


※本記事は継続的に最新情報へアップデートしています。
CUDA代替は、もはや「NVIDIAを使うか、使わないか」という単純な二択ではない。
ROCm、ZLUDA、Triton、Mojo、SYCL、oneAPI、MLIR基盤が広がるほど、私たちはCUDAの真の強みである「4層の密結合エコシステム」を再評価する必要がある。
そして2026年、Vera Rubinプラットフォームは静かな逆説を突きつけた。ソフトウェアの壁が薄くなるほど、「どのGPUでも動くか」ではなく「どのインフラが1円・1ワットあたり最も多くのトークンを生むか」が問われるからである。
✅ 先に結論
- CUDAの堀は「崩れる/崩れない」ではなく、層ごとに崩れ方が違います。 API互換は崩れやすく、GEMM・分散通信・プロファイリング・運用最適化は残りやすい領域です。
- ROCmはAMD MI系GPUの実運用スタック、ZLUDAは既存CUDA資産を動かす互換レイヤー、TritonはCUDAを書かずに高速カーネルを作る実装レイヤー、Mojoは長期の性能可搬性を狙う言語基盤として整理できます。
- ZLUDAは移植コストを下げる入口として有効ですが、商用本番で長期利用するには、ライセンス・サポート・継続性の評価が欠かせません。
- Vera Rubinプラットフォームは、Rubin GPU、Vera CPU、Vera Rubin NVL72、第6世代NVLink、BlueField-4 DPUを中核とするラックスケールAI基盤です。Groq 3 LPXは、Vera Rubin NVL72と組み合わせ可能な低遅延推論アクセラレータラックとして位置づけられています。
- 脱CUDAの本質は「NVIDIAから逃げること」ではありません。 どの層を抽象化し、どの層では物理効率を取りに行くかを見極めることです。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
CUDA代替とは何か
CUDA代替とは、CUDAで育ったAI資産を、NVIDIA以外のGPUや中立的な実装基盤でも動かしやすくするための技術群である。
CUDAは、NVIDIA GPUを使うための単なるプログラミング環境ではありません。AI開発の現場では、CUDAランタイム、PTX、cuBLAS、cuDNN、NCCL、Nsight、各種フレームワーク最適化までが重なり合い、ひとつの巨大な実行基盤になっています。
そのため「CUDA代替」と言っても、意味はひとつではありません。既存CUDAアプリケーションをなるべく書き換えずに動かしたいのか。CUDAを書かずに高速カーネルを開発したいのか。AMD GPUへ本格移行したいのか。あるいは、将来のマルチベンダー環境を見据えて言語やIRから作り直したいのか。
本記事では、CUDA代替を「CUDAという密結合の堀を、どの層で崩しにいくか」という視点で整理します。
| 分類 | 代表技術 | 狙い | 現場での見方 |
|---|---|---|---|
| 別スタック型 | ROCm / HIP | AMD GPUでAIワークロードを本格運用する | NVIDIA外の実運用候補。MI系GPUの性能向上と合わせて重要度が増している |
