


Agentic RAGとは?AIエージェントでRAGを強化する実践ガイド
この記事を読むと、従来のRAGの限界と、AIエージェント技術がそれをどう克服するかがわかり、次世代の知識活用システムを構築できます。
執筆者からひと言
こんにちは。30年以上にわたるITエンジニアとしての現場経験を基に、AIのような複雑なテーマについて「正確な情報を、誰にでも分かりやすく」解説することを信条としています。この記事が、皆さまのビジネスや学習における「次の一歩」のヒントになれば幸いです。
序論:RAGの限界を超える次の一手、「Agentic RAG」
2024年に広く普及したRAG技術は、LLMの知識限界を補う手法として定着しました。しかし、データの構造化だけでは精度向上に限界があることも明らかになり、2025年、その限界を克服する「Agentic RAG」がAI開発の最前線となっています。
従来のRAGは、「一発勝負」の検索やユーザー意図の誤解といった課題を抱えていました。Agentic RAGは、自律的なAIエージェントがRAGプロセス全体を知的に制御し、自ら検索戦略を立案・実行し、結果を評価・修正する自己修正ループを実現します。
これにより、回答精度と信頼性が大幅に向上します。
本記事では、従来のRAGが抱える3つの核心的課題を、Agentic RAGがいかに解決するのか、その神髄となるコンセプトから、実装を支える主要ツールまでを徹底的に解説します。
Agentic RAGで解決する、従来のRAGが抱える3つの課題
RAGはLLMの知識を外部情報で補強する有効な技術ですが、従来のアプローチには実運用上の課題がありました。ここでは特に重要な3つの課題と、Agentic RAGによる解決策を見ていきましょう。
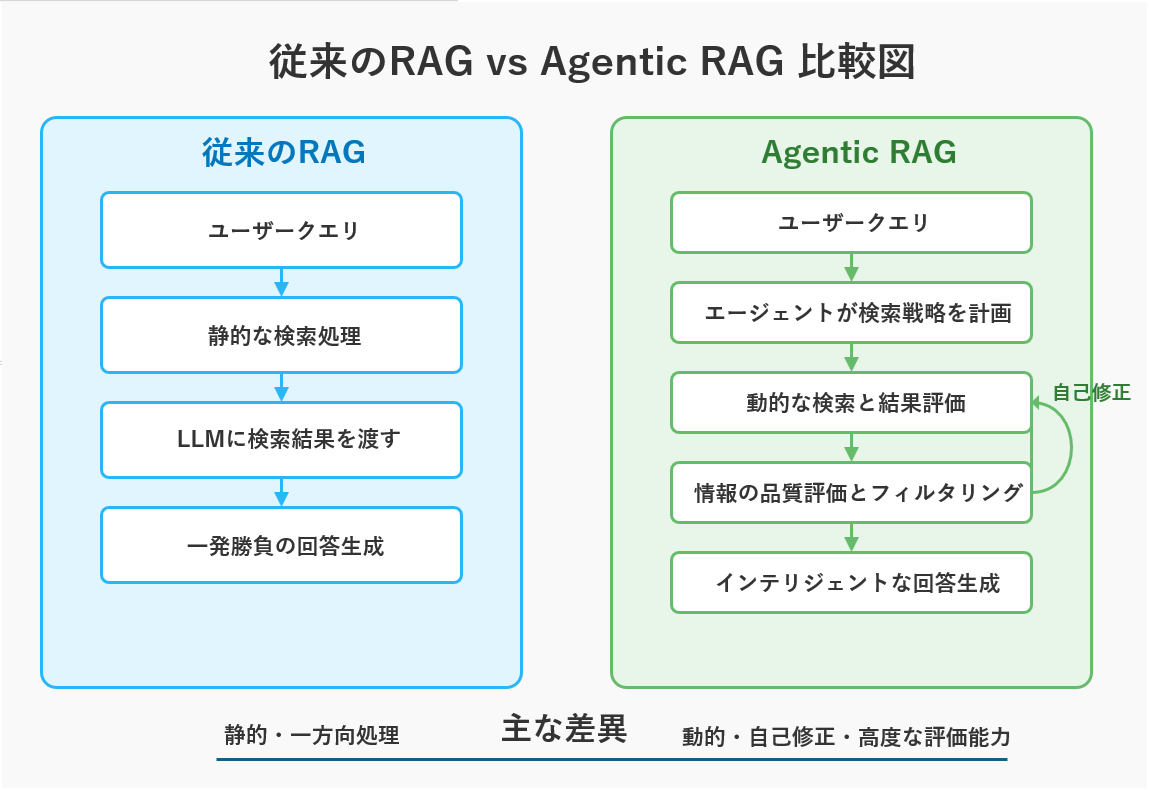
従来のRAGとAgentic RAGの違い
👨🏫 図1の解説ポイント
この図は、従来のRAGとAgentic RAGの根本的な違いを示しています。
・従来のRAG(左側)は、ユーザーの質問に対し、「検索→生成」という一方向の直線的なプロセスを一度だけ実行します。これは「一発勝負」であり、最初の検索が失敗するとそこで終わってしまいます。
・Agentic RAG(右側)は、AIエージェントが介在し、「計画→検索→評価→再計画…」というサイクルを回します。結果が不十分なら、エージェントが自ら戦略を練り直して何度も挑戦する「自己修正ループ」が最大の特徴です。
Agentic RAGによる課題解決:3つの代表的シナリオ
現行のRAGが抱える主な課題と、Agentic RAGによる解決アプローチを、代表的な3つのシナリオでご紹介します。
