


※本記事は継続的に「最新情報にアップデート」を実施しています。
2026年のLLM競争は性能比較では終わらない|OpenAI・Google・Anthropic・Microsoft・Appleの陣営戦略を読む
「どのLLMが最も賢いのか」。以前は、その問いだけでも十分でした。ですが2026年の現場では、それだけでは判断できなくなっています。いま企業が本当に見るべきなのは、モデル単体の性能ではなく、どの陣営が安定供給・販路・規制対応まで含めて勝ち筋を持っているのかです。この記事では、主要LLM企業の戦略を5つの軸で整理し、経営者や投資家が何を見極めるべきかを分かりやすく解説します。
※)本記事は、主要LLMを「陣営戦略・供給力・販路・規制対応」の観点から読むスポーク記事です。機能・性能の比較はB、思想と使い分けはCをご参照ください。
B)LLMの性能比較:
【2025】主要5大LLMの性能比較|GPT-5・Gemini・Claude・Llama・Grok
C)LLMの思想と使い分け:
LLMと検索エンジンの未来|思想と使い分け戦略【2025】
✅ この記事の結論(TLDR)
- ポイント1:2026年のLLM競争は、性能競争だけでなく供給力・運用品質・販路の競争に移っています。
- ポイント2:OpenAI、Google、Anthropic、Microsoft、Appleは、同じ土俵で戦っているのではなく、それぞれ異なる勝ち筋を取り始めています。
- ポイント3:企業がLLMを選ぶとは、単なるモデル選びではなく、どの陣営に乗るかを選ぶことです。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
なぜ2026年は「性能比較」だけではLLMを選べなくなったのか
性能表だけでは、もうLLMは選べない時代です。
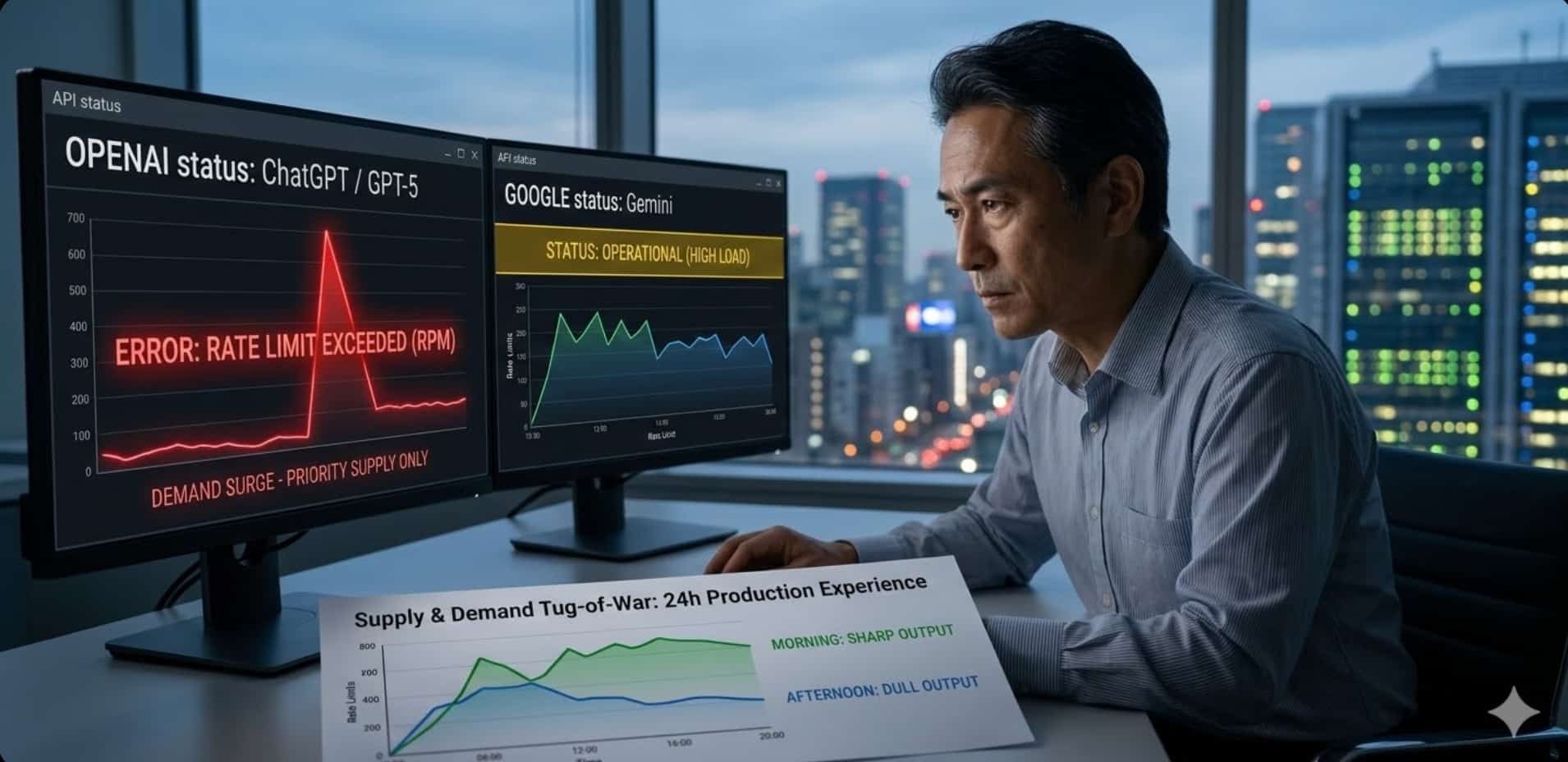
 2026年のLLM競争は、もはや単純な性能競争だけでは語れなくなってきています。もちろん、ベンチマークや推論能力の差は今でも重要です。ですが実際の企業導入や日常業務の現場では、それ以上に「どの陣営が安定して使えるのか」、「需要が集中したときにも品質や応答性を保てるのか」といった論点が前面に出ています。
2026年のLLM競争は、もはや単純な性能競争だけでは語れなくなってきています。もちろん、ベンチマークや推論能力の差は今でも重要です。ですが実際の企業導入や日常業務の現場では、それ以上に「どの陣営が安定して使えるのか」、「需要が集中したときにも品質や応答性を保てるのか」といった論点が前面に出ています。
その背景には、AIインフラそのものの制約があります。たとえばGoogleのGemini APIは、無料層から有料層までRPM、TPM、RPDといった利用上限を明示しており、これは単なる料金設計ではなく、システム性能と公平性を維持するための供給管理でもあります。つまり、2026年のAI市場ではモデル性能そのものだけでなく、供給余力をどう制御しているかが利用体験を左右するようになっています。
実際、OpenAIはChatGPTの性能低下やエラー発生をステータスページで公開しており、Anthropicも稼働状況を開示しています。GoogleもGemini APIのレート制限について、公平性の確保とシステム性能維持のためだと明記しています。つまり2026年の現実は、「最も賢いモデルはどれか」だけでなく、「最も賢い状態を安定して届けられるのは誰か」という競争へと移りつつあるのです。