| 互換実行型 | ZLUDA | 既存CUDA資産をなるべく書き換えずに動かす | 移植コストを下げる入口。ただし商用本番では継続性と法務リスクの評価が必要 |
| 新規開発型 | Triton | CUDAを書かずに高速GPUカーネルを作る | Attentionや前後処理など、融合カーネルで効く領域に強い |
| 基盤刷新型 | Mojo / SYCL / oneAPI / MLIR系 | 言語・コンパイラ・IRから性能可搬性を狙う | 短期置換よりも、中長期の標準化・マルチベンダー戦略に向く |
ここで重要なのは、どれかひとつが「CUDAを完全に置き換える」わけではないことです。脱CUDAは、万能の一本槍ではなく、層ごとに違う武器を使い分ける戦いです。
読み進める前に、自社が今悩んでいるのは「どのレイヤーか(API互換/カーネル開発/マルチベンダー化/インフラ調達)」を一度頭の中でラベリングしておくと、この後のマッピングが一気に読みやすくなります。
Vera RubinプラットフォームとCUDAの堀
Vera Rubinプラットフォームは、GPU単体ではなく、ラック全体をAIスーパーコンピュータとして協調設計するNVIDIAの次世代基盤である。
Vera Rubinプラットフォームとは、
NVIDIAが掲げる「データセンター、つまりラックこそが最小単位のコンピュータ」という思想を、Vera CPU、Rubin GPU、第6世代NVLink、Vera Rubin NVL72ラックまで一体で実装したアーキテクチャです。
GPU単体の馬力競争ではなく、演算、通信、制御、セキュリティ、ストレージ、推論アクセラレーションを“ひとつのAIスーパーコンピュータ”として協調設計し、長コンテキストのエージェント推論を止めないことを狙います。
図解:なぜ「GPUを速くするだけ」では勝てないのか
AIのボトルネックは、Blackwell世代ですでに顕在化していたように、計算そのものよりもデータ移動(メモリ/通信/I/O)へ寄っています。だから勝敗を分けるのは「主演(GPU)」ではなく、劇場(NVL72ラック)全体の待ち時間を消す設計です。
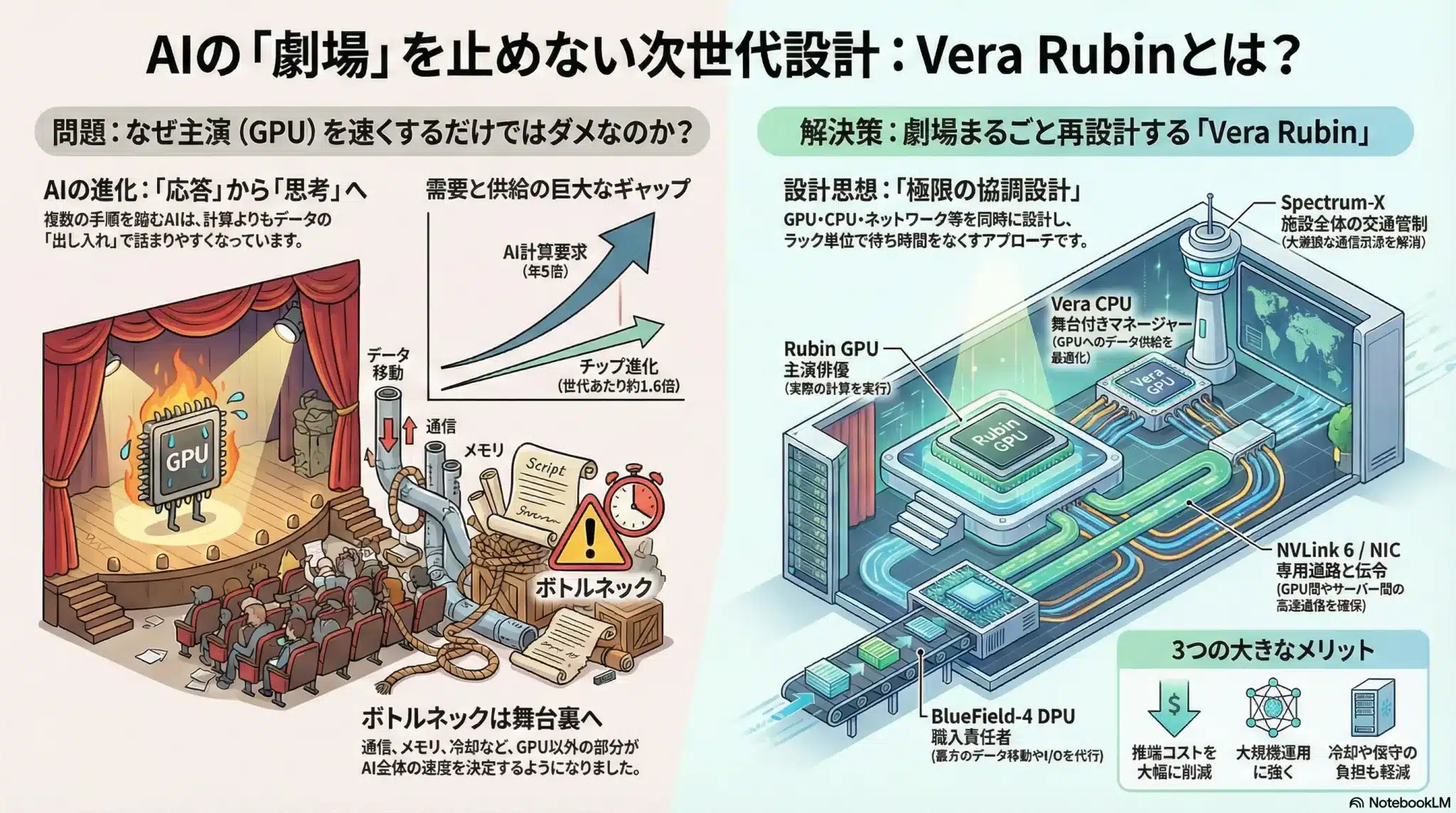
Vera Rubin NVL72の構成
Vera Rubin NVL72は、72基のRubin GPU、36基のVera CPU、ConnectX-9 SuperNIC、BlueField-4 DPU、第6世代NVLink / NVLink Switchを1ラックに統合するラックスケールAIスーパーコンピュータです。
NVIDIAはVera Rubin世代で、Blackwell世代比の「最大で4分の1のGPUで同等の学習性能」「特定の推論ワークロードでコストを最大1/10に下げる」といったメッセージを前面に出しています。
Groq 3 LPXは、Vera Rubin NVL72と組み合わせ可能な低遅延推論アクセラレータラックであり、Rubinプラットフォームと協調設計された「トークン生成エンジン」として位置づけられています。
NVIDIAは、Groq 3 LPXラックをRubin NVL72の隣に置く構成で、トリリオンパラメータ級のMoEモデルや数十万トークンのコンテキストに対して、低レイテンシかつ高トークンスループットの推論を狙うと説明しています。
