


※本記事は継続的に最新情報へアップデートします。
AI-PCは本当に必要か?2026年市場55%超え直前に押さえるべきハード・SLM・価格・導入戦略の完全ガイド
「次のPC更新でAI-PCにすべきか」「企業でAI-PCをいつ・どう導入すべきか」──この2つの問いに答えるため、本記事ではNPUアーキテクチャの実態、ローカルで動くSLMの選び方、Intel/AMD/Qualcomm/Appleの戦略比較、日本市場の価格動向、そして業種・用途別の導入判断マトリクスまでを一本で網羅します。2026年にはPC市場の過半数がAI-PCへ切り替わる転換点を目前に控え、今動くべき理由と、まだ待てる理由の両面から整理します。
✅ この記事の結論
- 今すぐ優先検討すべき3条件:Windows 10サポート終了後も未更新端末が残る・機密データのクラウド送信に制約がある・クラウドAIサブスクのTCO最適化を急ぎたい――このいずれかに該当する組織は、2026〜2028年の次回更改サイクルでAI-PCを標準機候補として評価すべき
- 選択の軸はNPU性能とメモリ帯域:Copilot+ PC認定(40 TOPS以上・16GB以上・256GB以上)を最低ラインとし、業種・用途・既存IT環境でIntel/AMD/Qualcomm/Appleから選ぶ
- 「待ち」も合理的なケース:購入後2年未満・AI活用計画が未定・Intel Core Ultra Series 3(Panther Lake)搭載機の市場評価を見極めたい、またはAMD Ryzen AI 400シリーズなど次世代機の選択肢を比較したい場合は、拙速に全社更新せず段階導入や次回更改までの見送りも十分合理的
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
▶ 詳細はこちら
AI-PCとは何か:NPUが変えるコンピューティングの前提

AI-PCとは、CPU・GPUに加えAI専用プロセッサ「NPU」を統合したPCであり、「クラウドに頼らず手元でAIを動かす」ことを前提に設計されたコンピュータの新標準だ。
AI-PCが従来のPCと根本的に異なるのは「知能」の所在です。これまでAIはクラウド上の巨大なデータセンターに存在していましたが、AI-PCはその知能を個人の手元デバイスへローカル化し、オフラインでも・プライバシーを守りながら・低遅延でAIを使える環境を実現します。パーソナルコンピュータの進化史において、2020年代の「AI推論」は新たな爆発的需要のひとつであり、今まさにその転換点が訪れています。
NPUとは何か:AI専用処理装置の役割
NPU(Neural Processing Unit)は、ディープラーニングの中核演算である行列計算に特化したプロセッサです。CPUは汎用的な処理を、GPUは並列処理を得意としますが、NPUはAI推論を桁違いに低消費電力で担う点が特徴です。
ビデオ会議中のノイズ除去や背景ぼかしをCPUで処理すればファンが高速回転しバッテリが急減します。同じ処理をNPUに任せると数ワット以下で完了し、ユーザーは電力を気にせずAI機能を常時有効にできます。
「40 TOPS・16GB・256GB」:Copilot+ PCが定めたゲート
MicrosoftはCopilot+ PCの条件として「NPU 40 TOPS以上」「RAM 16GB以上」「256GB以上のストレージ」を求めており、公式ストアのラインアップもこの仕様に揃えられています。これにより8GBモデルは事実上「非AI PC」へ分類され、量販店の棚でも徐々に姿を消しています。この要件は業界標準として定着しており、今後のデバイス選定の最低ラインです。
ハードウェア構成パターンの詳細比較

AI-PCの心臓部はSoCであり、Intel・AMD・Qualcomm・Appleの4陣営がそれぞれ異なる設計思想で性能・省電力・互換性のバランスを競っている。
主要プロセッサの構成比較
| プロセッサ系列 | アーキテクチャ | NPU性能(TOPS) | 標準/最大メモリ | メモリ方式 |
|---|---|---|---|---|
| Intel Core Ultra(Series 2/3) | x86 Hybrid | 47〜50+ | 16GB/64GB+ | ユニファイド/Arc GPU共有 |
