショーケースなのです。その完成後の出口市場である日本の産業クラスターを同時に提供できる点に、富岳NEXTの真の価値があります。
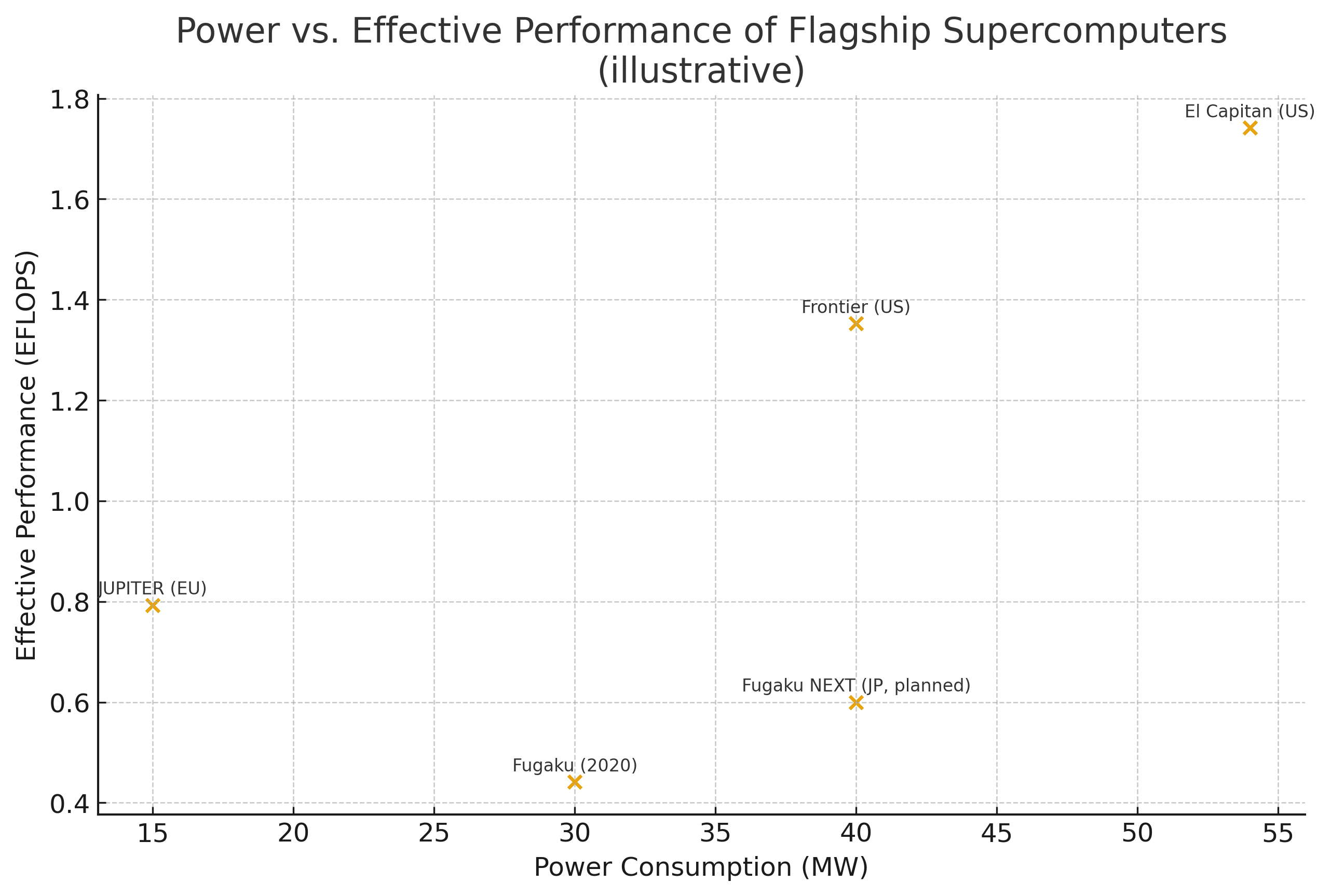
同じ約40 MWという電力枠で、富岳の0.44 EFLOPS(FP64換算)に対し、富岳NEXTは0.6 EFLOPS(FP64 目標値)へと向上します。これは計算速度で約1.4倍ですが、本質的な価値はアプリケーション実効性能にあります。ハードウェア設計の革新(約40倍)とソフトウェアの高度な最適化(約3倍)を組み合わせることで、最大100倍の性能向上を目標としており、これこそがポストエクサスケール時代の競争力の源泉です。
※ 2026年3月11日現在の公開目標値。正式値は今後の設計確定時に更新予定。
富岳NEXTとは何か──100倍性能を目指す国際連携プロジェクト
理研・富士通・NVIDIAの三位一体で、現行比最大100倍のアプリ実効性能を目指す日本の次世代計算基盤。
2025年8月に正式発表された「富岳NEXT」は、理化学研究所がプロジェクトを総括し、富士通が次世代CPUとシステム設計、NVIDIAがGPUを中心とする計算プラットフォームを提供する形で進む、次世代フラッグシップスーパーコンピュータ計画です。現行富岳が持つ電力効率の高さを引き継ぎつつ、“同等の電力枠で最大100倍のアプリケーション実効性能”を実現することが最大の目標とされています。
本計画の核心は、AI理論性能(FP8-Sparse)600 EFLOPS級を消費電力約40 MWという枠内で実現することにあります。富士通が開発する次世代CPUとNVIDIA製GPUを高密度実装技術で統合し、AIと従来型シミュレーションを同一ノードで極めて高速に実行できるアーキテクチャを目指します。これにより、AIが生成した仮説を即座にシミュレーションで検証し、その結果を再学習させるという「AI for Science」のサイクルが劇的に加速され、創薬や新材料開発といった分野での研究期間が桁違いに短縮されると期待されています。
富岳NEXTの本質は、GPUでAIを回し、CPUでシミュレーションを並列実行する「二刀流スパコン」である点にあります。そして、そこから得られた有望な候補を、将来的にはクラウド経由の量子コンピュータがさらに“深掘り”して最適解を見つけ出す。この三位一体モデルが、2030年代の研究開発スタイルを大きく変える重要なシナリオとして描かれています(※あくまで構想レベル)。
MONAKA-XとNVLink Fusion──CPU-GPUハイブリッドの技術詳細
富士通の次世代CPUとNVIDIA GPUをNVLink Fusionで直結しメモリ空間を共有。データ転送のボトルネックを解消。
CPUには、Armベースで開発された「FUJITSU-MONAKA」(最大144 Cores)の技術を基盤とする、富士通の次世代CPUが採用されます。GPU側は、NVLink Fusion技術により、複数のGPUとCPU間でメモリ空間を共有し、従来のPCIe接続におけるデータ転送のボトルネックを解消する設計が計画されています。
