


※本記事は継続的に最新情報へアップデートしています。
2026年、LLMアプリ開発は「APIを呼ぶだけ」の段階を超えました。 RAG、ツール連携、構造化出力、監視まで入ると、単発のAPI呼び出しだけでは設計がすぐに複雑化します。
水道の蛇口をひねるだけなら簡単でも、浄水、分岐、貯水、漏水検知まで必要になれば配管設計が必要です。LangChainは、OpenAI APIなどのLLMアプリを、プロンプト、モデル、RAG、ツール連携といった部品で組み立てるための「配管キット」です。
本記事では、LangChainを「LLMアプリの部品箱」として捉え、API直叩き、LangChain、LangGraphをどの場面で使い分けるべきかを整理します。
✅ 先に結論
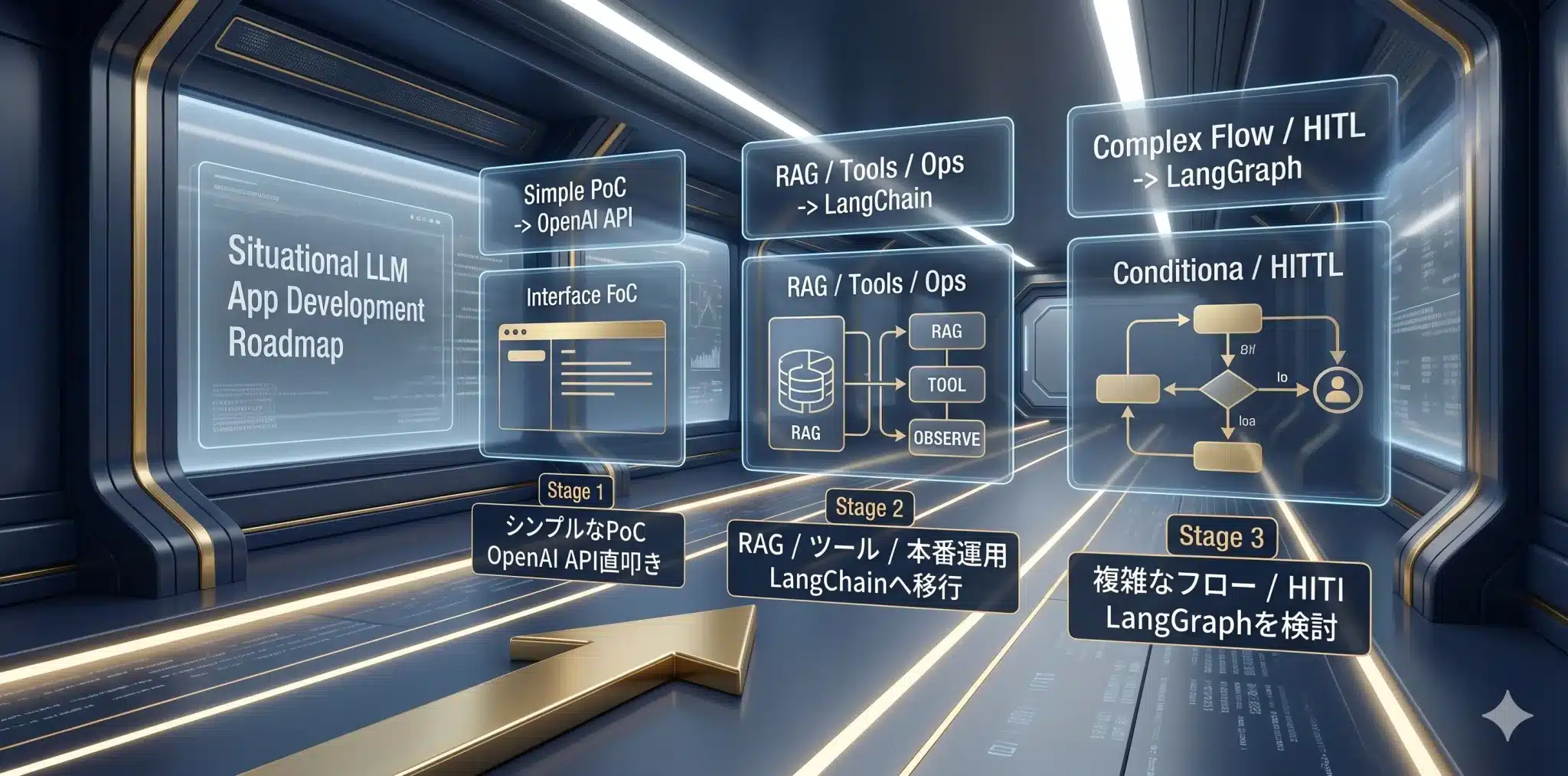
LangChainは、LLMアプリを素早く組み立てるための部品箱です。単発生成だけならOpenAI APIを直接呼ぶ方が速い場合もありますが、RAG、ツール呼び出し、会話状態、評価・監視が増えるほどLangChainの価値が高まります。
- ステージ1:API直叩き:プロンプト1つ、LLM1回呼び出しで完結するPoCや小さな自動化
- ステージ2:LangChain:RAG、ツール連携、会話状態、構造化出力、評価・監視のうち2つ以上が必要になった段階
- ステージ3:LangGraph:条件分岐、HITL、中断再開、監査ログが業務要件になった段階

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』▶ 詳細はこちら
LangChainとは?OpenAI API直叩きとの違い
LangChainは、LLMアプリを部品化し、検索・ツール・出力処理をつなぎやすくするフレームワークです。
OpenAI APIを直接呼ぶのは、蛇口からそのまま水を飲むようなものです。単発の生成なら速く、シンプルです。しかし実運用では、検索(RAG)、ツール呼び出し、会話履歴、エラー処理、監視といった「配管」が必要になります。
LangChainは、その配管を部品化し、つなぎ替え可能にするフレームワークです。つまり、LangChainはLLMそのものではなく、LLMアプリを組み立てるための部品箱です。
LangChain v1では、エージェント構築、ミドルウェア、構造化出力、プロバイダー横断の標準化などが整理され、LLMアプリを本番に近づけるための基盤としての性格がより強くなっています。特に、create_agent() はv1以降のエージェント構築における中心的な抽象です。
LCEL(prompt | llm | parser)は、Prompt、Model、Parserをつなぐ基本として有効です。一方で、ツール呼び出しやマルチステップのエージェントを作る場合は、create_agent() を前提に考える方がv1以降の設計に沿っています。
LangChainを使うべき場面・使わない場面
LangChainは、RAG・ツール・会話状態・評価が増えたときに効果を発揮する部品箱です。
| 状況 | LangChainが向く | API直叩きが向く |
|---|---|---|
