


※本記事は継続的に最新情報へアップデートしています。
Databricksは、評価額1,340億ドル、2026年2月発表時点で年換算売上54億ドル超、AI製品ランレート14億ドル超に達した。JPMorgan Chase、Microsoft、Qatar Investment Authorityなどが資金提供に関わったこの企業は、半導体メーカーでもLLM専業企業でもない。企業データとAIをつなぐAIデータ基盤企業である。
なぜ今、世界の機関投資家は「データ基盤」に殺到しているのか。答えは単純だ──AIの戦場が、「どのモデルを使うか」から「どのデータをAIへ渡せるか」に移ったからである。
本記事では、Databricksを「AIを作り動かすデータ基盤」と捉え、Lakehouse、Unity Catalog、Lakeflow、Lakebase、Agent Bricks、Genieを通じて、企業がいま整えるべきAIデータ基盤の設計思想を整理する。
✅ 先に結論
Databricksは、生成AI時代の企業データを統合・処理・ガバナンスし、AIアプリケーションへ接続するためのAIデータ基盤である。
- 本質:Lakehouse、Unity Catalog、Lakeflow、MLflowなどを通じて、データとAIの接続基盤を作る。
- 市場シグナル:2026年2月発表時点で、年換算売上54億ドル超、AI製品ランレート14億ドル超、評価額1,340億ドル、70億ドル超の資金調達が確認されています。さらに2026年6月の外部報道や推計では、年換算売上69億ドル規模、AI製品ランレート17億ドル規模に達したとされています。
- 位置づけ:RAGは重要なユースケースの一つだが、Databricksの価値はRAGに閉じない。
- 判断軸:企業が見るべきは、どのLLMを選ぶかではなく、AIが継続的に使えるデータ基盤を持てるかである。DatabricksとSnowflakeの全体比較は、DatabricksとSnowflakeの違いを比較したハブ記事で詳しく整理している。

.jpg)
DatabricksのRevenue Run-Rateは、2022年Q2頃の10億ドル超から、2026年2月発表時点で54億ドル超へと急拡大しました。
2024年末以降は、30億ドル、40億ドル、48億ドル、54億ドルと短期間で階段状に伸びています。AI製品だけでも、2026年2月発表時点で年率換算14億ドル超に達しています。
さらに2026年6月には、年換算売上が69億ドル規模、AI製品ランレートが17億ドル規模に達したとの外部報道や推計もあります。ただし、この数値はDatabricksの公式発表ではなく外部報道や推計に基づくものであるため、本記事では公式発表済みの2026年2月時点の数値とは区別して扱います。
さらに注目すべきは、成長率だけではありません。DatabricksはNet Revenue Retention 140%超を維持しており、既存顧客が継続的に利用を拡大していることも示しています。
これは単なる売上成長ではありません。企業が分析、機械学習、生成AI、AIエージェントを別々に扱う時代から、データとAIを一体で運用する基盤へ移り始めたシグナルです。
※本グラフの数値は会計上の確定売上ではなく、Revenue Run-Rateに基づくものです。
なぜ今、AIデータ基盤が競争力になるのか

生成AI時代の差別化領域は、モデル選定からデータ接続基盤へ移っている。
Databricksは、資本市場においても有力なIPO候補として注目を集めています。
2026年2月には、評価額1,340億ドルで、約50億ドルのエクイティ調達と約20億ドルの追加デット枠を含む大型資金調達を発表しました。
同時にDatabricksは、年換算売上54億ドル超、前年比65%超、AI製品ランレート14億ドル超、既存顧客売上拡大率140%超という成長指標も示しました。2026年6月の報道・分析では、年換算売上69億ドル規模、AI製品ランレート17億ドル規模へさらに拡大したとされますが、この点は公式発表とは分けて読む必要があります。
JPMorgan Chase、Microsoft、Goldman Sachs Alternatives、Morgan Stanley、Qatar Investment Authority(QIA)などが名を連ねたことは、単なる成長ベンチャーへの投資ではありません。
AIデータ基盤が、次の企業インフラになるという市場の確信を示すシグナルです。
上場すれば、Snowflake、Oracle、SAPといった既存プレイヤーとの比較はさらに鮮明になります。
だからこそ2026年の今、Databricksを「便利なデータ分析ツール」ではなく、AIデータ基盤の有力候補として理解しておく意味があります。
生成AIの導入初期には、「どのLLMを使うか」「どのチャットボットを入れるか」が議論の中心になりがちです。
しかし、企業利用がPoCから本番へ進むほど、より根深い問題が見えてきます。
- 部門ごとにデータが分断されている
- 同じ顧客情報でも、営業、保守、経理で見ている値が違う
- PDF、ログ、音声、画像、センサーデータなど非構造化データを扱いきれない
