


※本記事は継続的に最新情報へアップデートしています。
2026年のRAGにおけるベクトルDBは、単なるベクトルの保存先ではなく、検索精度・権限制御・運用性を左右する検索基盤である。
Embeddingで作った意味ベクトルを、どのDBに載せ、どの検索方式で取り出し、どの段階でRerankerに渡すかによって、同じ文書群でも回答品質は大きく変わる。
本記事では、ベクトルDBを製品比較だけでなく、Hybrid Search、RRF、メタデータフィルタ、Reranker、エンタープライズ運用まで含むRAG検索基盤として整理する。
✅ 先に結論
ベクトルDB選定の本質は、人気製品を選ぶことではありません。自社のRAGで必要な検索パイプラインを、どの基盤で安全かつ継続的に運用するかを決めることです。
- ポイント1:ベクトルDBは、Embeddingされた文書チャンクを高速に検索するための基盤です。ただし、ベクトル検索だけでは固有名詞・型番・権限・版数に弱い場面があります。
- ポイント2:本番RAGでは、ベクトル検索、BM25、sparse vector、メタデータフィルタ、RRF、Rerankerを組み合わせたHybrid Search設計が重要になります。
- ポイント3:PoCでは手軽さ、本番ではSLA・セキュリティ・監査・スケール・運用体制を重視して、専用型DBと既存DB拡張型を使い分けます。

何が変わったのか
ベクトルDBは、意味検索の保存先から、RAG検索パイプラインを支える運用基盤へ変化している。
以前のベクトルDB選定では、「どのDBが速いか」「どのDBが安いか」「無料枠があるか」といった比較が中心でした。もちろん、速度やコストは重要です。しかし、主要ベンダーがHybrid Search、RRF、多段検索、Reranker連携を前提にした設計を公式に打ち出している2026年のRAGでは、それだけでは判断できません。
本番RAGでは、文書をただベクトル化して保存するだけでは不十分です。ユーザーの質問に対して、正しい文書を、正しい権限で、正しい版数から、十分な速度で取り出し、必要に応じてRerankerで再順位付けし、LLMに渡す必要があります。
つまり、ベクトルDBは単なる「高速な意味検索エンジン」ではなく、RAGの検索品質と運用品質を同時に支える基盤になっています。
前工程として、文書をどう切るかは RAGチャンキング最適化、そのチャンクをどう意味ベクトル化するかは RAG Embedding最適化 で扱いました。本記事では、そのベクトルをどう検索基盤に載せるかに集中します。
製品比較から検索基盤設計へ
| 観点 | 従来の見方 | 2026年版の実務設計 |
|---|---|---|
| 主な関心 | どのベクトルDBが速いか | RAG検索パイプライン全体をどう安定運用するか |
| 検索方式 | ベクトル検索中心 | ベクトル検索、BM25、Hybrid Search、RRF、Rerankerを組み合わせる |
| データ管理 | ベクトルとIDを保存する | 出典、版数、権限、部署、日付、親子関係などのメタデータも設計する |
| 選定基準 | 価格、無料枠、ベンチマーク | PoCから本番移行、SLA、セキュリティ、監査、運用体制まで見る |
| 評価 | 検索速度やQPS | Recall@k、MRR、NDCG、回答品質、レイテンシ、運用コストを合わせて見る |
この変化を押さえると、ベクトルDB記事の役割は明確です。製品名を覚えることではなく、RAG検索基盤として何を設計すべきかを理解することが目的です。
なぜ今重要なのか

ベクトル検索だけでは、固有名詞、型番、権限、版数、監査に弱い場面がある。
