


※本記事は継続的に最新情報へアップデートしています。
動くデモを見せた瞬間、経営陣は感動した。しかし数か月後、現場ではほとんど使われなくなっていた。これは、RAG導入で起こりがちな失敗である。
PoCの感動が本番の沈黙に変わるとき、原因はLLMそのものではなく、その手前にあるデータ整備・検索設計・評価設計に潜んでいることが多い。
本記事では、経営層からトップエンジニアまでが実務でRAGを評価・活用できるよう、Classic RAG、Hybrid RAG、Agentic RAG、GraphRAGの選択基準とシステム全体の構造を解剖する。読み終えたとき、「自社は今どこにいて、次に何をすべきか」が見えている状態を目指す。
✅ 先に結論
RAGは検索機能ではなく、社内知識をLLM時代の業務資産へ変える知識活用基盤です。
成功の鍵は、データ整備・検索品質・評価設計・運用ログ、そして用途に応じた自律化やGraph化の選択にあります。
- なぜ7工程すべてが重要なのか:RAGはETL→Chunking→Embedding→VectorDB→Retrieval→Generation→Evaluationの全7工程のパイプラインです。1工程でも崩れれば、最終回答は崩れます。
- なぜLLMを替えても直らないのか:精度が出ないとき、先に疑うべきはLLMではなく、前段のデータ品質・チャンク設計・検索品質・評価設計です。
- どのアーキテクチャをいつ選ぶか:Hybrid・Agentic・GraphRAG・Platform RAGの使い分けは、技術選択ではなく経営判断です。自社のSLAとデータ要件が、答えを決めます。

何が変わったのか
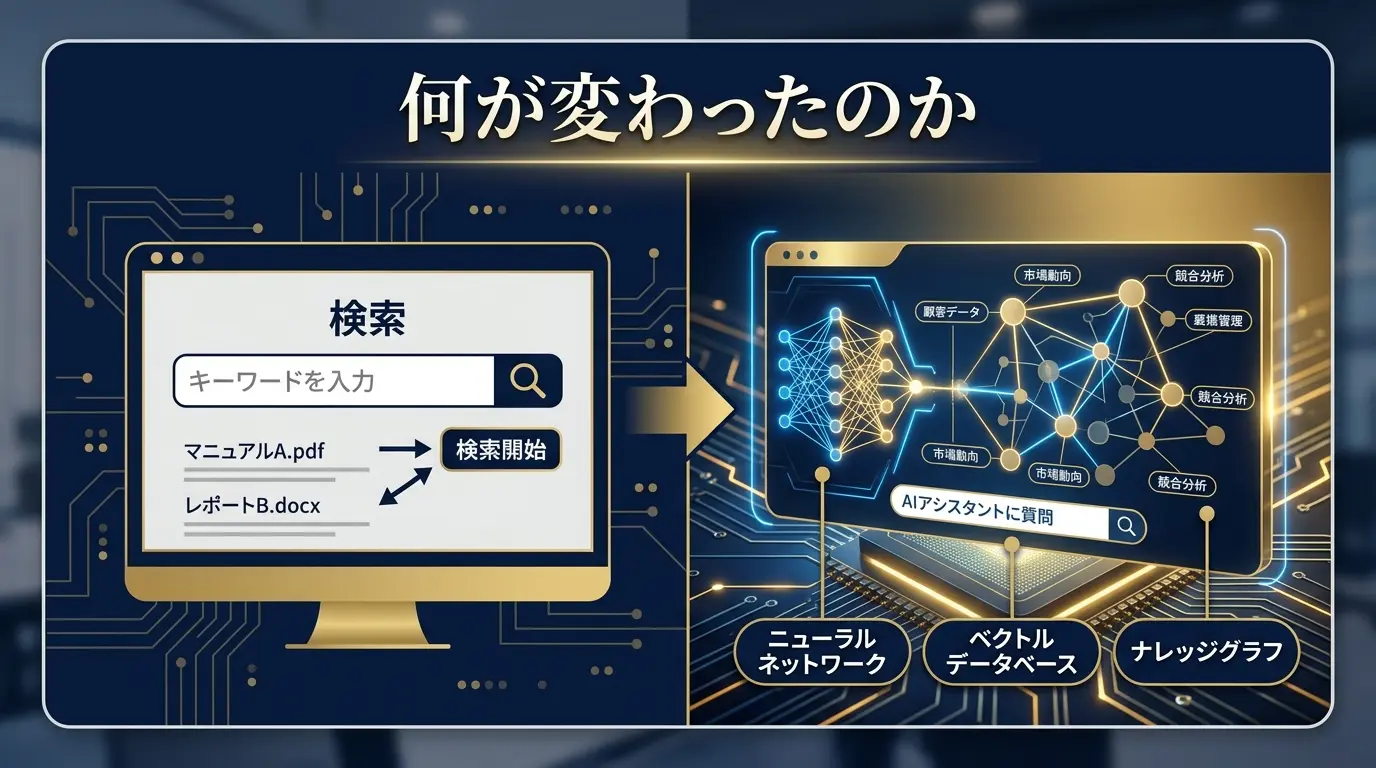
RAGを「検索ちょい足し」と捉えているうちは、本番で必ず壁にぶつかる。回答品質を支えるのは、7工程のパイプライン全体である。
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、一言でいえば「賢い新入社員であるLLM」に「最新の社内マニュアルである外部知識」を検索・参照させながら回答させる技術です。
ただし、マニュアルが3年前のまま放置されていたらどうでしょうか。棚の整理が雑で、必要なページが見つからなかったらどうでしょうか。
新入社員がどれほど優秀でも、渡された資料が古く、探しにくく、矛盾していれば、回答品質は上がりません。
2026年現在、LLMのビジネス導入はPoCから本番運用へ移行しつつあります。
その中でRAGは、単なる検索補助ではありません。
RAGは、社内知識を安全にLLMへ接続するための知識活用基盤です。
RAGは「検索して答えるだけ」の仕組みではなく、データ整備、チャンキング、Embedding、検索、再ランキング、生成、評価をつなぐパイプライン全体として設計・運用される必要があるためです。
どこか一つの工程が崩れれば、最終回答の信頼性も崩れます。各工程の役割と失敗リスクは以下の通りです。
変化の起点:RAGの基本構造パイプライン
まずは、RAGを一つの機能ではなく、複数工程で構成されるパイプラインとして見てください。
下の表で重要なのは、RAGの失敗がGenerationだけで起きるわけではない、という点です。
| 工程 | 役割 | 失敗すると起きること |
|---|---|---|
| ETL | 文書を取り込み、不要情報や重複を整える | 古い情報やノイズが回答に混ざる |
| Chunking | 文書を検索しやすい単位に分割する | 必要な根拠が切れる、または余計な情報が混ざる |
| Embedding | 文章の意味をベクトル化する | 意味検索の精度が落ちる |
| Vector DB / Index | ベクトルを保存し、高速に検索する | 検索速度や再現率が悪化する |
| Retrieval | 質問に関連する文書を取り出す | 必要な根拠を取得できない |
| Reranking | 取得候補を重要度順に並べ替える | ノイズ文書がLLMに渡る |
| Generation | 取得文書を根拠に回答を生成する | 根拠不足や誤引用が起きる |
| Evaluation | 回答品質を継続的に評価する | 改善すべき箇所が分からない |
| ※ 出典:Arpable Tech Team構造定義(2026年5月時点) | ||
従来アプローチとの差分:フェーズ別の深化
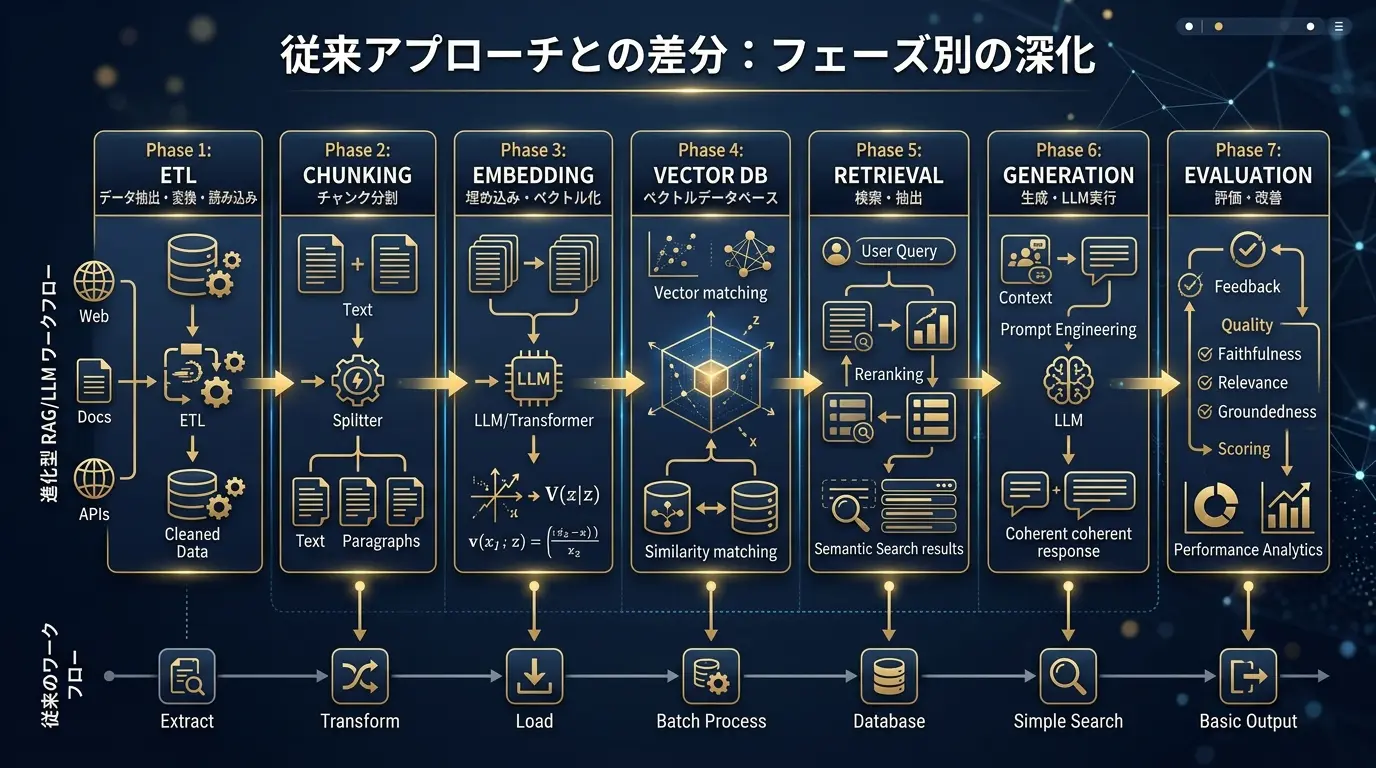