- AIに渡してよいデータと、渡してはいけないデータの境界が曖昧
- モデルの回答が、どのデータに基づくものか追跡できない
この状態でAIアプリケーションだけを増やすと、部門ごとに個別最適化された“生成AI案件”が乱立しやすくなります。
表面上は先進的に見えても、裏側ではデータの重複、権限管理の複雑化、品質のばらつき、監査不能なAI判断が増えていきます。
つまり、生成AI時代に企業が本当に整えるべきものは、単なるAIアプリではありません。
信頼できるデータを、AIが安全に・継続的に使える基盤です。
さらに、データを単に集めるだけでなく、業務上の意味や関係性まで整理する場合は、Palantir AIP / Ontologyの解説もあわせて読むと、AIデータ基盤の見方が立体的になります。
Databricksが「AI時代のOracle」と呼べる理由
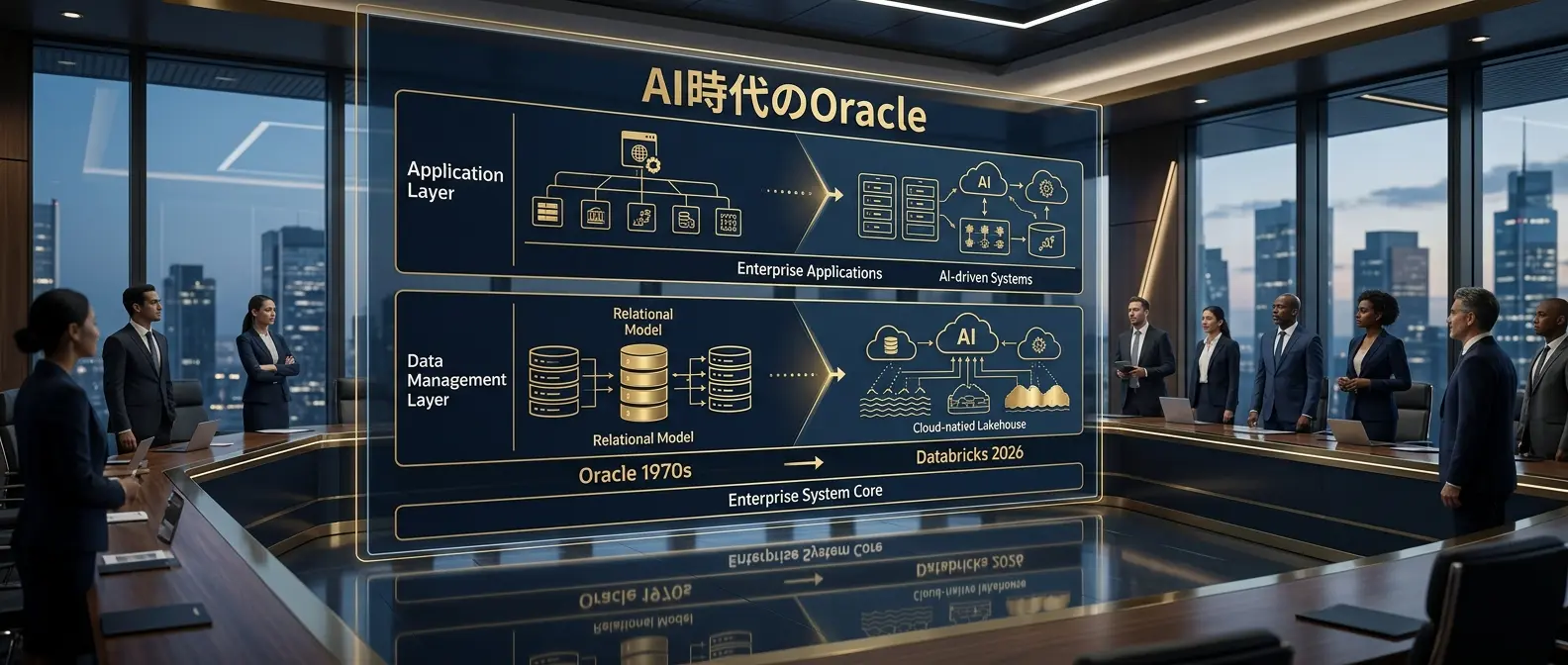
Databricksの本質は、企業システムの奥にあるデータ管理レイヤーを押さえる構造にある。
1970年代後半以降、Oracleが強みを発揮したのはアプリケーションそのものではありません。
企業システムの奥にある「データ管理レイヤー」でした。
販売管理、会計、人事、生産管理といったアプリケーションは変わっても、その背後には信頼できるデータベースが必要でした。
現在、AIの世界でも似た構造変化が起きています。
- LLMそのものは、時間とともにコモディティ化していく
- AIアプリケーションのUIも、やがて似た形に収束していく
- しかし、どの企業データを、どの粒度で、どの権限で、どのタイミングでAIへ渡すかは、企業ごとに異なる固有の課題である
この「データとAIをつなぐ層」を押さえたプレイヤーが、次の10年の標準になる可能性があります。
Databricksが「AI時代のOracle」と呼べる理由は、単なる勢いではありません。
競争軸が、アプリケーション層からデータ×AI基盤へ移りつつあるからです。
そして一度この層を押さえたプレイヤーは、1970年代後半以降のOracleがそうだったように、長期にわたってエコシステム全体の重力を引き寄せる可能性があります。
この「特定モデルに依存しない立ち位置」を示す象徴的な事実があります。
DatabricksはOpenAIと総額1億ドル規模の複数年パートナーシップを締結しています。GPT-5を含むOpenAIモデルを、Databricks Data Intelligence PlatformとAgent Bricks上で、2万社超の顧客へネイティブ提供する構想です。
Anthropicとも5年間の戦略提携を結び、ClaudeモデルをDatabricksプラットフォーム上で提供しています。
競合する基盤モデル企業の両方と並行して提携できることは、Databricksが特定モデルに依存しないAIデータ基盤を志向していることを象徴しています。
一方で、企業データを業務プロセスや意思決定モデルへ結びつける思想は、PalantirのOntology戦略とも近接します。経営・戦略面からこの流れを捉えるには、PalantirのOntologyとFDE Bootcampを整理した記事も参考になります。
ここでのポイント:Databricksを「RAGが作れるツール」と見ると、話が小さくなります。より正確には、DatabricksはBI、機械学習、RAG、AIエージェント、データガバナンスを同じデータ基盤上で扱うためのプラットフォームです。
Databricksの中核思想:Lakehouseとは何か

Lakehouseは、データレイクの柔軟性とDWHの信頼性を統合するAI時代の基盤である。
従来、企業のデータ基盤は大きく2つに分かれていました。
- データウェアハウス:構造化データを整理し、高速に分析するための基盤
- データレイク:ログ、画像、音声、文書など、多様なデータを柔軟に保存するための基盤
データウェアハウスは信頼性や分析性能に優れますが、非構造化データや機械学習用途には柔軟性が不足しがちです。
一方、データレイクは多様なデータを保存できますが、品質管理やガバナンスを怠ると、すぐに正しいデータを判別できない「データスワンプ(沼)」になります。
DatabricksのLakehouseは、この分断を埋めるためのアーキテクチャです。
Delta Lakeを中心に、データの信頼性、履歴管理、処理性能、AI活用を同じ基盤上に統合していきます。
DatabricksとSnowflakeの設計思想や用途の違いを俯瞰したい場合は、DatabricksとSnowflakeの違いを比較したハブ記事で比較軸を確認できます。
| 従来の分断 | Lakehouseでの統合 | AI活用への意味 |
|---|---|---|
| 構造化データはDWH、非構造化データはデータレイクに分散 | Delta Lakeを中心に多様なデータを統合管理 | AIが参照できるデータ範囲が広がる |
| BI、ML、RAG、アプリ開発が別々の基盤で動く | 同じデータ基盤上で分析、機械学習、AIアプリを展開 | データの重複や移動を減らし、整合性を保ちやすい |
