


※本記事は継続的に最新情報へアップデートしています。
2026年のRAGでは、Embeddingは単なる「ベクトル化」ではなく、検索精度・コスト・速度・運用性を左右する設計レイヤーである。
チャンキングで作った知識単位を、どのモデルで、何次元で、どの距離尺度で、どの検索方式に載せるかによって、同じRAGでも回答品質は大きく変わる。
本記事では、RAGにおけるEmbedding技術を、モデル選定、次元設計、圧縮、Reranker、評価指標まで含めて、実務で判断できる形に整理する。
✅ 先に結論
RAGのEmbedding最適化とは、最新モデルを選ぶだけではありません。文書タイプ・検索意図・日本語適性・次元数・圧縮・Reranker・評価指標をまとめて設計することです。
- ポイント1:Embeddingは、質問と文書を「意味の近さ」で比較するための数値表現です。RAGでは検索品質の土台になります。
- ポイント2:モデル選定では、精度だけでなく、日本語・多言語、ドメイン用語、コンテキスト長、次元数、コスト、運用基盤を見ます。
- ポイント3:ベクトル検索だけでは固有名詞や番号検索に弱い場面があるため、Hybrid Search、Reranker、メタデータフィルタ、評価指標を組み合わせて最適化します。

何が変わったのか
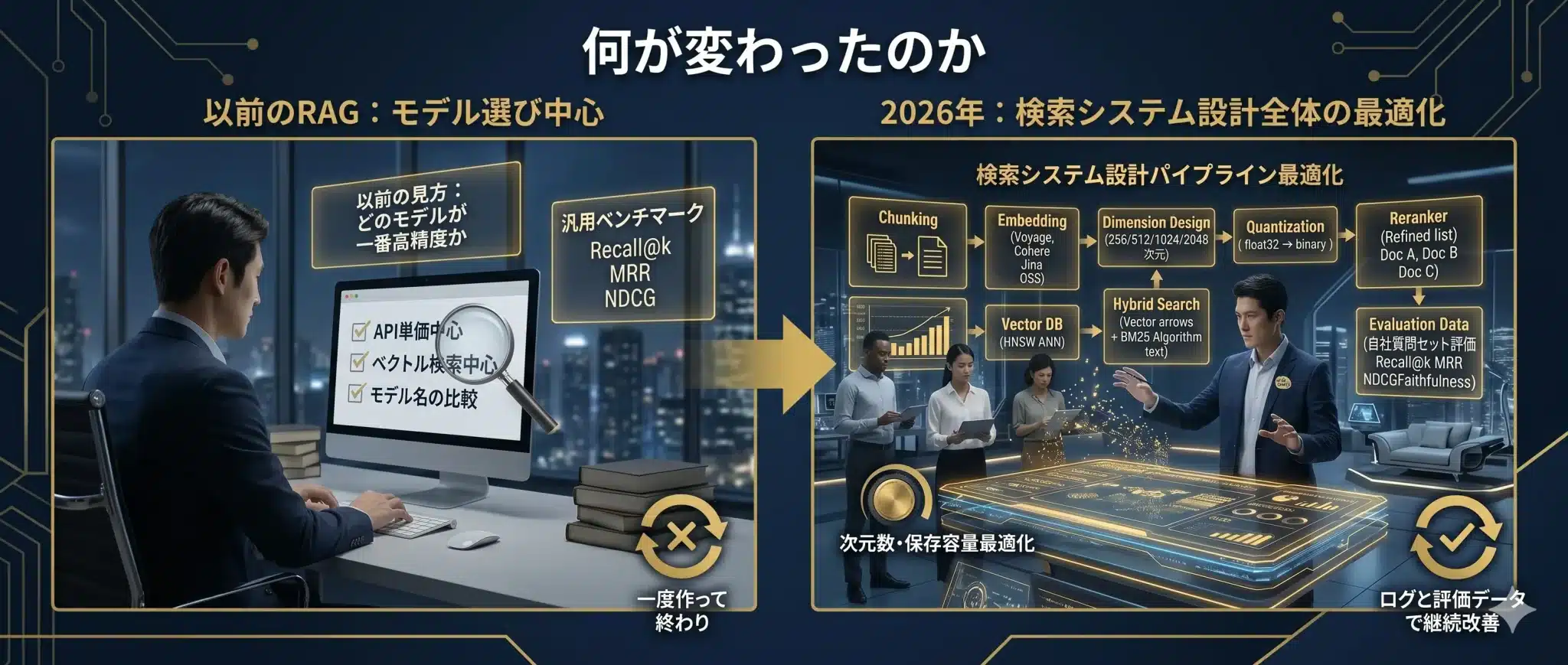
Embeddingの競争軸は、単純な高精度モデル選びから、検索設計全体の最適化へ移っている。
以前のRAGでは、「どのEmbeddingモデルを使うか」が議論の中心でした。もちろん、モデル選定は今でも重要です。しかし2026年の実務では、それだけでは足りません。
RAGの検索品質は、Embeddingモデルだけで決まるわけではありません。前工程のチャンキング、ベクトル次元、正規化、距離尺度、Vector DB、Hybrid Search、Reranker、評価データセットが組み合わさって、最終的な回答品質を決めます。
つまり、Embeddingは「モデル名の比較」ではなく、検索に使える意味表現をどう設計するかという実務課題になっています。
なお、文書をどう切るかというチャンキングの詳細は、すでに RAGチャンキング最適化 で扱っています。本記事では、チャンキング済みの知識単位を、どのようにベクトル化し、検索品質へつなげるかに集中します。
モデル比較から検索設計へ
| 観点 | 従来の見方 | 2026年版の実務設計 |
|---|---|---|
| 主な関心 | どのモデルが一番高精度か | 自社データと質問タイプでどのモデルが安定するか |
| 評価軸 | 汎用ベンチマーク | 社内質問セットでのRecall@k、MRR、NDCG、回答品質 |
| コスト | API単価中心 | 次元数、保存容量、検索速度、Reranker費用まで含める |
| 検索方式 | ベクトル検索中心 | Hybrid Search、Reranker、メタデータフィルタと組み合わせる |
| 運用 | 一度作って終わり | ログと評価データで継続改善する |
この変化を押さえると、Embedding記事の役割が明確になります。チャンキング記事が「何を1単位として切るか」を扱うなら、本記事は「その単位をどう意味ベクトル化し、検索可能にするか」を扱います。
なぜ今重要なのか
RAGの失敗は、モデル性能だけでなく、意味表現と検索設計のズレから起きる。
