


※本記事は継続的に最新情報へアップデートしています。
RAGデータパイプラインとは、PDF・Word・HTML・表・画像・社内文書を、AIが検索できる「知識データ」へ変換する一連の設計である。
RAGの精度は、検索時ではなく、取り込み時にかなり決まっている。古い文書、重複、表崩れ、権限違い、出典不明のチャンクが混ざれば、どれほど高性能なLLMを使っても回答は不安定になる。
本記事では、RAGを壊さないためのデータパイプライン設計を、前処理、メタデータ、差分更新、権限制御、品質評価まで含めて実務目線で解説する。
✅ 先に結論
RAGデータパイプラインの本質は、文書をそのままAIに渡すことではありません。文書を、検索できる知識に変えることです。
- ポイント1:RAGは、LLMに聞く前に勝負が決まっています。PDFの表崩れ、古い版、重複文書、出典不明のチャンク、権限違いが混ざると、検索品質は一気に落ちます。
- ポイント2:データパイプラインは、Extract、Clean、Structure、Metadata、Chunk、Embed、Index、Update、Permissionまでを含む設計です。ETLはその一部として理解すると実務に合います。
- ポイント3:本番RAGでは、初回投入よりも「更新し続ける仕組み」が重要です。差分更新、重複除去、版管理、アクセス制御、品質評価を最初から設計する必要があります。

何が変わったのか
RAGの改善ポイントは、プロンプトやモデル選定だけでなく、検索前のデータ品質設計へ移っている。
ある企業が、「社内の問い合わせは、まずRAGに聞く」を合言葉に、数千本のPDF、Word、議事録、社内規程、FAQ、問い合わせ履歴を一気にベクトルDBへ流し込みました。数ヶ月の構築期間と相応の投資をかけ、いよいよ社内展開というタイミングで、テスト回答が微妙にズレ始めます。
社長が「最新の出張旅費規程」を聞くと、3年前に廃止したルールが根拠として提示されます。別のチームでは、営業条件の表が崩れたまま回答に混ざり、さらに本来は部長以上しか見られない人事資料が候補として表示されてしまいました。
「モデルを変えれば良くなるはずだ」と考えていましたが、原因はLLMでもEmbeddingモデルでもありませんでした。負けていたのは、その一歩手前——文書を取り込む設計そのものだったのです。
RAGは、文書を入れれば賢くなる仕組みではありません。文書を抽出し、整え、構造化し、メタデータを付け、適切な粒度に分割し、更新し続けることで初めて、検索できる知識基盤になります。
この入口の設計が、RAGデータパイプラインです。従来のETLは、データウェアハウスや業務DB向けに「抽出・変換・格納」を行う考え方でした。RAGではそこに、文書構造、出典、チャンク、Embedding、権限、差分更新、検索評価が加わります。
RAG全体の設計は RAG完全ガイド、チャンクの切り方は RAGチャンキング最適化、Embedding設計は RAG Embedding最適化 で詳しく扱いました。本記事では、その前段にある「文書をAIが使える知識に変える工程」に集中します。
データ準備ではなく、検索品質の設計である
| 観点 | 従来のETL | RAGデータパイプライン |
|---|---|---|
| 主な対象 | 構造化データ、業務DB、ログ | PDF、Word、HTML、表、画像、議事録、社内ナレッジ |
| 目的 | 集計・分析しやすい形に整える | 検索・引用・生成に使える知識へ変換する |
| 重要な情報 | カラム、型、キー、日付 | 本文、見出し、ページ、表、図、出典、権限、版数 |
| 失敗時の症状 | 集計値がズレる | 回答が古い、根拠が追えない、検索で必要文書が出ない |
| 運用の要点 | 定期バッチ、整合性、監査 | 差分更新、重複除去、アクセス制御、検索評価、再Embedding |
この違いを押さえると、RAGデータパイプラインは「裏方の前処理」ではなく、検索品質そのものを作る設計だと分かります。
なぜ今重要なのか
社内文書は、AIにとって読みやすい形では存在していない。だから、取り込み設計がRAGの成否を分ける。
企業の知識は、きれいなテキストファイルとして存在しているわけではありません。
