


AIの脳を再設計せよ:KANsとFlow Matchingの革新
説明可能・省エネ・高性能。AIが“脳”の設計から進化を遂げようとしている。(2025/6/17更新)
今回は、AI研究の最前線から、未来のビジネスや社会を根底から変える可能性を秘めた、極めて重要な技術トレンドについてお届けします。ChatGPTやMidjourneyのような生成AIが私たちの日常を劇的に変えた「第一章」が終わり今まさにAIの歴史は「第二章」へ。その核心は、AIの”脳”そのものを再設計する動きにあります。
これまでのAIは確かに賢いですが、その成功の裏で2つの大きな課題が浮き彫りになりました。一つは、AIの判断プロセスが人間には理解できない「ブラックボックス問題」。そしてもう一つは、その性能を維持・向上させるために「莫大な電力と計算コストがかかる」というスケーリングの壁です。
しかし、今日ご紹介する「KANs (Kolmogorov-Arnold Networks)」と「Flow Matching」という2つの新しいアーキテクチャ(設計思想)は、これらの根本課題に真正面から挑戦し、解決する可能性を示しています。本記事では、これらの技術がなぜ革命的なのか、その仕組みからビジネス、社会へのインパクトまで、図解を交えながら分かりやすく、そして深く掘り下げていきます。AI革命の第二章、そのワクワクする最前線の旅へ、一緒に出かけましょう。
なぜ今、新しいAIの”脳”が必要なのか? – 現在のAIが直面する2つの壁
まず、根本的な問いから始めましょう。「なぜ、今、AIの新しい設計図が必要なのか?」
Transformerや拡散モデルをはじめとする現在の主流AIは、自然言語処理から画像生成まで、かつてSFの世界だったことを次々と現実のものとしました。しかし、その輝かしい成功の陰で、無視できない深刻な課題が顕在化しているのです。
壁①:ブラックボックス問題 – AIへの信頼を蝕む不透明性
現代のAI、特に大規模言語モデル(LLM)は、数千億にも及ぶパラメータが複雑に絡み合った結果として答えを出力します。しかし、「なぜ、他の選択肢ではなくその結論に至ったのか?」という問いに対して、人間が納得できる形で理由を説明することができません。これが「ブラックボックス問題」です。
この不透明性は、特に以下のような分野でAI導入の大きな障壁となっています。
❶ 金融・保険
融資審査や保険金支払いの査定で「AIがそう判断しました」では、顧客や規制当局への説明責任を果たせません。判断の根拠をトレースできないシステムは、規制の厳しい業界では致命的です。
❷ 医療
AIが診断を下したり治療法を提案したりする場合、その根拠が不明瞭では医師は最終判断を下せず、患者の同意(インフォームド・コンセント)も得られません。人命に関わる現場では、説明可能性は絶対条件です。
❸ 自動運転・重要インフラ
事故が発生した際、AIの判断プロセスを検証できなければ、原因究明や再発防止が困難になります。社会的な受容を得るためにも、透明性の確保が不可欠です。