ベクトル検索は、言い換えや意味の近さに強い検索です。「交通費の申請方法」と「経費精算の手順」のように、表現が違っても意味が近い文書を見つけられます。これはRAGにとって大きな価値です。
一方で、ベクトル検索だけに依存すると、実務で困る場面があります。たとえば、製品型番、契約番号、法令番号、社内略称、顧客名、案件コードなどは、意味の近さよりも文字列の一致が重要です。また、社内文書では「最新版だけを検索する」「特定部署の文書だけ検索する」「閲覧権限のある文書だけ返す」といった制御も欠かせません。
ある社内FAQボットでは、ベクトル検索だけでPoCを始めたところ、一般的な問い合わせには答えられたものの、製品型番や社内規程番号を含む質問では誤った候補が上位に出ました。改善に効いたのは、モデルを変えることだけではなく、BM25とのHybrid Search、部署・版数・権限メタデータの設計、Rerankerの配置でした。
本番RAGの品質は、ベクトルDB単体の性能ではなく、検索基盤全体の設計で決まります。
ベクトルDB選定で起きやすい失敗
| 失敗パターン | 症状 | 対策 |
|---|---|---|
| ベクトル検索だけに依存 | 型番・法令番号・固有名詞で外す | BM25や全文検索を組み合わせる |
| メタデータ設計が弱い | 部署、権限、版数、日付で絞れない | ETL段階でsource、version、access_roleなどを付与する |
| 価格表だけで選ぶ | 本番化後に運用・監視・障害対応で詰まる | TCO、SLA、サポート、運用体制まで見る |
| PoC環境のまま本番化 | データ増加や同時アクセスで遅くなる | 移行パス、スケール方式、バックアップを先に決める |
| Rerankerに渡しすぎる | コストとレイテンシが膨らむ | Vector DB側で候補を20〜100件程度に絞る |
どう捉えるべきか
ベクトルDBは、ANN検索、メタデータ、Hybrid Search、Reranker接続を担う検索基盤である。
ベクトルDBとは、Embeddingされたテキストや画像などのベクトルを保存し、質問ベクトルに近いデータを高速に探すためのデータベースです。RAGでは、文書チャンクをEmbeddingし、そのベクトルをベクトルDBに格納します。ユーザーが質問すると、質問もEmbeddingされ、意味的に近いチャンクを検索します。
この「近いものを探す」処理は、ANN、つまり近似最近傍探索によって高速化されます。すべてのベクトルを毎回比較するのではなく、HNSWやIVFなどのインデックスを使い、十分に近い候補を短時間で見つけます。
ただし、本番RAGでは「近いベクトルを探す」だけでは足りません。メタデータフィルタ、Hybrid Search、RRF、Reranker、アクセス制御、バックアップ、監視まで含めて設計する必要があります。
RAG検索パイプラインでの位置づけ

| 工程 | 役割 | 主な論点 |
|---|---|---|
| チャンキング | 文書を検索可能な知識単位へ分ける | 構造認識、可変長、親子チャンク、出典 |
| Embedding | チャンクと質問を意味ベクトルへ変換する | モデル選定、次元数、量子化、日本語適性 |
| Vector DB | ベクトルとメタデータを保存し、高速検索する | ANN、HNSW、フィルタ、スケール、SLA |
| Hybrid Search | ベクトル検索とキーワード検索を組み合わせる | BM25、Sparse Vector、RRF、重み付け |
| Reranker | 候補を質問との関連度で精密に並べ替える | 候補件数、コスト、レイテンシ、精度 |
| LLM生成 | 取得根拠をもとに回答を作る | 引用、根拠忠実性、プロンプト、ガードレール |
