


IT子会社が牽引するDX革命:Databricksで処理時間90%短縮
分散データを統合し、経営スピードを革新するDatabricksの実装戦略
▶ この記事の信頼性の源泉(クリックで開閉)
本記事では、AIの進化を支える技術的背景を多角的に捉え、専門知識をわかりやすく解説します。筆者はハードウェアからクラウド基盤、AI実装まで幅広い開発領域で活動、技術戦略や製品開発にも携わってきました。特に2015年以降は、ディープラーニングの急速な発展に加え、生成AIや大規模言語モデル(LLM)の動向を継続的に分析・発信しています。単なる情報整理にとどまらず、現場で培ったリアルな視点を交えた分かりやすい考察をお届けすることを目指しています。
はじめに:なぜ今、データ基盤の変革が求められるのか
現代のビジネス環境において、「データは新たな石油である」と言われて久しいですが、多くの企業ではその価値を十分に引き出せていません。その最大の原因は、部門ごと、システムごとにデータが分断されてしまう「データのサイロ化」にあります。営業データはCRMに、顧客サポートの記録は別のシステムに、そしてWebサイトのアクセスログはまた別の場所に、といった具合にデータが散在し、全社横断的な分析や迅速な意思決定を阻害しているのです。
企業内で各部門やシステムが独自にデータを管理し、他部門からアクセスできない状態を指します。これにより、同じ顧客の情報が営業・マーケティング・サポート部門でバラバラに管理され、統一的な顧客体験の提供や戦略的な意思決定が困難になります。
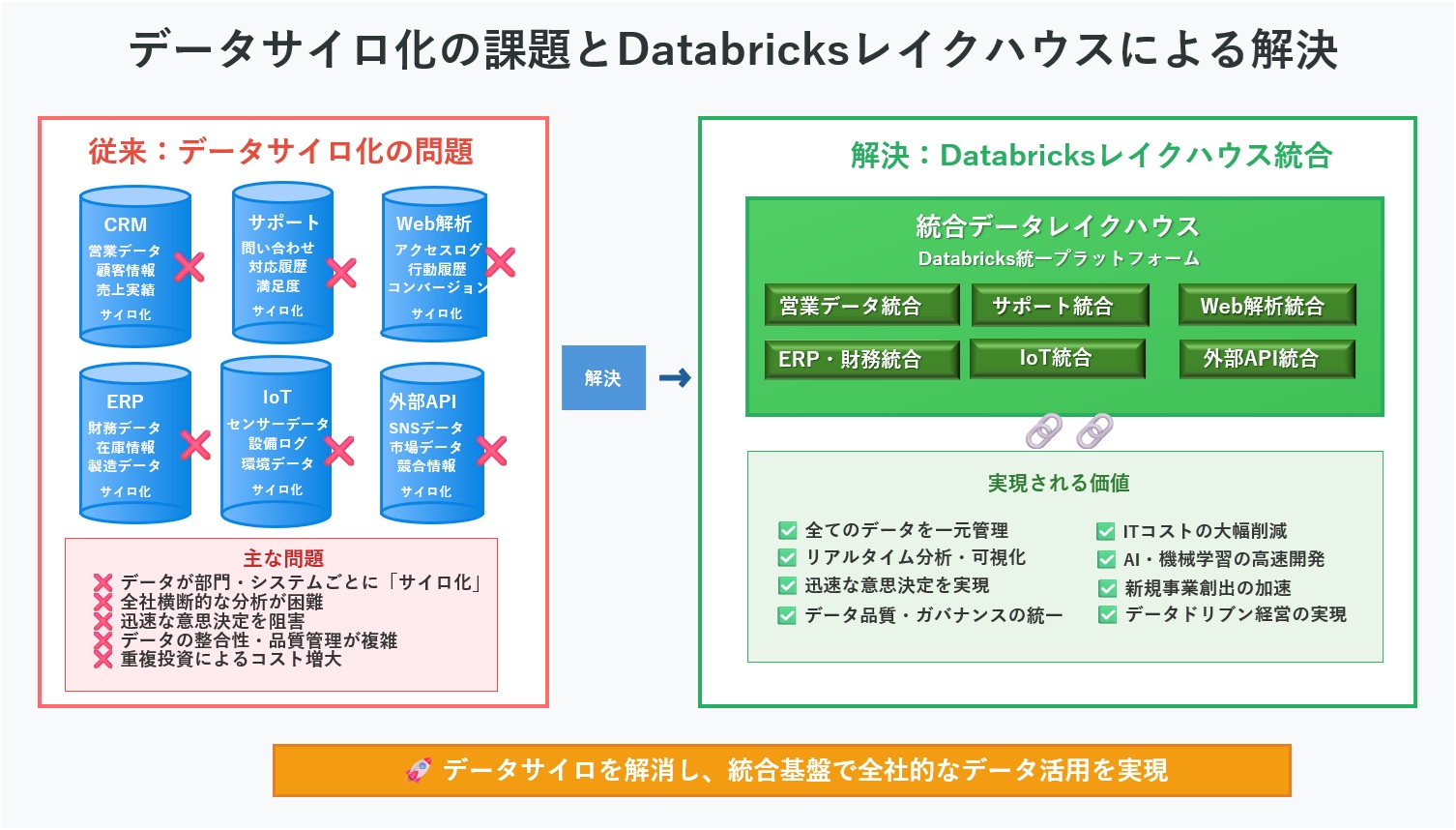
図1の説明文:この根深い課題を解決するために登場したのが、Databricksが提唱する「レイクハウス」という新しいアーキテクチャです。レイクハウスは、あらゆる形式のデータを柔軟に格納できる「データレイク」の利点と、信頼性の高いデータ管理と高速な分析を可能にする「データウェアハウス」の利点を統合した、まさに「良いとこ取り」のプラットフォームです。
本記事では、このDatabricksレイクハウスをグループ全体で導入し、その価値を最大化することを目指す企業の経営層、およびその実行部隊となるIT子会社のリーダーやエンジニアに向けて、具体的な経営インパクトから、IT子会社が担うべき9つの実行タスク、そして成功に導くための組織体制までを網羅的に解説します。
第1章:Databricksがもたらす4つの経営インパクト
Databricksの導入は、単なるITインフラの刷新に留まらず、経営そのものに直接的なインパクトをもたらします。ここでは、具体的な事例を交えながら、その効果を4つの側面に分解して解説します。
1-1. 意思決定の30%高速化:リアルタイムKPI可視化の実現
「経営会議のサイクルを週次から日次へ」——これは、データドリブン経営を目指す多くの企業にとっての理想形です。Databricksは、これを現実のものとします。
従来のデータ基盤では、各システムからデータを抽出し、集計・加工してレポートを作成するまでに数日を要することが珍しくありませんでした。これでは、経営層が目にする情報は常に過去のものとなり、市場の変化に迅速に対応することは困難です。
Databricksは、リアルタイムに近いデータ処理能力と、BIツールとのシームレスな連携機能を提供します。これにより、経営KPI(重要業績評価指標)をダッシュボード上で常に最新の状態に保つことが可能になります。
例えば、オーストラリアの鉄道貨物会社ARTC(Australian Rail Track Corporation)は、Databricksを導入することで、洞察を得るまでの時間を30%短縮し、より迅速な意思決定を実現しました。
(出典: Customer Story: ARTC—30% Faster Time to Insights 〈Databricks〉)
このような環境が整うことで、経営層は日々の業績を正確に把握し、問題の兆候を早期に発見して即座に対策を打つことができます。これは、勘や経験に頼った経営から、データという客観的な事実に基づいた科学的な経営への転換を意味します。
