


DatabricksとSnowflakeの違いは、もはや「AI開発向けか、SQL分析向けか」だけでは語れません。
3〜5年後、「なぜあのときこちらを選ばなかったのか」と経営会議で議論になるのは、AIエージェント時代のデータ基盤をどの思想で選んだかです。
DatabricksはAIを作り動かす基盤へ、SnowflakeはAIでデータを使う基盤へ、それぞれ進化しています。本記事では、技術思想、AI戦略、財務、株式報酬を含む収益性、そして実務での選び方までを比較します。
✅ この記事の結論(TLDR)
- Databricksは、レイクハウスを軸に、データ処理、機械学習、RAG、AIエージェント、運用データベースまで広げるAIを作り動かす基盤です。
- Snowflakeは、管理型DWHとSQL/BIの使いやすさを基盤に、Cortex AI、Snowflake Intelligence、AISQL、Iceberg対応でAIでデータを使う基盤へ進化しています。
- Databricksは、2026年2月時点で年換算売上54億ドル超、前年比65%超、AI製品の年換算売上14億ドル超、既存顧客売上拡大率140%超を公表しており、成長モメンタムが際立ちます。
- Snowflakeは、将来売上残97.7億ドル、既存顧客売上拡大率125%、フリーキャッシュフロー11.20億ドルを示す一方、株式報酬費用による公式会計上の赤字と株主希薄化をあわせて読む必要があります。
- 選び方の核心は、「AIを競争力の中核に据えるのか」「まず業務分析をAIで強化するのか」です。前者はDatabricks、後者はSnowflakeが有力です。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
DatabricksとSnowflakeの違いを一言でいうと

両社の違いは、単なる機能比較ではなく「AIをどの層で使うか」という経営判断にあります。
DatabricksとSnowflakeは、どちらも企業データを扱う中核基盤です。しかし、出発点は異なります。Databricksは、Apache Spark、Delta Lake、MLflowなどを背景に、データエンジニアリングとAI開発を一体化してきました。一方のSnowflakeは、管理型データウェアハウスとして、SQL分析、BI、部門横断のデータ共有を使いやすくすることで成長してきました。
2026年時点で重要なのは、両社が互いの領域へ踏み込んでいることです。DatabricksはLakebaseにより運用データ領域へ広がり、SnowflakeはCortex AIやSnowflake IntelligenceでAI活用体験を強化しています。つまり、比較軸は「どちらが高機能か」ではなく、自社がAIを作る側に立つのか、AIで業務データを使う側から広げるのかです。
| 観点 | Databricks | Snowflake |
|---|---|---|
| 思想 | AIを作り、動かすためのデータ基盤 | AIでデータを使いやすくする分析基盤 |
| 出発点 | Spark、Delta Lake、機械学習、データエンジニアリング | SQL、BI、管理型DWH、データ共有 |
| 向いている企業 | AIモデル、RAG、AIエージェントを競争力にしたい企業 | 既存の分析業務をAIで高度化したい企業 |
| 注意点 | 人材・設計力・全社アーキテクチャの負荷が大きい | AI利用を実際の消費量と売上へ転換できるかが問われる |
この比較で見落としやすい3つの前提
第一に、DatabricksとSnowflakeは「片方が正しく、片方が古い」という関係ではありません。両社は異なる思想から始まり、AI時代に向けて互いの領域へ近づいています。Databricksは分析・AI基盤から運用データへ広がり、Snowflakeは分析基盤から自然言語AI体験へ広がっています。
第二に、選定で重要なのは、現在の機能一覧ではなく、3〜5年後に自社がどのようなデータ活用企業になりたいかです。AIモデルやエージェントを自社の差別化要素にするなら、データの前処理、評価、ガバナンス、運用まで一体で考える必要があります。反対に、既存の業務部門がデータを使いやすくすることが主目的なら、利用者体験と運用の滑らかさが重要になります。
