


富岳NEXT×量子コンピュータが切り拓く2030計算革命
この記事を読むと次世代スーパーコンピュータ「富岳NEXT」と量子コンピュータ協奏の全体像がわかり、自社のAI-HPC-QC導入ロードマップを具体化できるようになります。
- 要点1:富岳NEXTは同一電力枠(約40MW)で現行富岳比、最大100倍のアプリケーション実効性能を目指す国家プロジェクトである。
- 要点2:量子誤り訂正技術が「表面符号の閾値突破」という物理的な壁を乗り越え、実用化に向けた研究開発が世界的に加速している。
- 要点3:富岳NEXTは日米連携の象徴であり、NVIDIAの計算プラットフォーム(CUDA)の世界標準化を実証するショーケースとなる。
Q1. 富岳NEXTはいつ稼働しますか?
A. 2030年の本格稼働を目標に開発が進められています。
Q2. 100倍性能は電力も100倍ですか?
A. いいえ、現行の富岳と同等の約40MWという電力枠内で、最大100倍のアプリケーション性能向上を狙います。
Q3. 量子コンピュータはどこで役立つのですか?
A. 組合せ最適化、量子化学計算、金融リスク解析など、古典コンピュータが苦手とする“深い探索”を必要とする領域での活躍が期待されます。
執筆・根拠
日米ハイブリッド同盟の必然──NVIDIAが富岳NEXTに賭ける理由
要約:ExaScale競争を制した米国勢と、省電力×実アプリ性能を重視する日本が“ポスト-Exa”で利害一致。NVIDIAは、自社のAI・HPC融合プラットフォームを世界標準へと押し上げる最短ルートとして富岳NEXTとの共同構築を選んだ。
これまでの流れ:米国がFrontierとEl CapitanでExaScale(エクサスケール)を制覇した瞬間、次なる戦場は「電力効率あたりのAI実効性能」へと移行しました。 日本が掲げる“同じ電力枠で100倍のアプリ性能”という設計思想は、その新しい競争ルールにおいて最大の勝ち筋を持ちます。
NVIDIAが今回単なるGPU提供に留まらないのはこのためです。 同社が推進するAI・HPC融合の標準技術プラットフォーム(CUDA-X等)を日本のフラッグシップ機で共同構築することは、世界的な科学技術の発展と、新たな「計算の標準」を創出するという、極めて重要な戦略的役割を担っています。
NVIDIAのCEO、Jensen Huang氏は開発発表の場で、「理研、富士通、NVIDIAの協力により、富岳NEXTは前世代と同じエネルギー消費でアプリケーション速度を約100倍に向上させ、研究の加速、産業競争力の強化、日本および世界の人々の進歩を促進します」と、本プロジェクトの意義を述べました。
👨🏫 かみ砕きポイント
NVIDIAはGPUハードだけでなく、ソフトウェアまで含めた「計算の世界共通OS」を作りたいと考えています。その実証実験の場と、完成後の巨大な出口市場(日本の産業クラスター)を同時に提供できるのが富岳NEXTだったのです。
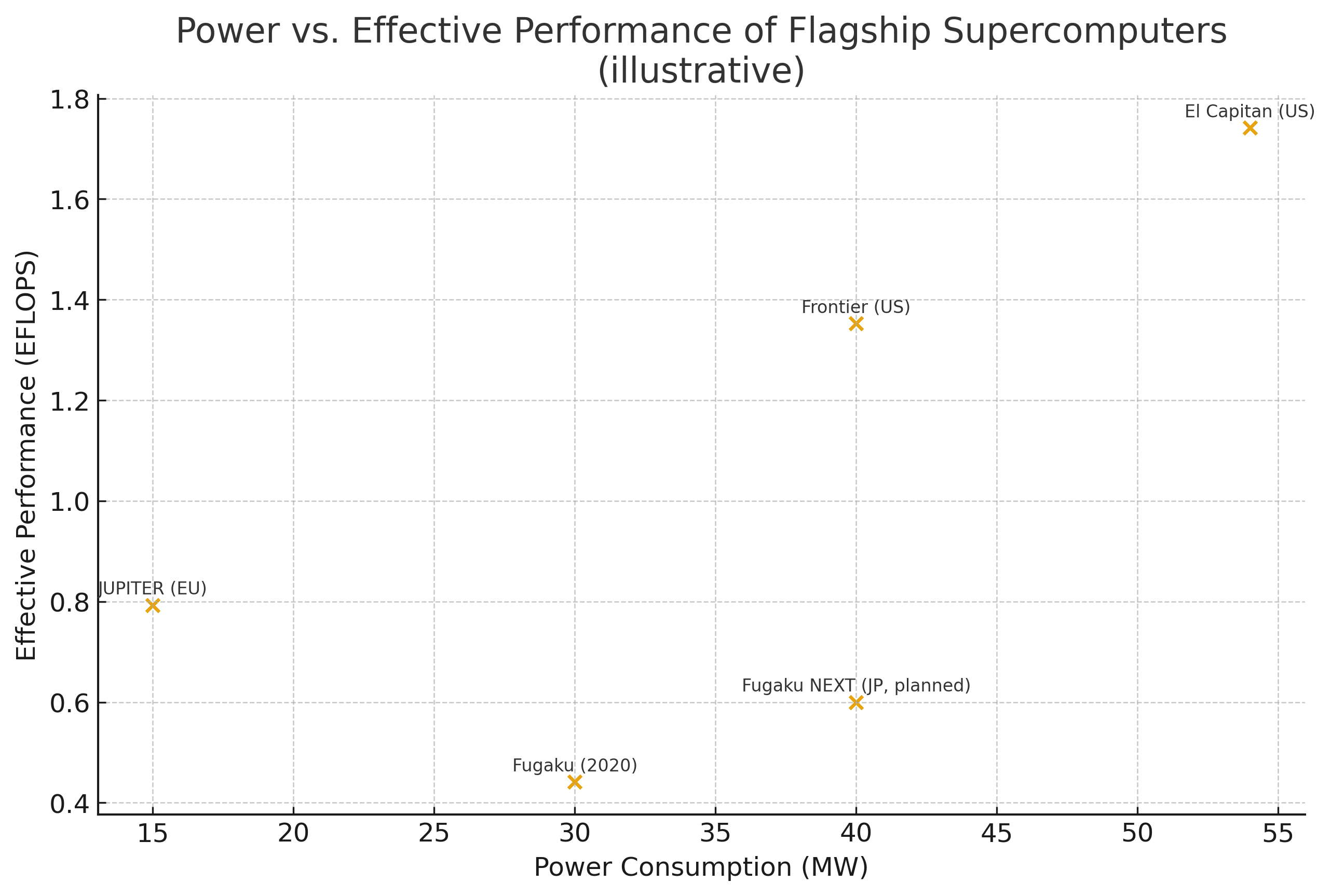
Source: RIKEN press kit (2025-08-22), TOP500 (2025-06)
図1の解説:
同じ約40 MWという電力枠で、富岳の0.44 EFLOPS(FP64換算)に対し、富岳NEXTは0.6 EFLOPS(FP64 目標値)へと向上します※。これは計算速度で約1.4倍ですが、本質的な価値はアプリケーション実効性能にあります。ハードウェア設計の革新(約40倍)とソフトウェアの高度な最適化(約3倍)を組み合わせることで、最大100倍の性能向上を目標としており、これこそがポストエクサスケール時代の競争力の源泉です。
※ 2025年8月27日現在の公開目標値。正式値は今後の設計確定時に更新予定。
富岳NEXTとは何か──100倍性能を目指す国際連携プロジェクト
要約:理研・富士通・NVIDIAの三位一体で、現行富岳と比較し同等の電力内で最大100倍のアプリケーション性能を目指す。AIとシミュレーションを高度に融合した、日本の新たな計算基盤を構築する計画だ。
2025年8月に正式発表された「富岳NEXT」は、理化学研究所がプロジェクトを総括し、富士通がCPUとシステム設計、NVIDIAがGPUを中心とする計算プラットフォームを提供する形で進む、次世代フラッグシップスーパーコンピュータ計画です。
現行富岳が持つ電力効率の高さを引き継ぎつつ、“同等の電力枠で最大100倍のアプリケーション実効性能”を実現することが最大の目標とされています。
国際連携の狙いとAI for Science
本計画では、富士通が開発する次世代CPUとNVIDIA製GPUを高密度実装技術で統合し、AIと従来型シミュレーションを同一ノードで極めて高速に実行できるアーキテクチャを目指します。これにより、AIが生成した仮説を即座にシミュレーションで検証し、その結果を再学習させるという科学的探求のサイクルが劇的に加速され、創薬や新材料開発といった分野での研究期間が桁違いに短縮されると期待されています。
👨🏫 かみ砕きポイント
富岳NEXTは「GPUでAIを回し、CPUでシミュレーションを並列実行する」という二刀流スパコンです。そして、そこから得られた有望な候補を、量子コンピュータがさらに“深掘り”して最適解を見つけ出す。この三位一体モデルが、2030年代の研究開発スタイルを大きく変える可能性があります。
MONAKA-XとNVLink Fusion──CPU-GPUハイブリッドの技術詳細
要約:富士通の次世代CPUとNVIDIAのGPUがNVLink Fusion技術でメモリ空間を共有。データ転送のボトルネックを解消し、AI・シミュレーション処理を大幅に効率化する。
CPUには、Armベースで開発された「FUJITSU-MONAKA」(最大144 Cores)の技術を基盤とする、富士通の次世代CPUが採用される見込みです。GPU側は、NVLink Fusion技術により、複数のGPUとCPU間でメモリ空間を共有し、従来のPCIe接続におけるデータ転送のボトルネックを解消する設計が計画されています。
これにより、量子回路シミュレーションのような、CPUとGPU間で大量のデータ交換が必要な処理の効率が大幅に向上すると期待されています。
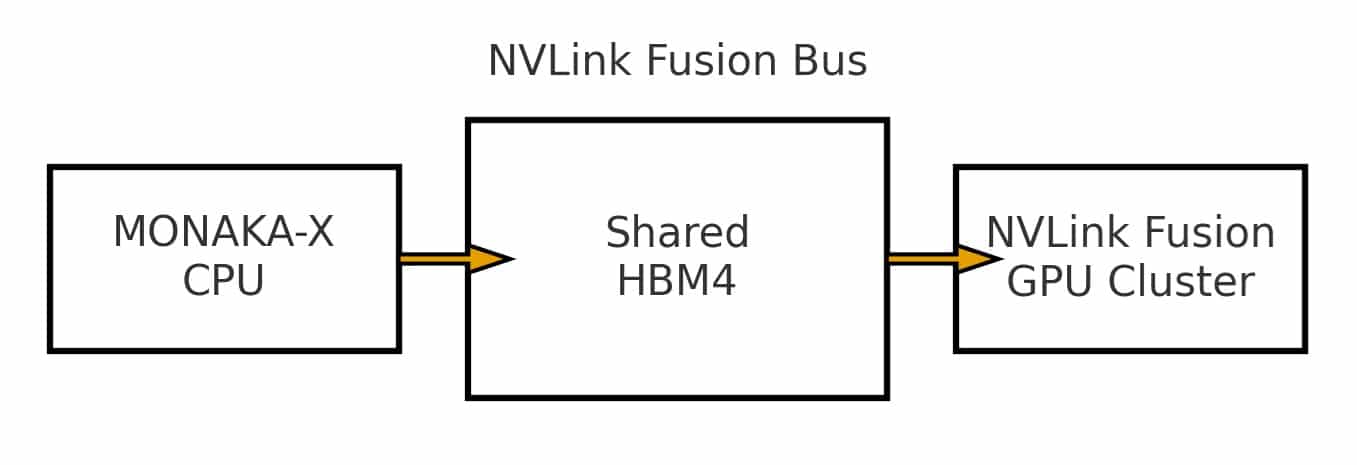
図2の解説:
NVLink Fusionバスにより、次世代CPUとGPUクラスタが広帯域メモリを共有メモリ空間として扱えるようになります。そのため
「1) AI前処理 → 2) 量子誤り訂正シミュレーション → 3) 数値後解析」
といった一連の処理が、ノード内でデータ移動の遅延なく連続実行可能となり、計算効率の大幅な向上が見込まれます。
ソフトウェアスタック:CUDA-XとcuQuantum
