


※本記事はプロジェクトの進行に合わせて継続アップデートされます。
「動かし方をすべてコードで書く」時代は、静かに終わりに近づいています。
SO-101とは、低コストなロボットアームを使って、模倣学習やSim2Realの設計原理を実際に学べる実践向けの構成です。ロボットが人間のお手本を「見て」覚え、自分で「判断して」動く——その流れを実機で体験できることが、本シリーズの出発点です。
あなたのチームは、ロボットに「新しい動作」を覚えさせるとき、何時間コードを書きますか。 SO-101が示す新しい設計パターンでは、その時間の一部が「人間がお手本を見せる時間」に置き換わります。Behavior Cloning、Real-to-Real、Sim2Real、Fine-tuningまでの流れを、実機を使いながら一気通貫で解きほぐします。
これは単なるロボット工作の記事ではありません。
SO-101を入口に、Physical AIが「大企業の研究所だけの話」から、小さなチームでも設計し、検証し、育てられる技術へ変わり始めていることを示す、ARPの実践記録です。
✅ この記事の結論(TLDR)
- SO-101とは:低コストなリーダー/フォロワー構成のロボットアームを使い、模倣学習・Sim2Real・Fine-tuningの設計原理を学べる実践向けの入口です。
- Behavior Cloningとは:人間がリーダーアームで見せた「お手本」を、カメラ映像と6関節状態のペアデータとして記録し、「この映像ならこう動く」という変換関数をAIに学習させる手法です。
- Sim2Realへの接続で重要なこと:Real-to-Realで学習したモデルをそのままシミュレーターへ渡すのではなく、SO-101の物理情報、タスク定義、成功基準を先に固めることです。
- Fine-tuningとは:Sim2Realで鍛えたモデルを実機へ転送した後、少量の追加デモで現実の物理・視覚特性に適応させる微調整です。