PDF、Word、Excel、PowerPoint、HTML、メール、チャット、チケット、画像、スキャン文書、契約書、仕様書、議事録、FAQが混在しています。
しかも、それぞれの文書には問題があります。
PDFは表が崩れることがあります。Wordは見出し構造が失われることがあります。Excelは行列の意味を保たないと検索しにくくなります。画像やスキャン文書にはOCRが必要です。古い版と最新版が混在すれば、RAGは古い情報を根拠に回答するかもしれません。
LangChainのDocument Loadersは、Slack、Notion、Google Driveなど多様なソースをDocument形式へ読み込むための標準インターフェースを提供しています。
LlamaIndexのIngestion Pipelineは、Transformationsのチェーンとキャッシュを組み合わせ、大量文書でも再処理コストを抑えながらノード生成やVector DBへの投入を行えます。
Unstructuredは、PDF、HTML、Word、PowerPoint、Spreadsheet、画像、メールなど幅広い非構造化文書を処理できる前処理プラットフォームです。
さらに、UnstructuredのContextual Chunkingでは、文書全体の文脈をチャンクに補足することで、複雑な企業文書の検索失敗を減らす方向性が示されています。
公式ブログでは、AnthropicのContextual Retrieval研究における平均35%のretrieval failure削減や、UnstructuredによるSEC 10-K文書評価での84%削減が紹介されています。
ただし、これは特定の手法・評価条件に基づく結果であり、すべてのRAGパイプラインで同じ改善率を保証するものではありません。実務では、自社ドメインの評価セットを用意し、同様の手法がどの程度効くかを必ず検証してから本番適用するのが安全です。
これらのツールが加速度的に整備されている背景には、「RAGの最大のボトルネックはLLMではなくデータ取り込みだ」という、現場の共通認識があります。
検索する前に、すでに負けていることがある

| 問題 | 何が起きるか | 必要な対策 |
|---|---|---|
| 古い文書が混ざる | 廃止済みルールを根拠に回答する | version、updated_at、statusをメタデータ化する |
| 表が崩れる | 金額、条件、対象部署の対応関係を誤る | 表抽出、Markdown化、行列の意味保持を設計する |
| 重複文書が多い | 同じ内容が検索上位を占め、重要文書が埋もれる | ハッシュ、doc_id、正規化、重複除去を行う |
| 出典がない | 回答の根拠を人間が確認できない | source、page、section、urlを必ず保持する |
| 権限情報がない | 見せてはいけない文書が検索候補に入る | access_role、department、tenant_idを設計する |
| 差分更新がない | 公開直後からインデックスが古くなる | 変更検知、再処理、再Embeddingの範囲を決める |
RAGの改善でモデルやプロンプトを見直す前に、まず「検索対象の知識が壊れていないか」を確認する必要があります。Vector DBに入れる前に、勝負は半分終わっています。
RAGデータパイプラインとは何か

RAGデータパイプラインは、文書を抽出し、整え、構造化し、検索基盤へ渡す知識化プロセスである。
RAGデータパイプラインは、単純なETLより広い概念です。Extract、Transform、Loadという基本形はありますが、RAGではその間に、文書解析、クリーニング、構造化、メタデータ付与、チャンキング、Embedding、Indexing、差分更新、権限制御が入ります。
では、本番RAGで本当に必要な工程は何でしょうか。ETLの「3工程」で収まると思ったなら、それが最初の落とし穴です。
| 工程 | やること | 主な設計論点 |
|---|---|---|
| Source Selection | 取り込む文書・データソースを決める | 対象範囲、責任部署、更新頻度、利用目的 |
| Extract | PDF、Word、HTML、画像などから情報を抽出する | OCR、表抽出、レイアウト保持、添付ファイル |