Ingestion(取り込み)フェーズ:知識を「検索可能」な形に整える
Ingestionフェーズは、RAGの「仕込み」であり、回答品質の土台となります。目的は、元のドキュメントを「検索しやすい形」に加工し、データベースに格納することです。
- ETL (取込・整形) の概念 (Why): なぜドキュメントをそのまま使えないのでしょうか? それは、LLMが一度に読める情報量(コンテキストウィンドウ)に限界があるためです。ETL工程では、長文のPDFやWebページを意味のある単位(チャンク)に分割(チャンキング)します。これにより、検索ノイズを減らし、LLMが処理できる最適なサイズへと文書を整えます。
- Index (索引) の概念 (Why): なぜ「ベクトル化」が必要なのでしょうか? 従来のキーワード検索では「AI」と「人工知能」を別物と認識してしまいます。一方、ベクトル化(Embedding)は、単語や文章の「意味」を数値の配列(ベクトル)に変換します。これにより、「意味が近い」文書を効率的に検索することが可能になります。
Generation(生成)フェーズ:検索した知識から「回答」を生成する
Generationフェーズは、ユーザーの質問(クエリ)に対し、Ingestionフェーズで準備した知識を使ってリアルタイムに回答を生成する工程です。
- Retrieve (近傍探索) の概念 (Why): 検索の精度がRAGの生命線です。ベクトル検索(意味)とキーワード検索(完全一致)を組み合わせる「Hybrid Search(ハイブリッド検索)」が重要です。なぜなら、「AI」のような概念はベクトル検索が得意ですが、「製品型番A-100」や「田中太郎」といった固有名詞はキーワード検索が必須だからです。両者を組み合わせることで検索漏れを防ぎます。
- Reranker(再ランキング)の概念 (Why): Retrieveを補完する後段の工程として、Reranker(リランカー)が重要です。Retrieveで広く集めた候補(例: 50件)にはノイズも含まれます。Rerankerは、この50件をより高精度なモデルで再評価し、本当に重要度の高い順(例: 5件)に並べ替える「精査」の役割を担います。
- Generate (制約付き生成) の概念 (Why): 検索した文書(コンテキスト)をLLMに渡し、回答を生成させます。この際、「取得した文書『だけ』を根拠に回答せよ」「出典IDを必ず明記せよ」といった厳格な制約(プロンプト)を与えることが、ビジネス利用での信頼性(トレーサビリティ)確保に不可欠です。
エンジニア向けの参考として、従来のベクトル検索のみの構成から、Hybrid Search+Reranker構成への移行を最小コードで示します。
経営層・PMの方は、キーワード検索とベクトル検索を組み合わせ、さらに重要度順に精査する2段階フィルターへ変わると読み替えてください。
# Classic:ベクトル検索のみ hits_vec = retrieve_vec(index, query, k=8) # Hybrid:キーワード×ベクトルのハイブリッド hits_bm25 = retrieve_bm25(corpus, query, k=20) hits = rerank(hits_bm25 + hits_vec, model="cross-encoder")
この2段階フィルターの有無が、現場での「使えるRAG」と「使えないRAG」の分かれ目となります。
さらにAgentic RAGへ発展させる場合は、LangGraphなどの状態管理ライブラリを活用し、条件分岐・再試行・自己評価をワークフローに組み込む設計が必要です。
なぜ今重要なのか

高性能なLLMに乗り換えれば解決する、という直感は裏切られやすい。まず疑うべきは、データ品質・検索品質・評価設計である。
RAGの精度が出ないとき、多くの現場では「もっと高性能なLLMに替えるべきか」と考えがちです。
しかし、実際にはRAGの失敗の多くは、LLMの性能不足ではなく、前段のデータ品質・検索品質・評価設計に起因しています。
開発現場のPoCやベンチマークでは、ナイーブなRAGパイプラインが検索段階で必要な情報を取りこぼす、あるいはノイズを拾うケースが繰り返し確認されています。
つまり、実務では「LLMそのもの」より、その手前のデータ整備や検索設計がボトルネックになっていることが多いのです。
たとえば「回答内容は悪くないが、参照している規程が古い」というケースは検索・データ側の問題です。LLMを高性能なモデルに差し替えても、根本的な改善にはなりません。