これにより、量子回路シミュレーションのような、CPUとGPU間で大量のデータ交換が必要な処理の効率が大幅に向上すると期待されています。現行富岳の「A64FX + Tofu Interconnect D」という構成と比較しても、この共有メモリ空間による高速化の恩恵は極めて大きく、理研のベンチマークにおいてもその有効性が示唆されています。
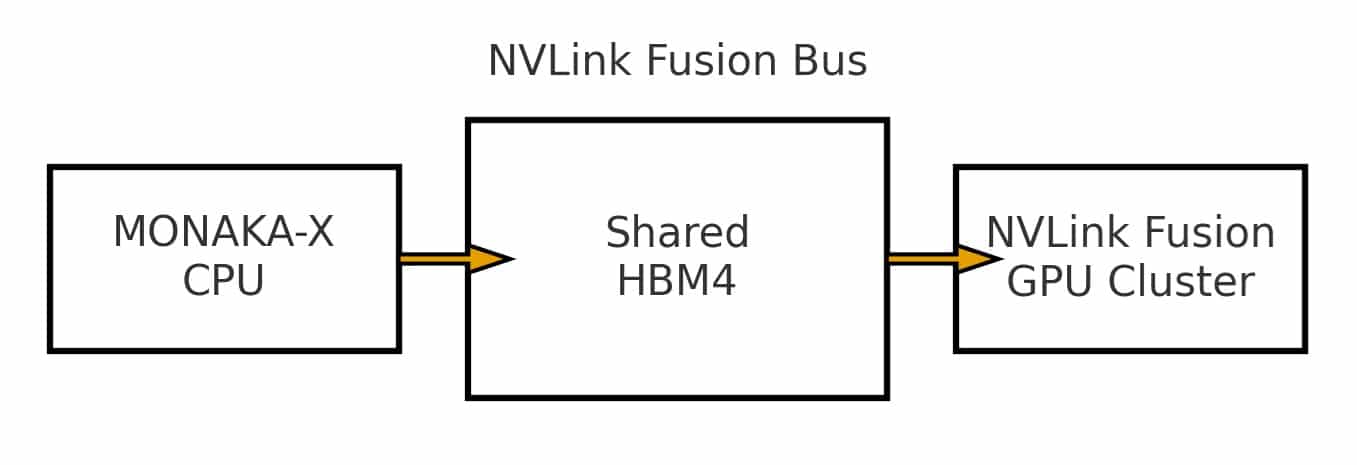
NVLink Fusionバスにより、次世代CPUとGPUクラスタが広帯域メモリを共有メモリ空間として扱えるようになります。そのため「1) AI前処理 → 2) 量子誤り訂正シミュレーション → 3) 数値後解析」といった一連の処理が、ノード内でデータ移動の遅延なく連続実行可能となり、計算効率の大幅な向上が見込まれます。
ソフトウェアスタック:CUDA-XとcuQuantum
プログラミング層では、CUDA-X、RAPIDS、NeMoなどNVIDIAの提供するフルスタックが利用可能となり、富士通のコンパイラ技術と連携して、単一コードでAIと数値計算を並列実行できることが、理研の試験ノードですでに動作確認されています。量子回路シミュレータcuQuantumも標準でサポートされ、HPCと量子コンピュータ(QC)を連携させるハイブリッドSDKを通じて、計算タスクを動的に振り分けることが可能になります。
これにより、開発者は従来の複雑なデータ転送コードを記述することなく、AI・HPC・量子の三領域を包含する柔軟な計算ワークフローを構築できるようになります。これはNVIDIAが狙う「計算の世界共通OS」としてのCUDAの真骨頂と言えるでしょう。
量子誤り訂正のブレイクスルー──実用化へのマイルストーン
2024年末、Google Willowが「閾値以下の動作」を実証。量子計算機は「壊れやすいオモチャ」から「拡張可能な計算機」へと進化した。
量子計算の実用化を阻んできた最大の壁である「エラー」に対し、2020年代半ば、決定的な進展がありました。2023年にGoogle AIが発表した研究では、量子誤り訂正において表面符号の閾値近傍で、コードサイズ拡大に伴う論理エラー抑制が初めて実験的に示されました。さらに2024年12月、Googleは新型プロセッサ「Willow」を用いて、表面符号の閾値を明確に下回る動作を初めて実証しNature誌に発表しています。
これは2023年の「閾値近傍」から、わずか1年で「閾値以下」へと到達した劇的な進化です。物理ビット数を増やすことで論理エラー率が指数関数的に減少することを確認したこの成果は、実用的な誤り耐性量子コンピュータ(FTQC)に向けた、極めて重要なマイルストーンと位置づけられています。ひとことで言えば、これまで「キュービットを増やした瞬間にノイズで壊れてしまうオモチャ」に過ぎなかった量子計算機が、「台数を増やすほど計算の信頼性が高まり、賢くなる計算機」へと変貌を遂げた転換点なのです。