| Clean | 不要な文字、重複、ノイズを除去する | ヘッダー、フッター、改行、文字化け、広告領域 |
| Structure | 見出し、表、箇条書き、ページ構造を保持する | Markdown化、HTML構造、表の意味保持 |
| Metadata | 出典、版数、権限、日付、部署を付与する | source、page、version、access_role、tenant_id |
| Chunk | 検索しやすい知識単位へ分割する | 構造認識、親子チャンク、可変長、オーバーラップ |
| Embed | チャンクを意味ベクトルへ変換する | Embeddingモデル、次元数、コスト、再Embedding条件 |
| Index | Vector DBや検索基盤へ格納する | Hybrid Search、メタデータフィルタ、RRF、Reranker連携 |
| Update | 変更を検知し、必要部分だけ再処理する | 差分更新、重複除去、削除、版管理、監査 |
この中で、チャンキングは非常に重要です。ただし、チャンキングだけを改善しても、抽出が崩れていたり、メタデータがなかったり、更新運用がなかったりすれば、本番RAGは安定しません。
実際、ある製造業のプロジェクトでは、「まずはチャンクサイズとオーバーラップだけを最適化しよう」という方針でPoCを進めました。しかし、ローンチ後にユーザーから上がってきた不満は、「欲しい文書がそもそも引っかからない」「どの版を根拠にしているのか分からない」というものばかりでした。
調べてみると、PDFの表が崩れたまま取り込まれていたり、最新版の規程にversion情報が付いていなかったことが原因でした。チャンクはあくまで「切り方」の工夫に過ぎません。そもそもの素材、つまり抽出結果とメタデータが壊れていれば、どれだけ上手に切っても、検索は安定しないのです。
詳しいチャンキング設計は RAGチャンキング最適化 を参照してください。
ETLは入口、RAGではその先がある
ETLという言葉は便利ですが、RAGでは少し足りません。たとえば、文書を抽出してベクトルDBに格納するだけなら、ETLと呼べます。しかし、本番RAGでは、検索時に「誰が」「どの版の」「どの文書の」「どのページを」「どの権限で」参照してよいかまで考える必要があります。
そのため、本記事ではETLを含む広い概念として「RAGデータパイプライン」と呼びます。つまり、ETLはゴールではなく、RAGを安全に動かすための入口です。
実務ではどう設計するか
実務のRAGデータパイプラインは、文書形式、メタデータ、更新、権限、評価を同時に設計する必要がある。
RAGデータパイプラインは、ツールを入れれば完成するものではありません。最初に決めるべきなのは、どの文書を、どの目的で、どの権限範囲で、どの頻度で更新し、どの検索品質を目指すかです。
たとえば、社内規程RAG、営業資料RAG、障害報告RAG、契約書RAGでは、取り込む文書も、必要なメタデータも、評価すべき質問も異なります。全社文書を一気に入れるより、まず1つの業務領域を選び、パイプラインを検証する方が安全です。
文書形式ごとの取り込み設計
文書形式ごとの違いを軽く見ると、RAGは静かに壊れます。PDF、表、スキャン画像、チャットログは、同じ「テキスト化」で済む相手ではありません。
| ソース | よくある課題 | 設計ポイント |
|---|---|---|
| 表崩れ、段組み、ヘッダー・フッター、スキャン画像 | レイアウト抽出、OCR、ページ番号保持、表のMarkdown化。複雑なPDFでは、LlamaParseのようなRAG向けパーサーを併用するのも選択肢になる | |
| Word / PowerPoint | 見出し階層、コメント、図表、箇条書きの意味が落ちる | 見出し構造、スライド番号、図表キャプションを保持する |
| HTML / Web | ナビゲーション、広告、関連記事、重複領域が混ざる | 本文抽出、不要領域除去、URL・更新日・見出しを保持する |
| Excel / 表 | 行列の意味、単位、結合セル、注釈が失われる | テーブル構造を保ち、列名・単位・注釈を本文化する |