| 権限管理や監査がツールごとに分断 | Unity CatalogでデータとAI資産を統制 | 本番AIで求められる説明責任と監査に対応しやすい |
主要コンポーネント:Databricksは何を一体化するのか
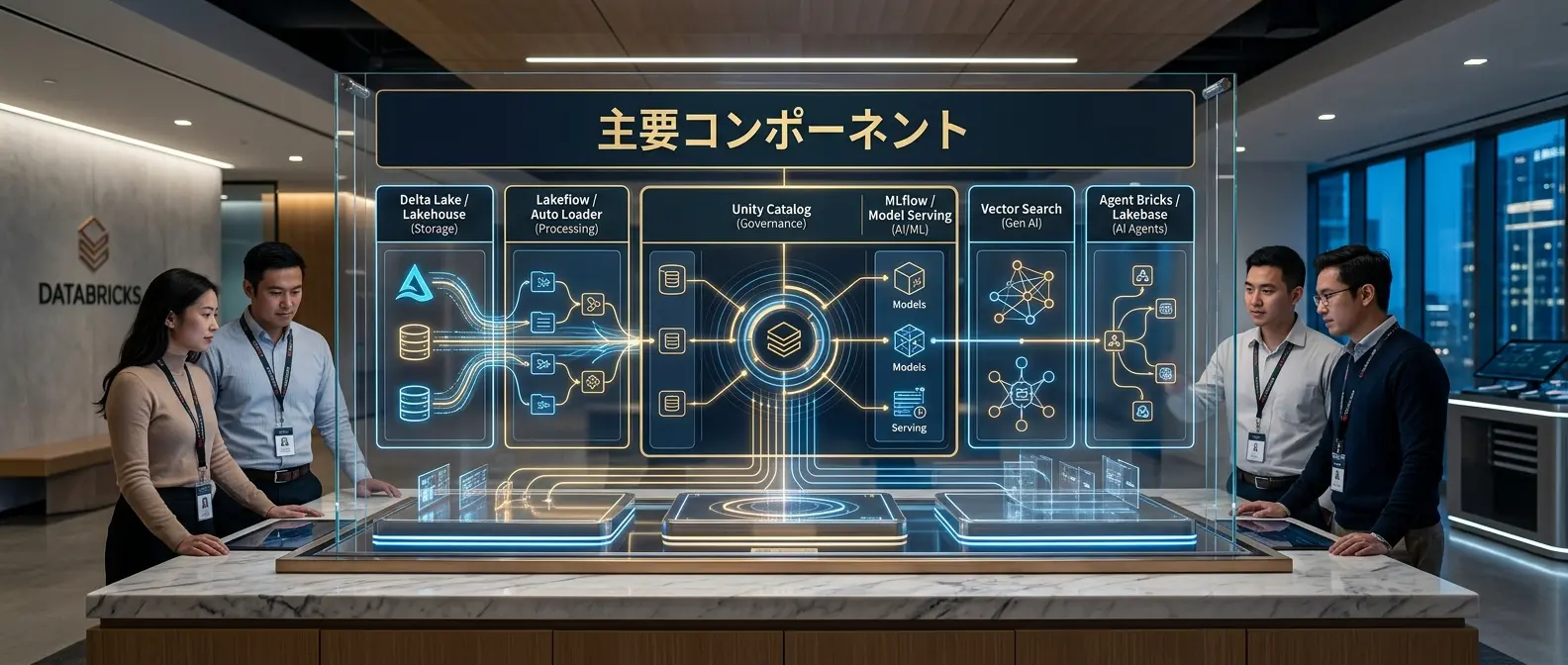
Databricksは、データ統合、処理、統制、AI実装を一体化する統合基盤である。
Databricksを理解するうえで重要なのは、個別機能の名前を暗記することではありません。
それぞれの機能が、企業データをAIで活用するためにどの役割を担っているかを見ることです。
| 領域 | 主な機能 | 役割 |
|---|---|---|
| 保存・管理 | Delta Lake / Lakehouse | 多様なデータを信頼できる形で保存し、履歴や整合性を管理する。 |
| 取り込み・処理 | Auto Loader / Lakeflow Spark Declarative Pipelines | 新規データの取り込み、変換、品質管理、パイプライン運用を自動化する。 |
| 統制 | Unity Catalog | データ、モデル、特徴量、AI資産へのアクセス制御、監査、リネージを管理する。 |
| AI・ML運用 | MLflow / Model Serving | モデルの実験管理、評価、デプロイ、本番運用を支援する。 |
| 検索・生成AI | Vector Search | Deltaテーブルと連動したベクトル検索基盤を提供し、RAGなどのAIアプリを支援する。 |
| AIアプリ・エージェント | Agent Bricks / Lakebase / Genie | 企業データ上でAIエージェント、AIアプリケーション、自然言語でのデータ活用を支援する。 |
競合比較:Snowflakeとの違いは「思想」の違い

SnowflakeとDatabricksの違いは、機能差ではなく、データ活用の主戦場の違いである。
Snowflakeは、データウェアハウス、クエリ性能、データ共有、業務分析の領域で強い優位性を持つプラットフォームです。
一方、DatabricksはApache Sparkを背景に、データエンジニアリング、機械学習、AI開発、非構造化データ処理を一体化する方向で進化してきました。
成長率から見る市場の期待:直近発表の成長率を見ると、Databricksは前年比65%超、SnowflakeはFY2026 Q4の製品売上で前年比30%成長です。もちろん単純比較だけで優劣は決まりませんが、AIデータ基盤としてのDatabricksに市場の期待が急速に集まっていることは確かです。
この違いを単純化すると、次のように整理できます。
思想レベルでの違い:
- Snowflake:分析基盤としての完成度、データ共有、SQL中心の業務分析に強い。
- Databricks:データ処理、機械学習、生成AI、AIエージェント実装までを一体化するAI実行基盤を志向する。
| 観点 | Snowflake | Databricks |
|---|---|---|
| 出自 | クラウドDWH、SQL分析 | Apache Spark、大規模データ処理、ML |
| 得意領域 | 業務分析、データ共有、DWH移行 | データ処理、ML、生成AI、AIエージェント基盤 |
| AI時代の位置づけ | 分析基盤をAIへ拡張 | AI活用を前提にデータ基盤を統合 |
| 向いている企業 | SQL分析、データ共有、DWH整理を重視する企業 | AI、ML、RAG、エージェント、非構造化データ処理まで広げたい企業 |
どちらが絶対的に優れているという話ではありません。
重要なのは、企業がいま何を主戦場にしているかです。
分析基盤の高度化が主目的なら、Snowflakeが自然な選択になる場面もあります。
一方で、データ処理、機械学習、生成AI、AIエージェントを同じ基盤で束ねたいなら、Databricksの思想は非常に強力です。
ここで重要なのは、「いま何ができるか」だけでなく、3年後・5年後に自社の主戦場がどこに移っているかを見据えて選ぶことです。
より詳しい比較は、DatabricksとSnowflakeの違いを整理した比較ハブ記事も参照してください。
また、Snowflake側でKnowledge GraphやGraphRAGをどう実現するかに関心がある場合は、RelationalAI × Snowflakeの記事が補助線になります。DatabricksとSnowflakeを「どちらが優れているか」ではなく、AIデータ基盤の設計思想として比較しやすくなります。
既存スキルはどう活きるのか

Databricks導入は、既存スキルを捨てる話ではなく、AI時代へ接続し直す話である。
Databricksの面白いところは、まったく新しい専門家だけの世界ではないことです。
SQLとPythonが分かる開発者なら、すでに入口に立っています。
そこにDelta Lake、Lakeflow、Unity Catalog、MLflowといった概念を加えることで、従来の開発経験をAIデータ基盤の設計力へ拡張できます。