1-2. 新規事業開発の3倍速化:共通基盤による迅速なプロトタイピング
デジタル時代において、新規事業の成否は市場投入までのスピードに大きく左右されます。Databricksは、この開発サイクルを劇的に加速させるための共通基盤となります。
多くの企業では、新規事業や新しいAIサービスを開発しようとするたびに、個別のデータ分析環境を構築する必要がありました。データの収集、基盤の準備、モデルの開発といったプロセスがプロジェクトごとに繰り返され、多大な時間とコストを浪費していたのです。
Databricksレイクハウスは、グループ内のあらゆるデータを一元的に管理する「共通データ基盤」として機能します。これにより、新規事業のアイデアが生まれた際、データサイエンティストや開発者は、必要なデータにすぐにアクセスし、AIモデルやSaaSアプリケーションの試作品(プロトタイプ)を迅速に構築できます。
クラウドセキュリティ企業のPrisma Cloudは、この統一データプラットフォーム上でイノベーションを加速させ、市場投入までの期間を3分の1に短縮することに成功しています。
(出典: Power of Compounding on Top of a Unified Data Platform — Accelerating Innovation in Cloud Security〈Databricks Blog/Prisma Cloud〉)
これは、失敗を恐れずに数多くのアイデアを試し、市場の反応を見ながら素早く改善を繰り返す「アジャイルな事業開発」を可能にします。結果として、成功確率の高いデジタル新規事業を量産できる体制が整うのです。
1-3. ITコストの最大80%削減:アーキテクチャ統合と運用の自動化
デジタルトランスフォーメーション(DX)を推進する上で、ITコストの増大は常に経営の悩みの種です。Databricksは、データ基盤のアーキテクチャを根本から見直すことで、この課題に正面から取り組みます。
従来のデータ基盤では、BIのためのデータウェアハウスと、AI開発のためのデータレイクが別々に存在し、同じデータが両方のシステムにコピーされるなど、非効率な運用がまかり通っていました。これにより、ストレージコストや管理コストが二重にかかっていました。
Databricksのレイクハウスアーキテクチャは、これらのシステムを一つに統合し、データの重複を排除します。さらに、処理が終わると自動的に計算リソースを停止する「Auto-Stop」機能や、ワークロードに応じてリソースを自動調整する「サーバーレスコンピューティング」機能により、クラウド費用を徹底的に最適化します。
CCCマーケティンググループは、Databricksによってデータ分析基盤を刷新し、処理時間を10分の1に、クラウド費用を80%削減することに成功しました。
(出典: CCCマーケティング、データ分析基盤を刷新〈Impress D×Cross〉)

図2説明文: CCCマーケティンググループの事例では、従来の分析基盤で10時間を要していたデータ処理が、Databricksレイクハウス導入により1時間に短縮されました。複数システムからのデータ抽出、クレンジング・統合、大量データ分析、レポート生成という4段階のプロセスが、統合データプラットフォーム上で自動化・最適化されたためです。Delta Lake形式での高速処理、ETL自動化、Photonエンジンによる分析高速化により、実に90%の処理時間短縮を実現。これにより意思決定に必要な情報をより迅速に提供できるようになりました。
このようにして削減されたITコストは、新たなデジタル事業への投資原資となり、企業の成長サイクルを加速させます。
1-4. 1,800名規模の人材リスキリング:全社的なデータリテラシー向上
DXの成否を最終的に決めるのは、技術ではなく「人」です。一部の専門家だけでなく、全社員がデータを活用できる文化をいかに醸成するかが鍵となります。Databricksは、そのための教育プラットフォームとしても機能します。
