


※本記事は継続的に最新情報へアップデートしています。
2026年のRAGチャンキングは、「何文字で切るか」から「文書構造をどう読み、どの知識単位に再編成するか」へ軸足が移った段階である。
多くの企業で、「検索結果は一見正しいのに、LLMの回答だけが微妙に外れる」原因は、固定長チャンキングが見出し・条文・表・FAQ・コードの意味境界を壊しているところにある。
本記事は、構造認識型・可変長チャンキングを中心に、固定長、Recursive、Semantic、Parent-Child、Late Chunking、RAPTOR、GraphRAG連携までを実務判断できる形で整理するガイドである。
✅ 先に結論
RAGチャンキング最適化とは、非構造化データを直接細切れにする作業ではありません。正しく抽出・構造化された文書を、検索と生成に適した可変長の知識単位へ再編成する設計です。
- ポイント1:最初に確認すべきは、OCR・パース・見出し・表・メタデータが壊れていないかです。壊れた抽出結果は、チャンキングでは救えません。
- ポイント2:基本は固定長ではなく、見出し・段落・表・FAQ・手順・コードなどの構造を読んだ可変長チャンキングです。
- ポイント3:単一文書の文脈分断はRecursive / Semantic / Parent-Childで補い、文書横断の関係性が必要な場合はGraphRAGを検討します。

何が変わったのか

チャンキングは固定長分割から、文書構造を読んだ可変長の知識設計へ変化している。
かつてのRAGでは、文書を500〜1,000トークン程度に固定長で切り、少しオーバーラップを入れてベクトル化する方法がよく使われていました。PoCではこの方法でも十分に見えることがあります。しかし、本番運用に近づくほど、固定長チャンキングの限界が見えてきます。
たとえば、見出しと本文が別々のチャンクに分かれる。表のタイトルと表本体が分離する。FAQの質問と回答が切り離される。手順書の前提条件と操作手順が別チャンクになる。規程文書の条文と例外条件が分断される。コードと説明文が別々に検索される。
このような状態では、EmbeddingモデルやVector DBを高性能化しても、検索対象となる知識単位そのものが壊れています。RAGの回答が不安定になる原因は、LLMだけではありません。何を1単位として検索・生成に渡すかが、回答品質の土台を決めます。
RAG全体の設計や導入ロードマップは、まず RAG完全ガイド を参照してください。本記事では、その中でも「チャンキング手法」に絞って、実務でどう選ぶべきかを整理します。
固定長チャンキングから構造認識型チャンキングへ
| 観点 | 従来の固定長中心 | 2026年版の実務設計 |
|---|---|---|
| 分割基準 | 文字数・トークン数 | 見出し、段落、表、FAQ、手順、コード、条文などの構造 |
| チャンク長 | ほぼ一定 | 意味単位に応じた可変長 |
| 文脈保持 | オーバーラップで補う | 親子チャンク、見出し継承、メタデータ、Late Chunkingで補う |
| 主な目的 | LLMやEmbeddingに入るサイズへ切る | 検索と生成に使える知識単位へ再編成する |
| 評価 | 体感で判断しがち | Context Precision / Recall、Faithfulnessなどで比較 |
ここで重要なのは、固定長チャンキングを否定することではありません。固定長+オーバーラップは、今でもベースラインとして有効です。ただし、それだけで本番品質まで持っていくのは難しくなっています。まず固定長で基準値を測り、文書構造に合わせて段階的に高度化する、という進め方が現実的です。
