


※本記事は継続的に「最新情報にアップデート、読者支援機能の強化」を実施しています(履歴は末尾参照)。
TSMC3nmだけでは勝てない:AI工場は受電×冷却で止まる
この記事を読むと、AI Business Optimizationについて「何が争点で、どこまでが確度の高い事実か」が整理でき、Physical AI時代に必要な投資の優先順位(電力・設計・製造)を判断できます。
この記事の結論:
- 「3nmの器」だけでは不十分です:Physical AIで需要が爆増する局面では、勝負は受電(系統接続)・冷却・建屋を含む稼働成立(Power-Ready)になります。
- Rubin級の汎用GPUは土台として活かせます:ただし、安全保障・日本語最適化・現場制約に合わせた推論では、要所で設計主導権が効きます。
- 最適解は「設計・製造・電力」を同時に立ち上げることです:段階的に進めるほど、電力が律速となり、機会損失が拡大します。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

1. 2026年、第二の開国がもたらす「AIビジネス最適化」への号砲
AI Business Optimizationとは、AIを「モデル単体」ではなく、先端半導体(3nm)・電力(受電/冷却/ベース電源)・チップ設計(推論最適化)・現場プロセスまで含めて一体で最適化し、Physical AIで価値を出し続ける設計思想です。
図1は「3nmプロセス」「核融合炉(象徴としてのベース電源)」「AIチップ設計」が一本の線で繋がる構図を示しています。図2はPhysical AIが供給網そのものを短くし、AIチップ需要を“現場の推論”へ拡散させる直感例です。本稿は、この2枚を背骨として議論を進めます。

1853年、たった4杯の黒船の来航によって、日本は夜も眠れぬほどの衝撃を受け、そこから怒涛の近代化へと舵を切りました。そして2026年2月。私たちは今、当時の熱量にも勝る「第二の近代化」のスタートラインに立っています。その号砲にあたるのが、「高市17分野」とTSMC 3nm投資を軸とした、日本の産業構造をAI前提に作り替える国家レベルの設計図です。
2026年2月5日、高市早苗首相とTSMCのC.C.ウェイCEO(会長)が会談し、熊本の第2工場(JASM、建設中)で3nmプロセスの生産方針が報じられました。北海道のラピダスによる2nm計画と合わせ、日本は最先端半導体を焼くための世界最高峰の器を、ようやく整えつつあります。
