※本記事は2026年3月16日発表の最新アーキテクチャに基づきアップデートしています。
AIロボットは「世界をどう見て」「どう学ぶ」のか?|Cosmos・Omniverse・Isaac Sim・OSMO入門
倉庫ロボットや自動運転のニュースで「NVIDIA Cosmos」「Omniverse」「Isaac Sim」といった単語を見かけても、それぞれが何者で、どうつながってロボットの学習を支えているのかまでは見えにくいのではないでしょうか。
本記事では、ロボット好きの一般読者に向けて、仮想倉庫での試運転(Omniverse / Isaac Sim)→世界バリエーションの拡張(Cosmos)→学習ループの自動化と統率(OSMO) という流れを、最新のPhysical AI開発ストーリーでわかりやすく解説します。最終的には、Sim→学習→運用の閉ループ がなぜ重要なのかまで整理します。
✅ この記事の結論
- ロボットは「動画だけ」ではなく、1フレームごとのカメラ画像とロボットの動作・センサー情報のセットを教材として世界と行動の関係を学んでいる。
- Omniverse(+Isaac Sim)は倉庫のデジタルツインとロボットを動かす舞台、Cosmosはその映像を増やす世界モデル、OSMOはそれらを自動で回す現場監督として機能する。
- 最新の「Physical AI Data Factory」では、仮想倉庫でのデータ取得からCosmosによる拡張、OSMOによる自動学習までが一本の神経系のように繋がり、改善が止まらないループを形成している。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』▶ 詳細はこちら
🚀本記事はPhysical AIの工場実装・運用5部作の第5部です。なお、本記事はロボット系クラスターの中では「開発基盤と学習ループを初心者にも腹落ちする形で説明する記事」の役割を担います。
- 👉 第1部:産業用ロボット2.0とは?Physical AI時代の工場OS選定
- 👉 第2部:Physical AI 2026:仮想と現実の双方向ループ
- 👉 第3部:AIロボット×デジタルツインで自己改善
- 👉 第4部:トヨタとTPSに学ぶAIロボットの学習ループ
- 👉 現在の記事:第5部:ロボットは「世界をどう見て」「どう学ぶ」のか?
Cosmos・Omniverse・OpenUSDはロボットにとって何者か