なぜ今重要なのか

RAGの精度は、Embeddingの前に「何を1単位として埋め込むか」で大きく変わる。
RAGの改善でよくある誤解は、検索精度をEmbeddingモデルやVector DBだけで語ってしまうことです。もちろんEmbeddingや検索基盤は重要です。しかし、その前に「どのテキストを1つの意味単位として埋め込むか」が決まっていなければ、検索の前提が崩れます。
たとえば、次のような文書を考えてみます。
元文書の例
第3条:本サービスは標準プランで利用できます。ただし、医療・金融・個人情報を含む業務で利用する場合は、事前に管理部門の承認を得る必要があります。承認なしに利用した場合、当社は当該利用を停止できるものとします。
この文章を途中で切ると、「標準プランで利用できます」だけが検索され、「ただし」以降の重要な例外条件が抜ける可能性があります。RAGでは、このような境界の誤りが回答の誤りに直結します。
つまり、チャンキングは単なる前処理ではありません。検索可能な知識単位を設計する工程です。RAGの精度改善を考えるなら、EmbeddingやRerankerの前に、チャンクの粒度と意味境界を見直す必要があります。
チャンキングの3つのジレンマ
チャンキングには、避けられない3つのジレンマがあります。
| ジレンマ | 小さく切りすぎる場合 | 大きく切りすぎる場合 | 実務上の対策 |
|---|---|---|---|
| 検索精度 | 文脈が失われ、意味が断片化する | ノイズが増え、質問と関係ない情報も混ざる | 見出し・段落・文単位を優先し、必要に応じて親子チャンクを使う |
| 回答品質 | LLMに渡す根拠が不足する | LLMが複数根拠に迷いやすい | 検索用チャンクと回答用コンテキストを分ける |
| コスト | チャンク数が増え、インデックス・検索コストが増える | 1チャンクあたりのトークンが増え、生成コストが増える | 評価指標で最小十分な粒度を探す |
このため、万能なチャンクサイズはありません。文書タイプ、質問タイプ、Embeddingモデル、検索方式、Reranker、LLMのコンテキスト長によって最適解は変わります。
RAGの精度が出ない原因全体を確認したい場合は、RAG精度改善ガイド を参照してください。本記事は、その中の「チャンク設計」に特化した実装判断ガイドです。
どう捉えるべきか
チャンキングは文字数調整ではなく、文書を検索可能な知識単位へ再構成する工程である。
RAGチャンキングを正しく理解するには、まず「前工程」と「主題」を分ける必要があります。
チャンキング以前には、PDF、Word、HTML、Excel、画像、議事録などから文字列や表、見出し、ページ番号、日付、版数、権限情報を抽出する工程があります。ここが壊れていると、どれだけ高度なチャンキングをしても品質は上がりません。
ただし、本記事の主題はETLやOCRではありません。ここでは、正しく抽出・構造化された文書を前提に、どの粒度で、どの手法で、どんなメタデータを持たせてチャンク化するかを扱います。
チャンキング以前に確認すべき前提
以下の項目が崩れている場合、チャンキングの前にデータ抽出・構造化工程へ戻るべきです。
| 確認項目 | 問題例 | チャンキングへの影響 |
|---|---|---|
| 文字抽出 | OCR誤認識、文字化け、改行崩れ | 意味単位を正しく判定できない |
| 見出し階層 | H2/H3、章番号、条番号が消える | 見出し単位のチャンク化やメタデータ付与ができない |