課題1:検索が一発勝負で、改善できない
【従来の失敗シナリオ】: ユーザーが「社内のパスワードポリシー、特に文字数について教えて」と質問しても、従来のRAGはキーワード「パスワード」「ポリシー」で一般的な文書しか見つけられず、具体的な答えを返せません。最初の検索が的外れでも修正がきかないのです。
【Agentic RAGによる解決】: Agentic RAGでは、AIエージェントがまず初期検索結果を評価し、「ユーザーの要求に対して具体性が不足している」と判断します。次に、エージェントは自ら検索戦略を修正し、「パスワード ポリシー 文字数」といった、より具体的なクエリを生成し再検索を実行します。この「検索→評価→戦略修正→再検索」という自己修正ループにより、ユーザーが本当に求める情報にたどり着くまで、粘り強く探索を続けます。
課題2:セマンティック検索が意図を読み違える
【従来の失敗シナリオ】: 「進行中のプロジェクトAの終了手順」を質問すると、意味が近いというだけで「プロジェクトの完了報告書の書き方」など、文脈に合わない情報を提示してしまうことがあります。
【Agentic RAGによる解決】: エージェントは、ユーザーの「終了手順」という言葉の裏にある「具体的なチェックリストが欲しい」という真の意図を推測します。その上で、意図を反映した戦略的なクエリを再構成し、文脈に合わない検索結果をフィルタリングすることで、本当に求めている情報を的確に選び出します。
課題3:検索結果の品質を評価できず、不適切な情報を使ってしまう
【従来の失敗シナリオ】: Web検索で情報を集める際、従来のRAGは信頼性の高いレポートと不確かなフォーラムの書き込みを区別できず、誤った情報源から回答を生成するリスクがあります。
【Agentic RAGによる解決】: エージェントは、収集した各情報に対し、出典の信頼性、情報の鮮度、他情報との整合性などを多角的に評価します。信頼性が低いと判断した情報は自動的に除外し、高品質な情報のみを根拠として利用することで、回答の信頼性を劇的に向上させます。実際に、LangGraphとAutoRAGを組み合わせた構成では、ベンチマーク(TruthfulQAサブセット)において誤答率が28%から12%へと劇的に低減したという検証結果も報告されています。
Key Takeaways(持ち帰りポイント)
- 従来のRAGは「一発勝負」の静的な検索であり、柔軟性に欠ける。
- Agentic RAGは、AIエージェントによる「自己修正ループ」で、粘り強く最適な答えを探す。
- エージェントはユーザーの真の意図を汲み取り、情報の品質を評価することで、回答の質と信頼性を飛躍させる。