Databricksは、SQLやPythonといった標準的な言語で操作できるため、多くのエンジニアやアナリストにとって学習のハードルが低いのが特徴です。さらに、専門家でなくても自然言語でデータを探索できるAIアシスタント機能なども搭載されており、「データの民主化」を強力に推進します。
米国インディアナ州政府は、全職員を対象としたデータ教育プログラムを実施し、1,800人ものDX人材を育成した実績があります。これは、特定のツールやスキルセットの教育に留まらず、データに基づいて物事を考え、対話し、意思決定を行うという文化そのものを組織に根付かせる取り組みです。
(出典: Indiana trained 1,800 employees in data literacy〈StateScoop〉)
Databricksを導入することは、単にツールを導入するだけでなく、全社員のデータリテラシーを向上させ、組織全体の競争力を底上げする人材育成への投資でもあるのです。
第2章:IT子会社が担うべき「データの架け橋」としての9つの実行タスク
グループ全体のデータ活用を成功させる上で、IT子会社(または情報システム部門)の役割は極めて重要です。親会社の巨大なデータ基盤(レイクハウス)と、各事業部門の現場で生まれる生きたデータ(現場データ)をつなぐ「データの架け橋」となり、ドメイン知識を活かしたソリューションを次々と生み出していくことが期待されます。
ここでは、そのための具体的な開発・運用タスクを9つのフェーズに分けて解説します。

図3の説明文:IT子会社は9つの実行フェーズを通じて、親会社レイクハウスと現場データを結ぶ「データの架け橋」として機能します。データ基盤構築から価値創出、継続改善まで段階的に実施することで、実証済みの成果を創出。ARTC社の30%短縮、CCCマーケティングの90%処理時間短縮、Prisma Cloudの市場投入期間3分の1短縮、インディアナ州政府の1,800名育成など、具体的な導入効果が確認されています。ドメイン知識と最新技術を融合させ、グループ全体のデジタル変革を牽引する戦略的パートナーとしての価値を発揮します。
フェーズ①:データ収集/連携
すべてのデータ活用の出発点は、あらゆるソースからデータを集めることです。IT子会社は、グループ内に散在する多種多様なデータをDatabricksレイクハウスに集約するパイプラインを構築する役割を担います。
- 工場IoTデータのストリーミング連携: 製造現場のセンサーからリアルタイムで送られてくるデータを、KafkaやAzure Event Hubsといったメッセージングシステムを経由して、Databricksのストリーミング機能で直接取り込みます。
- オンプレミスDBからのバッチ転送: 基幹システムなどで稼働しているOracleやSQL Serverといったオンプレミスのデータベースから、夜間バッチなどで定期的にデータを抽出し、Delta Lake形式でDatabricksに転送します。
- SaaS API連携: 営業部門が利用するSalesforceや、業務改善で導入されたkintoneなど、各種SaaSのAPIを叩いてデータを取得し、レイクハウスに統合します。
🤖 Kafkaとは?
Kafkaは高スループット・低遅延の分散型メッセージングプラットフォームです。大量データをリアルタイムで受け渡し、ログ収集やストリーム処理、イベント駆動型アプリケーションに利用されます。耐障害性やスケーラビリティにも優れています。
🤖 Azure Event Hubsとは?
Azure Event HubsはMicrosoft Azureが提供するクラウド型イベントストリーミングサービスです。Kafkaと同様に大量データの受信・配信が可能で、IoTやアプリからのリアルタイムデータ収集・分析に最適です。クラウドの利便性と拡張性が特徴です。
フェーズ②:データ整形(ETL/ELT)
収集しただけの「生データ」は、そのままでは分析に使いにくいことがほとんどです。表記の揺れや欠損値などをクレンジングし、親会社が定めた標準的なデータ形式(スキーマ)に変換するETL/ELT処理が不可欠です。