Embedding記事では、Rerankerを「Embedding検索の弱点を補う装置」として扱いました。本記事では、Rerankerを検索パイプラインの後段に置く部品として扱います。Vector DBは候補を高速に広く拾い、Rerankerはその候補を少数に絞って精密に並べ替える、という役割分担です。
メタデータは本番RAGの生命線
ベクトルDBに保存するのは、ベクトルだけではありません。RAGで使うなら、チャンク本文、出典、ページ番号、見出し、更新日、文書種別、権限、部署、版数などのメタデータが必要です。
| メタデータ | 目的 | 例 |
|---|---|---|
| source | 引用元の表示 | URL、ファイル名、文書ID |
| page_number | PDFや規程の根拠確認 | p.12、p.45 |
| section | 見出し階層の復元 | 第3章、料金規程、FAQ |
| updated_at / version | 最新版の優先 | 2026-05-21、v3.1 |
| access_role | 権限制御 | public、internal、management |
| tenant_id | 顧客・部署ごとの分離 | customer-a、sales、hr |
メタデータが弱いRAGは、PoCでは動いても本番でつまずきます。特に社内文書検索では、「回答できるか」だけでなく「回答してよいか」が重要です。
実務ではどう判断するか

ベクトルDBは、データ規模、運用体制、既存資産、Hybrid Search要件で選ぶべきである。
ベクトルDBには、専用型と既存DB拡張型があります。専用型はベクトル検索に強く、スケールやRAG機能に優れます。既存DB拡張型は、既存システムとの統合や構造化データとの一体管理に強みがあります。
最初から「この製品が最強」と決めるのではなく、自社のフェーズに合わせて選ぶことが重要です。PoCでは手軽さ、本番ではSLA・セキュリティ・運用性、エンタープライズでは監査・権限・マルチテナントを重視します。
主要ベクトルDBの使い分け
| 選択肢 | 特徴 | 向いているケース | 注意点 |
|---|---|---|---|
| Pinecone | マネージド型のベクトルDB。運用負荷を抑えつつ、dense vectorとsparse vectorを使ったHybrid Searchを構成しやすい | 短期間で本番品質のRAGを立ち上げたい、インフラ運用を最小化したい | マネージド費用とベンダーロックインを評価する |
| Weaviate | Vector SearchとBM25Fを組み合わせたHybrid Searchを標準サポートし、融合方式や重みを調整できる | RAG機能、Hybrid Search、OSSとCloudの両方を検討したい | スキーマ設計、モジュール構成、運用形態を事前に決める |
| Qdrant | Rust製で高速・軽量。dense / sparse / multi-vectorをRRFやDBSFで統合するHybrid / Multi-stage Queryに対応 | 高性能なフィルタ付き検索、OSS/Cloud併用、PoCから本番への移行 | 周辺検索エンジンやRerankerとの組み合わせ設計が重要 |
| Milvus / Zilliz | 大規模ベクトル検索に強いOSS系基盤。HNSW、IVF、PQなど多様なインデックスを扱える | 数千万〜数億規模のベクトル、研究・大規模AI基盤、マルチモーダル検索 | セルフホストでは運用難易度が高く、分散構成の知識が必要 |