- 本記事の役割:SO-101実践シリーズのハブとして、機材準備、Behavior Cloningセットアップ、Sim2Real設計、Isaac Sim実装へ進むための全体地図を示します。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』▶ 詳細はこちら
📚 SO-101実践シリーズの読み方
- この記事:SO-101でBehavior CloningからSim2Real・Fine-tuningまでの全体像を理解する
- 機材・準備編:SO-101、カメラ、PC、LeRobot環境など、模倣学習に必要な前提を確認する
- Behavior Cloningセットアップ編:LeRobotを使ったデータ収集・学習準備の流れを確認する
- Sim2Real設計編:身体・タスク・Ground Truthをどう設計するかを理解する
- NVIDIA Isaac / Physical AI設計編:Isaac Sim / Isaac LabとPhysical AI設計思想の関係を確認する
- URDF / USD / Isaac Sim実装編:SO-101をシミュレーション環境へ接続する技術要点を確認する
- Physical AI完全ガイド:SO-101実践を、Physical AI全体の技術潮流の中で位置づける
- AIロボット制作プロジェクト正式キックオフ:ARPがなぜSO-101実践を進めるのか、プロジェクト全体像を確認する
SO-101で何が学べるのか――従来制御との根本的な違い
従来はルールベースで「全部人間が書く」。新設計パターンは「データから学ぶ」。この違いが設計コスト・汎化性能・開発速度のすべてを変える。
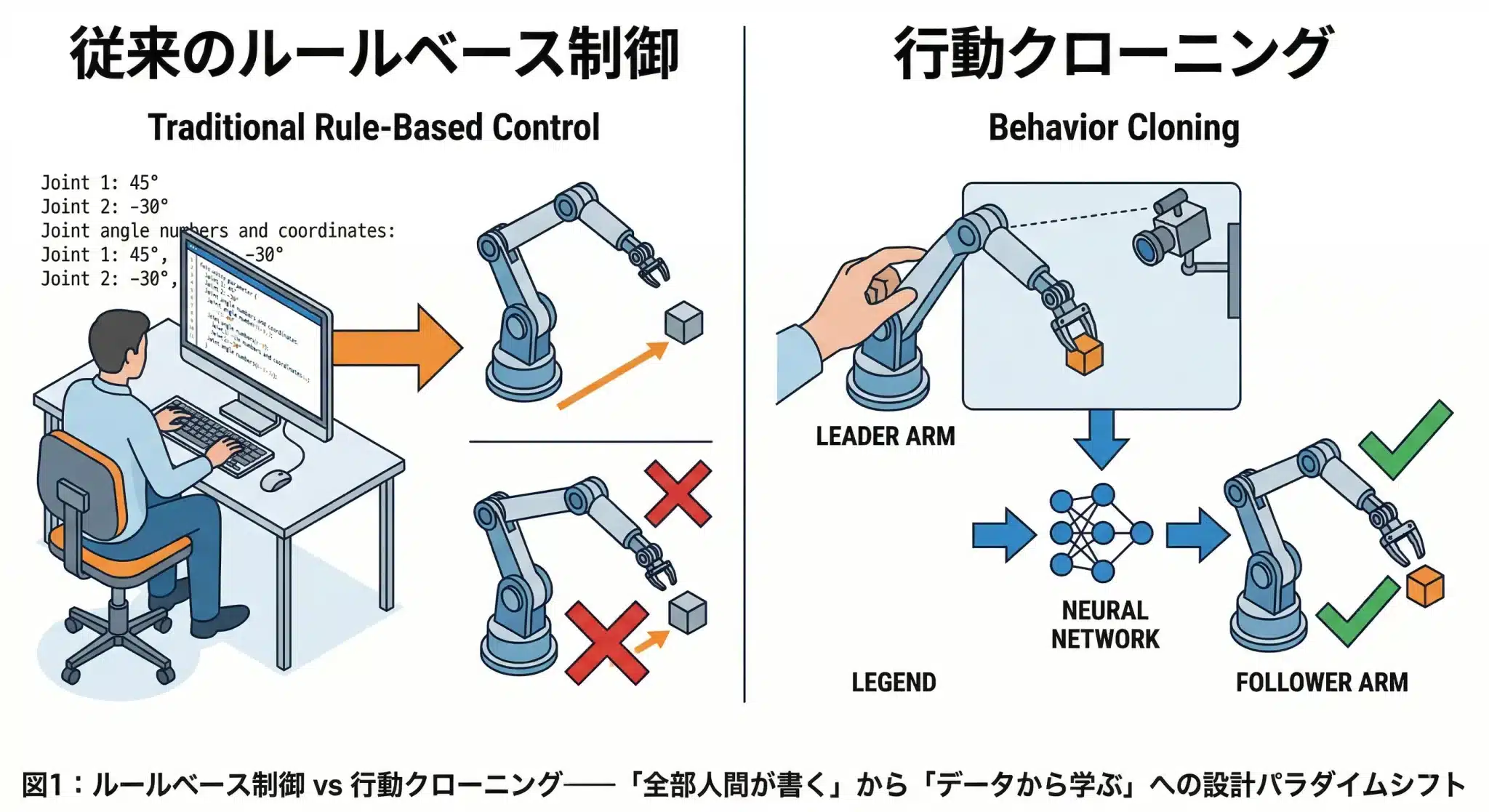
作業台の上の部品が、ほんの2cmずれただけで、昨日まで動いていたロボットアームが急に失敗し始める。
従来のロボットアーム制御を一言で表すと「全部人間が書く」です。物体をある位置から別の位置に移動させるだけでも、以下のようなコードを人間が手動で記述する必要があります。