逆に「正しいチャンクは取れているのに回答が要点を外している」場合は、プロンプトや生成側を見直すべきシグナルになります。
事業への影響:RAGが解決する3大課題(Why)
RAGが企業に必要とされる理由は、LLM単体では業務に必要な信頼性を満たしにくいからです。
「ChatGPTに聞いたら自信満々に間違えた」「去年廃止された規程を引用して回答した」「うちの独自製品は知らないと言われた」——これらすべて、LLM単体の構造的な限界です。
その原因は、「嘘・古さ・専門外」の3つに集約されます。
RAGはLLMの「嘘・古さ・専門外」を解決し、ビジネス利用の信頼性を担保する技術です。LLM単体が持つ以下の3つの根本的な課題を解決します。
- ハルシネーション(情報の捏造): LLMが事実に基づかない情報を生成する問題です。RAGは「参照すべき根拠(Citation)」を明示的に与え、その範囲内で回答を強制することで、回答の信頼性を担保します。
- ナレッジ・カットオフ(情報の古さ): LLMの学習データは特定の時点で停止しています。RAGはリアルタイムのデータベースや更新済みの社内文書を検索することで、最新の情報を反映した回答を可能にします。
- 専門性・機密性の欠如: LLMは一般的な知識しか持ちません。RAGは「社内文書」「顧客DB」「専門ナレッジベース」など、非公開の機密情報やドメイン固有の知識を安全に参照させることを可能にします。
開発への影響:精度が出ない7つの原因
「RAGの精度が出ない」と言うとき、現場で起きているのはたいてい次の7つのどれかです。LLMを疑う前に、まずこのリストと照合してください。
- 元データが古い・重複している: 古い規程、重複文書、未整理のPDFが混ざると、LLMは矛盾した根拠をもとに回答します。
- チャンクが大きすぎる/小さすぎる: 大きすぎるとノイズが増え、小さすぎると文脈が切れます。
- メタデータが不足している: 部門、日付、文書種別、権限などの情報がないと、検索結果を適切に絞り込めません。
- ベクトル検索だけに依存している: 固有名詞、型番、規程番号、顧客名などはキーワード検索やフィルタが重要です。
- Rerankerがない: 広く取得した候補を精査しないと、ノイズ文書がLLMに渡ります。
- 評価データがない: 何をもって「良い回答」とするかが定義されていないと、改善できません。
- 本番ログを見ていない: 実際の質問、検索結果、回答、ユーザー評価を見なければ、失敗パターンを把握できません。
どう捉えるべきか
RAGとファインチューニングを混同したまま設計すると、後から作り直しが発生しやすい。両者の役割の違いを最初に切り分けることが重要である。
本質的な見方:RAG vs ファインチューニング(概念整理)
ここで、RAGとファインチューニングの役割の違いを明確にしておきましょう。両者は目的が異なり、補完関係にあります。
- RAG(検索拡張生成): 外部から「知識」を注入・更新する技術です。「何を知っているか」を担当します。
- ファインチューニング: LLMの「振る舞い」や「口調・スタイル」を矯正する技術です。「どう振る舞うか」を担当します。
実務の使い分けはシンプルです。
「来月改定される社内規程を反映させたい」→RAG。
「回答が毎回バラバラで、口調と形式を統一させたい」→ファインチューニング。
「その両方が必要」→組み合わせ。
RAGとファインチューニングを混同して設計すると、半年後に「なぜか直らない」問題の原因を追えなくなります。
詳しい比較は、RAGとファインチューニングの違いで整理しています。
限界と注意点:長文コンテキストLLMが進化してもRAGが必要な理由
長文コンテキストLLMの登場により、「大量の文書をそのままLLMに読ませればよいのではないか」という議論があります。
しかし、業務利用ではコスト、遅延、権限制御、情報の鮮度、根拠提示、ノイズ制御の問題が残ります。
RAGは、LLMにすべてを読ませる技術ではありません。必要な情報だけを検索・選別し、根拠つきで回答させる仕組みです。
したがって、長文コンテキストLLMとRAGは競合ではなく、むしろ補完関係にあります。
アーキテクチャ分類:ClassicからGraphRAGまでの進化
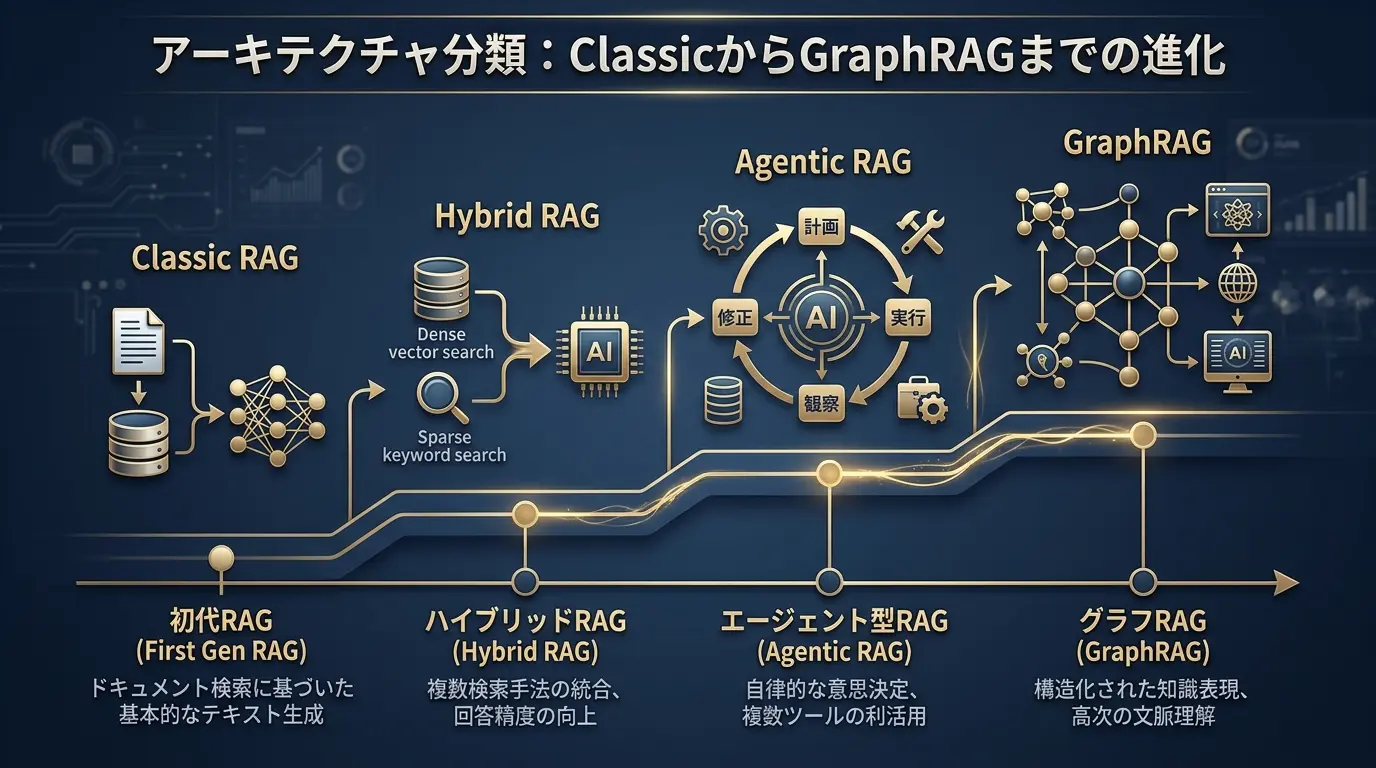
RAGはClassicからHybrid、Agentic、GraphRAGへ進化しています。