- PySpark/Databricks SQLによる品質ルールのコード化: 「このカラムは数値型でなければならない」「このカラムにNULL値は許容しない」といったデータ品質に関するルールを、PySparkやDatabricks SQLを使ってコードとして定義し、自動的にチェックする仕組みを構築します。
- Delta Live Tablesによるパイプライン自動化: Databricksの強力な機能であるDelta Live Tablesを活用します。これは、データの依存関係を自動で解決し、データ品質チェックやエラー処理まで含んだ信頼性の高いデータパイプラインを、簡単な宣言(SQLやPython)だけで構築できる画期的な機能です。
PySparkは、Apache SparkをPythonから操作するためのAPI(ライブラリ)です。Sparkは大規模データを高速に分散処理できるフレームワークであり、PySparkを使うことでPythonの文法でSparkの強力な分散処理機能(バッチ処理、ストリーミング、機械学習など)を簡単に利用できます。ビッグデータ分析や機械学習の前処理など、さまざまな用途で活用されています
フェーズ③:ガバナンス強化
データの民主化を進める上で、セキュリティとガバナンスの確保は絶対条件です。IT子会社は、親会社が定める全体的なガバナンスポリシーに基づき、自部門のデータに対する詳細なアクセス制御を実装します。
- Unity Catalogによるアクセス制御: Databricksの統合ガバナンス機能であるUnity Catalogを活用します。例えば、「このテーブルは自社の社員しか閲覧できない」といったビューを作成したり、個人情報などの機密カラムに対しては、特定の権限を持つユーザー以外には「***」のように表示を隠すマスキング処理を施したりします。
- 機密度タグ付け: データに対して「機密」「社外秘」「公開」といったタグを付与し、そのタグに基づいてアクセス制御ポリシーを自動的に適用する仕組みを構築します。
フェーズ④:BI/ダッシュボード
整形され、ガバナンスが効いたデータを、ビジネスユーザーが活用できる形に可視化します。IT子会社は、各部門のニーズに応じたKPIレポートやダッシュボードを構築・提供します。
- Databricks SQLダッシュボードの活用: Databricksに組み込まれているBI機能「Databricks SQL」を使い、インタラクティブなダッシュボードを迅速に作成します。また、使い慣れたPower BIやTableauといった外部BIツールと連携させることも可能です。
- マテリアライズドビューによる高速化: 経営会議で使われるような、大規模な集計を伴うレポートについては、あらかじめ集計結果を計算して保存しておく「マテリアライズドビュー」を作成します。
マテリアライズドビューは、データベースでクエリの実行結果を事前に計算し、テーブルとして保存する特別なビューです。これにより、複雑な集計や結合などのクエリを毎回実行せず、保存済みの結果をすぐに参照できるため、クエリの実行時間が大幅に短縮されます。ただし、元データが更新された場合は、マテリアライズドビューもリフレッシュして最新状態に保つ必要があります
フェーズ⑤:機械学習 / AI アプリ
データ基盤が整ったら、次はいよいよAIを活用した価値創造のフェーズです。IT子会社は、自社の事業ドメインに特化した機械学習モデルやAIアプリケーションを開発し、運用(MLOps)する役割を担います。
- ドメイン特化モデルの開発: 例えば、製造業の子会社であれば、設備ログを分析して故障を予知する「異常検知モデル」を開発します。開発したモデルのバージョン管理や性能監視は、MLflowというツールで行い、モデルの品質を継続的に維持・向上させます。
- RAGチャットボットの提供: 社内のFAQや業務マニュアルをDatabricksに取り込み、それらの情報を基に質問に答える「RAG(Retrieval-Augmented Generation)」技術を用いたチャットボットを開発します。