| 画像 / スキャン文書 | OCR誤り、図の意味、手書き、低解像度 | OCR、画像キャプション、信頼度、原画像リンクを保持する |
| チャット / チケット | 短文、ノイズ、時系列、担当者名、ステータス | スレッド単位、時系列、担当部署、解決済みフラグを設計する |
ここで重要なのは、抽出したテキストだけを見ないことです。文書の構造、出典、日付、権限、表の意味、画像の説明も含めて検索対象にすることで、RAGの回答は大きく安定します。
メタデータ設計:住所のない荷物を探さない

メタデータのないRAGは、住所のない荷物を探すようなものです。本文だけを検索できても、それがどの文書の、どのページの、どの版の、誰が見てよい情報なのか分からなければ、本番では使えません。
| メタデータ | 目的 | 例 |
|---|---|---|
| source_id | 文書単位の識別 | doc-2026-001、contract-a-12 |
| source_url / file_path | 元文書へ戻る | SharePoint URL、S3 path、社内Wiki URL |
| page / section | 引用・根拠確認 | p.12、第3章、FAQ-05 |
| version / status | 最新版・廃止版の制御 | v3.2、active、deprecated |
| updated_at | 鮮度判断 | 2026-05-21 |
| access_role | 権限制御 | public、internal、hr、management |
| tenant_id / department | 顧客・部署ごとの分離 | customer-a、sales、quality |
| content_hash | 重複検知・差分更新 | SHA256などのハッシュ値 |
メタデータ設計は、あとから追加しようとすると大きな手戻りになります。特に権限制御と版管理は、PoC段階から最小限入れておくべきです。検索精度だけでなく、セキュリティと監査の土台になるからです。
差分更新:公開直後から古くなるRAGを防ぐ
 RAGは、一度インデックスを作れば終わりではありません。社内規程は更新され、FAQは追加され、障害報告は増え、契約書は改訂されます。差分更新のないRAGは、公開直後から少しずつ古くなります。
RAGは、一度インデックスを作れば終わりではありません。社内規程は更新され、FAQは追加され、障害報告は増え、契約書は改訂されます。差分更新のないRAGは、公開直後から少しずつ古くなります。
毎晩フル再処理していませんか。文書が増えるほど、再処理コストは静かに膨らみます。コストが跳ね上がる前に、差分設計の論点を確認しておきましょう。
LlamaIndexのIngestion Pipelineでは、Transformationsを適用し、結果をノードとして返すかVector DBへ挿入できます。また、キャッシュを使うことで、同じノードと変換の組み合わせを再利用できます。こうした仕組みは、RAGの再処理コストを抑えるうえで重要です。
| 論点 | 設計内容 | 失敗するとどうなるか |
|---|---|---|
| 変更検知 | ファイル更新日、ハッシュ、doc_idで変更を検知する | 古い文書が残り続ける |
| 削除検知 | 削除・廃止された文書を検索対象から外す | 廃止済みルールを回答に使う |
| 再チャンキング | 変更文書だけを再分割する | 毎回全件処理になりコストが増える |
| 再Embedding | 変更チャンクだけを再ベクトル化する | 更新漏れや無駄なEmbeddingコストが出る |
| インデックス更新 | 追加・更新・削除をVector DBへ反映する | 検索結果に古いチャンクと新しいチャンクが混在する |
| 監査ログ | いつ、何を、誰が、どのパイプラインで処理したかを記録する | 障害時に原因追跡できない |
本番RAGで重要なのは、初回投入の美しさではありません。変化する文書を、壊さず、漏らさず、過剰コストにせず、更新し続けることです。
品質評価:取り込み結果をどう検査するか
データパイプラインは、作って終わりではありません。取り込んだ結果を検査する必要があります。どれだけ高性能なパーサーを使っても、PDFの表が崩れたり、OCRが誤ったり、不要なフッターが残ったりすることはあります。