第三に、財務の読み方も製品選定に影響します。Databricksは未上場のため詳細な損益計算書は公開されていませんが、成長率とAI製品売上の勢いが目立ちます。Snowflakeは公開企業として詳細な決算が見える一方、株式報酬費用を含めた利益の質まで読む必要があります。
この比較記事の読み方
Databricksの詳しいLakehouse戦略は、関連記事「Databricksで作るAIデータ基盤」に譲ります。本記事では、Snowflakeとの違いが意思決定にどう効くかに絞って解説します。
Databricks:AIを作り動かすデータ基盤
Databricksの強みは、データレイクハウス、AI開発、ガバナンス、運用データまでを一体で扱える点にあります。
Databricksを理解するには、「データレイクの柔軟性」と「データウェアハウスの信頼性」を統合するレイクハウスという考え方が重要です。構造化データ、ログ、画像、テキスト、IoTデータなどを保存しながら、分析、機械学習、RAG、AIエージェントまで同じ基盤で扱うことを目指します。
技術面では、Delta Lakeが信頼性のあるデータ管理を支え、Unity Catalogが権限・監査・データリネージュを統合します。Mosaic AIとMLflowは、モデル開発、評価、デプロイ、運用管理を支援します。これらは単体機能ではなく、AIアプリケーションを安全に動かすための「部品群」として機能します。
Databricksが強いユースケース
Databricksが特に強いのは、データの蓄積からAIモデルの開発、RAG、AIエージェントの実行、評価、運用監視までを一続きの流れとして設計したい場面です。たとえば、製造業であれば、設備ログ、品質データ、保守履歴、画像検査データを統合し、故障予兆や品質改善のAIへつなげるようなケースです。
この種のプロジェクトでは、単にSQLで集計できるだけでは足りません。生データの品質管理、特徴量の再利用、モデル評価、権限管理、監査ログ、推論結果の追跡までが必要になります。Databricksは、この一連の工程を「開発者とデータチームが作り込める」方向に強みを持ちます。
メダリオンアーキテクチャのように、Bronze、Silver、Goldの段階でデータ品質を高める設計は、AIプロジェクトでも重要です。AIはきれいなデータだけを見て動くわけではありません。むしろ現実の業務データは欠損、重複、表記揺れ、時系列の乱れを含みます。こうしたデータをAIが使える形に育てる工程こそ、Databricksが得意とする領域です。
Lakebase:運用データへ踏み込む一手
2025年5月、DatabricksはサーバーレスPostgreSQL企業であるNeonの買収意向を発表しました。狙いは、AIアプリケーションやAIエージェントが扱う運用データを、Databricksのデータ基盤の内側で扱えるようにすることです。
AIエージェントが「考える」だけでなく、業務システムに働きかけ、状態を記録し、次の判断に活かす時代には、分析データと運用データの境界が薄れます。Lakebaseは、Databricksを単なる分析・AI基盤から、AIアプリケーションを実行するフルスタックなデータ基盤へ近づける戦略的な拡張です。
ただし、Databricksは万能薬ではありません。データレイク、特徴量管理、RAG、AIエージェント、運用データベースまでを一体で設計するには、高度なデータエンジニアリング人材、AI基盤人材、全社アーキテクチャ設計力が必要です。2025年にはAI領域を牽引してきたNaveen RaoがDatabricksを離れ、新たなAIハードウェア企業を立ち上げたことも、技術リーダーシップの継続性を見るうえでの補助線になります。
もちろん、この人事だけでDatabricksの将来性を判断すべきではありません。ただし、AI製品の伸びとキーパーソンの動きをセットで追うことで、3〜5年後の技術リーダーシップを見通しやすくなります。
Snowflake:AIでデータを使う分析基盤
Snowflakeの強みは、SQL/BIの使いやすさ、大企業への浸透、AIを業務分析体験へ自然に組み込む方向性にあります。
Snowflakeは、企業が複雑なインフラ管理を意識せずにデータを集約・分析できる管理型データウェアハウスとして成長しました。部門ごとのBI、経営ダッシュボード、データ共有、データマーケットプレイスとの相性が高く、非エンジニアの分析利用を広げやすい点が強みです。