筆者自身、1日の業務の大半をLLMと共に過ごしています。その中で強く感じるのは、同じモデルでも時間帯や需要状況によって、出力の切れ味や安定性の印象が変わることがあるという点です。朝は切れ味が良いと感じたモデルが、昼や夕方になると妙に鈍く感じられることがあります。Geminiが非常に賢いと感じた時期のあとに画像系需要が増え、相対的にChatGPTの出力が良く見えるようになった場面もありました。ところが今度は、ChatGPT側でも応答のばらつきを感じることがあります。
もちろん、これは厳密な統計実験で証明した結論ではありません。ただ、各社が障害情報、利用制限、モデル更新、提供基盤の見直しを絶えず続けている現状を見ると、こうした体感を単なる気のせいとして片づけるのも不自然です。供給と需要の綱引きは、すでにプロダクト体験そのものに現れていると見るべきでしょう。
いま企業が見るべき論点は「性能」ではなく「供給の設計思想」です
経営者や投資家がLLMを評価する際には、少なくとも次の5つの指標が重要です。1)インフラと供給力、2)資本捻出力、3)市場フォーカス、4)販売チャネル、5)規制・ガバナンス対応です。2026年の選定は、モデル比較ではなく、これらの条件を総合的に見て「どの陣営に乗るか」を決める作業になりつつあります。
つまり2026年にLLMを選ぶとは、単にモデルを選ぶことではありません。どの陣営の運用思想に自社を乗せるかを選ぶことでもあるのです。
主要LLM企業を読む5つの軸
比較の起点は、性能順位ではなく5つの判断軸です。
主要LLM企業を比較するとき、いま最も重要なのは性能順位ではありません。比較の起点になるのは、インフラ、資本、市場フォーカス、販売チャネル、規制・安全保障対応の5軸です。2026年の競争は、モデル単体の優秀さではなく、こうした周辺条件まで含めた「陣営の総合力」で決まりつつあります。
インフラ――誰が計算資源を握っているのか

AnthropicはAWSを主要なクラウド・学習パートナーとしながら、Google Cloud TPUの活用も拡大し、さらにMicrosoft Azure上でも提供を広げています。Anthropic自身は、ClaudeがAWS、Google Cloud、Microsoft Azureの三大クラウドすべてで提供されるフロンティアモデルであることを前面に出しており、単一インフラにすべてを賭けるのではなく、複数の供給基盤にまたがることで企業向けの安定供給力を高めようとしています。
GoogleはGeminiを単独のモデル提供ではなく、自社クラウドと公共・企業向け基盤の上で動かす設計を鮮明にしています。Appleは自社の基盤モデルを持ちながら、必要に応じて外部モデルも取り込む方向に進んでいます。ここから見えてくるのは、どの企業も「AIをどう賢くするか」だけでなく、「どう安定して供給するか」で差をつけようとしているという現実です。
資本――誰が誰を支えているのか
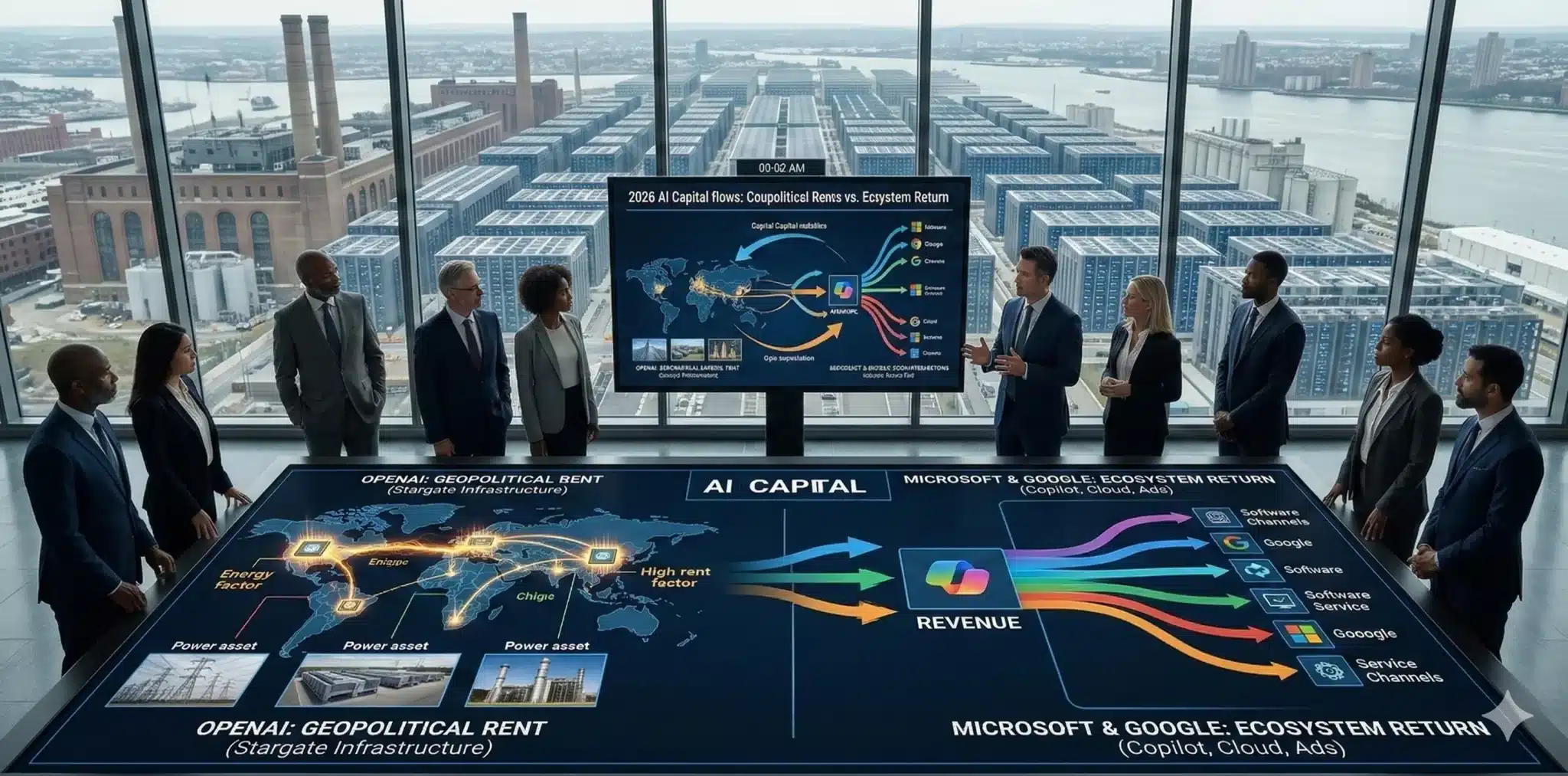 2つ目の軸は資本です。どれだけ優れたモデルを持っていても、巨額の設備投資と運用コストを支えられなければ、勝負は長続きしません。OpenAIはAIインフラ投資を前面に押し出し、巨大需要を受け止めるための資本と設備を調達する構えを強めています。これは投資家目線で見れば、技術競争だけでなく、資本集約型産業への移行を示しています。