RAGの回答が外れると、ついLLMやEmbeddingモデルの性能不足を疑いたくなります。しかし実際には、Embeddingモデルそのものよりも、データと検索設計の不一致が原因であることも多いです。
たとえば、社内文書では製品名、略称、案件名、型番、部署名、法令名、顧客固有の表現が頻出します。汎用Embeddingモデルは一般的な意味の近さには強い一方、自社固有の言い換えや専門用語の関係をうまく拾えないことがあります。
実際に、ある企業では「案件コード+略称」で検索したときに、類似案件ではなく全く別部門のFAQばかりがヒットし、問い合わせ対応時間が大きく増えたケースがありました。このときに効いたのはモデル乗り換えだけではなく、Hybrid Search、メタデータ設計、Rerankerの導入でした。
また、質問が短すぎる場合も問題になります。「申請方法は?」という質問だけでは、経費精算なのか、休暇申請なのか、AIツール利用申請なのかが分かりません。この場合、Embedding検索だけで正しい文書を取るのは難しく、クエリ拡張、メタデータ、Hybrid Search、Rerankerが必要になります。
Embeddingは、意味を数値化する技術であると同時に、検索失敗の原因を見える化する入口でもあります。
Embedding起因で起きやすい失敗
| 失敗パターン | 症状 | 主な対策 |
|---|---|---|
| 専門用語を拾えない | 社内略語や型番で検索すると関係ない文書が出る | ドメイン評価セット、Hybrid Search、辞書、メタデータを使う |
| 意味は近いが根拠が違う | 似た規程・似たFAQが混ざる | Reranker、文書種別フィルタ、版数管理を使う |
| 短い質問で意図が曖昧 | 検索結果が広がりすぎる | クエリ拡張、質問分解、カテゴリ指定を使う |
| ベクトル次元が過剰 | ストレージと検索コストが大きい | Matryoshka、次元削減、量子化を検討する |
| ベクトル検索だけに依存 | 製品番号、法令番号、固有名詞の検索に弱い | BM25とのHybrid Searchを使う |
| 評価せずにモデルを選ぶ | ベンチマークでは高性能でも自社データで弱い | 社内質問セットでRecall@k、MRR、NDCGを測る |
RAGの精度低下原因を工程別に確認したい場合は、RAG精度改善ガイドもあわせて参照してください。
どう捉えるべきか
Embeddingは、テキストを「意味の住所」に変換し、近い情報を探せるようにする技術である。
Embeddingとは、文章や単語を数値ベクトルに変換する技術です。たとえば、「経費精算の申請方法」と「交通費を申請する手順」は、表面上の文字列は違っても意味は近いです。Embeddingは、このような意味の近さをベクトル空間上の距離として扱えるようにします。
RAGでは、ユーザーの質問をEmbeddingし、あらかじめEmbeddingしておいた文書チャンクと比較します。意味的に近いチャンクを取り出し、それをLLMに渡して回答を生成します。
ベクトル空間とコサイン類似度
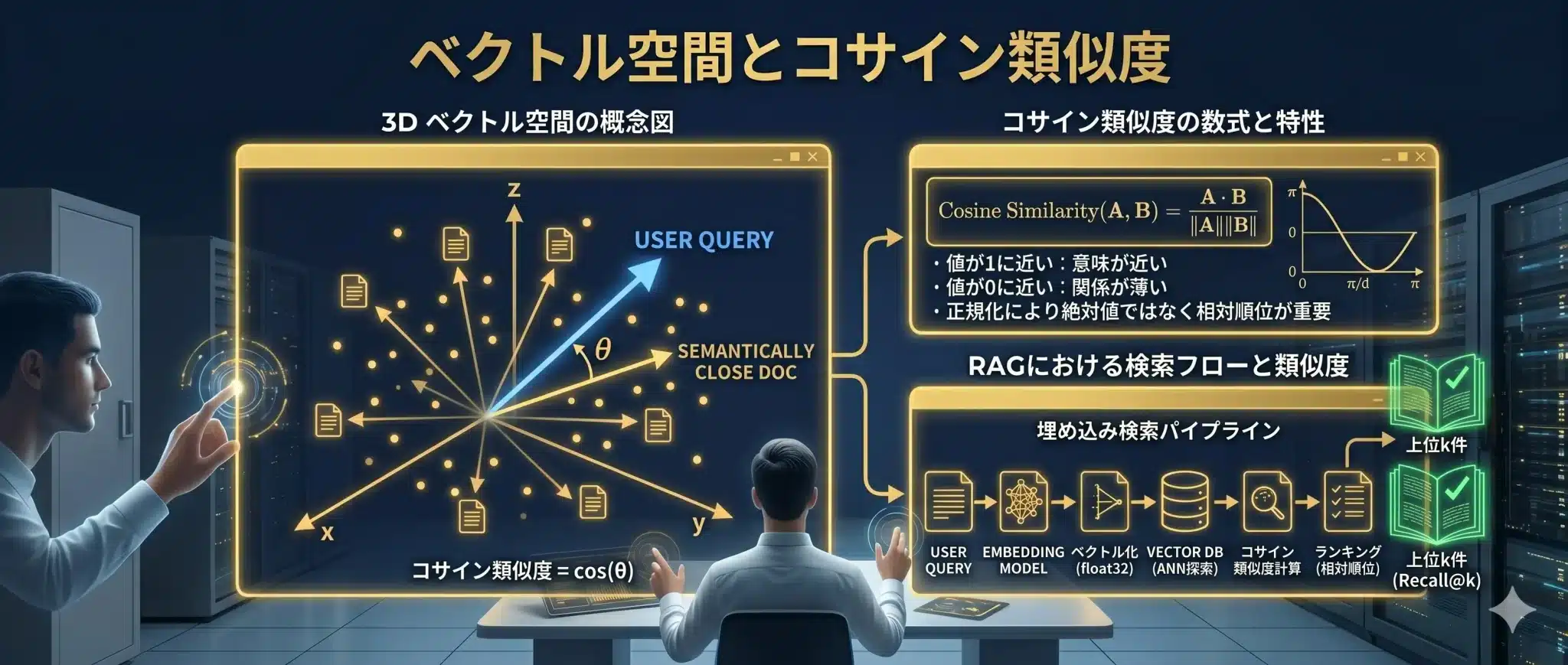
Embeddingされた文章は、多次元ベクトル空間の一点として表現されます。意味が近い文章は近い位置に置かれ、意味が遠い文章は離れた位置に置かれます。
類似度の計算では、コサイン類似度がよく使われます。これは、2つのベクトルの向きがどれだけ近いかを見る指標です。文章の長さそのものより、意味の方向性を比較しやすいという利点があります。