大規模言語モデル(LLM)に、企業独自の文書データベースから関連情報を検索・参照させて回答させる技術です。一般的なChatGPTでは答えられない社内固有の質問にも、正確で最新の情報に基づいて回答できるようになります。
フェーズ⑥:アプリ連携
開発したデータ分析機能やAIモデルは、それ単体で存在するだけでは価値を生みません。現場の業務で使われているアプリケーションに組み込むことで、初めてその真価を発揮します。
- Webポータルへの組み込み: 例えば、顧客情報を分析するWebポータルをReactやNext.jsで開発し、裏側ではDatabricksのDeltaテーブルを検索するREST APIを呼び出す、といった構成が考えられます。
- モバイルアプリとの連携: 工場の検品作業で使うモバイルアプリ(Flutterなどで開発)から、Databricks SQL Warehouseに直接アクセスし、製品の規格情報を参照する、といった活用も可能です。
フェーズ⑦:運用・自動化 (DevOps)
一度構築したシステムを安定的に、かつ効率的に運用し続けるためには、徹底した自動化が不可欠です。IT子会社は、DevOpsの考え方を取り入れ、開発からデプロイ、運用までのプロセスを自動化します。
- CI/CDパイプラインの構築: GitHub Actionsなどのツールを使い、コードの変更を自動的にテストし、問題がなければ本番環境へデプロイするCI/CD(継続的インテグレーション/継続的デリバリー)の仕組みを構築します。
- コスト最適化の自動化: クラウド費用が無駄に膨らまないよう、一定時間使われていない計算リソースを自動で停止する(Auto-Stop)設定や、予算を超えそうになったらアラートを出す仕組みを導入します。
フェーズ⑧:ユーザー教育
最高のデータ基盤を構築しても、使う人がいなければ意味がありません。IT子会社は、現場のビジネスユーザーがデータを活用できるようになるための教育やサポートを提供する重要な役割を担います。
- 社内ハンズオンの開催: 「やさしいSpark入門」のような、初心者向けの勉強会やハンズオントレーニングを定期的に開催し、データ分析のスキルを広めます。
- 分析コンペの実施: 特定のテーマ(例:「売上予測精度を競う」)で分析コンペティションを開催し、楽しみながらスキルアップできる機会を提供します。これにより、データ活用文化の醸成を促進します。
フェーズ⑨:PoC/新機能検証
Databricksは日々進化しており、新しい機能が次々とリリースされます。IT子会社は、これらの新機能を親会社が全社展開する前に、小規模なチームで先行してテストし、その有効性を検証する「PoC(概念実証)」の役割を担います。
- 新機能のベンチマーク: 新しい高速クエリエンジン「Photon」や、Unity Catalogの新機能などをいち早く試し、性能や使い勝手を評価します。
- 生成AI機能の試行: 自然言語でBI分析ができる「LakehouseIQ」のような生成AI関連の新サービスを試用し、自社のユースケースに適用可能か評価し、親会社にフィードバックします。
🤖 Photonとは
Photonは、Databricksが開発した高速なベクトル化クエリエンジンです。
SQLやDataFrameの処理を従来よりも高速に実行し、コスト削減とパフォーマンス向上を実現します。Apache Spark APIと互換性があり、既存のコードをそのまま利用可能です。大規模なデータ処理やAI・機械学習ワークロードにも効果を発揮します。
🤖 Unity Catalogとは
Unity Catalogは、Databricksプラットフォーム全体のデータやAI資産を一元的に管理・ガバナンスするためのカタログサービスです。アクセス制御や監査、データリネージ(流れの追跡)、メタデータ管理などを統合し、複数クラウドやワークスペース間でも安全かつ効率的なデータ管理を実現します。
🤖 LakehouseIQとは