Vera Rubinの構成要素(Rubin GPU、Vera CPU、Vera Rubin NVL72、Groq 3 LPX、BlueField-4 DPU、第6世代NVLink / NVLink Switchなど)の整理は別稿に集約しています。
Vera Rubin AIデータセンター完全ガイド
ここで逆説が生まれます。CUDA代替が進み、ソフトウェア資産を別GPUへ移しやすくなるほど、最後は「どのインフラが最も安く、少ない電力で、多くのトークンを生成できるか」が問われます。その土俵でNVIDIAは、CUDAだけでなくラックスケールの物理効率そのものを武器にしようとしているのです。
CUDAという密結合の堀は、なぜ強いのか
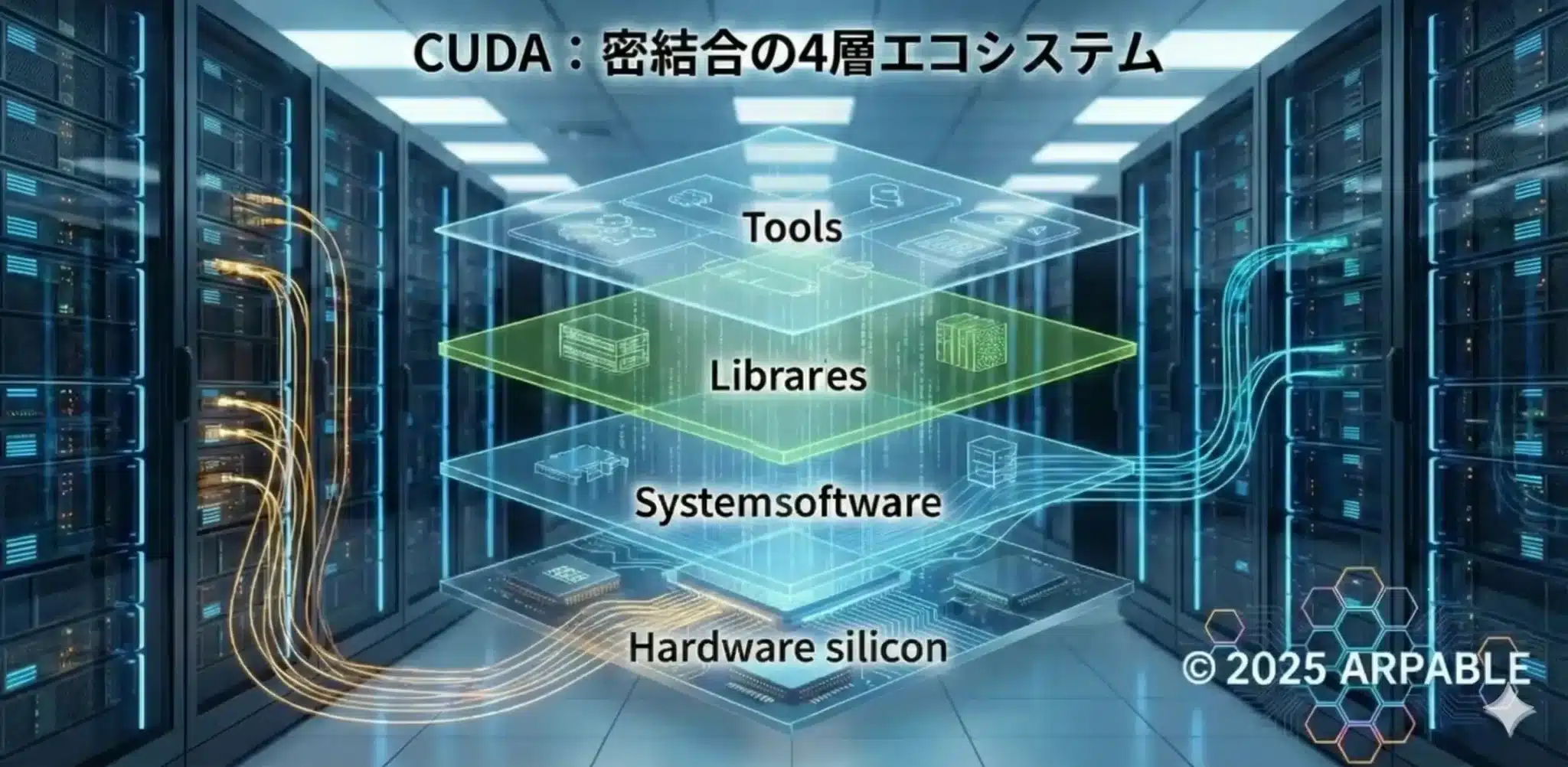
CUDAの強さは「GPUを動かす道具」ではなく、理論性能を実効性能へ変換する4層の密結合にある。
競合が同等以上のGPUを作れても、レースでは勝ち切れないことがあります。NVIDIAには、20年以上かけて育て上げたCUDAエコシステムという城壁(モート)があるからです。
エンジニアがNVIDIAから離れにくい理由は、単にCUDAコードが多いからではありません。物理回路を使い切るための仕組みが、ライブラリ、コンパイラ、プロファイラ、通信スタック、開発者知見まで一気通貫で揃っているからです。
GPUは、行列演算(GEMM)のように、同じ計算を大量データに繰り返し適用する処理で圧倒的です。一方で、GPUの理論性能は、放っておけば自動的に実効性能にはなりません。最大の敵はメモリ待ちです。
たとえばLLM推論では、行列積そのものよりも、KVキャッシュの読み書きやAttentionのメモリアクセスで演算器が遊ぶ瞬間が生まれます。いくらエンジンが速くても、燃料がうまく供給されなければ意味がありません。この「燃料供給」を最適化するノウハウの塊がCUDAです。
CUDAの強さは「GPUを動かす道具」ではありません。ポイントはたった1つです。Rubin世代のようなラックスケールGPUの理論性能(FLOPS)を、推論の実効性能(レイテンシ、スループット、コスト/トークン)に変換する仕組みが、ライブラリ、ツール、NVLinkスケールの通信スタックまで一体で揃っていることです。
要点:FLOPSは「馬力」、勝敗は「段取り」
GPU性能は「馬力(FLOPS)」だけでは決まりません。馬力をラップタイムに変える段取り、つまりメモリ配置、アクセスの揃え方、カーネル融合、並列実行、NVLinkスケールの通信設計で決まります。
CUDAという城を構成する4つの階層
CUDA依存の実態は、以下の4層が密接に絡み合った重層構造です。他社チップが苦戦するのは、単に「コードが動かない」からではありません。理論性能を実効性能へ変換する歯車が、層ごとに長年磨き込まれているためです。
| 階層 | 具体的な内容 | 脱CUDAにおける鬼門 |
|---|---|---|
| API / ランタイム層 | CUDA Runtime / CUDA Driver | メモリ確保、カーネル起動。互換レイヤーで置き換えやすい「城の門」。 |
| 実行・生成層 | PTX、NVCC、JIT | 物理チップの世代更新への追随が必要。互換だけでは性能が出にくい。 |