物理 → 論理キュービット変換効率の向上
このブレイクスルーを受け、2030年前後には特定の問題領域において、HPCと量子コンピュータを併用するメリットがコスト面で逆転する「交差点」を迎えるとの予測が現実味を帯びてきました。富岳NEXTというFP8 600EFLOPS級のAI性能と大規模量子回路シミュレーション能力を併せ持つ計算プラットフォームを活用し、cuQuantumで新たな誤り訂正符号の設計・検証サイクルを回すことで、「これまでは月単位だった探索」を研究者が日常的に回せる時間スケールへ落とし込める可能性があります。
量子コンピュータのエラー率が一定の基準を下回ったことで、開発の主戦場は「基礎研究」から「実用化ツール」へと移りました。HPCが得意とする大規模データ処理(前処理・後解析)と、量子コンピュータが得意とする深い探索(最適解の発見)を組み合わせることで、両者の強みを最大限に活かすハイブリッドな計算ワークフローが現実的になっています。2030年の本格稼働を待たずとも、今この瞬間からシミュレータ上での準備を始めることが、次世代の競争力を左右する経営課題と言えるでしょう。
HPCと量子の役割分担マトリクス──用途別ハイブリッド最適領域
 HPCは大規模演算を“広く高速”に、量子は組合せ最適化を“深く正確”に担当。協調ゾーンでの計算効率最大化を狙う。
HPCは大規模演算を“広く高速”に、量子は組合せ最適化を“深く正確”に担当。協調ゾーンでの計算効率最大化を狙う。
富岳NEXTと量子コンピュータの協奏を自社のビジネスに組み込む際、重要となるのはそれぞれの「得意不得意」を理解した役割分担の設計です。HPCは大規模行列演算やAI学習を“広く高速”に処理することに長けており、一方で量子コンピュータは、組合せ最適化や量子化学計算など、古典コンピュータが苦手とする指数的な計算量を必要とする深い探索領域で真価を発揮します。この役割を最適化することで、全体的な計算コストと時間を劇的に削減できるのです。
| 用途 | HPC 前処理 | 量子コア | HPC 後解析 |
|---|---|---|---|
| 気候予測 | メソスケール数値モデル | 組合せ最適化によるパラメータ探索 | 高解像ダウンスケーリング |
| 創薬 | タンパク質折り畳み AI | 量子化学シミュレーション | 候補化合物スクリーニング |
| 物流最適化 | AI需要予測 | QAOAルート最適化 | スケジューラ自動生成 |
| 金融リスク | AIボラティリティ計測 | 量子モンテカルロ | シナリオ分析 |
| ※ 比較条件:AI前処理=1.2 TB、量子化学=1 M orbitals等 判定根拠:大量データIOが必要な処理はHPC、指数的な計算量削減が見込める探索はQC。 |
|||
導入ステップ5段階──「1行」で量子へと繋がる実践フロー
富岳NEXT上のシミュレータから始め、API連携、本番適用へと至る5つのステップ。コードの互換性が投資リスクを最小化する。