いかにAIの精度が高くとも、その判断プロセスが密室の中にあっては、人命や社会の重要決定に関わる領域で安心して使うことはできません。この信頼性の危機を乗り越えるため、次世代AIには「説明可能性(Explainable AI, XAI)」が強く求められています。
壁②:スケーリングの壁 – 巨大化がもたらすコストと環境負荷
「性能を上げるには、モデルを巨大にする(=パラメータを増やす)」という、いわゆる”スケール則”がこれまでのAI開発を牽引してきました。しかし、この力技とも言えるアプローチは、今や限界に達しつつあります。
❶ 経済的コストの爆発
最先端AIの開発・運用には、NVIDIAのH100のような高性能GPUを数千〜数万個規模で稼働させる必要があり、その設備投資と運用コストは数百億円から数千億円に達します。これにより、AI開発は豊富な資金力を持つ一部の巨大テック企業に独占され、イノベーションの多様性が損なわれる「AI格差」が深刻化しています。
❷ 環境負荷の増大
AIモデルの学習と推論には、データセンターを通じて膨大な電力が消費されます。その電力消費量は、一国のそれに匹敵するとも言われ、地球温暖化への影響も懸念されています。持続可能性(サステナビリティ)の観点からも、よりエネルギー効率の良い、いわゆる「グリーンAI」への転換が急務です。
❸ 性能向上の鈍化
さらに、モデルサイズを大きくし続けても、性能の向上が次第に飽和し始める「収穫逓減」の兆候も指摘されています。これは、単に大きくするだけではない、よりスマートなAIの設計思想が必要であることを示唆しています。
これらの課題を克服し、「より賢く(高性能)、より分かりやすく(高解釈性)、そしてより効率的に(省エネ・高速)」動くAIを実現すること。これが、次世代アーキテクチャに課せられたミッションなのです。その挑戦の中で今、最も大きな注目を集めているのが、KANsとFlow Matchingです。
解決策① KANs:AIのブラックボックスに光を灯す新設計
さて、いよいよ本題の一つ目、KANs (Kolmogorov-Arnold Networks)の登場です。2024年5月にMITの研究チームによって提案されたこの新しいアーキテクチャは、AIコミュニティに大きな衝撃を与えました。
計算の主役が交代! KANsの革新的な仕組み
KANsがなぜ革命的なのか?それは、従来のAI(多層パーセプトロン:MLP)とは計算のやり方が根本的に異なる点にあります。これまでのAIは、図1が示すように、回路の「点(ノード)」に固定された活性化関数(例:ReLU)があり、そこで複雑な計算を行っていました。点と点をつなぐ「線(エッジ)」は、単に情報の重み(単一の数値)を伝えるだけの比較的単純な役割でした。
の仕組み2-1.png)
KANsは、この主役と脇役の関係を大胆にも逆転させました。図2をご覧ください。KANsでは計算の主役は「線(エッジ)」に移ります。一つ一つの線が、単なる数値ではなく、データに応じて形状が変化する「学習可能な関数(スプライン関数)」そのものとして機能するのです。一方で、「点(ノード)」の役割は非常にシンプルになり、接続されているエッジからの出力値を単純に合計するだけ(Σ)になりました。
