


※本記事は継続的に最新情報へアップデートしています。
GraphRAGとは、RAGに知識グラフを組み合わせ、文書同士・概念同士の「関係性」を検索に使う設計手法である。
通常のベクトル検索が「意味の近い文書」を探すのに対し、GraphRAGは人物・組織・製品・技術・出来事などのつながりをたどり、複雑な質問や全体像の把握に強みを発揮する。
本記事では、GraphRAGを「高度なRAG」という曖昧な言葉で終わらせず、知識グラフ、Local Search、Global Search、DRIFT Search、LazyGraphRAG、LightRAG、導入判断まで含めて実務目線で整理する。
✅ 先に結論
GraphRAGの本質は、RAGを「文書の類似検索」から知識の関係性をたどる検索へ拡張することです。
- ポイント1:「なぜ同じ文書を検索しても、関係する情報がつながらないのか」。その原因の多くは、文書間の関係性が検索に使われていないことにあります。GraphRAGは、エンティティと関係性を知識グラフとして構造化し、複数文書にまたがる情報をつなげて検索します。
- ポイント2:通常のVector RAGは「近い文書」を探すのが得意で、GraphRAGは「なぜ関係するのか」「全体として何が起きているのか」を扱うのが得意です。
- ポイント3:GraphRAGは万能ではありません。知識グラフ構築のコスト、更新運用、エンティティ抽出の精度を考え、Vector RAGやHybrid Search、LazyGraphRAG系の軽量手法と使い分けるべきです。

何が変わったのか
RAGの主戦場は、単なる文書検索から、知識の構造と関係性を使う検索へ広がっている。
ある製造業の品質部門では、同じような障害が何度も繰り返し発生していました。原因となった部品や工程、影響を受けた顧客、過去の対策会議の議事録はすべて文書として残っているのに、「どの情報とどの情報がどうつながっているのか」を一度に把握できないのです。
Vector RAGを入れると、「この障害の原因は?」という問いには、それらしい対策案が返ってくるようになりました。しかし、「今この障害が影響している顧客はどこか」「どの案件の納期リスクにつながるのか」は、検索するたびに担当者が頭の中でつなぎ直す必要がありました。
ここで効いてくるのが、部品・工程・顧客・案件といったエンティティの関係性をたどれるGraphRAGです。GraphRAGは、文書を探すだけでなく、文書の背後にある知識のつながりを検索対象にします。
これまでのRAGは、文書をチャンクに分け、Embeddingし、ベクトルDBで近い文書を検索する構成が中心でした。この方法は、FAQ、マニュアル、社内規程のように「質問に近い文書が存在する」ケースで非常に有効です。
一方で、現実の業務では、単一の文書だけでは答えられない質問が多くあります。たとえば、「この製品不具合は、どの部品、どの取引先、どの過去案件と関係しているのか」「ある顧客の問い合わせ傾向は、社内のどの部門課題とつながっているのか」といった問いです。
このような問いでは、文書同士の意味的な近さだけでなく、人物、組織、製品、技術、契約、出来事などのエンティティ同士の関係をたどる必要があります。そこで登場するのがGraphRAGです。
RAG全体の基礎は RAG完全ガイド、EmbeddingやベクトルDBの設計は RAG Embedding最適化 と ベクトルDB完全ガイド で扱いました。本記事では、その上にある「知識の関係性を検索に使う設計」に集中します。
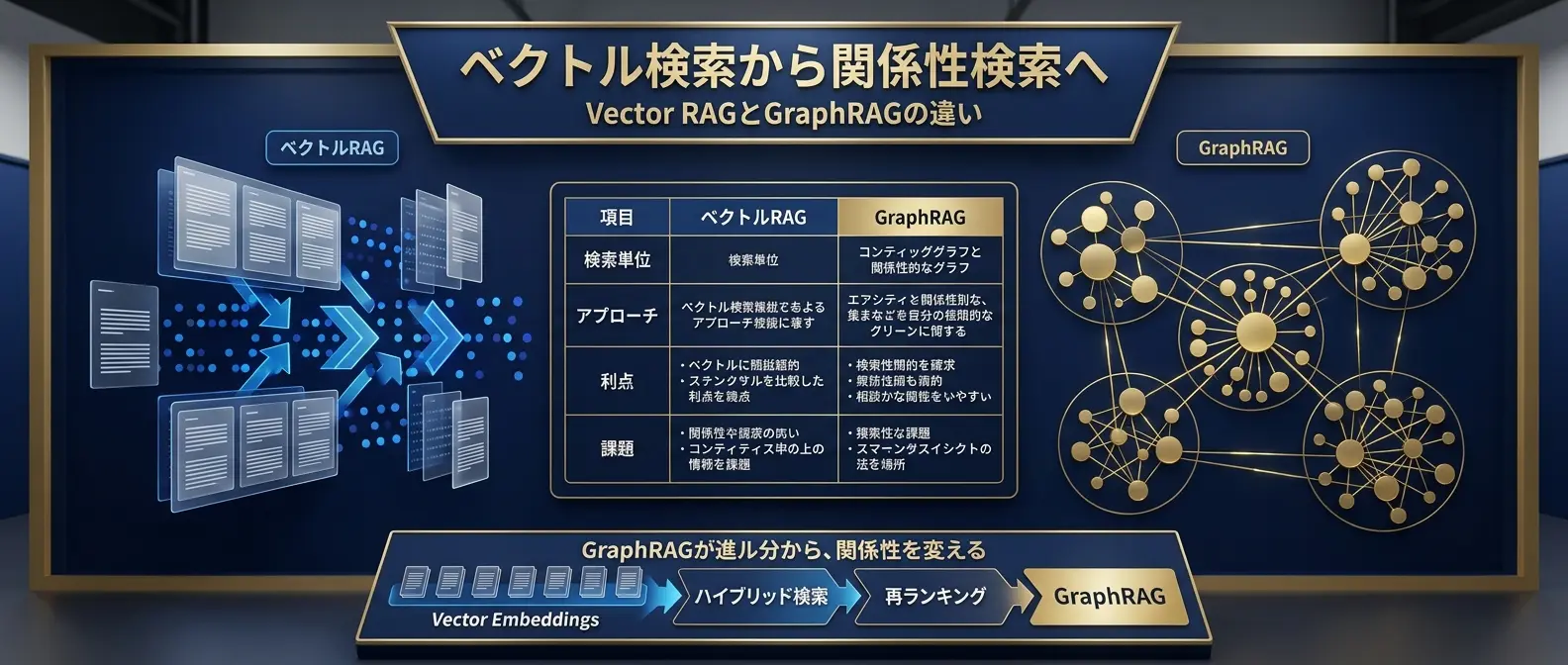
ベクトル検索から関係性検索へ
| 観点 | Vector RAG | GraphRAG |
