


LLMと検索エンジンの未来|思想と使い分けガイド【2025】
本記事はLLMの思想(開発哲学)と検索の融合、そして目的別の使い分けにフォーカスします。
“いつ・どのLLMを使うべきか”をケースで具体化し、検索→要約→検証という実務フローで価値を最大化します。
この記事の位置づけ:
本記事は思想・検索融合・使い分けに特化します。導入判断は記事A)、性能比較は記事B)をご参照ください。A)導入判断(価格・基盤・運用):
【2025】企業向けLLMの選び方|価格・導入基盤・運用ガイド
B)性能比較(機能・ベンチ):
【2025】主要5大LLMの性能比較|GPT-5・Gemini・Claude・Llama・Grok
📖 読了 約15分|🎯 対象:意思決定者/情報探索が多い職種/学生・研究者|🛠 難易度:★★★☆☆
この記事の結論
検索は「一次情報の発見と検証」、LLMは「要約・統合・思考」。両者をRAGでつなぎ、目的別に使い分けるのが最適解。
- 要点1:検索(Perplexity等)は情報源の特定と裏取り、LLMは文脈統合と下書き生成に最適。役割分担で意思決定が速く正確に。
- 要点2:使い分け原則:長文推論・安全性はClaude、総合力はGPT、コスト重視・量産はGemini、主権/高度カスタムはLlama、時事即応はGrok。
- 要点3:推奨フロー:検索で候補収集 → LLMで要約/骨子化 → 追加検索で検証 → LLMで仕上げ。社内RAGやツール連携で再現性と統制を高める。
冒頭FAQ
Q. LLMと検索はどのように役割分担する?
Q. どのLLMをいつ使い分ける?
Q. Perplexity等の検索融合型の位置づけは?
この記事の著者・監修者

はじめに:私たちはなぜ「どのLLMを使うべきか」で迷うのか?
本記事は、単なる機能比較や机上の空論ではありません。筆者自身が、
現時点(2025年10月3日)で市場をリードする以下の主要LLM(大規模言語モデル)を
「専門家チーム」として使い倒した実践知に加え、
信頼できる第三者機関のベンチマークデータを統合しています。
- ChatGPT(GPT-5/o3/GPT-4.5 など最新モデル群)
- Gemini(2.5 Pro/2.5 Flash、Google Workspace連携)
- Claude(Claude Sonnet 4.5/Opus 4 系列、安全性重視)
- Llama(Llama 3.1/Llama 4、オープンウェイト系)
- Grok(Grok-4、X連携・時事即応に特化)
- Perplexity(Deep Research、検索融合型)
この記事を読めば、あなたが本当に必要としている「AIパートナー」としてのLLMが誰なのか、
その客観的な根拠と共に見つかるはずです。
4大LLMの思想とポジショニング【データで補強】
なぜLLMによって回答の質や方向性が違うのか?
それは、開発企業の「DNA」が性能や回答スタイルに色濃く反映されているからです。
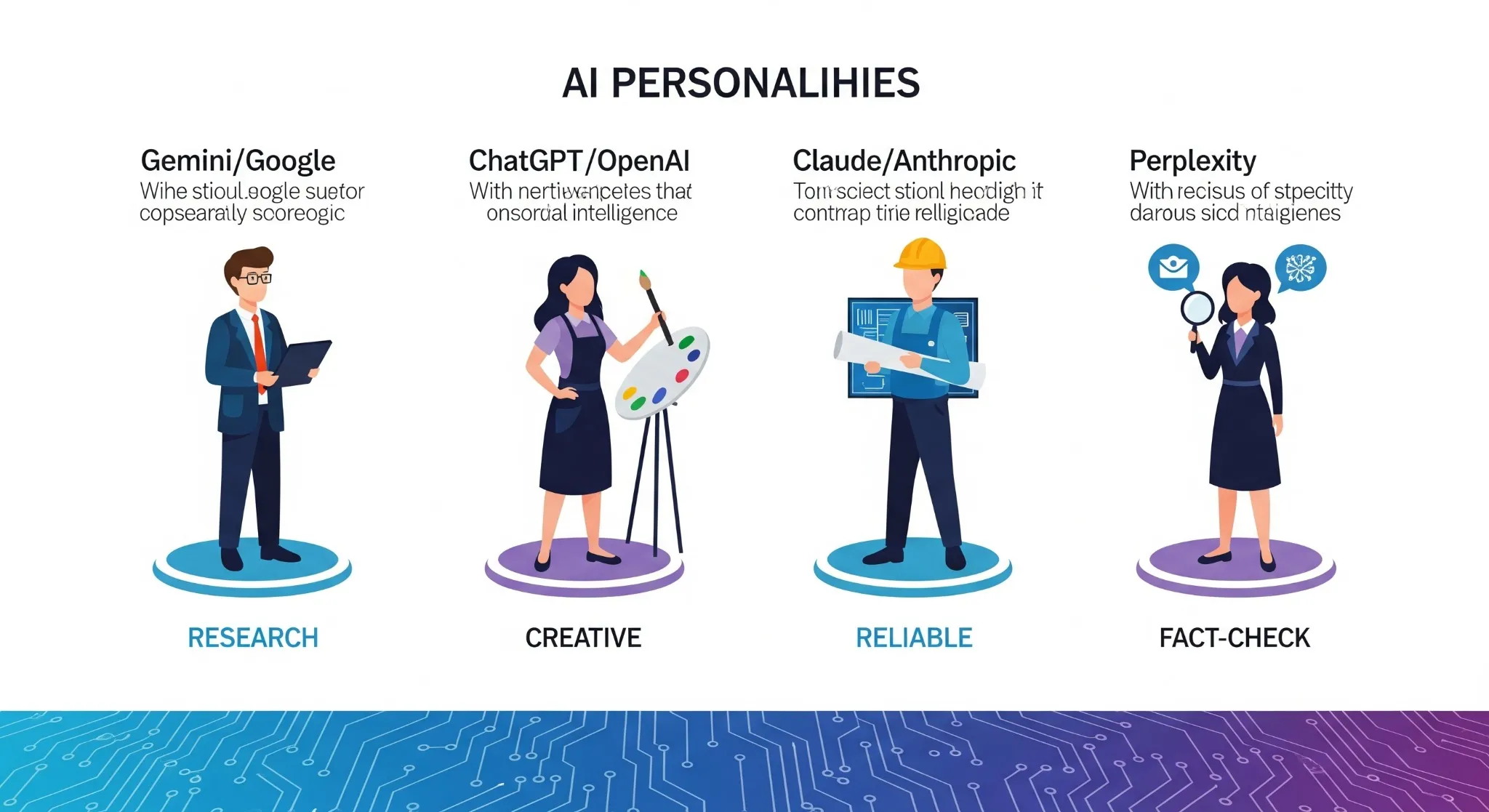
各LLMの「思想」と「個性」を可視化した相関図。
GoogleのGeminiは学術的正確性、OpenAIのChatGPTは創造性、AnthropicのClaudeは信頼性、Perplexityは事実調査力を武器とする。
加えて、MetaのLlamaは主権性・カスタマイズ性、xAIのGrokは時事即応力を強みとする。
この記事では客観的ベンチマークデータを基に、あなたの目的に最適な「AIパートナー」を見つける方法を解説します。
1. Google (Gemini):世界中の情報を整理し、日常に溶け込む「万能アシスタント」
Googleの使命は「世界中の情報を整理し、誰もがアクセスできるようにすること」。