ただし、ここで誤解してはいけません。重要なのは「工場が完成した」という静的な到達点ではなく、先端ノード導入が計画として具体化し、産業側の需要と結びつく議論が現実の設計図になり始めたという点です。器(ハードウェア)の導入はあくまで契機であり、真の目的は、器を起点に“産業の循環”を作ることです。
真の目的は、高市首相が掲げる「戦略的17技術分野」をバラバラの政策としてではなく、一つの巨大な「AIビジネスのエコシステム」として垂直統合し、日本が世界の真ん中で最適解を提示することにあります。
2. 米国の背中から学ぶ:需要の熱狂が招く「物理的な壁」と日本の好機
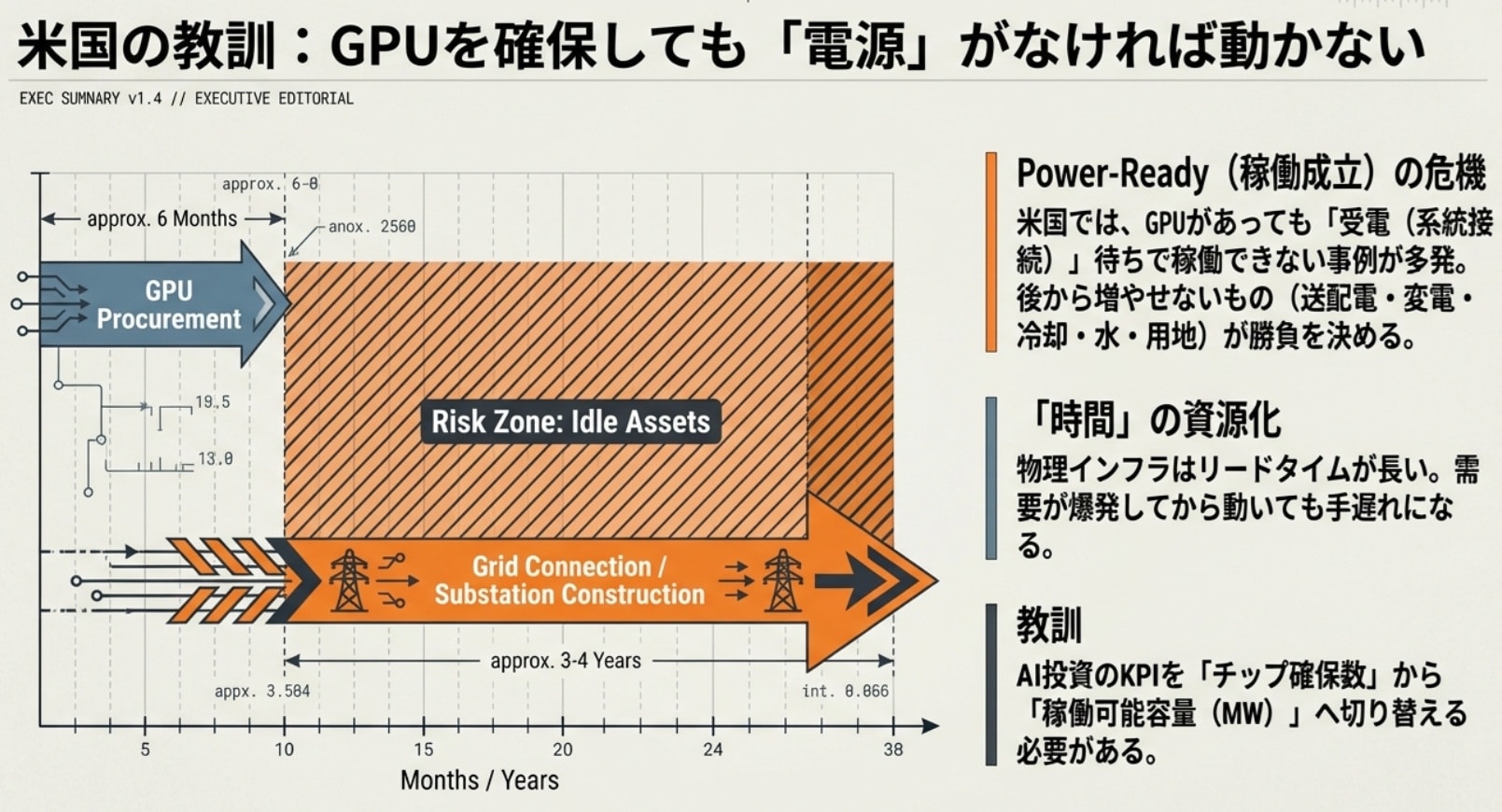
弊社(Arpable)の分析によれば、米国の巨大データセンター構築には現在、受電設備(系統接続に伴う設備増強を含む)の整備だけで最長4年から5年規模のリードタイムが発生しているケースがあります。州・事業者・電力会社ごとに差はあるものの、Vera Rubin級の600kWラックを前提にしたインフラ増強では、このオーダーの時間がボトルネックになり始めています。稼働成立(Power-Ready)とは、GPUを並べても「止まらず回り続ける状態」を意味し、まさにここが勝負所です。
対して、現在の日本はまだこの過密から距離を置いたブルーオーシャンに位置しています。この時間的な猶予を、私たちは「幸運な遅れ」と捉えるべきです。米国が既存インフラの調整に喘いでいる間に、日本は最初から小型原子炉(SMR)など次世代のベース電源とAIデータセンターを一体で設計できます。核融合炉はまだ実証段階ですが、「将来の本命候補」として、いまのうちから設計図に入れておくべき存在です。米国の先行事例を他山の石とし、最初から最適解を社会実装できる環境こそが、日本の真の優位性となるはずです。
- 要点: TSMCが熊本の第2工場(建設中)で3nm生産方針を示したと報じられました。総投資額は約170億ドル(約2.6兆円)と報じられています(正式発表待ち/報道ベース)。
- 元ネタ: Reuters(報道)
- 今のところ: As of 2026-02-04 / 報道ベース(条件は変わる可能性があります)
- 確認日:
では、日本はこの「物理的な壁」をどう打開すべきでしょうか。
3. 「製造請負屋」の先へ:米国の異端児たちから盗むべき設計の魂
ここで学ぶべきは、NVIDIAという巨人に正面から挑むのではなく、別ルールの勝ち筋を提示する米国の「チップ・マーベリックス(異端児)」たちの姿勢です。