|---|---|---|
| 検索の単位 | 文書チャンク | エンティティ、関係、コミュニティ、文書チャンク |
| 得意な問い | 質問に近い文書を探す | 複数文書にまたがる関係性や全体像を探る |
| 検索の考え方 | 意味的に近い文書を上位に出す | 関係性をたどり、関連する知識のまとまりを取得する |
| 強み | 実装が比較的簡単で、検索速度とコストを制御しやすい | 複雑な関係、全体傾向、マルチホップな問いに強い |
| 注意点 | 関係性や構造を明示的には扱いにくい | 知識グラフ構築・更新・評価のコストが高い |
GraphRAGは、Vector RAGの置き換えではありません。むしろ、Vector RAG、Hybrid Search、Rerankerの上に、関係性検索のレイヤーを追加する設計と考えると理解しやすくなります。
なぜ今重要なのか
社内文書は、答えをバラバラに持っている。GraphRAGは、その関係をつなぐ地図を作る。
企業内の知識は、きれいなFAQだけで構成されているわけではありません。議事録、設計書、契約書、問い合わせ履歴、障害報告、営業資料、仕様書、メール、チケット、コード、FAQが分散しています。そして、それらの間には多くの関係があります。
たとえば、ある障害報告は、特定の製品、部品、顧客、取引先、過去の設計判断、サポート履歴とつながっています。通常のベクトル検索は、質問に近い文書を探すことはできますが、「どの情報とどの情報がどう関係しているのか」を明示的に扱うのは得意ではありません。
Microsoft ResearchのGraphRAGでは、入力コーパスからエンティティ、関係、重要な主張を抽出し、知識グラフとコミュニティ要約を作り、質問時にそれらをLLMの文脈として利用する考え方が示されています。これは、単なるTop-k検索ではなく、データセット全体の構造を使う発想です。
GraphRAGが重要になるのは、RAGが「文書検索」から「知識構造の活用」へ進む局面です。
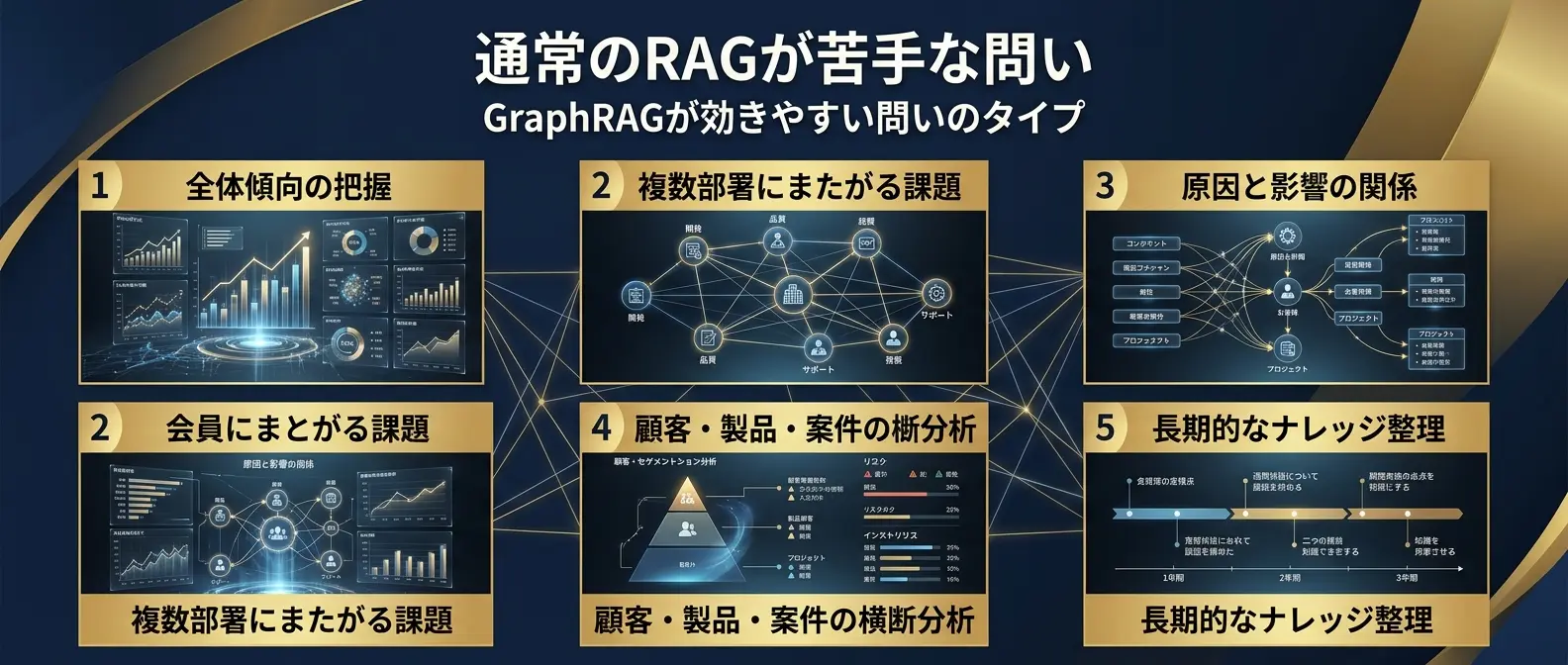
通常のRAGが苦手な問い
| 問いのタイプ | 業務で出やすい質問例 | GraphRAGで補える点 |
|---|---|---|
| 全体傾向の把握 | 「この半年の問い合わせ全体で、どの課題が増えているのか?」 | コミュニティ要約やグラフ構造からテーマを抽出する |
| 複数部署にまたがる課題 | 「この障害は、開発・品質・サポートのどの課題と関係しているのか?」 | 部署・案件・顧客・製品の関係をたどれる |
| 原因と影響の関係 | 「この不具合の原因部品は、どの顧客・案件に影響しているのか?」 | エンティティ間の関係として原因・影響を整理できる |
| 顧客・製品・案件の横断分析 | 「この四半期の解約リスクが高い顧客群はどれか?」 | 共通エンティティや関係を使って文書を結びつける |
| 長期的なナレッジ整理 | 「過去3年の対策会議で、繰り返し議論されている論点は何か?」 | 知識グラフとして更新・可視化・再利用しやすい |
ただし、GraphRAGを使えば必ず精度が上がるわけではありません。文書量が少ない、関係性が単純、質問がFAQ中心の場合は、通常のVector RAGやHybrid Searchで十分なことも多いです。
どう捉えるべきか

GraphRAGは、エンティティ、関係、コミュニティ要約を使って、知識の地図から回答根拠を探す仕組みである。
GraphRAGを理解するうえで重要なのは、「グラフ」とは図のことではなく、ノードとエッジで表される関係構造だという点です。ノードは人物、組織、製品、技術、法律、出来事などのエンティティを表し、エッジは「所属する」「利用する」「影響する」「原因である」「契約している」といった関係を表します。