Geminiもその思想を継承し、Googleサービスとの深い連携を武器にしています。特に理数系の専門的な問題解決で強みを発揮し、
Gemini 2.5 Proは高難度QAベンチマーク「GPQA Diamond」で84%というトップ級スコアを記録しました。
さらに最新のアップデートでは、Google Workspace連携による業務効率化においても評価が高まっています。
「情報の整理」という原点から、Geminiは検索や業務ツールとの統合を通じて調査・分析に強いアシスタントとして機能します。
2. OpenAI (ChatGPT):AGIを目指す「クリエイティブ・パートナー」
OpenAIのミッションは「人類全体に利益をもたらすAGIの構築」。
その汎用性は言語処理や創造力にも表れており、最新のGPT-5はMMLUで90%級を達成し、多言語・推論タスクに強みを発揮しています。
また開発者向けにはCodex系モデルがSWE-Bench Verifiedで72%級の精度を記録し、Claudeに肉薄する結果を示しました。
ChatGPTは総合的な対応力と創造性において依然として強力な選択肢です。
3. Anthropic (Claude):安全性を第一にした「信頼できる推論エンジン」
「AIの安全性」を中核に据えるAnthropicが開発したClaudeは、長文推論や専門業務で安定した性能を誇ります。
特筆すべきはClaude Opus 4.5がSWE-Bench Verifiedで72.7%というリーダーボード公式トップに立っていること。
契約書や法律文書、コードレビューなど精度と一貫性が最重要の領域で、他モデルを凌駕する信頼性を示しています。
4. Perplexity AI (Sonar):「根拠のある真実」に徹する知識探求者
Perplexityは「もっともらしい嘘(ハルシネーション)」を排除するため、すべての回答に出典を明示。
事実調査タスク(SimpleQA)で93.9%という驚異的正答率を達成し、検索融合型LLMとして確固たる地位を築いています。
特に最新のDeep Researchモードでは、複雑なリサーチ課題に対しても短時間で正確な一次情報を提示できます。
【機能・性能】主要LLMプラットフォーム徹底比較表
思想だけでなく、具体的な機能や客観的性能データで各LLMを比較します。
※ Llama 3.1 400B(MMLU 83.5%)や Grok-4(時事即応特化)は脚注で補足
| 項目 | Perplexity | ChatGPT (OpenAI) | Claude (Anthropic) | Gemini (Google) |
|---|---|---|---|---|
| コンセプト | 知識の探求者 | クリエイティブ・パートナー | 信頼できる専門家 | 万能アシスタント |
| 客観的性能と得意タスク | ●事実調査・引用付き検索 SimpleQA 93.9%(Perplexity AI) |
●多言語・推論 GPT-5: MMLU 90%級(OpenAI) ●コード生成 Codex-1: SWE-bench Verified 72.1%*1 |
●長文推論・専門業務 Opus 4.1: SWE-bench Verified 74.5%(Anthropic公式)/ Sonnet 4.5: 77.2%*2 |
●STEM高難度QA Gemini 2.5 Pro: GPQA Diamond 84% |
| 長文処理能力(コンテキスト長) | △(短文中心) | ◎(o3: 約200kトークン/GPT-5はThinkingで深推論) | ◎(200kトークン超) | ◎(最大約1Mトークン) |
