


※本記事は継続的に「最新情報にアップデート、読者支援機能の強化」を実施しています(履歴は末尾参照)。
AI半導体英雄譚:GPU・FPGA・ASIC・NPUが共演する『適材適所』の未来
この記事を読むとAI半導体の種類(CPU, GPU, ASIC, FPGA等)ごとの役割と、NVIDIA, AMD, Intel, クラウド各社ら「演出家」たちの最新戦略の関係性がわかり、AIの技術動向の全体像を把握し、「適材適所」の視点で未来を予測できるようになります。
- 要点1:GPU(NVIDIA)は「学習」の主役だが、CUDA生態系と先端パッケージ(TSMC)への依存が鍵。
- 要点2:クラウド企業(Google/AWS/MS)は「自前主義(ASIC/CPU)」でTCOを最適化し、GPU依存から脱却。
- 要点3:FPGA(Altera/Lattice)やAdaptive SoC(AMD)が、エッジの柔軟性・セキュリティ・アップデート需要を担う。
→ まずは「第2章:すべてを統べし者」で基本概念を理解し、次に「幕間:英雄たちの「適材適所」おさらい」で実践的な手順に進みましょう。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
第1章:AI都市の黎明と「計算力」という名の神託
 要約:AI都市は「計算力」を源泉に「学習・判断・制御」を繰り返す。その神託を実現するのがCPUやGPUといった半導体(英雄)たちである。
要約:AI都市は「計算力」を源泉に「学習・判断・制御」を繰り返す。その神託を実現するのがCPUやGPUといった半導体(英雄)たちである。
データの海が音を立てて流れ、深層学習のモデルがゆっくりと目を開く。膨大な情報が複雑なニューラルネットワークを駆け巡り、そこに一つの巨大な都市が生まれた。我々はその都市を「AI」と呼ぶ。
この〈AI都市〉は、特定の物理的な場所を指すのではない。それは我々の社会基盤、産業活動、日々の通信、金融システム、そして移動手段の未来形である。この都市が息を続けるためには、絶え間ない「計算力(コンピュート・パワー)」というエネルギー源が不可欠だ。都市が賢くなればなるほど、そのエネルギーへの渇望は増していく。
AI都市の活動は、突き詰めれば3つの動作の超高速な繰り返しだ。
- “学び”(学習):インターネット上の全テキスト、何十億もの画像、あるいは工場のセンサーが吐き出す膨大な時系列データから、知性の核となるパターンを抽出するプロセス。
- “判断”(推論):学習した知性に基づき、カメラが捉えた物体、投げかけられた質問、株価の変動に対し、瞬時に「答え」を導き出すプロセス。
- “つながる”(通信・制御):その判断を遅延なくネットワークに伝え、あるいは物理世界のロボットアームや自動車のブレーキを「動かす」プロセス。
この3つを、人知を遥かに超える速度、規模、そして電力効率で回し続けること。それこそがAI都市に下された唯一の「神託」である。
そして、この「神託」を実現するために、舞台に召喚された者たちがいる。それが「半導体」と呼ばれる英雄たちだ。CPU、GPU、FPGA、ASIC、そして彼らを束ねる新世代の指揮官たち。これは、AI都市の未来を形作る英雄たちの役割と、彼らを配役する「演出家(企業)」たちの戦略を巡る、壮大な物語である。
第2章:すべてを統べし者 ― 「司令塔」CPUの功績と再定義

要約:第1章で描いたAI都市の鼓動(学習・判断・制御)を絶やさないために、CPUは“万能実行者”から舞台監督へと役割を変えました。学習・推論の主演はGPUに譲りつつも、全体設計・TCO最適化・供給安定を指揮する中核として、むしろ重要度が増しています。
AI都市の幕が上がり続けるのは、裏で段取りを整える監督がいるからです。かつてCPUは、OSもアプリも通信も、さらには初期のAIの学習・推論まで一手に担う“万能の司令塔”でした。しかし、ディープラーニングという並列処理の怪物が登場すると、逐次処理を前提とする設計は限界を見せました。そこでCPUは、一歩下がって舞台全体の交通整理と配役を担う監督へと再定義されていきます。
監督の仕事は明快です。限られた電力と予算で、学習・推論・通信を滞りなく回すこと。そのために、CPUはサーバー設計からネットワーク、冷却、そしてアクセラレータ選定まで、クラウドという大劇場全体の最適化を采配します。
各社の取り組み(例)
- Microsoft:Arm系サーバーCPU「Cobalt」とAIアクセラレータ「Maia」を揃え、ラックや冷却まで含めてクラウド全体を自前最適化します。狙いはNVIDIA依存を緩め、コストと供給の主導権を徐々に取り戻すことです。