▶ Databricksで活かせる既存スキルを見る
プログラミング言語
- SQL:データ分析、変換、ETL処理、Databricks SQLで活用できます。
- Python:データ処理、API開発、AIモデル構築、ノートブック開発で中心的に使えます。
- Java / Scala:Apache Sparkの知見や大規模分散処理の経験を活かせます。
- R:統計解析、可視化、データサイエンス用途で利用できます。
フレームワーク・ライブラリ
- TensorFlow / PyTorch / scikit-learn:モデル学習や推論、MLflow連携で活用できます。
- Web開発:React、Next.js、Spring Boot、Djangoなどで作った業務アプリのバックエンドにDatabricksを接続できます。
プラットフォーム・ツール
- データベース設計:テーブル設計、正規化、パフォーマンス設計の考え方はDelta Lakeにも活きます。
- BIツール:Tableau、Power BIなどと連携し、大規模データを可視化できます。
- CI/CD:GitHub Actions、Jenkinsなどを使ったジョブ管理やIaC運用へ拡張できます。
- クラウド:AWS、Azure、Google Cloudのストレージ、IAM、ネットワーク知識を活かせます。
新たに押さえるべき3つのコンセプト
- Delta Lake:データレイクに信頼性、履歴管理、ACIDトランザクションを与える中核技術です。
- Lakeflow:データ取り込み、変換、品質管理、パイプライン運用を宣言的に扱う仕組みです。
- Unity Catalog:データ、モデル、AI資産に対するアクセス制御、監査、リネージを一元管理するガバナンス基盤です。
Databricksは「まったく異質な新技術」ではなく、既存のデータ・クラウド・開発スキルをAI時代の基盤へ接続する正統進化版として理解すると、導入のハードルが下がります。
この流れは、AI駆動開発における「実装力から構想力へ」という変化ともつながります。AIが扱う業務世界そのものを設計する視点については、Vibe Codingの次に来るオントロジー設計の記事も参考になります。
RAGやVector Searchはどこに位置づくのか

RAGはDatabricksの主役ではなく、AIデータ基盤上に乗る代表的な実装例である。
ここで誤解してはいけないのは、Databricksを「RAGのために導入するツール」と見る必要はないということです。
一方で、DatabricksがRAGや生成AI検索に強い機能を持っているのも事実です。
たとえばAuto Loaderは、クラウドストレージ上に到着した新規ファイルを効率的に取り込みます。
Lakeflow Spark Declarative Pipelinesを使えば、取り込み、変換、品質管理を宣言的に管理できます。
さらにVector SearchのDelta Sync Indexを使うと、Deltaテーブルの更新に応じて検索インデックスを自動・増分同期できます。
つまり、Databricks上のRAGは「単なる検索機能」ではなく、企業データ基盤と密接に連動したAIアプリケーションの一形態として位置づけると分かりやすいでしょう。
| 一般的なRAG構成 | Databricks上のRAG構成 |
|---|---|
| PDFや文書を個別スクリプトで読み込む | Auto Loaderで新規ファイルを自動取り込み |
| 前処理、分割、ベクトル化を個別実装する | Lakeflowでパイプラインとして管理 |
| ベクトルDBとの同期を自前で実装する | Vector SearchのDelta SyncでDeltaテーブルと同期 |
| アクセス制御をアプリ側で個別に実装する | Unity Catalogでデータ権限と監査を統制 |
RAG関連記事との役割分担:RAGそのものの設計、精度改善、チャンキング、Embedding、ベクトルDB比較については、RAG専門記事群で扱うべきテーマです。本記事では、DatabricksのAIデータ基盤上でRAGがどのような実装オプションとして位置づくかに絞ります。RAG基盤そのものを比較したい場合は、RAGプラットフォーム比較記事を参照してください。
Lakeflow:手作業のデータ処理を“育つパイプライン”へ変える

AIデータ基盤で重要なのは、単発コードではなく、変化に追従するパイプラインである。
AIアプリケーションの裏側では、データは常に変化します。
新しいPDFが追加される。ログが増える。顧客情報が更新される。製造現場のセンサーデータが流れ続ける。
これらを手作業や個別スクリプトで処理し続けると、導入当初は動いていた仕組みであっても、時間とともに保守困難な技術的負債へ変わっていきます。
「あの人しか触れないスクリプト」が増え始めたら、それはAI活用が進んでいるのではなく、静かに負債が積み上がっているサインです。
DatabricksのLakeflow Spark Declarative Pipelinesは、この問題に対して、データ処理を宣言的なパイプラインとして扱う考え方を提供します。