| ユニーク機能 | Deep Research, Pages | GPTs, o3(追加有効化), AIエージェント | Artifacts機能, 長文一貫性 | Workspace連携, Gemini CLI |
📝 表記ルールと脚注
本表は公式公表値を基本とし、実行条件が特殊な自己公表値は補足として併記しています。
SWE-benchはサブセット/thinking長/プロンプト・スキャフォールドで数値が変動します。
*1:Codex-1 の 72.1% は OpenAI 自社ブログの社内計測(1-try)。SWE-bench Verified 公式LBには未掲載(外部未検証)。
*2:Claude Sonnet 4.5 の 77.2% は Anthropic公表の条件付き値(10回平均・200K thinking・bash+文字列置換・特別プロンプト)。厳密比較には同条件の再測定が必要。
補足:Llama 3.1 400B(MMLU 83.5%)はOSS勢の有力株。Grok-4は時事即応タスクで強み。
【目的別】あなたの最強LLMパートナーはどれだ?
具体的な目的別に、データに基づいた最適なLLMを見ていきましょう。
Case 1:「最新の市場動向を、信頼できる情報源を基にレポートしたい」
結論:Perplexity が最適
理由:事実調査のベンチマーク SimpleQAで93.9% (Perplexity AI) という圧倒的なスコアが示す通り、誤情報のリスクが極めて低いのが特徴です。常に参照元リンクを提示するため、ファクトチェックの時間を大幅に削減できます。
Case 2:「新しいサービスのキャッチコピーを、100個ブレストしたい」
結論:ChatGPT (GPT-5) が最適
理由:創造性や発想の柔軟性はベンチマークで測りにくい部分ですが、MMLUで90%級という最新の多言語・推論性能 (OpenAI, 2025年9月発表) が裏付ける通り、高度な言語能力がクリエイティブタスクでも強みを発揮します。思考の「ジャンプ」を助ける最高のパートナーです。
Case 3:「大規模システムの複雑なバグを修正したい」
結論:Claude (Opus 4.1 / 4.5) が最適
理由:実際のバグ修正能力を測る SWE-Bench Verifiedで74.5% を記録し、公式リーダーボードでもトップクラス (Anthropic, 2025年) に位置しています。既存の複雑なコードベースを正確に理解し、信頼性の高い修正パッチを生成する能力に長けています。
Case 4:「今日の会議の議事録(Googleドキュメント)を要約して、関係者への報告メールを作りたい」
結論:Gemini が最適
理由:Google Workspaceとのシームレスな連携はGemini最大の強みです。ドライブ内のドキュメントを直接参照し、Gmailの下書きを作成するといった一連の作業をスムーズに行えます。特に最新の Gemini 2.5 Pro はGPQA Diamondで84% とSTEM系の正確性でも高評価です。
【未来展望】思考エンジンとAIエージェントの最適な使い分け
2025年、AIは「よく考える(Reasoning)」だけでなく「自律的に動く(Acting)」段階に進みました。ここでは
思考エンジン(例:GPT-5 Thinking/Claude) と AIエージェント(ツール実行の仕組み) の役割を整理し、
誤解の多い o3 の立ち位置も含めて、実務での最適解を示します。
あなたの目的はどっち?最短で“正しい相棒”を選ぶ
| こんなことをしたい(目的) | 選ぶべき中核 | 理由(要点) |
|---|---|---|