| 単発生成・検証 | △ 学習目的なら有効 | ◎ 最速で試せる |
| RAG / ツール / 会話状態 | ◎ 部品を組み合わせやすい | △ 自作部分が増える |
| 本番運用 | ◎ LangSmithやログ設計と組み合わせやすい | △ 評価・監視・再試行を自作しやすい |
| 判定根拠 | LLMを1回呼ぶだけならAPI直叩きで十分です。一方で、RAG、ツール、会話状態、評価、監視が増えるほど、LangChainで部品化しておく価値が高まります。 | |
重要なのは、LangChainを「必ず使うべき標準」と考えないことです。
プロダクトが検証段階(PoC)なら、API直叩きで素早く回す方が、学習も意思決定も速くなります。β版から社内展開に進み、RAGやツール連携、構造化出力、評価・監視が増え始めたタイミングで、配管をLangChainに乗せ替えると、後からの拡張コストを抑えられます。
さらに、業務クリティカルな本番運用で人間承認や複雑な分岐が絡み始めたら、状態管理をLangGraphに切り出す、という3段ジョブチェンジを前提にすると設計が安定します。
経営や事業戦略の視点から見れば、LangChainの導入は「独自コードのブラックボックス化を防ぎ、開発チームの属人性を排除するための先行投資」です。共通フレームワークを採用することで、オンボーディングコストを下げ、本番運用の最大リスクである「配管のスパゲティ化」を未然に防ぎやすくなります。
環境構築:PythonとOpenAI APIキーの準備
最初は最小パッケージで動かし、RAGや本番運用に必要な部品を後から足すのが安全です。
pip install -U langchain langchain-openai python-dotenv # RAGまで試す場合 pip install -U faiss-cpu
APIキーは、ローカルでは .env、本番環境ではシークレットマネージャで管理します。開発用と本番用のキーを分け、ローテーションできる設計にしておくことが重要です。
LangChainはパッケージ分割が進んでおり、OpenAI連携では langchain-openai を使う形が基本です。2026年時点ではv1.x系を前提に公式ドキュメントを確認し、最新のパッケージ名と初期化方法に合わせてください。
なお、0.x系の既存コードを持つ場合は、v1移行ガイドで案内されている「classic」系の名前空間や互換パッケージも確認対象になります。ただし、新規開発では基本的に langchain とv1系のAPI設計に寄せる方が、長期保守しやすいでしょう。
LCELで作るLangChain最小チェーン
LangChainの基本は、Prompt、Model、Parserをパイプのようにつなぐことです。
最初に作るべきなのは、複雑なRAGやツール連携ではありません。まずは、プロンプト、モデル、出力処理をつないだ最小チェーンを動かします。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2)
prompt = ChatPromptTemplate.from_messages([
("system", "あなたは日本語で簡潔に説明する技術アシスタントです。"),
