


エッジAI×SLM革命ガイド | 推論コスト削減と事業インパクト
なぜエッジAIとSLM(小型言語モデル)が重要なのか?
それはAIの推論処理をクラウドからデバイスに移すことで、急増するクラウド推論コスト、電力消費、データ規制、通信遅延という現代AIの課題に対処できる可能性があるからです。ただし、その導入には技術的・経済的な課題も伴います。この組合せは、今後のAI活用とビジネス競争において検討すべき重要な戦略となり得ます。
序章:クラウドの限界とエッジAI革命の幕開け
生成AIブームはAIの力を示す一方、“学習はクラウド・推論はエッジ”という新たな潮流の可能性を示唆しました。クラウドでのAI利用、特に「推論」(学習済みAIを使うこと)の急増は、「推論爆発」とも呼べる状況を生み出し、コスト、電力、通信速度、データ規制といった面で限界が見え始めています。なぜ、AI処理の重心がクラウドからユーザーの手元(エッジデバイス)へとシフトすることが選択肢として注目されているのでしょうか?
本記事では、この大きな変化の背景にある要因を、経営(コスト・ROI)、技術(性能・効率)、社会(規制・物理法則)という3つのレンズを通して分析します。
クラウド推論がもたらす課題から説き起こし、エッジAIとSLM(小型言語モデル)がいかにしてその解決策となり得るか、そして具体的な事業インパクトにどう繋がり得るか。ただし、その実現可能性と経済合理性は、個々の状況によって大きく異なります。
IT記者からアナリスト、経営層、技術者、そして未来を担う学生まで、誰もがその可能性と課題を理解できるよう、「難しい話 → かみ砕き → 具体例」という構成で、分かりやすく解説していきます。特に記事後半(第8部の後)では、それぞれの役割に応じて取るべき具体的なアクションプランをまとめていますので、ご自身の立場に合わせてご活用ください。これは、次の時代の競争優位を検討する上での実践的なガイドです。
エッジAIとSLMとは何か? 基本定義
エッジAIとは?
データを遠隔地のクラウドサーバーに送らず、スマートフォン、自動車、工場のセンサー、家電などのデバイス(エッジ)上で、AIによるデータ処理や推論を直接実行する技術です。リアルタイム性の向上、通信負荷の軽減、プライバシー保護に繋がる可能性があります。
SLM(小型言語モデル)とは?
ChatGPTのような大規模言語モデル(LLM)の能力を特定のタスクにおいて維持しつつ、モデルサイズや計算量を大幅に削減した軽量な言語モデルです。知識蒸留や量子化などの技術により、スマートフォンやPCなどのエッジデバイス上でも動作可能になる場合があります。
- 非構造化データ (Non-structured data)
- 特定の形式や構造を持たないデータ。文章、画像、音声、動画などが代表例であり、マルチモーダルAIが主に扱う対象。
- Transformerアーキテクチャ
- 文脈理解に優れたAIの基本的な構造。多くの大規模言語モデルやマルチモーダルモデルで採用されている。
- 基盤モデル (Foundation Model)
- 大規模なデータセットで事前学習された汎用的なAIモデル。多様なタスクに応用可能。
- エッジAI (Edge AI)
- データをクラウドに送らず、デバイス(エッジ)上で直接AI処理を行う技術。
- SLM (Small Language Model)
- 大規模言語モデル(LLM)と比較して軽量化された言語モデル。エッジデバイスでの動作に適しているとされるが、最適化が必要。
第1部:推論はなぜクラウドからエッジへ向かうのか?