これは、20世紀の数学者コルモゴロフとアーノルドが証明した「コルモゴロフ-アーノルド表現定理」という数学理論に着想を得ています。非常にざっくり言うと、「どんなに複雑な多次元の関数(例えば、3Dの複雑な地形)でも、実は単純な一次元の関数(単なる曲線)の組み合わせだけで表現できる」という驚くべき定理で、KANsはこの数学的な保証をAIの設計に大胆に取り入れたのです。
の仕組み2.png)
KANsがもたらす3つの衝撃的なメリット
この「計算の主役を点から線へ」という根本的な発想の転換が、ビジネスや科学に計り知れないインパクトをもたらす可能性を秘めています。
❶ 驚異的なパラメータ効率
KANsが注目される最大の理由は、その圧倒的な効率性です。論文では、特定の数学的な問題を解くタスクにおいて、KANsが従来のMLPの100分の1未満のパラメータ数で、より高い精度を達成したと報告されています。これは、AIモデルを劇的に小型化・軽量化できることを意味します。結果として、メモリ消費や計算コスト、電力消費を大幅に削減でき、これまで巨大テック企業しか扱えなかった高性能AIを、より多くの企業や研究者が扱える「AIの民主化」を加速させます。
❷ 高い解釈可能性
KANsでは、学習が完了した後、各エッジ(線)がどのような「関数」の形になったかをグラフとして視覚的にプロットできます。これにより、「AIがデータから何を学習し、どのように判断したのか」という思考プロセスを人間が直感的に理解しやすくなります。例えば、あるエッジがsin波のような周期的な関数を学習していれば、「この入力と出力には周期的な関係がある」と解釈できます。これはブラックボックス問題への強力な解決策であり、AIへの信頼性を飛躍的に高めます。
❸ 科学的発見の加速
この高い解釈性は、科学研究の進め方をも変えるかもしれません。KANsは、実験データや観測データの中から、その背後に隠れている数学的な関係性や物理法則を「発見」するツールとして利用できる可能性があります。人間がまだ気づいていない新たな科学的法則のヒントを、AIがデータから見つけ出してくれる。そんな未来が訪れるかもしれません。
KANsの課題と今後の展望
もちろん、KANsはまだ発展途上の技術であり、いくつかの課題も指摘されています。最大の課題は、現状では学習速度が従来のMLPに比べて遅い点です。各エッジが単純な数値ではなく関数を持つため、計算が複雑になるためです。しかし、この問題は今後の研究によるアルゴリズムの改善や、KANsの計算に最適化された専用ハードウェア(AIチップ)の開発によって解決される可能性があります。また、画像認識や自然言語処理といった、現在のAIが得意とする大規模データセットを扱うタスクにおいて、従来のTransformerアーキテクチャに対してどの程度の性能を発揮できるかは、まだ検証段階です。これらの課題を乗り越えた時、KANsは真に次世代の標準となる可能性を秘めています。