重要なのは最新構成を一気に導入することではありません。用途・データ・SLA・運用体制に合わせて段階的に選ぶことです。
Classic RAGは最小構成で、FAQや規程検索に最適です。
Hybrid RAGはBM25×ベクトルや再ランキングでカバレッジと精度を両立します。
Agentic RAGは計画・自己修正・評価のループを回し、運用での頑健性を高めます。
GraphRAGは、単なる意味検索では拾いにくい関係性や構造を扱うための発展形です。
| 分類 | 向いている用途 | 導入時の注意点 |
|---|---|---|
| Classic RAG | FAQ、社内規程検索、単純な文書検索 | 検索失敗がそのまま回答失敗につながる |
| Hybrid RAG | 固有名詞、型番、専門用語が多い業務 | キーワード検索とベクトル検索の重み調整が必要 |
| Agentic RAG | 調査、比較、複数ステップの業務 | ログ、評価、停止条件を設計しないと複雑化する |
| GraphRAG | 関係性、因果、組織構造、取引関係の分析 | グラフ構築と更新運用の設計が必要 |
| Platform RAG | 全社AI基盤、複数部門での共通ナレッジ活用 | 権限制御、監査、データガバナンスを先に決める |
| ※ 出典:2026年版標準選択マトリクス | ||
Classic RAG(第1世代:ナイーブRAG)
- 構造: 「Retrieve → Generate」という「一直線」のシンプルなパイプラインです。
- 思想・課題: 構造が単純で導入が容易ですが、「検索が失敗したら、回答も失敗する」という構造的な脆弱性を抱えています。検索結果にノイズが多いと(Garbage In)、回答もノイズに汚染されます(Garbage Out)。
Hybrid RAG(第2世代:アドバンスドRAG)
- 構造: Classicと同じ「一直線」のパイプラインですが、「Retrieve(検索)工程の内部」が高度化(Hybrid Search + Reranker)した形態です。
- 思想・改善点: 検索の「精度」と「再現率」を徹底的に高め、LLMに渡す情報の品質を最大化するアプローチです。多くの本番環境では、ベクトル検索だけでなく、キーワード検索、メタデータフィルタ、Rerankerを組み合わせる構成が現実的です。
Agentic RAG(第3世代:自己修正RAG)
- 構造: 最大の違いは「一直線」ではなく「ループ(反復)構造」を持つ点です。
- 思想・改善点: エージェント(Agent)と呼ばれる思考コンポーネントが介在します。エージェントは「①計画」し、「②検索を実行」し、結果を「③自己評価」します。もし評価が低い(例:情報が足りない)と判断すれば、「④検索クエリを変えてやり直す(自己修正)」といった自律的な動作が可能になります。
GraphRAG(関係性を扱うRAG)
- 構造: 文書を単なるチャンクの集合として扱うのではなく、人物、企業、製品、技術、契約、取引などの関係性をグラフとして整理します。
- 思想・改善点: ベクトル検索が得意な「意味の近さ」だけでなく、誰が何に関係しているか、どの要素がどの要因につながるかといった構造的な問いに対応しやすくなります。一方で、GraphRAG用のナレッジグラフ構築では、通常のベクトル検索型RAGよりも前処理コストやLLMコール数が増える傾向があります。また、エンティティ抽出や関係抽出の精度は対象ドメインや文書品質に大きく左右されるため、自社データで事前に評価することが重要です。
Platform RAG(クラウド・データ基盤と統合するRAG)
- 構造: Vertex AI、Azure AI Foundry、Databricks、LlamaIndexなどのデータ基盤・AI基盤と連携し、認証、権限制御、ログ、評価、運用まで含めて設計するRAGです。
- 思想・改善点: 部門ごとにバラバラに作ったRAGが、半年後に「誰が管理するかわからない」状態になる——これがPlatform RAGが必要とされる現実です。個別アプリではなく、企業のデータ基盤・AI運用基盤の一部としてRAGを設計することで、権限・監査・改善サイクルを組織として回せるようになります。
Classic RAGは最小構成、Hybrid RAGは検索精度の強化、Agentic RAGは自己修正、GraphRAGは関係性の扱いに強みがあります。重要なのは、最新構成を選ぶことではなく、自社の用途とSLAに合う段階を選ぶことです。
実務ではどう判断するか