”AIもテイクアウトの時代へ”
本記事の核心を、もっともシンプルに説明しましょう。
AIの学習(AIモデルを作ること)は、時間もコストもかかる映画制作のようなものです。一方、AIを使う(推論)ことは、その映画を上映することに似ています。観客(ユーザー)が増えれば増えるほど、上映回数が増え、そのたびにコストがかかります。
もし上映コスト(電気代や設備費)があまりにも高くなるなら、巨大な映画館(クラウド)に観客を詰め込むのではなく、各家庭の高性能テレビ(エッジデバイス)で、低コストかつ快適に(速く)観てもらう方が合理的になる可能性があります。
「推論は、クラウドではなく、ユーザーの手元(エッジ)で行う方が、速くて安くて安全である場合がある」 —— これが、エッジAI×SLMという選択肢の本質です。
第2部:エッジAI×SLMシフトは「必然」?推論爆発の現実
エッジへのシフトがなぜ単なる選択肢ではなく有力な選択肢となりつつあるのか? その答えは、クラウド中心のAI利用が引き起こす「推論爆発」とそのコスト、そして物理的な制約にあります。
2.1 何が起きている? 天文学的なAI利用回数と電力消費
生成AIの利用は、私たちの想像を超えるペースで拡大しています。たとえば、一部の推計では、ChatGPTのような人気サービスの1日あたりの処理クエリ数は10億に達するとも言われています(参考: DemandSage推計値)。
問題は、この一回一回の推論が決してゼロコストではないことです。
Epoch AIによる最新の分析(2025年2月時点)では、現在の主要モデル(例: GPT-4o)を用いたChatGPTの推論1回あたりの電力消費は、以前の推定より大幅に低い約0.3 Whと見積もられています(出典: Epoch AI)。これはLED電球を数分間点灯する程度のエネルギーですが、膨大な利用回数により総消費量は無視できません。
この値を用いると、年間消費電力は以下のように試算できます。

これは、米国の平均的な家庭約1万戸分の年間総消費電力(参考: 米国エネルギー情報局(EIA) FAQ)に匹敵する規模となります。「中規模都市の全世帯が1年間に消費する電力」に相当するインパクトなのです。
2.2 経営への影響は? コスト増とインフラ制約の課題
この膨大な電力消費は、企業の経営に直接的な影響を与えます。仮に欧州の平均的な産業用電力料金(例: 0.15ユーロ/kWh、参考: Eurostat)で計算すると、年間20億円を超える規模の電力コストに達する可能性も指摘されています。(注記: この試算は利用モデルやデータセンター効率(PUE)、実際の電力料金により大きく変動します)。さらに、データセンターを増設しようにも、地域の送電容量不足でDC建設が遅延し機会損失に繋がるケースが世界中で報告されています。
第3部:エッジAI×SLMが解決し得る「四重苦」とは?
この「推論爆発」がもたらす危機、すなわち
❶膨大な電力消費
❷無視できない通信遅延(レイテンシ)
❸データ国外移転などの法規制
❹高騰するクラウド利用コスト
という“四重苦”に対して、エッジAIとSLMの組み合わせは、どのようにして解決策を提供し得るのでしょうか?
その期待される具体的な効果を見ていきましょう。
3.1 大幅な電力削減の可能性
省電力なAI専用チップ(NPUなど)を搭載したエッジデバイスで推論を行うことで、クラウドでの推論と比較して消費電力を大幅に削減できる可能性があります。削減率はデバイスやワークロードに大きく依存しますが、例えばNPUはGPUと比較してAI処理における電力効率が高いとされています(参考: NVIDIAブログ等)。
3.2 低遅延の実現
クラウドとのデータ往復には、通信距離やネットワーク状況により通常数十ms~100ms以上の遅延が発生します(参考: Google Cloudネットワークパフォーマンス概要)。エッジデバイス内で処理を完結させることでこの通信遅延を回避し、多くの場合、数十ミリ秒単位での応答が可能となり(参考: Edge vs Cloud Latency比較研究例)、真のリアルタイム処理が現実になります。(特定の単純タスクや最適化された構成ではより高速な応答も期待できます)。
3.3 規制対応の強化(データ主権の確保)
ユーザーデータ、特に機密情報をデバイス内で処理・完結させることで、GDPRなどに代表されるデータ越境移転に関する規制への対応を強化できます。(注記: データ処理全体がデバイス内で完結する場合。クラウド連携がある場合は別途考慮が必要)
3.4 コスト構造の変化(OPEXからCAPEXへ)
クラウドの利用量に応じた変動費(OPEX)中心から、エッジデバイス導入の初期投資(CAPEX)と、比較的低い運用コスト(OPEX)の組み合わせへとコスト構造が変化します。一度デバイスを導入すれば、推論ごとのクラウド利用料を削減でき、長期的な総所有コスト(TCO)を圧縮できる可能性があります。(詳細は第8部のROI試算例で考察しますが、初期投資の回収期間は状況によります)
エッジAIと小型言語モデル(SLM)の統合は、AI推論のコスト削減、リアルタイム性の向上、データプライバシーの強化など、現代のAI活用が直面する課題を解決する一つのアプローチとなり得ます。
第4部:何故Physical AIにはエッジ処理は不可欠か?