("human", "{question}")
])
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"question": "LangChainとは?30秒で説明して。"}))
※上記のコードは、事前に .env ファイルなどで OPENAI_API_KEY が設定されていることを前提にしています。モデル名は、コピペして試しやすい例として gpt-4o-mini を使っています。2026年時点では、分類、データ抽出、サブエージェントのような大量かつ比較的シンプルな処理では gpt-5.4-nano、会話や軽量なマルチステップ処理では gpt-5.4-mini も選択肢になります。利用可能なモデルは契約・環境により異なるため、実装時はOpenAI Modelsドキュメントで確認してください。
この prompt | llm | parser という流れがLCELの基本です。LangChainでは、プロンプト、モデル、出力処理を部品としてつなぎ、後からRAGやツール呼び出しを追加できます。
なお、LangChain v1ではエージェント構築に create_agent() が推奨されるため、LCELは「チェーンの基本を理解する入口」、create_agent() は「エージェント化する入口」と分けて捉えると理解しやすくなります。
会話履歴は「必要最小限」で持つ
会話履歴は便利ですが、増やしすぎるとコスト、漏洩、誤誘導のリスクになります。
会話履歴を持たせると、ユーザーとの文脈を保ちやすくなります。ただし、履歴が増えるほど、トークンコスト、情報漏洩、過去発言への過剰依存が起こりやすくなります。
実務では、すべての履歴を保存するのではなく、必要な履歴だけを残し、長くなった会話は要約・圧縮する設計が重要です。LangChain v1では、会話履歴やコンテキスト制御をミドルウェアとして扱う方向も強まっており、単純な履歴追加よりも、何を残すかの設計が重要になります。
構造化出力は「型で返す」設計にする
本番アプリでは、自由文ではなくJSONや決まったスキーマで返す設計が重要です。
業務アプリでは、LLMの回答をそのまま画面に出すだけでなく、JSONや決まったスキーマとして後続処理に渡す場面が増えます。LangChainでは、出力パーサーやスキーマ検証と組み合わせて、モデル出力をアプリ側で扱いやすい形に整えます。
構造化出力は、単に「JSONで返して」と頼むだけでは安定しません。スキーマ、バリデーション、失敗時の再試行まで含めて設計する必要があります。
特に、OpenAIのStructured Outputs(JSON Schemaベース)と、LangChain側の出力パーサーや再試行ロジックを組み合わせると、「LLMはスキーマどおり返す」「LangChainは検証と再実行を担う」という役割分担が明確になり、本番での安定性が上がります。
ツール呼び出し:LLMを「行動できる」アプリにする
ツール呼び出しは便利ですが、実行前の検証と許可制が欠かせません。
ツール呼び出しは、LLMに計算、検索、API呼び出しなどの外部機能を使わせる仕組みです。ただし、モデルに直接実行させるのではなく、モデルが提案し、アプリが検証し、許可されたツールだけを実行する設計が基本です。