| pgvector | PostgreSQLでベクトル検索を扱える拡張。構造化データ、トランザクション、SQL、メタデータとベクトルを同じDBで一体管理でき、sparse vectorにも対応している | 既存PostgreSQL資産を活かしたい、小〜中規模RAG、業務DB連携、構造化データとベクトル検索を同じ基盤で扱いたいケース | 数千万規模以上、低レイテンシ、大量更新、高い同時実行が必要な場合は専用ベクトルDBと比較する。HNSWは高速だが、インデックス構築時間とメモリ使用量に注意する |
| OpenSearch / Elasticsearch系 | 全文検索、ログ検索、BM25、ベクトル検索を同じ検索基盤で扱いやすい | 既に検索基盤がある、型番・固有名詞・ログ・文書検索を統合したい | ベクトル検索専用DBとはチューニング観点が異なる |
| Azure AI Search | 全文検索、Vector Search、Hybrid Search、RRF、Semantic Rankerなどを統合しやすい | Azure基盤、Microsoft 365や社内文書検索、エンタープライズRAG | Azure前提の設計になるため、既存クラウド戦略と合わせて判断する |
※ ChromaはPoC・ローカル開発で広く使われるOSSですが、本番スケールや運用要件では別基盤への移行を検討するケースが多いため、上表の本番比較からは除外しています。
上表はランキングではありません。RAG検索基盤では、性能よりも「どの検索パイプラインを組みたいか」が先です。ベクトル検索だけでよいのか、BM25を混ぜるのか、Rerankerを置くのか、権限や版数で絞るのかによって、選ぶべき基盤は変わります。
目的別の選定フロー
| 状況 | 第一候補 | 判断ポイント |
|---|---|---|
| まずRAG PoCを早く試したい | Qdrant Cloud、Pinecone、Chroma、pgvector | セットアップの速さ、無料枠、移行しやすさ。ChromaはPoC特化で、本番移行時は別基盤も含めて検討する |
| 本番RAGを短期間で立ち上げたい | Pinecone、Weaviate Cloud、Qdrant Cloud、Azure AI Search | SLA、監視、バックアップ、運用負荷 |
| 全文検索と意味検索を組み合わせたい | Weaviate、OpenSearch、Elasticsearch、Azure AI Search、Qdrant | BM25、Hybrid Search、RRF、Reranker連携 |
| 既存PostgreSQLを活かしたい | pgvector | データ量、レイテンシ、既存トランザクションとの統合 |
| 大規模マルチモーダル検索を扱いたい | Milvus / Zilliz、Pinecone、Weaviate、Qdrant | スケール、インデックス方式、量子化、運用体制 |
| Azure中心のエンタープライズ環境 | Azure AI Search | Microsoft基盤、認証、Semantic Ranker、運用統合 |
Hybrid SearchとRRF

Hybrid Searchとは、ベクトル検索とキーワード検索を組み合わせる検索方式です。ベクトル検索は意味の近さに強く、BM25などのキーワード検索は固有名詞、型番、法令番号、エラーメッセージの一致に強いです。
両者のスコアは単位が異なるため、そのまま足し合わせるのは危険です。そこで、順位を使って結果を統合するRRF(Reciprocal Rank Fusion)がよく使われます。RRFは、複数の検索結果で上位に出る文書を優先する仕組みです。実際にAzure AI SearchやQdrantでは、Hybrid SearchやMulti-stage Queryの結果統合にこの方式が使われています。