Cerebras(セレブラス):物理的な通信の壁を、チップを分割せずウェハ一枚を丸ごと使う「ウェハスケール」で破壊。2026年時点でCerebrasは大規模な推論向け契約やパートナーシップを積み上げ、リアルタイムAIの覇権を狙うポジションを明確にしています(契約金額は非公開または推計ベースの情報も多いため、本稿では具体額の記載は控えます)。
Tenstorrent(テンストレント):設計主導権を自社に引き戻すため、RISC-Vを活用。すでに日本のLSTC(先端半導体技術センター)とのIP協業を通じ、用途別最適を組み立てる思想を日本に注入しています。
Etched(エッチト):計算前提を「Transformer」に固定し、汎用性を捨てることで爆速と低電力を極めたASICを開発。2026年1月に5億ドル(企業価値50億ドル)の資金調達を実施し、その「選ぶ勇気」が市場で高く評価されています。
日本が17分野を繋ぐために必要なのは、これら異端児たちの設計思想を日本の製造現場の「暗黙知」と融合させることです。NVIDIAのGPUを使いこなしつつ、要所では日本の職人技を論理回路として焼き付けた独自の推論特化型ASICを国内で製造する。この柔軟な設計力こそが、17分野を一つに束ねる強力な磁場となります。
結論:汎用GPU(Rubin等)は土台として活かしつつ、差別化が必要な領域は「用途別の推論設計」で主導権を握るのが現実的です。
| 評価軸 | 候補A:汎用GPU(Rubin等) | 候補B:用途別推論設計(IP/ASIC) |
|---|---|---|
| 強み | エコシステムが成熟し、導入が速いです。 | 用途を絞るほど省電力・低遅延・コスト最適化が効きます。 |
| 弱み | 供給制約・規制・価格の影響を受けやすいです。 | 設計・検証・量産に時間がかかり、見極めが必要です。 |
| 最適な使い方 | 学習と汎用推論の基盤として広く使います。 | 現場SLAが厳しい推論に集中投入します。 |
| 判定根拠 | 二者択一ではなく役割分担が合理的です。稼働成立(Power-Ready)を前倒しし、汎用GPUを活かしながら、差別化領域だけ設計主導権を握ります。 | |
読み終えたら確認したい3つの質問です
- 自社のAI計画は、GPU調達だけでなく受電(系統接続)・冷却・建屋まで含めて「稼働成立(Power-Ready)」を見積もれていますか。
- Rubin級の汎用GPUでどこまで行き、どこから用途別推論設計(IP/ASIC)へ踏み込みますか。
- Physical AIで最初にROIが出る現場(検査、保全、工程最適化、物流など)はどこですか。
4. Physical AIが再定義する日本の供給網と産業の矜持