| 表・図表 | 表の列関係、注釈、キャプションが分離する | 表だけ、または説明だけが検索される |
| 版数・更新日 | 旧版と最新版が混在する | 古い情報を根拠に回答する |
| アクセス権限 | 権限の異なる文書が同じ検索対象に入る | 回答してはいけない情報を検索するリスクがある |
この前提を確認したうえで、チャンキングに進みます。チャンキングは「壊れたデータを直す魔法」ではなく、構造化された文書を検索可能な知識単位へ再編成する工程です。
チャンキングの基本モデル
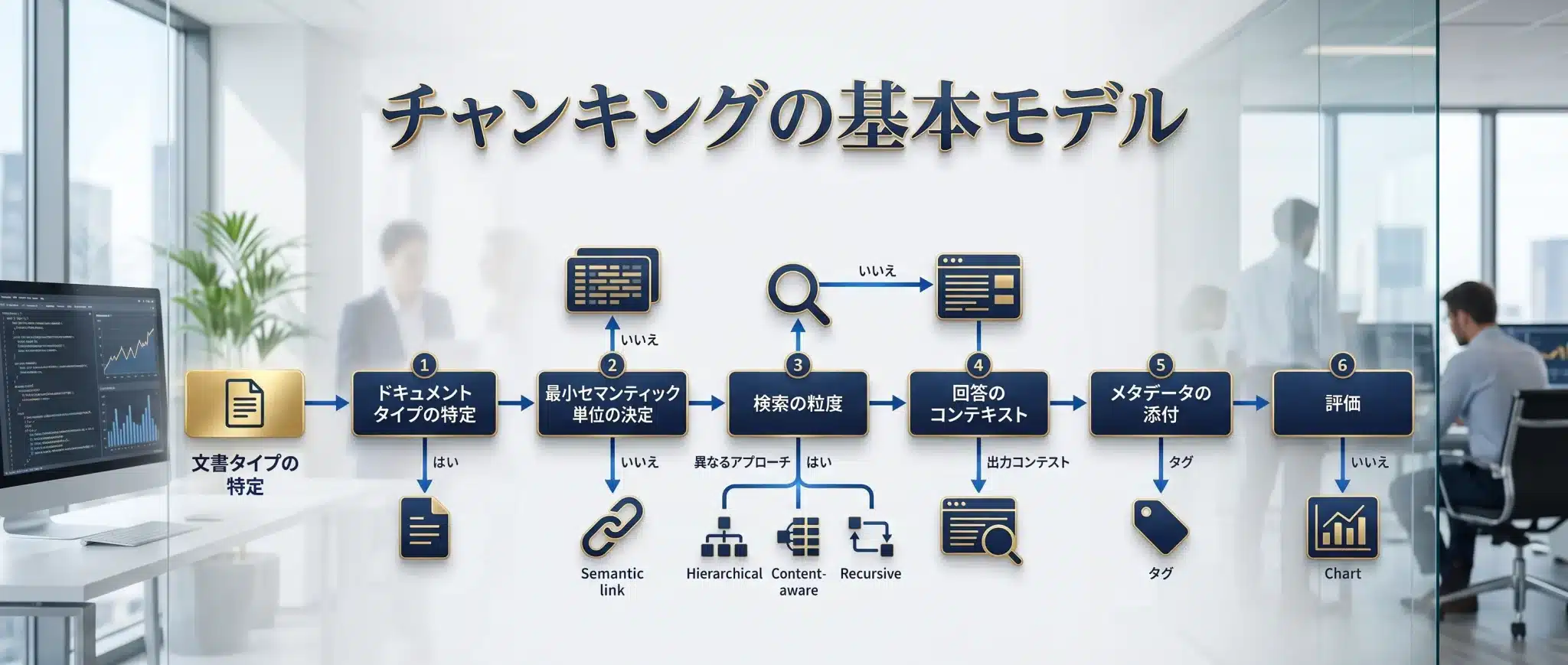
実務では、次の順番で考えると迷いにくくなります。
- 文書タイプを判定する:FAQ、マニュアル、規程、契約書、論文、コード、議事録など。
- 意味の最小単位を決める:質問+回答、手順+注意点、条文+例外、表+注釈など。
- 検索用の粒度を決める:小さく取りたいのか、文脈ごと取りたいのか。
- 回答用の文脈を決める:検索で当たったチャンクの周辺、親チャンク、見出し階層を渡すか。
- メタデータを付ける:文書名、章、ページ、日付、版数、権限、親IDなど。
- 評価する:Context Precision / Recall、Faithfulness、Answer Relevancyで比較する。
チャンキングの本質は、切ることではなく、検索・生成で再利用できる知識単位を設計することです。
実務ではどう判断するか
最初は固定長を基準にし、文書構造と失敗症状に応じて段階的に高度化するべきである。
チャンキング手法は多くありますが、すべてを最初から導入する必要はありません。実務では、まずシンプルなベースラインを作り、評価結果を見ながら必要な手法だけを追加します。
代表的なチャンキング手法
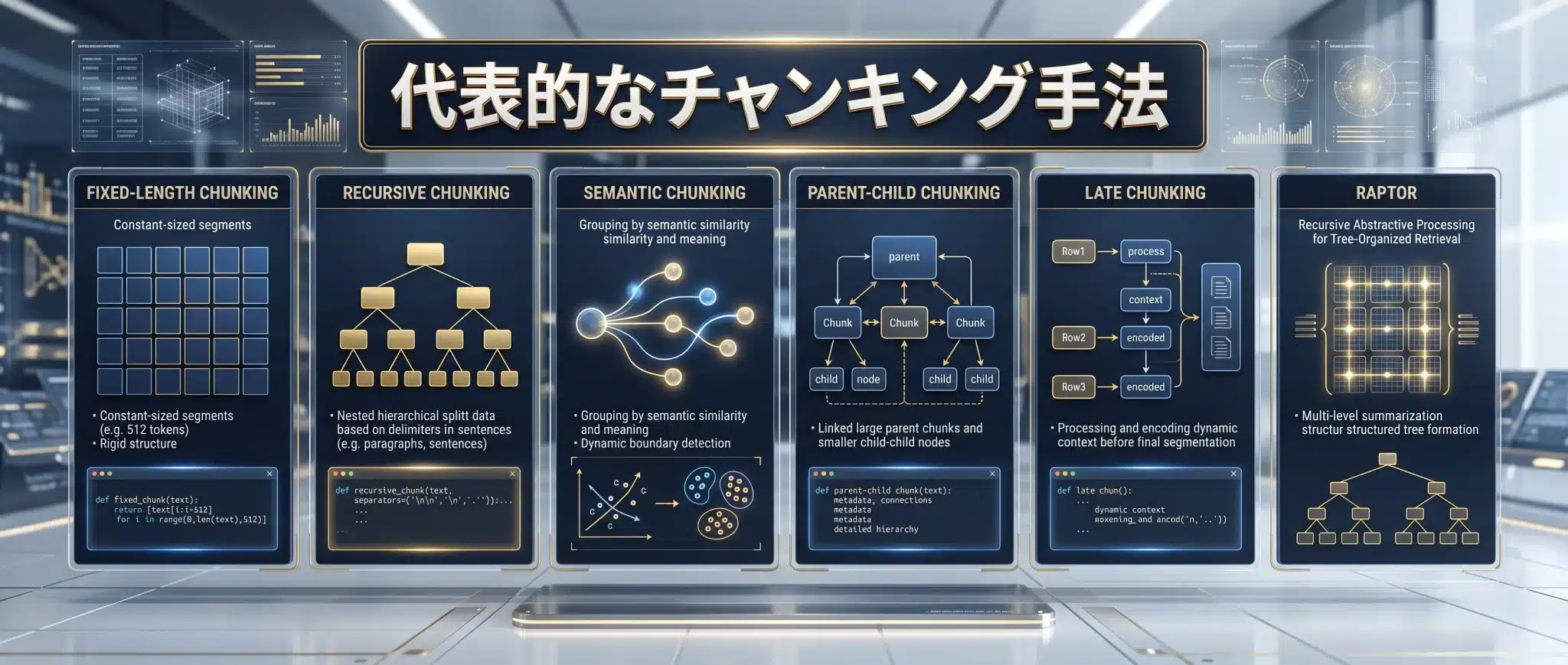
| 手法 | 概要 | 向いている文書 | 注意点 |
|---|---|---|---|
| 固定長チャンキング | 一定の文字数・トークン数で切る | 構造が弱いプレーンテキスト、PoC、短期検証 | 意味境界を壊しやすい。必ず評価用ベースラインとして扱う |
| 固定長+オーバーラップ | 前後の文脈を重ねて分割する | 一般的なテキスト、まず動かすRAG | オーバーラップを増やしすぎると重複とコストが増える |
| Recursive Chunking | 段落、改行、句点、単語などの優先順位で再帰的に切る | マニュアル、記事、規程、技術文書 | セパレータ設計が重要。日本語では句点・読点・改行を意識する |
| Markdown / Header Chunking | H2/H3などの見出し階層を使って切る | Markdown、HTML、社内Wiki、技術ブログ | 見出し階層が壊れている文書では効果が落ちる |
| Semantic Chunking | 意味の変化点を見て分割する | トピックが混在する長文、会議録、複数テーマ文書 | 計算コストが高く、固定長やRecursiveより常に優れるわけではない |
| Parent-Child Chunking | 検索は小さい子チャンク、回答は大きい親チャンクを使う | マニュアル、規程、契約書、技術仕様書 | 親子ID管理、ドキュメントストア、引用表示の設計が必要 |
| Late Chunking | 長文を先にモデルへ通し、その後チャンク埋め込みを作る | 代名詞や文脈依存が強い中長文 | 長文コンテキスト対応Embeddingモデルが必要。Jina AIのLate Chunkingでは、長文対応Embeddingモデルを使い、1回の長文エンコードから複数チャンクの埋め込みを生成する考え方が示されている |