| 最適化ライブラリ層 | cuBLAS / cuDNN / NCCL | 最も厚い本丸。GEMM、畳み込み、分散通信の職人技が蓄積されている。 |
| ツール層 | Nsight / Profilers | ボトルネックを短時間で見つけ、改善へつなげる診断力が問われる。 |
特に第3層の最適化ライブラリは、NVIDIAのエンジニアが回路設計の段階から磨き込んできた「最適化の集大成」です。cuBLASによる行列演算や、NCCLによる分散通信の効率は、単にコードを他社チップへ移植しただけでは再現できません。
F1マシンの比喩で解く「実効性能」の正体

F1はエンジンが強いだけでは勝てません。タイヤ温度、ピット作業、燃料戦略、路面状況、チーム間通信が噛み合って初めてラップタイムが出ます。GPU計算も同じです。
「エンジンの回転(演算)」を止めるのは、常に「燃料補給やタイヤ交換(メモリからのデータ供給)」です。 CUDAは、タイヤを並べる順番(Coalescing)や、チップ内の高速作業台(共有メモリ)の使いこなしを、ライブラリとツールとして製品化してきました。
不都合な真実:FLOPSが高いのに遅い理由
どんなに馬力のある他社製エンジン(チップ)を持ってきても、ピットクルー(ソフトウェア)がマシンの物理構造を熟知していなければ、タイヤ交換(メモリアクセス)に時間がかかり、ラップタイム(AI応答速度)で負けます。これが「FLOPS値は高いのに、推論が遅い」という現象の正体です。
ROCm・ZLUDA・Triton・Mojo:脱CUDAの勢力図
脱CUDAは、どの技術が最強かではなく、どの層を崩したいかで選ぶべきである。
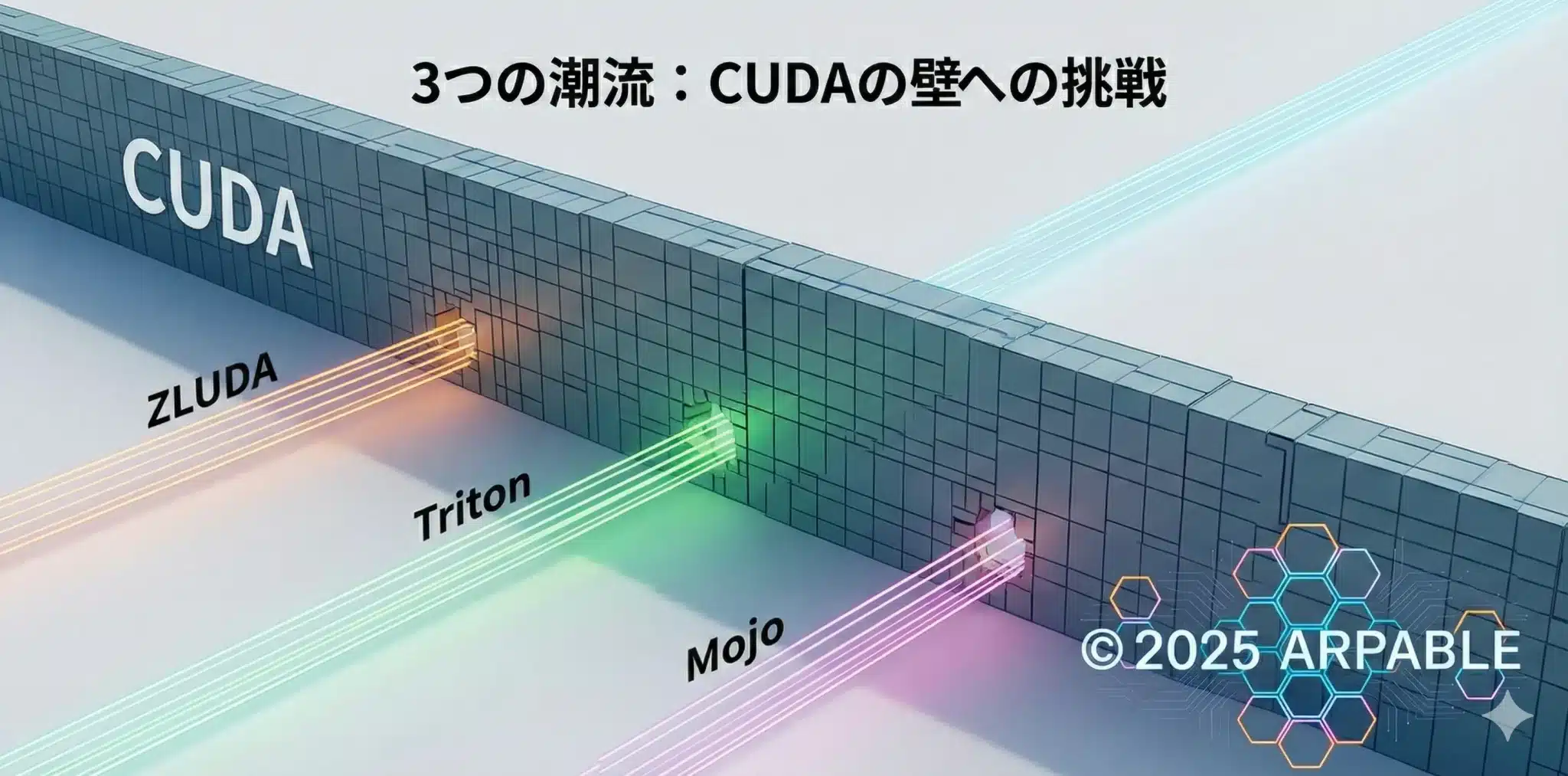
CUDAを崩すアプローチは無数に見えますが、要点は単純です。どの層を置き換えるかです。翻訳する層を間違えると、次のどちらかに落ちます。
- 動いたのに速くない。つまり本丸であるGEMMや通信最適化が残っている。
- 速いのに運用できない。つまり計測、デバッグ、再現性、性能回帰テストが弱い。
2026年時点では、ZLUDA、Triton、Mojoだけでなく、ROCm+AMD Instinct MIシリーズも無視できません。AMDはMLPerf Inference v6.0で、MI355XとROCm 6を組み合わせたシステムが、一部のLLM推論ベンチマークで秒間100万トークン超のスループットクラスを示したと公表しており、脱CUDA側も期待論から実測でNVIDIA Blackwell系と同じベンチマークの土俵に乗り始めています。
ROCmとは:AMD GPUでAIを本格運用するための別スタック
ROCmは、CUDA互換レイヤーというより、AMD GPU上でAIワークロードを動かすための独立したソフトウェアスタックです。
ROCmの重要性は、単に「CUDAではないGPUソフトウェア」だからではありません。AMD Instinct MIシリーズのようなAI向けGPUと組み合わさることで、クラウドやHPC、生成AI推論で現実的な選択肢になり始めている点にあります。
ただし、ROCmへの移行は「ボタンひとつでCUDA資産が移る」話ではありません。ライブラリ、ドライバ、カーネル、通信、ベンチマーク、運用監視まで含めて、CUDAとは別の山を登る覚悟が必要です。
