


Databricks対Snowflake、AI時代のデータ基盤を比較
📌データとAIの民主化を掲げる巨大ユニコーンの全貌を徹底分析
▼ この記事の信頼性の源泉(クリックで開閉)
本記事では、AIの進化を支える技術的背景を多角的に捉え、専門知識をわかりやすく解説します。筆者はハードウェアからクラウド基盤、AI実装まで幅広い開発領域で活動、技術戦略や製品開発にも携わってきました。特に2015年以降は、ディープラーニングの急速な発展に加え、生成AIや大規模言語モデル(LLM)の動向を継続的に分析・発信しています。単なる情報整理にとどまらず、現場で培ったリアルな視点を交えた分かりやすい考察をお届けすることを目指しています。
Databricksとは何か?
Databricksの使命と成り立ち、そして現在の市場でのポジションを概観します。Apache Sparkの開発者たちが創業し、今や9兆円超の評価を受けるに至った背景を探ります。
Databricksは、2013年に設立されたアメリカの企業で、企業が持つ大量のデータを簡単に活用できるようにするクラウドサービスを提供しています。「データとAIの民主化」をコアビジョンに掲げ、これまで専門家しか扱えなかった複雑なデータ分析やAI開発を、普通のビジネスパーソンでも使えるようにすることを目指しています。
同社の技術的な信頼性は、その学術的な出自に深く根ざしています。カリフォルニア大学バークレー校のAMPLabでApache Sparkを開発した研究者チームが創業し、このApache Sparkという革新的なデータ処理技術を商業的に発展させたのがDatabricksの始まりです。(出典: Databricks公式サイト)
2024年12月のシリーズJラウンドでは、会社の評価額が620億ドル(約9兆円)に達しました。(出典: Databricks公式発表)これは競合のSnowflake社の2025年7月上旬時点での時価総額(約725億ドル[出典])と比較しても遜色ない評価額です。また、年間経常収益(ARR)は2025年7月には37億ドルに達する見込みであるなど、財務面でも盤石な基盤を築いています。(出典: CNBC)
Apache Sparkとは
大量のデータを高速で処理するためのオープンソースのソフトウェア技術のこと。従来のMapReduce技術より圧倒的に速くデータを処理できるため、世界中の企業で使われています。メモリ上でのデータ処理により、従来比で最大100倍の高速化を実現できるとされています。(出典: Databricks解説ページ)
なぜDatabricksが注目されているのか
Databricksの評価を決定づけた革新的な「レイクハウス」アーキテクチャと、業界標準を確立したオープンソース戦略、そして顧客にデータの所有権を残すという画期的なビジネスモデルを解説します。
革新的な技術「レイクハウス」の開発
従来、企業はデータを保存・活用する際に2つの選択肢しかありませんでした:
- データウェアハウス:決まった形式の構造化データを高速で分析できるが、コストが高く、決められた用途にしか使えない
- データレイク:あらゆる形式のデータを安く保存できるが、データの品質管理が難しく、使いこなすのが困難
Databricksが開発したレイクハウスは、この2つの良いところを組み合わせた次世代アーキテクチャです。安いコストで大量のデータを保存しながら、高品質で高速な分析も可能にします。
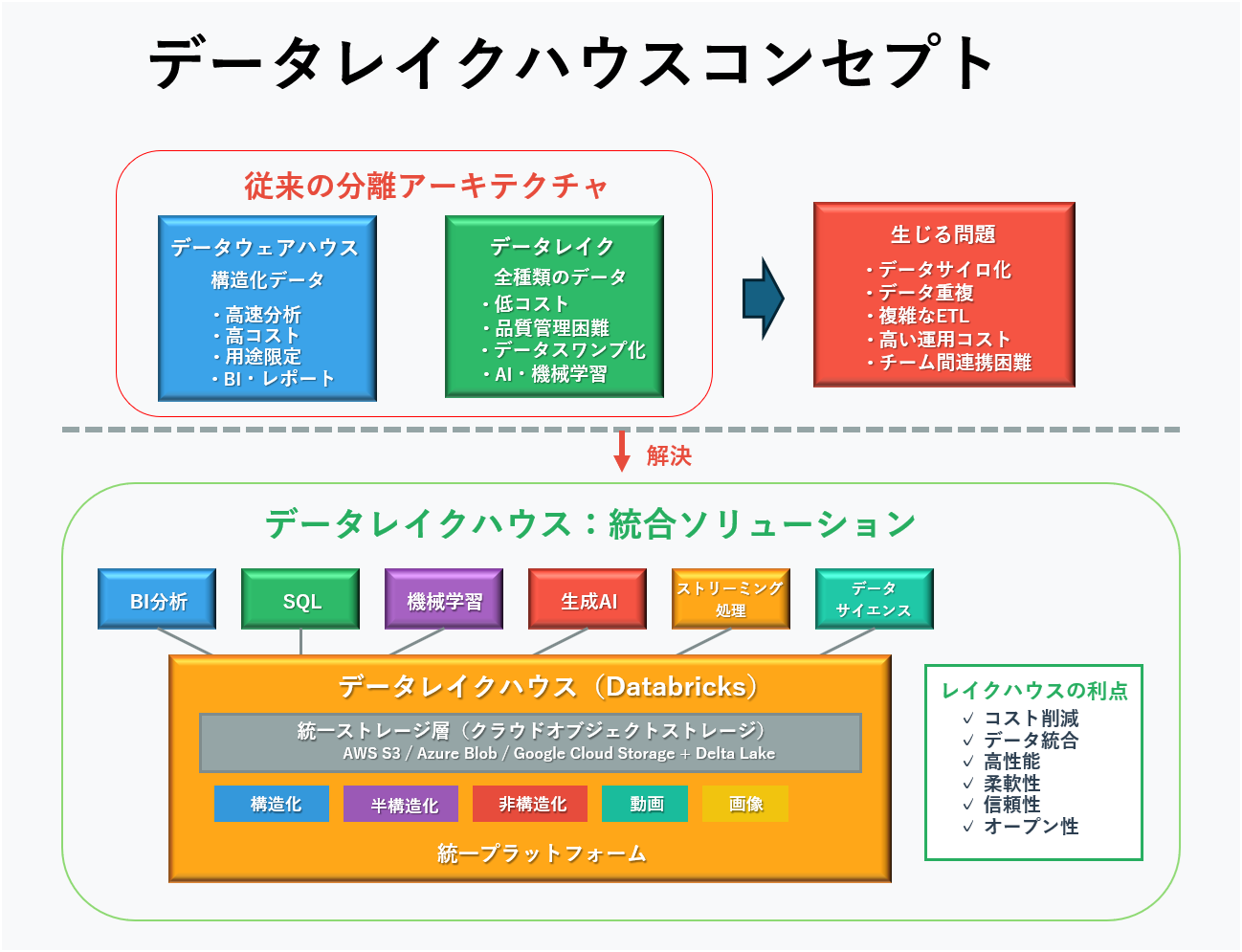 図1データレイクハウスコンセプト
図1データレイクハウスコンセプト
レイクハウスが解決する根本的な問題