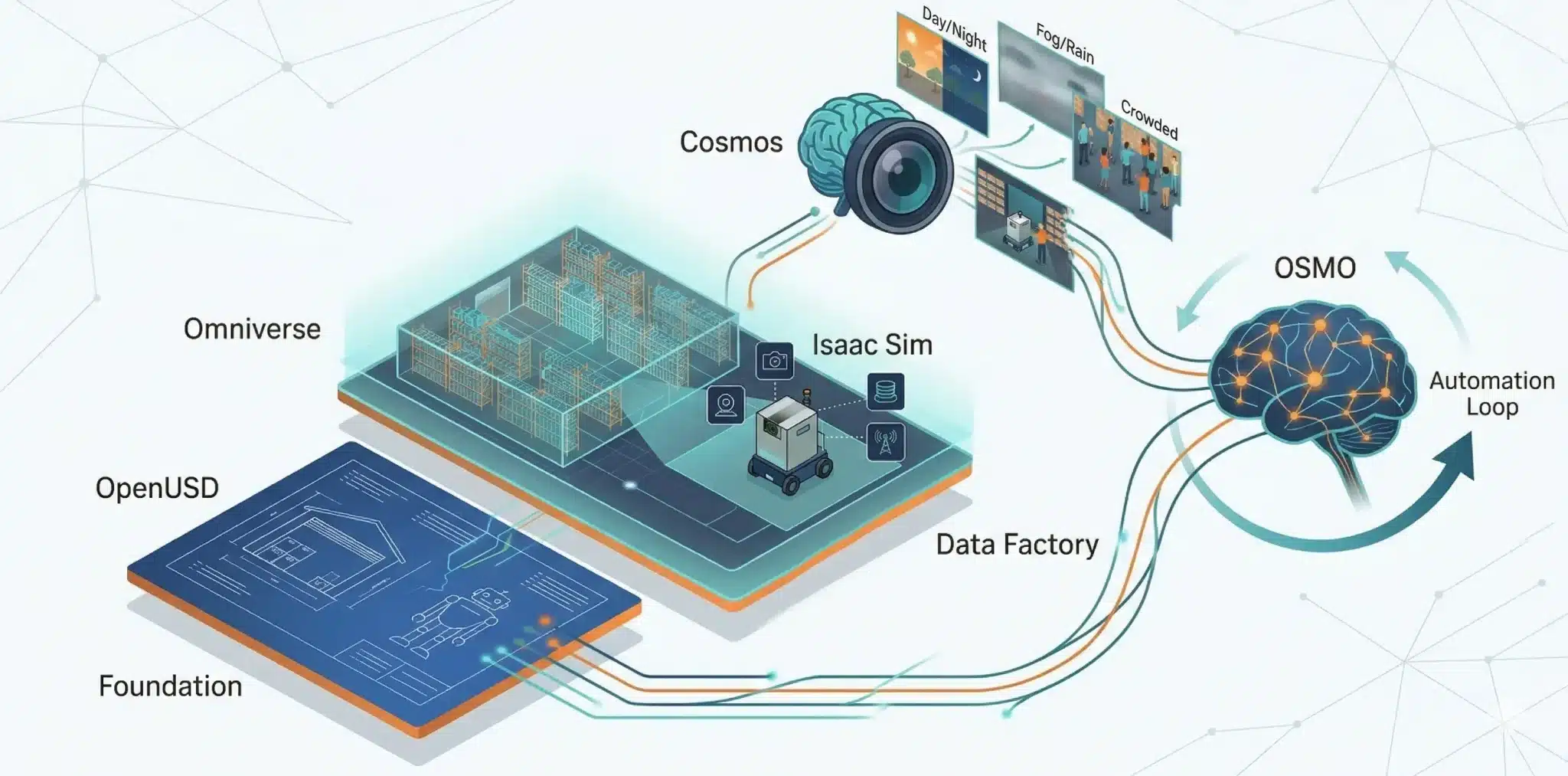
Cosmosは「世界の映像を理解・生成するAI」、Omniverseは「その世界を丸ごと再現する3Dスタジオ」、OpenUSDはその土台となる共通図面であり、これらを繋ぐOSMOが開発全体を指揮する。
まず、名前がややこしいNVIDIA Cosmos、Omniverse、Isaac Sim、そして新しく加わったOSMOの役割をざっくり整理します。細かいアルゴリズムよりも、「ロボットから見て何をしてくれる存在なのか」を押さえると全体像がつかみやすくなります。
なお、USDは一言でいえば「世界の設計図の書式」です。 倉庫の棚、通路、ロボット、センサーの位置などを共通のルールで記述し、その図面をみんなで共有しやすくした考え方がOpenUSDだと捉えると、後の話がかなり追いやすくなります。
ロボット工場を立ち上げる話として考えると分かりやすい
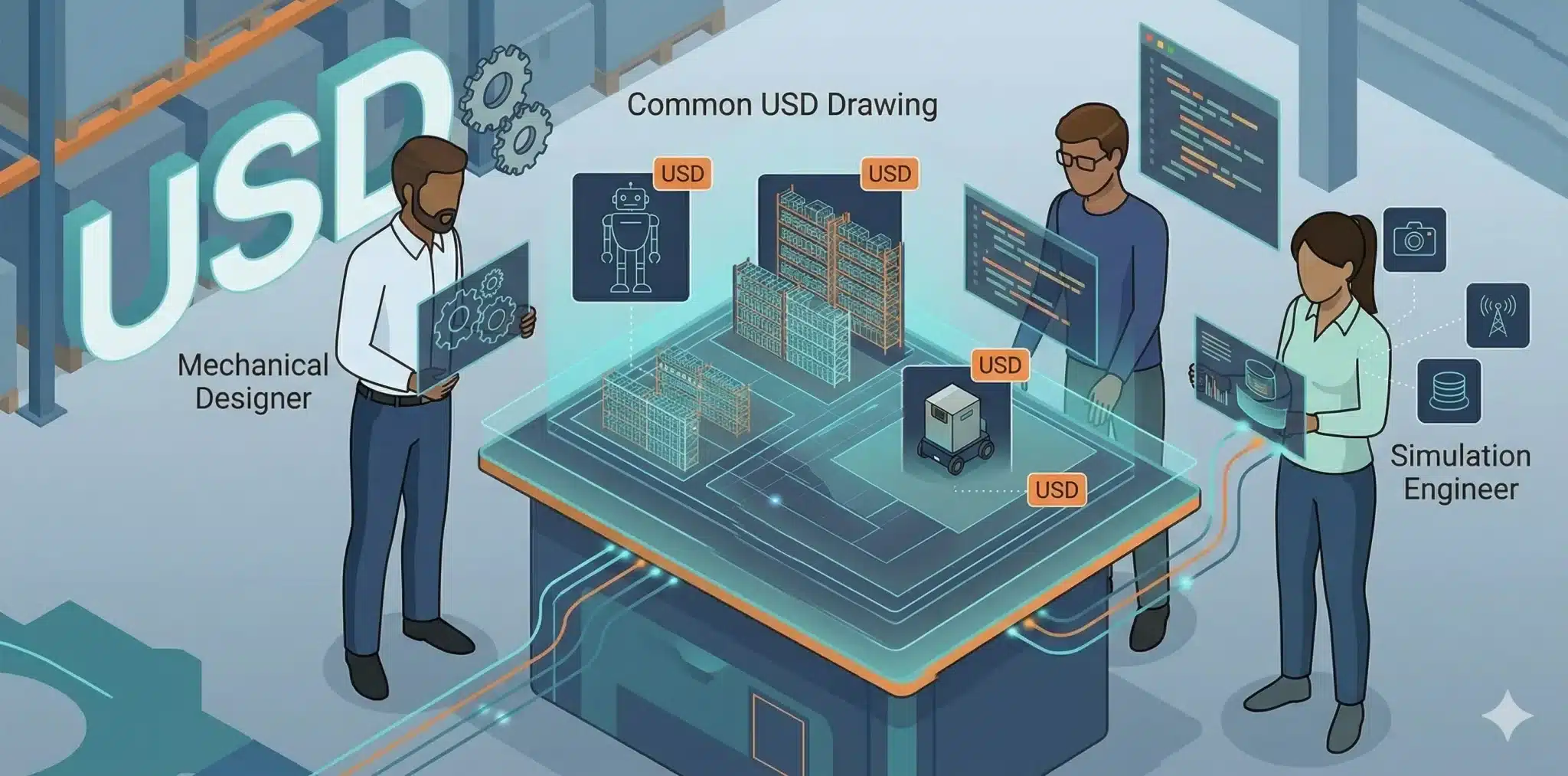
たとえると、このスタックは「ロボット工場を設計し、試運転して、本番さながらの過酷なテストを自動で繰り返す仕組み」です。
まずUSD / OpenUSDは、工場やロボットを同じ書き方で表す「みんなが読める共通図面のルール」です。設計部も制御部もこの同じ図面を見ながら作業します。
その図面を読み込んで、世界を動かす土台がOmniverseです。そしてその上で、ロボットを実際に走らせてデータを取る「テスト工場」がIsaac Sim / Isaac Lab。
そして注目なのがCosmos。これは単なる「試運転の場所」ではありません。
Cosmosは、その試運転工場に「現実世界の予測不能な牙を剥かせる」ための世界モデルです。晴れの日だけでなく、暗い、滑る、乱反射する、障害物が出る――そんな条件を増やして、ロボットを温室育ちのAIから、現場で戦えるPhysical AIへと進化させる道具箱です。
最後に、これら全ての工程――シミュレーション、映像生成、学習、評価――を一本の神経系のように繋ぎ、大規模GPUクラスタで自動実行する「現場監督」がOSMOです。
これにより、ロボット開発は職人芸から、24時間止まらない「Data Factory(データ工場)」へと変貌を遂げます。
4つの要素の位置づけ比較
Cosmos、Omniverse、Isaac、OSMOは、それぞれ役割が違うので混同しないことが重要です。