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
@tool
def calc_tax(price: int):
"""税込価格を計算する"""
return int(price * 1.1)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.2)
llm_tools = llm.bind_tools([calc_tax])
print(llm_tools.invoke("1200円の税込価格を計算して。"))
※モデル名は、コピペして試しやすい例として gpt-4o-mini を使っています。実運用では、コスト、速度、必要な推論能力、利用可能なモデルを確認し、用途に応じて gpt-5.4-mini や gpt-5.4-nano なども検討してください。
ツールは必ず allowlist、入力検証、監査ログ とセットで設計します。特に、メール送信、削除、決済、個人情報処理などの操作は、人間承認や権限制御を前提にしてください。
LangChainでRAGを組む最小構成
RAGは、文書を分割し、検索し、検索結果を回答に渡すための配管設計です。
RAGは、文書を分割し、埋め込み、検索し、検索結果をプロンプトに渡して回答する仕組みです。LangChainは、この一連の流れを部品として組み合わせやすくします。
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
text = "ここに社内文書やマニュアルを入れる想定です。"
docs = RecursiveCharacterTextSplitter(
chunk_size=600,
chunk_overlap=80
).create_documents()
vectorstore = FAISS.from_documents(
docs,
OpenAIEmbeddings(model="text-embedding-3-large")
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
hits = retriever.invoke("この文書の要点は?")
print(hits[0].page_content)
ここではRAGの最小構成だけを示しています。精度改善、チャンク設計、リランキング、評価方法は「RAG完全ガイド」と「Agentic RAG実践ガイド」で詳しく整理しています。
RAGが失敗する典型パターン
- チャンクが大きすぎる:関係ない情報が混ざり、回答がぼやける
- 検索件数が少なすぎる:検索ミスがそのまま回答ミスにつながる
- 根拠制約が弱い:検索結果にない内容をモデルが補ってしまう
RAGはコードよりも、データ分割、検索設計、評価の方が重要です。LangChain記事では入口に留め、詳細はRAG関連記事へつなぎます。
本番運用で効く基本設計
本番では、動くコードよりも、落ちにくく観測できる設計が重要です。
| 項目 | 目的 | 設計のポイント |