2つ目の軸は資本です。どれだけ優れたモデルを持っていても、巨額の設備投資と運用コストを支えられなければ、勝負は長続きしません。OpenAIはAIインフラ投資を前面に押し出し、巨大需要を受け止めるための資本と設備を調達する構えを強めています。これは投資家目線で見れば、技術競争だけでなく、資本集約型産業への移行を示しています。
しかも2026年のAIインフラ投資は、単なるソフトウェア開発費ではありません。OpenAIが資本で解こうとしているのは、モデル研究費だけでなく、電力、チップ、土地、データセンターという物理的な制約です。言い換えれば、AI競争は「計算資源の地政学」に入りつつあり、投資家はキャッシュフローを単なるR&Dではなく、エネルギー資源と計算資源の地政学的確保としても見る必要がある段階に来ています。
Anthropicは、よりはっきりと「支援陣営」が見える企業です。MicrosoftやNVIDIAとの関係強化により、同社は単独で顧客を取りにいく企業であると同時に、巨大プラットフォーマーにとっての重要な供給元にもなっています。GoogleとMicrosoftはむしろ「資本を受ける側」ではなく「資本を供給する側」であり、モデル単体で採算を見るのではなく、クラウド、業務基盤、端末、公共案件まで含めたエコシステム全体で投資を回収できる立場にあります。
市場フォーカス――誰に売ろうとしているのか
 3つ目の軸は市場フォーカスです。ここを見誤ると、性能が高いモデルを選んだつもりが、自社の用途にはあまり合わないということが起きます。OpenAIは依然として幅広い市場を狙っています。個人向けから企業、政府、国家単位までレンジが広く、消費者、企業、政府を横断して取りにいく姿勢が見えます。
3つ目の軸は市場フォーカスです。ここを見誤ると、性能が高いモデルを選んだつもりが、自社の用途にはあまり合わないということが起きます。OpenAIは依然として幅広い市場を狙っています。個人向けから企業、政府、国家単位までレンジが広く、消費者、企業、政府を横断して取りにいく姿勢が見えます。
Anthropicは、比較的わかりやすく企業市場寄りです。一般利用者向けの側面もありますが、提携の置き方や製品展開を見ると、B2Bと高付加価値のプロフェッショナル用途に重心を置いていると読むのが自然です。Googleは企業・公共・既存業務基盤との接続を重視し、Appleは企業向けAIベンダーというより、端末OSの入口を守るプレイヤーです。
ここで重要なのは、「どのモデルが賢いか」より「誰に売ろうとしている会社か」を見極めることです。企業向けに深く入る会社と、広く普及を狙う会社では、導入後のサポート、価格設計、製品進化の方向性まで変わってきます。
販売チャネル――誰が日常の入口を押さえるのか
 4つ目の軸は販売チャネルです。2026年は、モデルの勝敗だけでなく、「どこから使われるか」が極めて重要になっています。この点で最も強いのはMicrosoftです。Microsoftは、Copilotを通じて、日常業務の入口を押さえたうえで最適なモデルを流通させる側に回ろうとしています。これは販路支配という意味で非常に強いポジションです。
