


VLM(視覚言語モデル)とは? LLMとの違い、最新モデル比較、VLA(ロボティクス)への進化まで徹底解説
この記事を読むとVLMの基本的な仕組みから、GPT-5やGemini 2.5 Proなど最新モデルの比較、日本企業の動向までがわかり、VLMがAIの未来をどう変えるか説明できるようになります。
テキストのみを扱うLLMとは異なり、VLMは「見て、理解し、答える」能力を持つため、2025年現在は医療診断やロボット操作(VLA)など、より現実世界に近い領域で実用化が急速に進んでいます。
- 要点1:「推論モデル」の登場(GPT-5等)により、単なる認識から複雑な思考が可能に
- 要点2:VLA(Vision-Language-Action)への進化で、ロボットが言語指示で動作
- 要点3:小型モデル(SmolVLM)と大型モデル(Gemini 2.5 Pro)の二極化が進展
→ 最新モデル比較は「主要VLMモデル徹底比較(2025年10月版)」へ、日本の動向は「日本のVLM戦略」へ。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

VLM(視覚言語モデル)とは? LLMとの決定的な違い

VLM(Vision-Language Model:視覚言語モデル)は、2024年から2025年にかけてAI分野で最も急速な進化を遂げた技術の一つです。
従来、AIは「画像認識(コンピュータビジョン)」と「文章理解(自然言語処理)」という異なる分野で発展してきました。VLMは、この2つの能力を統合し、画像とテキストを組み合わせた入力から、人間のように文脈を理解し、テキスト(あるいは行動)を出力できるマルチモーダルAIを指します。
例えば、従来のLLM(大規模言語モデル)に「この写真に写っているものは何ですか?」と質問しても、写真を見ることができないため答えられません。しかし、VLMは写真を見て「これは公園で楽しそうに遊ぶ子供たちの写真です」と答えたり、「写っている料理のレシピを教えて」といった高度な質問にも応答できます。
この「視覚」という入力チャネルの追加こそが、LLMとの決定的な違いです。
この能力の基盤となっているのが、2021年にOpenAIが発表したCLIP(Contrastive Language-Image Pre-Training)です。CLIPは、インターネット上にある膨大な「画像と、その画像を説明するテキスト」のペアを学習しました。
これにより、AIは「犬の写真」と「”犬”という単語」が意味的(ベクトル空間上)で近い関係にあることを学習し、視覚と言語の橋渡しが可能になったのです。
この技術が、後のBLIPシリーズやGPT-4V(Vision)など、現代のVLMの基礎となっています。
👨🏫 AI専門家が解説:かみ砕きポイント

この進化は、2025年現在、単に画像の内容を説明するレベル(画像キャプション生成)を超え、複雑な問題の「推論」や、ロボットを動かす「行動(Action)」へと発展しています。次の章では、2025年に起きたVLMの3つの大きな進化(ブレークスルー)を見ていきましょう。
2025年 VLM最大の進化:3つの技術的ブレークスルー
要約:2025年のVLMは「思考するAI(推論)」「行動するAI(VLA)」「小型化(エッジ)」という3つの大きな進化を遂げました。これにより、VLMは研究段階から、産業やデバイスで使える実用段階へと移行しています。
2024年後半から2025年にかけて、VLMは単なる「認識AI」から「実用AI」へと飛躍的な進化を遂げました。その背景には、特に注目すべき3つの技術的ブレークスルーがあります。
ブレークスルー1:思考するVLM(推論モデル)の登場
2025年最大のブレークスルーは、VLMが「思考」する能力、すなわち段階的推論(Chain-of-Thought)を実行できるようになったことです。