- AWS:自社CPU「Graviton」と「Trainium/Inferentia」を組み合わせ、OSからチップまでの垂直統合でTCOを圧縮します。推論・学習を適材適所に振り分け、価格交渉力と可用性を高めます。
- (参考)Google:自社設計CPUやTPUを併用し、ワークロード特化でコストと安定供給を追求します。
ここで強調したいのは、これらの動きが今すぐGPU性能の覇権を奪う試みではないという点です。現在の焦点は、①TCOの最適化、②供給の安定化、③価格交渉力の回復にあります。GPUが学習の主演である構図は当面変わりませんが、誰が舞台を設計し、どのシーンでどの役者を立Sせるか――その配役権を握ることが、クラウド各社の勝負どころになっています。
結論:CPUはAI時代における経済合理性の中心=舞台監督として復権しました。第3章では、主演であるGPUがどのように光を浴び、どの制約に直面しているのかを、舞台裏(供給・電力・パッケージ)の実情とともに見ていきます。
第3章:学習の革命と生態系 ― 「主演」GPUの栄光と制約
 要約:NVIDIAはCUDA生態系でAI学習の主演を確立しました。ただし供給はTSMCの先端パッケージ(CoWoS)に依存し、電力・発熱・供給網が制約になります。
要約:NVIDIAはCUDA生態系でAI学習の主演を確立しました。ただし供給はTSMCの先端パッケージ(CoWoS)に依存し、電力・発熱・供給網が制約になります。
学習領域で革命を起こしたのはGPUです。元来は3D描画向けの並列計算の達人でしたが、ディープラーニングの行列演算と理想的に噛み合いました。NVIDIAはCUDAという開発基盤を築き、ソフトからハードまでを包む城塞型エコシステムで主役の座を固めました。
製品面では、Hopper(H100)→ Blackwell(B200:2025年前半生産開始/B300:2025年後半)→ Rubin(2026年後半予定)→ Rubin Ultra(2027年後半予定)→ Feynman(2028年予定)という年次ロードマップを公表している。
一方、舞台裏ではTSMCのCoWoSがボトルネックです。先端パッケージの能力増強は進むものの、世界的な需要に追いつきにくく、電力消費・発熱・供給枠が常に計画の制約になります。需給は波打ち、GPUが主役である事実は変わらないものの、製造・パッケージ・電力という現実的な足場が性能の上限を決めます。
なお、ネットワークやデータセンター設計、電力の話は本章では深追いしません。詳細は以下の関連記事をご参照ください。
- 【解説】AIインフラ市場2025最新|NVIDIA独占に挑む各社戦略(インフラ投資とサプライ動向)
- 【現地レポ】GTC 2025:AIファクトリーと“トークン採掘”(GPUロードマップと電力・冷却)
- 【技術比較】NVLink vs. Ethernet/InfiniBand(学習スケールのネットワーク設計)
ポイント:GPUは学習の主演、NVIDIAは生態系で主役の座を固定。ただし、勝敗を左右するのはチップ単体ではなく、電力・パッケージ・供給の現実に合わせた配役設計です。
第4章:未知と対峙する影 ― 「変幻のFPGA」と新たな使命
 要約:FPGAは「回路を書き換えられる」柔軟性で、エッジの低遅延やセキュリティ(PQC)という新たな使命を担う。Alteraの独立やLatticeが象徴だ。
要約:FPGAは「回路を書き換えられる」柔軟性で、エッジの低遅延やセキュリティ(PQC)という新たな使命を担う。Alteraの独立やLatticeが象徴だ。
GPUがデータセンターという「中央」で巨大な脳(モデル)を鍛えている間、AI都市の「最前線(エッジ)」ではまったく異なる戦いが始まってていた。工場の製造ライン、5Gの通信基地局、自動運転の開発車両――そこは、仕様がまだ固定せず、現実世界のノイズと戦い、ミリ秒以下の「超低遅延」が要求される過酷な現場だ。
このような「未知」と対峙する領域で、影から忍び寄り、任務を遂行する英雄がいる。それがFPGA(Field-Programmable Gate Array)だ。「現場でハードウェア回路そのものを書き換えられる」という特異な能力を持つ「忍者」である。CPUやGPUが固定されたアーキテクチャの上でソフトウェアを実行するのに対し、FPGAは回路設計そのものを変更し、タスクに最適化できる。