従来の企業では、BIやレポーティング用のデータとAI・機械学習用のデータが別々のシステムに保管されていました。この分離により深刻なデータサイロが生まれ、以下のような問題が起きていました:
- データの重複による保存コストの無駄
- ETL処理の複雑化によるシステム構築・運用コストの増大
- チーム間でのデータ共有困難による同じ分析の重複実施
- 分析対象データの陳腐化による意思決定の精度低下
レイクハウスは、構造化・半構造化・非構造化といったあらゆる種類のデータを単一のプラットフォームで管理し、SQL分析、BI、データサイエンス、機械学習、ストリーミング処理といった全てのワークロードを同じデータ上で実行できるようにしました。
| 項目 | データウェアハウス | データレイク | レイクハウス |
|---|---|---|---|
| 対応データタイプ | 構造化データのみ | 全種類(品質管理困難) | 全種類(品質管理可能) |
| 処理速度 | 高速 | 低速 | 高速 |
| コスト | 高い | 安い | 安い |
| 主な用途 | BI・レポート | AI・機械学習 | 全ワークロード統合 |
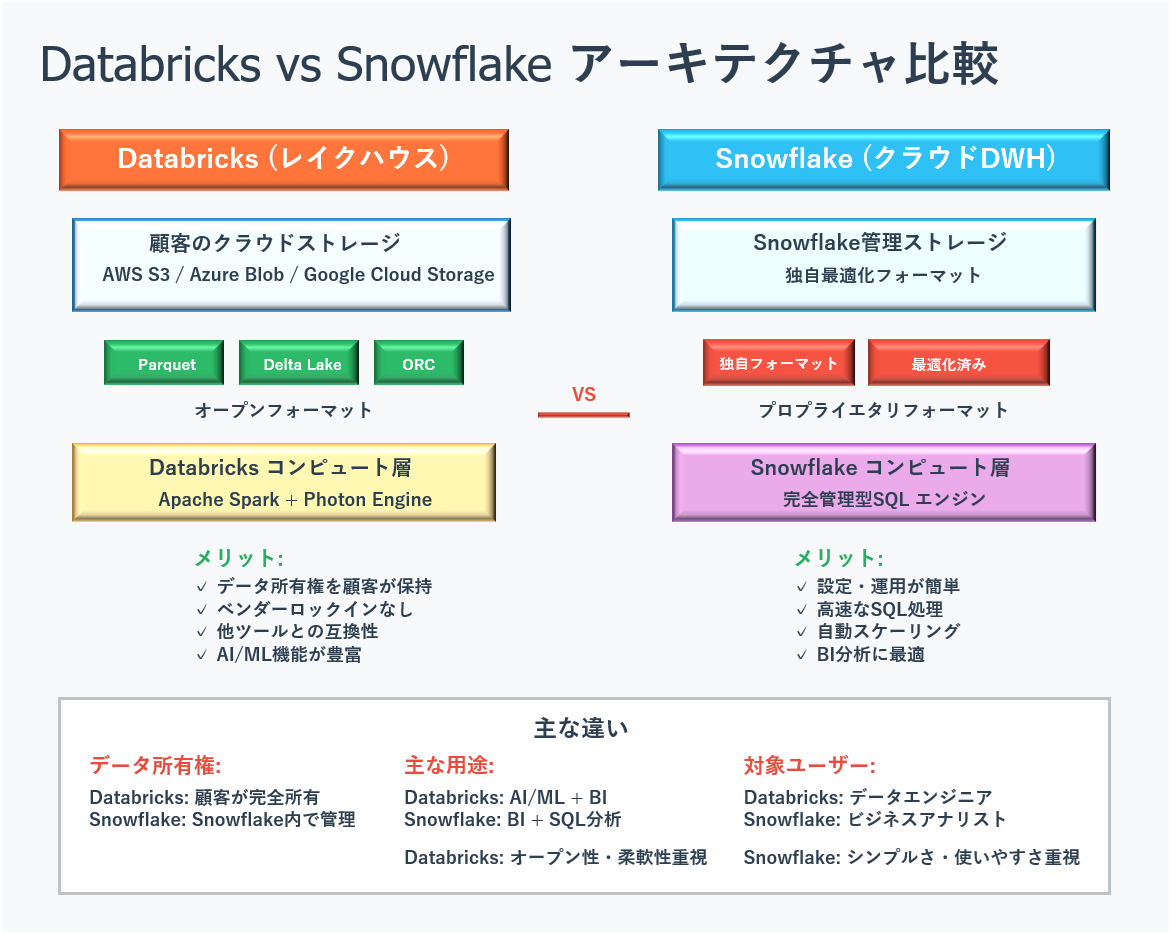 図3 Databricks vs Snowflake アーキテクチャ比較
図3 Databricks vs Snowflake アーキテクチャ比較 オープンソース戦略による業界標準の確立
Databricksは自社の技術をオープンソースとして公開し、世界中の開発者コミュニティと協力して技術を発展させています。Apache Spark、Delta Lake、MLflowといった基盤技術を開発・公開することで、有料顧客になる前の段階から多くの開発者がDatabricksの技術に習熟し、巨大なコミュニティが形成されます。
その結果、これらの技術は業界のデファクトスタンダードとしての地位を確立し、企業が本格導入を検討する際には、最も自然で信頼性の高い選択肢となります。この「コミュニティ主導の成長」モデルは、強力かつ自己強化的なセールスファネルを構築すると同時に、プロプライエタリな技術に依存する競合他社に対する強力な堀(moat)となっています。
データの所有権を顧客に残す画期的なアプローチ
他の多くのサービスでは、データを使うために専用のシステムにデータを移す必要があります。一度移すと、他のシステムに移行するのが困難になるベンダーロックインという問題が起きます。
Databricksは違います。顧客のデータは顧客自身のクラウドストレージ(AWS S3、Azure Blob Storage、Google Cloud Storage)にApache ParquetやORCといったオープンなファイルフォーマットで保存され、Databricksはその上でコンピュート処理やガバナンス機能を提供するだけです。
このデータとコンピュートの分離アーキテクチャにより、以下のメリットが生まれます:
専門用語解説
- レイクハウス:データウェアハウスの信頼性・性能とデータレイクの柔軟性・低コストを1つのプラットフォームで実現する革新的なデータ管理システム
- ETL:Extract(抽出)、Transform(変換)、Load(読み込み)の略。データを別のシステムから取り出し、使いやすい形に整えて、目的のシステムに格納する一連の処理
- データサイロ:部門やシステムごとにデータが分断され、他の部門からアクセスできない状態
- BI(ビジネスインテリジェンス):企業が持つデータを分析・可視化して、経営判断に活用する仕組みやツール
- ベンダーロックイン:特定の企業の製品やサービスに依存してしまい、他社製品への乗り換えが困難になる状況