| チェック項目 | 見るべきポイント | 確認方法 |
|---|---|---|
| 抽出品質 | 本文、表、見出し、ページ番号が正しく取れているか | 代表文書を人手でサンプリング確認 |
| ノイズ除去 | ヘッダー、フッター、広告、目次だけのチャンクがないか | ランダムチャンクを一覧確認 |
| メタデータ | source、page、version、access_roleが欠けていないか | メタデータ欠損率を集計 |
| 重複 | 同じ文書や同じチャンクが大量にないか | hash、近似重複、doc_idで確認 |
| 検索評価 | 期待文書がTop-kに入るか | 評価質問セットでRecall@kやMRRを見る |
| 回答品質 | 回答が根拠に忠実か、出典を示せるか | RAG評価セット、LLM-as-a-judge、人手評価 |
検索精度の改善方法は、RAG精度改善ガイド で詳しく整理しています。ETL記事では、その前提となる「評価できるデータの状態」を作ることが重要です。
Embedding・Vector DB・GraphRAGへどうつなぐか
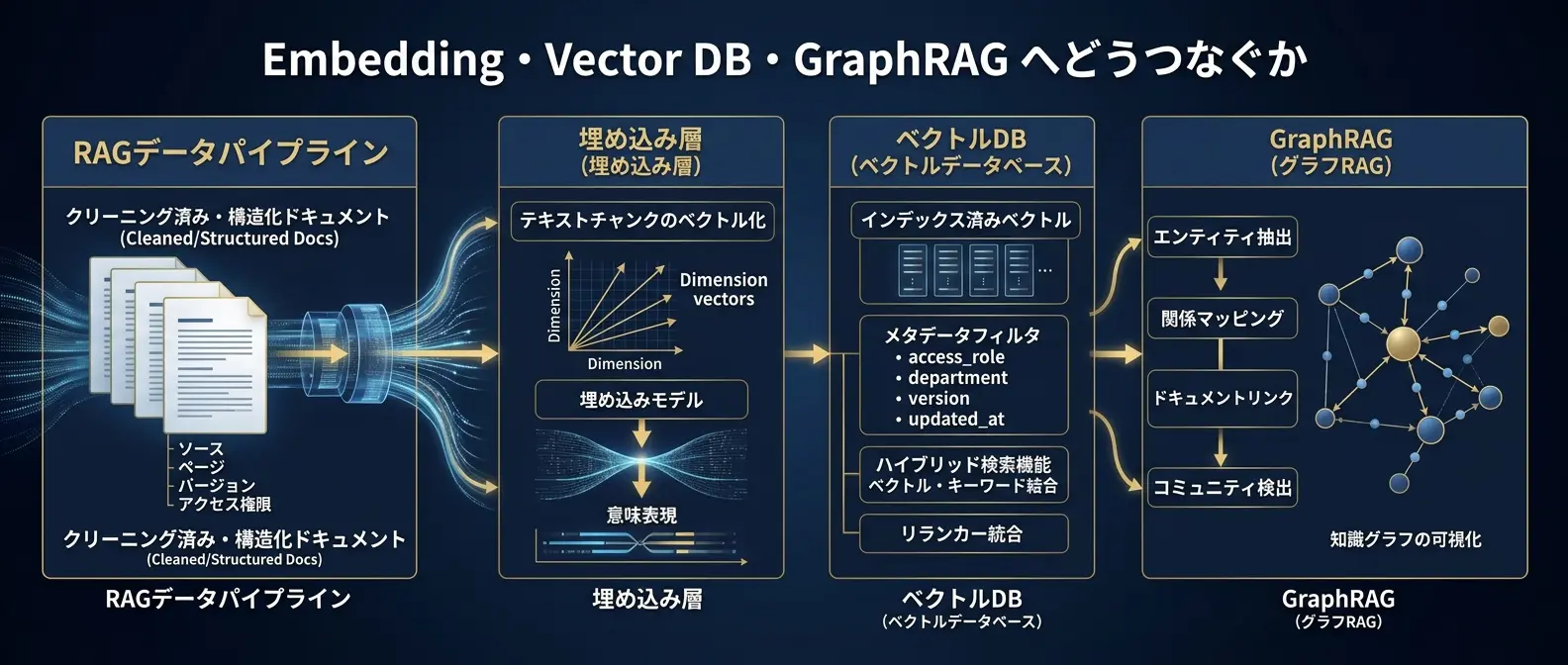
データパイプラインの出口は、Embedding、Vector DB、GraphRAGへつながる検索基盤である。
RAGデータパイプラインは、単独で完結しません。整えたデータは、Embeddingされ、Vector DBへ格納され、必要に応じてHybrid SearchやGraphRAGに使われます。つまり、パイプラインの出口設計は、後段の検索方式とセットで考える必要があります。
たとえば、Vector DBでメタデータフィルタを使うなら、パイプライン側でaccess_role、department、version、updated_atを付けておく必要があります。GraphRAGでエンティティや関係を使うなら、文書から人物名、製品名、部品名、顧客名、契約名などを抽出し、元文書と紐づける必要があります。
| 後段の用途 | パイプラインで必要な準備 | 関連する設計記事 |
|---|---|---|
| Embedding検索 | チャンク本文、見出し、親子関係、ノイズ除去 | RAG Embedding最適化 |
| Vector DB検索 | source、page、version、access_role、updated_at | ベクトルDB完全ガイド |
| Hybrid Search | キーワードに強い本文整形、見出し、型番、法令番号 | ベクトルDB完全ガイド |
| GraphRAG | Entity、Relationship、文書ID、出典、コミュニティ化の材料 | GraphRAG設計ガイド |
| Agentic RAG | 再検索可能なメタデータ、評価可能な根拠、検索ログ | Agentic RAG実務判断ガイド |
RAGのデータパイプラインは、後段の検索方式から逆算して設計するのが安全です。「とりあえず全部テキスト化して入れる」ではなく、「どの検索で、どの情報を、どの条件で取り出したいか」から逆算します。
よくある失敗:「全部取り込めば賢くなる」という幻想

RAGデータパイプラインの失敗は、文書量を増やすほど賢くなるという誤解から始まりやすい。
「社内文書を全部入れれば、AIが何でも答えてくれる」——この期待は、多くのRAGプロジェクトを遠回りさせます。実際には、壊れた文書、古い文書、重複文書、権限のない文書を増やすほど、検索は難しくなります。
「入れるほど賢くなる」——この勘違いが、RAGプロジェクトを静かに失速させます。増やすべきなのは文書量ではなく、検索できる形に整えられた信頼できる知識です。
| 失敗 | なぜ問題か | 回避策 |
|---|---|---|
| PDFをそのまま入れる | 表崩れ、段組み、脚注混入で意味が壊れる | 抽出結果をサンプリングし、表・見出し・ページを検査する |
| 古い文書と最新版を混ぜる | 廃止済みルールを根拠に回答する | version、status、updated_atで制御する |
| メタデータを後回しにする | 出典、権限、版数で絞れない | PoC段階から最低限のメタデータを付与する |