従来のVLMは直感的に「猫がいる」と答えることはできても、「なぜそう判断したのか?」を論理的に説明するのは苦手でした。
しかし、2025年に登場したGPT-5やGLM-4.5V、Kimi-VL-A3B-Thinkingなどは、複雑な問題に対して段階的に思考プロセスを実行できます。
例えば、
❶GPT-5は難問に食らいつく“思考の怪物”:数学問題のベンチマーク(AIME 2025)で94.6%の正答率を達成し、複雑な理詰め課題でトップクラスの性能を示します。
❷Gemini 2.5 Proは“長編に強い参謀”:最⼤100万トークン級の長文脈を扱え、動画や長文の要約・分析に強み(例:SWE-Bench 63.8%)。
❸Claude Sonnet 4.5は“段取り名人”:エージェントとしてPC操作を遂行し、Devinとの統合で計画性能が18%向上するなど実務タスクに強いと報告されています。
これは、VLMが画像やグラフを「見て」、その背後にある論理や数式を「理解し」、問題を「解く」という高度な知能を獲得したことを意味します。
ブレークスルー2:行動するVLM(VLA)の実用化

2つ目の進化は、VLMが「見て、答える」だけでなく、「見て、理解し、行動する」が可能なVLA(Vision-Language-Action)モデルへと発展したことです。これは特に日本が得意とするロボティクス分野で顕著です。
NVIDIA製ロボット基盤AIである”NVIDIAのGR00T N1“やロボットの知能や行動能力の向上を目指すスタートアップ企業Physical Intelligenceのロボット用学習モデルπ0(パイ・ゼロ)といったVLAモデルは、自然言語の指示(例:「テーブルの上にある赤いリンゴを取って」)を理解し、カメラ映像(Vision)からリンゴを特定し、ロボットアームを制御して掴む(Action)までの一連の動作を完結できます。
日本国内でも、Telexistence社は2025年9月にセブン‐イレブン・ジャパンと、VLA技術を搭載したヒューマノイドロボット『Astra』の開発・導入に関するパートナーシップを発表しました。2029年の店舗導入を目指しており、労働力不足の解決策として期待されています。
ブレークスルー3:小型高性能モデル(SmolVLM)の台頭
3つ目の重要な進展は、モデルの「小型化」です。GPT-5のような超巨大モデルが高性能化を追求する一方で、学術研究コミュニティが取組んでいるSmolVLMシリーズ(スモル・ブイ・エル・エム:2.5億~22億パラメータ)のような小型モデルも登場しました。
※)GPT-4のパラメーター数が約1.7兆(推測値)
これらの小型モデルは、300倍以上も大きいモデルの性能を上回るケースも報告されており、スマートフォンや消費者向けデバイスでの動作(エッジAI)を可能にします。
例えば、1GB未満のGPUメモリで動画理解を実現できるため、リアルタイムの翻訳ゴーグルや、オフラインで動作する視覚障害者支援アプリなど、VLM技術をより多くの人々に届ける道筋が立ちました。
Gemma系の軽量モデルを筆頭に、小さくて速い潮流が来ています。 ポケットサイズのVLMが実用的な道具になりつつあります。
VLMはどのように「見て・理解する」のか? 最新アーキテクチャの仕組み
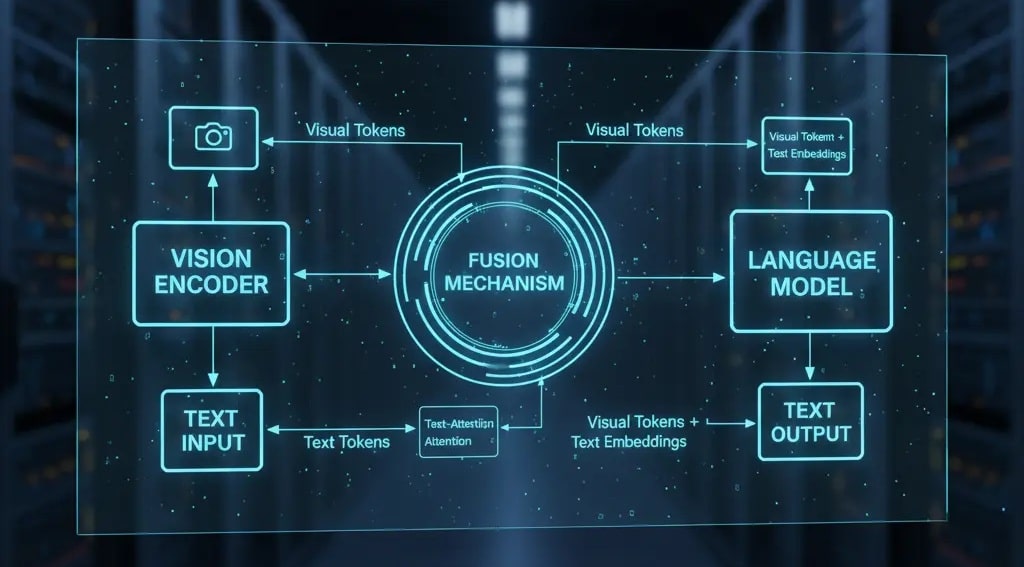
VLMが画像と言語という異なる種類の情報をどうやって統合しているのか、その基本的な構造は3つの要素で説明できます。
- 視覚エンコーダー (Vision Encoder):AIの「目」
- 言語モデル (Language Model):AIの「脳(言語野)」
- 融合機構 (Fusion Mechanism):目と脳を繋ぐ「神経」
① 視覚エンコーダー:画像を「言語」に翻訳する