従来「Delta Live Tables(DLT)」と呼ばれていた仕組みは、現在Lakeflow Spark Declarative Pipelinesとして整理されています。
既存のDLTコードは引き続き利用できますが、今後の公式ドキュメントではLakeflowの名称を押さえておくと安全です。
概念を示す簡略コード例:※以下は構造理解のための簡略例です。実装時はLakeflow Spark Declarative Pipelinesの最新仕様と公式ドキュメントを確認してください。
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table
def raw_documents():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/path/to/documents")
)
@dp.table
def clean_documents():
return (
spark.readStream.table("raw_documents")
.select(
col("document_id"),
col("content"),
col("updated_at")
)
.where(col("content").isNotNull())
)
どちらも「動くコード」を書くことはできます。しかし、前者が個別スクリプトの積み上げであるのに対し、後者はデータの追加、更新、品質管理、再実行に耐えるパイプラインです。時間が経つほど差が出るのは、最初の開発速度ではなく、運用し続けられる設計になっているかどうかです。
Unity Catalog:AI時代のデータガバナンスを支える中核
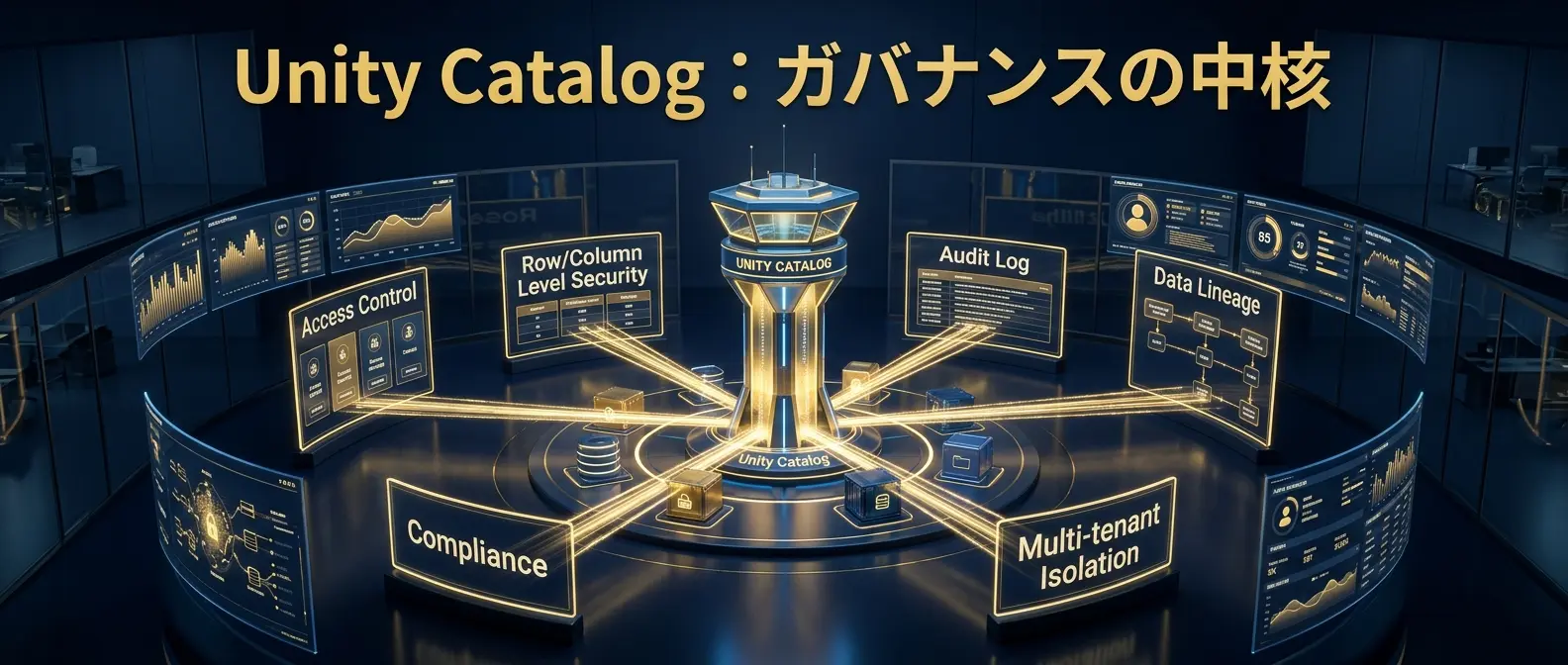
生成AIを本番で使うほど、AIに何を見せてよいかを制御する仕組みが重要になる。
企業AIで怖いのは、AIが間違えることだけではありません。
本来見てはいけないデータを参照してしまうこと。
部門や顧客をまたいで情報が混ざること。
誰がどのデータを使ってどの判断をしたのか追跡できないこと。
こうしたリスクは、AI活用が本番に近づくほど深刻になります。
Unity Catalogは、Databricksにおける統合ガバナンス機能です。
テーブル、ファイル、モデル、特徴量、AI資産に対して、アクセス制御、監査、リネージ管理を行います。
行レベル・列レベルの制御や、属性ベースのアクセス制御を組み合わせることで、部門別、顧客別、プロジェクト別のデータ利用を安全に管理しやすくなります。
- 誰が:ユーザー、グループ、サービスアカウント
- 何に:テーブル、列、行、モデル、ファイル、特徴量
- どの条件で:部門、役割、顧客、機密区分、タグ
- どうアクセスしたか:監査ログ、リネージ、利用履歴
AI活用が部門単位のPoCに留まっているうちは、アプリ側の個別制御でも何とかなるかもしれません。しかし、全社展開や外部顧客向けサービスに進むと、ガバナンスは後付けでは間に合いません。AIデータ基盤にガバナンスが組み込まれているかが、本番化の成否を左右します。
Agent Bricks・Lakebase・Genie:DatabricksはAIエージェント基盤へ広がる

Databricksは、分析基盤からAIアプリケーション、AIエージェント、会話型データアクセス基盤へ広がっている。
2025年以降、DatabricksはAgent Bricks、Lakebase、そしてGenieを前面に出し始めました。
これは、同社が単なる分析基盤ではなく、AIアプリケーションやエージェント、さらにビジネスユーザーの自然言語データ活用まで支える基盤へ進もうとしていることを示しています。
とくにLakebaseは、2026年2月にGA(一般提供)となり、構想やプレビュー段階から本格提供段階へ移りました。サーバーレスPostgreSQL互換の運用データベースとして、AIエージェントが状態を記録し、業務アプリと連携し、次の判断へつなげるための実行基盤に近づいています。
- Agent Bricks:企業データ上で、本番品質のAIエージェントを構築・評価・最適化するための仕組みです。
- Lakebase:AIアプリケーションやエージェント向けに設計された、Postgres互換のサーバーレス運用データベースです。
- Genie:社員が自然言語でデータと対話し、業務上の問いに素早く答えるための会話型AIアシスタントです。
これまでの企業データ基盤は、主に「分析するための基盤」でした。
しかしAIエージェントの時代には、データ基盤は単に過去を見るための場所ではありません。
AIが次の行動を判断するための環境になります。
たとえば、営業支援エージェントが顧客情報を参照し、過去の商談履歴を確認し、最新の契約条件を読み、次の提案内容を作る。保守支援エージェントが設備ログを見て、過去の故障パターンと照合し、部品交換の優先度を判断する。このような世界では、AIに渡すデータの鮮度、権限、履歴、監査がすべて重要になります。