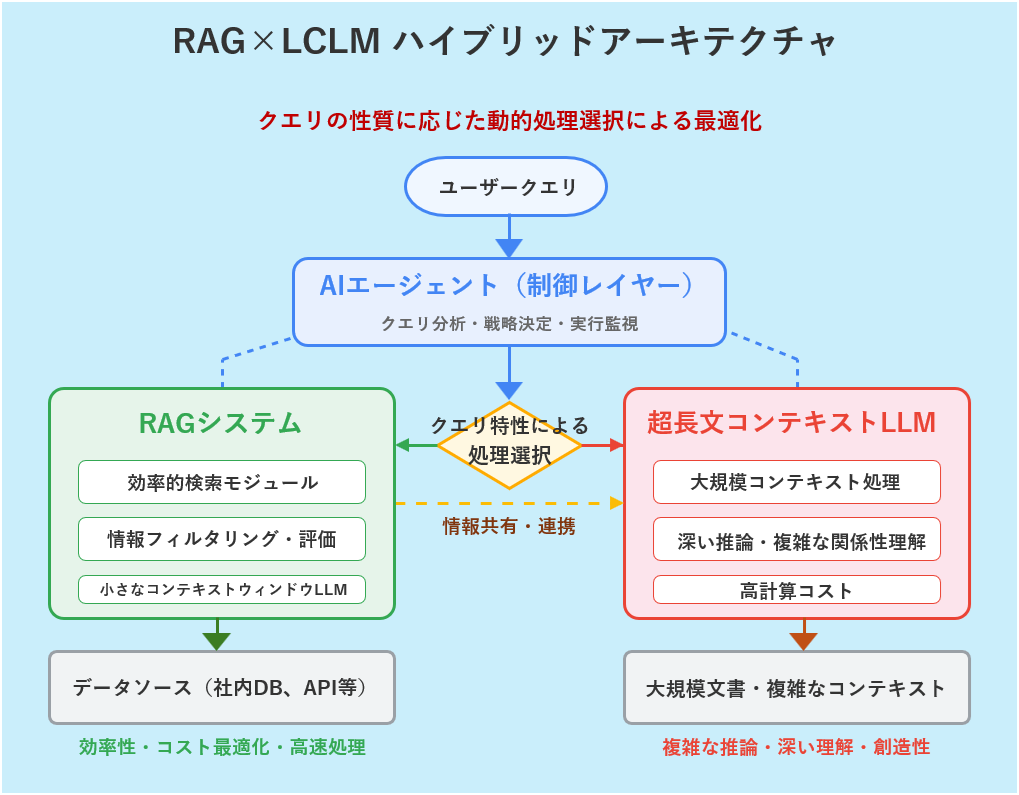
RAG vs 長文コンテキストLLM:相互補完の新時代へ
2025年4月5日に公開されたMeta社のLlama 4シリーズ(Scoutモデルは最大1000万トークン)に加え、Anthropic社のClaude 3.5 Sonnet (200K)やOpenAI社のGPT-4 Turbo (128K)など、複数の超長文コンテキストLLM(LCLM)が登場し、「RAGは不要になるのでは?」という議論があります。しかし、両者は対立ではなく、むしろ「相互補完」し合う関係です。
LCLMは広大なコンテキスト内で複数文書の関係性を直接理解できる可能性がある一方、RAGは圧倒的なコスト効率、高い説明可能性、そしてリアルタイム情報への追従性という明確な利点を持ち続けます。したがって、「RAGかLCLMか」という二者択一ではなく、両者の強みを組み合わせたハイブリッドアプローチが今後の主流となるでしょう。
👨🏫 図2の解説ポイント
今後の主流は、両者の強みを活かすハイブリッドアプローチです。まず、RAGが広大なデータベースから最も関連性の高い情報を高速に絞り込みます。そして、その絞り込まれた高品質な情報を、超長文コンテキストLLMが深く読み解き、精緻な答えを生成します。RAGが「優秀な司書」、LCLMが「天才的な読解力を持つ学者」として協業するイメージです。この連携をインテリジェントに制御する上でも、AIエージェントの役割はますます重要になります。
Agentic RAG構築のためのツール選定ガイド
「2025年はAIエージェント元年」とも言えるほど、現在、数多くの開発ツールが登場し、まさに群雄割拠の様相を呈しています。LangChain、LlamaIndex、CrewAI、AutoGenなど、よく目にする名前も多いでしょう。しかし、重要なのは「全てのツールがAgentic RAGの構築に最適とは限らない」という点です。そこで、この章ではまず主要な10のツールを概観し、その中から本当にAgentic RAGの構築に有効なツールを一緒に選別していきましょう。
注目されるAIエージェントツール10選(リスト)
まず、現在のAIエージェント開発分野で注目されている主要な10のツールをリストアップします。
LangChain, LlamaIndex, CrewAI, AutoGen, MetaGPT, LangGraph, BabyAGI, SuperAGI, Open Interpreter, Hugging Face Transformers Agents.