| RAPTOR | チャンクをクラスタリングし、要約を再帰的に作る階層型手法 | 長大な報告書、論文群、抽象質問と具体質問が混在する文書 | 要約生成コスト、階層管理、評価設計が重くなる |
| Agentic Chunking | 本記事での便宜的な呼称。LLMが内容を読んで分割やメタデータ付与を判断する、いわゆるagentic RAG / agentic workflowsに近い手法 | 法律、医療、金融など高価値・高リスク文書 | コストと再現性に注意。オフライン前処理向き |
Semantic Chunkingを過信しない
Semantic Chunkingは「意味で切る」ため直感的には優れて見えます。しかし、実務では常に最良とは限りません。公開ベンチマークの一例では、Semantic Chunkingが平均43トークン程度の細かすぎる断片を生成し、Recursive分割より低い精度にとどまったケースも報告されています。
この結果を一般化しすぎるべきではありませんが、少なくとも 「Semanticだから常に高精度」ではない ことは押さえるべきです。Semantic Chunkingは、トピックが極端に混在する文書や、明確な意味境界が重要な文書で試す価値があります。一方で、標準的な業務文書では、RecursiveやHeader-based、Parent-Childの方が安定する場合もあります。
文書タイプ別の実務判断

チャンキング手法は、文書タイプでかなり変わります。以下は、実務での初期判断表です。
| 文書タイプ | 基本方針 | 推奨手法 | 保持すべきメタデータ |
|---|---|---|---|
| FAQ | 質問+回答を1単位にする | Header / Recursive | カテゴリ、質問ID、更新日、対象製品 |
| 手順書 | 前提条件+手順+注意点をセットにする | Recursive / Parent-Child | 手順番号、章、対象システム、版数 |
| 規程・契約書 | 条文+例外+補足を分断しない | Header / Parent-Child / Semantic | 条番号、章、施行日、改定日、権限 |
| 技術ブログ・HTML | H2/H3単位を基本に、長い章だけ分割する | Markdown / Header / Recursive | 見出し階層、URL、公開日、著者 |
| API仕様書 | エンドポイント単位でまとめる | Header / Parent-Child | API名、メソッド、パス、バージョン |
| コード解説 | コードと説明文を切り離さない | Recursive / Code-aware Splitter | ファイル名、関数名、クラス名、行番号 |
| 表中心のPDF | 表タイトル+表本体+注釈を1単位にする | 構造化後にRecursive / Parent-Child | ページ番号、表番号、列名、注釈 |
| 議事録 | 議題、決定事項、TODO、発言要旨で分ける | Semantic / Recursive | 会議名、日付、参加者、議題、担当者 |
ミニストーリー:社内ポリシーQ&Aボットの場合
たとえば、社内規程とFAQを混在させた「社内ポリシーQ&Aボット」を考えてみます。
規程PDFは条文+ただし書きをParent-Childでまとめ、FAQは質問+回答で1チャンクにするだけで、「標準プランで利用できます」だけがヒットして例外条件を落とす、といった典型的な事故の多くは防げます。