これらは、ロボットから見たときの立ち位置で整理すると分かりやすくなります。
| 要素 | 役割 | ロボットから見たイメージ | 技術的な中身の例 |
|---|---|---|---|
| OpenUSD | 倉庫やロボットを記述する3D設計図 | 倉庫の図面、ロボットの設計図 | シーン構造、ロボット配置、センサー位置、マテリアルなど |
| Omniverse+Isaac Sim | 倉庫とロボットを動かす3Dスタジオ | 仮想倉庫の中で走り回る練習場 | 物理シミュレーション、センサーシミュレーション、合成データ生成 |
| Cosmos | 世界の振る舞いと物理を学んだ世界モデル | 映像を増やし未来を予測する世界観監修 | Cosmos Predict/Reason/Transferなど、動画生成・物理推論 |
| OSMO | 開発ループ全体を自動で回す神経系 | GPUクラスタを段取りするオーケストレーター | ワークフロー定義(YAML)、ジョブスケジューリング、学習・評価の自動実行 |
| ※ 2026年3月時点のNVIDIA Physical AI Data Factory Blueprintに基づきArpable編集部で整理。 | |||
なぜこの組み合わせが注目されているのか
実世界の倉庫ロボットをいきなり現場で学習させると、事故や業務停止のリスクが大きすぎます。そこで、まず仮想世界で徹底的に練習してから、実機に移す「シミュレータ先行」の流れが主流になりつつあります。
一方で、仮想世界だけでは「現実と見え方が違う」「レアなトラブルがうまく再現できない」という課題が残ります。
そこでCosmosのような世界モデルが入ることで、仮想倉庫をベースにしながら、夜間・混雑・悪天候・視界不良などの条件違いを増やしやすくなるため、倉庫ロボットの学習効率と安全性を引き上げる存在として注目されています。
そして、これら全ての工程を「AIファクトリー」として統合管理するOSMOが登場したことで、開発のスピードが劇的に向上しました。
2026年3月の最新動向では、単なるシミュレーションを超えた、自律的な学習サイクルの構築が業界のスタンダードとなっています。
ロボットは「何を見て」「何を学んでいるのか」