近年は、Cortex AI、Snowflake Intelligence、AISQL、Horizon Catalog、Iceberg対応により、AI時代の分析体験へ踏み込んでいます。たとえば、自然言語でデータに質問し、SQLを意識せずに分析結果を得る体験は、Snowflakeが「AIを作る基盤」ではなく、AIで業務データを使う基盤へ進化していることを示します。
一方で、Snowflakeの課題は、AI利用の広がりをどれだけ消費量と売上に転換できるかです。AI機能の利用アカウント数は増えていますが、AIセグメント単独の売上が明確に開示されているわけではありません。したがって、読者が見るべき問いは「SnowflakeのAI機能は便利か」だけではなく、「それが新たな従量課金消費を生むのか」です。
Snowflakeが強いユースケース
Snowflakeが特に強いのは、すでに社内に広がっている分析業務を、より安全に、より簡単に、より多くの人へ届けたい場面です。経営ダッシュボード、部門別レポート、売上分析、顧客分析、需要予測、データ共有など、SQLとBIを中心にした業務では、Snowflakeの管理型サービスとしての完成度が効きます。
また、Snowflakeの価値はエンジニアだけに閉じません。事業部門、経営企画、マーケティング、営業企画など、日々SQLを書くわけではない利用者がデータを使う場面で、自然言語による問い合わせやAI支援分析が意味を持ちます。Cortex AIやSnowflake Intelligenceは、この「使う人を増やす」方向のAIです。
この違いは、導入後の社内展開にも影響します。Databricksは強力ですが、AI基盤を設計・運用できるチームが必要です。Snowflakeは、既存のDWH/BI運用に近い感覚でAI機能を広げやすく、全社展開の初速を出しやすい場合があります。
財務で見るDatabricksとSnowflake:数字の見方を間違えない
成長率ではDatabricks、契約基盤と現金創出力ではSnowflakeが目立ちます。ただし、Snowflakeの利益を見るときは株式報酬費用を含めて読む必要があります。
2026年5月時点の補助線:Databricksは大型IPO候補として注目されている
Databricksは2026年5月時点では未上場であり、正式な上場時期やS-1提出は確認されていません。一方で、年換算売上54億ドル超、前年比65%超、AI製品の年換算売上14億ドル超、直近12か月のフリーキャッシュフロー黒字という数字は、同社を大型IPO候補として強く印象づけています。
上場が実現すれば、DatabricksとSnowflakeの比較は、製品比較だけでなく、公開市場における成長率、利益の質、株式報酬、AI売上の比較へと移ります。
IPO観測を本文に入れる理由は、投資の話をしたいからではありません。公開市場で比較されるようになると、Databricksの数字は「勢い」だけでなく、粗利率、営業利益、株式報酬費用、顧客構成、AI製品の継続率まで細かく見られるようになります。Snowflakeはすでにその視線にさらされています。つまり今の比較は、非公開企業の成長ストーリーと、公開企業の決算責任を同じテーブルに置く試みでもあります。
主要財務指標の比較
主要財務指標の比較
| 指標 | Databricks | Snowflake | 読み方 |
|---|---|---|---|
| 年換算売上 | 54億ドル超 | FY2026売上46.84億ドル、Q4売上12.84億ドル | 売上規模は近づいている。ただし、Databricksは年換算ベース、Snowflakeは実績売上ベースである点に注意。 |
| 売上成長率 | 前年比65%超 | Q4売上30%成長、FY2026製品売上29%成長 | 成長モメンタムはDatabricksが優勢。 |
| 既存顧客売上拡大率 | 140%超 | 125% | 既存顧客の利用拡大力でもDatabricksが強い。既存顧客内でAI/データ活用が広がっているかを見る重要指標。 |
| AI製品の年換算売上 | 14億ドル超 | AI機能利用は拡大。ただしAIセグメント売上は非開示 | AI需要の売上転換はDatabricksの方が読みやすい。SnowflakeはAI利用の広がりを、今後どれだけ消費量と売上へ転換できるかが焦点。 |
| 大口顧客 | 100万ドル超顧客800社超、1,000万ドル超顧客70社超 | 100万ドル超顧客733社、Forbes Global 2000顧客790社 | Databricksは急伸、Snowflakeは大企業基盤が厚い。両社ともエンタープライズ市場で深く浸透している。 |