AIは画像をピクセルの集まりとしてではなく、「概念」として理解する必要があります。視覚エンコーダーは、入力された画像を分析し、その特徴を数値のベクトル(Token)に変換する役割を持ちます。この分野ではViT (Vision Transformer)が主流です。
2025年現在、このエンコーダーは単に画像を圧縮するだけでなく、画像と言語を関連付けるAI”CLIP“やその改良版SigLIP(シグリップ)といった対照学習手法で事前学習されています。これにより、画像の特徴が、言語モデルが理解しやすい「意味」を持ったベクトル空間にマッピングされます。
② 言語モデル:視覚情報と言語指示を同時に思考する
言語モデル部分は、LLM(大規模言語モデル)そのものです。視覚エンコーダーから送られてきた「画像の情報(ベクトル)」と、ユーザーから入力された「テキストの情報(例:「これは何?」)」を同時に受け取り、統合的に処理して、最終的な回答テキストを生成します。
③ 融合機構:VLMの「個性」が決まる場所
VLMのアーキテクチャ(構造)の違いが最も現れるのが、この「融合機構」です。2025年現在、主流となっている方式には以下のような違いがあります。
| 方式 | 代表モデル | 特徴(仕組み) |
|---|---|---|
| 早期融合型(MLPアダプター) | LLaVA, Qwen2.5-VL | 最もシンプルで効率的。視覚エンコーダと言語モデルの間に単純な線形層(アダプター)を挟み、視覚トークンを言語トークンに変換する。 |
| Q-Former型 | BLIP-2, InternVL | 高性能。Q-Formerという小型のTransformerを仲介役として使用。視覚情報から「クエリ(問い)」を自動生成し、重要な特徴だけを抽出して言語モデルに渡す。 |
| クロスアテンション型 | Flamingo | 言語モデルの各層に、視覚情報を参照するためのクロスアテンション機構を追加する。計算コストが高いが、詳細な情報を反映させやすい。 |
| 判定根拠 | 2025年時点では、計算効率と性能のバランスに優れた「早期融合型」と、より高度な情報抽出が可能な「Q-Former型」の派生アーキテクチャが主流となっている。 | |
図の要点:VLMの構造は、視覚エンコーダ(目)、言語モデル(脳)、融合機構(神経)の3つで構成され、特に「融合機構」の設計(LLaVA型かBLIP-2型かなど)がモデルの性能と効率を左右します。
さらに、訓練プロセスも高度化しています。単なる画像とテキストのペア学習だけでなく、長文の文脈を学習させたり(長文コンテキスト事前学習)、人間のフィードバック(RLHF)だけでなく、より複雑な報酬設計(MPO, GSPOなど)を用いた多層的な強化学習によって、VLMの回答の「質」と「安全性」を同時に高めるアプローチが2025年10月現在のポストトレーニング革命となっています。
※)ミニ解説
- RLHF: 人間フィードバックでAI行動を調整
- MPO: 特定行動の重み付けにより複雑な目標達成や安全性の確保を目指す最適化手法報酬設計
- GSPO: 高い安全性の制約下で最適行動を学習する手法
主要VLMモデル徹底比較(2025年10月版):GPT-5からオープンソースまで
要約:2025年現在、VLMは「GPT-5」「Gemini 2.5 Pro」「Claude Sonnet 4.5」が最先端を競っています。オープンソース分野でもInternVL3.5やQwen2.5-VLがこれに迫る性能を示しています。
VLM市場は、クローズドモデル(商用)とオープンソースモデルが互いに性能を競い合い、急速に進化しています。2025年10月時点での主要モデルの動向を比較します。
クローズドモデル:3強が「思考力」と「長文脈」で競う
GPT-5 (OpenAI, 2025年8月):