この忍者の世界が今、大きく動いている。かつてIntelの内部部門だったAlteraは、2025年4月14日にSilver Lakeによる51%出資が発表され、取引は2025年下半期に完了予定。Intelは49%を保持しつつ、AlteraはアブダビのMGXなどからも出資を受け、FPGA専業として「機動力」と「顧客密着のスピード経営」を取り戻そうとしている。これは、仕様が揺れ動く現場において「プロトタイピング」の脇役だった忍者が、「本番の主戦力」として再び主役級の役割を担おうとする動きだ。
さらに、このFPGAには「セキュリティ」という新たな使命が与えられた。Lattice Semiconductorは、「ポスト量子暗号(PQC)」対応のFPGA、MachXO5-NX TDQを発表。これは、将来量子コンピュータが現在の暗号を破る「量子ブレイク」に備え、データセンターや通信インフラの「制御」部分に「量子耐性」という新しい鎧を与えるものだ。
GPUのような華々しさはない。だが、AI都市が現実世界と接続し、変化に対応し、そして「安全」であり続けるために、この変幻自在な忍者の暗躍は、不可欠な物語の構成要素となっている。
第5章:一点特化の効率主義 ― 「刺客」ASICとクラウド“自前主義”の加速
要約:ASICは特定用途(主に推論)に特化したチップで、究極の効率を出す。GoogleやAWSが、GPU依存脱却とTCO削減のため「自前主義」で開発を加速中だ。
AI都市が拡大すると「効率」の壁が生まれた。データセンターでは学習(Training)だけでなく、学習済みモデルで「判断」を下す「推論(Inference)」の量が爆発的に増加。これを圧倒的な物量、超低コスト、超低電力で処理する必要に迫られたのだ。
この「仕様が完全に固まった」戦場において、汎用性や柔軟性をすべて捨て去り、ただ一点の任務を遂行するためだけに生まれてきた英雄がいる。ASIC(Application-Specific Integrated Circuit)、すなわち「特定用途向け集積回路」だ。
ASICは、その任務においてCPUやGPUを遥かに凌駕する究極の効率(性能電力比)を叩き出す「一点特化の暗黒騎士」である。このASICの力にいち早く気づき、自らの「刺客」として育て上げたのが、クラウドの巨人たちだ。
- Google:TPU v7『Ironwood』(第7世代)を打ち出し、生成AIアプリや推論系ワークロードを安価・低電力で大量稼働させる“クラウド側の量産エンジン”と位置づける。最近ではAnthropicとの大規模な長期契約も公表され、ASIC型アプローチが実験段階ではなく本番スケールに入ったことを示している。
- AWSは、「Inferentia(推論用)」と「Trainium(学習用)」を世代更新し続け、自社サービスと一体化させることで、NVIDIAのGPUに依存しない「価格交渉力」と「可用性」を手に入れた。
- Metaは、自社開発の「MTIA」を量産導入し、GPUと併用するハイブリッド運用を公表。汎用GPUの覇権下で、自社の負荷に合わせた「最適化の刃」を磨き続ける。
彼らクラウド勢の「自前主義」の狙いは明確だ。自社のワークロードに完璧に合わせたASICを持つことで、TCO(総所有コスト)、電力効率、そして供給安定性の三点を制すること。成功すればGPUに代わる主役となるが、失敗すれば高価な墓標となる、ハイリスク・ハイリターンな戦略である。
第6章:将軍と忍者の融合 ― 「適応型SoC」とAMDの総合演出
 要約:Adaptive SoCはCPUとFPGAの能力を1チップに統合した指揮官だ。Xilinxを買収したAMDは、これを武器に「総合演出家」として高度エッジ市場を狙う。
要約:Adaptive SoCはCPUとFPGAの能力を1チップに統合した指揮官だ。Xilinxを買収したAMDは、これを武器に「総合演出家」として高度エッジ市場を狙う。
CPUの「汎用性」、GPUの「並列処理力」、FPGAの「柔軟性」、ASICの「効率性」。AI都市が成熟するにつれ、最前線の現場は、これらの異なる能力を「同時に、かつバランス良く」求めるようになった。
例えば、自動運転車(AD/ADAS)だ。基本的な車両制御はCPUが担い、歩行者認識はAIエンジン(ASIC的要素)が瞬時に処理し、将来の新しい通信規格にはFPGA的要素が「適応」する。この複雑怪奇な要求に応えるため、新世代の英雄、Adaptive SoC(適応型System-on-a-Chip)が誕生した。