|---|---|---|
| タイムアウト | 処理停止を防ぐ | 外部API呼び出しには上限時間を設定する |
| リトライ | 一時的な失敗に備える | 回数を制限し、middlewareや外部ジョブ基盤で無限再試行を避ける |
| ストリーミング | 体感速度を上げる | 長文回答やチャットUIで有効 |
| 監視 | 品質・コストを追跡する | LangSmithやログ基盤と連携する |
LLMアプリは、モデルが賢いだけでは本番で安定しません。コスト、遅延、失敗率、ツール呼び出し、RAGの検索精度を観測できるようにしておく必要があります。
より詳しい本番運用、評価、監視、コスト管理は「LLMOps完全ガイド」で整理しています。
LangChainとLangGraphの違い
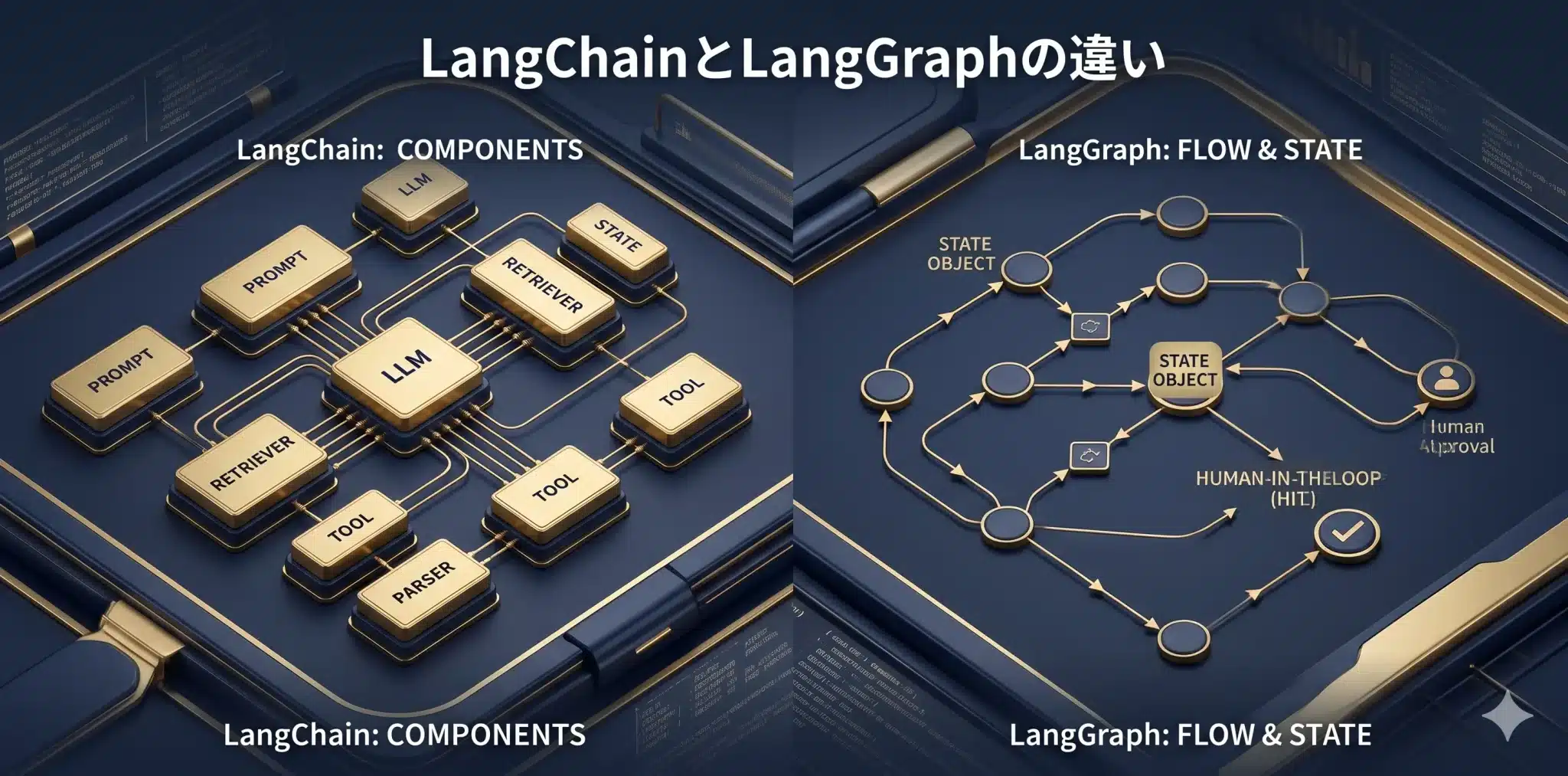
LangChainは部品をつなぐ道具、LangGraphは状態と実行フローを制御する基盤です。
| 観点 | LangChain | LangGraph |
|---|---|---|
| 主な役割 | LLMアプリの部品をつなぐ | 状態と実行フローを制御する |
| 向いている場面 | プロンプト、RAG、ツール連携、出力処理 | 条件分岐、ループ、HITL、中断再開、監査ログ |
| 設計の中心 | Prompt、Model、Parser、Retriever、Tool | State、Node、Edge、Checkpointer |
単純なRAGやツール連携であればLangChainで十分です。一方で、次のような要件が1つでも本格的に入ってきたら、LangGraphを検討するサインです。
- 承認フロー:与信や契約レビューなど、人間の承認を待つノードが複数入るワークフロー
- 再実行:途中で失敗した場合に、最初からではなく途中のステップから中断再開したいケース
- 監査:いつ、どのノードで、どのツールがどんな入力・出力で実行されたかを、後から追跡する必要がある業務
こうした要件が揃い始めたときが、「LangChainの上にLangGraphを敷く」タイミングです。詳しくは「LangGraphとは?LangChain・CrewAI・MAFとの使い分けと本番設計【2026年版】」で解説しています。
一次情報からどこまで言えるか
事実と解釈は分けて書くべきです。
一次情報から確実に言えるのは、LangChain v1で create_agent()、ミドルウェア、標準コンテンツブロック、構造化出力などの整理が進み、OpenAI連携も専用インテグレーションとして提供されているという点です。
v1の公式情報では、プロバイダー横断の統一インターフェース、構造化出力とツール呼び出しのパターン化、LangGraphとの連携が重視されています。
本記事のスタンスも、「どの抽象がいつ必要か」「API直叩き、LangChain、LangGraphをどう使い分けるか」という実務判断にフォーカスしており、v1の方向性と整合しています。
一方で、すべてのLLMアプリにLangChainが必要というわけではありません。APIを1回呼ぶだけなら直叩きで十分な場合があります。本記事の解釈は、周辺機能が増えるほどLangChainの価値が高まり、状態制御が必要になればLangGraphへ進むという実務判断にあります。