「推論モデル」の代表格。大学院レベルのマルチモーダルベンチマーク(MMMU-Pro)で78.4%を達成するなど、複雑な思考や数学問題で圧倒的な強さを見せます。
ただし、“顕微鏡で細部まで観るのが得意なタイプ”と“長回しの全体像を掴むタイプ”がいる。 物体検出や視覚理解は競技種目で勝者が入れ替わる世界だ、と覚えておけばOK。
Gemini 2.5 Pro (Google, 2025年3月):
「長文脈(コンテキストウィンドウ)」の王者。公表値では100万トークン級(長尺動画に相当)という広大な文脈を扱え、動画全体の要約や分析に優れます。コーディング能力(SWE-Benchは60%台前半の報告)も非常に高く、実用的なバランスに優れたモデルです。
Claude Sonnet 4.5 (Anthropic, 2025年9月):
「エージェント機能(コンピュータ操作)」で世界最高性能を達成。
Claude Sonnet 4.5は“作業を段取りしてPCを動かすのが抜群にうまい”。 実務でのタスク遂行に強く、エージェントの中心選手として語られることが増えています。
オープンソースモデル:商用モデルを猛追
オープンソース分野では、中国のAIラボが商用モデルに匹敵、あるいは凌駕するモデルを次々と発表しています。
- InternVL3.5-241B:
オープンソース最強の座を確立。MMBenchで72.2を記録し、特に図表やチャートの理解(ChartQAで1位)に優れます。「Visual Resolution Router」という技術で、推論速度を4倍高速化しながら高い認識精度を両立しています。 - Qwen2.5-VL-72B:
“英語圏+アジア圏にも強いマルチリンガル”。 チームや顧客の言語が混ざる現場でも扱いやすいのがQwen系の魅力です。動画入力や、画像内の物体の位置を特定する(位置特定)能力もサポートしており、非常に汎用性が高いモデルです。 - LLaVA (ファミリー):
VLMのオープンソース標準とも言える存在。特にLLaVA-Mini(ICLR 2025)は、視覚トークンを大幅に削減する技術で、“スマホ級の軽さで動画もいける”。 軽量VLMの研究が進み、エッジで回る未来像が一気に現実味を帯びました。
Key Takeaways(持ち帰りポイント)
- 2025年のVLM選びは、タスクの目的に応じて「思考力(GPT-5)」「長文脈(Gemini)」「エージェント(Claude)」を選ぶ時代になった。
- オープンソースモデル(InternVL, Qwen)が商用モデルに肉薄しており、特定のタスク(図表理解など)では凌駕している。
- LLaVA-MiniやSmolVLMの登場により、動画処理やエッジAIでのVLM活用が現実的になっている。
産業DXを加速するVLM:4大分野での実用化事例
VLMは研究室を飛び出し、2025年現在、多くの産業で具体的な経済効果を生み出しています。
1. 医療分野:専門医レベルの診断支援
VLMは、X線、MRI、CT、病理スライドといった医療画像と、臨床文書(カルテ)を同時に解釈できます。米国企業のJohn Snow Labsが2025年5月に発表したMedical VLM-24Bは、500万以上の医療画像で訓練され、専門医レベルの診断精度82.9%を達成しました。
また、イギリスの学術誌Nature Digital Medicine(2025年)によると、GPT-4oが救急・ICU環境で68.1%の診断精度を示すなど、医師の「セカンドオピニオン」として機能し、診断の見落としを防ぐツールとしての実用化が進んでいます。
2. ビジネス・小売:顧客対応と契約書レビューの自動化
スウェーデンの決済大手Klarnaは、2024年2月にVLMを統合したAIアシスタントを導入。月間230万件の会話を処理し、顧客の問題解決時間を平均11分から2分未満に短縮しました。これにより、2024年だけで4,000万ドル(約60億円)の利益押上効果があったと報告されています。