たとえば、営業エージェントが朝一番に前日のログとSFAを読み込み、「本日フォロー優先度が高い顧客はこの10社です。うち3社は、2週間以内の解約リスクが高い可能性があります」とチームチャットに投げてくる世界です。同じ営業メンバーでも、「どの顧客を見るか」「何から始めるか」が変わるだけで、1日の積み上がりはまったく違うものになります。
なぜLakebaseが重要なのか:AIエージェントは、単にデータを読むだけではありません。状態を持ち、処理結果を記録し、必要に応じてアプリケーションのデータを更新します。2026年2月にGAとなったLakebaseは、こうしたAIアプリケーションやエージェントの運用データを、Lakehouseと近い場所で扱うための重要なピースとして位置づけられます。
もう一つ見落とせない柱が、Genieです。
Genieは、社員が自然言語でデータと対話できる会話型AIアシスタントです。SQLを書ける一部の専門家だけでなく、現場マネージャーや事業部門の担当者が、自分の業務データへ直接問いかけられる世界を目指しています。
LakebaseがAIアプリケーションやAIエージェントの実行環境を支えるなら、GenieはビジネスユーザーのAIデータアクセス窓口です。
Databricksの「State of AI Agents 2026」および関連ブログでは、Lakebaseの中核技術であるNeon上で、作成されるデータベースの80%、データベースブランチの97%にAIエージェントが関与していると説明されています。これは、データ基盤が人間の分析作業を支えるだけでなく、自律的に動くAIエージェントの実行環境へ変わり始めていることを象徴しています。
あわせて同レポートは、単一のチャットボットから複数エージェントが連携するシステムへの移行が進み、マルチエージェントシステムが4か月未満で327%成長したことも示しています。単体のAIアプリから、複数のエージェントが業務を分担して動く構成へ──この変化は、思った以上の速度で進んでいます。
AIエージェントが業務データを正しく扱うには、データそのものだけでなく、業務上の意味・関係・権限の設計が重要になります。この観点では、Palantir AIP / Ontologyの記事も、Databricksとは異なる角度からAIデータ基盤を理解する助けになります。
業界別シナリオ:Databricksはどこで効くのか

Databricksの効果は、処理時間短縮だけでなく、意思決定速度とデータ再利用性に表れる。
Databricksの導入効果は、業界ごとに見え方が変わります。
重要なのは、単にクラウド費用が下がるかではありません。
現場データをAIが使える状態に整え、業務判断の速度と質を上げられるかです。
| 業界 | 主な活用シナリオ | 期待できる効果 |
|---|---|---|
| 製造業 | 設備ログ、品質データ、部品在庫、サプライチェーン情報を統合し、予兆保全や品質異常検知に活用する。 | 突発停止の削減、歩留まり改善、保守計画の高度化。 |
| 小売・EC | 購買履歴、Web行動、在庫、キャンペーン反応を統合し、需要予測やパーソナライズに活用する。 | 在庫最適化、顧客体験の個人化、販促精度の向上。 |
| 金融 | 取引データ、顧客属性、外部指標、問い合わせ履歴を横断し、不正検知や信用リスク分析に活用する。 | リスク検知の迅速化、監査対応の効率化、コンプライアンス強化。 |
| グループ会社・IT子会社 | 親会社、事業部門、現場システムに分散したデータを共通基盤へ集約し、AI活用の土台を整える。 | DX推進の標準化、データ人材育成、全社AI活用の加速。 |
これまでは、現場マネージャーが朝礼後にExcelを開き、勘と経験で判断していた世界かもしれません。しかし、見るデータと気づけるパターンが変わるだけで、同じ人、同じチーム、同じ業務でも、1日の風景はまったく変わります。Databricksは、現場が見ているデータと判断材料を更新し、“見える世界”そのものを変えるための基盤だと捉えると分かりやすいでしょう。
現場に入り込み、業務プロセスとデータ基盤をつなげる実装組織の考え方は、PalantirのForward Deployed Engineerにも通じます。AIデータ基盤を単なるツール導入で終わらせない視点として、Palantir FDE Bootcampの記事も有効です。
導入ロードマップ:小さく試し、全社基盤へ広げる

Databricksは、効果が見えやすい小さなテーマから始め、共通基盤へ広げるのが現実的である。
Databricks導入で避けたいのは、最初から壮大な全社基盤を作ろうとして、プロジェクトが途中で頓挫してしまうことです。
まずは、効果が見えやすく、データの範囲をコントロールしやすいテーマから始めるのが安全です。
| 期間 | 進め方 | 成功条件 |
|---|---|---|
| 〜1ヶ月 | 既存データの一部を使い、Databricks上で小さな分析・AI活用テーマを試す。 | 既存スキルで扱えるか、データ取り込みや処理の感触を確認する。 |