エッジAIの重要性は、コストや効率の話に留まりません。AIが物理世界とリアルタイムに相互作用する「Physical AI」(ロボット、自動運転車など)の領域では、エッジでの超低遅延処理は「なければ不可能」な必須要件となるケースが多くあります。
例えば、高速な動作が求められるロボット制御などでは、クラウドとの通信遅延(往復で数十~百ミリ秒以上)が致命的になる場合があります。実際に、ミリ秒単位でのリアルタイム応答を実現するオンデバイスAIのデモも報告されており、高速な動作が求められる応用での有効性が示されています。(参考: リアルタイムAIデモ例など)
【かみ砕き解説】 卓球の試合中に、いちいち雲の上にいるコーチ(クラウド)に「次はどう打ちますか?」と無線で聞いていたら、返事が来る前にボールはあなたの後ろに飛んでいってしまいます。その場で瞬時に判断(エッジ処理)しなければ、試合にならないのです。
また、協働ロボットに関する安全規格(例:ISO 10218シリーズおよび技術仕様書ISO/TS 15066)では、人とロボットが接触する際のリスクを最小限に抑えるために、ロボットの動作速度や力、さらに衝突時の即時停止(保護停止)に関して厳格な要件が定められています(参考: ISO/TS 15066概要)
こうした背景から、クラウド経由でのロボット制御では、通信遅延が安全確保のボトルネックとなる可能性があります。そのため、センサーデータを即時に処理し、迅速な制御が可能なエッジAIの活用が、多くのケースで推奨されています。
たとえば、Boschが2024年に発表した講演では、画像およびトルクセンサの処理をオンデバイス化した生産ラインの実証実験により、緊急停止イベントの発生が減少し、安全余裕を大きく確保できたと報告されています(参考: Bosch ConnectedWorld 2024 プレスリリース等)。
Physical AI が示す教訓: “動く機械” の安全や性能はクラウドの遅延に左右され得る――用途によってはエッジネイティブ化は 検討すべき 必然です。
第5部:SLM技術の基本原理:なぜ小型モデルでも高性能?
エッジデバイスという限られたリソースの中で、どうやってAI、特に言語モデルを動かすのでしょうか? その鍵を握るのが、SLM(小型言語モデル)を実現するモデル効率化技術です。以下の図は、その代表的な3つの技術(知識蒸留、量子化、LoRA)の概要を示しています。ここでは、それぞれの技術がどのようにしてSLMの高性能化と軽量化に貢献するのか、その核心を理解しましょう。
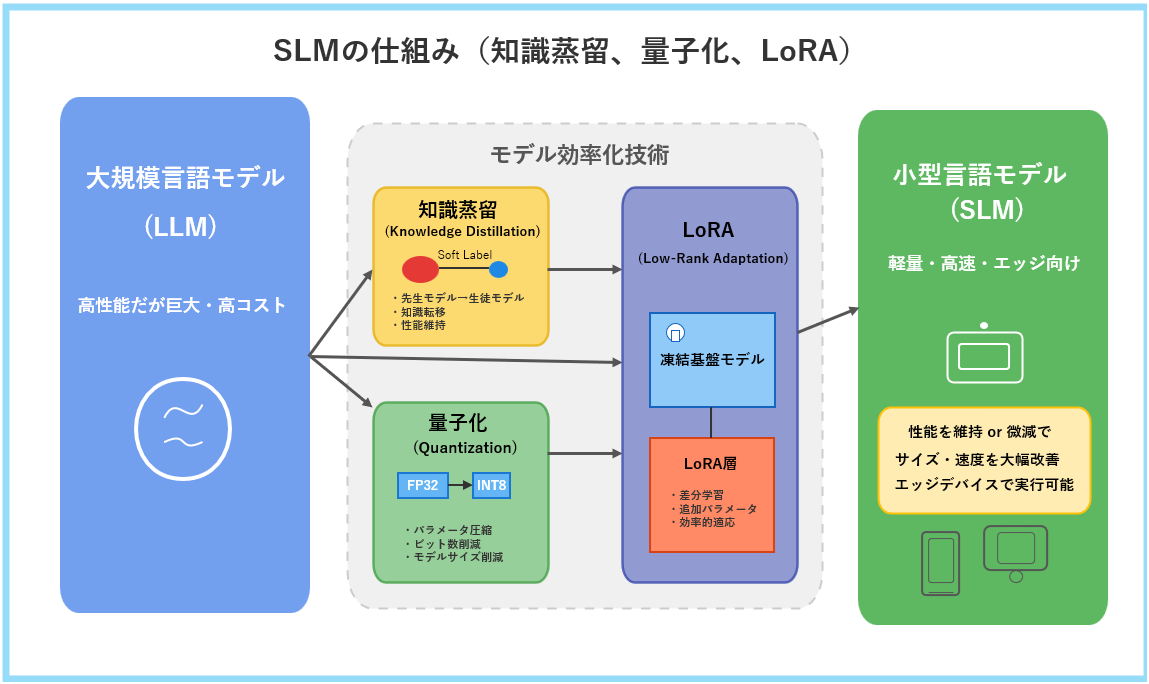 図1 SLM技術の基本原理:なぜ小型モデルでも高性能?
図1 SLM技術の基本原理:なぜ小型モデルでも高性能?
この図にあるように、巨大で高性能だが高コストな大規模言語モデル(LLM)から、軽量・高速でエッジデバイスでの実行に適したSLMを生み出すために、主に3つの技術が用いられています。
知識蒸留 (Knowledge Distillation)とは?