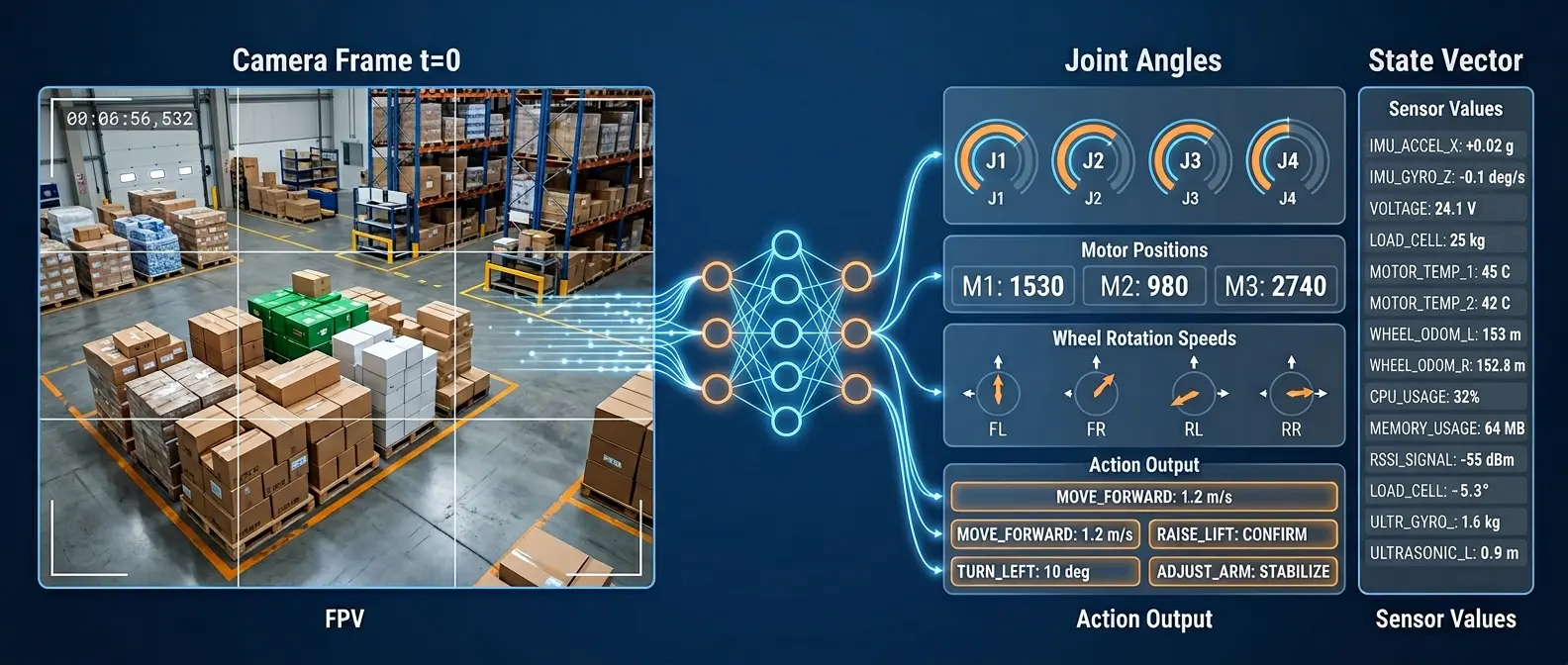 ロボットが学んでいるのは「世界の動画だけ」ではなく、1フレームごとのカメラ画像と、その瞬間のロボットの動きやセンサー値のセットであり、それを通じて「この見え方のときは、こう動くと得をする」という対応関係を覚えている。
ロボットが学んでいるのは「世界の動画だけ」ではなく、1フレームごとのカメラ画像と、その瞬間のロボットの動きやセンサー値のセットであり、それを通じて「この見え方のときは、こう動くと得をする」という対応関係を覚えている。
CosmosやOmniverseの話に進む前に、ロボットの学習データが実際にどういう形をしているかを一度はっきりさせておくと、全体のイメージがぐっとクリアになります。
ロボットが1ステップで受け取る情報
強化学習や模倣学習では、ロボットの経験を「一瞬ごとの教材」に区切って考えます。
倉庫ロボットであれば、1ステップごとに、カメラの1フレーム画像、その瞬間のロボットの状態、ロボットが出した行動、そして結果としての報酬がセットで記録されます。
カメラの1フレーム画像は、フロントカメラや360度カメラなどのRGB画像であり、場合によっては深度画像が含まれます。ロボットの状態には、関節角度(サーボモータの位置)、関節速度や車輪の回転数、IMUや力センサーの値などが含まれます。
行動は、次の車輪速度や旋回角度、リフトの高さ、グリッパーの開閉量といった操作量です。これらが時間方向に並んだものが、ロボットの学習に使われる一本のエピソード、つまり教材になります。
「動画」と「ロボットの動作ログ」の関係
一般には「ロボットは動画で学ぶ」と言われがちですが、実際には動画だけでは足りません。 確かに「動画を見て学ぶ」と言ってしまいますが、ロボットにとっては「その映像を見た瞬間に、どの筋肉(モーター)をどう動かしたか」という記憶の同期こそが命です。
実際の学習では、各フレーム画像が画像認識用のニューラルネットワークに入力されて特徴量ベクトルに変換されます。同時に、関節角度や速度、センサー値も数値ベクトルとして扱われます。
そしてこれらが結合されて「今の世界の状態」を表す1本の数値ベクトルとなり、そのベクトルから「どの行動を選ぶか」を出すのがロボットの頭脳、つまりポリシーネットワークとなります。
Cosmosが学習データに与えるインパクト
Cosmosは、この「世界の見え方」と「物の動き方」を学んだ世界モデルです。