# 従来のルールベース制御の例
IF object_position == (x=120, y=85, z=30):
move_joint(1, angle=35.0)
move_joint(2, angle=-12.3)
move_joint(3, angle=45.7)
move_joint(4, angle=3.1)
move_joint(5, angle=-1.2)
move_joint(6, angle=0.8)
gripper_close(force=0.73)
問題は、コードが間違っていることではありません。現実の方が、コードより先に変わってしまうことです。
物体が1cmずれたら、動きません。照明が変わったら、動きません。誰かが作業台を少し動かしたら、やはり動きません。 ルールベース制御は、あらかじめ書かれた条件の外側に出た瞬間、急に無力になります。
新しい設計パターンの本質は「入力→出力のペアをそのまま学習する」ことです。人間がお手本を見せ、AIがそのパターンを学習します。コードで動作を定義するのではなく、データから動作を導き出します。
SO-101の構造――リーダーアームとフォロワーアームの役割
SO-101は2本1セット。リーダーは「データ生成専用」、フォロワーは「学習・推論の実行機」。この役割分担が設計の出発点だ。
SO-101はアームが2本セットで構成されています。それぞれに明確な役割があります。
| アーム | 役割 | 使用フェーズ |
|---|---|---|
| リーダーアーム | 人間が手で動かす「お手本側」です。学習データを生成するためだけに存在します。 | データ収集時のみ(学習完了後は不要) |
| フォロワーアーム | 学習・推論の実行機です。データ収集時はリーダーを模倣し、学習後は自律動作します。 | 全フェーズで使用 |
SO-101の6関節構成(LeRobot API準拠)