コサイン類似度のイメージ
- 値が1に近い:意味が近い
- 値が0、またはそのモデルの通常レンジの下限に近い:関係が薄い
※数学的には-1まで取り得ますが、実務のテキストEmbeddingではモデルや正規化方式によってスコア分布が偏ります。そのため、絶対値そのものよりも、同じ条件で比較したときの相対順位が重要です。
ANNとHNSW
文書が数百件であれば、すべてのベクトルと比較しても問題ありません。しかし、RAGでは数万、数百万、場合によっては数億のチャンクを扱います。すべてを毎回比較するのは現実的ではありません。
そこで使われるのが、ANN(Approximate Nearest Neighbor)、つまり近似最近傍探索です。厳密な最近傍を全件探索するのではなく、十分に近い候補を高速に見つけます。Vector DBでよく使われるHNSW(Hierarchical Navigable Small World)は、グラフ構造を使って近い候補へ素早くたどり着く代表的な方式です。
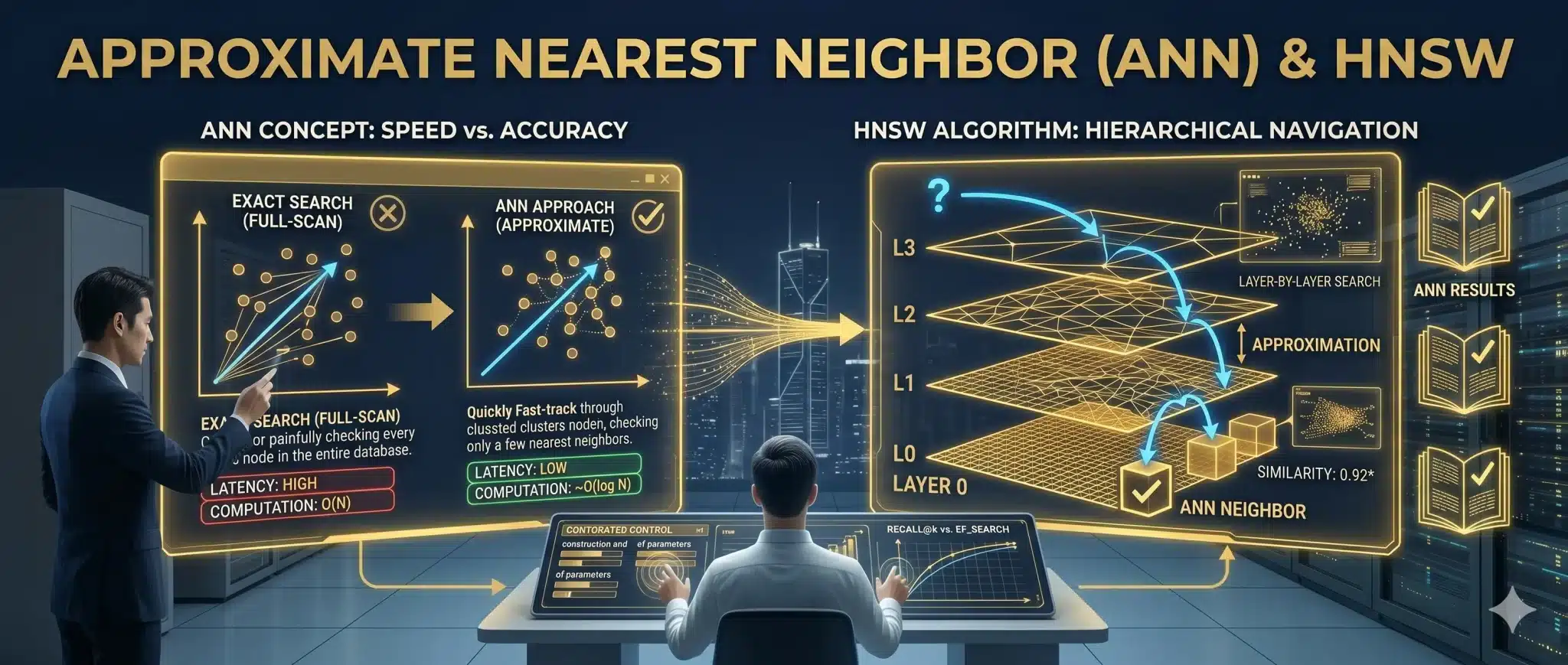
上の図は、膨大な知識データからユーザーの質問に「似た情報」を高速に探す技術(近似最近傍探索、ANN)と、その代表的なアルゴリズム「HNSW」を解説しています。全てのデータを正確にチェックする「厳密検索」は時間がかかりすぎます(左下)。そこで、少しの正確性を犠牲にして、圧倒的な検索速度を得る技術が「ANNアプローチ」です(左上)。
図の右側は、その代表的手法「HNSW」です。HNSWは層を重ねたグラフ構造を利用し、データが疎(少ない)な上層から大まかに、層を降りるにつれて精緻にターゲット(ANNネイバー)へ近づく「階層的ナビゲーション」を行います。この上層から下層への移動により、探査範囲を劇的に減らし、数百万件の知識からコンマ秒単位で関連情報を検索することを可能にします。
Vector DBや検索基盤の選び方は、次工程の記事である ベクトルDB完全比較とRAG最新活用 で詳しく扱います。
チャンキングは前工程として扱う
Embeddingの品質は、前工程であるチャンキング設計にも影響されます。見出し、表、FAQ、手順、条文を壊したチャンクをどれだけ高性能なモデルでベクトル化しても、検索品質は安定しません。
ただし、本記事ではチャンキングの手法そのものは深掘りしません。Late Chunkingも、Embeddingとチャンキングの境界にある重要技術ですが、詳細は RAGチャンキング最適化 に譲り、本記事では「長文文脈を保持しやすいEmbedding関連技術」として短く扱います。
実務ではどう判断するか
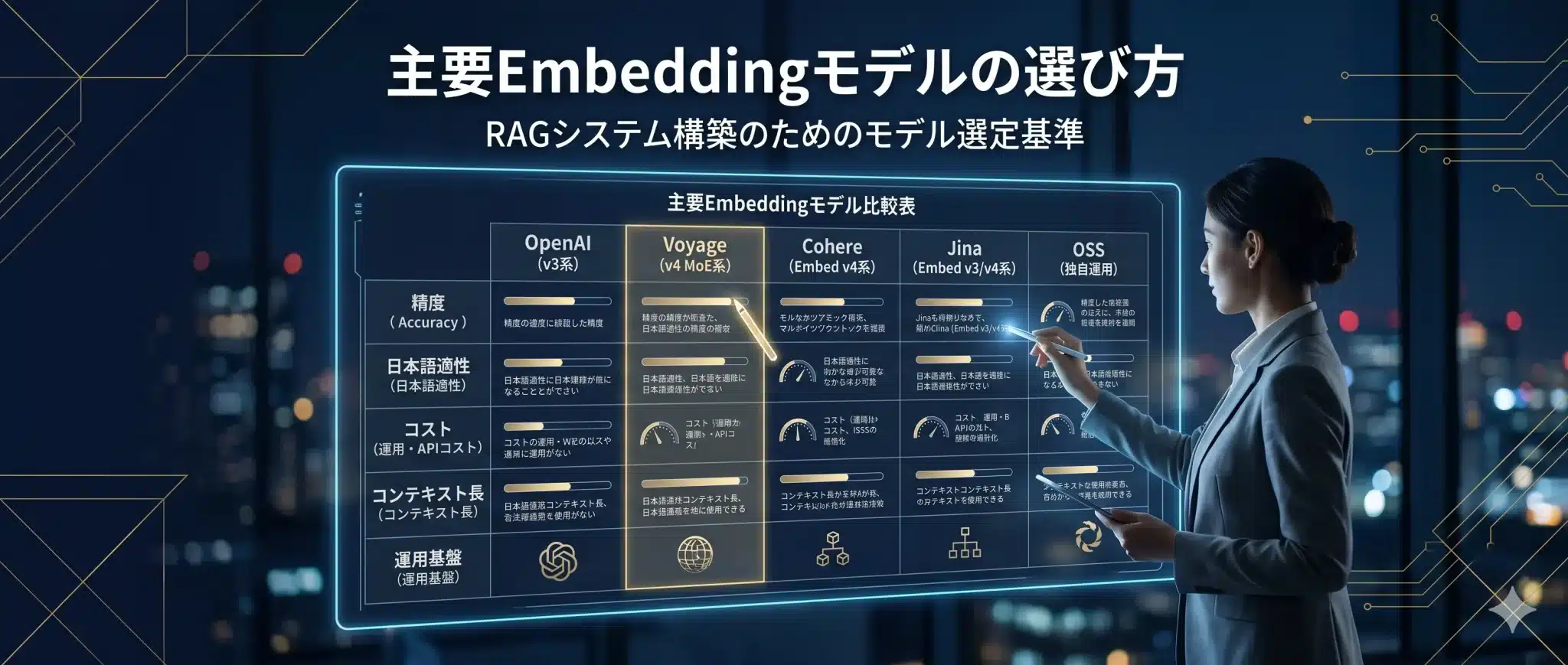
Embeddingモデルは、精度・日本語適性・次元・コスト・運用基盤を合わせて選ぶべきである。
Embeddingモデル選定では、「ベンチマークで一番高いモデル」を選べばよいわけではありません。RAGで大切なのは、自社のデータ、自社の質問、自社の運用制約で安定して検索できることです。
主要Embeddingモデルの選び方
| 候補 | 特徴 | 向いている用途 | 注意点 |
|---|---|---|---|
| OpenAI text-embedding-3系 | API導入が容易で、text-embedding-3-smallは1536次元、text-embedding-3-largeは3072次元が標準。dimensions指定で低次元出力も可能 |