PoCは成功した。しかし本番には進めなかった。この停滞を避けるには、データ・評価・権限・運用まで含めた7ステップの判断が必要である。
判断基準:RAG導入ロードマップ(PoCから本番運用まで)
RAGは小さく始められます。
しかし、業務で使い続けるには、データ管理、権限、評価、運用まで含めた設計が必要です。
PoC止まりを避けるには、デモ品質ではなく、本番運用で改善し続ける仕組みを作る必要があります。
以下の7つの手順で進めると、PoC止まりを避けやすくなります。
- ユースケースを絞る: まずは社内規程検索、FAQ、技術文書検索など、成功条件を定義しやすい業務から始めます。
- 対象データを棚卸しする: どの文書を対象にするか、誰が更新するか、どの情報を除外するかを決めます。
- 小さくPoCを作る: 全社データではなく、限定された文書群と代表質問で検証します。
- 評価データを作る: 代表質問、期待回答、参照すべき根拠文書を用意します。
- 精度改善を回す: チャンク、Embedding、検索、Reranking、プロンプトを順に改善します。
- 権限制御・ログ・監査を設計する: 誰がどの文書にアクセスできるか、どの回答を記録するかを明確にします。
- 本番運用で継続改善する: ユーザー評価、失敗ログ、更新文書をもとに、検索品質を改善し続けます。
RAG導入の成否は、PoCのデモ品質ではなく、本番運用で継続的に改善できる仕組みを作れるかで決まります。導入事例やROI観点は、RAG導入成功・ユースケース・ROIで詳しく扱います。
向いているケース:RAG精度改善の全体地図
RAGの精度改善に、一発逆転のテクニックはありません。
精度改善は、生成モデルを替える前に、ETL・チャンキング・検索・評価を疑うところから始めます。
RAGの精度改善は、単一のテクニックではなく、工程ごとの改善を積み上げる取り組みです。特に本番導入では、「なんとなく良くなった」ではなく、評価データを使って改善効果を確認する必要があります。
まず取り組むべきは、データ品質、チャンキング、検索品質です。これらが弱いまま生成モデルだけを強化しても、RAG全体の信頼性は高まりません。
| 改善領域 | 主な施策 | 期待できる効果 |
|---|---|---|
| データ品質 | 重複削除、古い文書の除外、形式統一 | 矛盾回答やノイズの低減 |
| チャンキング | 見出し単位、段落単位、意味単位での分割 | 根拠文脈の保持 |
| Embedding | モデル選定、正規化、多言語対応 | 意味検索の精度向上 |
| 検索 | Hybrid Search、メタデータフィルタ | 検索漏れと誤検索の低減 |
| Reranking | 候補文書の再評価 | LLMに渡す根拠の精度向上 |
| GraphRAG | 関係性・因果・階層構造の活用 | 複雑な問いへの対応力向上 |
| 評価 | Context Recall、Faithfulness、Task Success | 改善効果の定量化 |
| ※ 出典:Arpable精度向上フレームワーク | ||
評価・テスト・運用:何を計測し、どう改善するか

品質計測は再現率(Recall)、精度(Precision)、根拠整合(Citation / Faithfulness)、有用度(Task Success)で行います。
2026年の実務設計では、Ragasなどの指標を用い、自社のユースケースごとに目標値を設定するケースが増えています。たとえば、社内FAQや規程検索のように正確性が重視される用途では、以下のようなスコア帯を一つの目安として採用し、継続的に監視します。
- Faithfulness > 0.90
- Answer Relevancy > 0.85
- Context Precision > 0.80
※本記事で示す評価スコアやコスト増加傾向は、特定ベンダーの公式基準ではなく、公開情報・実務PoC・Arpableの整理に基づく目安です。実際の値は、対象データ、業務領域、評価セット、モデル構成によって変動します。
A/Bテストは同一コーパス・同期間・同温度で比較し、クリック後の満足度まで追跡します。
テストデータはユースケース別の代表質問を10〜30個用意し、異常系(未回答・誤引用)も含めます。代表質問の選定自体は、現場担当(カスタマーサポート、営業、コンサルタントなど)と協働することで、「現場感のある評価セット」になります。
RAG評価の2つの側面(概念整理)