チップ上には、司令塔たるCPU(将軍)、AI処理などを担う専用エンジン(ASIC)、そして自在に回路を書き換えられる再構成可能ロジック(忍者=FPGA)が、一つのチームとして統合されている。彼は「将軍的司令塔」の処理能力と、「忍者的適応力」を併せ持つ、新世代の「統合指揮官」だ。
この指揮官のポテンシャルに賭けたのが、演出家AMDである。AMDは、高性能なCPU(Ryzen)とGPU(Radeon)を擁していたが、2022年、FPGAとAdaptive SoCの最大手であったXilinxの買収を完了する。
この一手により、AMDは「CPU+GPU+Adaptive SoC」という、市場のあらゆる要求に応えうる最強のポートフォリオを手に入れた。
データセンターという「中央」から、車載、通信、産業機器という「エッジ」まで、「配役の最適化」をワンブランドで回す「総合演出家」としての地位を確立した。エッジの戦いが「個々の英雄の力」から「いかにチームをまとめめるか(SoCの力)」へと移行する中で、AMDの戦略はひときわ輝きを放っている。
幕間:英雄たちの「適材適所」おさらい
要約:AIの未来は単一のチップが支配するのではない。CPU、GPU、ASIC、FPGA、SoC、NPU、Adaptive SoC、Chiplet――特性の異なる英雄たちが「適材適所」で配役される演劇である。
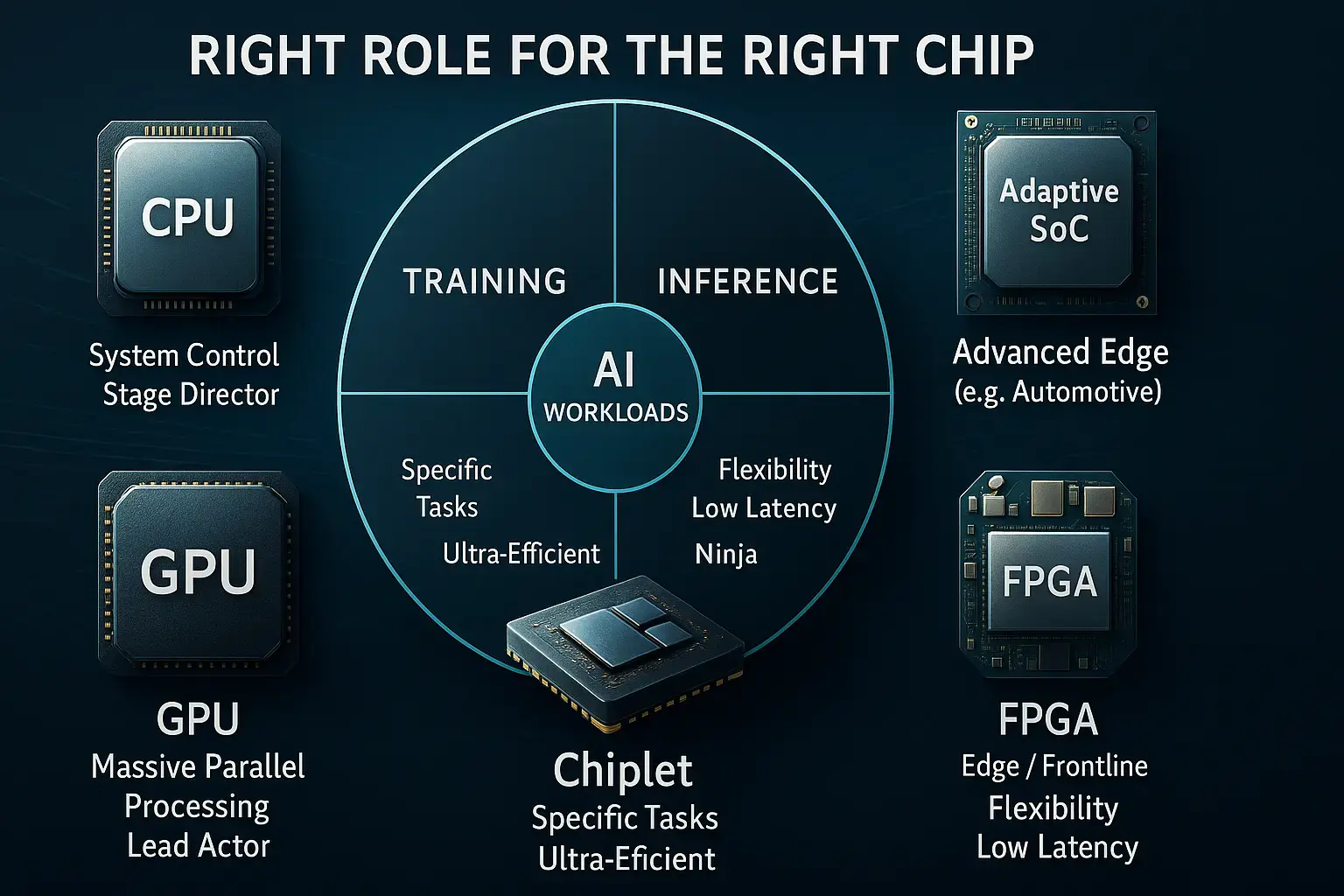
図の要点:AIワークロード(学習/推論)とエッジに対し、GPU(学習主役)、ASIC(推論特化)、CPU(全体制御)、FPGA(低遅延)、Adaptive SoC(高度エッジの統合指揮)などが役割分担して機能します。
ここまでで、AI都市の舞台に立つ主要な英雄たちが揃った。物語が「演出家(企業)たち」の複雑な戦略に移る前に、ここで一度、各英雄の特徴と役割を簡潔におさらいしておこう。
AIクラウドとエッジの未来は、単一の英雄が支配するのではなく、特性の異なる英雄たちが「適材適所」で配役される壮大な演劇である。 なぜ彼らは、それぞれの形で生き残り、必要とされ続けているのだろうか。
CPU(舞台監督)
 CPUは、まるで「舞台監督」のように、パソコンやスマホの全てを指揮する司令塔です。
CPUは、まるで「舞台監督」のように、パソコンやスマホの全てを指揮する司令塔です。
OSの起動からアプリの実行、ネットワーク通信の管理まで、あらゆる指示を一つずつ正確にこなす「逐次処理」の天才。AIが動くシステム全体の交通整理を担い、どの情報がどこへ向かうべきかを瞬時に判断します。AIの計算自体は他のチップに任せつつも、システム全体の効率と安定性を保つことで、舞台裏からAI都市の経済合理性を支える、縁の下の力持ちなのです。
GPU(絶対的主演)
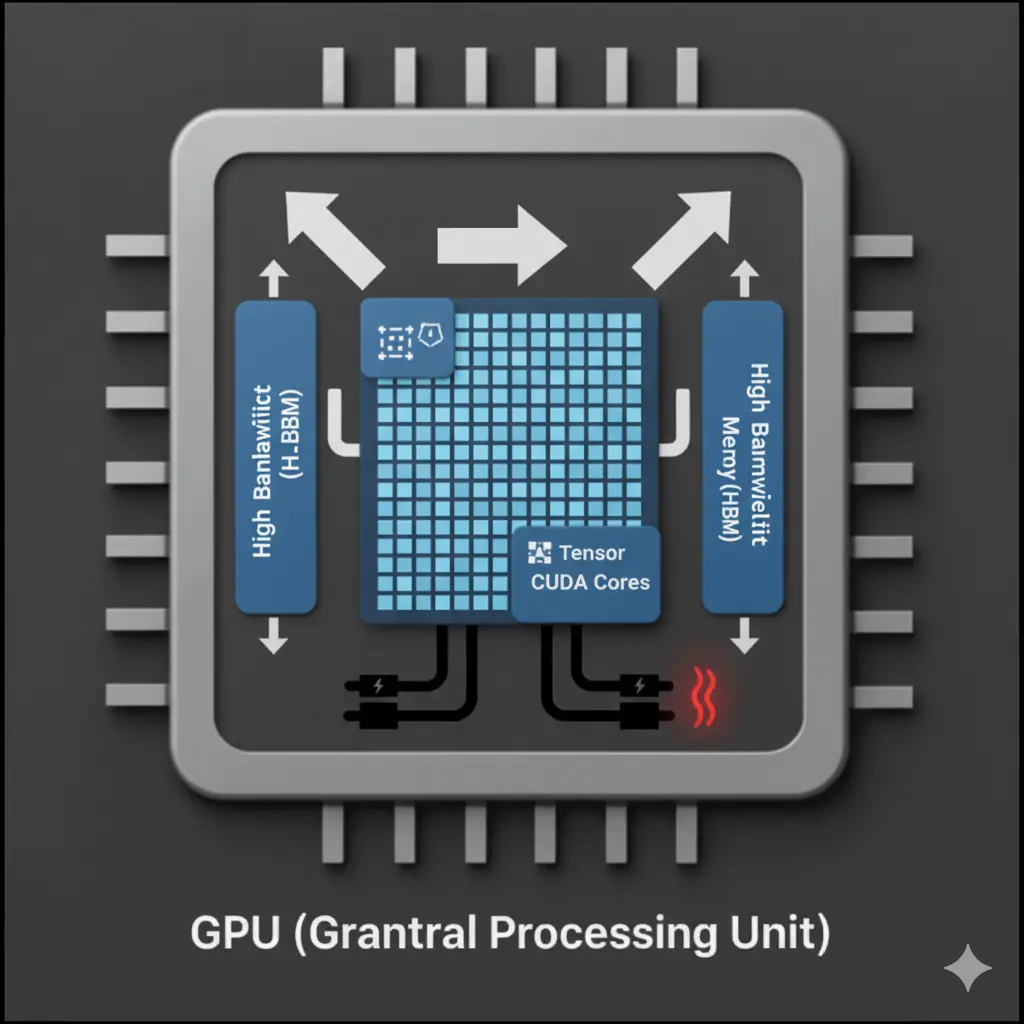
GPUは、AI学習の舞台で「絶対的主演」を演じる、大規模並列処理のスターです。
何千、何万もの計算を同時にこなせるその能力は、膨大なデータを学習して賢くなるAIモデルにとって不可欠。まるで何百人ものダンサーが一斉に複雑な振り付けを踊るように、膨大な行列演算を爆速で処理します。その力ゆえに電力消費は大きいですが、NVIDIAのCUDAのような強力なエコシステムに支えられ、AI進化の最前線を走り続ける、輝かしい主役なのです。
ASIC(一点特化の刺客)
 ASICは、AIの特定タスクに特化した「一点特化の刺客」です。
ASICは、AIの特定タスクに特化した「一点特化の刺客」です。
「このAI推論だけを究極に効率良くこなす!」と決められた目的のためにだけ設計されるため、無駄が一切ありません。まるで標的を確実に仕留めるスナイパーのように、超低電力で最高の性能を発揮します。クラウド企業が自社AIのために開発することも多く、汎用的なGPUに頼らず、独自の道を切り開く「GPU依存からの脱却」の切り札として、密かにAI都市の舞台裏で暗躍しています。
FPGA(変幻の忍者)

FPGAは、その名の通り「現場でハードウェア回路を書き換えられる」唯一無二の「変幻の忍者」です。
CPUやGPUが固定された機能を持つ一方、FPGAはまるで真っ白なキャンバスのように、使うたびに最適な回路を「その場でデザイン」できます。この柔軟性により、仕様がまだ固まっていない最新技術への対応や、超高速なデータ処理、最高レベルのセキュリティ(PQCなど)が求められる予測不能な「最前線」で真価を発揮します。刻々と変化するAI都市のニーズに応え、暗闇で多様なタスクをこなす、まさに変幻自在の半導体です。
SoC(オールインワンの実務家:器)