4つ目の軸は販売チャネルです。2026年は、モデルの勝敗だけでなく、「どこから使われるか」が極めて重要になっています。この点で最も強いのはMicrosoftです。Microsoftは、Copilotを通じて、日常業務の入口を押さえたうえで最適なモデルを流通させる側に回ろうとしています。これは販路支配という意味で非常に強いポジションです。
Googleもまた、検索、Workspace、Android、クラウド、公共案件という複数の入口を持っています。OpenAIはChatGPTという強い直販チャネルを持っていますが、企業導入の世界では直販だけでなく、既存ワークフローやOS、オフィス環境にどれだけ自然に入り込めるかが問われます。Anthropicは、直販の強さよりもパートナー経由の浸透が目立ちます。
つまり、2026年の勝負は「どのモデルが優秀か」だけでなく、「どの入口から日常業務に浸透できるか」という競争でもあるのです。
安全保障・規制対応――誰が止まりにくいのか
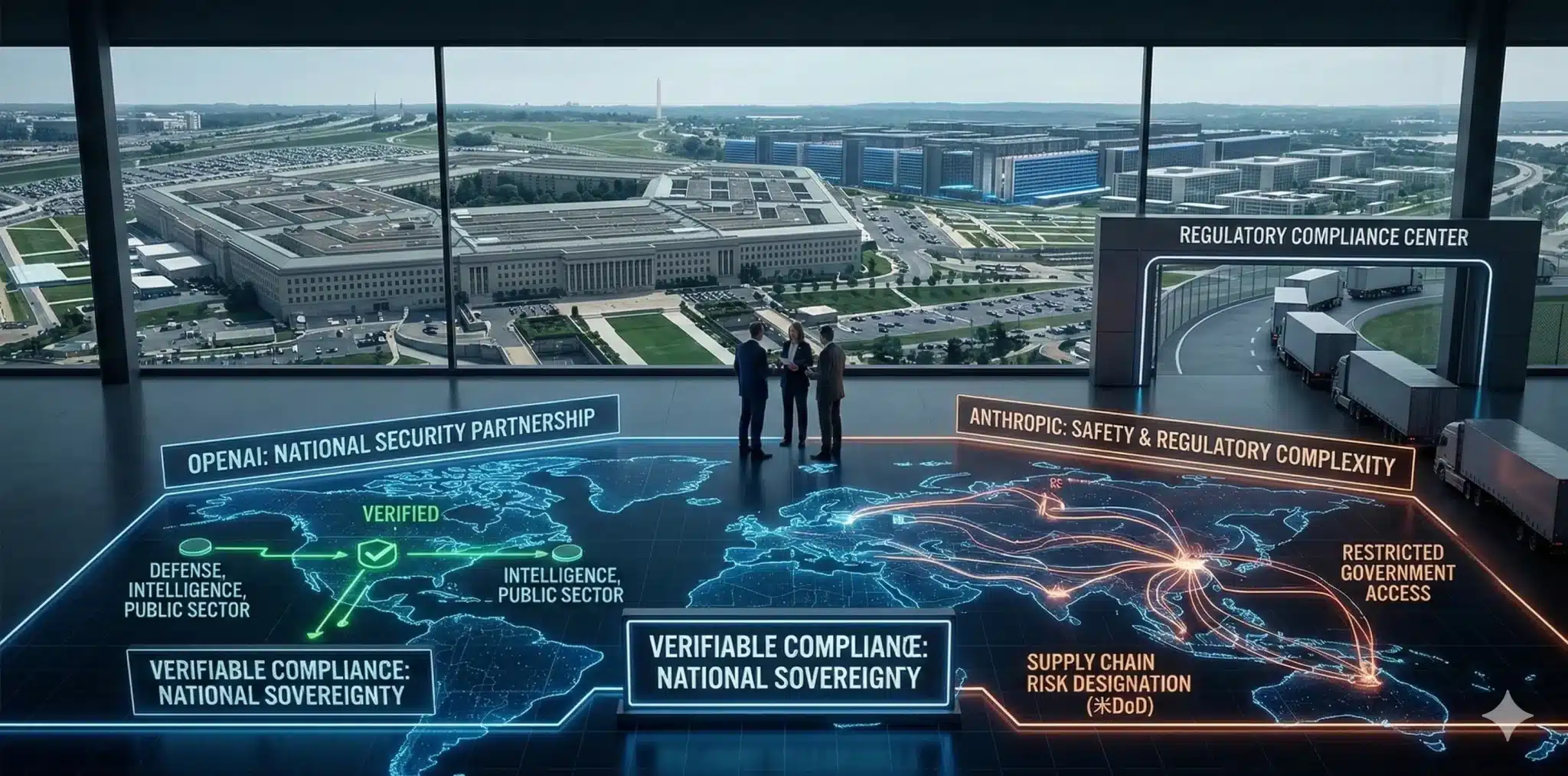 最後の軸は、安全保障と規制対応です。AIが大企業や公共部門の基盤に入り込むほど、単に賢いだけでは採用されません。監査、主権、コンプライアンス、国防・公共用途での扱いやすさが問われます。Googleは公共部門向けに安全で認定済みの入口を提供する方向を強めていますし、OpenAIも国家との関係を強めており、民間SaaS企業という枠を超えた存在感を持ち始めています。
最後の軸は、安全保障と規制対応です。AIが大企業や公共部門の基盤に入り込むほど、単に賢いだけでは採用されません。監査、主権、コンプライアンス、国防・公共用途での扱いやすさが問われます。Googleは公共部門向けに安全で認定済みの入口を提供する方向を強めていますし、OpenAIも国家との関係を強めており、民間SaaS企業という枠を超えた存在感を持ち始めています。
Anthropicについては、この論点が2026年に入って一段と複雑になりました。同社は安全性への姿勢を差別化軸に据えてきましたが、監視や完全自律兵器への利用を制限するスタンスが米国防総省との摩擦要因の一つとなり、TechCrunchなどが報じたように、DoDからサプライチェーンリスクとして扱われる事態に発展しました。これは、「安全性を重視すること」と「政府調達で止まりにくいこと」が必ずしも一致しないことを示す、2026年らしい事例です。
Appleはオンデバイスやプライバシー訴求を続けながら、必要に応じて外部モデルとも連携する構えです。ここで経営者が見るべきなのは、単なる性能ではなく、「どの企業が規制や安全保障の時代にどの市場で止まりにくいか」という点です。企業市場での安定性と、政府・国防調達での扱われ方は、必ずしも同じではありません。
主要LLM企業は何を握ろうとしているのか
主要5社は、同じ土俵ではなく別々の勝ち筋を取り始めています。
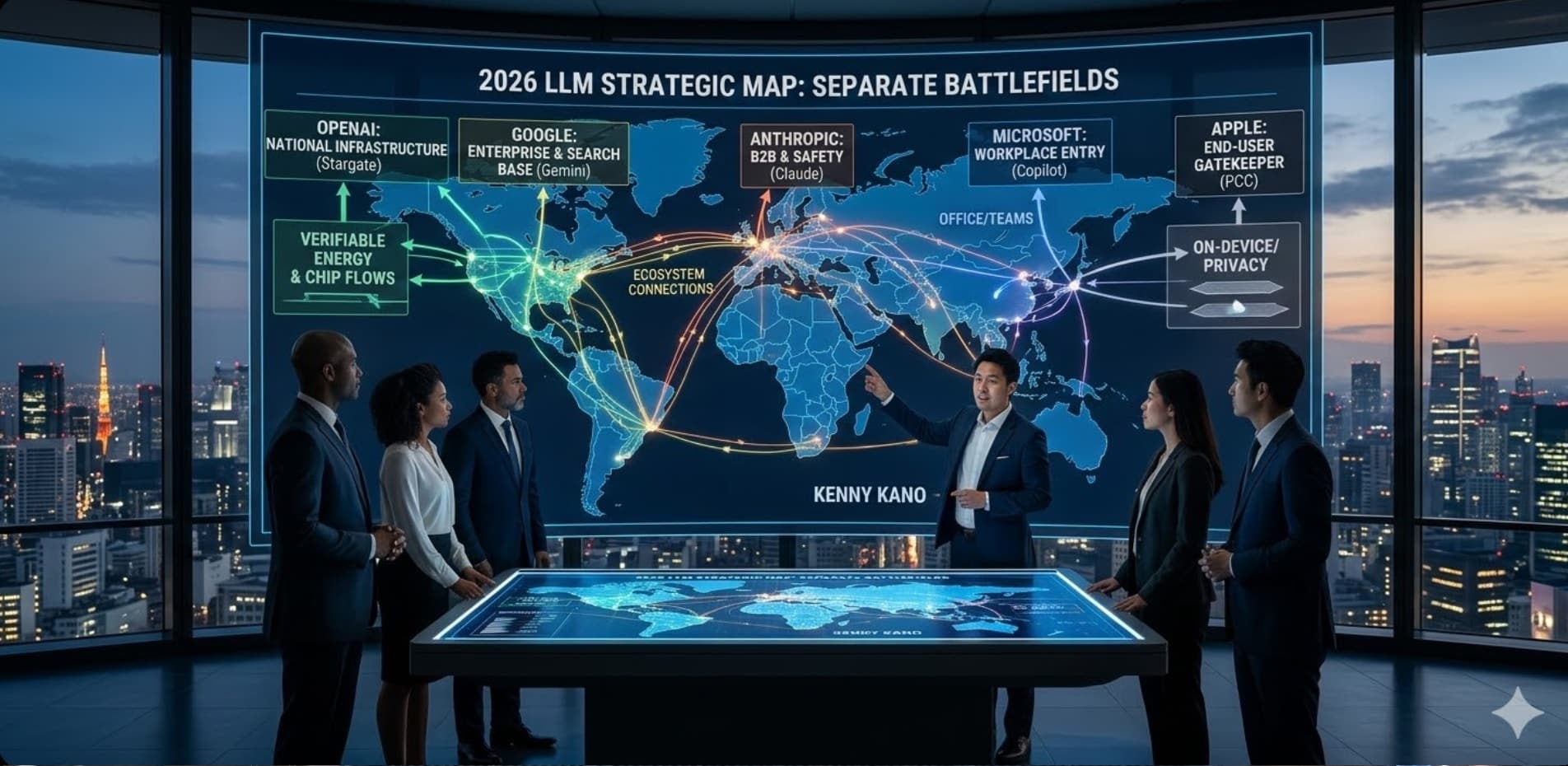
OpenAI――モデル企業から、国家級インフラ企業へ
OpenAIをひと言で表すなら、「モデル企業から国家級インフラ企業へ変わりつつある会社」です。現在のOpenAIは、最先端モデルを作るだけでなく、AIインフラと国家単位の導入支援を前面に打ち出しています。Stargateは2025年時点で5,000億ドル規模・10GW級の長期構想として示され、アビリーンを含む複数の旗艦キャンパス計画が本格始動しました。これは単なるSaaS企業やモデル企業の動きではありません。OpenAIは、AIそのものではなく、AIを供給するための国家級の土台を取りにいっていると見るべきです。