| AMD Ryzen AI(300/400) | x86 | 50〜60(HX最大60 TOPS、非HX 50 TOPS) | 16GB/64GB+ | ユニファイド/Radeon内蔵共有 |
| Qualcomm Snapdragon X Elite/Plus | ARM | 45 | 16GB/64GB | 完全ユニファイドメモリ |
| Qualcomm Snapdragon X2 Elite/X2 Plus | ARM | 80級 | 16GB/64GB | 完全ユニファイドメモリ |
| Apple M5/Pro/Max | ARM | 40+(Neural Engine) | 16GB/128GB+ | 高帯域ユニファイドメモリ |
| ※ 各社公開仕様・Arpable調査(2026年3月時点) | ||||
Intel Core Ultra:Windows互換性とvPro管理の強み
Intelの戦略的軸足は、既存のWindowsソフトウェアエコシステムとの完全互換性を維持しながらNPU性能を40 TOPS超へ引き上げることにあります。
Lunar Lake(Core Ultra 200Vシリーズ)ではメモリをチップパッケージ上に直接搭載する設計を採用し、データ移動の遅延を最小化しています。
法人向けにはvProプラットフォームとの統合を売りに、IT管理部門への親和性を強調しています。Copilot+ PC対応機種の中でも最も広いラインアップを誇ります。
AMD Ryzen AI:クリエイティブとハイパフォーマンスを両立
AMDはマルチコア性能と強力な内蔵グラフィックス(RDNA 3.5)を武器に、動画編集・3DCG・機械学習ワークロードを持つユーザー層を取り込んでいます。
Ryzen AI 400シリーズは最大60 TOPSのNPUを搭載(非HXモデルは50 TOPS)。x86互換性を保ちながら高いAI性能を求める法人ユーザーへの訴求力があります。
Qualcomm Snapdragon X:長時間バッテリとモバイル特化
スマートフォン向けチップで磨かれたARMアーキテクチャの省電力性が最大の武器です。第1世代のSnapdragon X Elite/Plusは45 TOPSながら20時間超のバッテリ駆動を実現し、後継のX2シリーズは80 TOPS級へと引き上げられました。
常時接続LTE/5G対応モデルも充実しており、出張・フィールドワーク中心のプロフェッショナルに対し他社が追いつけていない体験を提供しています。ただしx86アプリのエミュレーション性能に依然課題があり、導入前の互換性確認は必須です。
Apple M5:高帯域ユニファイドメモリの圧倒的優位
2026年3月時点の現行MacBook ProはM5 Pro/M5 Max、MacBook AirはM5へ更新済みです。Apple SiliconはCPU・GPU・Neural Engineが同一ダイに統合され、メモリ帯域幅は他プラットフォームを大きく上回ります。
これは量子化などの最適化を前提とした70Bクラスの大規模モデルをローカルで扱う際に、他アーキテクチャと比べて明確な優位性をもたらします。
エンタープライズ管理ツールとの統合に追加コストが発生するケースはあるものの、クリエイティブ用途とデータサイエンスにおける性能面の強みは変わりません。
メモリ帯域が推論速度を左右する理由
ローカルでSLMを動かすには、モデルの重みデータをメモリ上に常駐させる必要があります。容量だけでなく帯域幅(100GB/s超が一般的)が推論スループットを直接決定するため、AI-PCではLPDDR5xが事実上の標準です。
ユニファイドメモリアーキテクチャの採用により、プロセッサ間のデータコピーが不要になり推論速度が大幅に向上します。
ローカルで動くSLMの実態:小さいモデルがなぜ「使える」のか

AI-PCで動くのはSLM(Small Language Model:端末上で動く小型AI)だ。
ローカル運用で効いてくるのは「このPCのVRAMで動くか」と「一度に読めるトークン数」であり、実務ではパラメータ数よりVRAMとコンテキスト窓が制約となる。
合成データ・蒸留・高密度学習の3手法により、14B以下のモデルがビジネス実務で十分な精度を発揮する。