| 難しい理論・数理・厳しめ制約付きの長手順で、正確な結論が欲しい | GPT-5(必要時にThinkingへ自動昇格) ※比較用に o3 を手動A/Bで併用可 |
GPT-5は標準でルーターが働き、難問時はGPT-5 Thinkingで深い推論。o3は「追加モデル」扱いで明示選択が必要。まずはGPT-5を既定、詰まる所だけo3とA/B。 |
| 大量の資料(契約書/研究/設計書)から要点と一貫した結論を出したい | Claude / Gemini / GPT-5 長文・要点化に強い系 |
長文一貫性と安全性でClaude、超長コンテキストやWorkspace連携でGemini、総合運用はGPT-5。どれでも良いが、社内RAG併用で再現性が上がる。 |
| 毎日の定型業務(収集→整形→レポート配信)を自動化したい | AIエージェント 頭脳は GPT-5 / Claude / Llama 等を選択 |
エージェントはブラウザ操作、API/アプリ連携、スケジューリングを自律実行。頭脳は要件で選ぶ(コスト=Gemini、精度=Claude、総合=GPT-5、主権=OSS/Llama)。 |
| Webで調査→分析→スライドまで作成してほしい | AIエージェント+RAG (Perplexity等で根拠収集 → LLMで骨子/清書) |
検索で一次情報を集め出典を保持し、LLMが要約・構成・原稿化。Slides/Docs APIや社内ドライブ接続で資料を自動生成。出典保持&監査ログで統制。 |
結論:
「答え」を最短で得たい → 思考エンジン(既定はGPT-5、必要時にThinking)。
「行動」まで自動化したい → AIエージェント(適切な頭脳+権限+RAG)。
o3は“明示選択の追加モデル”として、本当に難しい課題での比較検証用にピンポイントで使うのが現実的です。
実装TIPS(失敗しない三原則)
- 分離:「思考(どのLLM?)」と「実行(どのツール/権限?)」を設計上はっきり分ける。
- 根拠:検索→要約→検証の流れをRAGで定型化し、出典URLとログを必ず残す。
- 統制:エージェントの権限は最小限(原則読み取り→下書き)。本番実行は人の承認を必須化。
よくある誤解(1分で解消)
- 誤解:「o3を選べば常に一番賢い」→ 訂正:ChatGPTの既定はGPT-5で、難問時は自動でThinkingへ。o3は自動選択されず、比較用に手動で使う位置づけ。
- 誤解:「エージェントがあればLLMは何でも同じ」→ 訂正:頭脳の違いで品質・コスト・安全性が大きく変わる。用途別に頭脳を差し替えられる設計に。
よくある質問(FAQ)
日本語の精度が一番高いLLMはどれですか?
A. 「日本語で最強」は用途と条件で変わります。実務では次の観点で選ぶのが確実です。
- 汎用対話・翻訳・作文:GPT-5(必要時にGPT-5 Thinkingへ自動)
多言語・推論の総合力が高く、敬語・文体の切替や“下書き→推敲”の往復が安定しています。 - 長文精読・安全性重視(契約・法務・研究):Claude(Sonnet 4.5 / Opus 4.1)
長文での一貫性や慎重さに定評。要約→論点抽出→反証提示の工程が作りやすいです。 - 検索前提の事実調査:Perplexity Deep Research
出典リンクを必ず添える設計で、一次情報の裏取りと引用管理が容易です。 - Google連携・超長文の社内資料:Gemini 2.5 Pro
Workspaceと自然に接続し、大容量のドキュメント処理やスプレッドシート操作が得意。
結論:日常はGPT-5、長文・安全性はClaude、検索検証はPerplexity、Google業務はGemini。定期的に同一プロンプトで再評価(日時とモデル名を記録)する運用がベストです。
結局、最初に試すべきLLMはどれですか?