日本の産業がAIで世界最強を奪還する舞台は、画面の中ではなく、物理世界(Physical AI)にあります。ここで重要なのは、私たちが長年培ってきた「緻密な仕事ぶり」をデジタルな知能としてハードウェアに実装することです。

例えば、水産資源の確保から流通までのプロセスを考えてみましょう。これまでは、荒天の海原で獲った魚を港へ運び、そこから加工工場へ輸送し、捌いてパッケージングしてスーパーに届けていました。しかし、日本独自の推論ASICを搭載した自律航行船があれば、港に着くまでの間に、船上で正確に魚を捌き、パッケージングまでを完結させることが可能です。
港に着底した瞬間に、そのまま陸上の物流網に乗り、数時間後にはスーパーの店頭に並ぶ。完全自動化までの道のりは段階的ですが、検査・計量・ラベリングから始め、徐々に高度化することで、供給網全体の効率を大幅に改善できます。陸上の工場に運んでから加工する時間をショートカットし、鮮度とコストを究極まで最適化する。これは単なる自動化ではなく、供給網全体の再定義です。
製造現場においても、人間と呼吸を合わせ、1ミクロンの狂いも感知して作業を完遂する協働ロボット。これらを、国内で設計・製造されたチップと、融合炉による次世代電源によって支えられ、一つのビジネスエコシステムとして回り出す。その光景は、もはや夢物語ではなく、私たちが今この瞬間に着手すべき現実の設計図です。
5. 設計・製造・電力を同時に立ち上げる、唯一の解
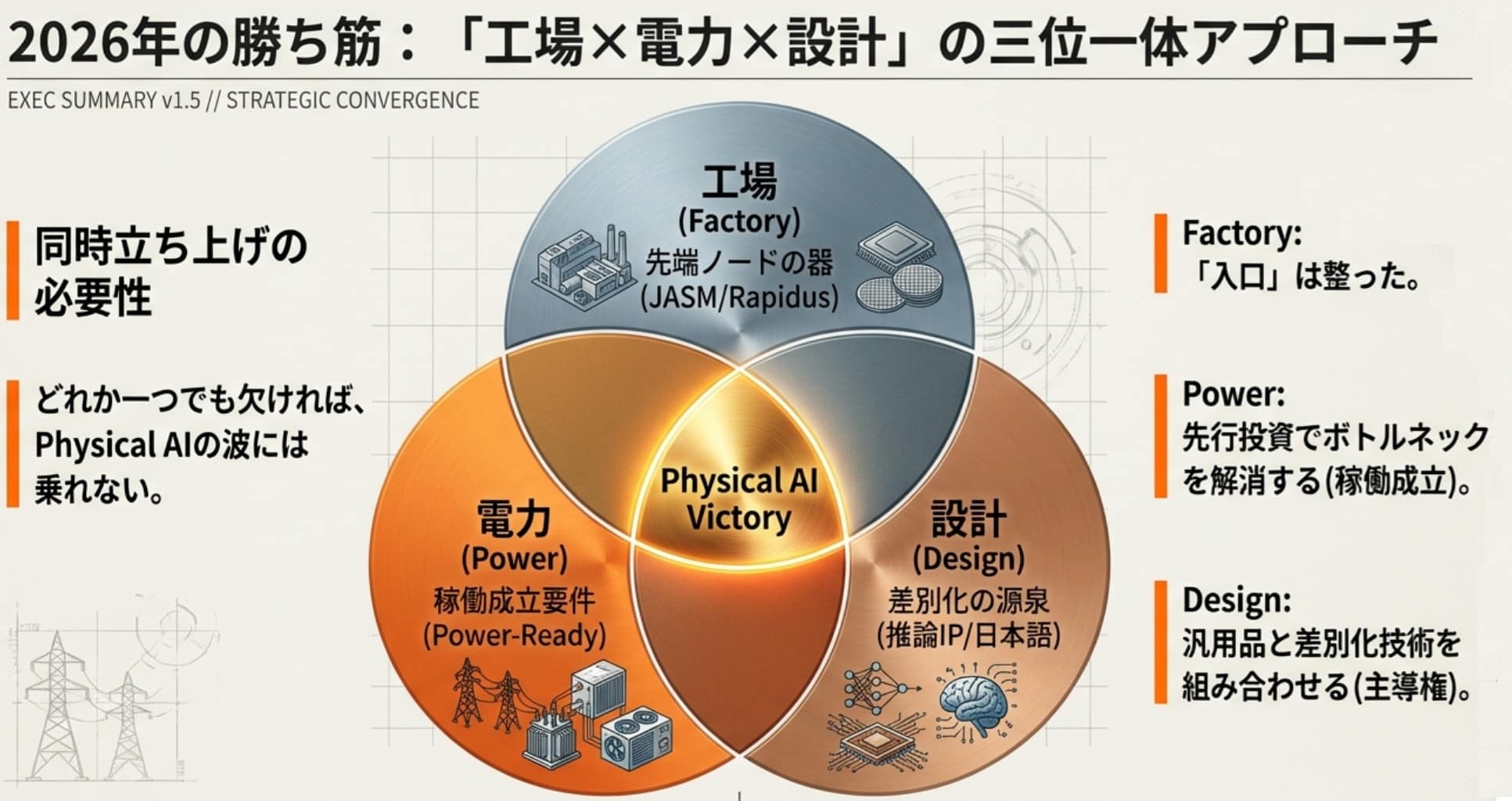
高市17分野を真に機能させるための最適解は、以下の三つを「同時」に立ち上げること以外にありません。
- 日本の製造業に最適化された推論特化型AIチップの「設計手法」の確立。
- 熊本や北海道のファウンドリを活用した「国内製造」の実行。
- AIインフラを支える、将来の核融合やSMRによる効率的な「ベース電源」の構築検討。
【具体像】「Power-Ready」先行で、AI工場の稼働を前倒しします
たとえば、工場やデータセンターの稼働を「GPU納入」起点で考えると、受電(系統接続)・変電・冷却の遅れがそのまま待機損になります。そこで最初から、受電・冷却・建屋を一体で前倒しし、稼働成立(Power-Ready)を確保した状態でGPUを受け入れます。すると同じ設備投資でも、稼働開始の遅れによる機会損失を小さくでき、Physical AIの需要増に合わせて増設の判断も速くなります。
特定のAIモデル単体の性能に一喜一憂するのではなく、物理世界への実装において世界をリードする「AIビジネス全体の循環」を創り出すこと。米国の需要過熱を学びとし、日本のブルーオーシャンで最適設計を完遂する。これこそが、日本の産業界が誇りを取り戻し、世界の真ん中に立つための、最後にして最大のチャンスなのです。