GraphRAGでは、文書からエンティティと関係を抽出し、知識グラフを作ります。そのうえで、質問に応じて関連するノードや近傍関係を取得したり、グラフ上のコミュニティを要約したりして、LLMに渡す文脈を作ります。
GraphRAGを構成する4つの要素
| 要素 | 意味 | 実務での例 |
|---|---|---|
| Entity | 知識グラフ上のノード | 製品名、顧客名、部署名、技術名、規程名 |
| Relationship | Entity同士のつながり | 顧客Aが製品Bを利用、部品Cが障害Dに関係 |
| Text Unit | 文書を分析するための単位 | 段落、チャンク、見出し単位の本文 |
| Community Summary | 関連するEntity群をまとめた要約 | ある製品群の主要課題、顧客群の問い合わせ傾向 |
重要なのは、GraphRAGが「文書を検索するだけ」ではなく、文書から抽出した関係構造を使って検索する点です。これにより、単純なキーワード一致やベクトル類似度では見えにくい情報のつながりを扱えます。
Local SearchとGlobal Search
Microsoft GraphRAGでは、質問の種類に応じて複数の検索モードが整理されています。特定の人物・製品・案件などに関する質問では、対象エンティティの近傍をたどるLocal Searchが有効です。一方、データセット全体のテーマや傾向を聞く質問では、コミュニティ要約を使うGlobal Searchが有効です。
| 検索モード | 向いている問い | 取得する情報 |
|---|---|---|
| Local Search | 特定の顧客、製品、案件、人物について知りたい | 対象エンティティの近傍ノード、関係、関連文書 |
| Global Search | データ全体のテーマ、傾向、リスク、論点を知りたい | コミュニティ要約、関連する知識群、全体的なパターン |
| DRIFT Search (Dynamic Reasoning and Inference with Flexible Traversal) |
特定エンティティについて深掘りしながら、コミュニティ情報も加えた広い文脈が必要 | Local SearchにコミュニティInsightを組み込んだ拡張文脈。Local SearchとGlobal Searchのコスト・品質バランスを取る |
| Basic Search | 通常のTop-k検索で十分な質問 | 質問に近い文書チャンク |
この切り分けは実務でも重要です。すべての質問をGraphRAGで処理する必要はありません。FAQのような質問はBasic SearchやHybrid Searchでよく、関係性や全体像が必要な質問だけGraphRAGに渡す構成が現実的です。
実務ではどう判断するか

GraphRAGは、関係性・全体像・マルチホップ推論が重要な領域で使うべきである。
GraphRAGは強力ですが、導入コストも高い設計です。エンティティ抽出、関係抽出、グラフ構築、コミュニティ要約、更新処理、評価指標の整備が必要になります。そのため、「高度そうだから使う」のではなく、通常のRAGでは解けない問いがあるかを先に確認すべきです。
判断の第一歩は、質問の性質を見ることです。単一文書に答えがある質問なのか、複数文書を横断する必要があるのか、エンティティ同士の関係をたどる必要があるのかで、採るべき構成は変わります。
Vector RAG / Hybrid Search / GraphRAGの使い分け

| 方式 | 主な用途 | 向いている質問 | 注意点 |