記録の要となるアームの構造を詳しく見ていきましょう。このアームは、物理的には5つの回転軸と1つのグリッパー、合わせて6つの動作部で構成されています。LeRobot API上でも、この6つを「6関節」として一貫して扱います。
まず、土台となるJ1:ショルダーパン。これはアーム全体を左右に旋回させる回転軸です。 続くJ2:ショルダーリフトと、J3:エルボーフレックスは、肩と肘のように連動してアームのリーチと高さを決定します。
手首にあたるJ4:リストフレックスは上下の角度を、その先のリストロールは手首自体の回転を担います。この5つの回転軸の組み合わせにより、アームは空間上のあらゆる位置に、自由な角度で到達できます。
そして最終端にあるのが、J6:グリッパーです。この開閉率を制御することで、対象物を『掴む・放す』というアクションを完結させます。
これら5軸の回転角度とグリッパーの開閉状態。この全ての連動データが、30ミリ秒間隔でPCへと吸い上げられます。この精密な数値の積み重ねこそが、AIが模倣すべき『お手本』の正体なのです。
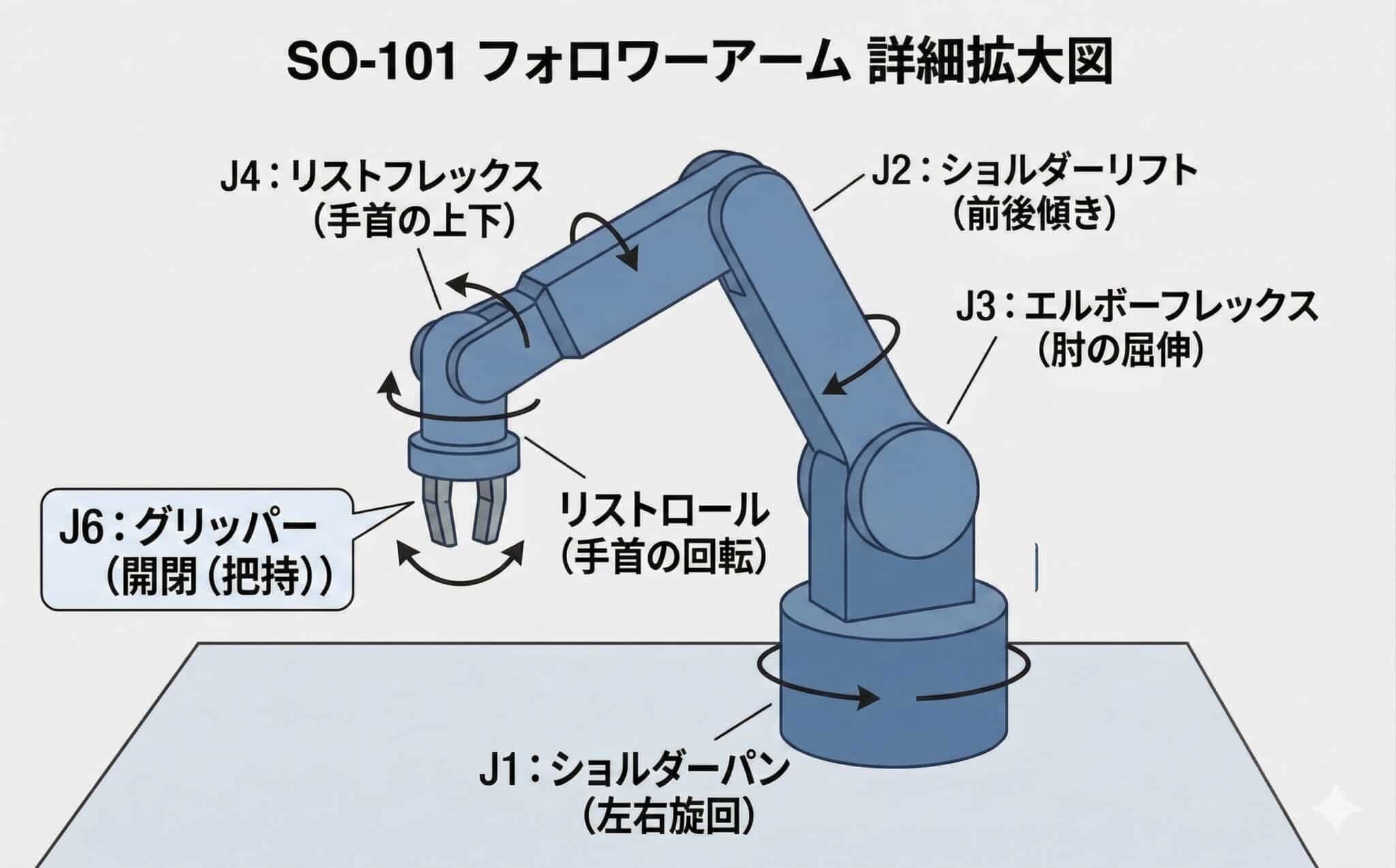
SO-101はLeRobot API上、6つの関節として扱われます。各関節が記録・制御の対象になります。
| 軸番号 | 関節名(LeRobot API名) | 動作 | 記録されるデータ |
|---|---|---|---|
| 軸1 | ショルダーパン(shoulder_pan) | 左右旋回 | 角度(度) |
| 軸2 | ショルダーリフト(shoulder_lift) | 前後傾き | 角度(度) |
| 軸3 | エルボーフレックス(elbow_flex) | 肘の屈伸 | 角度(度) |
| 軸4 | リストフレックス(wrist_flex) | 手首の上下 | 角度(度) |
| 軸5 | リストロール(wrist_roll) | 手首の回転 | 角度(度) |