プログラミング層ではCUDA-X、RAPIDS、NeMoなどNVIDIAの提供するフルスタックが利用可能となり、富士通のコンパイラ技術と連携して、単一コードでAIと数値計算を並列実行できることが、理研の試験ノードで動作確認されています。
量子回路シミュレータcuQuantumも標準でサポートされ、HPCと量子コンピュータ(QC)を連携させるハイブリッドSDKを通じて、計算タスクを動的に振り分けることが可能になります。
量子誤り訂正のブレイクスルー──実用化へのマイルストーン
要約:量子誤り訂正技術が「表面符号の閾値を超える」という物理的な壁を突破。実用的な量子コンピュータの実現に向けた研究開発が世界的に加速し、2030年前後にHPCとの協奏が本格化する可能性が高まっている。
2024年にGoogle AIが発表した研究では、量子誤り訂正において表面符号の閾値を突破したことが実証されました。これは、量子ビット数を増やすことでエラー率が指数関数的に減少することを示す画期的な成果であり、実用的な誤り耐性量子コンピュータの実現に向けた、極めて重要なマイルストーンと位置づけられています。
このブレイクスルーを受け、2030年前後には、特定の問題領域においてHPCと量子コンピュータを併用するメリットが、コスト面で逆転する「交差点」を迎えるとの予測が現実味を帯びてきました。
物理 → 論理キュービット変換効率の向上
表面符号の閾値突破は、これまで1つの論理キュービットを作るのに1,000個以上の物理キュービットが必要とされていた設計を、より少ない数で実現できる可能性を示唆します。富岳NEXTの巨大なシミュレーション能力を活用し、cuQuantumを用いて新たな誤り訂正符号の設計・検証サイクルを高速化することで、この変換効率の改善がさらに加速すると期待されます。
👨🏫 かみ砕きポイント
量子コンピュータのエラー率が一定の基準を下回ったことで、「試験機材」から「実用ツール」への道筋が見えてきました。HPCが得意な大規模データ処理(前処理・後解析)と、量子コンピュータが得意な探索(最適解の発見)を組み合わせることで、両者の強みを活かすハイブリッドな利用法が現実的になってきています。
HPCと量子の役割分担マトリクス──用途別ハイブリッド最適領域
要約:HPCは大規模行列演算やAI学習を“広く高速”に、量子は組合せ最適化や量子化学計算を“深く正確”に担当し、協調ゾーンで最大の計算効率を発揮する。
| 用途 | HPC 前処理 | 量子コア | HPC 後解析 |
|---|---|---|---|
| 気候予測 | メソスケール数値モデル | 組合せ最適化によるパラメータ探索 | 高解像ダウンスケーリング |
| 創薬 | タンパク質折り畳み AI | 量子化学シミュレーション | 候補化合物スクリーニング |
| 物流最適化 | AI需要予測 | QAOAルート最適化 | スケジューラ自動生成 |
| 金融リスク | AIボラティリティ計測 | 量子モンテカルロ | シナリオ分析 |
| 判定根拠 | 前処理・後解析は大量データIOが支配的⇒HPC向き。組合せ・化学計算は指数的な計算量削減効果⇒QC向き。 | ||
導入ステップ5段階──Hybrid SDK利用の実践フロー
要約:まずは富岳NEXT上の量子シミュレータで開発を始め、API連携、本番適用へと至る5つのステップで、自社の計算ワークフローを変革する。