また、文書から高精度にテキスト・表を抽出するNVIDIA NeMo Retriever Parseのような技術は、契約書や財務諸表(PDFや画像)からテキストと表をレイアウト通りに高精度で抽出し、グローバル法律事務所では法的レビュー時間を数日から数時間へと短縮しています。
3. 製造業:リアルタイム品質検査とコスト削減
製造業の品質検査ラインにおいて、VLMは人間の目視検査を代替・支援しています。
現場の肌感はシンプルです──“見落としが減り、止まらない”。 Foxconn(鴻海)はVLM導入で欠陥検出率を80%向上、検査時間を30%削減したと報告。目視検査の取りこぼしが減ってラインが軽くなる──メーカー各社が同じ方向へ舵を切っています。
VLMは200ミリ秒未満のリアルタイム処理で最大99.86%の精度で欠陥を検出可能であり、AI視覚検査市場は2033年にかけて約3倍に成長すると予測されています。
4. アクセシビリティ:視覚情報の音声化
VLMは、視覚障害を持つ人々が世界を認識するための強力なツールとなっています。
視覚障害者とボランティアを繋ぐ映像通話アプリBe My Eyesや視覚障害者向けに周囲を音声で説明するAIアプリMicrosoft Seeing AIといったアプリはVLMを統合し、ユーザーがスマートフォンのカメラをかざすだけで、周囲の風景、標識、紙幣、製品ラベルなどをリアルタイムで音声説明する機能を提供しています。
日本のVLM戦略:ロボティクスと文化適応で世界をリード

要約:日本は汎用VLM開発で米中と競うのではなく、強みである「ロボティクス(VLA)」や「日本語・文化への最適化」で独自の地位を確立しています。
Sakana AIやPFN、Telexistenceがその代表例です。
汎用的な超巨大VLMの開発競争では米中企業が先行していますが、日本は独自の強みを活かした分野で世界的な存在感を示しています。
1. VLAとロボティクス(日本の「お家芸」)
日本の最大の強みは、Vision-Language-Action (VLA) モデルと、世界クラスのロボティクス産業の融合です。
- 遠隔操作を開発する日本のTelexistence(テレイグジスタンス)と セブン-イレブン
Telexistence社製のヒューマノイドロボット「Astra」について、開発・導入に向けたパートナーシップを発表。店舗業務(補充・陳列等)への適用を目指し、労働力不足の解決策として期待されています。 - Preferred Networks (PFN) と トヨタ:
AI駆動の産業用ロボットを自動車製造ラインに導入。2030年までに5,000億円規模の投資が計画されており、日本の製造業の根幹を支える技術となっています。
2. 日本語・文化への最適化と独自アプローチ
多くのAIは、その訓練データから欧米(特にサンフランシスコ周辺)の文化や価値観を色濃く反映しがちです。例えば欧米のGreen lightは日本では「青信号」と認識するように、地域の文化を深く理解したAIこそが求められており、日本のスタートアップや研究機関がこの点で世界をリードしています。
- Sakana AI (サカナAI):
「進化的モデルマージ」という独自技術で、既存の高性能モデル(英語VLMと日本語LLM)を「結婚」させ、EvoVLM-JPを開発しました。このモデルは、日本の信号機を現地の慣習通り「青(ao)」と識別できるなど、深い文化的文脈を理解しています。(Nature Machine Intelligence 2025年1月掲載) - Preferred Networks / Preferred Elements:
NEDO(経済産業省所管)の支援を受け、1,000億パラメータのマルチモーダル基盤モデルを開発中。テキスト、画像、動画だけでなく、ゲノムデータやセンサー値まで扱う「全モダリティ統合」を目指しており、2025年の商用化が予定されています。 - 東京大学 松尾・岩澤研究室:
NEDOの委託を受け、数万時間の大規模マルチモーダルデータを収集し、ロボット基盤モデルの開発(TRAIL)を進めています。
このように、日本は「人口減少(労働力不足)」という最大の課題を、VLMとロボティクスという最先端技術で解決する「世界のモデルケース」となりつつあります。
VLMに残された5つの重大な課題と限界
VLMの進化は目覚ましい一方で、2025年現在も解決すべき根本的な課題が残されています。
1. 視覚的幻覚 (ハルシネーション):
VLM最大の課題です。
モデルが存在しない物体を「認識」したり、曖昧な状況でも断定的な誤解釈を生成します。訓練データ内の共起パターン(例:「食卓」の画像には「ナイフ」が写りがち)に依存しすぎる傾向があります。
2. 空間的・時間的推論の欠如:
「AはBの後ろにある」「Cの間にある」といった相対的な空間認識が不正確です。
また、動画をフレームごとに独立して処理するため、時間経過に伴う変化の追跡(例:物が移動した)を苦手とします。
3. 計算コストと効率性:
最先端のVLMは推論(実行)に膨大な計算資源を要求します。
特に視覚トークンはテキストのみのLLMと比べ、大きなオーバーヘッドを生みます。(ただし、SparseVLMやSmolVLMなどの効率化研究も進んでいます)
4. 安全性とプライバシー:
VLMはテキストベースの安全フィルターを回避する可能性があります。画像ファイルに悪意のあるプロンプト(プロンプトインジェクション)を埋め込む攻撃が確認されています。また、Enkrypt AIの2025年5月レポートでは、特定のモデルが危険なコンテンツを生成しやすい脆弱性も指摘されています。
5. 著作権と法的問題:
VLMが学習したデータに著作権物が含まれる場合、その訓練が「侵害」にあたるか、法的な議論が続いています。米国著作権局の2025年5月報告書は「一応の侵害を構成する可能性がある」と結論付けており、AI業界にとって最大のリスク要因の一つとなっています。
👨🏫 AI専門家が解説:かみ砕きポイント
VLMのハルシネーションは、「思い込みが激しい新人」に似ています。多くの知識(訓練データ)はありますが、経験が浅いため、曖昧な写真を見ても「これはきっと〇〇です!」と自信満々に間違えます。また、「Aさんの隣にBさんがいる」という空間認識も苦手です。これらの「思い込み」や「認識の甘さ」が、医療診断や自動運転のような人命に関わる分野での実用化における最大の障壁となっています。
まとめ:2025年、VLMは「思考し、行動する」実用AIへ
2025年10月、VLMは単なる「見て説明するAI」から、「見て、思考し、行動するAI」へと決定的な移行を遂げました。GPT-5のような「推論モデル」の登場、KlarnaやFoxconnでの具体的なビジネス成果、そしてTelexistenceのロボットのような「VLA」の実用化がそれを証明しています。
医療(専門医レベルの精度)、製造(欠陥検出率80%向上)、小売(顧客対応時間80%削減)といった分野で、VLMはすでに測定可能な価値を生み出しています。
一方で、「ハルシネーション」「安全性」「著作権」といった重大な課題は依然として残っており、これらを解決することが次のイノベーションの鍵となります。
日本は、Sakana AIの「進化的モデルマージ」やPFN・Telexistenceの「ロボティクス統合」といった独自の強みを活かし、世界のVLM開発競争において「実用化・社会実装」の領域で確固たる地位を築いています。
2025年から先、VLMはさらに小型化・効率化が進み、スマートフォンから工場のロボットまで、あらゆる場所に「見る知能」として浸透していくでしょう。