Agentic RAG構築に最適なツールの選定基準
上記リストから、真に効果的なAgentic RAGを構築するために、この記事では、単なるツール紹介ではなく、**RAGを強化するための『自律的ワークフロー構築能力』**を最重要視し、以下の基準でツールを絞り込みました。
- 複雑なワークフロー制御能力: 自己修正ループや条件分岐など、単線的ではない思考プロセスを設計できるか。
- マルチエージェント連携能力: 複数のエージェントに役割を与え、協調作業をさせられるか。
- データ連携とRAG親和性: RAGの中核であるデータとの連携がスムーズで、検索プロセスを柔軟に組み込めるか。
選抜されたトップ5ツール詳細解説
上記の基準に基づき、特にAgentic RAGの構築に推奨される5つのフレームワークを深掘りします。
1. LangGraph:複雑なワークフローの制御
LangGraphは、AIエージェントの思考フローを「グラフ」として視覚的に定義できるライブラリです。条件分岐やループ、自己修正といった複雑な制御を可能にし、洗練されたAgentic RAGを構築する上で最も強力な選択肢の一つです。(詳細は「LangGraphで極めるRAG型AIエージェント開発」へ)
2. AutoGen:マルチエージェントの協調
AutoGenは、Microsoftが開発した、複数のAIエージェントを協調させるためのフレームワークです。例えば「リサーチ担当エージェント」がRAGで情報を収集し、その結果を「執筆担当エージェント」が要約する、といった役割分担による高度なタスク実行を設計できます。(詳細は「AutoGen完全ガイド」へ)
3. CrewAI:ビジネスプロセスへの特化
CrewAIは、マルチエージェントのコンセプトを、よりビジネスプロセスに特化させたフレームワークです。明確な役割とタスクを定義することで、エージェントのチーム(クルー)を編成し、構造化された業務の自動化を容易に実現します。(詳細は「CrewAIが変えるマルチエージェントの常識」へ)
4. LlamaIndex:データ連携のスペシャリスト
LlamaIndexは、RAGのデータ連携部分に非常に強いフレームワークです。多様なデータソースからの接続や、高度な検索戦略の実装に長けており、エージェントが利用する「知識」の品質を最大化する上で重要な役割を果たします。
5. LangChain Agents:汎用性とエコシステム
LangChain Agentsは、AIエージェント開発のデファクトスタンダードです。豊富なツール連携機能と巨大なエコシステムを持ち、迅速なプロトタイピングから複雑なエージェントの実装まで、あらゆる開発フェーズで基本となるフレームワークです。
まとめ:Agentic RAGは知識活用の新次元へ
Agentic RAGは、単なる情報検索の精度向上にとどまらず、AIが自律的に思考し、目標達成のために動的に行動する、新しいパラダイムの幕開けを告げています。
Deloitte社の予測では2025年までに企業の25%がAIエージェントを導入するとされており、この変化は加速する一方です。大手テック企業では「従来RAG比で回答精度20%以上向上」という実績も報告されており、Agentic RAGは日本のDX推進においても不可避の潮流です。AIを補助的なツールから、複雑な知的タスクを任せられる真のパートナーへと進化させるこの技術の理解は、今後の競争優位性を左右する重要な鍵となるでしょう。
専門用語まとめ
- Agentic RAG
- AIエージェントが、その自律的な思考・行動サイクルの中で、RAGを情報収集ツールの一つとして利用する先進的なアーキテクチャ。
- 自己修正ループ
- エージェントが自身の行動結果を評価し、目標達成に不十分な場合は、計画や次の行動を自律的に修正するプロセス。Agentic RAGの核心的機能。
- LCLM (Large Context Length Models)
- 超長文コンテキストLLM。一度に数百万トークン以上の膨大な情報を処理できる次世代の大規模言語モデル。
- マルチエージェント
- それぞれが異なる役割や専門性を持つ複数のAIエージェントが、互いに協調・対話しながら、一つの大きな目標を達成するシステム。
- ツール利用 (Tool Use)
- AIエージェントが、検索、計算、API実行など、外部の機能(ツール)を呼び出してタスクを遂行する能力。
- 思考の連鎖 (Chain of Thought)
- 複雑な問題に対し、AIが最終的な答えを出す前に、その中間の思考プロセスをステップバイステップで記述する手法。推論の精度を高める。
- ReActフレームワーク
- Reasoning(推論)とActing(行動)を繰り返すことで、AIエージェントがタスクを解決するための思考プロセス。
よくある質問(FAQ)
Q1. Agentic RAGの導入コストは、通常のRAGと比べてどれくらい高くなりますか?