自社にAI・HPC・量子のハイブリッド基盤を導入するには、戦略的な段階を踏む必要があります。まず最初の一歩はQCシミュレータ on HPCです。これは、cuQuantumを富岳NEXT上で実行し、量子アルゴリズムをデバッグ・最適化することから始まります。次にCUDA-Qのような統合開発環境を用いたHybrid SDK導入により、GPUとQPU(量子プロセッサ)を呼び出すコードを単一プログラムに統合します。
続くステップでは、将来の量子機による解読に耐えうる耐量子計算機暗号(PQC)の性能や影響を、HPC側で測定・検証します。その後、APIを介して計算タスクの一部をクラウド上の実機へ動的に振り分ける量子-HPC API本番化へと進みます。最終的には、CI/CDパイプラインに量子タスクを組み込むDevOps自動化を実現することで、開発からデプロイまでをシームレスに統合することが可能になります。これにより、実運用ログに基づく継続的な改善サイクルが回り始めます。
📊 CxO向け:意思決定のための3カ年投資ロードマップ
| フェーズ | 目的(何を達成するか) | 投資目安 |
|---|---|---|
| 1年目 (2026) | HPCクラウド上で量子シミュレータPoCを回し、「どの業務なら元が取れそうか」を見極めるフェーズ。 | 月額数十万円〜 |
| 2年目 (2027) | Hybrid SDK導入とクラウドQPU接続試験を通じて、「社内のどのチームなら運用できるか」を確かめるフェーズ。 | 月額数百万円〜 |
| 3年目 (2028-) | 見極めた1〜2業務に絞ってハイブリッド環境へ本番移行し、「本当にPLに効くのか」を検証するフェーズ。 | 数千万円規模〜 |
自社に導入する際、最も懸念されるのは「将来、ハードウェアが変わった時にソフトが動かなくなる」というリスクです。しかし、以下のコードが示す通り、現在の開発環境ではプログラムの根幹を変えずに計算先を切り替えることが可能です。「1年目はシミュレータで知見を溜め、2年目に実機へ移行する」というステップが、わずか1行の変更で完結する。この「将来への互換性」こそが、今すぐR&Dを開始すべき技術的根拠となります。
# CUDA-Q & cuQuantum ハイブリッド呼び出しのイメージ
import cudaq, cuquantum
@cudaq.kernel
def qaoa_layer(beta, gamma):
# ここに量子アルゴリズム(QAOAなど)の定義を記述
pass
# 1. 最初は「富岳NEXT(HPC)」上のシミュレータで実行
result = cudaq.sample(qaoa_layer)
# 2. 準備が整ったら、ターゲットを実量子機(QPU)へ「1行」で切り替え
# cudaq.set_target("quantinuum") # このコメントを外すだけで、実機へジョブが飛ぶ
# result_qpu = cudaq.sample(qaoa_layer)
このように、まずは富岳NEXTという強力なシミュレータの上で、量子アルゴリズムを純粋なソフトウェアとして開発・検証します。そこで性能やパラメータを十分に詰めた後、APIの接続先をシミュレータから本物の量子コンピュータに切り替えて、ハイブリッド実行へと移行する。このシームレスな移行性があるからこそ、ハードの完成を待たずに今すぐ投資を開始できるのです。