OpenAI基盤のRAG、汎用検索、PoCから本番まで | 社内固有語や専門領域では、自社評価セットで確認が必要 |
| Voyage 4系(voyage-4-large / voyage-4 / voyage-4-lite) | 32,000トークン級のコンテキスト長、256/512/1024/2048次元、量子化に対応。voyage-4-largeはMoEアーキテクチャを採用し、共有Embedding空間により、重いモデルで文書インデックスを構築しつつ、軽いモデルでクエリ検索を行う非対称検索も設計しやすい | 長文RAG、法律・金融・コードなど検索品質を重視する用途。高精度な文書Embeddingと軽量なQuery Embeddingを組み合わせたい場合 | 2025年2月にMongoDBがVoyage AIの買収を発表。MongoDB Atlas等との統合が進む一方、Voyage AI APIも継続されているため、採用時は利用基盤とサポート体制を確認する |
| Cohere Embed 4 | テキスト・画像・インターリーブ入力に対応するマルチモーダルEmbedding。最大128kトークンのコンテキスト長に対応し、256/512/1024/1536次元とfloat/int8/uint8/binary/ubinary形式を選択できる | PDF、画像混在文書、グローバル・多言語文書検索、ドキュメント理解 | 提供基盤ごとに利用可能な仕様や制限を確認する |
| Jina Embeddings | v4はテキスト・画像を統合したマルチモーダルEmbedding、v5 textは軽量なテキスト特化ライン、v5 omniはテキスト・画像・音声・動画を扱うマルチモーダルラインとして展開されている | 長文検索、Late Chunking検証、テキスト・画像・音声・動画を単一インデックスで扱うマルチモーダルRAG、OSS/自前運用を含む検討 | モデルごとにライセンス、商用利用条件、コンテキスト長、次元数、推論コストが異なるため、採用前に確認する |
| OSS Embeddingモデル | 自社環境で運用でき、データガバナンスに強い | 機密データ、閉域環境、コスト制御が必要なRAG | 運用・GPU・評価・チューニングの負担が増える |
この表は「絶対的なランキング」ではありません。モデルの優劣は、言語、データ形式、質問タイプ、評価セットによって変わります。最終判断は、自社データでの検索評価で決めるのが基本です。
非対称検索とは、文書側は高精度な大きいモデルで一度だけEmbeddingし、クエリ側は低コスト・低レイテンシの小さいモデルでEmbeddingする設計です。Voyage 4系のように共有Embedding空間を持つモデル群では、両者を同じベクトル空間で比較できるため、精度と運用コストの両立を狙いやすくなります。
なお、Voyageには文脈化チャンクEmbedding向けの voyage-context-3 もあります。これは通常のEmbeddingモデル比較というより、チャンキングとEmbeddingの境界にある関連技術として扱うのが自然です。
次元数とコスト設計
Embeddingの次元数は、検索品質だけでなく、ストレージ、メモリ、検索速度、Vector DB費用に直結します。高次元にすれば常に良いわけではありません。