|---|---|---|---|
| Vector RAG | 意味的に近い文書を検索する | 「この制度の申請方法は?」「このエラーの対処法は?」 | 固有名詞や関係性の扱いは弱い場合がある |
| Hybrid Search | ベクトル検索とBM25を組み合わせる | 「型番A-100の仕様は?」「規程第12条の内容は?」 | RRFやRerankerなど検索統合の設計が必要 |
| Agentic RAG | 検索、評価、再検索をエージェント的に制御する | 「根拠が不足していれば再検索して回答して」 | 制御が複雑になり、評価と監視が重要になる |
| GraphRAG | 知識の関係性や全体像を使って検索する | 「この課題に関係する部署・製品・顧客を整理して」 | グラフ構築・更新・評価のコストが高い |
| LazyGraphRAG | 事前のコミュニティ要約生成を抑え、クエリ時に必要な探索を行う軽量なGraphRAG系アプローチ | 大規模データセットで、全体像の問いにも答えたいが、フルGraphRAGの事前インデックスコストを抑えたい場合 | コストは抑えやすい一方、クエリ時の処理設計、品質評価、応答時間の確認が重要 |
あなたのチームが今抱えている検索課題は、どの行に当てはまるでしょうか。FAQならVector RAGで十分かもしれません。しかし、「なぜこの顧客は解約したのか」「この障害はどの案件に波及するのか」という問いが出てきているなら、次のGraphRAGパイプラインが現実味を帯びてきます。
GraphRAGは、Vector RAGやHybrid Searchを置き換えるものではなく、検索方式の選択肢を増やすものです。実務では、まずVector RAGとHybrid Searchで基礎を固め、関係性の検索が必要になった段階でGraphRAGを検討するのが安全です。
小さく試すなら:1スプリントPoCの進め方
GraphRAG系の技術は、最初から全社ナレッジに適用するより、関係性が効きやすい1領域に絞って試す方が安全です。たとえば、障害報告、問い合わせログ、対策会議の議事録を対象に、既存のVector RAGとLazyGraphRAGまたはLightRAGで同じ質問を投げ、差を確認します。
🧪 1スプリントPoCの進め方
- 対象ドメインを「障害報告+問い合わせログ+議事録」など、関係性が効きやすい1領域に絞る。
- 5〜10個の実務質問を用意し、Vector RAG、Hybrid Search、GraphRAG系手法で回答を比較する。
- 回答の網羅性、関係性の説明力、根拠の追跡性、インデックス時間、クエリ時間を確認する。
このPoCを1スプリントで回すと、「どの問いにGraphRAG系が本当に効くのか」を机上ではなく手触りで判断できます。ここで価値が見えなければ、無理にGraphRAGへ進まず、Hybrid SearchやRerankerの改善を先に行う判断もできます。
GraphRAGの基本パイプライン

| 工程 | やること | 実務上の注意点 |
|---|---|---|
| 文書分割 | 文書を分析単位へ分ける | チャンク単位が粗すぎると関係抽出がぶれる |
| Entity抽出 | 人物、組織、製品、技術、出来事を抽出する | 表記ゆれ、略称、同名異義語を処理する |
| Relationship抽出 | Entity同士の関係を抽出する | 関係の種類を増やしすぎると運用が難しくなる |
| Graph構築 | ノードとエッジとして保存する | グラフDB、検索基盤、Vector DBとの連携を設計する |
| Community検出 | 関連するEntity群をクラスタとしてまとめる | 大規模データでは計算コストと更新頻度に注意する |