RAGの品質評価は、パイプラインの「検索」と「生成」の2つの側面で捉える必要があります。どちらがボトルネックになっているかを特定することが改善の鍵です。
❶ Retriever(検索)の評価: 検索側が正しく機能しているか。
- Context Precision(検索適合率): 取得した文書は、本当にクエリと関連していたか?(ノイズの評価)
- Context Recall(検索再現率): 回答に必要なグラウンドトゥルース(正解)情報のうち、実際に検索で取得できた割合。以下の数式で定量スコアリングされます。

検索漏れを定量的に評価するための最重要指標です。
❷ Generator(生成)の評価: 生成側が正しく機能しているか。
- Faithfulness(根拠整合性): 生成された回答は、取得した文書の内容に忠実か?(ハルシネーションの評価)
- Answer Relevancy(回答関連性): 最終的な回答は、ユーザーのクエリの意図に答えているか?(的外れな回答の評価)
評価駆動開発(Evaluation-Driven Development)の思想
「動いているように見えるが、実際に正しいかどうか分からない」——これがRAGの最も危険な状態です。
RAG開発は「作って終わり」ではありません。評価指標を先に定義し、そのスコアを継続的に改善する「評価駆動開発」の思想が不可欠です。
評価指標のないRAG運用は、計器なしで飛ぶ飛行機に似ています。晴天では問題なく見えても、荒天になって初めて、何も見えていなかったことに気づきます。
本番環境では、これらの指標をリアルタイムで監視する「可観測性(Observability)」の設計が運用品質の生命線となります。
評価ログは「改善の地図」である
RAGの評価ログは、単なる監査記録ではありません。
どの質問で検索に失敗したのか、どのチャンクがノイズになったのか、どの回答が根拠とずれたのかを把握するための改善の地図です。
本番運用では、少なくとも質問、取得文書、回答、引用、ユーザー評価、失敗理由を記録し、検索側と生成側のどちらに問題があるのかを切り分けられるようにします。
運用品質の落とし穴(回避策)
① チャンク過大→要点喪失。② メタデータ不足→フィルタ不可。③ Rerank未整備→ノイズ混入。
まずはRetriever上流を改善し、生成側は引用必須・禁止語で制約します。
「RAGは死んだ」は本当か――2026年の最前線
一次情報で見るRAGの5大進化
「RAGは死んだ」。近年、単純なベクトル検索型RAGの限界を語る文脈で、こうした刺激的な言い方を見かけることがあります。
しかし、正確にはRAGが死んだのではありません。死んだのは、「検索結果をLLMに渡せば何とかなる」という素朴なRAG観です。
RAGは不要になったのではなく、Classic RAGからHybrid RAG、Agentic RAG、GraphRAG、Platform RAGへと進化しています。ここで見るべきなのは、流行語ではなく、どの業務にどの構成が必要なのかという実務判断です。
最新の技術動向・ドキュメント解説から読み解ける、RAGの現在地は以下の通りです。
動向1:Agentic RAG(検索・評価・再検索の自律化)
従来のRAGは「1回検索して答える」構造でした。これは、試験前に教科書を1ページだけ読んで解答するようなものです。
Agentic RAGは、この前提を変えます。まず何を調べるべきかを考え、検索し、結果を自己評価し、足りなければ別の角度で再検索する。人間のリサーチャーに近い思考ループを持つ構成です。
ただし、Agentic RAGは最初から導入するものではありません。Classic RAGやHybrid RAGで限界が見えた後に検討する拡張です。
まずはClassic RAGで対象業務を絞り、検索品質を高め、評価データを整えたうえで、必要に応じてAgentic化するのが現実的です。
動向2:Multi-modal RAG(テキスト以外の検索)
従来のRAGはテキスト(Text)データが対象でした。
最新の動向では、画像、表(Table)、音声(Audio)データも検索対象とする「マルチモーダルRAG」が注目されています。
「このグラフが示す傾向は?」「この製品写真の型番は何か?」「先週の会議で決まったことは?」——テキストだけでは答えられなかった問いが、検索の射程に入り始めています。
動向3:GraphRAG(関係性の検索)
ベクトル検索は「意味が似ている文書を探す」技術です。
しかし、「A社とB社の共通の取引先は?」「この不具合はどの製品ラインに連鎖するか?」といった問いは、意味の近さだけでは解けません。関係性のネットワークを辿る必要があります。