同じRAG基盤でも、チャンキング設計を変えるだけで「検索は当たっているのに回答がズレる」状態から、監査で説明可能な回答へ近づけます。CxOやPMが見るべきなのは、モデル名ではなく、どの文書構造をどの知識単位として検索対象にしているかです。
最小コード:構造認識型・可変長チャンキング
以下は、構造認識型チャンキングの最小例です。ポイントは、単純に文字数で切るのではなく、段落、改行、句点、読点、空白の順に分割候補を試すことです。この例では文字数ベースで512前後を目安にし、約15%のオーバーラップで前後文脈を保つ設定にしています。トークン数ベースで制御したい場合は、利用するトークナイザーに合わせて length_function を指定してください。
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 日本語の文章構造を考慮し、改行・句読点で段階的に切り分ける
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=80,
separators=["\n\n", "\n", "。", "、", " "],
)
chunks = text_splitter.split_documents(documents)
for i, chunk in enumerate(chunks):
chunk.metadata["chunk_index"] = i
chunk.metadata["section"] = chunk.metadata.get("section", "unknown")
chunk.metadata["source"] = chunk.metadata.get("source", "unknown")
このコードは完成形ではありません。実務では、PDF、HTML、Markdown、Excelなどの抽出段階で付与したメタデータを引き継ぐ必要があります。chunk_index、section、source、page_number、updated_at、version、access_role などは、検索結果のフィルタリング、引用表示、監査対応に効きます。
メタデータ設計:チャンクに必ず持たせたい情報
チャンキングでは、テキスト本文だけでなくメタデータ設計が重要です。メタデータがないと、最新版だけを検索する、特定部署の文書だけを検索する、引用元を表示する、権限に応じて検索対象を制御する、といった運用が難しくなります。
| メタデータ | 目的 | 例 |
|---|---|---|
| source | 引用元・出典表示 | ファイル名、URL、文書ID |
| section | 見出し階層の復元 | 第2章、料金規程、API仕様 |
| page_number | PDF引用・確認 | p.12、p.45 |
| version / updated_at | 最新版の優先 | v3.2、2026-05-20 |
| access_role | 権限制御 | public、internal、management |
| parent_id | Parent-Child検索 | doc-001-section-03 |
| entity / topic | GraphRAGや絞り込み検索 | 製品名、顧客名、法令名、案件名 |
評価設計:チャンキング手法は比較して決める
チャンキング手法は、理屈だけでは決まりません。同じデータ、同じ質問セット、同じEmbeddingモデル、同じLLMで比較し、どの手法が最も安定するかを確認します。