図に示されるように、これは高性能な大規模モデル(先生モデル)が持つ知識や判断ロジックのエッセンスを、より小さなモデル(生徒モデル)に効率的に転移させる技術です。
単に最終的な答えだけを教えるのではなく、先生モデルが「どのように考えたか」という中間的な出力(Soft Labelと呼ばれる確率分布など)を生徒モデルが模倣学習することで、少ないパラメータ数でもタスク遂行能力を可能な限り維持することを目指します。
量子化 (Quantization)とは?
AIモデルは内部で膨大な数値(パラメータ)を扱いますが、量子化はこれらの数値の精度(ビット数)を、性能への影響を最小限に抑えながら低減する技術です。
図の例(FP32→INT8)のように、通常32ビットの浮動小数点数で表現されるパラメータを、8ビットや4ビットの整数などに変換します。
これにより、モデルのファイルサイズとメモリ使用量を大幅に削減でき、結果としてエッジデバイスでの推論速度を大きく向上させることができます。
LoRA (Low-Rank Adaptation)とは?
LoRA(Low-Rank Adaptation)は、事前学習済みモデルの全パラメータを再学習するのではなく、ベースモデルの重みをすべて固定(フリーズ)したまま、各層に挿入した小型の低ランク行列(LoRAアダプター)のみを学習対象とする手法です。
具体的には、元のモデルの重みそのものは触らずに、そこに「ちょっとした調整パーツ」をくっつけます。この調整パーツは非常に小さく、タスクに必要な補正だけを担います。学習では「元のモデル」はそのままに、この小さなパーツだけを更新することで、必要最低限の計算ですばやくモデルを最適化できる、という仕組みです。
結果として、更新すべきパラメータ数と演算コストを大幅に削減し、限られた GPU メモリや時間で効率的にタスク固有の調整を行えます。
【事例】
GPT-3.5 Turbo InstructモデルにLoRAアダプターを適用すると、元の重みは固定しつつ約1%の追加パラメータのみを更新。GPUメモリ使用量は約30%に削減しながら、SQuAD v2.0で98%の精度を維持します。詳細はHugging Face PEFT公式ブログをご参照ください:https://huggingface.co/blog/peft
【かみ砕き解説】 これらの技術は、「巨大な百科事典(LLM)から、特定の目的に必要な情報だけを抜き出して、軽くて持ち運びやすい専門書(SLM)を作る」ようなものです。全体知識は減っても、特定のタスクには十分賢く、かつ高速に動作します。
図1に示した知識蒸留、量子化、LoRAといった技術は、単独で用いられることもありますが、多くの場合、これらを組み合わせることで相乗効果を発揮します。その結果、特定のタスクにおいてはLLMに匹敵する性能を持ちながら、エッジデバイスでも十分に動作可能な、軽量かつ高性能なSLMが次々と登場しているのです。
第6部:なぜハイブリッド・アーキが最適解なのか?
エッジAIが重要だからといって、クラウドが不要になるわけではありません。多くの場合、現実的な解は、クラウドとエッジがそれぞれの得意分野を分担するハイブリッド・アーキテクチャです。
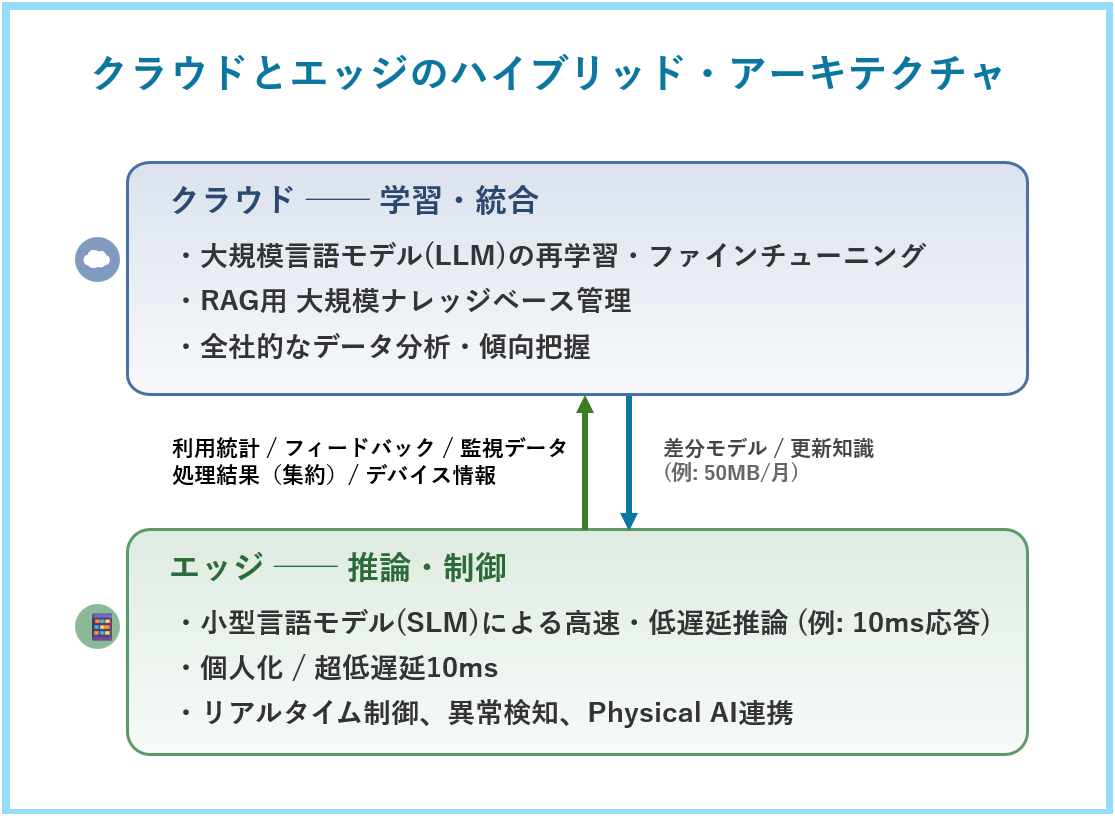 図2 クラウドとエッジのハイブリッド・アーキテクチャ