主要SLMの特性比較
| モデル名 | パラメータ数 | 学習データ量 | コンテキスト窓 | 特徴・用途適性 |
|---|---|---|---|---|
| Phi-4(Microsoft) | 14B | 約9.8Tトークン | 16K | 科学・数学推論で上位LLMに匹敵。ビジネス文書処理向き |
| Phi-4 Mini | 3.8B | 高品質合成データ中心 | 128K | 3GB VRAMで動作可能。低スペック機・軽量タスクに最適 |
| Llama 3.2(Meta) | 1B/3B | 数兆トークン規模 | 128K | エッジ・モバイル向け最適化。オープンライセンスで改変容易 |
| Gemma 3(Google) | 1B〜27B | 蒸留学習 | 128K | ネイティブマルチモーダル(画像理解)対応。資料解析に強み |
| Qwen 3〔SLM向け小型モデル〕(Alibaba) | 1.7B/4B | 約36Tトークン | 128K | 119言語対応。グローバル展開・多言語業務に最適 |
| Mistral 7B | 7B | 非公開 | 32K | 効率性と精度のバランスに優れたベースモデル。RAG構築の土台に |
| ※ 各モデル公式ドキュメント・Arpable調査(2026年3月時点) | ||||
SLMが「使える」3つの技術的背景
①合成データ(Synthetic Data)による学習:
MicrosoftのPhiシリーズは、強力なモデルが生成した「教科書的テキスト」を学習データとして活用。パラメータ数が少なくても高度な推論が可能になる、従来とは根本的に異なるアプローチです。
②知識の蒸留(Distillation):
巨大な「教師モデル」の知識を小さな「生徒モデル」に継承させる手法。
GemmaシリーズはGeminiファミリーからの蒸留により、小型サイズでマルチモーダルな理解力を保持しています。
③高密度トークン学習:
Qwen 3は4Bモデルに36兆トークンという非常に多いデータを段階的に学習させることで、「これ以上増やしても伸びない」という飽和点ぎりぎりまで性能を引き上げ、小規模モデルでも本来の限界に近い精度を発揮できるようにしています。
主要プラットフォーム4陣営+NVIDIAの戦略:何を狙い、何で差別化しているか
AI-PC市場はCPU覇者(Intel/AMD)・モバイル覇者(Qualcomm)・エコシステム覇者(Apple)・AIデータセンター覇者(NVIDIA)が激突する過去数十年で最も競争の激しい戦場だ。各社の戦略を読むことが最適なプラットフォーム選択に直結する。
NVIDIA:垂直統合とCUDAエコシステムの堀
勝負軸:垂直統合によるシステム全体の推論効率最大化
- ARMベースCPU「Vera」とBlackwell GPUを「エクストリーム・コデザイン」で統合し、PC・ネットワーク両面に優位性を拡張
- CUDAエコシステムという強固な堀が開発者の移行コストを高め、優位を持続させる
Qualcomm:「電力効率(TOPS/Watt)」という勝負軸
勝負軸:推論市場での電力効率トップを狙う
- NVIDIAが支配する学習市場ではなく、急拡大する推論市場でのコスト優位性を狙う。Hexagon NPUのデータセンター転用構想も進行中
- ARMシェア拡大はAppleが先鞭をつけた流れを追う形だが、Qualcommはエンタープライズ向けWindowsという異なる土俵で差別化を図る
Intel:エコシステム防衛とコスト競争力
勝負の軸:既存IT資産との親和性を保ったままAIを導入できる“低摩擦”路線
- 「既存のITインフラを変えずにAI機能を付加できる」という提案が大企業の情シス部門に刺さりやすい
- データセンター向けGaudi推論チップをNVIDIA H100より低価格で提供し、法人の裾野を押さえる
AMD:ハイエンド性能とデータセンター代替
勝負軸:PC・DC両面でのパフォーマンス追求
- Ryzen AI Maxでワークステーション級性能をノートPCで実現。内蔵GPUの性能が外付けGPUに迫るモデルも登場
- MI300シリーズでデータセンター市場においてNVIDIA代替を狙う
実務での見方:AI-PCと通常PCのアーキテクチャ的相違