HPC×量子コンピュータ連携ロードマップ──2025‒2035年の実装シナリオ

| 年度 | HPC側マイルストーン | QC側マイルストーン | 連携ポイント |
|---|---|---|---|
| 2025 | 富岳NEXT 基本設計完了、cuQuantumシミュレータ全面実装 | 表面符号の実証、実用化研究加速 | QCシミュレーション on HPC |
| 2027 | NVLink Fusionノード量産、Hybrid SDK v2.0 | 大手ベンダーが10万物理qubit級を目標とした試作機を発表 | API経由でのジョブ振り分け検証 |
| 2030 | 富岳NEXT本稼働 | 100万物理qubit級QPUを目指す開発計画の本格化 | リアルタイム協調ワークロード実用化 |
| 2035 | ゼタ級(ZettaScale)本番クラスタ | 誤り耐性量子コンピュータ(FTQC)の普及期 | 三位一体基盤の標準化 |
| ※ 到達目標はベンダー各社のロードマップに依存。電力40 MW枠を前提とした推定値。 | |||
産業ユースケース──2025-2030年の実装シナリオ
気象予測、材料開発、金融リスク管理。国内外で始動しているPoCプロジェクトが、ビジネス効果の道筋を示す。
❶気候予測:理研 R-ATMチームは、富岳および次期富岳NEXTを見据えた高解像度気象モデルの開発を進めており、一部の研究グループでは量子アルゴリズム(QAOA)を用いたパラメータ最適化のPoC(概念実証)が検討されています。将来的に、従来数週間かかっていた計算を数日に短縮することを目指した研究シナリオが描かれています。
❷材料開発:自動車メーカーにとって、電池材料の開発は「試作しては壊す」ことに莫大な時間とコストが吸い取られるゲームです。今、その一部をひっくり返すために、量子コンピュータで分子レベルの振る舞いを計算し、その結果をHPC上の機械学習モデルで一気にふるいにかける、というアプローチがPoCレベルで動き始めています(トヨタ中央研究所での取り組みが一例として報告されている)。私たちはこれを“QC-drivenディスカバリ”と呼びます。人間が思いついた配合を評価するのではなく、計算機側から「これ、試してみないか」と新しい材料案が上がってくる世界への第一歩です。
❸金融:MUFGは、量子モンテカルロ法とHPC上のAIを組み合わせ、大規模な金融ポートフォリオのリスク量(VaR)計算を高速化する共同研究プロジェクトを推進しています。研究レベルの取り組みながら、将来的な計算コストの劇的削減と高精度化を目指した、ハイブリッド計算のショーケースと言えるでしょう。
世界TOP500とZettaScale時代への展望
単純な速度競争は終わり、電力効率とAI実効性能が主戦場へ。富岳NEXTは58 GF/Wという驚異の目標で世界をリード。