| 営業利益 | 未上場のため、公式会計上の営業利益は非開示 | 公式会計上の営業損失14.35億ドル、調整後営業利益4.90億ドル | Snowflakeは調整後では黒字だが、公式会計では大きな営業赤字。株式報酬費用の影響を分けて読む必要がある。 |
| フリーキャッシュフロー | 直近12か月で黒字 | 11.20億ドル、マージン24% | Snowflakeは現金創出力が強い。ただし株式報酬費用を現金支払いとみなすと、見え方は大きく変わる。 |
| 株式報酬費用 | 非開示 | 株式報酬関連費用17.11億ドル | Snowflakeの公式会計上の赤字と、フリーキャッシュフロー黒字を同時に読むうえで最重要の調整項目。 |
| 将来売上残 | 非公表 | 97.7億ドル | Snowflakeの契約基盤は厚い。すでに契約済みだが、まだ売上計上されていない将来売上が大きい。 |
| 評価額・時価総額 | 評価額1,340億ドル | 公開企業のため、時価総額は株価により変動 | 市場はDatabricksに高いAI成長プレミアムを付けている。一方、Snowflakeは公開市場で利益の質を常に評価される立場にある。 |
Snowflakeの強み:大企業向けSaaSとしての基盤
Snowflakeを単純に「成長が鈍化した企業」と見るのは早計です。将来売上残97.7億ドル、既存顧客売上拡大率125%、100万ドル超の大口顧客733社という数字は、同社が大企業の分析基盤に深く入り込んでいることを示します。
これは日本企業の感覚では、大きな受注残と継続利用基盤を持つ状態に近いです。Snowflakeの強さは、製品の使いやすさだけでなく、既存顧客との長期的な関係と、部門横断の分析基盤としての定着度にあります。
日本企業の感覚で読むとどう見えるか
日本企業の管理会計では、人件費は現金支出として強く意識されます。一方、米国SaaS企業では、優秀な人材を獲得するために株式報酬を多用します。これは会計上も開示上も正当な仕組みですが、現金流出を伴わないため、フリーキャッシュフローが強く見えやすいという特徴があります。
そのため、Snowflakeのような公開SaaS企業を見るときは、「現金を生んでいるか」と「株主の持ち分が薄まっていないか」を分けて読む必要があります。前者は事業の安定性、後者は株主から見た実質コストです。
注意点:株式報酬費用で見る利益の質
一方で、Snowflakeのフリーキャッシュフローを見るときは、単に「現金を生んでいるから強い」と読むだけでは不十分です。背景には、株式報酬費用(SBC)があります。これは社員に現金ではなく株式で報酬を渡す仕組みに伴う費用で、会社から現金は出ていきませんが、株式の希薄化を通じて株主に実質的なコストが発生します。
つまり、Snowflakeは「公式会計上は赤字だが、調整後では黒字で、フリーキャッシュフローも強い」と説明できます。しかし、株主の立場からは、株式報酬費用を無視してよいわけではありません。
株式報酬費用をすべて現金給与とみなした場合の試算:
![\[\text{試算FCF} = 11.20 - 17.11 = \mathbf{\triangle 5.90}\ \text{億ドル}\]](https://arpable.com/wp-content/ql-cache/quicklatex.com-dc34efd87c10c21e663dc712627fbe61_l3.png "Rendered by QuickLaTeX.com")
この式は、Snowflakeの公表フリーキャッシュフロー11.20億ドルから、株式報酬関連費用17.11億ドルを差し引いた単純試算です。実際の人件費設計や税務影響を反映したものではありませんが、株式報酬費用を実質コストとして見た場合に、現金創出力の印象が大きく変わることを示しています。
| 仮定 | 試算フリーキャッシュフロー | 読み方 |
|---|---|---|
| 25%を現金支払いとみなす | 約6.93億ドル | なお健全だが、公表値より余裕は小さい。 |
| 50%を現金支払いとみなす | 約2.65億ドル | 黒字は残るが、強い現金創出企業という印象は薄れる。 |
| 75%を現金支払いとみなす | 約▲1.63億ドル | 実質的には現金創出も赤字に近い姿になる。 |