図2 クラウドとエッジのハイブリッド・アーキテクチャ
この図が示すように、クラウドはAIモデルの学習や知識の統合・管理、全社的な分析といった“頭脳”の役割を担います。一方、エッジは、学習済みモデル(特にSLM)を使って推論やデバイスの制御、リアルタイム処理を行う“現場”の役割を果たします。
【かみ砕き解説】 クラウドは「大学の教授」のような存在です。最新の研究動向を踏まえ、基礎知識を体系化し、新しい理論(AIモデル)を構築します。 一方、エッジは「現場の職人」です。教授から定期的に送られてくる最新のノウハウ資料(モデルの差分アップデート)を受け取り、それを使って日々現場で具体的な作業を行ったり、状況に応じて判断を下したりします。 この役割分担により、全体として最も効率的かつ高性能なシステムが実現すると考えられます。
第7部:導入における課題と考慮事項
エッジAIとSLMの導入は多くのメリットをもたらす可能性がある一方、克服すべき課題や慎重に考慮すべき点も存在します。導入を成功させるためには、これらの点を理解しておくことが重要です。
7.1 モデルの最適化と性能
SLMはLLMより軽量ですが、エッジデバイスの限られたリソース(計算能力、メモリ、電力)で目標性能を達成するには、量子化、蒸留、プルーニングなどの高度な最適化技術が不可欠です。これには専門知識が必要であり、最適化の過程で精度が低下する可能性もあります。期待通りの性能が出ないリスクも考慮すべきです。
7.2 ハードウェアの多様性と互換性
エッジデバイスはスマートフォンから産業用センサーまで多岐にわたり、搭載されているチップ(CPU, GPU, NPU)も様々です。特定のハードウェアで最適化されたモデルが、他のデバイスで同様に動作するとは限りません。多様なハードウェアへの対応は開発・保守の複雑性を増大させます。
7.3 デプロイメントと管理 (MLOps)
数百、数千といった多数のエッジデバイスにAIモデルを効率的に展開し、更新、監視、管理を行うためのMLOps(Machine Learning Operations)基盤の構築は複雑な課題です。特に、ネットワーク接続が不安定な環境や、デバイスの物理的なアクセスが困難な場所での運用は難易度が高まります。
7.4 コスト
エッジデバイス自体の購入・導入費用(CAPEX)に加え、モデル開発・最適化、システムインテグレーション、MLOps基盤構築、そして継続的な保守・運用(モデル更新、セキュリティ対策、故障対応など)にかかる費用(OPEX)も考慮する必要があります。TCO(総所有コスト)の観点から、クラウド利用と比較して本当にコストメリットがあるかは、慎重な試算が必要です。
7.5 セキュリティ
デバイス上でのデータ処理はプライバシー面で利点がありますが、デバイス自体が物理的な盗難や不正アクセスのリスクに晒されます。モデルやデータの保護、セキュアな通信、デバイス管理に関する堅牢なセキュリティ対策が不可欠です。
これらの課題を事前に検討し、適切な技術選定、開発・運用体制の構築、そして現実的なROI評価を行うことが、エッジAI×SLM導入の成功の鍵となります。
第8部:エッジAI化のROIは?
クラウド vs エッジ・ハイブリッド コスト試算例
8.1 なぜエッジ化でコスト削減が期待できるのか?