たとえば、OpenAIのtext-embedding-3-largeは標準で3072次元、text-embedding-3-smallは1536次元です。一方、Voyage 4系では、256、512、1024、2048次元のように柔軟な出力次元を選べます。Cohere Embed 4も、256〜1536次元の出力を選べます。
| 判断軸 | 高次元が有利なケース | 低次元が有利なケース |
|---|---|---|
| 検索精度 | 専門用語、長文、多様な質問を扱う | FAQや短文中心で検索対象が限定的 |
| コスト | 精度最優先でコスト許容度が高い | 大量チャンクを保存し、検索回数も多い |
| 速度 | 多少遅くても精度を優先する | 低レイテンシが必要 |
| 運用 | 評価・監視・改善体制がある | PoCや初期導入で早く検証したい |
実務では、いきなり最高次元で本番化するより、まず標準次元でベースラインを作り、次に低次元化や圧縮を評価するのが安全です。
Matryoshkaと量子化

高次元Embeddingは検索品質に寄与しますが、ストレージと検索コストが増えます。そこで重要になるのが、Matryoshka Embeddingsや量子化です。
Matryoshka Embeddingsは、1つのベクトルの先頭側に重要な情報を集め、短い次元に切り詰めても検索品質を保ちやすくする考え方です。Voyage 4シリーズでは、このMatryoshka Representation Learning(MRL)を前提に、256〜2048次元を選べる設計になっています。
たとえば、OpenAIの text-embedding-3-large は標準で最大3,072次元のEmbeddingを生成しますが、dimensions パラメータを指定することで、1,024次元などの低次元ベクトルを取得できます。これは、検索品質とストレージコストのバランスを取る実務上の重要な設計ポイントです。
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-large",
input="経費精算の申請方法を教えてください。",
dimensions=1024
)
embedding = response.data[0].embedding
print(f"ベクトルの次元数: {len(embedding)}")
このように、モデル側が低次元出力に対応していれば、開発者が自前でPCAなどの次元削減を行わなくても、保存容量や検索コストを抑える設計が可能です。なお、実運用では256、512、1024、フル次元などを同じ評価セットで比較し、Recall@kやMRRの低下幅を確認します。
Binary Quantizationやint8/uint8量子化は、ベクトルの数値表現を軽くする技術です。これにより、保存容量や検索速度の改善が期待できます。ただし、圧縮は情報を落とす処理でもあるため、単体で使うのではなく、候補抽出後にフル精度ベクトルやRerankerで再評価する構成が現実的です。
実務での考え方
- まず標準次元・floatベクトルでベースラインを測る。
- 次に512次元や256次元などへ落として、Recall@kとMRRを比較する。
- 大量データでは量子化で候補抽出し、Rerankerや高精度ベクトルで再順位付けする。
Hybrid Searchにおけるスコア統合
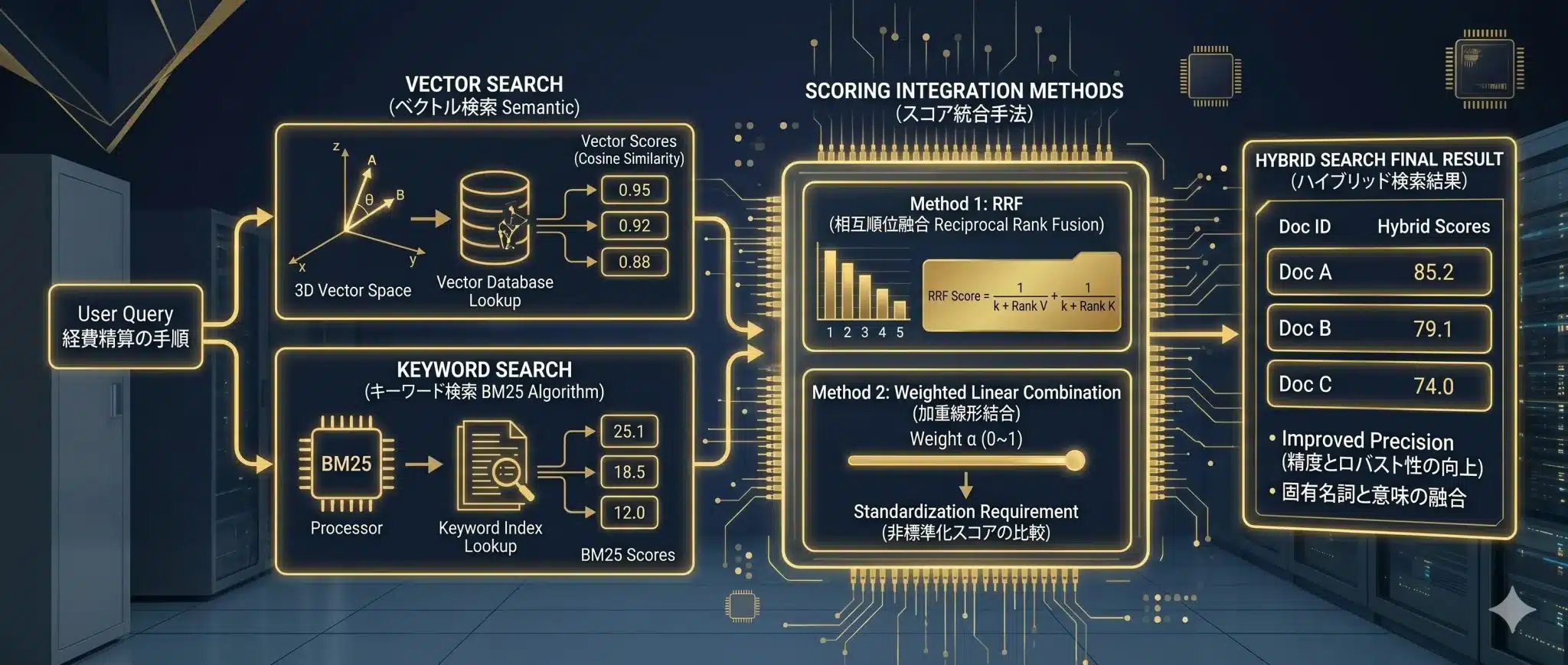