経営者や投資家の視点で見れば、OpenAIの強みは「最先端モデル」だけではなく、「巨大需要を受け止めるための資本と設備を調達できる構え」にあります。その一方で、需要が集中した局面では性能低下やエラーが表面化することもあり、最前線を走っているがゆえに供給責任の重さも大きい企業です。ここで問われるのは、モデルの知能だけでなく、その知能を何人に、どれだけ安定して届けられるかです。
Google――Geminiを「企業基盤」にしていく企業
Googleの強みは、Geminiを単体モデルとして売ることではなく、企業基盤そのものに埋め込めることです。GoogleはGeminiを、検索、クラウド、公共分野、Android、Workspaceといった既存接点の中に組み込みながら、大規模組織の中で運用できるAI基盤として育てようとしています。
その意味でGoogleの本当の強さは、モデルそのものより、接点の広さにあります。企業や公共機関にとって重要なのは、賢いモデルよりも、安心して既存業務の中に載せられる基盤です。Googleはそこに強いポジションを持っています。
Anthropic――安全性とB2Bで「中枢」を取りにいく企業
Anthropicは、「安心して基幹業務に載せられるAI」という立ち位置を強めている企業です。一般向け利用もありますが、近年の流れを見ると、同社は「誰でも使うAI」よりも、「企業が安心して採用できるAI」に軸足を置いています。
この動きが意味するのは、Anthropicが単なる「賢いモデルの会社」ではなく、企業の中枢業務に入り込むための条件整備を進めているということです。その象徴がマルチクラウド戦略で、Anthropic自身は2026年2月の資金調達発表で、ClaudeがAWS、Google Cloud、Microsoft Azureの三大クラウドすべてで提供されるフロンティアモデルであることを前面に出しました。経営者目線で見れば、Anthropicの論点は「Claudeが賢いか」ではなく、「Claudeを安心して基幹業務に載せられるか」です。
Microsoft――モデルを握るより、仕事の入口を握る企業
Microsoftの本質は、モデルを作ることよりも、仕事の入口を支配することにあります。Microsoftは、Copilotを通じて日常業務の入口を押さえたうえで、必要なモデルを束ねる側へ回っています。
この戦略の意味は非常に大きいです。企業にとって本当に重要なのは、最高性能のモデルを単体で買うことではなく、Word、Excel、Teams、メール、ワークフローの中で自然に使えることだからです。Microsoftはこの「仕事の入口」をすでに押さえています。つまり同社の勝負は、モデルの勝敗ではなく、業務のデフォルトUIとしてAIを定着させられるかにあります。
Apple――自前主義を保ちながら、外部知能を取り込む企業
Appleは、モデル競争の最前線で勝つことよりも、最終ユーザー接点を守る統合者として振る舞っています。自社の基盤モデルを保ちながら、必要に応じて外部モデルの力も借りることで、最終的なユーザー接点は自社が持つという構えです。