A1. はい、特に推論コストが大幅に増加します。例えばLangGraph+Llama3のタスク分割実験では、従来のRAGに比べて推論APIコストが最大で8倍に増加したという報告があります。また、米大手製造業の導入事例(2025年上半期)では、月間コストが従来比185%上昇した一方で、回答精度(F1スコア)は12.3ポイント向上したとされています。
Q2. 超長文コンテキストLLMが登場しても、Agentic RAGは必要ですか?
A2. はい、必要と考えられます。コスト効率、スケーラビリティ、説明可能性、リアルタイム性などの点でRAGは依然として優位性があります。今後は両者を組み合わせたハイブリッドアプローチが主流になると予想されます。
Q3. Agentic RAGツールを選ぶ際のポイントは何ですか?
A3. プロジェクトの複雑さに応じて選択します。単純なツール連携ならLangChain、複数のエージェントの協調作業ならCrewAIやAutoGen、複雑なフロー制御が必要ならLangGraphが有力な選択肢となります。
Q4. Agentic RAGはどのような課題を解決しますか?
A4. 「検索が一発勝負で改善できない」「ユーザーの意図を読み違える」「検索結果の質を評価できず不適切な情報を使う」といった従来のRAGの課題を、エージェントの自己修正能力、意図理解、情報品質評価によって解決します。
Q5. Webアクセスなどを行うエージェントの、データセキュリティ上の注意点は何ですか?
A5. エージェントに与える権限を最小限にすることが重要です。社内情報が意図せず外部に送信されたり、エージェントが悪意のあるサイトにアクセスしてしまったりするリスクがあります。サンドボックス環境での実行や、アクセス先の厳格なホワイトリスト管理といった対策が必要です。
Q6. まず手軽にAgentic RAGを試すには、何から始めるべきですか?
A6. LangChain Agentsのチュートリアルから始めるのが最も一般的です。既存のRAGシステムに、ウェブ検索ツールを追加してみるだけでも、Agenticな挙動の一端を体験できます。
Q7. Agentic RAGと従来のRAGの主な違いは何ですか?
A7. 従来のRAGは静的な検索プロセスですが、Agentic RAGはAIエージェントが自律的に計画・実行・評価・修正を行う動的なプロセスです。これにより、より複雑な質問に対応し、精度を高めることができます。
更新履歴
- 最新情報アップデート、FAQ、専門用語等読者支援強化
- 初版公開
主な参考サイト
- Agentic RAG: What it is, its types, applications and implementation – LeewayHertz
- Technology, Media & Telecommunications (TMT) Predictions – Deloitte
- Meta releases Llama 4, a new crop of flagship AI models – TechCrunch
合わせて読みたい
- 【2025年最新】Vertex AI Search / Agent Builder × Gemini 2.5 で作る超高速RAGシステム(Vertex AIとGemini 2.5を使った最先端のRAGシステム構築方法)
- 2025年にやってくる?AIエージェントの時代(AIエージェントの全体像を掴む)
- RAG(検索拡張生成)とは?仕組み・重要性を図解で徹底解説【2025年版】(エージェントが使う「ツール」の基本を学ぶ)
- RAGの精度を向上させる7つの技術|高度なチューニング戦略ガイド(RAGをさらに強化する)
以上