Embedding検索は意味の近さに強く、BM25は製品番号、法令番号、固有名詞などのキーワード一致に強い検索です。両者を組み合わせるHybrid Searchでは、ベクトル類似度とBM25スコアの単位が異なるため、単純に足し算するのではなく、順位を使って統合する方法がよく使われます。
代表例が RRF(Reciprocal Rank Fusion:相互順位融合) です。RRFは各検索手法での順位をもとに統合スコアを作り、複数の検索結果で上位に出る文書を優先します。
![\[RRF\_Score(d) = \sum_{m \in M} \frac{1}{k + r_m(d)}\]](https://arpable.com/wp-content/ql-cache/quicklatex.com-309973a9b8af8a1efab8de5ab97fef1d_l3.png "Rendered by QuickLaTeX.com")
ここで M は検索手法の集合、r_m(d) は手法 m における文書 d の順位、k は順位差の影響を調整する定数です。Hybrid Searchの詳細は、Vector DB / Hybrid Search記事で扱います。
Rerankerとの役割分担
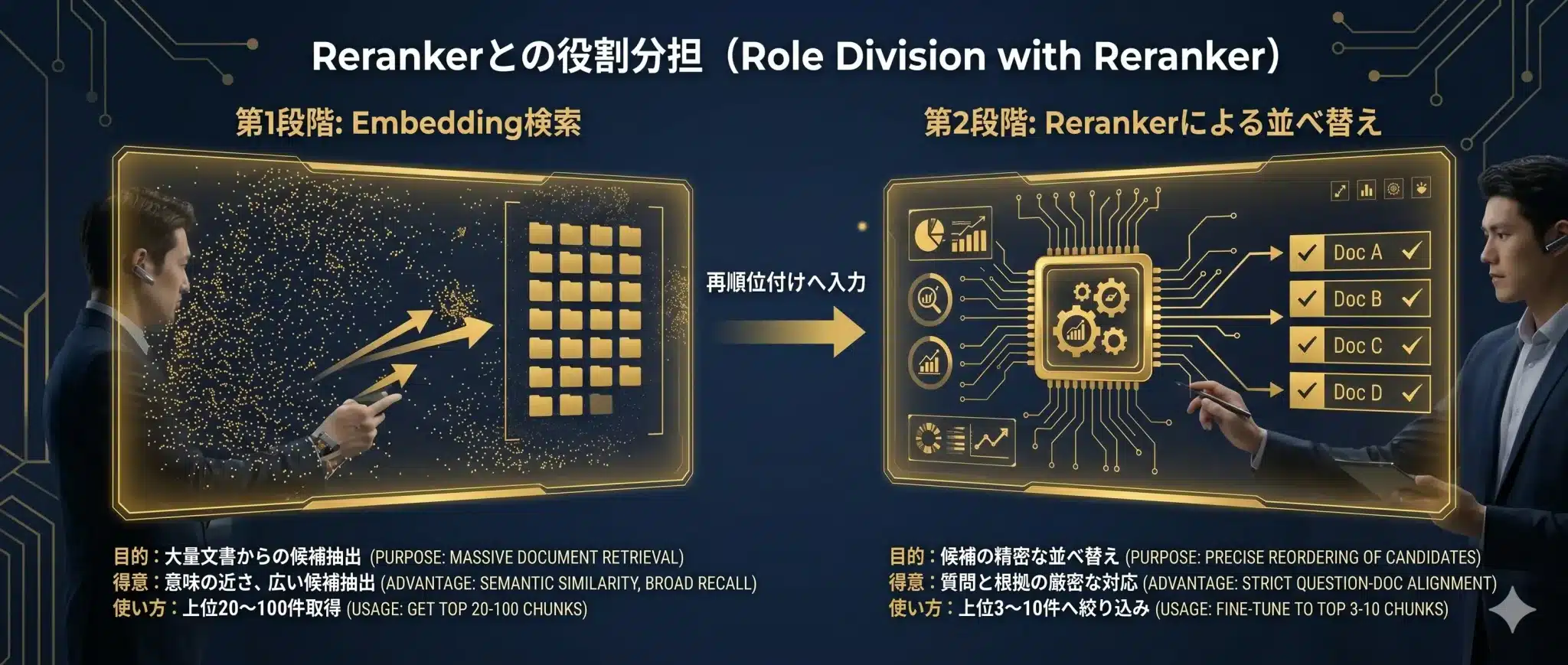
Embedding検索は、候補を広く拾う第1段階として非常に有効です。しかし、Embedding検索だけで最終回答に使う根拠を決めると、似ているが微妙に違う文書が混ざることがあります。
そこで使うのがRerankerです。Rerankerは、検索で取ってきた上位候補を、質問と文書の組み合わせとして再評価し、より回答根拠に近い順番へ並べ替えます。
| 役割 | Embedding検索 | Reranker |
|---|---|---|
| 目的 | 大量文書から候補を高速に拾う | 候補を精密に並べ替える |
| 得意 | 意味の近さ、広い候補抽出 | 質問と根拠の厳密な対応 |
| 弱点 | 似ているが違う文書を混ぜやすい | 対象候補が多いとコストが上がる |
| 使い方 | 上位20〜100件を取得 | 上位3〜10件へ絞る |
実務では、Embedding検索で広く拾い、Rerankerで絞る2段階構成が安定します。特に、規程、契約書、マニュアル、FAQのように「似た文書が多い」領域では効果が出やすいです。
評価指標:モデル名ではなく検索結果で判断する
Embedding最適化では、モデル名やベンチマークだけで判断しないことが重要です。自社の質問セットを作り、検索結果がどの程度正しいかを測ります。
| 指標 | 見るもの | 実務での使い方 |
|---|---|---|
| Recall@k | 上位k件に正解根拠が含まれるか | RAGでは最重要。まず取りこぼしを減らす |
| Precision@k | 上位k件のうち関連文書がどれだけあるか | ノイズが多い検索結果を見つける |
| MRR | 正解根拠が何位に出るか | 上位に根拠が来るかを評価する |
| NDCG | 順位と関連度を合わせて見る | 複数の関連文書がある検索で使う |
| Faithfulness | 回答が取得根拠に忠実か | 検索後の生成品質まで見る |
評価は、Embeddingモデル単体ではなく、チャンキング、検索方式、Reranker、LLM、プロンプトまで含めたパイプライン全体で見る必要があります。
一次情報からどこまで言えるか

一次情報から言えるのは、最新モデル名よりも、用途別に評価して選ぶ姿勢が重要ということである。