比較対象: A. 固定長 512 chars / overlap 80 B. Recursive splitter C. Parent-child chunking 評価指標: - Context Precision:検索結果にノイズが少ないか - Context Recall:必要な根拠を取りこぼしていないか - Faithfulness:回答が取得根拠に忠実か - Answer Relevancy:質問意図に合った回答か 判断: 検索漏れが多い → Context Recallを確認 ノイズが多い → Context Precisionを確認 回答が根拠から逸脱する → Faithfulnessを確認 回答が質問に噛み合わない → Answer Relevancyを確認
Ragasなどの評価フレームワークを使う場合も、チャンキングだけを単独で見るのではなく、検索結果と生成回答の両方を確認します。評価の詳細は、RAG精度改善ガイドで扱ったように、検索品質と回答品質を分けて測ることが重要です。
一次情報からどこまで言えるか
一次情報から言えるのは、万能手法ではなく、文書構造と評価に基づく選択が重要ということです。
LangChainのText Splittersでは、多くの用途でRecursiveCharacterTextSplitterから始めることが推奨されています。これは、文脈をなるべく保ちながらチャンクサイズを管理する現実的なベースラインです。
Jina AIのLate Chunkingは、8K以上の長文コンテキストに対応した埋め込みモデルを使い、まず全文を1度だけエンコードして全トークンのベクトル列を得てから、その上で小さいセグメントごとに平均プーリングなどでチャンク埋め込みを生成する手法です。これにより、各チャンクが局所テキストだけでなく文書全体のコンテキストを反映しやすくなります。
RAPTORは、チャンクを再帰的にEmbedding、クラスタリング、要約し、文書の階層的な木構造を作る手法です。長大な文書や、抽象度の異なる質問に対応したい場合に検討できます。
Microsoft GraphRAGでは、まずIndexフェーズで入力テキストをTextUnitに分割し、その単位からEntities、Relationships、Claimsを抽出して知識グラフとコミュニティ階層を構築します。そのうえでQueryフェーズでは、グローバルサマリーやローカルな近傍ノードからコンテキストを組み立てます。
GraphRAGはチャンキングの先にある構造化手段
GraphRAGは、通常のチャンキングの代替ではありません。むしろ、チャンキングやTextUnitを前提として、その中から人物、組織、製品、案件、概念などの関係性を抽出し、文書横断の知識構造へ発展させる手段です。
単一文書内の文脈分断はチャンキングで直し、複数文書をまたぐ関係性はGraphRAGで扱う、という切り分けが実務では分かりやすいです。
| 課題 | 主な対応策 | 判断ポイント |
|---|---|---|
| 見出しと本文が分かれる | Header / Recursive Chunking | 同一文書内の構造を保てば解ける |
| 表と注釈が分かれる | 構造化+Parent-Child | 表・注釈・ページ番号をセットで保持する |
| 条文と例外条件が分断される | Parent-Child / Semantic | 回答用に広い文脈を戻す必要がある |
| 複数文書の人物・組織・案件関係をたどる | GraphRAG | 単純なチャンク検索では関係性が拾えない |