![\[RRF\_Score(d) = \sum_{m \in M} \frac{1}{k + r_m(d)}\]](https://arpable.com/wp-content/ql-cache/quicklatex.com-309973a9b8af8a1efab8de5ab97fef1d_l3.png "Rendered by QuickLaTeX.com")
ここで M は検索手法の集合、r_m(d) は手法 m における文書 d の順位、k は順位差の影響を調整する定数です。数式を覚える必要はありません。実務では「ベクトル検索とBM25の双方で上位に出る候補を優先する仕組み」と理解すれば十分です。
Rerankerをどこに置くか
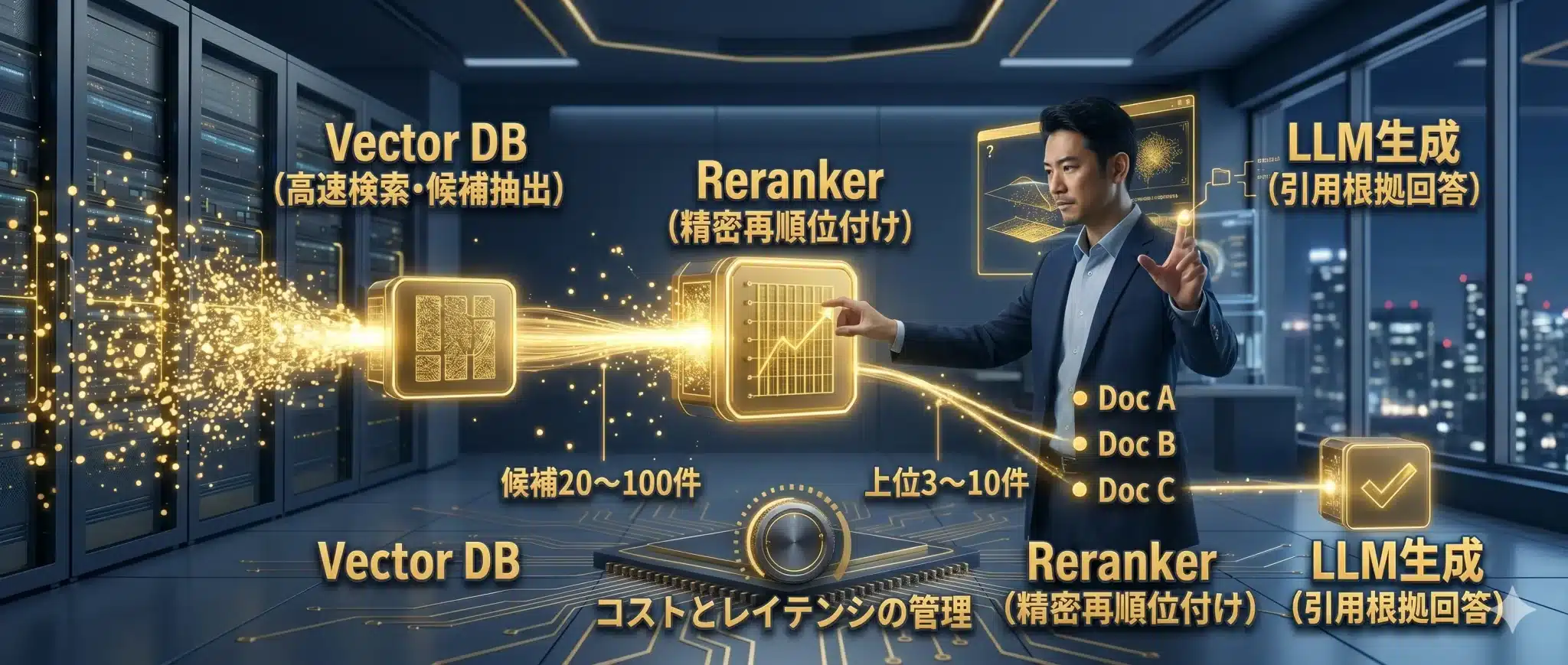
Rerankerは、Vector DBの代替ではありません。Vector DBは大量の文書から候補を高速に拾う役割を持ち、Rerankerはその候補を質問との関連度で精密に並べ替える役割を持ちます。
実務では、まずVector DB側でメタデータフィルタ、ベクトル検索、BM25、RRFを使って候補を20〜100件程度まで絞ります。その後、Rerankerで上位3〜10件へ再順位付けし、LLMに渡します。
| 役割 | Vector DB / Hybrid Search | Reranker |
|---|---|---|
| 目的 | 大量データから候補を高速に取得する | 候補を質問との関連度で精密に並べ替える |
| 処理件数 | 数万〜数億件から上位20〜100件 | 候補20〜100件を上位3〜10件へ絞る |
| 強み | 速度、スケール、フィルタ、運用制御 | 質問と根拠の対応関係を精密に評価 |
| 注意点 | 似ているが違う文書を混ぜることがある | 渡す件数が多いとコストとレイテンシが増える |
この配置を意識すると、Rerankerの説明はEmbedding記事と重複しません。Embedding記事では「Embedding検索の補正」、本記事では「検索基盤パイプラインの後段処理」として扱います。
一次情報からどこまで言えるか

一次情報から言えるのは、各製品の優劣ではなく、Hybrid Searchと運用統合が共通潮流ということである。
Pineconeの公式ドキュメントでは、dense vectorとsparse vectorを使ったHybrid Searchや、統合Embedding / Rerankingの流れが示されています。ベクトル検索だけでなく、キーワード的な信号を組み合わせる設計が前提になりつつあります。
Weaviateの公式ドキュメントでは、Hybrid SearchがVector SearchとBM25Fを組み合わせる方式として説明されています。検索結果の融合方法や、vectorとkeywordの重みを調整できる点が特徴です。
Qdrantの公式ドキュメントでは、dense vector、sparse vector、multi-vectorの検索結果をRRFやDBSFで統合するHybrid / Multi-stage Queryが扱われています。単なるベクトル保存先ではなく、多段検索基盤としての性格が強まっています。
Azure AI Searchでは、Hybrid Queryにおいて全文検索とVector Queryを並列に実行し、RRFで統合する仕組みが公式に説明されています。Microsoft基盤では、検索、RRF、Semantic Ranker、認証・運用をまとめて設計しやすいのが特徴です。
Milvusの公式ドキュメントでは、HNSWが高次元ベクトル検索の性能向上に使われるグラフ型インデックスとして説明されており、pgvectorではHNSWやIVFFlatなどのANNインデックスを追加できることが示されています。