 SoCは、CPU、GPU、AI専用のNPUなど、多様な機能を「一枚のチップに統合した器」、まさに「オールインワンの実務家」です。
SoCは、CPU、GPU、AI専用のNPUなど、多様な機能を「一枚のチップに統合した器」、まさに「オールインワンの実務家」です。
スマートフォンやタブレット、IoT機器といった「エッジ」の最前線で活躍し、電力、サイズ、コストの全てを最適化します。まるで多才な職人が、必要な道具全てをコンパクトなツールボックスに収め、あらゆる現場で効率的に作業をこなすように、AIが搭載されたエッジデバイスの頭脳として、様々なタスクを統合的に処理し、私たちの生活を支えています。
NPU(専属ダンサー:行列演算の主演)
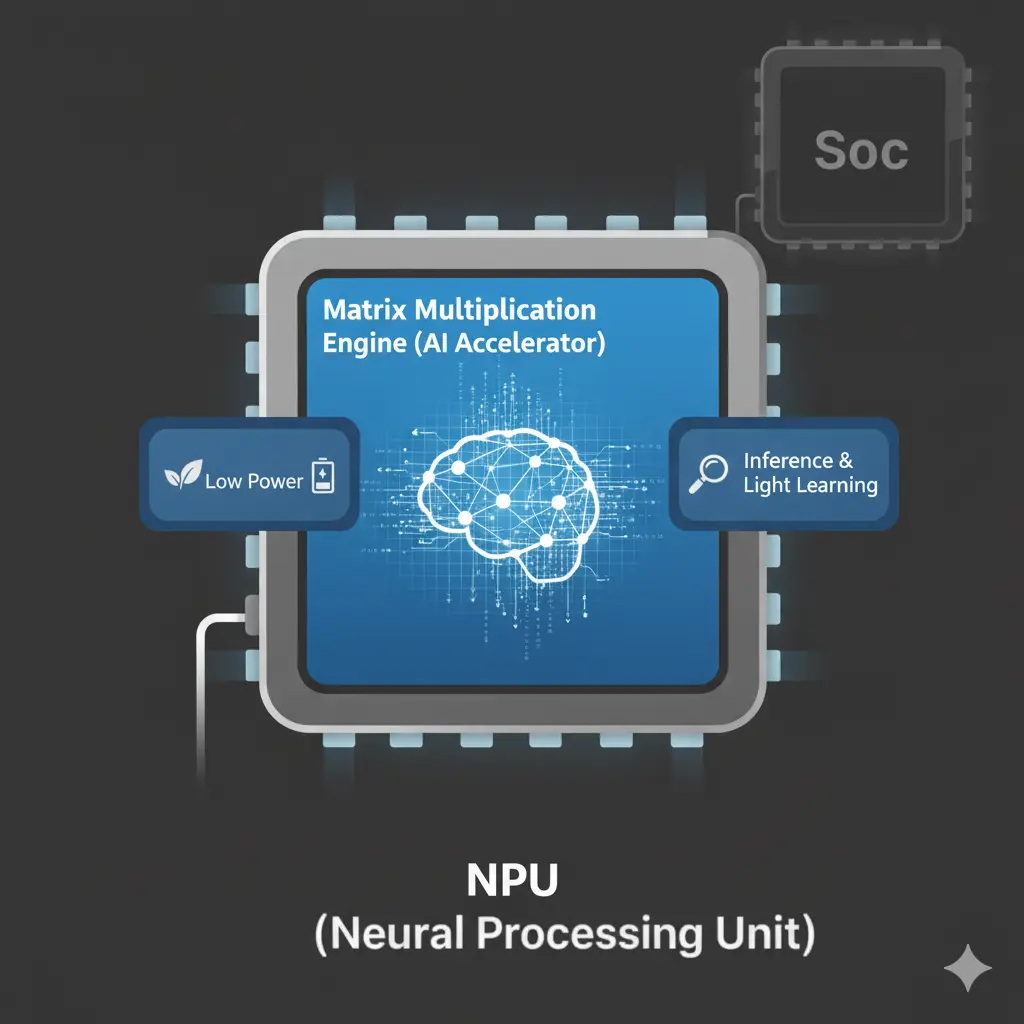 NPUは、AIの頭脳であるニューラルネットワークの計算を専門とする「AI専用プロセッサ」です。
NPUは、AIの頭脳であるニューラルネットワークの計算を専門とする「AI専用プロセッサ」です。
私たちの脳のように、多くの情報を一度に処理するAIは、特に「行列演算」という複雑な計算を大量にこなす必要があります。NPUは、この行列演算を超高速かつ低電力で行うことに特化して設計されており、まるでAI計算の「専属ダンサー」のように、効率的に動き続けます。
スマートフォンやパソコン、エッジデバイスなどでAIが賢く動くのは、このNPUが推論(AIの判断)や、時には簡単な学習を素早く処理してくれるから。SoC(システムオンチップ)の一部として搭載されることが多いですが、AIの進化と共に、より強力な独立チップとしても注目されています。AIを身近にする立役者と言えるでしょう。
Adaptive SoC(統合指揮官)
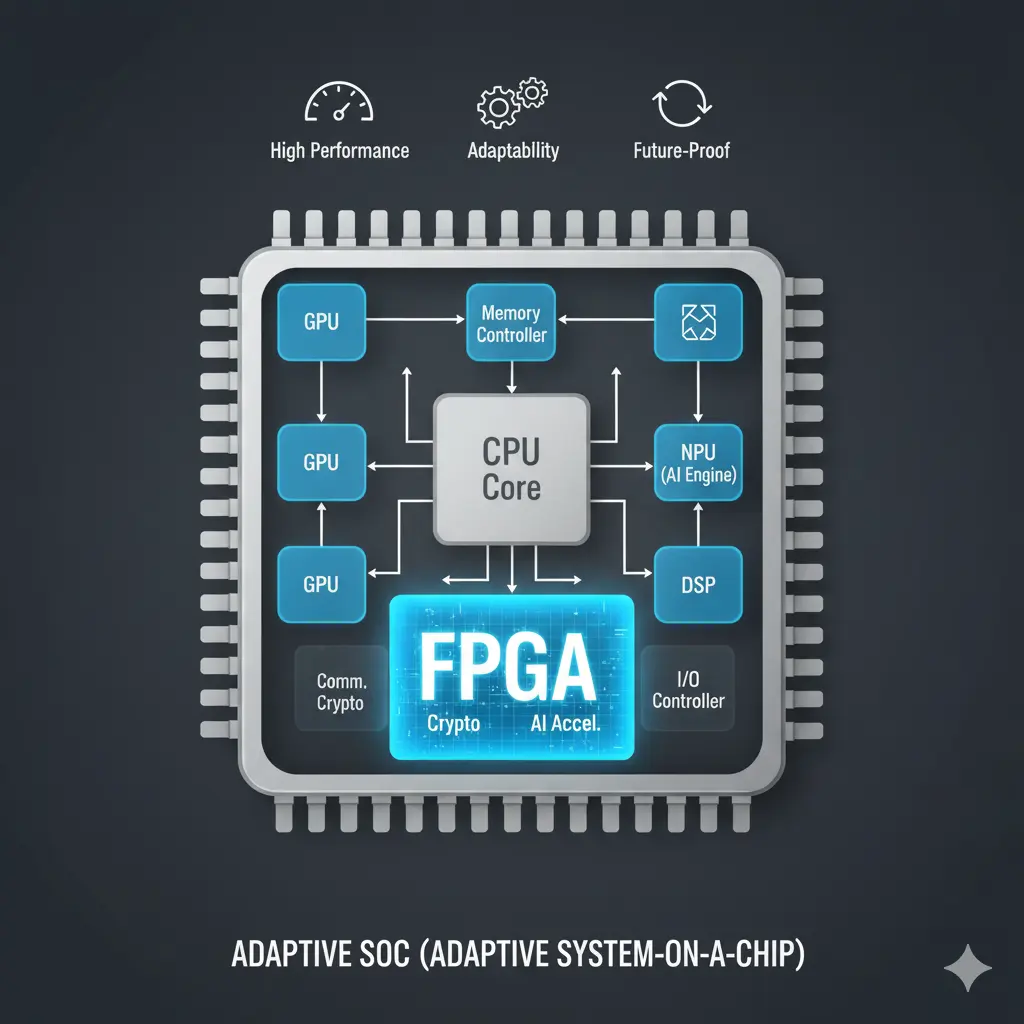 Adaptive SoCは、SoCの多機能性にFPGAの「変幻の柔軟性」を融合した「統合指揮官」です。
Adaptive SoCは、SoCの多機能性にFPGAの「変幻の柔軟性」を融合した「統合指揮官」です。
CPU、GPU、AIアクセラレータといった固定機能に加え、現場で回路を書き換えられるFPGAロジックを搭載。まるで状況に応じて部隊の編成や戦略を瞬時に変える指揮官のように、刻々と変化する要求や将来のアップデートに対応できます。特に自動運転や通信システムなど、高性能と高い適応力が求められる高度なエッジ分野で、未来のAIを支える重要な役割を担っています。
Chiplet(設計思想/舞台装置)
 Chipletは、半導体の製造を根本から変える「舞台装置」のような革新的な設計思想です。
Chipletは、半導体の製造を根本から変える「舞台装置」のような革新的な設計思想です。
これまでのSoCが多機能を一枚岩のように統合するのに対し、ChipletはCPUやGPU、AIエンジンなど、異なる役割を持つ小さなチップ(チップレット)を個別に製造。それらをまるでレゴブロックのように組み合わせて、一つの大きな高性能プロセッサを作り上げます。これにより、製造コストを抑えつつ、各機能に最適な最新技術を適用可能に。異なる企業が作ったチップレット同士もUCIe規格で連携し、半導体設計と製造に無限の自由度をもたらす、舞台裏の革命家なのです。
AI半導体・英雄たちの比較表
| チップ名 | 別名(比喩) | 得意な処理 | AIにおける主な役割 | 代表企業・製品 |
|---|---|---|---|---|
| CPU | 司令塔 / 舞台監督 | 逐次処理、複雑な制御 | OS、ネットワーク、システム全体の管理、TCO最適化 | Intel (Xeon), AMD (EPYC), AWS (Graviton), Microsoft (Cobalt) |
| GPU | 絶対的主演 | 大規模並列処理 | AIモデルの学習/大規模推論 | NVIDIA (H100, B200), AMD (MI300) |
| ASIC | 一点特化の刺客 | 特定タスク(主に推論) | 推論の超高効率化、TCO削減(クラウド自前主義) | Google (TPU), AWS (Inferentia), Meta (MTIA) |
| FPGA | 変幻の忍者 | 低遅延I/O、回路書き換え | 仕様未定タスク、通信制御、セキュリティ(PQC) | Altera (Agilex), Lattice (MachXO5) |