| 要約生成 | コミュニティやサブグラフを要約する | 要約の根拠、更新、評価を管理する |
| 検索・生成 | 質問に応じてグラフと文書を取得し回答する | Local / Global / DRIFT / Basicを質問タイプで切り替える |
このパイプラインを見ると、GraphRAGは単なる検索技術ではなく、ナレッジ整備のプロセスでもあることが分かります。特にEntity抽出とRelationship抽出の品質が、最終的な回答品質に大きく影響します。
GraphRAGが向く領域
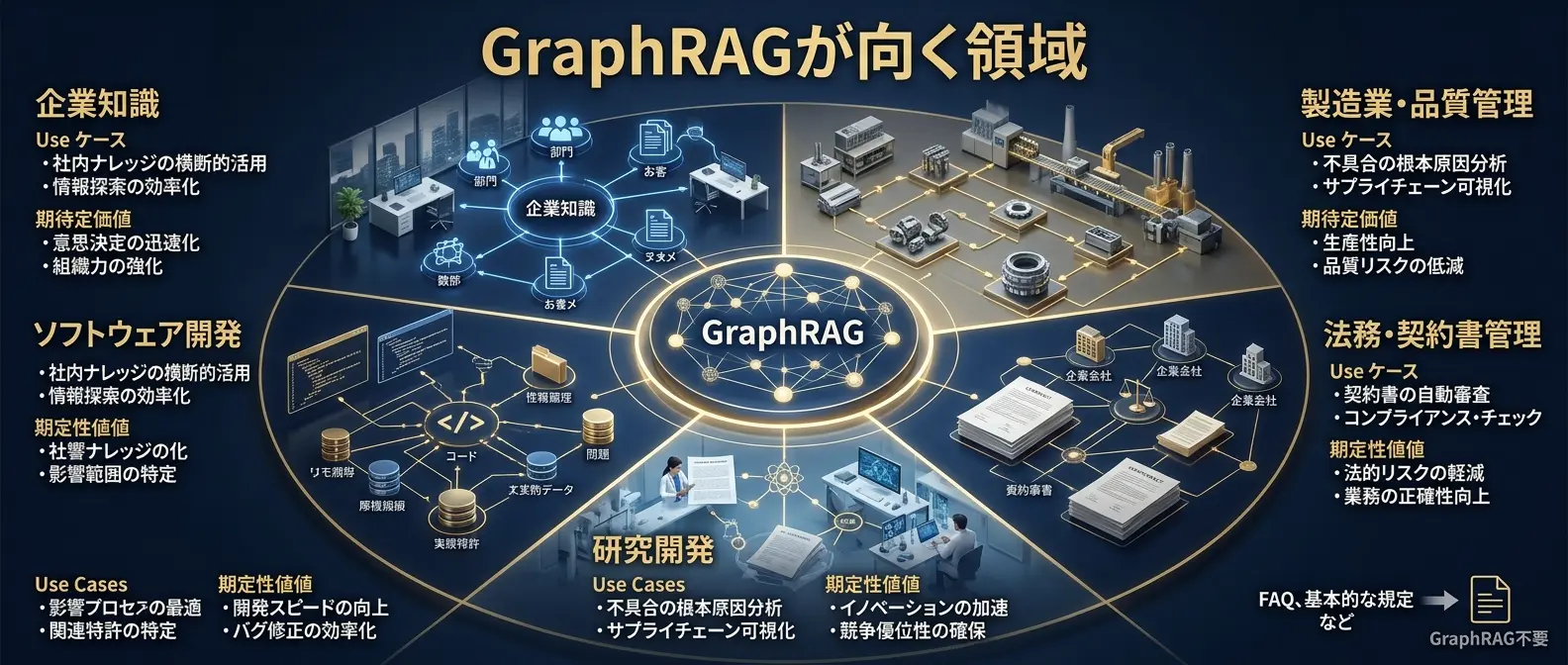
GraphRAGが向くのは、情報同士の関係が価値を持つ領域です。企業ナレッジ、法務、製造、研究開発、サプライチェーン、コードベース分析などでは、単一文書の検索よりも、複数情報の関係を整理することが重要になります。
| 領域 | 使いどころ | 期待できる価値 |
|---|---|---|
| 企業ナレッジ | 部署、顧客、案件、文書の関係を整理する | 暗黙知の可視化、問い合わせ対応、引き継ぎ支援 |
| 製造・品質管理 | 部品、工程、障害、サプライヤーの関係をたどる | 原因分析、影響範囲の把握、再発防止 |
| 法務・契約 | 契約条項、関連法令、取引先、案件の関係を整理する | 条項確認、リスク把握、関連文書探索 |
| 研究開発 | 論文、技術、研究者、実験結果の関係を整理する | 研究テーマ探索、類似研究把握、技術ロードマップ |
| ソフトウェア開発 | コード、仕様、Issue、依存関係をつなげる | 影響分析、障害調査、仕様理解 |
一方で、FAQ検索や単純な社内規程検索などでは、GraphRAGは過剰な場合があります。その場合は、チャンキング、Embedding、Vector DB、Hybrid Search、Rerankerを丁寧に設計する方が、コスト効率よく成果につながります。
一次情報からどこまで言えるか
一次情報から言えるのは、GraphRAGは構造化検索に強い一方で、構築コストと運用設計が重要ということである。
Microsoft Researchは、GraphRAGをテキスト抽出、ネットワーク分析、LLMによるプロンプト・要約を組み合わせるエンドツーエンドの仕組みとして説明しています。公式ドキュメントでは、入力文書からEntity、Relationship、Key Claimを抽出し、階層的なクラスタリングとコミュニティ要約を作る流れが示されています。
また、Microsoft GraphRAGのドキュメントでは、Baseline RAGが「点と点をつなぐ」ような複雑な問いや、データセット全体を俯瞰する問いに弱い場面があると説明されています。その対策として、Local Search、Global Search、DRIFT Search、Basic Searchを使い分ける考え方が提示されています。
DRIFT Searchは、Dynamic Reasoning and Inference with Flexible Traversalの略で、Global SearchとLocal Searchの特徴を組み合わせ、計算コストと回答品質のバランスを取る検索方式として説明されています。特定のエンティティを深掘りしながら、コミュニティ情報も取り入れる点が特徴です。
Microsoft Researchは2024年11月にLazyGraphRAGを発表し、事前のコミュニティ要約生成を行わず、LLM利用をクエリ時まで遅延させることで、フルGraphRAGの事前インデックスコストを大きく下げる方向性を示しました。