| 1〜3ヶ月 | 営業、保守、製造、社内FAQなど、成果を測りやすい1業務でパイロットを実施する。 | 処理時間、品質、利用者満足度、運用工数を測定する。 |
| 3〜6ヶ月 | データパイプライン、Unity Catalog、BI、AIアプリの標準構成を作る。 | 部門ごとに個別最適化せず、再利用できるテンプレート化を進める。 |
| 6〜12ヶ月 | 成功した構成を複数部門へ横展開する。 | データ権限、監査、コスト管理、運用ルールを統一する。 |
| 12〜24ヶ月 | Databricksを全社AIデータ基盤として位置づけ、BI、ML、生成AI、AIエージェントを統合的に運用する。 | 単発AI案件の集合ではなく、全社で再利用できるAI基盤へ育てる。 |
未来の後悔を避けるには:ここで共通基盤を持たずに部門ごとの生成AI案件を乱立させると、数年後には「スプレッドシートだらけだった頃」と同じ混沌が、AIアプリの形で再来します。Databricksを「新しい分析ツール」と見るのか、「全社データ×AIの共通OS、つまりデータ・AI共通基盤」と見るのか。この解像度の差が、そのまま数年後の競争力の差になります。
CxOの立場で言えば、最初の一歩はシンプルです。「自社で一番データを持っている部門」と「一番AIに関心の高いチーム」を1つずつ指名し、“小さなLakehouse + 1つのAIユースケース”に絞ったパイロットを依頼するところから始められます。
その前にDatabricksとSnowflakeのどちらを比較対象にすべきか整理したい場合は、DatabricksとSnowflakeの違いを比較したハブ記事から読むと、基盤選定の全体像をつかみやすくなります。
まとめ:次に選ぶべきは、モデルではなく基盤かもしれない
読者が持ち帰るべきなのは、次のモデル名ではなく、AIデータ基盤をどう設計するかという問いである。
この記事では、Databricksを生成AI時代のAIデータ基盤として整理しました。
Databricksの価値は、RAGや機械学習の個別機能だけにあるのではありません。Lakehouse、Delta Lake、Unity Catalog、Lakeflow、MLflow、Vector Search、Lakebase、Agent Bricks、Genieを通じて、企業データをAIが継続的に使える状態へ整えることにあります。
AI開発の主戦場は、もはやモデルの優劣だけではありません。どのデータを、どの粒度で、どの権限で、どのタイミングでAIへ渡せるかという「データとAIの接続設計」に移っています。
もしあなたの組織が、すでに生成AIやAIエージェントのPoCを経験しているなら、次の一手は「次のモデル」を探すことだけではないかもしれません。むしろ問うべきは、AIが使い続けられるデータ基盤があるかどうかです。
Databricksを検討することは、単なるツール選定ではありません。部門ごとに散らばったAI活用を、全社で再利用できるAIデータ基盤へ統合するための経営判断です。いわば、生成AI時代のゲームボードを張り替える選択に近いものです。
Databricksを選ぶかどうかに関わらず、「AIデータ基盤をどう設計するか」が、これからの企業IT戦略の中核テーマになる──そのことだけは、今のうちから前提として共有しておく価値があるはずです。
まずは「自社で一番データを抱える部門」と「一番AIに積極的なチーム」を1つずつ選び、“小さなLakehouse + 1つのAIユースケース”のパイロットを始めることで十分です。導入ロードマップのステップ1は、そこから始まります。
専門用語まとめ
- Delta Lake
- データレイクにACIDトランザクション、履歴管理、信頼性を加える中核技術です。ファイル群を信頼できるテーブルとして扱えるようにします。
- Lakehouse
- データレイクの柔軟性とデータウェアハウスの信頼性を統合するアーキテクチャです。分析、機械学習、AI活用を同じ基盤で扱いやすくします。
- Lakeflow Spark Declarative Pipelines
- 従来のDelta Live Tables(DLT)として知られていた宣言型パイプライン機能を含む、データ処理基盤です。バッチやストリーミング処理をSQL/Pythonで定義できます。
- Unity Catalog
- データ、モデル、AI資産へのアクセス制御、監査、リネージを一元管理するガバナンス機能です。
- MLflow
- AIモデル開発における実験記録、評価、バージョン管理、デプロイを支援する機能です。
- Vector Search
- Deltaテーブルと連動したベクトル検索機能です。RAGや生成AI検索の実装を支援します。
- Agent Bricks
- 企業データ上で本番品質のAIエージェントを構築・評価・最適化するための仕組みです。
- Lakebase
- AIアプリケーションやAIエージェント向けに設計された、Postgres互換のサーバーレス運用データベースです。
- Genie
- ビジネスユーザーが自然言語でデータに質問し、ダッシュボードやデータ資産から洞察を得るための会話型AI機能です。
参考文献 / 出典
一次情報