LakehouseIQは、Databricksが提供するAI搭載の知識エンジンです。自然言語での質問に対し、企業独自のデータや用語、組織構造を理解したうえで最適なデータ検索や分析を支援します。Unity Catalogと連携し、セキュリティやガバナンスも担保しながら、全社員が直感的にデータ活用できる環境を提供します。
このように、IT子会社は単なる開発・運用部隊ではなく、グループ全体のデータ活用を最前線で牽引し、現場のニーズと最先端技術をつなぐ、極めて戦略的な役割を担うことになるのです。
第3章:実装成功のためのベストプラクティス
Databricksレイクハウスの導入を成功に導くには、技術的な実装だけでなく、組織的な変革管理も重要な要素となります。ここでは、実際の導入プロジェクトで直面する課題と、それを乗り越えるためのベストプラクティスを解説します。
3-1. 段階的導入戦略:スモールスタートから全社展開へ
多くの企業が犯しがちな失敗は、いきなり全社規模でのレイクハウス導入を試みることです。これは技術的リスクだけでなく、組織の抵抗も招きやすく、プロジェクトの頓挫につながります。
推奨される段階的アプローチ:
- パイロットプロジェクト(3-6ヶ月):
特定の部門や業務領域に限定して、小規模なレイクハウス環境を構築します。例えば、営業部門の売上分析や、製造部門の品質管理データから始めることで、具体的な成果を早期に示すことができます。 - 水平展開(6-12ヶ月):
パイロットでの成功事例を他部門に横展開し、データソースとユーザーを段階的に拡大します。この段階では、部門間のデータ連携による新たな価値創造が期待できます。 - 全社統合(12-24ヶ月):
全てのデータソースを統合し、グループ全体でのデータガバナンスとセキュリティポリシーを確立します。
この段階的アプローチにより、技術的なノウハウの蓄積と組織の変革を並行して進めることができ、リスクを最小化しながら確実な成果を積み上げられます。
3-2. データガバナンス体制の構築
レイクハウスの真価を発揮するには、技術的な統合だけでなく、データの品質、セキュリティ、プライバシーを確保するガバナンス体制が不可欠です。
| ガバナンス要素 | Databricksでの実装方法 | 期待効果 |
|---|---|---|
| データ 品質管理 |
Delta Live Tablesの品質チェック機能 | データの信頼性向上、分析結果の精度向上 |
| アクセス 制御 |
Unity Catalogのロールベースアクセス制御 | 情報漏洩リスクの低減、コンプライアンス強化 |
| データ 系譜管理 |
自動的なリネージュ追跡機能 | データの影響範囲把握、監査対応の効率化 |
| メタデータ 管理 |
統合カタログによる一元管理 | データ発見性の向上、重複データの削減 |
3-3. 組織変革管理:データ文化の醸成
技術的な基盤が整っても、それを活用する組織文化がなければ宝の持ち腐れとなります。特に重要なのは、「データドリブンな意思決定」を組織に根付かせることです。
効果的な変革管理手法:
- エグゼクティブスポンサーシップ: 経営層が率先してデータに基づく意思決定を実践し、その姿勢を全社に示します。経営会議でのKPIダッシュボード活用は、特に強いメッセージとなります。
- チェンジエージェントの育成: 各部門から数名のデータ活用推進者を選出し、集中的にトレーニングを実施します。彼らが現場でのデータ活用を牽引し、同僚への指導役となります。
- 成功事例の社内共有: データ活用による具体的な成果(コスト削減、売上向上、業務効率化など)を定期的に社内で共有し、データ活用の価値を可視化します。
第4章:ROI最大化のための戦略的活用シナリオ
Databricksレイクハウスの投資対効果(ROI)を最大化するには、自社の業界特性や事業モデルに応じた戦略的な活用シナリオを描くことが重要です。
4-1. 製造業における予知保全とサプライチェーン最適化
製造業におけるDatabricksの最大の価値は、IoTデータを活用した予知保全と、サプライチェーン全体の可視化・最適化にあります。
具体的な活用シナリオ:
- 設備故障予知: 工場内の数千台のセンサーからリアルタイムで収集される振動、温度、圧力データを分析し、設備の異常兆候を早期検知します。これにより、計画外の停止時間を大幅に削減できます。
- 品質管理の自動化: 製造プロセスの各工程でのデータを統合分析し、品質不良の原因を特定します。AIモデルが最適な製造パラメータを提案することで、歩留まり率の向上を実現します。
- サプライチェーン最適化: 部品調達から製品出荷までの全工程のデータを一元管理し、需要予測の精度向上と在庫最適化を実現します。
自動車業界では、Databricks活用による大きな成果が報告されています。例えば、トヨタ情報システム愛知株式会社では、Azure Databricksを大規模データ処理基盤に導入することで、処理速度を約30倍向上させ、運用コストを8分の1まで削減することに成功しました。
(出典: トヨタ情報システム愛知株式会社様の大規模データ処理基盤においてAzure Databricks の導入支援を行い、約30倍の処理速度向上と1/8のコスト削減を実現〈PR TIMES/ナレッジコミュニケーション〉)
4-2. 小売・EC業界における顧客体験の個人化
小売・EC業界では、膨大な顧客行動データを活用した「超個人化」されたサービス提供がDatabricksの主要な活用領域となります。
- リアルタイムレコメンデーション: Web閲覧履歴、購入履歴、在庫状況を統合し、顧客一人ひとりに最適化された商品推奨をリアルタイムで提供します。
- 動的価格設定: 競合他社の価格、在庫状況、需要予測を総合的に分析し、収益を最大化する動的な価格設定を自動化します。
- 顧客離反予測: 購買パターンの変化を検知し、離反リスクの高い顧客に対して適切なタイミングでリテンション施策を実行します。
4-3. 金融業界におけるリスク管理とコンプライアンス
金融業界では、厳格な規制要件への対応と、高度なリスク管理がDatabricks活用の中心となります。
- リアルタイム不正検知: クレジットカード取引や銀行取引をリアルタイムで監視し、異常なパターンを即座に検出して不正取引を防止します。
- 信用リスク評価: 膨大な顧客データと外部の経済指標を組み合わせ、より精度の高い信用スコアリングモデルを構築します。
- 規制レポートの自動化: バーゼル規制やIFRS等の複雑な規制要件に対応するレポートを自動生成し、コンプライアンス業務の効率化を実現します。
各業界でDatabricks導入のROIを算出する際は、直接的なコスト削減だけでなく、機会損失の回避、新規事業創出、コンプライアンスリスクの低減なども含めた総合的な評価が重要です。特に製造業では設備停止コストの回避、小売業では売上機会の増大が大きなインパクトとなります。
専門用語解説
本記事で登場した専門用語について、わかりやすく解説します。
▶ Delta Live Tables(クリックで開閉)
SQL/Pythonで宣言的に書いたパイプラインを自動生成・監視するDatabricks機能。データの依存関係推論やデータ品質チェックを一括で管理し、運用負荷を大幅削減する画期的な仕組みです。従来は複雑なコードが必要だったデータパイプラインを、簡単な設定だけで構築できます。
▶ MLflow(クリックで開閉)
機械学習の実験結果・モデル・パラメータを自動記録し、モデル登録・提供まで一貫管理できるオープンソースソフトウェア。複数のデータサイエンティストが同じプロジェクトで作業する際の混乱を防ぎ、再現性とMLOps効率を高めます。
▶ Feature Store(クリックで開閉)
機械学習で使う特徴量(年齢、購入履歴、地域など)をオンライン/オフライン両面で保存・共有する仕組み。学習時と推論時のデータ不整合を防ぎ、AIモデル開発を高速化します。チーム間での特徴量の再利用も促進します。
▶ React(クリックで開閉)
Facebookが開発したコンポーネント指向のJavaScriptライブラリ。差分レンダリングで高速UIを実現し、現代のWebアプリ開発におけるデファクトスタンダードとなっています。再利用可能なUIコンポーネントを作成できるため、開発効率が大幅に向上します。