まとめ:LangChainはLLMアプリを組み立てる部品箱
読者が持ち帰るべきなのは、LangChainを使うかどうかの判断基準です。
OpenAI APIを直接呼ぶだけなら、LangChainは必須ではありません。しかし、RAG、ツール呼び出し、会話状態、構造化出力、評価・監視が必要になった瞬間、アプリは単なるAPI呼び出しではなくなります。
LangChainは、LLMを使うためのライブラリではなく、LLMアプリを組み立てるための部品箱です。
ただし、状態管理、分岐、HITL、中断再開まで必要になった場合は、LangGraphの領域です。LangChainとLangGraphを競合としてではなく、役割の異なるレイヤーとして使い分けることが、2026年のLLMアプリ開発では重要になります。
専門用語まとめ
- LCEL
- LangChain Expression Languageの略。Prompt、Model、Parserなどの部品をパイプのようにつなぐ記法。
- create_agent()
- LangChain v1で標準化されたエージェント構築用の抽象。ツール、モデル、ミドルウェアを組み合わせてエージェントを作る入口。
- RAG
- 検索で根拠を取得してから回答を生成する設計。社内文書検索やナレッジ活用で使われる。
- Chunking
- 文書を検索しやすい単位に分割する設計。RAGの品質を大きく左右する。
- Tool calling
- LLMが関数やAPIの利用を提案する仕組み。実行前の検証と許可制が重要。
- LangGraph
- 状態管理、条件分岐、HITL、中断再開を扱うための実行基盤。LangChainより複雑な制御に向く。
参考文献 / 出典
一次情報
次に読むならこの3本
補足Q&A
Q1. LangChainは何を楽にしてくれますか?
A1. RAG、ツール連携、会話状態、評価・監視など、LLMアプリの周辺機能を部品化してくれます。 単なるAPIクライアントではなく、LLMアプリの配管を再利用可能な形で設計するためのフレームワークです。
Q2. LangChainとLangGraphはどう使い分けますか?
A2. LangChainは部品をつなぐ道具、LangGraphは状態と実行フローを制御する基盤です。 単純なRAGやツール連携ならLangChain、条件分岐、HITL、中断再開、監査ログが必要ならLangGraphを検討します。
Q3. RAGの品質が安定しない場合、最初に何を疑うべきですか?
A3. 最初に疑うべきはチャンク設計です。 文書分割のサイズ、重なり、見出し単位の扱いによって検索精度は大きく変わります。詳細はRAG完全ガイドで確認してください。
更新履歴
- 2025年1月29日:初版公開
- 2025年9月26日:最新情報にアップデート、読者支援機能を強化
- 2026年2月3日:検索意図を再整理し、LCEL最短実装、RAG、運用チェックを強化
- 2026年5月19日:2026年版へ更新。コード量を整理し、LangGraphとの役割分担と内部リンクを強化。