- デファクトスタンダード:法的な規格ではないが、市場で広く使われることで事実上の業界標準となった技術や製品
Databricksの技術的特徴を詳しく解説
プラットフォームの強さを支える「メダリオンアーキテクチャ」「Delta Lake」「Unity Catalog」、そしてAI開発機能「Mosaic AI & MLflow」といった核心技術の仕組みと利点を解説します。
メダリオンアーキテクチャ:データ品質の3段階管理
Databricksでは、データを品質に応じて3段階で管理するメダリオンアーキテクチャという仕組みを採用しています。これは、レイクハウスを実践的に実装するための設計パターンとして広く採用されています。
- ブロンズテーブル:様々なソースから集めた生データをそのまま保存する層
- シルバーテーブル:ブロンズのデータをクレンジング、フィルタリング、エンリッチメントして、検証済みの状態に加工した層
- ゴールドテーブル:シルバーのデータをビジネス要件に合わせて集計し、BIや分析レポートに最適化した層
この多段階のアーキテクチャにより、データはパイプラインを通過する過程で段階的に品質が向上し、最終的にはSingle Source of Truthが提供されます。
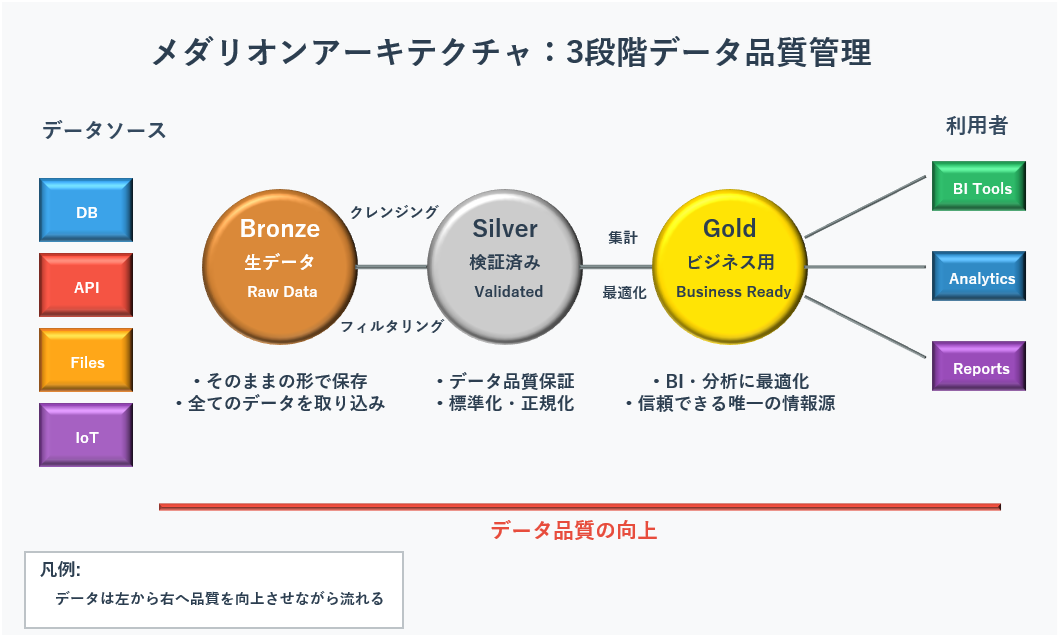 図3 Databricksメダリオンアーキテクチャの3段階データ処理フロー図
図3 Databricksメダリオンアーキテクチャの3段階データ処理フロー図Delta Lake:データレイクに信頼性をもたらす革新技術
Delta Lakeは、データレイクハウスを実現する核心的な技術で、データレイクにデータウェアハウスのような信頼性をもたらすオープンソースのストレージレイヤーです。
Delta Lakeの主要機能
- ACIDトランザクション:複数のユーザーやプロセスが同時にデータの読み書きを行う際に、データの完全性と一貫性を保証
- スキーマエンフォースメント:データ書き込み時にスキーマを強制し、意図しないデータの混入を防止
- スキーマエボリューション:ビジネスの変化に合わせてスキーマを柔軟に変更することが可能
- タイムトラベル機能:テーブルへの全ての変更履歴が自動的にバージョン管理され、過去の任意の時点のデータを照会可能
これらの機能により、従来はデータウェアハウスでしか実現できなかったエンタープライズグレードの信頼性を、低コストなデータレイク上で実現できます。
| 機能 | 従来のデータレイク | Delta Lake | ビジネス価値 |
|---|---|---|---|
| データ品質保証 | なし | スキーマ強制 | 分析結果の信頼性向上 |
| 同時アクセス | データ破損リスク | ACID保証 | チーム協業の安全性 |
| 履歴管理 | 手動実装が必要 | 自動バージョン管理 | 監査・コンプライアンス対応 |
| エラー対応 | 復旧困難 | タイムトラベル機能 | 迅速な問題解決 |
プラットフォームの主要機能
Databricks SQL:BIワークロードへの本格参入
Databricks SQLは、BIや分析レポート作成といった従来のデータウェアハウスのワークロードを実行するために設計された、サーバーレスのデータウェアハウス機能です。
C++で書かれた高性能クエリエンジン「Photon」により、Snowflakeなどの競合製品と遜色ない価格性能比を実現し、TableauやPower BIといった主要なBIツールとの連携も可能です。これにより、Databricksはデータサイエンス専用ツールから総合データプラットフォームへと進化しました。
Unity Catalog:統一ガバナンスの実現