専門用語まとめ
- AI Business Optimization
- 先端半導体・電力・設計・現場プロセスまで含めて、AIを“事業の循環”として最適化する考え方です。
- Physical AI
- AIが物理世界(製造・物流・ロボット等)で、センサー入力→判断→制御までを担い、現場制約の中で最適化を実行する仕組みです。
- 稼働成立(Power-Ready)
- 受電(系統接続)・送配電・変電設備・冷却・建屋・冗長性まで揃い、GPUやサーバーが止まらず回り続ける状態です。
- 受電(系統接続)
- 送配電網へ接続し必要電力を得るための手続き・設備の総称です。接続待ちや設備増強の遅れが稼働を止めます。
- 3nmプロセス
- 半導体製造の先端ノードの一つです。高性能・省電力なAIチップの実装に直結しやすいとされます。
- 推論(Inference)
- 学習済みAIモデルで回答や判断を生成する処理です。Physical AIでは低遅延・省電力・高信頼が重要になります。
- 推論ASIC
- 推論処理に特化した専用回路です。用途を絞るほど電力・遅延・コストの最適化が効きます。
よくある質問(FAQ)
Q1. なぜ「工場(製造)」だけでは勝てないのですか
A1. Physical AIの需要爆増局面では、受電(系統接続)・冷却・建屋を含む稼働成立(Power-Ready)が律速になるためです。チップを焼けても回らなければ価値が出ません。
Q2. なぜ将来の核融合やSMRを「同時に」検討する必要があるのですか
A2. 電力は後追いで増やしにくく、需給が逼迫した後では稼働の前倒しが難しいためです。短期はPower-Readyを前倒ししつつ、中長期の電源オプションを設計前提に組み込みます。
Q3. Rubin級の汎用GPUを使えば十分ではないのですか
A3. 汎用GPUは土台として最適ですが、差別化は日本語・現場制約・安全保障を満たす推論設計で作るのが現実的です。
Q4. 「設計主導権」とは何を指しますか
A4. 用途別に推論の最適化(IP/ASIC/ソフト)を、自分たちの意思で決められる状態です。供給リスクと運用コストを抑え、現場要件に合わせて進化できます。
Q5. 図2の漁船ユースケースは本当に実現できますか
A5. 価値は「工程の前倒し」と「供給網の短縮」です。完全自動化の有無より、検査・計量・ラベル・包装など部分最適から段階導入するのが現実的です。
Q6. 「受電」と「電力インフラ」は同じ意味ですか