しかもAppleは、オンデバイス処理を基本としつつ、より高度な推論が必要な場合にはPrivate Cloud Compute(PCC)を介してクラウド側の大規模モデルへ処理を渡す設計を採っています。Apple公式は、PCCではユーザーデータを保存せず、Appleも閲覧できない設計に加え、計算の透明性と検証可能性を前面に出しています。これによりAppleは、プライバシーという聖域を守りながら外部知能を取り込み、ユーザーがAIを使う「最後の1インチ」で非常に強い支配力を持つ構図を築こうとしています。
ただし、Appleに対しては別の見方も必要です。AppleのAI戦略は後から見ると一貫しているものの、ChatGPTが市場を一変させた2023年の時点では、その基本方針を十分に早く、十分に強く市場へ伝えられませんでした。そのため、戦略の不在というより、戦略の逡巡として受け取られた面があるのも事実です。この見えにくさが、AppleのAI方針に対する評価を分ける大きな理由になっています。
この構図を経営者と投資家はどう読むべきか
見るべきはベンチ表ではなく、誰がどの価値レイヤーを取るかです。
ここまで整理すると、主要LLM企業は同じ土俵で競っているように見えて、実際にはまったく異なる価値レイヤーを取りにいっていることがわかります。OpenAIは供給力と国家級インフラ、Googleは企業基盤と接点の広さ、Anthropicは安全性とB2Bの深さ、Microsoftは仕事の入口、Appleは端末OSと最終接点を握ろうとしています。
したがって、経営者や機関投資家が見るべきなのは、単純なベンチマーク表ではありません。重要なのは、「どの企業がどの層で価値を取りにいっているのか」「その勝ち筋が自社の戦略や投資仮説と合っているのか」を見極めることです。企業導入の観点では、モデル性能よりも「止まりにくさ」「契約しやすさ」「既存環境への載せやすさ」が重要になる場面が増えます。投資の観点では、「最先端モデルを持っているか」よりも、「供給制約の時代にどのプレイヤーが収益化しやすいポジションにいるか」が重要になります。
2026年のLLM市場は、性能競争が消えたわけではありません。しかし、その上にインフラ競争、流通競争、信頼競争が重なったことで、見方を変えないと本質を見誤る段階に入っています。
| 企業 | 主な勝ち筋 | 強み | 経営者が見るべき点 |
|---|---|---|---|
| OpenAI | Stargateによる国家級インフラ拡張 | 最先端モデルと供給拡張力 | 需要急増時の安定供給と価格交渉力 |
| 検索・クラウド・Workspaceを束ねる企業基盤 | 接点の広さと統制しやすさ | 既存業務への載せやすさと規制対応 | |
| Anthropic | B2B・安全性・三大クラウド対応 | 安心して基幹業務に載せやすい | 高規制業界や中枢業務との相性 |
| Microsoft | 仕事の入口 | Copilotによる業務接点 | 自社環境への自然な浸透力 |
| Apple | 端末OS・最終接点・PCCによる統合 | ユーザー接点の支配力 | 最終体験を誰が握るか |
| ※2026年3月10日時点の公開情報をもとにArpable編集部作成 | |||
まとめ:2026年にLLMを選ぶとは、どの陣営に乗るかを選ぶことです
モデル選びではなく、陣営選びの時代です。