| 検索失敗時に再検索・質問分解したい | Agentic RAG | 検索計画や再試行をエージェントに任せる |
GraphRAGの詳細は、別途 GraphRAG / Knowledge Graph記事 で深掘りするのが適切です。本記事では、GraphRAGを「チャンキングの先にある文書横断の構造化手段」として位置づけます。
よくある失敗
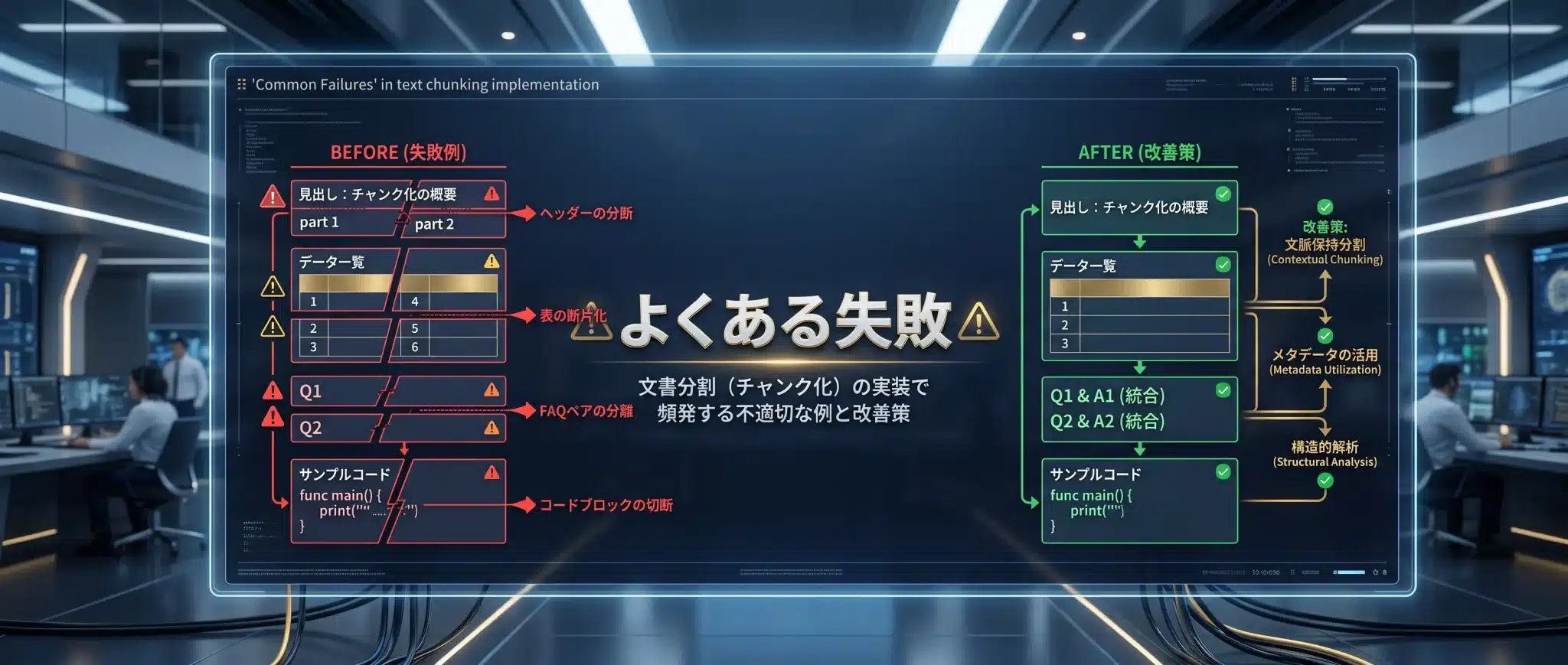
チャンキングの失敗は、検索結果のノイズ、根拠不足、引用ミス、回答の不安定さとして現れる。
RAGのチャンキングでよくある失敗は、手法選定そのものよりも、文書構造を壊してしまうことです。
| 失敗パターン | 症状 | 対策 |
|---|---|---|
| 見出し分断 | 本文だけ検索され、何の話か分からない | 見出しをメタデータ化し、チャンク本文にも継承する |
| 表分断 | 数値だけ検索され、列名や注釈が抜ける | 表タイトル、列名、注釈、ページ番号をセットにする |
| FAQ分断 | 回答だけ検索され、質問意図が消える | 質問+回答を1チャンクにする |
| 条文分断 | 原則だけ回答し、例外条件を落とす | 条文+ただし書き+補足を同一単位にする |
| コード分断 | コードだけ、または説明だけが検索される | コードブロックと説明文をセットにする |
| 長すぎるチャンク | 検索結果にノイズが多く、LLMが迷う | 見出し・段落単位で再分割し、Rerankerを併用する |
| 短すぎるチャンク | 根拠不足で回答が断片的になる | オーバーラップ、Parent-Child、周辺チャンク取得を使う |
| メタデータ欠落 | 最新版・部署・権限・出典で絞れない | source、section、page、version、access_roleを付与する |
特に注意したいのは、「短く切れば検索精度が上がる」と単純に考えることです。検索ヒットの粒度は細かくなりますが、回答に必要な文脈が不足することがあります。逆に、長く切りすぎるとノイズが増えます。チャンキングは、常に検索精度と回答文脈のバランスで考える必要があります。
まとめ
チャンキング最適化の本質は、構造を読み、意味単位で切り、評価で改善することである。
RAGチャンキング最適化とは、文書を一定文字数で切る作業ではありません。正しく抽出・構造化された文書を、検索と生成に適した知識単位へ再編成する設計です。
実務では、まず固定長+オーバーラップでベースラインを作り、次にRecursiveやHeader-basedで構造を反映します。そのうえで、文脈不足が目立つ場合はParent-Child、代名詞や前後文脈が重要な場合はLate Chunking、長大文書や抽象度の異なる質問にはRAPTOR、文書横断の関係性にはGraphRAGを検討します。
最も重要なのは、万能なチャンクサイズを探すことではなく、自社の文書タイプと質問タイプに合わせて、チャンキング手法を評価しながら選ぶことです。
Key Takeaways(持ち帰りポイント)
- チャンキングは文字数調整ではなく、検索可能な知識単位を設計する工程である。
- 構造化に失敗した文書は、チャンキングでは救えない。OCR、表、見出し、メタデータを先に確認する。
- 固定長はベースラインとして有効だが、本番では構造認識型・可変長チャンキングへ進むべきである。
- Parent-Child、Late Chunking、RAPTOR、GraphRAGは、失敗症状に応じて段階的に使う高度化手段である。
専門用語まとめ
- チャンキング