A. はじめてなら次の2本柱から。どちらも無料枠/有料プランがあり、導入が簡単です。
- まずは万能の体験を: ChatGPT(GPT-5)
迷ったら既定のGPT-5でOK。必要に応じてThinkingへ自動で深掘りします。 - Google中心のワークスタイル: Gemini
Gmail/Docs/Driveの連携が強力で、すぐに業務フローに乗せやすいです。
応用: 長文リスク管理が重要ならClaude、出典つきで調べ物を固めたいならPerplexityを追加で並行試験するのが近道です。
LLMに入力した情報やデータのプライバシーは安全ですか?
A. 重要な注意点です。まず原則として、デフォルト設定のまま機密情報を入れないのが基本。業務で使う場合は次の3点を必ず確認しましょう。
- 学習利用の無効化: 各サービスの 設定 → データ管理/Privacy で「モデル改善のための利用」をオプトアウト(#opt-out)。
- プラン選定: 企業向け(Enterprise/Team/Edu等)は原則、入力を学習に使わない契約が前提。個人向けよりもログ管理・権限分離がしやすいです。
- データ境界: 社内RAGやVPC/専用プロジェクトで機密データを外部に持ち出さない設計。監査ログとアクセス制御を徹底。
加えて、「読み取り専用→下書き作成→人の承認→本番反映」の段階制御にしておくと、誤送信や権限濫用のリスクを大幅に減らせます。
まとめ:単一の「最強」は存在しない。データに基づき「専門家チーム」としてのLLMを使いこなそう
ここまで見てきたように、2025年現在、すべてのタスクを完璧にこなす単一の「最強LLM」は存在しません。しかし、客観的なデータでそれぞれのLLMが持つ「個性」と「得意分野」を理解すれば、彼らはあなたの仕事を強力にサポートする「専門家チーム」になります。
- 事実を調査する「リサーチャー」としてのPerplexity
- アイデアを広げる「クリエイター」としてのChatGPT(GPT-5)
- コード修正の「トップエンジニア」としてのClaude
- 日常業務を片付ける「秘書」としてのGemini
- そして、高度な思考を担う「博士」としてのGPT-5 Thinking/o3、業務を自動化する「実行部隊」としてのAIエージェント
これからは、一つのLLMに固執するのではなく、解決したい課題に応じて最適な専門家(LLM)に協力を仰ぐ――。そんな「LLMチーム」をデータに基づいて率いる監督のような視点こそが、これからの時代に求められるスキルなのです。
主な専門用語解説
- LLM(大規模言語モデル)
- 膨大なテキストデータを学習することで、人間のように自然な文章を生成したり、要約したり、質問に答えたりできるAI技術。本記事で紹介しているAIの頭脳にあたる部分です。
- AIエージェント
- 与えられた目標に対し、自ら計画を立て、Web検索やアプリ操作といったツールを使いながら自律的にタスクを実行する仕組みのこと。「実行部隊」のような役割を担います。
- AGI(汎用人工知能)
- 特定のタスクに特化するのではなく、人間と同等かそれ以上に、幅広い知的作業をこなせるAIのこと。多くのAI開発企業が目指す最終的な目標の一つです。
- ハルシネーション
- AIが事実に基づかない、もっともらしい嘘の情報を生成してしまう現象のこと。AIの回答を鵜呑みにせず、特に正確性が求められる場面では出典の確認が重要です。
- コンテキスト長(Context Length)
- AIが一度に処理できる情報量(文脈の長さ)のこと。単位は「トークン」で表されます。この値が大きいほど、長文の資料を一度に読み込ませたり、長い会話の文脈を維持したりするのが得意になります。
- ベンチマーク
- AIの性能を客観的に測定するための標準的なテストや指標のこと。SWE-Bench(実際のGitHub上のバグに対し修正パッチを生成する能力を評価)、MMLU(言語理解)、GPQA(理数系QA)など、様々な種類があります。
- オプトアウト
- 「拒否する」「参加しない」という意味。LLMサービスにおいて、ユーザーが入力したデータをAIの学習に利用されることを拒否する設定を指します。プライバシー保護のために重要な機能です。
更新履歴
- 章の整合性・表記統一・FAQ更新(GPT-5/Claude/Gemini/Perplexityの最新整理)
- 最新情報のアップデート
- 用語解説追加、比較表とFAQを新たに追加
- 初版公開
主な参考公式サイト
- OpenAI Blog(ChatGPT開発元)
- The Keyword | Google AI(Gemini開発元)
- Anthropic News(Claude開発元)
- Perplexity Blog
- ITmedia AI+(国内AI関連ニュース)
- WIRED.jp | AI(グローバルなAI動向)