ここまで見てきたように、2026年のLLM市場は、単純な性能競争では説明できなくなっています。もちろん、モデルの性能差は今でも重要です。しかし現実の経営判断では、それだけでは足りません。なぜなら、企業が実際に導入するのは「モデル」そのものではなく、モデルを取り巻く陣営全体だからです。
どのクラウドで動くのか、どの販路から供給されるのか、どの資本に支えられているのか、規制や安全保障の観点で止まりにくいのか。そうした条件まで含めて初めて、実務に使えるAIの姿が見えてきます。
 経営者にとって重要なのは、もはや「最も賢いモデルはどれか」という問いではなく、「自社の事業にとって、最も止まりにくく、最も載せやすく、最も将来の交渉力を持てる陣営はどこか」という問いです。
経営者にとって重要なのは、もはや「最も賢いモデルはどれか」という問いではなく、「自社の事業にとって、最も止まりにくく、最も載せやすく、最も将来の交渉力を持てる陣営はどこか」という問いです。
たとえば、業務基盤との親和性を重視するならMicrosoftの入口戦略は魅力的に映りますし、企業統制や公共領域との整合を重視するならGoogleの基盤型アプローチは有力です。安全性やB2Bでの信頼性を重視するならAnthropicは有力候補です。ただし政府・国防調達が要件に入る場合は、2026年に生じた米DoDとの摩擦も念頭に置いた判断が必要です。もちろん、最終ユーザー接点やデバイス統合まで視野に入れるならAppleの立ち位置は無視できません。
投資家にとっても、見るべきポイントは変わっています。これから問われるのは、「最先端モデルを持っている企業はどこか」だけではありません。むしろ重要なのは、「過剰需要の時代に、供給力、稼働率、販路、収益性をどう両立するのか」です。
2026年のAI市場は「どのモデルが最強か」を問う市場ではなく、どのプレイヤーがどの層を支配するのかを読む市場になっているのです。
そして、ここに2026年らしい本質があります。
筆者自身、日々の業務の大半をLLMと共に過ごしていますが、最近強く感じるのは、モデルの「頭の良さ」だけでは体験が決まらないということです。
同じモデルでも、時間帯や需要状況、提供基盤の混雑によって、応答の切れ味や安定性の印象が変わることがあります。もちろん、これは厳密な実験で証明した結論ではありません。しかし、こうした体感は単なる気のせいではなく、供給制約時代のAI利用体験として理解するほうが自然です。
2026年の勝者は、もっとも賢いモデルを持つ企業とは限りません。むしろ、もっとも賢い状態を、もっとも多くの利用者に、もっとも安定して届けられる陣営が勝つ可能性が高いのです。
だからこそ、企業がLLMを選ぶとは、単なるツール選定ではありません。どの陣営に、自社の将来を預けるかを選ぶことです。そして、この視点を持てるかどうかが、導入の成否だけでなく、数年後の交渉力や柔軟性にも直結していくはずです。
専門用語まとめ
- LLM
- 大規模言語モデルのことです。大量のテキストデータを学習し、文章生成や要約、推論、対話などを行うAIの中核技術を指します。
- 陣営競争
- モデル単体ではなく、インフラ、資本、販路、規制対応まで含めた総合力で勝負が決まる競争状態を指します。
- AIインフラ
- AIモデルを学習・推論・配信するために必要なクラウド、GPU、データセンター、ネットワークなどの基盤全体を指します。