| SoC | オールインワンの“器” | CPU/GPU/NPU/IO等の機能統合 | 端末の総合処理、電力・サイズ・コスト最適化(エッジ) | Apple (A/M), Qualcomm (Snapdragon), MediaTek (Dimensity), Samsung (Exynos) |
| NPU | 専属ダンサー / 行列演算の主演 | NN向け行列演算、データフロー処理、systolic配列 | エッジ/PC/サーバでの推論(と軽い学習)を低電力高速に実行 | Arm (Ethos), Apple (Neural Engine), Intel (NPU), Qualcomm (Hexagon), Google (Tensor NPU) |
| Adaptive SoC | 統合指揮官 | 汎用+AI+適応ロジックの統合 | 車載・通信・産業などの高度エッジで性能と柔軟性を両立 | AMD (Versal), Intel (Agilex SoC) |
| Chiplet(技術) | 装置家 / 舞台装置 | 機能の分離・接続 | 製造効率の最適化、異社混載(UCIe規格) | UCIe(規格), TSMC (CoWoS), Intel (Foveros) |
第7章:「分離」と「集中」 ― Intel / Alteraの“離れて繋がる”作戦
要約:Intelはファウンドリ事業に集中するため、FPGA部門Alteraを分離・独立させた。これはAMDの「統合」戦略とは真逆の「分離・集中」モデルである。
さて、物語は再び「演出家」たちの戦略に戻る。AMDが「統合」の道を選んだ一方、長年のライバルであるIntelは、苦境の中で正反対の戦略的決断を下した。「分離」と「集中」である。
Intelは、自社のチップ設計だけでなく、他社のチップも製造する「ファウンドリ(製造受託)」事業の王座をTSMCから奪還するという野心的な計画「IDM 2.0」にすべてを賭けている。これは、Intelが「演者」であると同時に、「舞台装置(製造)」の覇者にもなるという壮大な戦略だ。
この大戦略の下、Intelは経営資源を「製造」に集中させるため、非中核事業の「分離」を断行した。その象徴が、第4章で触れたFPGA部門(Altera)の過半数株式売却だ。
これは、AMDとは真逆の「分離」戦略である。Alteraを「俊敏なFPGA専業(忍者)集団」として独立させ、市場で機動的に戦わせる。その一方で、Intel本体は「製造ファウンドリ」という「舞台装置」の強化に経営資源を集中する。Alteraは独立後、AgilexやQuartusといった製品・ソフトウェアの更新テンポを上げ、「顧客密着のスピード経営」で存在感を再構築中だ。IntelはAlteraの49%の株を保持し、ファウンドリの顧客として「離れて繋がる」関係を維持する。これは、AI都市の覇権を巡る、AMDの「統合」モデルに対するIntelの「分離・集中」モデルという、壮大な社会実験とも言える。
第8章:舞台裏の静かなる革命 ― 「装置家」チップレットとUCIe 3.0の衝撃
 要約:製造限界を突破する「チップレット」設計が革命を起こしている。標準規格「UCIe 3.0」の登場で、他社製チップの「異社混載」という究極の自由が現実になる。
要約:製造限界を突破する「チップレット」設計が革命を起こしている。標準規格「UCIe 3.0」の登場で、他社製チップの「異社混載」という究極の自由が現実になる。
英雄たちがどれほど強力になろうとも、彼ら全員が共通の、そして物理的な危機に直面していた。「ムーアの法則」の鈍化と、製造技術の限界である。
AIの要求に応えるため、チップは巨大化・複雑化し、一つの巨大なシリコンウェハーから完璧なチップを切り出す「モノリシックSoC」は、製造コストと歩留まりの悪化という限界に達した。
この舞台そのものの崩壊危機を救ったのは、演者(英雄)ではなく、舞台裏の「装置家」だった。チップレット(Chiplet)という設計思想の革命である。
チップレットとは、巨大な一つのチップを作る代わりに、機能ごとに小さなチップ(CPUコア、GPUコア、I/Oなど)を個別に製造し、それらを後から高密度に接続・合体させる技術だ。これにより、CPUコアは最先端の3ナノで、I/O部分は枯れた14ナノで、といった「適材適所」の製造プロセスを選べる。
この革命を現実のものとして加速させているのが、「UCIe(Universal Chiplet Interconnect Express)」という業界標準規格だ。2025年8月5日に発表されたUCIe 3.0では、接続速度が最大64 GT/sに向上し、管理性や省電力機能も拡充された。