GraphRAGは、文書間の人物・企業・取引・契約などをグラフ構造として整理し、ベクトル検索では届かない「つながり」を検索可能にします。
図書館で「この本に似た本」を探すのがベクトル検索なら、GraphRAGは「この著者と共著関係にある人物が書いた本」を探せる仕組みです。
動向4:RAGの自動最適化(AutoRAG / Self-RAG)
RAGのパイプラインは非常に複雑です。どのEmbeddingモデル、どのチャンキング戦略、どのLLMを選ぶかによって性能が大きく変わります。
この最適な組み合わせ自体をAIが自動で評価・構築する「AutoRAG」や、検索結果を自己評価して再検索する「Self-RAG」系のアプローチが注目されています。
これが成熟すると、「RAGのチューニングにエンジニアが週単位の工数を費やす」という現在の常識が変わる可能性があります。
まだ発展途上ですが、方向性として注目に値します。
動向5:LLMのコンテキストウィンドウ巨大化の影響(RAGは不要になるか?)
LLMが一度に読める情報量(コンテキストウィンドウ)は拡大しています。
「すべての文書をLLMに直接読み込ませればRAGは不要になる」という議論がありますが、結論から言えばRAGの重要性は変わりません。
理由は4つあります。①全文投入のコストとレイテンシは現実的ではありません。②大量の無関係情報を与えるとLLMの精度が逆に落ちます。③部門や役職による権限制御が設計しにくくなります。④リアルタイムの知識更新には検索・更新基盤が不可欠です。
コンテキストが広がるほど、「何を読ませないか」を決める仕組みの価値は上がります。
RAGは「長文コンテキストLLMに与える最適な情報を絞り込む」役割として、むしろ重要性を増しています。
まとめ
読者が持ち帰るべきなのは情報ではありません。次に何を判断し、どう動くべきかです。
RAGの本質は、工程分解、評価駆動、知識基盤化です。
そして今あなたに問われているのは、「導入するかどうか」だけではありません。どのアーキテクチャを、いつ、どの順番で選ぶかという経営判断です。
数か月後に使われなくなるRAGを作らないために、最初の一手は華やかなAgentic RAGではなく、地味だが確実なデータの棚卸しです。
まずはETL・チャンキング・Embedding・検索の品質を固め、ニーズに応じてClassic→Hybrid→Agentic→GraphRAGへ段階的に発展させましょう。
重要なのは、RAGを「LLMに検索結果を渡すだけの仕組み」と見ないことです。業務で使えるRAGには、データ更新、権限制御、評価、監査ログ、改善サイクルが必要です。
RAGは、社内知識をLLM時代の業務資産へ変えるための基盤です。
次に読むべきなのは、あなたの課題に一番近いスポーク記事です。精度が課題なら精度改善へ、構成が課題ならAgentic RAGやGraphRAGへ、導入判断が課題ならRAG導入成功の記事へ進んでください。
Key Takeaways(持ち帰りポイント)
- まず対象データを棚卸しする:古い文書、重複文書、権限不明の文書を除外し、RAGに読ませる情報を整理する。
- 次に評価セットを作る:代表質問、期待回答、参照すべき根拠文書を用意し、改善前後を比較できる状態にする。
- 最後に構成を選ぶ:Classic、Hybrid、Agentic、GraphRAGの順に、業務要件とSLAに合わせて段階的に発展させる。
専門用語まとめ
- Hybrid RAG
- キーワード検索(BM25等)とベクトル検索を組み合わせ、カバレッジと精度を両立させる方式。
- Reranker
- 取得候補を関連度で並べ替えるモデル。クロスエンコーダ等を用い、誤検出の抑制に有効。
- 可観測性(Observability)
- ログや指標を通じて挙動を把握し、品質改善につなげる設計思想。運用の肝。
- Agentic RAG
- AIエージェントが検索計画、再検索、自己評価、ツール実行などを行う発展型RAG。
- GraphRAG
- 文書間の関係性や構造をナレッジグラフとして扱い、複雑な問いに対応するRAGの発展形。
- Chunking
- 文書を検索しやすい単位に分割する処理。大きすぎるとノイズが増え、小さすぎると文脈が切れる。
- Embedding
- 文章や単語の意味を数値ベクトルへ変換する技術。意味検索や類似検索の基礎となる。
- Faithfulness
- 生成された回答が、取得した根拠文書に忠実であるかを示す評価観点。