| 100%を現金支払いとみなす | 約▲5.90億ドル | 公表黒字の印象は大きく変わる。 |
株式報酬費用を実質的な人件費として差し戻した場合の試算:
![\[\text{試算上の実質営業利益} = 4.90 - 17.11 = \mathbf{\triangle 12.21}\ \text{億ドル}\]](https://arpable.com/wp-content/ql-cache/quicklatex.com-401f4209d06e45dee31f23e7705cad56_l3.png "Rendered by QuickLaTeX.com")
この試算は、Snowflakeを否定するためのものではありません。むしろ、米国SaaS企業を読むときに重要な「利益の質」を可視化するための補助線です。Snowflakeは強い事業基盤を持ちますが、株式報酬費用への依存を下げながらAI機能を新たな消費量エンジンにできるかが、再評価の分岐点になります。
「高速化で従量課金が減った」は本当に主因なのか
Snowflakeの成長率鈍化については、クエリ効率化や処理高速化によって顧客のコンピュート消費が抑えられた、という説明もあります。これは顧客にとって良いことであり、長期的な信頼にもつながります。
ただし、AI需要が急拡大する局面で、本当に効率化だけが成長率低下の主因なのかは慎重に見る必要があります。DatabricksはAI製品だけで年換算売上14億ドル超に達したことを公表しており、AI需要の収益化が数字として見えています。SnowflakeはAI機能の利用拡大を示す一方、AIセグメント単独の売上は読み取りにくい状態です。
どちらを選ぶべきか:実務での判断基準
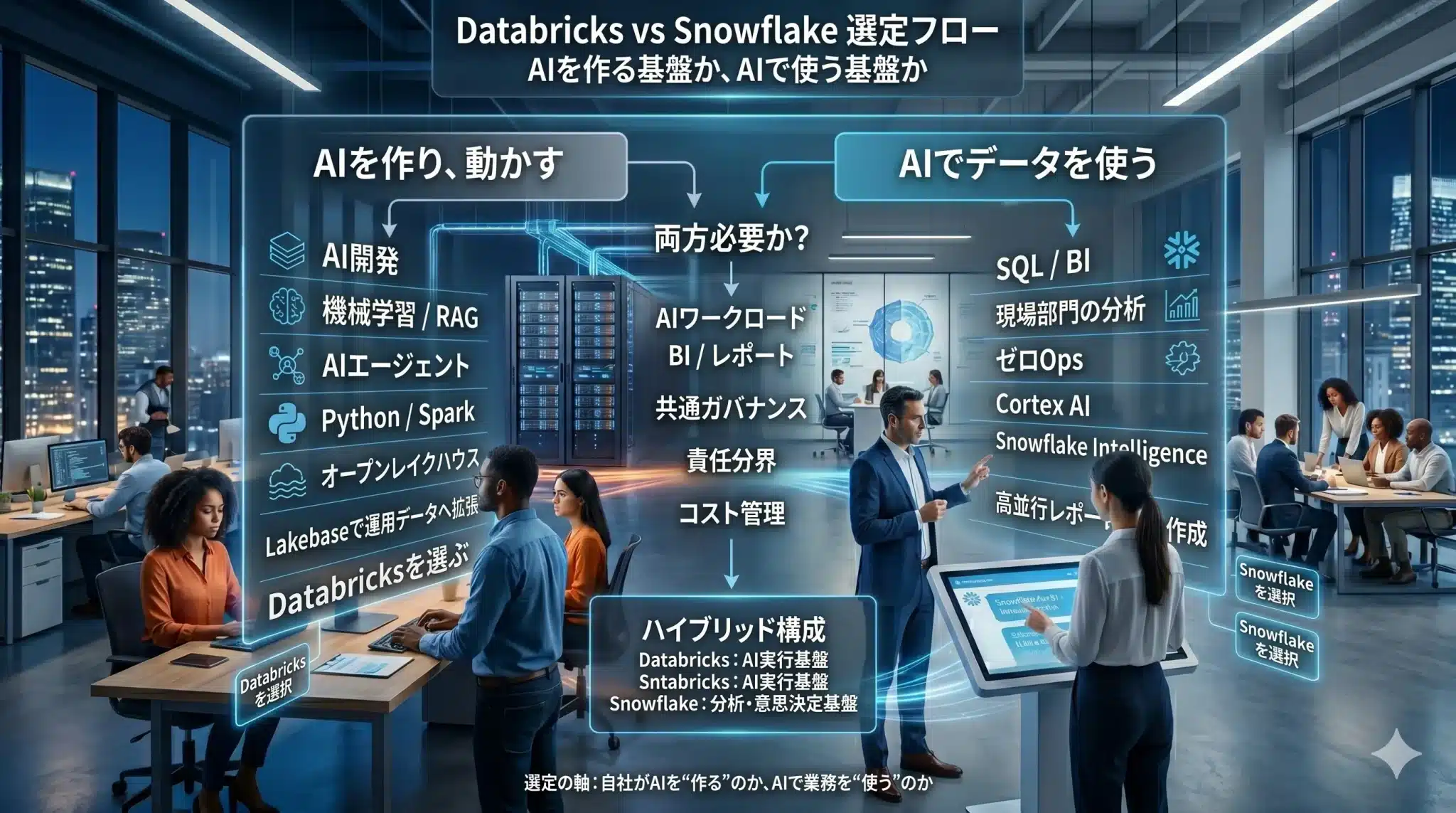
選定の出発点は、機能一覧ではなく「自社がどのようにAIを競争力へ変えるか」です。
判断フロー:最初に問うべき3つの質問
選定会議では、いきなり製品機能を比較するより、次の3つを先に確認する方が判断しやすくなります。
- AIを自社のプロダクトや業務プロセスに組み込み、競争力の中核にしたいのか。この答えが「はい」なら、Databricksの重要度が高まります。
- まず既存の分析・レポート・BIをAIで使いやすくしたいのか。この答えが「はい」なら、Snowflakeの合理性が高まります。
- 自社に、データ基盤を作り込む人材と運用体制があるのか。ここが弱い場合、Databricksの自由度は強みであると同時に負荷にもなります。
つまり、Databricksは「作れる組織」に強く、Snowflakeは「広げたい組織」に強いと言えます。もちろん実際には重なり合いますが、この整理を持っておくと、ベンダー比較の迷路に入りにくくなります。
| 選定基準 | Databricks推奨 | Snowflake推奨 |
|---|---|---|
| 主な目的 | AIアプリ、RAG、AIエージェントを内製・運用したい | 部門横断の分析、BI、自然言語分析を広げたい |
| 利用者 | データエンジニア、AIエンジニア、MLOps担当 | 経営企画、事業部門、BI担当、SQL利用者 |
| 設計負荷 | 高い。自由度が高い分、アーキテクチャ設計が重要 | 比較的低い。管理型で導入しやすい |
| 自社のストーリー | AIそのものを競争力の中核に据えたい企業 | まず業務分析の完成度を高め、AIはその延長として広げたい企業 |
ハイブリッド構成も現実的な選択肢
実務では、DatabricksかSnowflakeかを単純に二者択一にする必要はありません。たとえば、生データの蓄積、機械学習、RAG、AIエージェントの実行はDatabricksで担い、部門別のBI、定型レポート、自然言語分析はSnowflakeで提供するという二層構成は、日本企業でも現実的です。
この構成では、Databricksを「AIを作り、動かす基盤」として使い、Snowflakeを「現場部門がAIでデータを使う基盤」として使います。重要なのは、どちらか一方を正解と決めつけることではなく、データの責任分界、ガバナンス、コスト管理、利用者体験を分けて設計することです。
導入後に起きやすい誤解
Databricksを選んだ企業で起きやすい誤解は、「AI基盤を導入すればAI活用が自然に進む」というものです。実際には、データ品質、権限設計、評価基準、モデル運用、コスト監視までを設計しなければ、強力な基盤を持っていても成果につながりません。