解決策② Flow Matching:生成AIを高速・高品質にする新潮流
次に、MidjourneyやStable Diffusionに代表される生成AIの世界で起きているもう一つの革命、「Flow Matching(フロー・マッチング)」です。
彫刻家から、天才的な設計士へ:生成プロセスの革新
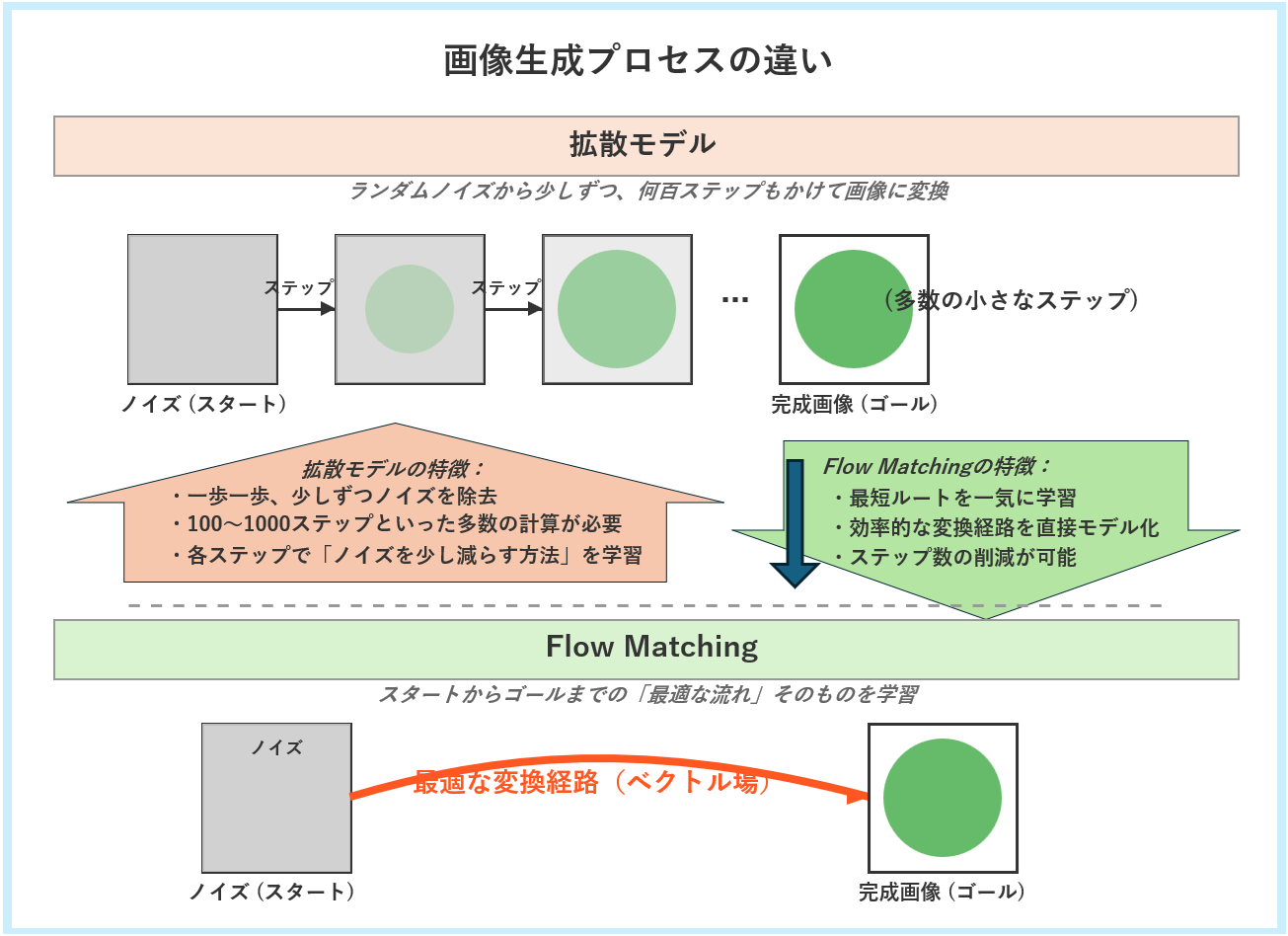
図3の上半分に描かれているのが、これまでの主流だった「拡散モデル(Diffusion Model)」のアプローチです。これは、完全なノイズ画像(砂嵐のような状態)からスタートし、「ノイズを少し取り除く」という作業を何百回、時には千回以上も繰り返して、最終的にクリーンな画像を生成します。まるで彫刻家が、大理石の塊から少しずつ不要な部分を削り出して、最終的な像を掘り出す作業に似ています。非常に高品質な画像を生成できますが、ステップ数が多いため生成に時間がかかるのが課題でした。
一方、図3の下半分に描かれている「Flow Matching」は、全く異なるアプローチを取ります。ノイズ(スタート)から完成画像(ゴール)まで、データが変化していく「最も効率的な流れ(フロー)」そのものを、ベクトル場として一度に直接学習します。これは例えるなら、山頂から麓まで、石を一つ一つ転がして道を探すのではなく、最も速く滑り降りられる完璧な”滑り台”の形状そのものを一気に設計してしまうようなものです。この「流れ」は、数学的には常微分方程式(ODE)として記述され、理論的な見通しの良さも特徴です。
Flow Matchingがビジネスにもたらす価値
この賢いアプローチは、理論がシンプルで学習が安定しやすいため、開発者にとって扱いやすいという利点があります。そして、ビジネスにおいては以下の価値をもたらします。
❶ 高速・高品質なクリエイティブ生成
Flow Matchingは、より少ないステップ数で高品質な生成を可能にします。これにより、ユーザーはより速く、よりインタラクティブにAIとの対話や創作活動を行えるようになります。最新の画像生成AI「Stable Diffusion 3」がこの技術と従来の知見を組み合わせたアーキテクチャを採用したことからも、その性能の高さがうかがえます。
❷ 多様な応用可能性
この技術は画像生成だけに留まりません。その柔軟なフレームワークは、動画、3Dモデル、音楽、音声といった様々なデータの生成に応用可能です。さらに、創薬のための分子構造生成や、金融市場における価格変動シミュレーション、製造業におけるサプライチェーン最適化など、より高度な科学・産業分野での活用も期待されています。
Flow Matchingの課題と今後の展望