倉庫ロボットの文脈では、Isaac Simや現実の倉庫から集めた映像とログをもとに、夜間や雨の日、霧が出ているなど条件の違う倉庫映像、人やフォークリフトの動きがよりランダムで混雑している危ない状況の映像、最近では数秒先の未来のフレームを予測して延長した長いシーンまでを生成することで学習を後押しします。
これによって、現実の倉庫ではめったに起きないレアケースや、取りづらい条件下でのデータを安全に大量に用意できるようになります。ロボットの強化学習では、こうした多様な状況下での経験が増えるほど、現実では遭遇しにくい条件への耐性を事前に高めやすくなる と期待されています。
倉庫ロボット開発の「実務フロー」として見る
現場の開発フローとして見ると、「仮想倉庫でデータを撮る→Cosmosで世界バリエーションを増やす→強化学習でロボットの頭脳を鍛える→OSMOでこのループを自動化する」という流れが中核になる。
ここからは、倉庫ロボットの具体的なストーリーに落として、Cosmos、Omniverse、Isaac Sim、OSMOがどう連携するのかを順番に追いかけてみます。
頭の中で「倉庫の中を走り回る自律搬送ロボット」をイメージしながら読んでください。
倉庫ロボット開発ループの4ステップ
倉庫ロボットのPhysical AI開発を、現場寄りに分解すると次の四つのステップに整理できます。まず、Omniverseで倉庫のデジタルツインを作り、次にIsaac Simでロボット目線のデータを集めます。そのうえでCosmosを使って条件違い・未来予測の映像を増やし、最後に強化学習でロボットの頭脳を更新しながら、OSMOでこの一連の流れを自動化します。
ステップ1:Omniverseで倉庫のデジタルツインを用意する
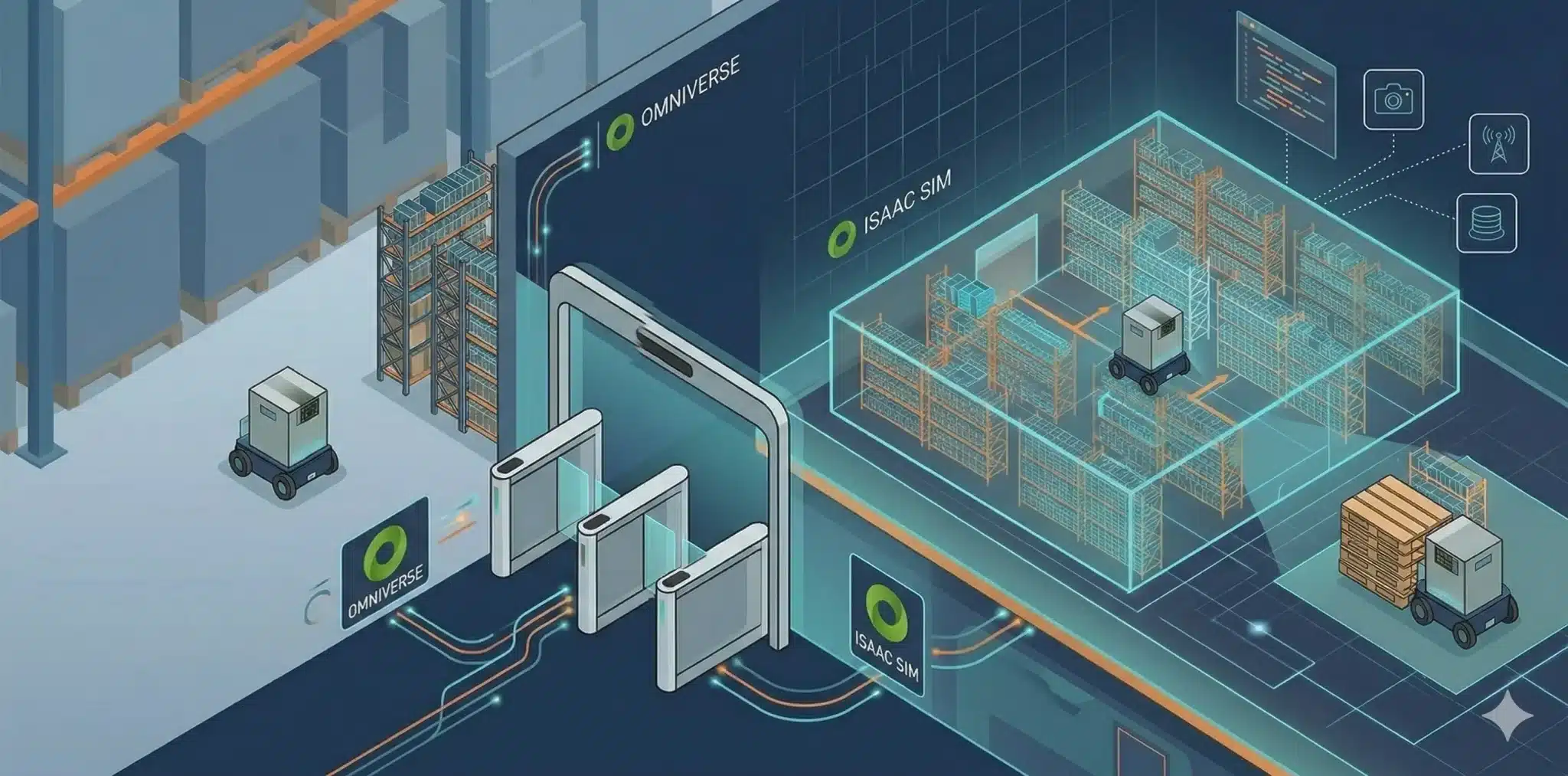
最初に行うのは、現実の倉庫を仮想世界にコピーすることです。
ここで活躍するのがOmniverseです。CADデータやBIM、点群データなどから棚や通路、パレットの配置を取り込み、仮想倉庫のレイアウトを作ります。
ロボット本体についても、OpenUSDという共通設計図の形で記述します。現場の倉庫に近いけれど、ぶつかっても誰も怪我をしない安全な倉庫が、仮想空間に立ち上がるわけです。
※)BIM(Building Information Modeling)とは建物を3Dモデル化し属性情報も一元管理する、建築の設計・施工・維持管理用の情報モデル手法

ステップ2:Isaac Simでロボットのログを取る