AI-PCの本質はNPUの「有無」ではなく、「常時オンAI」を低電力で実現するシステム全体の設計思想の転換にある。
構成要素の比較
| 構成要素 | 通常のPC | AI-PC | 変化のメカニズム |
|---|---|---|---|
| 主要プロセッサ | CPU+(GPU) | CPU+GPU+NPU | NPUがAI専用計算(行列演算)を低電力で担う |
| NPU性能 | なし〜 10 TOPS未満 |
40〜80+ TOPS | Copilot+ PC要件。ローカルSLM実行に必須 |
| メインメモリ | 8〜16GB(DDR4/5) | 16〜32GB+(LPDDR5x) | モデルの重みをメモリ常駐させるため容量増大 |
| メモリ帯域 | 標準的 (〜50GB/s程度) |
100GB/s超が一般的 | 推論時のデータ転送ボトルネックを解消 |
| バッテリ駆動 | CPU/GPU負荷で 急減 |
NPU活用で長寿命化 | ビデオ会議の背景ぼかし等をNPUが低電力処理 |
| ※ Arpable調査・各社公開仕様(2026年3月時点) | |||
導入判断基準:業種・用途別マトリクス
判断の軸は「セキュリティ制約」「モビリティ」「クリエイティブ負荷」「既存IT環境」の4つです。
| 業種/用途 | 優先プラットフォーム | 理由 | 注意点 |
|---|---|---|---|
| 金融・医療・法務(機密データ重視) | Intel Core Ultra(vPro) | 既存MDM・セキュリティ基盤との親和性。ローカル推論でデータが外部に出ない | Qualcomm ARMは一部業務ソフトの互換性確認が必要 |
| 出張・フィールドワーク中心 | Qualcomm Snapdragon X系 |
20時間超バッテリ。常時接続LTE/5G対応モデルあり | x86エミュレーションのパフォーマンス低下リスク |
| 動画編集・3DCG・クリエイティブ | Apple M5 Pro/Max または AMD Ryzen AI Max |
高帯域ユニファイドメモリ+強力な内蔵GPU。大型モデルのローカル実行にも余裕 | Appleはエンタープライズ管理ツール統合に追加コストが発生することも |
| データサイエンス・機械学習 | AMD Ryzen AI Max または Apple M5 Max |
96〜128GBユニファイドメモリで量子化前提の70B規模モデルのローカル実行が可能 | NVIDIA CUDAエコシステムが必須なら外付けGPUを別途検討 |
| 一般ビジネス(Office中心) | Intel Core Ultra Series 2/3 または AMD Ryzen AI 300/400 |
Copilot+ PC認定を最低コストで満たす。既存ソフトとの完全互換 | 16GB以上・40 TOPS以上・256GB以上を必ず確認。8GBモデルは対象外 |
| グローバル展開・多言語業務 | Qualcomm Snapdragon X系 または AMD Ryzen AI |
Qwen 3(119言語)などの多言語SLMをローカル実行可能 | 日本語特化モデルの選択肢はまだ限られる(2026年3月時点) |
| ※ Arpable独自調査・各社公開資料(2026年3月時点) | |||
よくある失敗:AI-PC導入で陥りがちなパターン
失敗①:Qualcomm ARMへの一括移行で業務ソフトが動かなくなる
Snapdragon X系は省電力・長時間駆動に優れますが、x86専用の業務ソフト(特に古いERPや計測機器ドライバ)が動作しないケースがあります。パイロット50〜100台で互換性を検証してから全社展開するのが鉄則です。
失敗②:クラウドAIサブスクを全廃してローカル完結を目指す
ローカルSLMが得意なのは定型・軽量タスクです。複雑なマルチステップ推論や最新情報が必要な調査はクラウドAIが依然として優位です。ローカルとクラウドのハイブリッド運用が最適解であり、コスト削減はサブスク全廃ではなく「不要なシートの削減」で実現します。
価格動向:日本市場の現状と2026年以降の見通し

AI-PCは現在15〜42万円のプレミアム層を形成しているが、2026年はDRAM・NAND価格の上昇でPC価格全体に上昇圧力がかかっており、「今が最後の適正価格窓」になる可能性がある。