もう一つの潮流として、専用ベクトルDBを別途立ち上げるのではなく、pgvectorのように既存のPostgreSQLを拡張して使う選択肢も存在感を増しています。新規インフラを増やさず、構造化データとベクトルを同じ運用基盤で扱える点が、中規模RAGでは評価されやすいポイントです。
一次情報から見える実務上の結論は、「どのDBが最強か」ではなく、RAGに必要な検索信号をどこで統合し、どこで絞り込み、どこで再順位付けするかを設計することです。
よくある失敗

ベクトルDBの失敗は、製品選定ミスよりも、検索基盤設計の不足から起きることが多い。
ベクトルDB導入でよくある失敗は、PoCの成功をそのまま本番成功と勘違いすることです。小さなデータセットでは、どのDBでもそれなりに動きます。しかし、本番ではデータ量、更新頻度、権限、監査、障害対応、コスト管理が一気に重要になります。
| 失敗 | なぜ問題か | 回避策 |
|---|---|---|
| PoC用DBをそのまま本番化 | アクセス増加やデータ増加で性能が落ちる | PoC時点で移行パスを決める |
| メタデータを後回しにする | 権限・版数・出典で絞れない | ETL段階で必須メタデータを定義する |
| Hybrid Searchを検討しない | 固有名詞・型番・番号検索に弱い | BM25や全文検索との組み合わせを評価する |
| Rerankerを万能視する | 候補が多すぎると遅く高くなる | Vector DB側で候補を適切に絞る |
| バックアップ・監視を設計しない | 障害時に復旧できない | バックアップ、監視、SLA、DRを事前に確認する |
特に重要なのは、ベクトルDBだけを入れてもRAGは完成しないという点です。RAGの精度改善全体は、RAG精度改善ガイド で整理しています。ベクトルDBは、その中の検索基盤を担う重要部品です。
まとめ
ベクトルDB選定の本質は、RAG検索パイプラインをどう本番運用するかを決めることである。
ベクトルDBは、Embeddingされた文書チャンクを高速に検索するための基盤です。しかし、本番RAGでは、ベクトル検索だけでは足りません。BM25、Hybrid Search、RRF、メタデータフィルタ、Reranker、アクセス制御、監査、運用監視を組み合わせて設計する必要があります。
PoCでは手軽さを重視してよいですが、本番ではSLA、セキュリティ、バックアップ、運用体制、将来のデータ規模を考えるべきです。専用型DBがよい場合もあれば、pgvectorやOpenSearch、Azure AI Searchのように既存基盤を活かす方がよい場合もあります。
RAGの本番品質は、ベクトルDB単体ではなく、検索基盤全体の設計で決まります。
Key Takeaways(持ち帰りポイント)
- ベクトルDBは、RAGにおける意味検索とメタデータ検索を支える検索基盤であり、RAG検索パイプラインの中心部品である。
- 本番RAGでは、ベクトル検索だけでなく、BM25、Hybrid Search、RRF、Rerankerを組み合わせたRAG検索パイプライン設計が重要になる。
- メタデータ設計は、出典表示、権限制御、最新版検索、監査対応のために不可欠である。
- 製品選定では、価格や速度だけでなく、SLA、セキュリティ、移行パス、運用体制まで見る。
専門用語まとめ
- ベクトルDB
- Embeddingされたベクトルを保存し、意味的に近いデータを高速に検索するためのデータベース。
- ANN(近似最近傍探索)
- 完全に最も近い点を全件探索するのではなく、十分に近い候補を高速に見つける検索手法。
- HNSW
- 階層型グラフ構造を使って高次元ベクトルを高速に検索するANNインデックスの一種。