- 販売チャネル
- AIが実際にユーザーへ届くための入口です。ChatGPTの直販、Microsoft 365 Copilot、Google Workspace、Appleの端末体験などが該当します。
- 供給制約時代のAI利用体験
- モデル性能だけでなく、混雑、稼働率、レート制限、提供基盤の余力によってユーザー体験が揺れやすい状況を指します。
よくある質問(FAQ)
Q1.
2026年もLLMは性能競争が中心ですか?
A1.
性能競争は続いていますが、それだけでは勝敗を説明できません。
- 現在は供給力、運用品質、販路、規制対応も重要な比較軸です。
- AIインフラの供給力、レート制限、混雑状況による応答遅延も2026年には無視できない要素です。
Q2.
経営者はどの指標を優先して見るべきですか?
A2.
インフラ、資本、市場フォーカス、販売チャネル、規制対応の5軸を優先して見るべきです。
- 性能表だけでは導入後の安定性や交渉力は見えません。
- 「どの陣営に乗るか」という視点が重要です。
Q3.
OpenAIとGoogleの違いは何ですか?
Q4.
Anthropicはなぜ企業向きと言われるのですか?
A4.
安全性とB2Bを重視し、「安心して基幹業務に載せやすいAI」という立ち位置を強めているからです。
- 一般向けよりも企業導入との相性が強い戦略が目立ちます。
- 三大クラウド対応により、企業向けの安定供給力も補強されています。
Q5.
企業がLLMを選ぶとは、結局どういうことですか?
A5.
単なるツール選定ではなく、どの陣営に自社の将来を預けるかを選ぶことです。
- クラウド、販路、規制対応、供給体制まで含めて判断する必要があります。
- 数年後の柔軟性や交渉力にも影響します。
関連:まとめへ
より詳しい情報は、主要LLM比較記事や、
AI検索エンジン進化の記事もご覧ください。
参考サイト・出典
- OpenAI Status
- Anthropic Status
- Google AI for Developers – Gemini API Rate limits
- OpenAI – OpenAI for Countries
- OpenAI – Five new Stargate sites
- Anthropic – Series G funding announcement
- Anthropic – Microsoft and NVIDIA partnerships
- TechCrunch – Pentagon moves to designate Anthropic as a supply-chain risk
- Apple Security – Private Cloud Compute
- Apple – Apple Intelligence & Privacy
あわせて読みたい
更新履歴
- 2025年03月25日:初版公開
- 2025年07月12日:情報アップデート、読者支援機能の強化
- 2025年08月19日:最新情報アップデート
- 2025年10月02日:最新情報アップデート
- 2026年03月10日:主要LLM企業の戦略地図に合わせて全面改稿。2026年時点の最新動向を反映し、「性能競争」から「陣営競争」への構図、主要5社の勝ち筋比較、FAQ、用語集、参考出典を追加