私たちは今、AIが現実世界と本格的に融合を始める、その歴史的な転換点に立っています。
専門用語まとめ
- VLM (視覚言語モデル)
- Vision-Language Modelの略。画像や動画などの視覚情報と、テキストなどの言語情報を同時に理解・処理できるマルチモーダルAIモデル。LLMがテキストのみを扱うのに対し、VLMは「見る」能力を持つ。
- VLA (視覚言語行動モデル)
- Vision-Language-Action Modelの略。VLMの進化形で、視覚と言語の理解に基づき、ロボットアームの操作など、物理的な「行動(Action)」までを実行できるモデル。ロボティクス分野での応用が期待される。
- CLIP (Contrastive Language-Image Pre-Training)
- OpenAIが2021年に発表したVLMの基盤技術。膨大な画像とテキストのペアを学習し、AIが「画像」と「それを説明するテキスト」を意味的に関連付けることを可能にした。現代のVLMの多くがこの技術に基づいている。
- 推論モデル (Reasoning Model)
- 2025年のトレンド。単に情報を認識するだけでなく、複雑な問題(数学、科学など)に対して、人間のように段階的に思考し、論理的な答えを導き出す能力を強化したモデル。GPT-5やClaude Sonnet 4.5が代表例。
よくある質問(FAQ)
Q1. VLMの訓練にはどのようなデータが使われるのですか?
A1. 主にインターネットから収集された、膨大な数の「画像(または動画フレーム)」と「その画像を説明するテキスト(キャプションやaltタグ)」のペアが使われます。医療用VLM(Medical VLM-24B)のように、特定の専門分野(医療画像と臨床文書)に特化したデータセットで追加訓練されることもあります。
Q2. VLMの「ハルシネーション(幻覚)」はなぜ起こるのですか?
A2. 主な原因は、訓練データへの過度な依存です。例えば、訓練データ内で「キッチン」の画像に「ナイフ」が写っていることが多すぎると、モデルが「キッチン=ナイフがあるはず」と強く学習し、実際にはナイフが写っていない画像を見ても「ナイフがある」と答えてしまうことがあります。
Q3. 日本のVLM技術は世界から遅れていますか?
A3. 汎用的な超巨大モデルの開発では米中に先行されていますが、「得意分野」では世界をリードしています。特にロボット制御(VLA)や、Sakana AIのような独自のアプローチ(進化的モデルマージ)、日本語と日本の文化に最適化されたモデル開発において、日本は非常に高い競争力を持っています。
主な参考サイト
- OpenAI – Introducing GPT-5(2025)
- Anthropic – Claude Sonnet 4.5(2025)
- John Snow Labs – Introducing Medical VLM-24B(2025)
- Sakana AI – EvoVLM-JP(2024)
- Telexistence, Inc.(VLA / Robotics)(2025)
合わせて読みたい
- 思考するAI、推論が拓く未来 – LLM進化の核心と社会変革(最新動向)
- 2025年にやってくる?AIエージェントの時代(VLA/エージェント)
- RAGとシステム連携の最前線(実装)
- 【2025】主要5大LLMの性能比較|GPT-5・Gemini・Claude・Llama・Grok(モデル比較)
- KVキャッシュ最適化でLLM推論を速く安く賢く【2025】(技術深掘り)
更新履歴
- 初版公開(V2.0)
- 最新情報にアップデート、読者支援機能の強化(V6.8テンプレート適用、2025年10月までの最新動向・モデル情報・VLA・日本動向を全面的に反映)