デジタルツインができたら、その中でロボットを走らせてデータを集めます。
ここではIsaac SimやIsaac Labが活躍します。ロボットが走る間、カメラ映像と、車輪の速度やロボット本体の姿勢、関節角度、トルクなどもログとして記録します。
これが、後でCosmosに渡すための元ネタ映像と動作ログになります。
ステップ3:Cosmosで世界のバリエーションを増やす
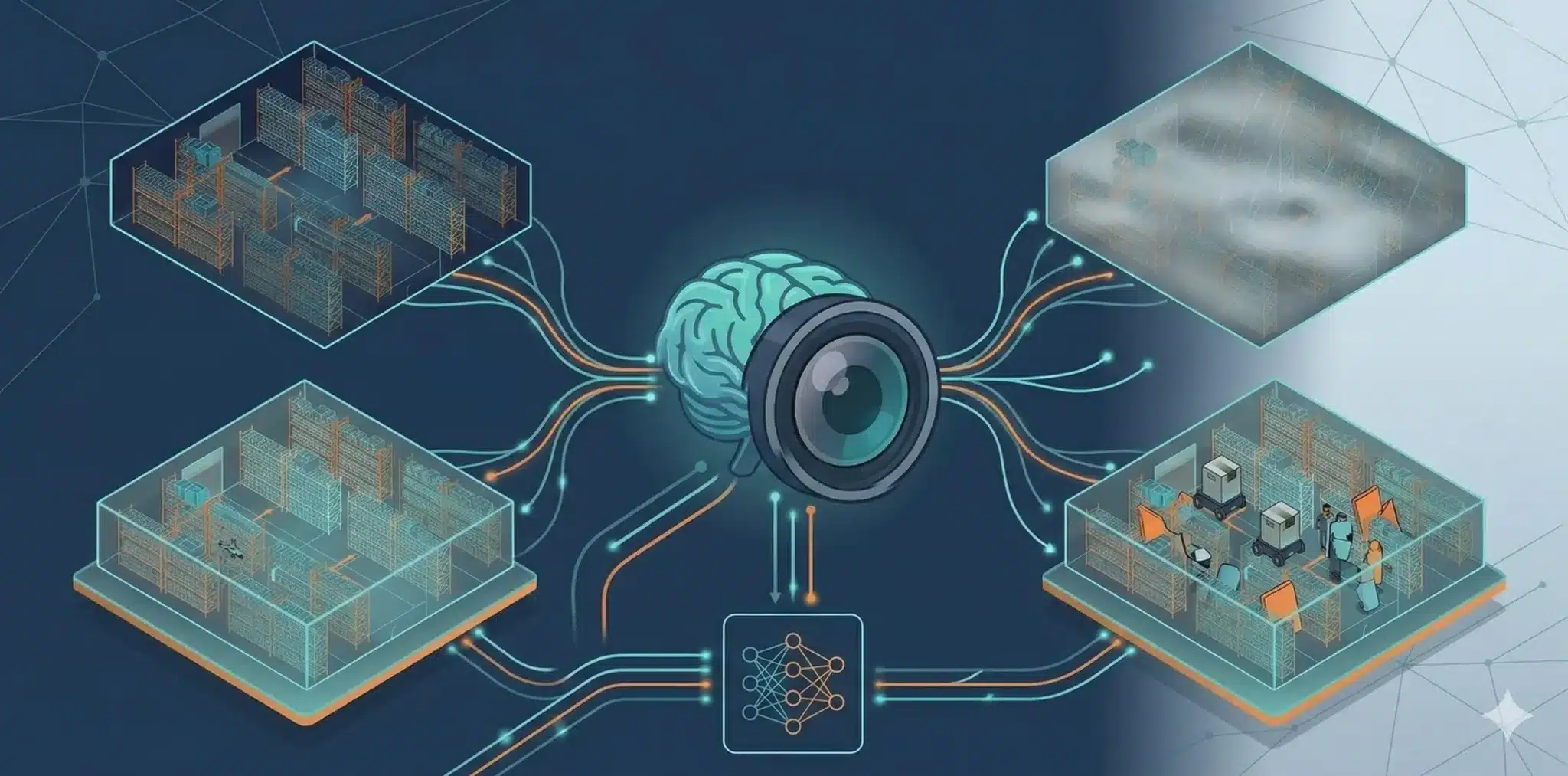
次に、この元ネタ映像とログをCosmosに渡して、世界のバリエーションを増やします。
最新のCosmos Transferなどを使えば、元映像をベースに、夜間や悪天候、混雑状況などの条件を自由に変更した映像を生成できます。
ここで重要なのは、Cosmosが作るのが単なる映像ではないという点です。物理現象を推論するCosmos Reasonなどの機能により、元の動作ログと矛盾しない形で、未来の展開や条件違いの世界を増やしていきます。その結果、現実には撮れない危ないシーンも安全に再現しやすくなります。
ステップ4:強化学習とOSMOで「試す→学ぶ→また試す」を回す
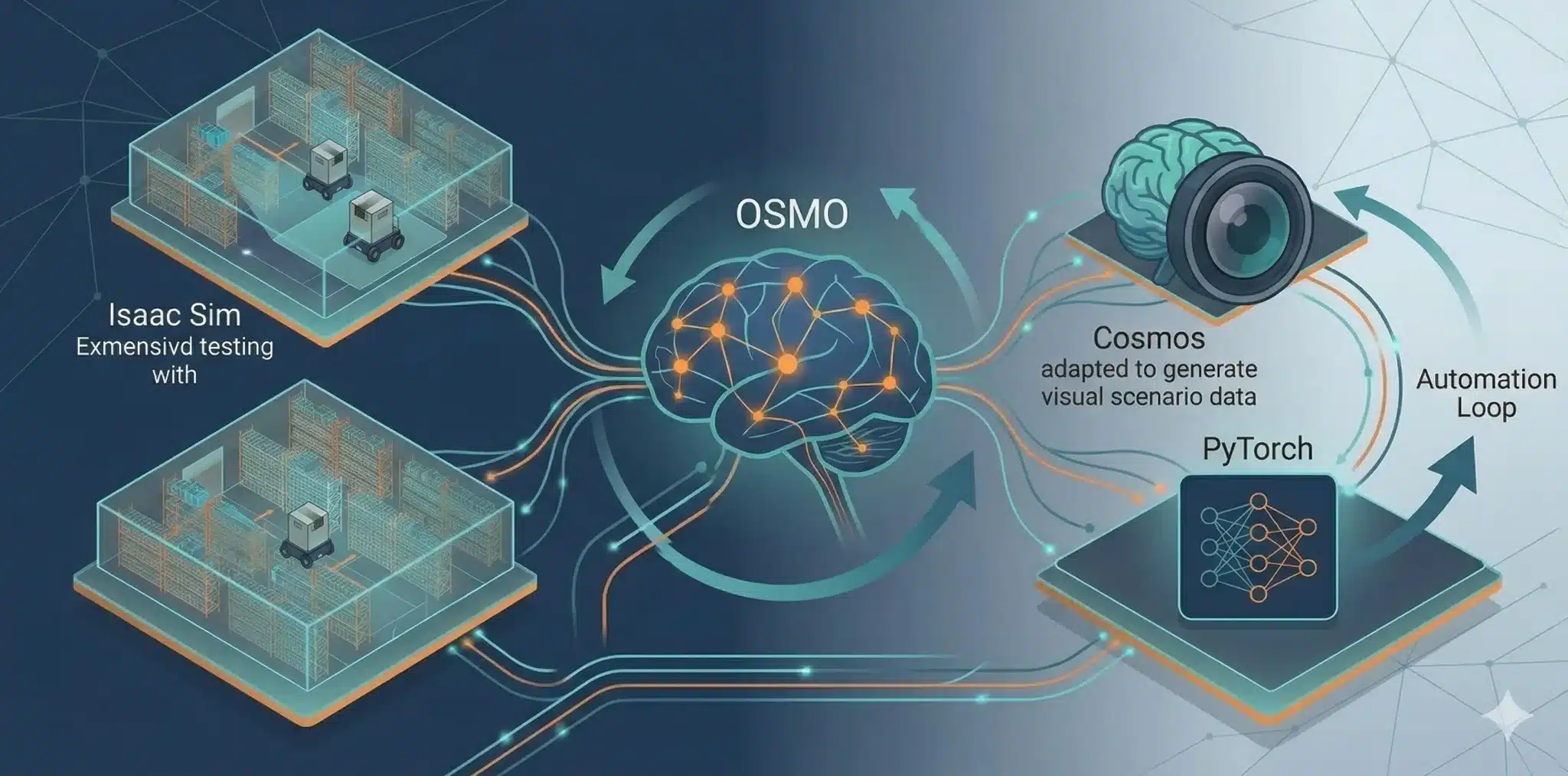
Cosmosで増やした映像とログを使って、ロボットの頭脳、つまりポリシーネットワークを強化学習で鍛えます。学習用のGPUクラスタ上で、カメラ画像とロボットの状態を入力に「どの行動を取ると報酬が高くなるか」を学習させます。
この一連の巨大なサイクルを、大規模かつ自動で繋ぎ止めてくれるのがOSMO(NVIDIAが提供するクラウドネイティブなオーケストレーションフレームワーク)です。
OSMOは、これらを自動で回す「神経系」として機能します。
2026年3月16日に発表された「Physical AI Data Factory Blueprint(Physical AI Factory Blueprint)」では、Cosmos Curator / Transfer / Evaluatorと並び、OSMOがデータ生成〜拡張〜評価〜学習を束ねるオーケストレーション層として中心的な役割を果たします。
具体的には、Isaac Simでのシミュレーション、Cosmosによるデータ拡張、そしてPyTorchなどを用いた学習ジョブをYAMLファイル一本で定義し、クラウドやオンプレミスのGPUリソースを最適に割り当てて自動実行します。