Snowflakeを選んだ企業で起きやすい誤解は、「AI機能を有効化すれば全社員がデータ活用できる」というものです。自然言語分析は便利ですが、裏側のデータ定義、指標の意味、アクセス権限、回答の検証責任が曖昧なままだと、かえって混乱を広げます。
したがって、どちらを選んでも重要なのは、ツール導入ではなく運用設計です。AI時代のデータ基盤は、単なるIT投資ではなく、データを使った意思決定の作法を変える組織改革でもあります。
日本企業で起きやすい3つの導入シナリオ
日本企業で現実的に多いのは、いきなり全社をDatabricksまたはSnowflakeに寄せる形ではありません。既存のDWH、BI、データレイク、基幹システム、部門別Excel文化が残る中で、段階的に役割分担を整理していくケースです。
シナリオ1:Snowflake中心からAI活用を広げる
すでにSnowflake上に販売、会計、顧客、在庫などのデータが集まっている企業では、まずCortex AIやSnowflake Intelligenceを使って、分析部門や事業部門のデータ利用を広げるのが自然です。この場合、Databricksをいきなり全面導入するより、既存のデータ活用基盤を活かしてAI分析体験を高める方が、社内合意を得やすい場合があります。
シナリオ2:AIプロダクト開発をきっかけにDatabricksを中核化する
自社サービスにAIレコメンド、需要予測、異常検知、RAG検索、AIエージェントを組み込む企業では、Databricksの価値が高まります。単なる分析ではなく、データを使って継続的にAIを改善し、運用する必要があるからです。この場合、Snowflakeは経営・部門分析の基盤として残し、DatabricksをAIワークロードの中核にする構成が考えられます。
シナリオ3:グループ企業・複数クラウドで役割分担する
大企業グループでは、事業会社ごとに利用クラウドやデータ成熟度が異なることがあります。この場合、全社共通のガバナンス方針を定めたうえで、AI開発をDatabricks、部門分析をSnowflake、特定クラウドのネイティブ分析をBigQueryやRedshiftに残すといった複合構成も現実的です。大切なのは、ツールの統一よりも、データ定義と責任分界を統一することです。
コスト管理とガバナンスで見る実務上の差
DatabricksとSnowflakeは、どちらも従量課金の性格を持ちます。そのため、導入初期は小さく始められても、AIワークロードや部門利用が広がるとコスト管理が重要になります。特にAIエージェントやRAGは、検索、前処理、推論、評価、ログ保存など複数の処理が連鎖するため、単純なクエリ単価だけでは総コストを読み切れません。
Databricksでは、ワークロード設計、クラスタ管理、ジョブ設計、モデル評価、データ品質管理をどう組み合わせるかがコストと品質に直結します。自由度が高い分、設計が甘いとコストも運用品質もぶれやすくなります。
Snowflakeでは、利用者が増えるほど、ウェアハウス設定、権限管理、クエリ設計、AI機能の利用制御が重要になります。使いやすい基盤ほど利用が広がりやすく、気づいたときには部門ごとの消費量が膨らむことがあります。つまりSnowflakeでも、便利さの裏側にコスト統制の設計が必要です。
ガバナンスの観点では、DatabricksはUnity Catalogを中心に、データ、モデル、ノートブック、ワークフローまでを統合的に管理する方向です。SnowflakeはHorizon Catalogやアクセス制御、データ共有の仕組みを通じて、企業内外のデータ利用を安全に広げる方向です。どちらが優れているかではなく、自社が管理したい対象が「AI開発プロセス」なのか「業務データ利用」なのかで評価軸が変わります。
クラウド企業との関係:協力と競争の両立
DatabricksもSnowflakeも、AWS、Azure、Google Cloudの上で動きながら、同時にクラウド各社の分析・AIサービスと競合しています。
DatabricksとSnowflakeは、主要クラウド上で利用できるマルチクラウド型のプラットフォームです。これは企業にとって、特定クラウドへの過度な依存を避ける選択肢になります。一方で、BigQuery、Redshift、Microsoft Fabricなど、クラウドベンダー自身のデータ基盤とも競合します。