OpenAIの公式ドキュメントでは、text-embedding-3-smallが1536次元、text-embedding-3-largeが3072次元であり、dimensionsパラメータで出力次元を調整できることが示されています。
Voyage AIの公式情報では、Voyage 4シリーズとして voyage-4-large、voyage-4、voyage-4-lite などが示され、共有Embedding空間により、用途に応じてクエリ側と文書側のモデルを組み合わせやすい設計が打ち出されています。MongoDBによるVoyage AI買収後も、VoyageのEmbedding / Rerankerは独立APIやクラウドマーケットプレイス経由で継続提供されており、MongoDB Atlasとの統合オプションが増えた形に近いと捉えられます。
Cohere Embed 4は、テキスト・画像・インターリーブ入力に対応するマルチモーダルEmbeddingモデルとして提供され、最大128kトークンのコンテキスト長、複数次元、複数量子化形式を扱えることが公式情報で確認できます。
Jina AIは、v4でテキスト・画像を扱うマルチモーダルEmbeddingを提供し、v5 textでは軽量なテキスト特化ライン、v5 omniではテキスト・画像・音声・動画を扱うマルチモーダルラインへ展開しています。
Voyage AIやCohere、Jinaの情報を並べて見ると、どのベンダーも「長文コンテキスト」「柔軟な次元数」「量子化」「Matryoshka」「マルチモーダル」「Reranker連携」といった設計オプションを軸にモデルを整理していることが分かります。
一次情報から見える実務上の結論は、「ベンダーごとの最新モデル名」を追いかけることではなく、自社データで評価し、次元・圧縮・検索方式・Rerankerをまとめて設計することです。
まとめ
Embedding最適化は、RAGの検索品質と運用コストを同時に設計するための中核工程である。
RAGにおけるEmbeddingは、テキストを意味のベクトルへ変換し、質問と文書の近さを計算できるようにする技術です。しかし、実務で重要なのは、単に高性能モデルを使うことではありません。
モデル選定、日本語・専門用語対応、次元数、圧縮、距離尺度、Vector DB、Hybrid Search、Reranker、評価指標を組み合わせて初めて、安定したRAG検索になります。
チャンキングは前工程、Embeddingは意味表現、Vector DBは検索基盤、Rerankerは最終順位付けです。それぞれの役割を分けて設計することで、RAGの精度改善は再現性のある取り組みに変わります。
Key Takeaways(持ち帰りポイント)
- Embeddingは、テキストを意味のベクトルへ変換し、RAG検索の土台を作る技術である。
- モデル選定は、汎用ベンチマークではなく、自社データと質問セットで評価する。
- 次元数、Matryoshka、量子化は、検索精度とコストのバランスを取る重要な設計要素である。
- Embedding検索だけで完結させず、Hybrid SearchやRerankerと組み合わせると安定しやすい。
専門用語まとめ
- Embedding
- テキストや画像などを数値ベクトルに変換し、意味的な近さを計算できるようにする技術。
- ベクトル
- 複数の数値で構成される表現。RAGでは文章やチャンクの意味を数値の並びとして表す。
- コサイン類似度
- 2つのベクトルの向きの近さを測る指標。テキスト検索では意味の近さを見るためによく使われる。