ZLUDAとは:既存CUDA資産を活かす同時通訳
ZLUDAは、既存CUDAアプリケーションを非NVIDIA GPU上で動かすことを狙う互換実行アプローチです。

ひとことで言えば、ZLUDAはCUDAアプリが期待する呼び出しを別実装で受け止め、非NVIDIA GPUでも実行できるようにする「同時通訳」です。特定のワークロードでは、RadeonやInstinct MI向けにほぼネイティブ性能で動作した事例も報告されています。
しかし、この実用的な同時通訳アプローチを採用するにあたっては、技術面以外の不確実性にも目を向ける必要があります。2024年以降、法的背景からコードが一時取り下げられた経緯は、ZLUDAを長期運用基盤として扱う際のガバナンス課題を浮き彫りにしました。
ZLUDAは、初期の移植コストを圧縮する優れたツールである一方、長期的な商用プロダクションにおけるサプライチェーンの継続性と、コンプライアンス上のリスク評価が極めてシビアに問われる選択肢と言えます。
- まず得すること:巨大なCUDA資産を抱えるほど、移植コストを圧縮できる。
- 向く状況:PoCを急ぐ、どこが詰まるかを実測して差分を掴みたい。
- 落とし穴:最終性能、未対応API、ライセンス、サポート、コミュニティ継続性を確認する必要がある。
使い方の型
- まず動かす:機能互換を確立する。
- 計測する:GEMM、Attention、通信のどこが支配的か切り分ける。
- 本番の道筋を決める:必要ならROCmネイティブや別スタックへの移行も視野に入れる。
そのためZLUDAは、移植コストを下げる入口としてPoC・検証用途に活かしつつ、最終的な本番環境ではROCmネイティブや別スタックへの移行も視野に入れる、という使い方が現実的です。
Tritonとは:CUDAを書かずに高速カーネルを作る
Tritonは、CUDAを直接書かずに、GPUに効くカーネルを高水準に記述するための実装レイヤーです。

Tritonが強いのは、CUDAそのものを置き換えるというより、GPUカーネル開発の敷居を下げ、メモリ待ちを減らす融合カーネルを作りやすくする点です。FlashAttention系の最適化が象徴的です。
- まず得すること:融合カーネルでメモリ往復を削りやすい。
- 向く状況:推論の主戦場がAttentionや前後処理で、工夫による改善余地が大きい。
- 落とし穴:GEMM、分散通信、巨大ライブラリ一式をTritonだけで丸ごと置換するのは難しい。
Mojoとは:言語基盤から性能可搬性を狙う
Mojoは、Python的な書きやすさとシステム言語的な性能を両立し、将来のマルチターゲット実行を見据える言語基盤です。

Mojoは、短期的に「CUDAコードを今すぐ置き換える」ための道具というより、AI開発の言語・コンパイル基盤を次の世代へ進める試みです。勝負は言語仕様だけではありません。計測、デバッグ、再現性、回帰テスト、チーム運用まで含めて定着するかが重要です。
「動く」より難しいのは「現場で回る」です。性能だけでなく、観測性、再現性、標準手順をセットで設計してください。
LLM推論の実務:FlashAttentionで見える脱CUDAの境界線