- 文書を検索・生成に使いやすい単位へ分割・再構成する工程。RAGでは、回答品質の土台となる。
- Recursive Chunking
- 段落、改行、句点、読点などの分割候補を順番に試し、なるべく文脈を保ちながらチャンク化する手法。
- Semantic Chunking
- 意味やトピックの変化点を見て分割する手法。多様なテーマが混在する文書で有効な場合がある。
- Parent-Child Chunking
- 検索用の小さな子チャンクと、回答用の大きな親チャンクを分けて管理する手法。
- Late Chunking
- 長文を先にEmbeddingモデルへ通し、その後にチャンク埋め込みを作ることで、文書全体の文脈を保ちやすくする手法。
- RAPTOR
- チャンクをEmbedding、クラスタリング、要約し、再帰的な木構造を作る階層型検索手法。
- GraphRAG
- TextUnitからエンティティや関係性を抽出し、知識グラフとして構造化するRAG高度化手法。
参考文献 / 出典
一次情報 / 公式ドキュメント
- LangChain Documentation – Recursive text splitter
- LangChain Reference – RecursiveCharacterTextSplitter
- Jina AI – Late Chunking in Long-Context Embedding Models
- Jina AI – Embeddings API
- Late Chunking – arXiv
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval – arXiv
- Microsoft GraphRAG Documentation – Dataflow
- Microsoft GraphRAG Documentation – Indexing Methods
- Ragas Documentation
二次情報 / ベンチマーク
次に読むならこの3本
補足Q&A
Q1.
最適なチャンクサイズはいくつですか?
A1.
万能なサイズはありません。
文書タイプ、質問タイプ、Embeddingモデル、検索方式によって変わります。まず固定長+オーバーラップでベースラインを作り、Recursive、Parent-Child、Semanticなどを比較評価するのが現実的です。
Q2.
固定長チャンキングはもう使わない方がよいですか?
A2.
固定長チャンキングは、今でもベースラインとして有効です。
ただし、本番RAGでは固定長だけに依存せず、見出し、段落、表、FAQ、手順、コードなどの構造を反映した可変長チャンキングへ進むべきです。
Q3.
チャンキングの良し悪しはどう評価すればよいですか?
A3.
複数のチャンキング手法を同じ質問セットで比較し、検索品質と回答品質を分けて評価します。
固定長、Recursive、Parent-Childなど複数パターンを用意し、Context Precision、Context Recall、Faithfulness、Answer Relevancyを比較するのが現実的です。Ragasなどを使う場合も、検索品質と回答品質を混同しないことが重要です。
更新履歴
- 2026年5月20日:v11.3に適合し、構造認識型・可変長チャンキング中心へ全面再構成。
- 2025年10月25日:Late Chunking、Parent-Child、RAPTOR、Ragas評価を追加。
- 2024年9月26日:初版公開。