特に注目すべきはコストです。Microsoft Researchの公式ブログでは、LazyGraphRAGのインデックスコストはVector RAGと同等で、フルGraphRAGの0.1%に相当すると説明されています。また、条件によってはGraphRAG Global Searchと同等品質を、700分の1未満のクエリコストで実現するケースも示されています。これは、「GraphRAGは重すぎる」という実務上の懸念に対する重要な進展です。
2025年6月の編集者注記では、GraphRAGとLazyGraphRAGの技術がMicrosoft Discoveryで利用可能になり、Azure Localのパブリックプレビューにも統合されたことが示されています。これにより、GraphRAG系の技術は研究段階の概念から、エンタープライズ実装を意識した選択肢へ近づいています。
GraphRAGの論文では、全体像を問うようなGlobal Questionに対して、通常のTop-k型RAGでは十分に答えにくい課題が示されています。GraphRAGは、知識グラフとコミュニティ要約を使い、データセット全体のテーマや多様な観点を回答に反映しようとするアプローチです。
LightRAGでは、グラフ構造とベクトル表現を組み合わせ、低レベル検索と高レベル検索の二段階で情報を取得する考え方が示されています。Microsoft GraphRAGのようなフルスケールなグラフ構築に比べ、より軽量・低レイテンシでGraphRAG的なメリットを取りにいく実装と位置づけると、技術選定のイメージが掴みやすくなります。
一次情報から見える実務上の結論は、GraphRAGを万能な高精度RAGとして扱うのではなく、関係性検索・全体像把握・複雑な知識整理に向く選択肢として使い分けることです。
よくある失敗:「GraphRAGを入れれば賢くなる」という幻想
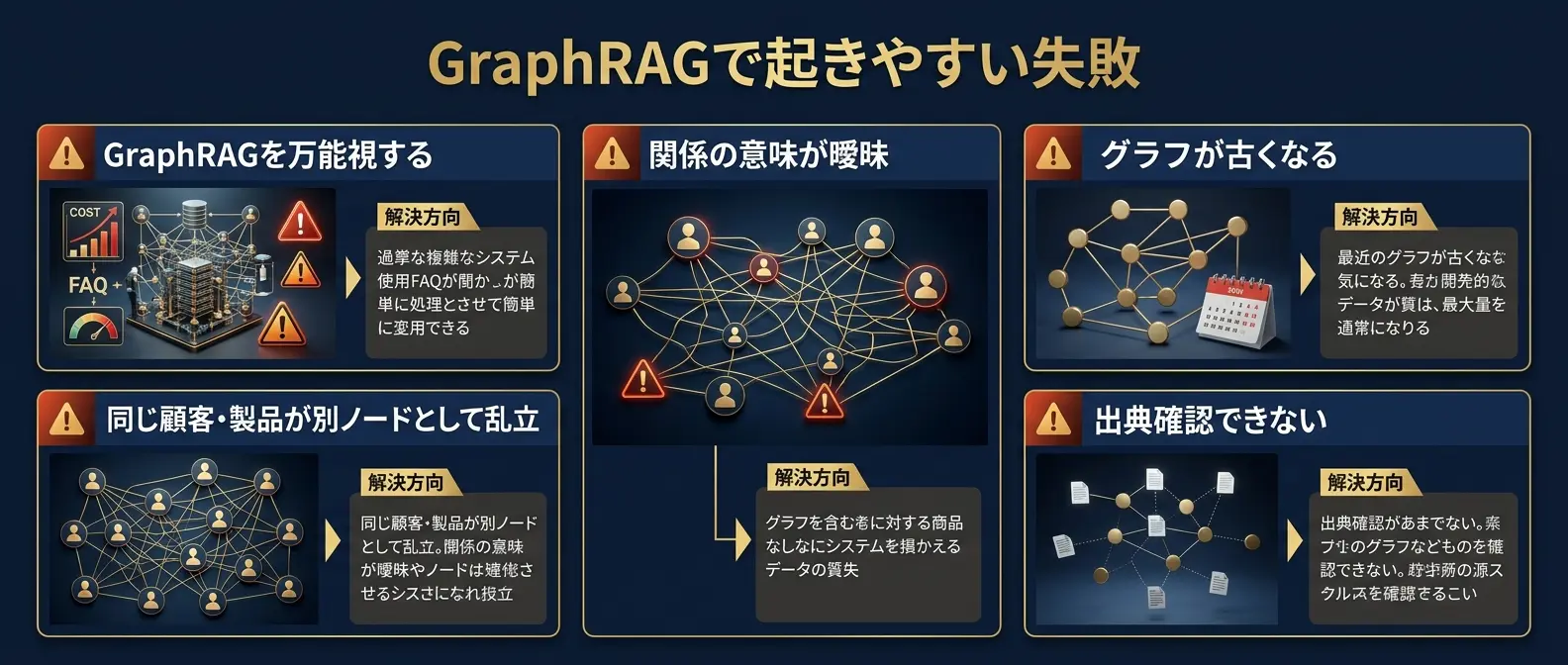
GraphRAGの失敗は、技術選定よりも、グラフ設計と更新運用を軽く見たときに起きやすい。
「GraphRAGを入れれば解決する」——この一言が、プロジェクトを複雑化させる出発点になることがあります。実際には、Entity定義や更新運用を軽く見たプロジェクトほど、「前より複雑で説明しにくい検索基盤が増えただけ」という状態に陥りがちです。
GraphRAGは魅力的な技術ですが、「これさえ入れれば一気に賢くなる」という期待が先行すると、多くの場合は失望に終わります。知識グラフの設計や更新運用を軽く見ると、通常のRAGより複雑で扱いにくいシステムになります。
| 失敗 | なぜ問題か | 回避策 |
|---|---|---|
| GraphRAGを万能視する | 単純なFAQにも過剰な構成を使い、コストが増える | Vector RAG / Hybrid Searchで十分な質問を切り分ける |
| Entity定義が曖昧 | 同じ顧客・製品・案件が別ノードとして乱立する | 表記ゆれ、同義語、ID体系を先に決める |
| Relationshipを増やしすぎる | 関係の意味が曖昧になり、検索品質が落ちる | 最初は重要な関係タイプに絞る |
| 更新運用を設計しない | グラフが古くなり、回答が現状とズレる | 差分更新、再要約、版管理を運用に組み込む |
| 根拠文書への戻り道がない | グラフ上の関係だけが残り、出典確認できない | EntityとRelationshipを元文書・ページ・チャンクに紐づける |
特に重要なのは、GraphRAGでも出典と根拠が必要だという点です。知識グラフ上で関係が見つかっても、その関係がどの文書のどの記述から抽出されたのかを確認できなければ、企業利用では信頼されません。
まとめ