| 全件再処理しかできない | 更新のたびにコストと時間が膨らむ | doc_id、hash、差分更新、キャッシュを設計する |
| 権限制御を検索後に考える | 見せてはいけない候補が検索結果に混ざる | 検索前フィルタに使えるaccess_roleを設計する |
| 評価セットがない | 改善したかどうか判断できない | 代表質問と期待根拠文書を用意する |
特に危険なのは、PoCで「とりあえず動いた」状態のまま本番化することです。PoCでは10個のPDFで動いても、本番では数万文書、複数部署、権限、更新、監査が入ります。
結果として、社長の肝いりで導入したAIアシスタントが、古いルールや誤った表を根拠に回答してしまい、現場から一気に信用を失う。こうしたシナリオは、RAG導入で起きやすい典型的な失敗パターンです。
金融なら誤った商品条件や規制対応、製造なら誤った仕様書や作業手順が混ざりかねません。一度信用を失うと、単にRAGプロジェクトが止まるだけでなく、「AIを業務判断に使うこと」そのものへの社内合意形成が難しくなります。
最初からすべて作り込む必要はありません。しかし、「あとで必ず必要になる設計項目」をPoCの段階で把握し、小さくても入れておくことが、RAGプロジェクトを守るセーフティネットになります。
まとめ
RAGデータパイプラインは、文書をAIが使える知識へ変える、RAG成功の入口である。
RAGの精度は、検索時ではなく、取り込み時にかなり決まっています。LLMやEmbeddingモデル、Vector DBを改善しても、入力される文書が壊れていれば、回答は安定しません。
RAGデータパイプラインでは、PDFやWord、HTML、表、画像、チャット、チケットなどを抽出し、ノイズを除去し、構造を保ち、メタデータを付け、適切にチャンク化し、Embeddingして検索基盤へ渡します。さらに、本番では差分更新、重複除去、権限制御、監査、品質評価が欠かせません。
RAGは、文書を入れれば賢くなる仕組みではありません。文書を「検索できる知識」に変える設計こそが、RAGの品質を決めます。
明日、あなたの組織でできる一歩は、大げさなものではありません。代表的な文書を10件だけ選び、「抽出結果が人間の目で読んで意味が通るか」「source、page、version、updated_at、access_roleが付いているか」をチェックしてみてください。
その小さな診断こそが、「なんとなくのRAG PoC」から「事業の武器としてのRAG基盤」へ進む最初のスイッチになります。
📋 明日から使えるRAGデータパイプライン診断
- 代表的な文書を10件選び、抽出後のテキストを人間が読んで意味が通るか確認する。
- source、page、version、updated_at、access_roleの5つが各チャンクに付いているか確認する。
- 古い文書、重複文書、廃止文書が検索対象に混ざっていないか確認する。
- 代表質問を10個作り、期待する根拠文書がTop-kに入るか確認する。
- 文書更新時に、変更部分だけを再処理・再Embeddingできるか確認する。
Key Takeaways(持ち帰りポイント)
- RAGの精度は、LLMに聞く前、つまりデータ取り込み時点で大きく決まる。
- RAGデータパイプラインは、Extract / Transform / Loadだけでなく、構造化、メタデータ、差分更新、権限制御まで含む。
- チャンキングは重要だが、抽出品質、メタデータ、更新運用が弱いと本番RAGは安定しない。
- メタデータのないRAGは、出典確認、版管理、権限制御、検索フィルタでつまずく。
- 本番RAGでは、初回投入よりも、文書を安全に更新し続ける仕組みが重要である。
専門用語まとめ
- RAGデータパイプライン
- 文書やデータを抽出・前処理・構造化・メタデータ付与・Embedding・Indexingし、RAGで検索できる知識へ変える一連の処理。
- ETL
- Extract、Transform、Loadの略。データを抽出し、変換し、格納する処理。RAGではこれに文書構造、メタデータ、Embedding、更新運用が加わる。
- Document Ingestion