この構図は「協争」です。クラウド企業はDatabricksやSnowflakeの利用拡大によってインフラ消費を得ますが、上位レイヤーでは顧客のデータ戦略をめぐって競います。したがって選定時には、機能だけでなく、クラウド戦略、既存契約、人材、ガバナンス方針を合わせて判断する必要があります。
まとめ:DatabricksとSnowflake、どちらを選ぶべきか
結論は、DatabricksかSnowflakeかではなく、自社がAIをどの層で競争力にするかです。
3〜5年の成長性という観点では、Databricksが優勢です。年換算売上、成長率、既存顧客売上拡大率、AI製品売上のすべてで強いモメンタムを示しており、AIエージェント時代の基盤としての収益化がすでに始まっています。
一方で、Snowflakeを過小評価するのは危険です。将来売上残、大口顧客、既存の分析基盤としての定着度は強く、Cortex AIやSnowflake Intelligenceが業務分析体験を変える可能性もあります。ただし、株式報酬費用への依存を下げながら、AI機能を本当の消費量エンジンにできるかが分岐点です。
AIを作る基盤としてのDatabricks、AIでデータを使う基盤としてのSnowflake。この対比を起点に、自社のAI戦略、人材、データガバナンス、クラウド契約、将来のプロダクト構想を見直すことが、後悔しない選定につながります。
社内でこの記事を使うなら、最初に「どちらが優れているか」ではなく、「自社のAI戦略はどちらの物語に近いか」を議論するとよいでしょう。AIをプロダクトや業務プロセスの中核に組み込み、データとモデルを継続改善する企業を目指すならDatabricks寄りです。既存の分析基盤をより多くの社員に開放し、意思決定の速度を高めたいならSnowflake寄りです。
そして、現実の大企業では、この2つは対立ではなく分担になります。AIを作るチームと、AIでデータを使う部門は、同じ会社の中に同時に存在するからです。だからこそ、最終的な論点は「製品名」ではなく、データの責任分界、AIの運用責任、コスト管理、業務部門の利用体験をどう設計するかに移ります。
最後に残る意思決定の問い
最終的に、DatabricksとSnowflakeの比較は「どちらが多機能か」では決まりません。むしろ、経営としてどの能力を社内に持ちたいかで決まります。AIモデルやエージェントを自社で設計し、改善し、業務システムへ組み込む力を持ちたいなら、Databricksを中心にしたデータ・AI基盤の設計が重要になります。
一方で、まず必要なのが「全社員が正しいデータにアクセスし、迷わず意思決定できる状態」であれば、Snowflakeを中心にした分析体験の高度化が現実的です。AI時代の競争力は、必ずしも高度なモデルを作る企業だけに宿るわけではありません。正しいデータを、正しい人が、正しいタイミングで使える企業もまた強くなります。
だからこそ、この記事の結論は一つに単純化しません。DatabricksはAIを作る企業の武器であり、SnowflakeはAIでデータを使う企業の武器です。自社がどちらの物語を先に進めるべきかを見極めることが、最初の意思決定になります。
なお、ここでいう「選択」とは、必ずしも一方を捨てることではありません。多くの企業では、既存の分析基盤を残しながら、AIワークロードだけを別基盤で育てる段階を経ます。その意味で、本記事は製品の勝敗表ではなく、役割分担を設計するための地図として読むのが自然です。
※)Databricksをより大きなAIデータ基盤の文脈で捉えたい方は、Databricksで作るAIデータ基盤|生成AI時代のLakehouse戦略をご参照ください。RAGの設計・検索基盤については、RAG完全ガイド2026およびベクトルDB完全ガイド|RAG検索設計とHybrid Search【2026年版】で整理しています。
専門用語まとめ
- レイクハウス
- データレイクの柔軟性と、データウェアハウスの信頼性を組み合わせたデータ基盤の考え方です。
- Cortex AI
- Snowflake上でAI関数、自然言語処理、生成AI活用を行うための機能群です。
- 年換算売上(Revenue Run-Rate / ARR)
- 現在の月次・四半期売上を年換算した勢いです。確定売上ではなく、売上ペースを見るための指標です。
- 既存顧客売上拡大率(NRR)
- 既存顧客が前年よりどれだけ利用額を増やしたかを示す指標です。
- 将来売上残(RPO)