Unity Catalogは、テーブル、ファイル、機械学習モデル、ダッシュボードといった、あらゆるデータとAI資産を複数のクラウドにまたがって一元的に管理するための統一ガバナンスレイヤーです。
主な機能:
- きめ細かなアクセス制御:行レベル・列レベルでの権限設定
- データリネージの自動追跡:データの流れと依存関係を可視化
- 監査ログ:全てのデータアクセスを記録・追跡
- クロスクラウド対応:AWS、Azure、GCP間でのデータ共有
Mosaic AI & MLflow:エンドツーエンドのAI開発支援
DatabricksのAI・機械学習における能力は、競合他社に対する大きな差別化要因です:
- MLflow:実験の追跡からモデルのパッケージング、本番環境へのデプロイ、運用監視まで、機械学習のライフサイクル全体を管理するオープンソースプラットフォーム
- Mosaic AI:MosaicMLの買収(出典)によって強化された生成AI関連機能の統合ブランド。LLMの構築、ファインチューニング、デプロイ、ガバナンスを支援
- DBRX:自社開発したオープンソースLLM。GPT-3.5クラスの性能を誇ります。(出典: Databricks公式ブログ)
専門用語解説
- メダリオンアーキテクチャ:データを品質レベルに応じてブロンズ・シルバー・ゴールドの3層で管理する設計パターン
- エンリッチメント:既存のデータに追加情報を付加して価値を高める処理
- Single Source of Truth:組織内で「唯一正しい情報源」として認められるデータ
- ACIDトランザクション:データベースで複数の処理を安全に実行するための仕組み(原子性・一貫性・独立性・持続性)
- スキーマ:データベースのテーブル構造(列名、データ型など)を定義したもの
- サーバーレス:サーバーの管理や設定を気にせずにアプリケーションを実行できるクラウドサービスの形態
- データリネージ:データがどこから来て、どのような処理を経て、どこに行くかを追跡する仕組み
- LLM:Large Language Modelの略で、ChatGPTのような大規模な言語AIモデル
- ファインチューニング:既存のAIモデルを特定の用途に合わせて追加学習させ、性能を向上させる手法
- MLOps:Machine Learning Operationsの略で、機械学習モデルの開発から運用までを効率化する手法や仕組み
驚異的な成長を遂げる財務状況
急成長を続ける売上と、巨大テック企業も認める高い評価額を解説。市場の注目を集めるIPO(株式公開)への道筋と、その資金戦略に迫ります。
急成長する売上と投資家からの高い評価
Databricksの財務成長は、その技術力を裏付ける説得力のある数字を示しています。
Microsoft、Google、AWS、NVIDIAといった巨大テック企業からの戦略的投資も受けており、業界全体での重要性が認められています。特に、NVIDIAが参加したシリーズIや、Thrive Capitalが主導したシリーズJは、AIブームの中心で同社が果たす役割への高い期待を反映しています。
IPOへの道筋
市場では、Databricksが2025年にもIPOを実施するとの見方が広く共有されています。CEOのアリ・ゴディシは、市場の不確実性を理由に2024年のIPOを見送ったと公言しており(出典: Bloomberg)、これは同社が最適なタイミングを慎重に見計らっていることを示しています。
2024年のシリーズJラウンドには従業員が保有株を売却できるセカンダリー取引が含まれており、これはIPOを待たずに従業員に流動性を提供する「プライベートIPO」としての機能を持っていました。同時に、調達した巨額の資金は、Tabularのような戦略的買収(出典)の原資となり、競争力をさらに強化するための「軍資金」となっています。