参考文献 / 出典
一次情報
- LangChain Conceptual Guide – Retrieval
- LangChain Conceptual Guide – RAG
- Ragas Documentation – Evaluation framework for RAG
- Microsoft GraphRAG Documentation
関連公式ドキュメント
次に読むならこの3本
補足Q&A
最後に、RAG導入時によく出る疑問を整理します。ここは実務判断のショートカットとして読んでください。
Q1.
Classic RAG、Hybrid RAG、Agentic RAGはどれを選ぶべきですか?
A1.
まずは対象業務のSLAとデータ要件に応じて段階的に選択すべきである。
最初から複雑な構成にするより、段階的に進化させる方が安全です。
定型的なFAQや社内規程検索なら、Classic RAGまたはHybrid RAGから始めます。
複数ステップの調査、比較分析、レポート生成が必要になった段階で、Agentic RAGを検討します。
Q2.
RAGの精度改善はどこから始めるべきですか?
A2.
LLMを変更する前に、必ず元データ、チャンキング、検索エンジンの設定を先に見直すべきである。
多くの場合、精度低下の根本的な原因は生成モデル(LLM)ではなく、前段の検索側(Retriever)や元データのノイズにあります。
メタデータの付与、Hybrid Searchの導入、Rerankerの整備、そして定量的評価データの作成から着手するのが鉄則です。
Q3.
評価データ(グラウンドトゥルース)はどう作ればよいですか?
A3.
対象とするユースケースごとに、現場業務のリアルな代表質問を10〜30個用意して整理すべきである。
各質問に対し、「期待される正しい回答」「参照すべき根拠文書(チャンクID)」「想定される誤回答例」を紐付けます。
未回答にすべき質問や、古い情報を参照しがちな異常系のケースを含めることで、実運用に近い頑健な評価セットが構築できます。
Q4.
RAGとファインチューニングはどう使い分けますか?
A4.
知識の注入・動的更新はRAG、固有の振る舞いや口調・出力形式の調整はファインチューニングと使い分けるべきである。
社内文書、最新情報、顧客データなどをLLMに参照させたい場合は、まずRAGを検討します。
一方で、回答のメタ表現を特定のサポート口調に統一したい場合や、特殊なコード形式で常に出力させたい場合にファインチューニングを組み合わせるのが最適です。
Q5.
長文コンテキストLLMがあればRAGは不要ですか?
A5.
コンテキストウィンドウが巨大化しても、実務におけるRAGの必要性は大きく変わりません。
大量の文書をそのままLLMに投入すると、コストの大幅な増加、遅延(レイテンシ)の悪化、情報の鮮度管理の難化、きめ細かな閲覧権限制御の喪失、精度低下といった実務上の致命的な課題が残るためです。
Q6.
RAG導入の主なコストは何ですか?
A6.
ベクトルDBの運用・ストレージ費用、Embeddingの計算費用、LLMの推論APIコスト、データメンテナンス費用である。
インフラやモデルのAPI費用に加えて、社内文書の整備、古くなったドキュメントのパージ(削除)、権限変更の追随などが必要です。
システムを健全に維持するための「データ運用側の人的・運用的コスト」が、中長期的な総所有コスト(TCO)の多くを占めます。
Q7.
Agentic RAGは最初から導入すべきですか?
A7.
多くの場合、初期構築からAgentic RAGを選択する必要はない。
まずはClassic RAGやHybrid RAGの構成で対象業務のデータ品質と評価スコア(ベースライン)を固めるのが先決です。
シンプルな検索ではどうしても取りこぼす、複数ステップの自律的な推論や、自己修正ループが必要になった段階で、拡張として導入するのが安全なアプローチです。
更新履歴
- 2024年12月18日:初版公開
- 2025年07月10日:構成見直し(パイプライン全体の体系化)
- 2025年10月25日:最新情報へのアップデート、読者支援機能(中間拡張)の強化
- 2026年05月19日:RAG関連記事群の再設計に伴い、2026年版の正典ハブとして構成を刷新。Arpableテンプレート v11.3への適合、RAGAS評価指標の実務目安、GraphRAGのコスト制約、速読性向上のための段落分割・強調表現を反映。