現在の市場価格帯(日本市場)
ハイエンド(プロフェッショナル・ミッションクリティカル向け):30万円以上
- VAIO Pro PK / PJ:35〜42万円クラス
- パナソニック レッツノート(CF-FC6クラス):36〜40万円前後
- Apple MacBook Pro(M5 Pro / Max):30万円以上
メインストリーム(一般ビジネス・個人向け):15〜28万円
- VAIO Pro PK(エントリー構成):25万円前後〜
- HP OmniBook X(Snapdragon搭載):18〜25万円帯
- Dell XPS / Lenovo Yoga AIモデル:15〜25万円帯
エントリー(2026年以降に急拡大予想):12〜15万円帯
2026年以降、各ベンダーが1,200ドル(約18万円)以下のAI-PCモデルを拡充する計画を持っており、エントリー層への普及が本格化します。
2026年の「価格上昇」リスクと逆説的な購入好機
2026年はDRAM・NANDの価格上昇でPC市場全体に価格上昇圧力が強まっています。
IDCは平均販売価格の上昇を見込み、業界報道でも一部OEMの価格改定が伝えられており、調達タイミングには注意が必要です。
500ドル以下のエントリーPCカテゴリが事実上消滅し、1,000ドル前後の「AI-PC」へ市場が集約される構図も見えてきています。2025年後半から2026年前半は「AI-PC同等スペックを現行価格で調達できる最後の窓」になる可能性があり、更新計画のある情シス担当者にとってこの時間軸は無視できません。
企業における導入実態:ロット購入・TCO・日本の先行事例

企業導入の最大の動機はセキュリティとTCO最適化であり、特に金融・医療・製造業でのローカル推論ニーズが強い。グローバルでは2027年までに法人出荷の5割超〜6割がAI-PC化するとの予測があり、日本市場も中長期的に同様のトレンドを辿る可能性が高い。
導入動機の実態
セキュリティとプライバシーが最大の動機:
金融・医療・法務など規制の厳しい業界では、機密データをクラウドへ送信することへの法的リスクが高く、ローカル推論は「クラウド使用禁止」の制約をクリアしながらAIを活用できる唯一の現実的手段です。
TCO最適化:
Microsoft 365 Copilotを全社員分サブスク契約する場合と比較して、AI-PCへの一度のハードウェア投資で基本的な推論タスクをローカル処理できるため、3〜5年の保有期間でROIが逆転するシナリオが存在します。全社員へのCopilotライセンスが不要になる業務範囲を特定することが、導入前の重要な事前評価です。
Windows 10サポート終了による更新需要:
大手企業の約4〜5割が次回のデバイス更新でAI-PCを優先導入する計画を持つとされ、2025年10月のWindows 10 EOS(End of Support)が一つのトリガーでした。
日本市場においては2026年は過半数、2028年までに完全なパラダイムシフトが完了すると見るというのが一般的な見方のようです。
日本市場の先行事例
パナソニック コネクト:AIファースト組織のベンチマーク
自社向けAIアシスタント「ConnectAI」(クラウド型AIサービス)を国内全社員約11,600人へ展開し、2024年には年間240万回の利用と44.8万時間の業務削減を達成しています。AI活用を全社規模で定着させてきた同社は、企業におけるAI活用成熟度の高い先行事例として参照価値があります。
※ConnectAIはクラウド型の自社向けAIアシスタントサービスであり、AI-PCのローカル推論とは異なりますが、企業AI活用の成熟度モデルとして参考になる先行事例です。
製造業・フィールドサービス:
工場や現場でのマニュアル参照・トラブルシューティングにローカルSLMを活用する動きが出始めています。電波が届かない環境や製品図面などの機密情報をクラウドへ送れない場面での価値が高く、現場向けレッツノートやToughBookシリーズへのAI機能搭載に対する期待が高まっています。
IT部門が直面する実務課題:
現場から「AI-PCを入れたい」という声が上がる一方で、情シス担当者が直面するのは(1)既存MDMツール(Intune・JAMF等)との互換性、(2)リース期間中の端末入れ替えコスト、(3)UEFI・セキュアブート設定のARM対応、という実務課題です。Qualcomm ARMプラットフォームへの移行はドライバやグループポリシーの再設定が発生するケースがあり、パイロット導入から始めることを強く推奨します。
市場予測:2024〜2031年の出荷台数とシェア推移
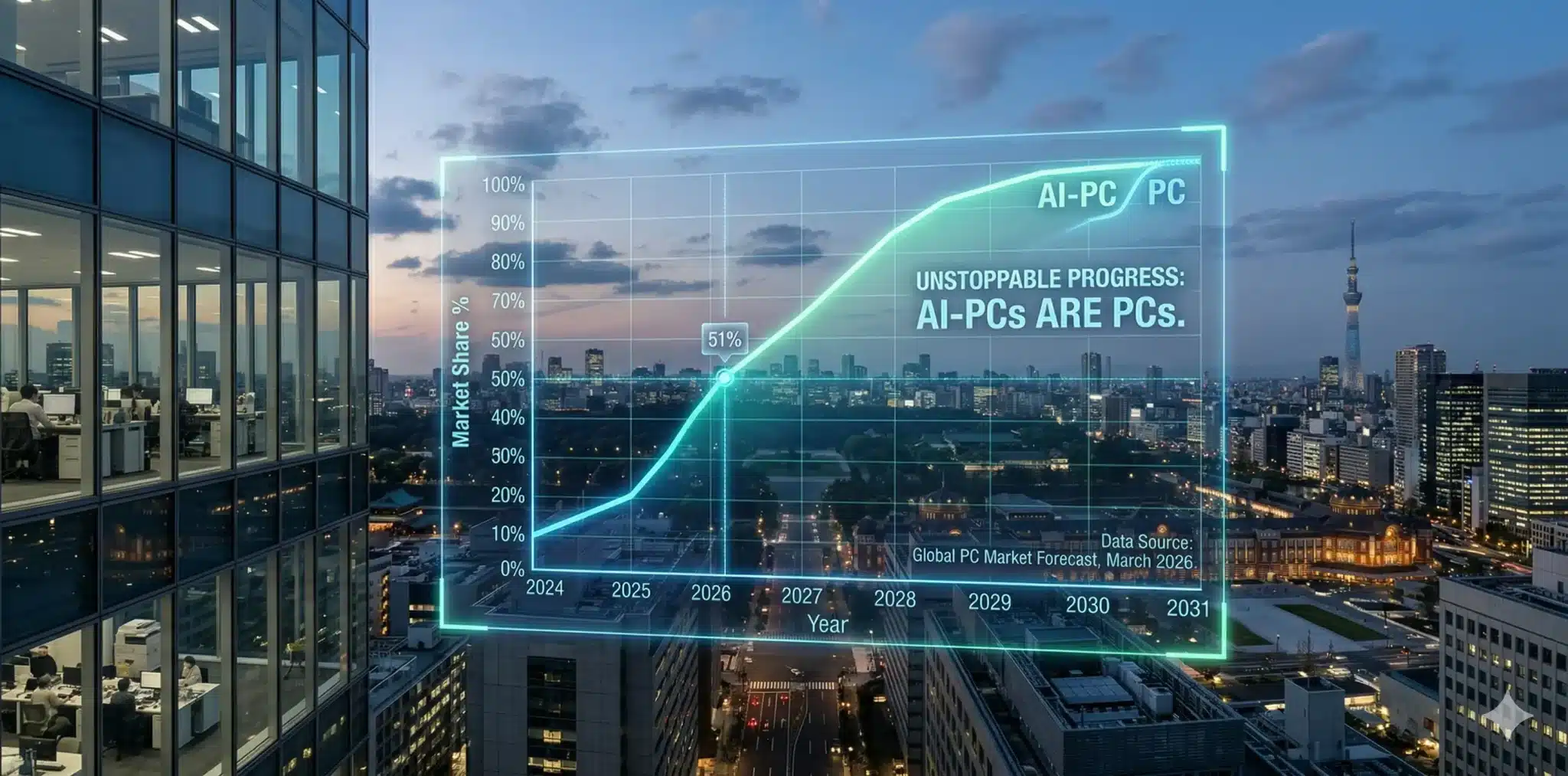
主要調査では2026年前後にAI-PCが市場の過半数を超えると予測されており、2029年頃には「AI-PC」と「PC」が事実上同義になるシナリオが有力だ。成長を牽引するのはエンタープライズセグメントだ。
| 年度 | 出荷台数(百万台) | 市場シェア | 動向・マイルストーン |
|---|---|---|---|
| 2024 | 約38〜44 | 15〜19% | 早期採用層と特定法人による試験導入 |
| 2025 | 約78〜100 | 30〜40% | 爆発的成長期。Windows 10更新需要がピーク |
| 2026 | 約140前後 | 50〜55% | 市場の過半数がAI-PCに。SLMの普及が進展 |
| 2027 | ― | 60%超 | 法人向け出荷の6割以上がAI-PC |
| 2029 | ― | ほぼ100% | 「AI-PC」という呼称が「PC」と同義に |
| 2031 | ― | ― | 市場規模は約2,604億ドルに到達との予測 |
| ※ Gartner・Canalys・Counterpoint等複数社の予測レンジを統合して記載(2026年3月時点) | |||
法人主導の成長:
2025年時点のAI-PC売上の約7割強はエンタープライズセグメントが占め、コンシューマー市場への波及はその後の構図です。
ARM vs x86の力学では、消費者市場でARMがシェアを拡大する一方、法人市場ではARMが緩やかに伸びつつもx86が依然として5割超〜7割程度のシェアを維持するシナリオが有力視されています。
ローカルAIとクラウドAIのハイブリッド運用:具体的なシナリオ

AI-PCの価値は「クラウドを不要にすること」ではなく「ローカルとクラウドを賢く使い分けること」で最大化される。有料LLMの利用制限という現実的な課題にも、SLMによるローカル実行が有効な対策となる。
LLMの「利用制限」問題:SLMが切り開く逃げ道
LLMを日常業務で多用しているユーザーが直面する現実的な障壁が「レートリミット(利用制限)」です。
要約・下書き・コード補完など定型タスクの処理がリミットに引っかかるたびに業務が止まる──この問題に対し、SLMのローカル実行は実質的な「逃げ道」になります。
重い推論はクラウドLLMへ、軽量な定型タスクはローカルSLMへ振り分けることで、クラウド側の利用枠を高度なタスクのために温存できます。
「利用制限によりAIが使えない時間帯を減少させる」という観点からも、ローカルSLMの導入価値は改めて注目されつつあります。
ローカルAIが担うべきタスク(速度・プライバシー・コスト優先)
- 会議録の自動要約:Zoom・Teamsの録音データをローカルSLMで即時要約。クラウド送信なし、15秒以内に完了。
- 社内文書の意味検索:「先月の役員プレゼンでの競合言及箇所」をPC内のあらゆるファイルからセマンティック検索できる、Recall型の機能です。
- メール・チャットの定型返信草案:受信メールの文脈を読んで返答候補を3パターン生成。オフラインでも動作。
- リアルタイム翻訳・文字起こし:ビデオ会議中の多言語キャプションをNPUが低電力処理。バッテリに影響なし。
- コード補完・ドキュメント生成:GitHubのサーバーへ接続せずにコードサジェストが動作。クラウドLLMの利用枠も温存できる。
クラウドAIが担うべきタスク(最新情報・高度推論・大規模知識)
- 市場調査・競合情報収集:最新のインターネット情報が必要な検索・リサーチはGPT-4クラス、Gemini 1.5 Proクラスへ。
- 複雑なマルチステップ推論:M&A検討の財務モデル構築、法律文書の深い解釈など、14Bクラスのローカルモデルでは精度が不安定なタスク。