専門用語解説
- ARR:Annual Recurring Revenueの略で、サブスクリプション(月額・年額課金)サービスの年間売上予測のこと。安定的な収益の指標として重要視される
- シリーズJラウンド:スタートアップ企業の資金調達ラウンドの段階を示すもので、Jは非常に後期の段階を意味する
- フリーキャッシュフロー:企業が事業活動から得た現金収入から、設備投資などの必要な支出を差し引いた実質的な現金創出力を示す指標
- IPO:Initial Public Offeringの略で、これまで限られた投資家しか投資できなかった会社の株式を、一般の投資家も購入できるよう証券取引所で公開すること
- セカンダリー取引:既存株主が保有株式を売却する取引のこと
競合他社との比較:DatabricksとSnowflakeの違い
データ基盤市場の2大巨頭、DatabricksとSnowflake。両社の思想的な違いから、得意分野、適用シーン、そしてどのような企業がどちらを選ぶべきかまでを、機能比較表を交えて詳しく解説します。
基本的なアプローチの違い
Databricks(オープンレイクハウス方式)
- データは顧客のクラウドストレージに標準的なオープンフォーマットで保存
- 「オープン性」と「コントロール」を重視
- データエンジニアやデータサイエンティストなど技術的な専門家向け
Snowflake(管理型クラウドDWH方式)
- データをSnowflake独自のフォーマットにロードして利用
- 「シンプルさ」と「使いやすさ」を重視
- データアナリストやビジネスユーザーなど、SQLスキルを持つ非技術者向け
機能別詳細比較
| 項目 | Databricks | Snowflake |
|---|---|---|
| コアアーキテクチャ | オープンレイクハウス(顧客のクラウドストレージにオープンフォーマットで保存) | クラウドネイティブDWH(Snowflake管理ストレージに独自フォーマットでロード) |
| 対応データタイプ | 構造化・半構造化・非構造化データをネイティブサポート | 主に構造化・半構造化データ(非構造化も対応拡大中) |
| 主要ワークロード | データエンジニアリング、ML、生成AI、ストリーミング処理、BI | BI、SQL分析、レポーティング(Snowparkでデータサイエンスにも対応) |
| ターゲットユーザー | データエンジニア、データサイエンティスト、MLエンジニア中心 | データアナリスト、ビジネスユーザー中心 |
| データ所有権 | 顧客が完全所有・管理(ベンダーロックインリスク低) | Snowflakeプラットフォーム内で管理(移行時の制約あり) |
| AI・ML機能 | MLflow、Mosaic AIなど統合ネイティブ機能 | Snowpark APIやサードパーティ連携 |
| データ共有 | Delta Sharing(オープンプロトコル、プラットフォーム問わず) | Snowflake Marketplace(主にSnowflakeアカウント間) |
| 価格モデル | クラスタ設定ベースの従量課金(柔軟だが管理複雑) | ストレージ・コンピュート使用量ベース(シンプル) |
得意分野と適用シーン
Databricksが優位な分野
- データサイエンス・機械学習:ネイティブなMLOps環境
- 大規模データ処理:ペタバイト級データの効率的処理
- 非構造化データ活用:画像、動画、テキストデータの統合処理
- ストリーミング処理:リアルタイムデータパイプライン
- 生成AI開発:LLMの構築・ファインチューニング