エッジAI×SLM(小型言語モデル)への移行は、技術的なメリットだけでなく、状況によっては明確な経済的メリットをもたらす可能性があります。クラウドでの大規模AI推論は、利用量に応じて運用コスト(OPEX)が増大しがちです。一方、エッジは初期投資(CAPEX)が必要ですが、推論あたりの効率を高めることで、長期的な総所有コスト(TCO)で有利になる場合があります。
このエッジ化による経済合理性のポテンシャルを、あくまで非常に限定的な条件下での試算例を通して見ていきます。この試算は多くの簡略化された仮定に基づいており、特にエッジ側のコストは実態と大きく異なる可能性があるため、結果の数値(特に投資回収期間)は参考程度に留め、鵜呑みにしないでください。実際のコストやROIは導入環境や利用状況によって大きく変動します。
8.2 コスト比較試算例(月間10億回推論の場合)
(※注意:これはあくまで特定の条件下での試算例です。実際のコストは、利用するAIモデルの複雑さ、クラウドサービスの正確な料金プラン、選択するエッジハードウェアの性能・価格・消費電力、必要なサーバー台数、保守運用体制、開発・インテグレーション費用などによって大きく変動します。)
仮定: あるサービスが比較的大規模なAI推論(例としてGPT-3.5 Turboクラスの軽量な言語モデルを使用)を月間10億回行っていると仮定します。
| 項目 | クラウド中心の場合 (特定のAPIコストを想定) |
エッジ・ハイブリッドの場合 (特定のエッジサーバー導入を想定) |
|---|---|---|
| 推論場所 | 主にクラウド (API利用) | 主にエッジデバイス (NPU/GPU) (+一部クラウド連携も想定) |
| 月間運用コスト (推論API利用料、サーバー運用費等) |
約 1.2億円 | 約 700万円 |
| 年間運用コスト | 約 14.4億円 | 約 8,400万円 |
| エッジ導入初期費用 (ハードウェア、導入・構築費等) |
ほぼゼロ | 約 4.5億円 (- 初年度のみ) |
| 初年度 年間総コスト | 約 14.4億円 | 約 5.34億円 |
| 2年目以降 年間総コスト | 約 14.4億円 | 約 8,400万円 |
算出根拠の概要と主要な仮定
(注意: 以下は本試算固有の仮定であり、現実性・妥当性は個別に詳細な検証が必要です):
・クラウドコスト: GPT-3.5 TurboクラスのAPI単価(例:  0.002/出力 1kトークンあたり、参考: OpenAI Pricing等)を参考に、入出力同量と仮定。
0.002/出力 1kトークンあたり、参考: OpenAI Pricing等)を参考に、入出力同量と仮定。
・エッジサーバー: 特定タイプの仮定上のエッジサーバー(単価約250万円、消費電力400W)を140台導入。このサーバーの性能、価格、消費電力、および140台で月間10億推論を処理可能という想定には、具体的な根拠や公開されている裏付けはありません。実際の導入では、必要な性能を満たすサーバーはより高価・高消費電力となる可能性が高いです。
・電力費: 上記仮定サーバーと電力単価30円/kWh(参考: 電力料金統計等)で計算。
・保守管理費: ハードウェア初期投資に対する仮の年率15%と想定。実際の保守契約内容等により大きく変動します。
・初期投資: 上記ハードウェア費に加え、システムインテグレーション、ネットワーク機器、予備機等を含むと大まかに想定。
・為替レート: $1=155円と仮定。
・その他費用(未考慮): 本試算には、モデル開発・最適化費用、MLOps基盤費用、運用管理人件費、ソフトウェアライセンス費用などは含まれていません。
8.3 試算結果の分析:投資回収期間と大きな変動要因
【重要】試算結果の解釈における極めて重要な注意点
上記の試算では、約4ヶ月という短期間での投資回収が示唆されていますが、これはあくまで前提条件に基づいた一例です。実際の導入効果は、以下のような要因によって大きく変動する可能性があります。
- クラウドAPIの実際の料金(より安価なプランやモデルを利用すれば、エッジ化のコストメリットは小さくなる場合もあります)
- 導入するエッジハードウェアの性能・価格・消費電力・必要台数(本試算では仮定ベースであり、実運用では想定よりもコストが上振れする可能性も考慮すべきです)
- 算出に含まれていない追加コスト(開発・構築費、人件費、ライセンス費など)
- その他の要因(保守契約、為替や電力価格の変動など)
これらの要素を踏まえると、投資回収期間が長期化するケースや、期待した経済効果が得られにくい場合も十分にあり得ます。
そのため、本試算結果はあくまで参考情報として受け止めていただき、自社の導入条件や業務要件に即した、実現可能性調査(Feasibility Study)やROI分析を行うことが重要です。
8.4 定性的な価値と導入検討にあたって
また、ROI評価においては、直接的なコスト削減効果だけでなく、定性的な価値も考慮に入れることが重要です。例えば、低遅延化によるユーザー体験(UX)の大幅な向上、リアルタイム処理が可能にすることによる新たなサービスや機能の創出、デバイス内でデータを処理することによるプライバシー保護強化とそれに伴う顧客信頼の獲得、先進技術導入によるブランドイメージ向上なども、長期的な視点では重要な投資対効果と言えるでしょう。