GraphRAGは、RAGを文書検索から知識構造の活用へ拡張する設計手法である。
GraphRAGは、RAGに知識グラフを組み合わせ、エンティティと関係性を検索に使う設計手法です。通常のVector RAGが意味的に近い文書を探すのに対し、GraphRAGは情報同士のつながりをたどり、複数文書にまたがる問いや全体像の把握を支援します。
ただし、GraphRAGは万能ではありません。グラフ構築、Entity抽出、Relationship抽出、コミュニティ要約、更新運用にはコストがかかります。FAQや単純な文書検索では、Vector RAGやHybrid Searchの方がシンプルで効果的な場合もあります。
GraphRAGを導入すべきなのは、検索したい対象が「文書」ではなく「知識の関係性」になったときです。
冒頭の製造業の品質部門に戻ると、最初からGraphRAGを全面導入する必要はありません。まずは障害報告・問い合わせログ・議事録を対象にVector RAGで一次対応を整え、そのうえで「どの障害が、どの部品・工程・顧客・案件とつながっているのか」という問いに対して、GraphRAGやLazyGraphRAGを小さく試すのが現実的です。
うまく設計できれば、品質会議で担当者が過去文書を手作業で探し回る時間を減らし、「どの設計判断を変えるべきか」「どの顧客へ先に説明すべきか」という判断に時間を使えるようになります。
自社の問い合わせログ、障害報告、契約書、議事録を眺めたとき、「単一文書ではなく、関係性をたどらないと答えが出ない問い」がどれくらいあるかを数えてみることが、GraphRAG導入可否を判断する最初の一歩になります。
📋 明日から使える判断チェック(3ステップ)
- 自社のRAGで「複数文書をまたがないと答えられない問い」を5つ書き出す。
- そのうち「エンティティ同士の関係」が必要な問いを選別する。
- 1〜2問でも該当すればGraphRAG系の小規模PoCを検討し、0問ならHybrid Searchの精度改善を先行する。
Key Takeaways(持ち帰りポイント)
- GraphRAGは、知識グラフを使ってエンティティ同士の関係性を検索に活用するRAG設計である。
- 通常のVector RAGは近い文書検索に強く、GraphRAGは全体像・関係性・マルチホップな問いに強い。
- Local Search、Global Search、DRIFT Search、Community Summaryを使い分けることで、具体的な問いと全体傾向の問いを扱いやすくなる。
- LazyGraphRAGやLightRAGの登場により、GraphRAG系の設計はフルスケールなグラフ構築だけでなく、軽量・低コストな方向にも広がっている。
- GraphRAGは導入コストが高いため、Vector RAGやHybrid Searchで十分な領域と切り分けて使うべきである。
専門用語まとめ
- GraphRAG
- RAGに知識グラフを組み合わせ、エンティティと関係性を検索・生成に活用する設計手法。
- 知識グラフ
- 人物、組織、製品、技術などのエンティティと、それらの関係をノードとエッジで表した構造。
- Entity
- 知識グラフ上のノード。顧客名、製品名、部署名、技術名、文書名などを指す。
- Relationship
- Entity同士の関係。所属、利用、原因、影響、契約、依存などを表す。
- Community Summary
- 関連するEntity群をコミュニティとしてまとめ、その内容や傾向を要約したもの。
- Local Search
- 特定のEntityを起点に、その近傍ノードや関係をたどって回答根拠を探す検索方式。
- Global Search