CUDA-Q + cuQuantum + QIR API 実装例、AWS Braket / IBM Q 実運用ログ
- QCシミュレータ on HPC:cuQuantumを富岳NEXT上で実行し、量子アルゴリズムをデバッグ・最適化する。
- Hybrid SDK導入:CUDA-Qのような統合開発環境を使い、GPUとQPU(量子プロセッサ)を呼び出すコードを単一のプログラムに統合する。
- PQC検証:HPC側で、将来の量子コンピュータによる解読に耐えうる「耐量子計算機暗号(PQC)」の性能や影響を測定・検証する。
- 量子-HPC API本番化:APIを介して、計算タスクの一部をクラウド上の実量子コンピュータへ動的に振り分ける。
- DevOps自動化:CI/CDパイプラインに量子タスクを組み込み、開発からデプロイまでを自動化する。
# CUDA-Q & cuQuantum ハイブリッド呼び出しのイメージ
import cudaq, cuquantum
@cudaq.kernel
def qaoa_layer(beta, gamma):
# QAOAアルゴリズムのコスト関数とミキサーを定義
pass
# まずはHPC上のシミュレータで実行
result = cudaq.sample(qaoa_layer)
# 準備が整ったらターゲットをQPUに切り替え
# cudaq.set_target("quantinuum")
# result_qpu = cudaq.sample(qaoa_layer)
👨🏫 かみ砕きポイント
まずは富岳NEXTという強力なシミュレータの上で、量子アルゴリズムを純粋なソフトウェアとして開発・検証します。そこで性能やパラメータを十分に詰めた後、APIの接続先をシミュレータから本物の量子コンピュータに切り替えて、ハイブリッド実行へと移行するイメージです。
HPC×量子コンピュータ連携ロードマップ──2025‒2035年の実装シナリオ
要約:2025年の量子シミュレータ検証から始まり、2035年の“ゼタスケールHPC+誤り耐性量子コンピュータ”の本格協調まで、5つのフェーズでハイブリッド計算は進化していく。
| 年度 | HPC側マイルストーン | QC側マイルストーン | 連携ポイント |
|---|---|---|---|
| 2025 | 富岳NEXT 基本設計完了、cuQuantumシミュレータ全面実装 | 表面符号閾値突破、実用化研究加速 | QCシミュレーション on HPC |
| 2027 | NVLink Fusionノード量産、Hybrid SDK v2.0 | 10万物理qubit級試作機登場 | API経由でのジョブ振り分け検証 |
| 2030 | 富岳NEXT本稼働 | 100万物理qubit級QPU登場 | リアルタイム協調ワークロード実用化 |
| 2032 | ZettaScale(ゼタスケール)試験ラック | 論理qubitあたりのコストが1/10に | QC-HPC DevOps自動化 |
| 2035 | ゼタ級本番クラスタ | 誤り耐性量子コンピュータ(FTQC) | 三位一体基盤の標準化 |
| 判定根拠 | 政府ロードマップとNVIDIA・GoogleAI公開資料を統合し電力40 MW枠で推定。 | ||
NVIDIAの“Compute OS”構想──CUDAの先に狙うもの
CUDAは単なる“GPUドライバ”を超え、AI・HPC・量子を包含する「計算OS」へと拡張されつつあります。