- 高度なマルチモーダル活用:大量の図表・画像を含む資料の統合解析は、クラウド側の大規模マルチモーダルモデルが優位。
OSによる自動振り分けの進化
現時点ではユーザーが意識的に切り替える必要がありますが、Windows側のローカルAI基盤(Windows Studio Effectsやローカル推論ランタイムなど)を通じて、自動振り分けの仕組みが急速に整備されつつあります。
ユーザーがプロンプトを入力すると、OSがタスクの難易度を推定し、単純なものはNPUでローカル処理、高度な推論が必要と判断した場合のみバックグラウンドでクラウドへルーティングします。
「インターネット接続時はより賢く、オフラインでも基本支援は継続する」という、接続状況に応じて段階的に変化する体験です。
まとめ:AI-PCを巡る意思決定──3つの読者層へのNext Step

AI-PCへの移行は不可逆であり、問題は「いつ、どのように乗るか」だ。
NPUを統合しSLMをローカルで常時駆動するAI-PCは、PCをユーザーの文脈を理解し能動的に支援する自律的パートナーへと進化させる。
読者の立場別に、今すぐ取るべきアクションを示す。
【CxO・経営層向け Next Step】
- AI-PC移行をIT戦略ロードマップに明記する:Windows 10サポート終了(2025年10月)を自然なトリガーとして活用し、2025〜2026年の更新計画にAI-PC移行を組み込む。
- TCOの再試算を情シスに依頼する:クラウドAIサブスク(Copilot等)とローカル推論コストの比較試算を行う。3〜5年の保有期間で見たコスト差と、レートリミット回避による生産性向上効果を合わせて把握する。
【情報システム部門・IT管理者向け Next Step】
- パイロット導入から始める:50〜100台規模のパイロットでMDM(Intune等)との互換性を検証。特にQualcomm ARMを検討する場合は早期に互換テストを実施する。
- Copilot+ PC認定モデルリストを確認する:Microsoft公認の40 TOPS以上・16GB以上・256GB以上機種を基準にベンダー候補を絞る。
【エンジニア・プロダクトマネージャー向け Next Step】
- OllamaでローカルAPIサーバーを立てて接続してみる:Phi-4 MiniやLlama 3.2をOllamaでローカルAPIサーバーとして起動し、自作のVS Code拡張機能やCLIツールと接続してみる。NPUが「ただの飾り」から「推論バックエンド」に変わる瞬間を体感できます。
- NPUオフロードの最新動向を追う:Windows AI基盤・Qualcomm AI Hub・AMD ROCm等のNPU開発ツールの動向を定期的にウォッチする。
専門用語まとめ
- NPU(Neural Processing Unit)
- AI推論に特化したプロセッサ。CPUやGPUよりも低消費電力でAI演算を処理できる。Copilot+ PCの要件では40 TOPS以上が必須。
- TOPS(Tera Operations Per Second)
- 1秒あたりの演算回数を兆単位で表したAI性能指標。AI-PCでは40 TOPSがCopilot+ PCの認定下限値。
- SLM(Small Language Model)
- パラメータ数を10億〜140億程度に抑えた小規模言語モデル。クラウドの巨大LLMと異なり、PC上でローカル実行できる点が特徴。
- ユニファイドメモリアーキテクチャ
- CPU・GPU・NPUが同一のメモリプールを共有する設計。プロセッサ間のデータコピーが不要になり推論速度が大幅に向上する。Apple SiliconやQualcomm Snapdragon Xで採用。
- 量子化(Quantization)
- モデルの重みデータを32bitから8bit・4bit等の低精度形式に変換し、メモリ使用量と推論速度を改善する手法。70Bクラスのモデルを限られたメモリでローカル実行するために不可欠。
- ハイブリッドAI
- ローカル(NPU)での推論とクラウドでの推論を組み合わせて最適化するAI運用形態。速度・プライバシー・利用制限回避はローカル、高度推論・最新情報はクラウドに振り分ける。
よくある質問(FAQ)
Q1.