Flow Matchingもまた発展途上の技術であり、さらなる進化が期待される領域です。例えば、生成されるコンテンツの「忠実度(Fidelity、指示にどれだけ忠実か)」と「多様性(Diversity、どれだけ多彩な結果を出せるか)」のバランスをどう最適化するかは、活発な研究テーマです。また、どのような「流れ」のパス(線形か非線形かなど)を学習させるのが特定のタスクに最適なのか、その戦略についても研究が進められています。拡散モデルで培われた膨大な知見とFlow Matchingの新しいアイデアが融合することで、今後さらに高性能で効率的な生成AIが登場するでしょう。
結論:AI革命第二章が拓く未来 – 社会・経済へのインパクト
さて、KANsとFlow Matchingという二つの革命的技術が切り拓く未来とは、どのようなものでしょうか? これらは単なる研究室の中の話ではありません。図4が示すように、その衝撃はドミノ倒しのように社会全体へと広がっていきます。
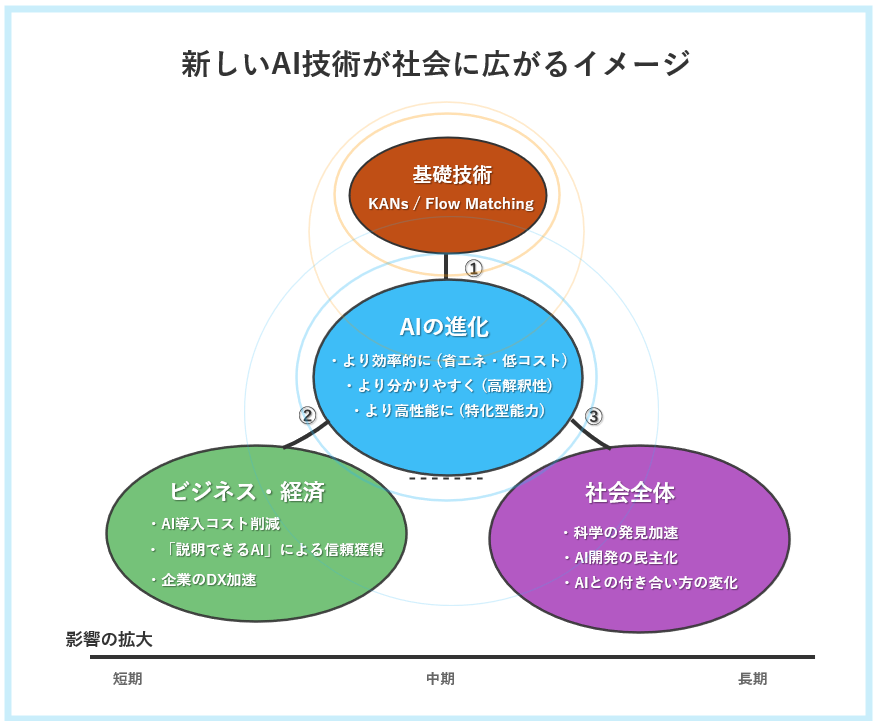
この変革の波は、まず「① AI自身の進化」から始まります。AIはより省エネ・低コストになり、判断根拠を説明できるようになり、そして高性能になります。次に、その進化したAIが「② ビジネス・経済」に波及します。AI導入コストの低下は企業のDXを加速させ、「説明できるAI」は金融や医療などの規制産業に新たなサービスを生み出します。例えば、「Explainable AI as a Service (XAIaaS)」といった新しいビジネスモデルや、中小企業が高効率なカスタムAIを開発できるようなローコード・プラットフォームが登場するかもしれません。スタートアップも大企業と対等に戦える土壌が整い、競争環境は一変するでしょう。
最終的に、その影響は「③ 社会全体」へと広がります。KANsは科学的発見を加速させ、Flow Matchingはクリエイティブ産業の姿を変えるかもしれません。そして何より、AIが「理由が分からない魔法の箱」から「理解可能な信頼できるパートナー」へと変わることで、私たちのAIとの付き合い方、そして社会のあり方そのものが、より建設的なものへと変わっていくのです。
AIは、ただ「賢い」だけの存在から、「効率的で、わかりやすく、信頼でき、誰でも使える」存在へと進化しようとしています。もちろん、これらの技術はまだ発展途上です。しかし、そのポテンシャルは計り知れません。AI革命の第二章の幕は、確実に上がり始めています。
よくある質問(FAQ)
▶ Q1. KANsの革新的な点は、一言で言うと何ですか?(クリックで開閉)
A1. 計算の主役を、従来の「点(ノード)」から「線(エッジ)」に変えたことです。これにより、AIの内部構造が可視化しやすくなり(説明可能性の向上)、同時にはるかに少ない部品(パラメータ)で高い性能を発揮できる(効率性の向上)ようになりました。
▶ Q2. Flow Matchingは拡散モデルより常に優れているのですか?(クリックで開閉)
A2. 一概には言えません。Flow Matchingは学習の安定性や理論のシンプルさ、生成速度の面で大きな利点がありますが、拡散モデルも長年の研究で培われた非常に強力な技術です。最新のStable Diffusion 3のように、両者の良い点を組み合わせたハイブリッドなアプローチが今後の主流になる可能性もあります。