TOP500の最新ランキング(2025年6月時点)では、米国のEl Capitanが1.742 EFLOPSで首位を維持していますが、競争の軸は変化しています。目標とするAIピーク性能600 EFLOPS(FP8-Sparse)は、El Capitan級システムの推定AI性能(約400〜500 EFLOPS相当)を上回るレンジに位置づけられます。さらに重要なのは、現行機の15 GF/Wから目標58 GF/Wへの電力効率の飛躍であり、これがポストエクサスケール時代の決定的な優位性となるのです。
まとめ:2030年計算経済圏の勝者へ
HPCの「広さ」と量子の「深さ」を統合し、計算コストと時間を劇的に削減する。これが2030年の勝ち筋。
富岳NEXTと誤り訂正量子技術の連携は、創薬、材料、気候、金融のすべてを塗り替えます。2030年に向けて、ハイブリッドSDK・APIを使いこなし、自社の計算ワークフローを段階的に統合していく企業こそが、この新しい計算経済圏のリーダーとなるでしょう。
💡 Key Takeaways(持ち帰りポイント)
- 富岳NEXTは同一電力で最大100倍のアプリ性能を目指す、AI+HPC融合の二刀流。
- 量子誤り訂正は2024年に「閾値以下の動作」を実証。実用ツールへの転換点を迎えた。
- 今期はシミュレータPoCから着手。3カ年の投資ステップで自社業務のPL最適化を狙う。
専門用語まとめ
- Surface Code (表面符号)
- 量子誤り訂正の代表的手法。2024年にGoogle Willowチップで閾値以下の動作が実証され、実用化が加速した。
- NVLink Fusion
- NVIDIAの次世代接続技術。CPU-GPU間でメモリ空間を共有し、データ転送の遅延を劇的に解消する。
- MONAKA-X (仮称)
- 富岳NEXT向け次世代CPUのコードネーム。AIとHPCに最適化された「知能の骨格」を担い、現在も設計が磨かれている。
よくある質問(FAQ)
Q1. 富岳NEXTはいつ稼働しますか?
A1. 2030年の本格稼働を目標に開発が進行中です。
- 現在は設計の最終調整フェーズ。2027年頃から試作ノードの検証が始まる予定です。
Q2. 量子コンピュータは物理的に組み込まれるのですか?
A2. いいえ、APIやクラウドサービスを介して「動的に連携」します。
- 物理的な結合ではなく、ソフトウェア(CUDA-Q等)による論理的な統合運用が主軸です。
Q3. ハイブリッドSDKの導入コストはどのくらいですか?
A3. PoCフェーズで月額数十万円、本番移行期には数千万円規模が見込まれます。
- まずはシミュレータ上での検証から始めるのが現実的です。
参考サイト・出典
あわせて読みたい
更新履歴
- 2024年12月10日:初版公開
- 2025年8月27日:富岳NEXT開発体制の公式発表に基づき全面改訂
- 2026年3月11日:Google Willow成果およびCxO投資ロードマップを統合し最新化