- 価格性能比:大規模処理でのコスト効率
Snowflakeが優位な分野
- BI・SQL分析:ビジネスユーザー向けの直感的操作
- インタラクティブクエリ:アドホック分析の高速実行
- 設定の簡単さ:すぐに使い始められる
- データ共有エコシステム:成熟したMarketplace
- 運用管理:自動チューニング・メンテナンス
選択の判断基準
Databricksを選ぶべき企業
- AI・機械学習を本格的に活用したい
- マルチクラウド戦略を採用している
- ベンダーロックインを避けたい
- 高度なプラットフォームを管理できる技術的人材がいる
- 大量の非構造化データを扱う
- リアルタイムストリーミング処理が必要
Snowflakeを選ぶべき企業
- 主にBI・レポート作成が目的
- 設定や管理を簡単にしたい
- SQLに慣れたアナリストが多い
- 技術的な専門知識が限られている
- 構造化データ中心の分析
- すぐに成果を出したい
大手クラウド企業との関係
AWS、Microsoft Azure、Google Cloud。巨大クラウド企業と競合しつつも、深く協業する「Coopetition(協争)」という独特な関係性と、その戦略的な価値を解説します。
「協争」(協力と競争の両立)
これらの企業は、AWS Redshift、Google BigQuery、Azure Synapse Analyticsといった自社でもデータ分析サービスを提供しているため、Databricksと競合関係にあります。同時に、Databricksが各社のクラウド基盤上で動作する重要なパートナーでもあります。
特にMicrosoft Azureとは深い協力関係にあり、「Azure Databricks」としてAzureのファーストパーティサービスに完全に統合されています。Google Cloudとも戦略的パートナーシップを結び、BigQueryやGoogle Kubernetes Engineとの連携を強化しています。
マルチクラウド対応の戦略的価値
Databricksの最大の価値提案は、どのクラウドでも一貫したデータ・AI戦略を展開できることです。企業は特定のクラウドプロバイダーのエコシステムにロックインされることを回避でき、柔軟性と将来の選択肢を保てます。
これは、データとAIが企業の戦略的資産となる中で、ベンダーの選択肢を維持したい大規模なエンタープライズにとって、非常に強力なメッセージとなっています。
専門用語解説
- ペタバイト:1,000テラバイト(1兆バイト)に相当する非常に大きなデータ容量の単位
- アドホッククエリ:事前に定義されていない、その場で作成する臨時的なデータ検索
- マルチクラウド:複数のクラウドサービス(AWS、Azure、GCPなど)を組み合わせて使用する戦略
- Coopetition:CooperationとCompetitionを組み合わせた造語で、協力と競争を同時に行う関係
- ファーストパーティサービス:クラウドプロバイダー自身が提供する純正サービス
市場での評価と顧客の声
GartnerやForresterといった第三者機関からの客観的な評価と、実際に利用する顧客からのリアルな声(評価点・課題点)をまとめて紹介します。
業界専門家からの評価
Gartner社の評価
- 「クラウドデータベース管理システム」部門でMagic Quadrantの「リーダー」に4年連続選出
- 「データサイエンス・機械学習プラットフォーム」部門で「実行能力」と「ビジョンの完全性」両軸で最高評価
Forrester社の評価
- 「データレイクハウス」部門のForrester Waveで「戦略」と「現行製品」両カテゴリーで全ベンダー中最高スコア