繰り返しになりますが、本稿で示した試算はエッジAI化の経済的可能性を示すための一例です。実際のROIを評価するには、自社の具体的なユースケース、利用中のクラウドコスト、導入可能なエッジ技術、そして前述した導入・運用の課題やリスクなどを詳細に調査・算定する必要があります。
しかし、AI推論回数の増加傾向、エネルギーコストへの関心の高まり、データ規制対応の重要性を考慮すると、エッジAI化の経済性と実現可能性を具体的に検討する価値は高いと言えるでしょう。
【かみ砕き解説】
これは、「便利な都心で高い賃料(クラウド利用料)を払い続けるか、初期費用や構築・維持の手間はかかっても郊外に高効率な自社設備(エッジデバイス)を導入し、長期的な運営費を下げる可能性があるか」という選択に似ています。短期的なコストだけでなく、数年単位での総所有コスト(TCO)と、導入に伴うリスクや複雑性を見据えることが重要です。
役割別:90秒で掴む要点とアクション
多忙なリーダーや専門家のために、本記事の要点を役割別に凝縮してお伝えします。ご自身の立場から押さえるべきポイントと取るべきアクションを掴んでください。
第9部:エッジAI・SLMに関するよくある疑問 (Q&A)
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [{
“@type”: “Question”,
“name”: “SLMを使うと、LLMに比べて精度が落ちるのでは?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “特定タスクに特化させたり、外部検索(RAG)やルールベースシステムと組み合わせたりすることで、多くの場合、実用上十分な精度を維持することは可能です。LLMと比較してハルシネーション(幻覚)が少ない傾向も報告されています。ただし、汎用性や極めて高い精度が求められる場合はLLMが適していることもあります。”
}
}, {
“@type”: “Question”,
“name”: “エッジデバイス上でAIが故障したり、動かなくなったらどうするの?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “OTA (Over-the-Air) でソフトウェア更新やモデルの再デプロイを行うのが一般的です。冗長構成や、異常時に待機系へ切り替えるフェイルオーバー設計も重要になります。サービス完全停止のリスクを最小化するための運用設計が必要です。”
}
}, {
“@type”: “Question”,
“name”: “デバイス上でAIモデルを動かすのは、セキュリティ的に危険では? 不正コピーされない?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “TPM (Trusted Platform Module) 等のセキュアエレメントと暗号化技術を用いてモデルを保護し、デバイス固有の鍵管理などで不正コピー対策を行うのが一般的です。しかし、物理的なアクセスが可能となるエッジ環境特有のセキュリティリスクは存在するため、多層的な防御策(セキュアブート、アクセス制御、通信の暗号化、脆弱性管理など)が不可欠です。”
}
}]
}
Q. SLMを使うと、LLMに比べて精度が落ちるのでは?
A. 特定タスクに特化させたり、外部検索(RAG)やルールベースシステムと組み合わせたりすることで、多くの場合、実用上十分な精度を維持することは可能です。LLMと比較してハルシネーション(幻覚)が少ない傾向も報告されています。ただし、汎用性や極めて高い精度が求められる場合はLLMが適していることもあります。
Q. エッジデバイス上でAIが故障したり、動かなくなったらどうするの?
A. OTA (Over-the-Air、無線経由でのソフトウェア更新) でソフトウェア更新やモデルの再デプロイを行うのが一般的です。冗長構成や、異常時に待機系へ切り替えるフェイルオーバー設計も重要になります。サービス完全停止のリスクを最小化するための運用設計が必要です。
Q. デバイス上でAIモデルを動かすのは、セキュリティ的に危険では? 不正コピーされない?
A. TPM (Trusted Platform Module、セキュリティチップ) 等のセキュアエレメントと暗号化技術を用いてモデルを保護し、デバイス固有の鍵管理などで不正コピー対策を行うのが一般的です。しかし、物理的なアクセスが可能となるエッジ環境特有のセキュリティリスクは存在するため、多層的な防御策(セキュアブート、アクセス制御、通信の暗号化、脆弱性管理など)が不可欠です。
第10部:結論と最初の一歩:アクションチェックリスト
本稿では、AI推論に伴うコストや遅延等の課題に対し、エッジ AI × SLM(Small Language Model) が有力な解決策の一つとなりつつある理由と、その期待されるビジネスインパクト、そして導入における課題について解説してきました。
最後に伝えたいメッセージ
AI 活用の重心は、選択肢として クラウド中心からエッジとの連携・分散へ と移行を検討する価値が高まっています。
これは単なる技術トレンドではなく、
コスト構造、サービス品質(レイテンシ)、データガバナンス、そして競争優位の源泉
を見直す契機となり得る、構造的な転換点です。
クラウドから「AI を借りる」だけでなく、自社デバイスに AI を実装・最適化していくアプローチも視野に入れる時代が到来しつつあります。――自社の状況に合わせてこの変化をどう捉え、活用していくか、その検討を始めることが重要ではないでしょうか?