LLM推論では、CUDAから離れやすい領域と、NVIDIAの本丸が残りやすい領域がはっきり分かれる。
推論の現場で起きているのは、計算力の殴り合いだけではありません。実際には「待ち」を潰す競争です。しかも待ちには種類があり、同じ薬は効きません。巨大なレストランに置き換えると、全体像が見えやすくなります。
- GEMM(行列積):仕込み担当。大量の下ごしらえを高速に回す。
- Attention:盛り付け担当。情報をまとめて完成形にする。
- 分散通信:配膳・動線。厨房とホール、店舗同士をつなぐ物流。
厨房に最強の火力(GPU)があっても、仕込みが遅い、盛り付けが非効率、配膳が詰まると、お客さん(ユーザー)は待たされます。LLM推論は、この詰まりをどこで消せるかの勝負です。
境界線:GEMMは職人の道具が支配する
GEMMは、同じ作業を超高速で回し続ける世界です。ここで効くのは、誰でも使える包丁ではなく、店の厨房に合わせて研ぎ澄まされた専用の職人道具です。だからGEMMは、動かすことより、同じ速度で勝つことが難しい領域になります。
境界線:Attentionはまとめて一回でやると強い
Attentionは、火力よりも皿を取りに行く回数で遅くなります。何度もVRAMへ往復すると、そのたびに時間が溶けます。FlashAttentionが強いのは、盛り付け工程をまとめて一気に終わらせるからです。
この領域は、やり方の工夫で勝てる余地が大きいため、CUDA一本足ではなくなりやすい場所です。Tritonのような高水準カーネル記述が効きやすいのも、この領域です。
境界線:分散通信は道路と交通整理がすべて
店が1店舗ならよいですが、店舗が増える、つまりGPUやラックが増えると、最後は物流です。いくら厨房が速くても、道路が細い、信号が下手、渋滞が見えないと料理は届きません。
分散通信はコードだけでなく、ネットワーク、観測、運用まで含めて勝負が決まります。そのため、NCCLやNVLink、ラックスケール設計が絡む領域では、置換は簡単ではありません。
この章の結論
- GEMM:専用道具の厚みが効く。置換が最難関。
- Attention:往復回数を減らせば勝てる。中立化が進みやすい突破口。
- 分散通信:道路と交通整理の総合戦。置換が起きにくい最後の壁。
逆説のVera Rubinプラットフォーム:互換性が招くハブへの回帰
ソフトウェアの壁が薄くなるほど、最後は物理効率の高いAIファクトリーへ資産が集まる可能性がある。

ここまで積み上げてきた議論の果てに、2026年の市場はひとつの逆説に直面しています。
それは、ソフトウェアの壁が下がり「どこでも動く」自由が増えるほど、最後に選ばれるのは再びNVIDIA、特にVera Rubinプラットフォームになる可能性がある、という仮説です。
Vera Rubinプラットフォームは、Rubin GPU、Vera CPU、NVL72ラック、第6世代NVLink、BlueField-4 DPU、Confidential Computingを整合させたエージェント時代のAIファクトリーです。Groq 3 LPXは、その隣に配置して組み合わせ可能な低遅延推論アクセラレータラックとして、長コンテキスト・高トークンスループットの推論を支える構成要素になります。
ここで重要になる「中立資産」とは?