- 「クラウドデータパイプライン」部門でも「リーダー」認定
実際の顧客からの評価
よく評価される点
- 卓越したパフォーマンスとスケーラビリティ:大規模データ処理での高い性能
- データとAIの統合アプローチ:単一プラットフォームでの一貫した開発体験
- チーム間のコラボレーション促進:データエンジニアとデータサイエンティストの協業環境
- ベンダーロックインからの解放:オープンソースベースによる選択の自由
指摘される課題
- コスト管理の複雑性:従量課金制モデルで最適化には専門知識が必要
- 学習曲線の急さ:機能が豊富で技術的側面が強く、非技術者には習得が困難
- 運用管理の複雑さ:最適化には慎重な設定と継続的な監視が必要
将来展望と成長可能性
生成AIブームを追い風に、Databricksが今後どのように成長していくのか。既存顧客への拡大戦略と、投資家や導入検討企業が注目すべきポイントを考察します。
生成AIブームがもたらす絶好のチャンス
現在進行中の生成AI革命は、Databricksにとって最大の追い風です。企業の独自データを活用したカスタムLLMの構築が重要になる中で、レイクハウスアーキテクチャは、そのための理想的な基盤、いわば「AIファクトリー」としての役割を担います。
- 多様なデータセットの効率的処理:モデルの学習やファインチューニングに不可欠な膨大なデータを統合管理
- Unity Catalogによる厳格なガバナンス:企業が安心してAI開発できるセキュリティ環境
- MLflowによる堅牢なMLOps:AI開発から運用まで全工程をサポート
同社が開発した高性能なオープンソースLLM「DBRX」のリリースは、この分野における深い専門知識とリーダーシップを証明しています。
既存顧客での利用拡大戦略
現在、Fortune 500企業の50%以上がDatabricksを利用しています。(出典: Databricks公式サイト)今後の成長は、これらの企業内でランド・アンド・エクスパンド戦略を展開することにかかっています:
- 既存顧客内での利用拡大:BIからAIまで、より多くのユースケースをDatabricksプラットフォームに移行
- Databricks SQLを武器とした市場浸透:従来のデータウェアハウス市場のシェア獲得
投資判断のポイント
企業にとっての判断基準
Databricksを選ぶべき企業
- AI中心のデータ戦略を考えている
- マルチクラウド方針を取っている
- オープンアーキテクチャを重視している
- 高度なプラットフォームを管理できる技術的人材がいる
導入時の注意点
- ライセンス費用だけでなく、複雑なデータエコシステムを管理・最適化するTCOを慎重に評価
- 社内の技術レベルと必要な学習コストを評価
投資家にとっての判断基準
2025年予定のIPOは、データ・AIインフラというカテゴリを定義するリーダー企業への投資機会となる可能性があります。
IPO後に注視すべき主要指標
- Snowflakeと比較した成長率の持続性
- 顧客維持率と拡大率:既存顧客がサービス利用を増やし続けるか
- 規模拡大に伴う利益率の維持・向上
成功の鍵
- 「データインテリジェンスプラットフォーム」という統一ビジョンの市場浸透
- 高い評価額(620億ドル)に見合う継続的な成長の実現
専門用語解説
- Magic Quadrant:Gartner社が発行する市場分析レポートで、企業を「実行能力」と「ビジョンの完全性」の2軸で評価したもの
- Forrester Wave:Forrester社が発行する競合他社比較レポートで、様々な評価軸で各社を詳細に分析したもの
- スケーラビリティ:システムの利用量増加に応じて性能を拡張できる能力