最初の一歩を踏み出すためのアクションチェックリスト
下記の項目を “現状把握/検討済/未着手” などで評価できれば、エッジ AI × SLM 導入検討の準備が進んでいると言えます。未着手の項目から具体化してみてください。
| # | チェック項目 |
|---|---|
| □ | 自社の AI推論コスト と レイテンシ要件 を定量把握しているか |
| □ | GDPR など データ規制への対応状況を整理し、エッジ化で改善できる可能性を評価したか |
| □ | エッジ AI / SLM が効果を発揮しそうな 具体ユースケース を洗い出したか |
| □ | PoC に必要な SLM・エッジデバイス・最適化技術 の調査・選定を開始したか |
| □ | ハイブリッドアーキテクチャ(クラウド+エッジ)の設計方針と開発・運用体制を検討したか |
| □ | エッジ固有の セキュリティ対策 を理解し、導入計画に反映する準備があるか |
| □ | 自社状況に基づいた ROI シミュレーション を行い、リスクや不確実性を含めて経営層へ説明できるか |
この記事が、皆さまの エッジ AI × SLM 戦略検討の一助となれば幸いです。
用語集(30秒で復習)
- SLM (Small Language Model): 軽量で効率的な言語モデル。特定のタスクで高い性能を発揮し得る。
- NPU (Neural Processing Unit): AI計算に特化した省電力チップ。GPUより一般的に省エネ。
- 知識蒸留: 大モデルから小モデルへ知識を転写する技術。
- 量子化: AIモデルの数値(パラメータ)を低ビット(例: 4/8bit整数)に圧縮する技術。モデルサイズ削減と高速化に寄与。
- LoRA (Low-Rank Adaptation): 少ない追加パラメータで効率的にAIモデルを特定のタスクに適応させる技術。
- RAG (Retrieval-Augmented Generation): AIモデルが外部データベースを検索し、その結果を考慮して回答を生成する技術。知識の補完や最新情報への対応に有効。
- OTA (Over-the-Air): 無線通信を経由してソフトウェアなどを更新する技術。エッジデバイスの管理に重要。
- TPM (Trusted Platform Module): ハードウェアレベルでセキュリティ機能を提供するチップ。モデルやデータの保護に利用。
あわせて読みたい
- 効率的なAIの時代 – 学習から推論へのパラダイムシフト
- フィジカルAI最前線:生成AI×ロボット革命【技術解説・事例・未来図】
- 5大AIモデル比較!GPT-4.5・Gemini・Claude・LLaMA 3・Grokの進化と未来
参考文献
(注記: 以下のリストは主要な参考情報源の例です。リンク先の有効性や内容は時間とともに変化する可能性があります。)
- Epoch AI: How much energy does ChatGPT use? (https://epoch.ai/gradient-updates/how-much-energy-does-chatgpt-use)
- OpenAI Pricing (https://openai.com/pricing)
- U.S. EIA FAQ – How much electricity does an American home use? (https://www.eia.gov/tools/faqs/faq.php?id=97&t=3)
- Eurostat – Electricity price statistics (https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Electricity_price_statistics)
- NVIDIA Blog: What’s the Difference Between a CPU, GPU, and NPU? (https://blogs.nvidia.com/blog/whats-the-difference-between-a-cpu-gpu-and-npu/)
- ResearchGate: Edge AI vs Cloud AI… Latency… (Example) (https://www.researchgate.net/publication/390711129_Edge_AI_vs_Cloud_AI_Comparative_Performance_and_Latency_in_Real-Time_Applications)
- Hugging Face: Open LLM Leaderboard (https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- ISO/TS 15066:2016 Robots and robotic devices… (https://www.iso.org/standard/62462.html)
- Bosch Press Release: ConnectedWorld 2024 (https://www.bosch-presse.de/pressportal/de/en/news/connected-world-2024-bosch-presents-innovations-for-an-ai-driven-future-268741.html)
- Art. 83 GDPR – General conditions for imposing administrative fines (https://gdpr-info.eu/art-83-gdpr/)
- (その他、元記事にあった参考文献や、表内で使用したリンクなども必要に応じて精査・追記してください。)
以上
ケニー狩野(中小企業診断士、PMP、ITコーディネータ)
キヤノン(株)でアーキテクト、プロマネとして多数のプロジェクトをリード。
現在、株式会社ベーネテック代表、株式会社アープ取締役、一般社団法人Society 5.0振興協会評議員ブロックチェーン導入評価委員長。
これまでの知見を活かしブロックチェーンや人工知能技術の推進に従事。趣味はダイビングと囲碁。
2018年「リアル・イノベーション・マインド」を出版。