▶ Flutter(クリックで開閉)
Google製のUIフレームワーク。Dart言語1本でiOS/Android/Webアプリへ高性能なネイティブUIを同時提供できる革新的な技術です。一度のコード作成で複数プラットフォームに対応でき、開発コストを大幅に削減できます。
よくある質問(FAQ)
▶ Databricksの導入コストはどの程度かかりますか?(クリックで開閉)
Databricksは従量課金制のため、使用量に応じてコストが変動します。小規模な検証環境であれば月額数万円から開始でき、企業規模での本格運用でも従来のオンプレミス基盤と比較して30-50%のコスト削減が期待できます。Auto-Stopやサーバーレス機能により、無駄なリソース消費を自動的に抑制できる点も大きなメリットです。
▶ 既存のデータウェアハウスからの移行は複雑ですか?(クリックで開閉)
Databricksは既存システムとの共存を前提に設計されているため、段階的な移行が可能です。まず新規分析案件をDatabricksで実装し、その後既存システムのデータを順次移行していくアプローチが一般的です。多くの企業では6-12ヶ月程度で主要なワークロードの移行を完了しています。
▶ データサイエンティストがいない場合でも導入効果はありますか?(クリックで開閉)
はい、十分な効果が期待できます。DatabricksのSQL機能により、従来のBIツール感覚でデータ分析が可能です。また、自然言語でクエリを実行できるAIアシスタント機能も搭載されており、専門知識がなくてもデータ活用を始められます。重要なのは段階的にスキルアップしていくことです。
▶ セキュリティやコンプライアンス要件は満たせますか?(クリックで開閉)
Databricksは企業レベルのセキュリティ機能を標準装備しています。SOC2、ISO27001、GDPR、HIPAAなど主要なコンプライアンス基準に準拠しており、金融機関や官公庁でも採用実績があります。Unity Catalogによる細かいアクセス制御やデータマスキング機能により、厳格なガバナンス要件にも対応可能です。
まとめ:データドリブン経営への変革を実現するために
本記事では、Databricksレイクハウスがもたらす4つの経営インパクトと、その価値を最大化するためにIT子会社が担うべき9つの実行タスクについて詳述しました。
重要なのは、IT子会社が単なる「下請け」や「コストセンター」ではなく、グループ全体のDXを牽引する「戦略的パートナー」として機能することです。
上記で示した9つのフェーズを段階的に実行し、現場で生まれる生きたデータと、親会社が持つ巨大なレイクハウス基盤を連結する「データの架け橋」となること。そして、ドメイン知識を活かしたソリューションを次々と生み出し、グループ全体のROI、DXのスピード、そして市場における競争優位性を飛躍的に高めていくこと。
これこそが、これからのIT子会社に求められる姿であり、Databricksはそのための最も強力な武器となるでしょう。データドリブン経営の実現は一朝一夕には成し遂げられませんが、適切な戦略と継続的な取り組みにより、必ず組織変革の成果を手にすることができます。
更新履歴
- Ver. 3.2 Databricksレイクハウス導入ガイド初版公開
主な参考サイト
- Customer Story: ARTC—30% Faster Time to Insights(Databricks)
- Power of Compounding on Top of a Unified Data Platform(Databricks Blog)
- CCCマーケティング、データ分析基盤を刷新(Impress D×Cross)
- Indiana trained 1,800 employees in data literacy(StateScoop)
- トヨタ情報システム愛知株式会社様の大規模データ処理基盤においてAzure Databricks の導入支援を行い、約30倍の処理速度向上と1/8のコスト削減を実現〈PR TIMES/ナレッジコミュニケーション〉