- 契約済みだが、まだ売上計上されていない将来売上です。日本企業の「受注残」に近い指標です。
- 株式報酬費用(SBC)
- 社員に現金ではなく株式で報酬を渡す仕組みに伴う費用です。現金は出ていきませんが、株主希薄化という実質コストを伴います。
- フリーキャッシュフロー(FCF)
- 本業から生まれた現金から設備投資などを差し引いた、自由に使える現金です。
よくある質問(FAQ)
Q1. DatabricksとSnowflakeの一番大きな違いは何ですか?
A. DatabricksはAIを作り動かす基盤、SnowflakeはAIでデータを使う基盤として捉えると分かりやすいです。
Q2. どちらがAIエージェント時代に有利ですか?
A. AIエージェントを自社の競争力として開発・運用するならDatabricksが有利です。一方、既存の分析業務をAIで広げるならSnowflakeにも強い合理性があります。
Q3. Snowflakeのフリーキャッシュフローは本当に強いのですか?
A. 強い数字であることは確かです。ただし、株式報酬費用を実質コストとして見ると印象が変わるため、公式会計利益、調整後利益、株主希薄化をあわせて読む必要があります。
Q4. DatabricksとSnowflakeを併用する意味はありますか?
A. あります。AIワークロードやRAG、モデル開発はDatabricks、部門別BIや自然言語分析はSnowflakeといった役割分担は現実的です。ただし、データの責任分界とガバナンス設計が重要です。
Q5. Databricksの方が将来性は高いのでしょうか?
A. 3〜5年の成長性ではDatabricksが優勢と見ます。ただし、導入には高度な人材と設計力が必要です。Snowflakeは既存顧客基盤と業務分析体験の強さがあり、AI機能を収益へ転換できれば再評価余地があります。
参考サイト・出典
- Databricks公式 – Databricks Grows >65% YoY, Surpasses $5.4B Revenue Run-Rate
- Databricks公式 – Databricks Agrees to Acquire Neon
- Databricks公式 – Announcing Lakebase Public Preview
- Snowflake公式 – FY2026 Q4 and Full-Year Financial Results
- Snowflake Investor Relations – Events & Presentations
- InfoWorld – Databricks at a crossroads: Can its AI strategy prevail without Naveen Rao?
- Arpable – Databricksで作るAIデータ基盤|生成AI時代のLakehouse戦略
- Arpable – ベクトルDB完全ガイド|RAG検索設計とHybrid Search【2026年版】
あわせて読みたい
更新履歴
- 2026-05-25: 記事全体をDatabricks/Snowflake比較に再集中し、約15,000字級へ圧縮。Databricksの大型IPO観測、Lakebase / Neon、Snowflakeの株式報酬費用試算、ハイブリッド構成例、関連記事タイトルの2026年整合を反映。本文中の既存画像を削除し、2026年版の比較マップおよび選定フロー/ハイブリッド構成図のプレースホルダーを追加。
- 2026-03-09: DatabricksのSeries L評価額・最新run-rate・AI製品売上を反映。SnowflakeのCortex AI、Snowflake Intelligence、Horizon Catalog / Iceberg対応の記述を更新。比較章・結論・FAQ・参考出典を全面更新。
- 2026-02-17: 最新市場データ(評価額・時価総額の比較)を追加。Unity Catalogに関するセクションの出典整合を実施。FAQ 5問を追加。
- 2025-07-04: Databricks v2024.7リリースに対応。Mosaic AI、Unity Catalog機能強化を反映。コスト比較セクションを更新。
- 2025-01-01: 初版公開。Databricks vs Snowflakeの基本比較、アーキテクチャ解説、選定基準、コスト分析を網羅。