A6. 同じではありません。受電(系統接続)は“つなぐ”行為と設備を指し、電力インフラは送配電・変電・発電・冷却など“回す”ための全体条件を指します。本稿では重複しないよう言い分けています。
まとめ

米国の受電待ちが示す通り、電力は後追いで間に合いません。
だからこそ日本は、将来の核融合実装を見据えた設計も含めつつ、まずはSMRなど現実に進む次世代ベース電源オプションを視野に入れ、最初から電力とデータセンターを一体で設計すべきです。
同時に、Rubin級の汎用GPUを土台に使いながら、安全保障・日本語最適化・現場制約に直結する領域では用途別の推論設計(IP/ASIC)へ踏み込みます。つまり、「設計・製造・電力」を同時に立ち上げることが唯一の解です。
今日のお持ち帰り3ポイント
- 工場は入口で、勝負は稼働成立(Power-Ready)です。
- 汎用GPUを土台に使い、差別化は用途別の推論設計で作ります。
- 設計・製造・電力を同時に立ち上げるほど、需要爆発の前にボトルネックを潰せます。
経営者・投資家が明日決めるべき3つの優先順位
まず、「いつまでにどの規模のPower-Readyを確保するか」を決め、用地・系統接続・冷却方式の前倒し投資計画を引き直します。
次に、「Rubin級GPUをどのレイヤーまで共通基盤にし、どのユースケースから用途別推論ASIC/IPに踏み込むか」を3年スパンで切り分けます。
最後に、「自社の現場(製造・物流・インフラ)のどこでPhysical AIが最初にROIを出すか」を、1〜3件の具体プロジェクトとして特定し、PoCではなく量産前提の設計に着手します。
これにより、「ストーリーとしての気づき」から「ポートフォリオの組み替え」までの橋渡しができます。
主な参考サイト
本記事は一次情報を軸に執筆しています。公式発表・主要メディアを優先し、外部リンクで検証可能性を担保します。
- TSMC CEO flags 3-nanometre chip production in Japan(Reuters, 2026)
- TSMC to make advanced AI semiconductors in Japan(AP News, 2026)
- TSMC to produce advanced chips in Japan(Financial Times, 2026)
- AIインフラ投資2028年予測(Arpable, 2026)
- AIチップ・マーベリックス(Arpable, 2026)
あわせて読みたい
本稿の理解を「電力(受電)→ 設計主導権 → Rubin世代 → 実装(CUDA代替)」の順に深められる関連記事を7本に厳選しました。
更新履歴
- 初版公開