中立資産とは、特定ベンダー(CUDA専用、ROCm専用など)に縛られない形で蓄積でき、ONNX、MLIR、各社のIR・グラフ表現を経由して、Rubin / Blackwell / MI系 / 他ベンダーGPUのどれに対しても再利用・再コンパイルしやすい資産のことです。
- モデル、重み、量子化済みチェックポイント:どのGPUで動かすかと切り離された成果物。
- グラフ、IR、コンパイル可能な表現:ONNXやMLIR系のようにバックエンド差を吸収しやすい表現。
- アルゴリズム設計、タイル化、融合の知見:FlashAttention的な「メモリ往復を減らす設計思想」。
- 運用資産:測る、直す、回すためのベンチ手順、性能回帰テスト、再現性ある評価基盤。
中立資産が増えるほど、囲い込みの価値は相対的に下がります。その一方で、物理効率が最も高い舞台へ資産が集まる力は強まります。
もし、ZLUDA、Triton、Mojo、SYCL、ROCm、oneAPIのエコシステムがさらに成熟し、モデルや中間表現をより多くのGPUスタックへ移しやすくなる世界が訪れたら、ユーザーは何を基準にインフラを選ぶでしょうか。
答えは、純粋な1円・1ワットあたりのトークン生成量です。つまり、推論コスト/トークンとトークン/ワットです。
NVIDIAがVera Rubin世代で掲げる「特定の推論ワークロードでコストを最大1/10に下げる」というメッセージ。その文脈で象徴的なのが、低遅延推論に特化したGroq 3 LPXを、Vera Rubin NVL72と組み合わせ可能なラックスケール推論アクセラレータとして位置づけた点です。
GPUが長コンテキストや大規模推論の土台を支え、LPUベースのLPXラックがトークン生成の低遅延化を担う。つまりNVIDIAは、すべてをGPUだけで処理するのではなく、異なる計算アーキテクチャを協調設計し、AIファクトリー全体の物理効率を高める方向へ踏み出していると見ることができます。
ソフトウェアの檻が薄くなる世界では、皮肉にもVera Rubinの高密度な物理効率とエージェント推論向け最適化が、他社スタックで鍛えられたソフトウェア資産までも吸い寄せるインフラの磁石として働く可能性があります。
もちろん、これは確定した未来ではありません。価格、供給、クラウド契約、規制、既存運用、エンジニアの習熟度が絡みます。それでも、壁が薄いほど最終的に物理効率へ収束する力そのものは消えません。
CxOや投資家の視点では、「どのベンダーに賭けるか」ではなく、「1円・1ワットあたりトークン生成量の改善カーブを、どのポートフォリオで取りに行くか」という問いに置き換えると、この逆説が自分の意思決定と直結して見えてきます。
実務ではどう判断するか
脱CUDA戦略は、移植コスト・実効性能・運用力・調達リスクを分けて判断する必要がある。
CTOや技術選定者が避けるべきなのは、「CUDAか非CUDAか」という古い二元論です。実務では、次のように分けて考える方が安全です。
| 目的 | 候補 | 見るべきポイント |
|---|---|---|
| 既存CUDA資産をまず動かす | ZLUDA、互換レイヤー | 機能互換、対応API、性能差、ライセンス、サポート、継続性 |
| AMD GPUへ本格移行する | ROCm、HIP、AMD MI系 | ライブラリ成熟度、MLPerf結果、クラウド提供状況、運用体制 |
| 推論カーネルを高速化する | Triton、FlashAttention系 | Attention、前後処理、メモリ往復削減、ベンチ再現性 |
| 中長期でマルチベンダー化する | Mojo、SYCL、oneAPI、MLIR系 | 言語習熟、ツールチェーン、デバッグ、性能回帰テスト |
| 最高効率のAIファクトリーを使う | Vera Rubin、Blackwell、NVLink、NVIDIA AI Enterprise | コスト/トークン、トークン/ワット、供給、クラウド契約、CUDA資産 |
最優先が移植コスト削減なら、ZLUDAでまず動かし、計測して差分を掴む。推論最適化が主戦場なら、Tritonで融合カーネルを量産する。AMD GPU採用を本気で検討するなら、ROCmとMI系の実測・運用体制を確認する。3年スパンでマルチベンダー化したいなら、MojoやSYCL、MLIR系の中立資産を育てる。
そして、推論コスト、電力効率、長コンテキスト、分散通信まで含めたAIファクトリー全体の効率を最重視するなら、Vera Rubinプラットフォームのようなラックスケール設計を避けて通ることはできません。
まとめ:CUDAは崩れるのではなく、再配置される
2026年のAIインフラ競争は、CUDAの城壁を崩す戦いであると同時に、物理効率の高いAIファクトリーへ資産が集まる戦いでもある。
CUDAの強さは、GPUを動かす道具にとどまりません。API、PTX、最適化ライブラリ、プロファイラ、通信スタック、開発者知見まで含む、密結合の4層エコシステムです。
一方で、ROCm、ZLUDA、Triton、Mojo、SYCL、oneAPI、MLIRベースのコンパイル基盤のような選択肢は、CUDAの壁を層ごとに薄くし始めています。API互換、カーネル開発、中間表現、マルチベンダー運用の自由度は確実に増えています。
しかし、自由度が増えるほど、最後に問われるのは「どこでも動くか」だけではありません。どこで動かすと、最も安く、少ない電力で、速くトークンを生成できるかです。
2026年、AIの戦場はRubinプラットフォームの本格展開と、ROCmやMI系GPUスタックのMLPerfでの台頭に象徴されるように、「チップを何枚持っているか」という物理枚数の争いから、「どのスタックでも動かせる知力」を、いかに安く・省電力に回すかという抽象化×物理効率の二重の勝負に移りつつあります。
- CUDAの強さは、20年以上の密結合が生んだ「ハードとソフトの物理的な整合性」にある。
- ROCm、ZLUDA、Triton、Mojoは、それぞれ異なる層でCUDAの城壁を薄くしている。