- データセット全体のテーマや傾向を把握するため、コミュニティ要約などを使って検索する方式。
- LazyGraphRAG
- フルGraphRAGのように事前に大量のコミュニティ要約を作るのではなく、クエリ時に必要な探索を行う軽量なGraphRAG系アプローチ。
参考文献 / 出典
一次情報 / 公式ドキュメント
- Microsoft GraphRAG Documentation
- Microsoft GraphRAG Documentation – DRIFT Search
- Microsoft Research – Project GraphRAG
- Microsoft GraphRAG – GitHub
- Microsoft Research Blog – LazyGraphRAG: Setting a new standard for quality and cost
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization – arXiv
- LightRAG: Simple and Fast Retrieval-Augmented Generation – arXiv
- LightRAG – Simple and Fast Retrieval-Augmented Generation
- LightRAG – GitHub
- IBM Think – What is GraphRAG?
次に読むならこの3本
補足Q&A
Q1.
GraphRAGとは一言で何ですか?
A1.
RAGに知識グラフを組み合わせ、文書や概念の関係性を使って検索・生成する設計手法です。
通常のRAGが文書チャンクの類似度を中心に検索するのに対し、GraphRAGはエンティティ同士の関係やコミュニティ要約も使います。
Q2.
GraphRAGはVector RAGより常に優れていますか?
A2.
いいえ。質問の種類によって使い分けるべきです。
FAQや単純な文書検索ではVector RAGやHybrid Searchの方がシンプルで有効です。GraphRAGは、複数文書にまたがる関係性や全体像の把握が必要な場合に向いています。
Q3.
GraphRAG導入で一番難しい点は何ですか?
A3.
知識グラフの構築と更新運用です。
EntityやRelationshipの抽出、表記ゆれの統合、元文書との紐づけ、コミュニティ要約の更新などを設計しないと、検索品質や信頼性が安定しません。
Q4.
GraphRAGはどの業務に向いていますか?
A4.
企業ナレッジ、製造・品質管理、法務、研究開発、ソフトウェア開発など、関係性の把握が重要な業務に向いています。
顧客、製品、部署、案件、契約、障害、仕様などの関係をたどる必要がある場合、GraphRAGの価値が出やすくなります。
Q5.
GraphRAGとグラフDBや既存ナレッジグラフはどう関係しますか?
A5.
GraphRAGは検索・生成の設計であり、グラフDBや既存ナレッジグラフはその基盤や入力になり得ます。
Neo4j、Memgraph、既存の社内ナレッジグラフなどを持っている場合、それらをGraphRAGのEntityやRelationshipの基盤として活用できます。ただし、LLMに渡す文脈、出典、更新運用、評価設計は別途必要です。
更新履歴
- 2026年5月21日:v11.3に適合し、Microsoft GraphRAG、LazyGraphRAG、LightRAG、Local / Global / DRIFT Search、Community Summary、Vector RAGとの使い分け、1スプリントPoC、導入判断チェックを反映して全面再構成。
- 2024年10月:初版公開。