これにより、開発者は「どのサーバーでどのジョブを動かすか」という管理から解放され、「仮想倉庫で試す→世界条件を増やす→学習する→また試す」という改善ループそのものの設計に没頭できるようになりました。ここで重要なのは、単発のデモではなく、改善が止まらない閉ループ(データ工場)をどう構築するかです。
根拠・出典の整理
本記事は、Cosmos・Omniverse・Isaac Sim・OSMOの役割を、最新のPhysical AI Data Factoryの概念で再整理した解説である。
CosmosやOmniverse、Isaac Sim、OSMOに関する基本的な位置づけや機能は、NVIDIAの公式サイトや、2026年3月のGTCでの発表に基づいています。
特に、世界モデルとしてのCosmos(Predict/Reason/Transfer)や、オーケストレーターとしてのOSMOの活用については、最新の技術リファレンスを踏まえています。
ロボットの強化学習における観測と行動の扱い、シミュレーション環境との連携方法などは、Isaac Sim/Isaac Labのドキュメントをベースにしています。一方で、「倉庫ロボットの具体的な開発ループ」「神経系・オーケストレーターといった比喩」「データの流れを図解した解釈」は、Arpable編集部による独自整理です。
まとめ
ロボットは「世界の動画だけ」で学んでいるのではなく、1フレームごとの映像と動作・センサー値のログを通じて、世界の見え方と自分の行動の関係を少しずつ身体化していきます。
倉庫ロボットの学習の裏側を覗いてみると、Cosmos、Omniverse、Isaac Sim、OSMOはそれぞれがはっきりした役割を持っていることが分かります。Omniverseは倉庫とロボットを動かす舞台、Isaac Simはその舞台の上でロボットをシミュレーションする専用ステージ、Cosmosはその世界の見え方と動き方を学び、条件違いの映像や未来予測を生み出す世界モデルです。そして、これらを一本のラインとして繋ぎ、24時間365日の自動学習を実現する指揮者がOSMOです。
ロボットが実際に学んでいるのは、カメラ映像の連続と、フレームごとのロボットの状態と行動のセットです。Cosmosがそこに条件違いの映像や物理推論に基づいたシーンを供給することで、倉庫ロボットは現実だけでは到底集められない経験を、仮想世界の中で安全に積むことができます。その結果として、より安全で頼れるロボットが、現場に送り出されていきます。