- Matryoshka Embeddings
- ベクトルの一部の次元だけを使っても検索性能を保ちやすくする学習・表現手法。
- 量子化
- ベクトルの数値表現を軽量化し、保存容量や検索速度を改善する技術。
- RRF(Reciprocal Rank Fusion)
- 複数の検索手法の結果を、スコアの絶対値ではなく順位にもとづいて統合する手法。
- Reranker
- Embedding検索で取得した候補を、質問との関連度に基づいて再順位付けするモデルまたは処理。
参考文献 / 出典
一次情報 / 公式ドキュメント
- OpenAI API Documentation – Vector embeddings
- Voyage AI Documentation – Text Embeddings
- Voyage AI – The Voyage 4 model family
- Voyage AI – Introducing voyage-context-3
- MongoDB – Shared Embedding Space: Optimizing AI Retrieval with Voyage 4
- MongoDB – Acquisition of Voyage AI
- Cohere – Introducing Embed 4
- AWS Documentation – Cohere Embed v4
- Jina AI – Embedding API
- Jina AI – jina-embeddings-v5-text-small
- Jina AI – jina-embeddings-v5-omni
- Elastic – Jina embeddings v5-omni: All media, one index
- Microsoft Learn – Reciprocal Rank Fusion in Azure AI Search
- Matryoshka Representation Learning – arXiv
次に読むならこの3本
補足Q&A
Q1.
RAGのEmbeddingとは一言で何ですか?
A1.
質問と文書を意味の近さで比較できるように、テキストを数値ベクトルへ変換する技術です。
RAGでは、ユーザーの質問と文書チャンクをEmbeddingし、ベクトル空間上で近い文書を検索してLLMに渡します。
Q2.
Embeddingモデルはどの基準で選べばよいですか?
A2.
精度だけでなく、日本語・専門用語・次元数・コスト・運用基盤で選ぶべきです。
汎用ベンチマークだけではなく、自社文書と実際の質問セットでRecall@k、MRR、NDCGを比較することが重要です。
Q3.
RerankerはEmbedding検索と何が違いますか?
A3.
Embedding検索は候補を広く拾い、Rerankerは候補を精密に並べ替える役割です。
実務では、Embedding検索で上位候補を取得し、Rerankerで回答根拠にふさわしい順番へ再順位付けする2段階構成が安定します。
更新履歴
- 2026年5月21日:v11.3に適合し、Voyage 4・Cohere Embed 4・Jina v5・RRFを反映。
- 2025年10月25日:最新Embeddingモデル、Matryoshka、Binary Quantization、Late Chunkingを追加。
- 2024年9月26日:初版公開。