これにより、「AMDのCPUと、IntelのGPUと、XilinxのFPGAを、レゴブロックのように組み合わせる」という「異社混載」の夢が、いよいよ現実のものとなり始めた。“好きな才能を、好きな工場で作って、後で合流させる”という、究極の配役の自由。これは、AI半導体という演劇の「脚本」そのものを根本から変える、静かだが決定的な革命だった。
第9章:舞台を制する者 ― 「製造覇権」TSMCとCoWoSの支配力
要約:チップレット時代は、接続技術「先端パッケージ」が覇権を握る。TSMCの「CoWoS」が市場を支配し、供給のボトルネックとなっている。
チップレットという革命は、新たな権力構造を生み出した。それは、「演者(チップ)がどれだけ優れていても、彼らが立つ舞台(先端パッケージ)がなければAIは動かない」という冷厳な現実である。英雄たちをレゴブロックのように高密度に接続する技術、それこそが「先端パッケージ」だ。
この舞台の支配者として君臨するのが、台湾のTSMCである。彼らが提供する「CoWoS」などの先端パッケージ技術は、第3章で述べたNVIDIAの高性能GPU(H100, B200)を現実に組み上げるために不可欠だ。NVIDIAがどれだけ優れた設計をしても、TSMCがCoWoSの生産枠を確保できなければ、AI都市は深刻なGPU不足に陥る。
TSMCは、第3章で触れた通り、CoWoSの能力(2025年末は月産6.5〜7.5万枚規模、2026年末に約10万枚規模を目指すと報じられている)を拡大し続けることで、GPU時代、そして来るべきチップレット時代の「ボトルネック」を握り、実質的にどの英雄を舞台に立させるかを決める「キャスティングボード」を支配している。
この「舞台支配」の構図に真っ向から挑むのが、第7章で触れたIntel Foundryだ。Intelは、自社こそが最先端の製造技術とパッケージ技術を(地政学的リスクの低い)欧米で提供できる唯一の存在だと宣言し、TSMCの牙城に攻め込もうとしている。
演者(チップ設計)の戦いと同時に、あるいはそれ以上に熾烈な「舞台装置(製造・パッケージ)」の覇権争い。AI都市の未来は、この裏方でありながら実質的な権力を握る者たちの動向に大きく左右される。
第10章(終章):勝者はひとりではない ― 「配役」を制する者が未来を纏う
要約:AI半導体に絶対王者は存在しない。GPU, ASIC, FPGAなどが「適材適所」で配役される時代だ。最適な「配役(演出)」こそが未来の戦略である。

これまで説明してきたように、AI半導体戦略とは、単一のチップではなく、指揮者(企業)がCPU・GPU・ASIC・FPGAといった楽団(チップ群)を「適材適所」で指揮し、調和させる「演出」であることを象徴しています。
AI半導体英雄譚、その物語の核心は「絶対王者」の不在である。
かつてCPUがそうであったような、すべてを支配する唯一の英雄は、もはや存在しない。
AI都市の真実とは、「適材適所」という言葉に尽きる。
データセンターでの「学習」はGPUが、「推論」と「TCO最適化」はASICが、「最前線」の低遅延や適応力はFPGAやAdaptive SoCが担う。それぞれの英雄が、UCIe 3.0という共通言語を得た「チップレット」という舞台装置の上で、自らの役割を演じているのだ。
この複雑な演劇において、企業の役割は「最強の英雄を育てる」ことから、「最適な配役を決定する演出家」へと完全に移行した。
この壮大な連携と再編の渦の中で、AI都市の未来は形づくられていく。
勝者はひとりではない。
この複雑な戦場で、英雄たちの特性を見抜き、最適な役割を与え、最高の舞台を用意する「配役のマジック」。それこそがAIの勝敗を決め、未来を纏う唯一の戦略なのである。
読者であるあなたは、どの英雄に、そしてどの演出家の采配に、未来を託すだろうか。
専門用語まとめ
- CoWoS (Chip-on-Wafer-on-Substrate)
- TSMCの先端パッケージ技術。チップレット(小さなチップ)を高密度に基板上で接続する。NVIDIAの高性能GPU製造に不可欠で、AI半導体の供給量を左右するボトルネックとなっている。
- Cobalt (Microsoft Cobalt CPU)
- Microsoftが自社開発したArmベースのCPU。Azureクラウドの汎用ワークロード向けに設計。NVIDIA GPUへの依存を減らし、TCO(総所有コスト)を最適化する「自前主義」戦略の柱の一つ。
- Maia (Microsoft Maia 100)