- BM25
- キーワード検索で広く使われるランキング手法。固有名詞や型番、番号検索に強い。
- Hybrid Search
- ベクトル検索とキーワード検索を組み合わせ、意味検索と文字列一致の長所を両立する検索方式。
- RRF(Reciprocal Rank Fusion)
- 複数の検索結果を、スコアの絶対値ではなく順位にもとづいて統合する手法。
- Reranker
- 検索で取得した候補を、質問との関連度にもとづいて再順位付けするモデルまたは処理。
参考文献 / 出典
一次情報 / 公式ドキュメント
- Pinecone Documentation – Hybrid search
- Pinecone Documentation – Search overview
- Weaviate Documentation – Hybrid search
- Weaviate Documentation – Hybrid search concepts
- Qdrant Documentation – Hybrid and Multi-Stage Queries
- Microsoft Learn – Hybrid search in Azure AI Search
- Microsoft Learn – Reciprocal Rank Fusion in Azure AI Search
- Milvus Documentation – HNSW
- Milvus Documentation – Index Explained
- pgvector – GitHub
- PostgreSQL – pgvector 0.7.0 Released
- OpenSearch Documentation
次に読むならこの3本
補足Q&A
Q1.
ベクトルDBとは何ですか?
A1.
Embeddingされた文書や画像などを保存し、意味的に近いデータを高速に検索するためのデータベースです。
RAGでは、文書チャンクをEmbeddingしてベクトルDBに格納し、ユーザーの質問に近い根拠文書を検索します。
Q2.
RAGではベクトルDBだけで十分ですか?
A2.
多くの場合、ベクトルDBだけでは不十分です。
ベクトル検索は意味検索に強い一方、固有名詞、型番、法令番号、最新版管理、権限制御には弱い場面があります。そのため、BM25やsparse vectorと組み合わせたHybrid Search、メタデータフィルタ、Rerankerを組み合わせる設計が重要です。
Q3.
Hybrid Searchはなぜ必要ですか?
A3.
意味検索とキーワード検索の弱点を補い合えるからです。
ベクトル検索は言い換えに強く、BM25などのキーワード検索は固有名詞や型番に強いです。Hybrid Searchは両者を組み合わせ、RRFなどで検索結果を統合します。
Q4.
Pinecone、Weaviate、Qdrant、pgvectorはどう選べばよいですか?
A4.
PoC、本番運用、既存DB活用、Hybrid Search要件で選びます。
運用を任せたいならPinecone、Hybrid SearchやRAG機能を重視するならWeaviate、OSS/Cloud両方と高性能フィルタを重視するならQdrant、既存PostgreSQLを活かしたいならpgvectorが候補になります。
更新履歴
- 2026年5月21日:v11.3に適合し、RAG検索基盤設計、Hybrid Search、RRF、Reranker、メタデータ設計を中心に全面再構成。
- 2025年10月25日:選定フローチャート、コスト比較、エンタープライズ要件、RAG活用事例を追加。
- 2024年9月15日:初版公開。