▶ Q3. これらの新技術は、いつ頃私たちのビジネスに影響しますか?(クリックで開閉)
A3. 既に影響は始まっています。例えば、最新の画像生成AI「Stable Diffusion 3」はFlow Matchingの知見を活用しています。KANsはまだ研究開発段階の側面が強いですが、そのポテンシャルの高さから世界中の研究機関や企業が開発を加速させています。今後1~3年で、より多くの実用的なアプリケーションが登場すると予測されます。
▶ Q4. これらの技術は、現在の主流であるTransformerを置き換えるのでしょうか?(クリックで開閉)
A4. 現時点では「置き換える」と断言するのは時期尚早です。Transformerアーキテクチャは、特に自然言語処理において圧倒的な実績と巨大なエコシステムを築いています。KANsやFlow Matchingは、Transformerが苦手とする可能性のある領域(高い解釈性が必要な科学計算や、極めて効率的な生成など)でまず強みを発揮し、将来的にはTransformerの一部と融合・共存していく可能性が高いと考えられます。
▶ Q5. これらの技術の登場で、NVIDIAのようなGPUメーカーへの影響はありますか?(クリックで開閉)
A5. 影響は十分に考えられます。短期的には、AI開発競争が続くためGPUへの需要は高いままでしょう。しかし中長期的には、KANsのようにパラメータ効率が極めて高いAIが主流になれば、必要なGPUの数が減る可能性があります。一方で、KANsのような新しい計算原理に最適化された、次世代のAIチップ(NPUなど)を開発する新しいプレイヤーが台頭する可能性もあり、ハードウェア市場の勢力図が変化するきっかけになるかもしれません。
参考記事
- KAN: Kolmogorov-Arnold Networks (arXiv) – KANsの原論文です。
- Flow Matching for Generative Modeling (arXiv) – Flow Matchingの原論文です。
- Stable Diffusion 3 Announcement (Stability AI) – Flow Matchingの採用に言及した公式発表です。
以上
筆者プロフィール:ケニー狩野
中小企業診断士、PMP、ITコーディネータ
キヤノン株式会社にてアーキテクト、プロジェクトマネージャーとして数々のプロジェクトを牽引。その豊富な経験を基に、現在はブロックチェーンや人工知能(AI)といった先端技術の社会実装と推進に注力中。
現在の主な役職:
・株式会社ベーネテック 代表
・株式会社アープ 取締役
・一般社団法人Society 5.0振興協会 評議員 ブロックチェーン導入評価委員長
2018年には著書「リアル・イノベーション・マインド」を出版。
趣味はダイビングと囲碁。