AI-PCと普通のPCの見分け方は?
A1.
「Copilot+ PC」ロゴ、または仕様表でNPU 40 TOPS以上・RAM 16GB以上・ストレージ256GB以上の3条件を確認してください。
- 量販店での「AI PC」表記はメーカー独自の表現であり、必ずしもCopilot+ PC認定ではない
- Microsoftの公式Copilot+ PC対応機種リストで確認するのが最確実
- 8GBモデルはローカルSLMを快適に動かせないため注意が必要
関連:AI-PCとは何か
Q2.
AI-PCでインターネットなしでAIは使えるか?
A2.
ローカルSLMを使う限り、インターネット接続なしでAI機能を利用できます。
- 文書の要約・メール下書き・コード補完などの定型タスクはオフラインで動作
- 最新情報の検索や高度なマルチステップ推論はクラウドAIが必要
- 製造業の工場内・機内・地下など電波の届かない環境でも基本的なAI支援が継続できる
Q3.
AIが搭載されたPCは個人情報や業務データが漏洩しないか?
A3.
ローカル推論はデータがPC外に出ないため、クラウドAIより高いプライバシー保護を実現できます。
- NPUで処理するローカルSLMはネットワーク通信を行わない
- ただし「Copilotボタン」などクラウドに接続する機能は別途管理が必要
- MDMポリシーでクラウドAI機能をOFF・ローカルのみに制限する設定が法人では推奨される
関連:企業における導入実態
Q4.
今すぐAI-PCを買うべきか、次世代チップを待つべきか?
A4.
Windows 10 EOS対応が急ぎでなければ、状況に応じて以下のように判断してください。
- 急ぎの場合:現行Copilot+ PC認定モデルは実用水準として十分
- 少し待てる場合:Panther Lake(Intel Core Ultra Series 3)はCES 2026で発売開始済み。ただしNPU性能は前世代Series 2と同等(約50 TOPS)のため、NPU目的での待ちとしては効果が限定的な点に注意
- さらに待てる場合:AMD Gorgon Point(Ryzen AI 400シリーズ・Strix Pointリフレッシュ)はQ2 2026予定で電力効率向上が見込まれる。なおZen 6ベースのMedusa APUは2027年以降の予定
- 2026年はPC価格上昇圧力が高まっているため、調達タイミングの見極めが重要
関連:価格動向
Q5.
法人でAI-PCを一括導入するとき、最初に何をすればよいか?
A5.
まず50〜100台規模のパイロット導入でMDM互換性と業務ソフトの動作確認を行い、その後全社展開の計画を立てるのが鉄則です。
- Intune・JAMF等のMDMツールとの互換性確認を最優先で実施
- Qualcomm ARMを選ぶ場合は特にx86業務ソフトの動作テストが必要
- ローカルSLMのデプロイ基盤(Windows AI基盤・Ollama等)の評価もパイロット期間中に並行して実施する
参考サイト・出典
一次情報
- Microsoft – Copilot+ PCs 公式ページ
- Intel – AI PC overview 公式ページ
- AMD – Ryzen AI 公式ページ
- Qualcomm – Snapdragon X Series 公式ページ
- Apple – MacBook Pro 公式ページ(M5 / M5 Pro / M5 Max)
二次情報・市場調査
あわせて読みたい
更新履歴
- 2026年3月27日:初版公開