- Fortune 500:アメリカの経済誌が発表する売上高上位500社のランキング
- ランド・アンド・エクスパンド:まず小さく始めて(Land)、徐々に利用を拡大する(Expand)営業戦略
- TCO:Total Cost of Ownershipの略で、システム導入から運用終了までにかかる総費用
よくある質問(FAQ)
▶ Databricksとは何ですか?(クリックで開閉)
Databricksは、企業のデータ活用とAI開発を支援するクラウドプラットフォームです。「レイクハウス」という革新的なアーキテクチャにより、データウェアハウスの信頼性とデータレイクの柔軟性を両立し、BI分析から機械学習まで全てのワークロードを単一環境で実行できます。
▶ DatabricksとSnowflakeの違いは何ですか?(クリックで開閉)
主な違いは以下の通りです:
Databricks:オープンなレイクハウスアーキテクチャで、データは顧客が所有。AI・機械学習に強く、技術者向け。
Snowflake:管理型クラウドデータウェアハウスで、Snowflake内でデータを管理。BI・SQL分析に強く、ビジネスユーザー向け。
▶ レイクハウスとは何ですか?(クリックで開閉)
レイクハウスは、データウェアハウスの高性能・高信頼性と、データレイクの低コスト・柔軟性を組み合わせた次世代のデータアーキテクチャです。構造化・非構造化を問わず全てのデータを統一環境で管理し、BI分析からAI開発まで全ワークロードを実行できます。
▶ Databricksの導入コストはどれくらいですか?(クリックで開閉)
Databricksは従量課金制で、使用したコンピュートリソースとストレージに応じて料金が発生します。具体的なコストは、データ量、処理頻度、利用機能によって大きく異なるため、事前にPoCや試算を行うことをお勧めします。また、ライセンス費用だけでなく、運用・管理にかかる総コスト(TCO)も考慮することが重要です。
▶ どのような企業がDatabricksを導入すべきですか?(クリックで開閉)
以下のような企業に特におすすめです:
・AI・機械学習を本格活用したい企業
・大量の非構造化データを扱う企業
・マルチクラウド戦略を採用している企業
・ベンダーロックインを避けたい企業
・データエンジニアやデータサイエンティストなど技術人材がいる企業
▶ Databricksは日本でも利用できますか?(クリックで開閉)
はい、DatabricksはAWS、Azure、Google Cloudの日本リージョンで利用可能です。日本語サポートも提供されており、多くの日本企業が導入しています。また、データの国内保管が要求される業界でも、日本のクラウドリージョンを使用することで要件を満たすことができます。
主な外部サイト(参考サイト)
公式サイト・ドキュメント
業界分析レポート
- Gartner Magic Quadrant for Cloud Database Management Systems
- Forrester Wave: Cloud Data Warehouses
- Gartner Magic Quadrant for Data Science and Machine Learning Platforms
- Databricks資金調達履歴(Crunchbase)
技術解説・比較記事
- データレイクハウス (Data Lakehouse) とは?(Japan公式グロッサリー)
- データウェアハウスとは(Snowflake解説)
- データレイクとアナリティクス(AWS解説)
- データレイクとは(Google Cloud解説)
オープンソースプロジェクト
あわせて読みたい
以上