- Microsoftが自社開発したAIアクセラレータ(ASIC)。主にAIの「推論」処理を効率化するために設計された。CPU「Cobalt」と連携し、クラウドインフラ全体の最適化を目指す。
- Graviton (AWS Graviton)
- AWS(Amazon)が自社開発するArmベースのCPU。クラウド(EC2)の汎用ワークロード向け。高い電力効率とコスト性能を武器に、IntelやAMDに対抗し、クラウドのTCO最適化を推進する。
- Trainium / Inferentia (AWS)
- AWSが自社開発するAIチップ(ASIC)。「Trainium」はAIの「学習」に特化、「Inferentia」は「推論」に特化している。GPU依存から脱却し、AIワークロードのコストを最適化する切り札。
- Altera (アルテラ)
- FPGA(回路を書き換えられる半導体)の大手。元々はIntelの一部門だったが、2025年4月14日発表、同年下半期にスピンアウト完了予定。機動力を高め、AIエッジデバイスや通信インフラ市場での「適応力」を武器に再攻勢をかける。
- Lattice (Lattice Semiconductor)
- 低消費電力FPGAに強みを持つ半導体メーカー。AI都市の「最前線(エッジ)」に加え、将来の量子コンピュータによる暗号解読に備える「ポスト量子暗号(PQC)」対応チップで、インフラの制御・セキュリティ分野を担う。
- Ironwood(Google TPU v7/第7世代)
- Googleが開発したAIチップ(ASIC)であるTPU(Tensor Processing Unit)のTPU v7(第7世代)。主に「推論」処理に最適化されており、自社サービスおよびGoogle Cloudで利用される。ASICによる「自前主義」の象徴。
- NVLink vs. Ethernet/InfiniBand
- AIデータセンター内でGPU同士を接続する超高速ネットワーク技術に関する議論です。NVIDIAの独自規格か汎用規格かという戦略の違いを指します。
→ 詳細は「AIネットワーク三層|NVLink・InfiniBand・Ethernet/Spectrum-の役割」で解説しています。
よくある質問(FAQ)
Q1. FPGAとは何が優れているのですか?
A1. 出荷後にハードウェア回路を書き換えられる「柔軟性」が最大の特徴です。仕様が未定の現場や、PQC(ポスト量子暗号)対応など、セキュリティや適応力が求められる通信・産業分野で活躍します。
Q2. AMDの「Adaptive SoC」戦略とは何ですか?
A2. Xilinx買収により、CPU(将軍)の制御力とFPGA(忍者)の適応力、AIエンジンを1チップに統合した戦略です。高性能と将来のアップデートという相反する要求を両立させ、特に車載や通信市場を狙っています。
Q3. チップレットとUCIe 3.0の登場で何が変わるのですか?
A3. 製造限界を突破できるだけでなく、UCIeという共通規格により、メーカーの垣根を超えたチップの「異社混載」が可能になります。これにより、AMDのCPUとIntelのGPUを組み合わせるような、究極の「適材適所」が実現し、設計の自由度が飛躍的に高まります。
Q4. IntelがAltera(FPGA部門)を分離したのはなぜですか?
A4. AMDが「統合(全部入り)」戦略を採るのに対し、Intelは「分離と集中」戦略を選びました。本体はファウンドリ(製造)事業に集中し、Alteraは独立させて機動力を高める狙いです。Intelは製造顧客としてAlteraと「離れて繋がる」関係を維持します。
主な参考サイト
- NVIDIA Blackwell アーキテクチャ
- AMD Instinct™ MI300X アクセラレータ
- Google Cloud TPU の概要
- AWS Trainium(AIアクセラレーター)
- UCIe 3.0 仕様アップデート
合わせて読みたい
- NVLink vs Broadcom論争の真相|AIネットワークの力学を一気に理解する
- AIネットワーク三層|NVLink・InfiniBand・Ethernet/Spectrum-の役割
- AIインフラ市場2025最新|NVIDIA独占に挑む各社戦略
- AIはどこへ行く?エージェント・イノベーター・パーソナルAI
- AIが金を掘る時代へ:NVIDIA GTC 2025が示したトークン採掘の未来
更新履歴
※初版以降は、「最新情報にアップデート、読者支援機能の強化」の更新を
日付つきで繰り返し追記します。
- 初版公開