- ソフトの壁が薄くなるほど、最後はVera Rubinのような高効率AIファクトリーへ資産が集まる可能性がある。
専門用語まとめ
- CUDA
- NVIDIA GPU向けの並列計算プラットフォーム。AI学習・推論の多くのライブラリやツールがCUDAを前提に最適化されてきた。
- ROCm
- AMD GPU向けのオープンなAI/HPCソフトウェアスタック。AMD Instinct MIシリーズと組み合わせてAIワークロードを実行する。
- ZLUDA
- 非NVIDIA GPU上でCUDAアプリケーションを動かすことを狙う互換実行アプローチ。移植コスト削減の入口として注目されるが、商用本番では継続性や法務面の確認が必要。
- Triton
- CUDAを直接書かずにGPU向け高速カーネルを記述するための言語・コンパイラ基盤。Attention最適化などで使われる。
- Mojo
- AI開発向けに設計された高性能プログラミング言語。Python的な書きやすさとシステム言語的な性能の両立を狙う。
- PTX(Parallel Thread Execution)
- NVIDIA GPU向けの中間命令表現。CUDAコードとGPU実行の間をつなぐ重要な層。
- MLIR(Multi-Level Intermediate Representation)
- 複数の抽象度を扱える中間表現。異なるチップやバックエンドへ最適化を展開する基盤として注目される。
- ONNX
- 機械学習モデルを異なるフレームワークや実行環境へ移しやすくするためのオープンなモデル表現形式。
- NVLink
- NVIDIAの高速GPU間接続技術。ラックスケールAIインフラでは、GPU同士の通信性能を左右する重要要素。
- Groq 3 LPX
- Vera Rubin NVL72と組み合わせ可能な低遅延推論アクセラレータラック。長コンテキスト・エージェント推論で重要になる。
参考文献 / 出典
- NVIDIA — Vera Rubin NVL72
- NVIDIA Technical Blog — NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer
- NVIDIA Technical Blog — Inside NVIDIA Groq 3 LPX
- NVIDIA Newsroom — NVIDIA Kicks Off the Next Generation of AI With Rubin
- ZLUDA — CUDA on Non-NVIDIA GPUs
- Phoronix — Open-Source AMD GPU Implementation Of CUDA “ZLUDA” Code Has Been Taken Down
- OpenAI — Triton: An intermediate language for AI compilers
- Modular — Mojo Programming Language
- AMD — MLPerf 6.0: AMD Instinct MI355X GPUs Surpass 1M Tokens/Sec
- MLCommons — MLPerf Inference v6.0 Results
合わせて読みたい
よくある質問(FAQ)
Q1. CUDA代替とは何ですか?
A1. CUDA代替とは、NVIDIA CUDAに依存してきたAI資産を、ROCm、ZLUDA、Triton、Mojo、SYCL、oneAPI、MLIR系の技術を使って、別GPUや中立的な実行基盤でも動かしやすくする考え方です。
Q2. ZLUDAとは何ですか?
A2. ZLUDAは、既存CUDAアプリケーションを非NVIDIA GPU上で動かすことを狙う互換実行アプローチです。RadeonやInstinct MI向けに、CUDAアプリがほぼそのまま動作した事例も報告されていますが、一部機能は未対応で、法的な懸念から一時的にコードが取り下げられるなど、プロジェクトの継続性に関する議論が続いてきた経緯もあります。
そのため、移植コストを下げる入口として有効である一方、商用本番での長期利用には、ライセンス・サポート・コミュニティの継続性といったリスク評価が不可欠です。
Q3. TritonやMojoを使えばCUDAエンジニアは不要になりますか?
A3. いいえ。抽象化レイヤーの背後で性能を絞り出すには、GPUのメモリ階層、並列実行、カーネル融合、分散通信の知識が依然として重要です。役割が「CUDAを書く人」から「ハードウェア特性を理解して設計する人」へ広がると捉えるべきです。
Q4. ROCmはCUDAの代替になりますか?
A4. 一部の用途では有力な代替候補になります。特にAMD Instinct MIシリーズとROCmの組み合わせは、生成AI推論やHPCで現実的な選択肢になりつつあります。ただし、CUDA資産をそのまま完全移行できるわけではなく、ライブラリ・運用・検証体制まで含めた評価が必要です。
Q5. Vera RubinプラットフォームはCUDA代替を弱めますか?
A5. 直接的には弱めません。むしろ、ソフトウェアの壁が薄くなるほど、最後はコスト/トークンやトークン/ワットのような物理効率で選ばれます。その意味で、Vera Rubinプラットフォームは、CUDAの囲い込みだけでなく、AIファクトリー全体の効率で資産を引き寄せる可能性があります。
更新履歴
- :初稿公開。CUDAの密結合エコシステム、ZLUDA・Triton・Mojoによる脱CUDAの可能性、Vera Rubinの逆説を整理。
- :2026年版として改稿。タイトルを「CUDA代替」起点へ変更し、ROCm、MLPerf Inference v6.0、Vera Rubinプラットフォーム、Groq 3 LPX、ZLUDAの継続性リスク、コスト/トークン、トークン/ワット、関連記事5本を反映。