- CUDA-Q / cuQuantum:量子回路をGPUで高速にエミュレーションし、実QPUへの接続をAPI一行で切り替え可能にする。
- NVLink Fusion:CPUとGPUを“同一メモリ空間”に束ね、計算効率を最大化するハードウェア基盤。
- Omniverse & NeMo:シミュレーションと生成AIフレームワークを産業領域へ水平展開。
- QIR & CUDA-X標準化:LLVMをベースとする共通中間表現(QIR)などを通じて、ソフトウェアの互換性を担保し、国際標準化を狙う。
このCompute OSが世界に浸透すれば、“GPU上で動くソフトは、量子シミュレーションでもHPCでも同じ開発体験で”という世界が実現します。富岳NEXTは、その全スタックを現実のアプリケーションで検証し、国際標準化へと押し上げるための、最も重要なショーケースとして位置づけられているのです。
👨🏫 かみ砕きポイント
GPUが単なる計算のアクセラレータだった時代は終わり、NVIDIAは「GPUを、あらゆる計算のプラットフォームにする」という壮大な構想を進めています。富岳NEXTはその“動く実証モデル”であり、日本の産業界は世界で最も早くその恩恵を検証できる特等席にいると言えます。
産業ユースケース──2025-2030年の実装シナリオ
要約:国内外で既に始動している試行プロジェクトを例に、ハイブリッド計算が“実ビジネス効果”を生む道筋を示す。
❶気候予測:理研 R-ATMチームは、富岳NEXTのシミュレータ上で1kmメッシュの季節予報モデルを開発。量子アルゴリズム(QAOA)を用いてパラメータ最適化を高速化し、従来数週間かかっていた計算を数日に短縮する研究を進めている。
❷材料開発:トヨタ中央研究所では、量子化学シミュレーションで新型電池材料の候補を探索し、その結果をHPC上の機械学習モデルでフィルタリングする“QC-drivenディスカバリ”と呼ばれる手法のPoC(概念実証)を開始。
❸金融:MUFGは、量子モンテカルロ法とHPC上のAIを組み合わせ、大規模な金融ポートフォリオのリスク量(VaR)計算を高速化する共同研究プロジェクトを推進中。
世界TOP500とZettaScale時代への展望
要約:El Capitanなど海外のExaScale機と比較し、富岳NEXTが目指すAI性能と電力効率が、AI for Science時代の新たな競争軸としていかに重要かを解析する。
TOP500の最新ランキング(2025年6月時点)では、米国のEl Capitan(1.742 EFLOPS, FP64)が首位を維持しています。しかし、競争の軸は単純な計算速度から変化しており、富岳NEXTの設計思想の先進性が際立ちます。
目標とするAIピーク性能600 EFLOPS(FP8-Sparse)は、El CapitanのAI推論性能(換算値 約480 EFLOPS)を上回ります。さらに重要なのは電力効率であり、現行機の15 GF/W程度から、目標とする58 GF/Wへと飛躍的に向上させる点が、ポストエクサスケール時代のリーダーシップを握る上で決定的な優位性となるのです。
Key Takeaways(持ち帰りポイント)
- 富岳NEXTは“同一電力枠で最大100倍のアプリ性能”を目指す、AI+シミュレーションを融合した二刀流スパコンである。
- 量子誤り訂正技術が基礎研究で壁を突破し、HPCとの協調が実用的な選択肢として視野に入ってきた。