本質は、どれか一つのツールが魔法のように賢いのではなく、ロボットに「見たもの」と「そのとき自分がどう動いたか」を何度も対応づけて学ばせることにあります。
現実のログだけでは足りない場面をシミュレーションで補い、条件違いの映像や動作を大量に与えながら、失敗も成功も次の学習に変えていく──その反復こそが、ロボットを少しずつ賢くします。
この記事で本当に押さえてほしいのは、華やかな製品名の違いではありません。ロボットは、世界を一度で理解するのではなく、映像と行動の対応を何度も学び直しながら、少しずつ「動ける知能」になっていく──その学習の仕組みこそが核心です。
専門用語まとめ
- OpenUSD
- 倉庫やロボット、センサー配置などを共通の形で記述し、複数のツールで共有しやすくするオープンな基盤。
- Cosmos
- 映像生成だけでなく物理推論(Reason)や未来予測(Predict)を統合した世界モデル。
- OSMO
- シミュレーション、データ拡張、学習、評価といった多段階のAI開発ワークフローをGPUクラスタ上で自動管理する基盤。
- Physical AI Data Factory
- 2026年に提唱された、AIロボットの学習データを自動で生成・拡張・学習し続ける仕組み全体を指すリファレンスアーキテクチャ。
よくある質問(FAQ)
Q1.
ロボットの学習データは、本当に「動画」だけではないのですか?
A1. はい。「動画(視覚)」と「その瞬間にロボットがどう動いたか(動作ログ)」がセットでなければ、AIは行動の結果を学べません。
Q2.
OSMOを使わなくても、CosmosとOmniverseで開発はできますか?
A2. 小規模な実験なら可能ですが、何千回もの反復学習を24時間体制で回すなら、OSMOによる自動化が不可欠です。
Q3.
Dynamoとは何が違うのですか?
A3. Dynamoは主に「大規模モデル推論の配信・スケーリング」を最適化する基盤で、OSMOは「シミュレーションやCosmosによるデータ生成〜学習〜評価」といった開発ワークフローの自動化を担います。
参考サイト・出典
あわせて読みたい
更新履歴
- 2026年1月12日:初稿公開
- 2026年3月18日:GTC 2026での「OSMO」「Physical AI Data Factory Blueprint」発表に基づき全面更新