- Databricks公式 – Databricks Grows >65% YoY, Surpasses $5.4B Revenue Run-Rate
- Databricks公式 – Databricks Grows >55% YoY, Surpasses $4.8B Revenue Run-Rate
- Databricks公式 – Databricks Surpasses $4B Revenue Run-Rate, Exceeding $1B AI Revenue Run-Rate
- Databricks公式 – Databricks is Raising $10B Series J Investment at $62B Valuation
- Databricks公式 – Databricks Raises Series I Investment at $43B Valuation
- Databricks公式 – Product Announcements from Data + AI Summit 2025
- Databricks公式 – Databricks Lakebase is now Generally Available
- Databricks公式 – Genie
- Databricks公式ドキュメント – What happened to Delta Live Tables?
- Databricks公式ドキュメント – Lakeflow Spark Declarative Pipelines
- Databricks公式ドキュメント – What is Auto Loader?
- Databricks公式ドキュメント – Vector Search
- Databricks公式ドキュメント – Row filters and column masks
- Databricks公式 – Databricks and OpenAI Launch Partnership
- Databricks公式 – Databricks and Anthropic Sign Landmark Deal
- Databricks公式 – 2026 State of AI Agents
- Databricks公式ブログ – Enterprise AI Agent Trends, Top Use Cases, Governance, Evaluations and More
- TechCrunch – Databricks crosses a $1B annual run rate
- Tom Tunguz – Databricks Widens the Lead on the Yellow Brick Token Path
- The Wall Street Journal – Databricks Releases General AI Agents for Businesses
次に読むならこの5本
補足Q&A
Q1.
DatabricksはRAGのために導入するものですか?
A1.
DatabricksはRAGにも強いが、本質はAIデータ基盤です。
RAGはDatabricks上で実現できる重要なユースケースの一つです。ただし、Databricksの価値はRAG専用機能ではなく、データ統合、処理、ガバナンス、機械学習、生成AI、AIエージェントを支える基盤にあります。
Q2.
SnowflakeとDatabricksはどちらを選ぶべきですか?
A2.
分析基盤中心ならSnowflake、AI実装基盤まで見据えるならDatabricksが有力です。
SQL分析、データ共有、DWH移行が中心ならSnowflakeが自然な選択になる場面があります。一方、機械学習、生成AI、非構造化データ処理、AIエージェント基盤まで含めて統合したい場合はDatabricksが有力です。詳しい比較は、DatabricksとSnowflakeの比較ハブ記事で整理しています。
Q3.
小規模チームでも導入効果はありますか?
A3.
小さなデータ活用テーマから始めれば、段階的に効果を確認できます。
最初から全社基盤を目指すより、特定業務のデータパイプライン、分析、AI活用テーマから小さく始めるのが現実的です。運用負荷を減らし、再利用できる基盤として育てられるかが重要です。
更新履歴
- 2026年7月9日:ファクト表現を明確化しつつ、比喩とストーリー性を残す方針で、冒頭、Lakeflow、RAG、導入ロードマップ、まとめの日本語を微修正。
- 2026年7月8日:Databricks/Snowflake比較ハブ記事との内部リンク整合を実施。Lakebase GA、2026年6月のDatabricksランレート報道・分析、著者ボックスの書籍名修正、marker2のHTML順序統一、参考文献更新を反映。
- 2026年5月23日:DatabricksのQ4収益ランレート、評価額1,340億ドルの大型資金調達、Lakebase、Agent Bricks、Genie、Lakeflow表記、AIエージェント関連データを反映し、記事構成をv11.3へ適合。
- 2025年7月11日:初稿