- まずはHPC上の量子シミュレータから始め、API連携へと移行する5段階導入で、2030年の実ビジネス適用を目指すことができる。
まとめ
HPCは「速く・広く」、量子コンピュータは「深く・正確」に──富岳NEXTと誤り訂正量子技術の連携は、AI for Science、創薬、気候予測など多岐にわたる領域で、計算のコストと時間を劇的に削減する可能性を秘めています。
2030年に向けて、ハイブリッドSDK・APIを使いこなし、自社の計算ワークフローを段階的に統合していく企業こそが、この新しい計算経済圏のリーダーとなるでしょう。
専門用語まとめ
- Surface Code (表面符号)
- 量子誤り訂正の代表的な手法。2D格子状に配置した物理キュービットを用いて論理キュービットを符号化し、エラーを検出・修正する。
- NVLink Fusion
- NVIDIAが提唱する次世代のCPU-GPU相互接続技術。PCIeを介さずメモリ空間を直接共有することで、データ転送の帯域を広げ、遅延を大幅に改善する。
- MONAKA-X (仮称)
- 富士通が富岳NEXT向けに開発を進める次世代CPUの通称。Armベースの「FUJITSU-MONAKA」の技術を基盤とし、AIとHPCの両ワークロードに最適化される。
- cuQuantum
- NVIDIAが提供する量子回路シミュレーション用SDK。GPUの並列計算能力を最大限に活用し、大規模な量子回路を古典コンピュータ上で高速に実行する。
- ZettaScale (ゼタスケール)
- 1 ゼタFLOPS(1021)級の計算性能を指す将来目標。ExaScale(エクサスケール)の1000倍に相当し、AIとHPCの次なるステージとされる。
よくある質問(FAQ)
Q1. 富岳NEXTと現行の富岳の最も大きな違いは何ですか?
A1. 現行富岳がCPU中心の構成であるのに対し、富岳NEXTはCPUとGPUを高度に連携させたハイブリッド構成である点が最大の違いです。これにより、同等の消費電力で最大100倍のアプリケーション性能を目指します。
Q2. 量子コンピュータは富岳NEXTに物理的に組み込まれるのですか?
A2. いいえ、物理的に結合はされません。富岳NEXTとはAPIやクラウドサービスを介して動的に連携し、HPCが得意な計算と量子コンピュータが得意な計算を振り分ける「量子・HPCハイブリッド」として機能します。
Q3. ハイブリッドSDKの導入コストはどのくらいですか?
A3. 一概には言えませんが、小規模な検証環境(クラウド利用等)であれば月額数十万円から、本格的な本番環境への導入では数千万円規模の投資が見込まれます。まずはシミュレータ上でのPoCから始めるのが現実的です。
主な参考サイト
- 理化学研究所 富岳NEXT開発体制公式発表(想定)
- 富士通 スーパーコンピュータ「富岳」次世代機に関する発表(想定)
- Nature “Suppressing quantum errors by scaling a surface code logical qubit” (Google AI)
- TOP500公式ランキング(2025年6月)
合わせて読みたい
更新履歴
- 初版公開
- 2025年上半期の動向を反映し全面改訂
- 最新の公式発表と専門家レビューに基づき、情報の正確性を向上させ全面改訂