- PDF、Word、HTML、画像、チャットなどの情報源から、RAGで扱える文書データを取り込む工程。
- クリーニング
- ヘッダー、フッター、文字化け、広告、重複、不要な改行など、検索品質を下げるノイズを除去する処理。
- メタデータ
- データに関する付帯情報。RAGではsource、page、version、updated_at、access_roleなどが検索品質と安全性を支える。
- 差分更新
- 変更された文書やチャンクだけを再処理・再Embeddingし、検索インデックスへ反映する運用方式。
参考文献 / 出典
一次情報 / 公式ドキュメント
- LangChain Documentation – Document loader integrations
- LangChain Documentation – Text splitter integrations
- LlamaIndex Documentation – Ingestion Pipeline
- LlamaIndex Documentation – Metadata Extraction
- Unstructured Documentation – Open Source Overview
- Unstructured Documentation – Supported file types
- Unstructured Blog – Contextual Chunking in Unstructured Platform
- LlamaIndex Blog – Parsing PDFs with LlamaParse
- Microsoft Learn – Indexers in Azure AI Search
- Microsoft Learn – Skillsets in Azure AI Search
- Pinecone Learn – Chunking Strategies for LLM Applications
次に読むならこの3本
補足Q&A
Q1.
RAGデータパイプラインとは何ですか?
A1.
社内文書や各種データを、RAGで検索・引用・生成に使える知識データへ変換する一連の処理です。
PDFやWordからの抽出、前処理、構造化、メタデータ付与、チャンキング、Embedding、Vector DBへの格納、差分更新まで含みます。
Q2.
ETLとRAGデータパイプラインは同じですか?
A2.
ETLはRAGデータパイプラインの一部と考えるのが自然です。
RAGでは、抽出・変換・格納に加えて、チャンク設計、Embedding、メタデータ、権限制御、差分更新、検索評価が重要になります。
Q3.
まずどこから手をつければいいですか?
A3.
「モデルを変える」前に、抽出品質とメタデータを疑うのがおすすめです。
多くのプロジェクトでは、最初に「LLMの精度が悪いのでは?」と疑われます。しかし実際には、PDFの表崩れ、古い文書、出典不明、権限情報なしのチャンクが原因だった、というケースが少なくありません。EmbeddingモデルやVector DBのチューニングは、そのあとでも間に合います。
Q4.
チャンキングはこの記事でどこまで扱うべきですか?
A4.
この記事ではデータパイプライン内の重要工程として扱い、詳細な分割戦略は専用記事に分けるのがよいです。
固定長、再帰的分割、構造認識、親子チャンクなどの詳細は、RAGチャンキング最適化の記事で深掘りする方が読みやすくなります。
Q5.
本番RAGではなぜ差分更新が重要ですか?
A5.
文書は日々更新されるため、差分更新がないRAGは公開直後から古くなるからです。
変更文書だけを再処理・再Embeddingできるようにしておくと、コストを抑えながら検索インデックスを最新状態に保てます。
更新履歴
- 2026年5月21日:v11.3に適合し、RAGデータパイプライン全体の設計記事として、前処理、メタデータ、差分更新、権限制御、品質評価、後段検索基盤との接続を中心に全面再構成。Unstructured、LlamaParse、Contextual Chunking、読者行動導線を追記。
- 2025年8月6日:FAQ、専門用語、読者支援要素を追加。
- 2024年10月10日:初版公開。