| 軸6 | グリッパー(gripper) | 開閉(把持) | 開閉率(0%=全閉〜100%=全開) |
リーダーとフォロワーはどう繋がっているか
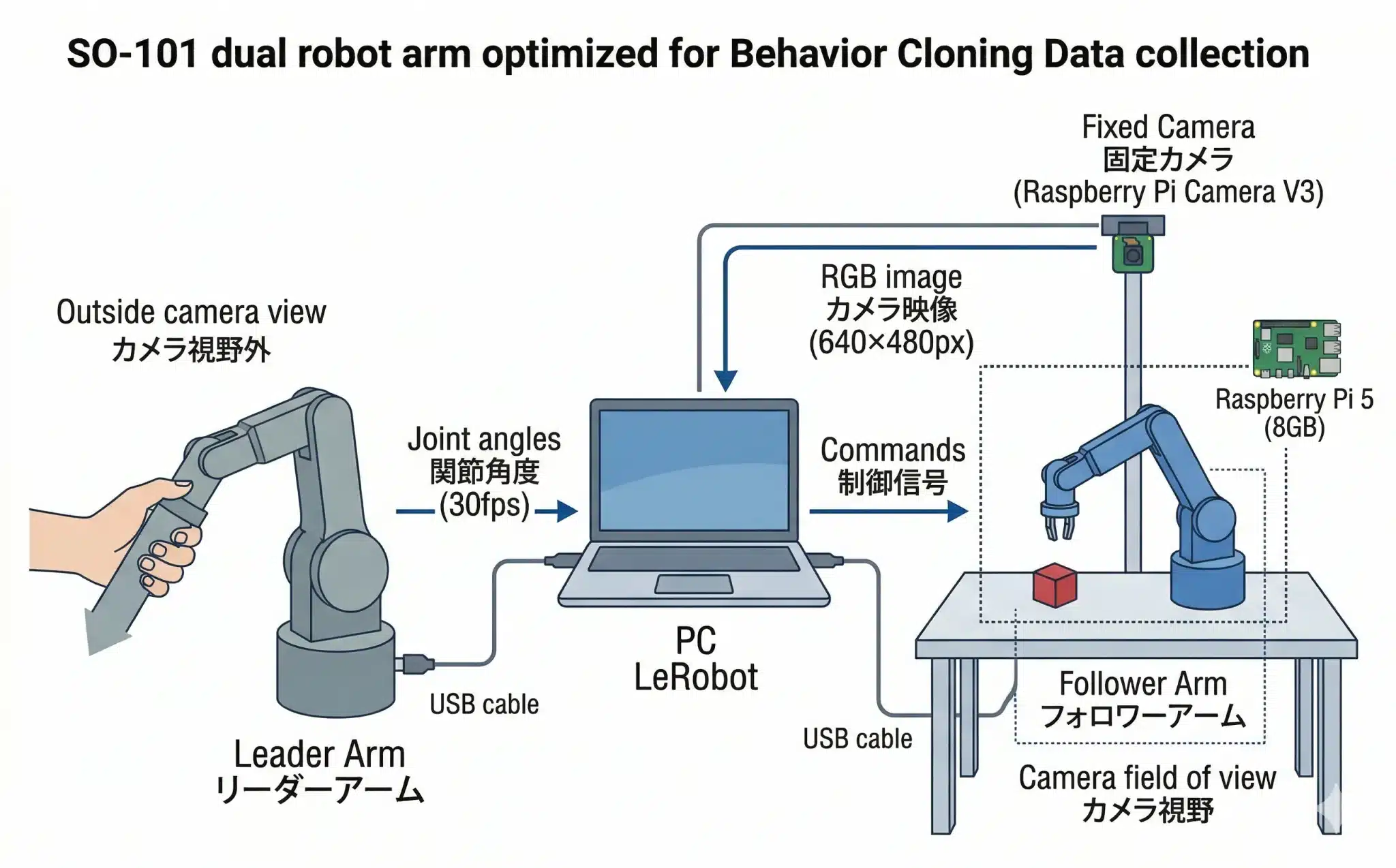 図2:SO-101システム接続構造図——リーダー・フォロワー・カメラ・PCの関係と、カメラ視野の設計原則
図2:SO-101システム接続構造図——リーダー・フォロワー・カメラ・PCの関係と、カメラ視野の設計原則この図は、Behavior Cloning用の学習データがどのように生成されるかを示したものです。
左のLeader Arm(リーダーアーム)は人間が手で動かす「お手本側」、右のFollower Arm(フォロワーアーム)はその動きを再現する「実行側」です。
中央のPC / LeRobotはシステム全体の司令塔として機能し、リーダー側から送られてくるJoint angles(関節角度)を受け取り、その情報をもとにフォロワー側へCommands(制御信号)を送ります。同時に、上部の固定カメラが取得するRGB image(カメラ映像)もPCに集約され、映像と関節状態が時刻同期したペアデータとして記録されます。
ここで重要なのは、この段階のフォロワーアームはまだ「自律知能」として動いているわけではないという点です。今行っているのは、AIが後で学習するための正解データを作る工程であり、人間の実演をそのままデータ化するための仕組みです。
この図でいちばん重要なのは、Outside camera view(カメラ視野外)とCamera field of view(カメラ視野)が明確に描き分けられている点です。
リーダーアームや操作者の手はあえて視野外に置かれ、視野内にはフォロワーアームと対象物だけが入るように設計されています。こうすることで、AIは余計な手がかりに頼らず、「この映像なら、この動きを出すべきだ」という対応関係を学習できます。
リーダーアーム │ │ USB接続 ↓ PC(LeRobotが動作中) │ ├─ カメラ映像を受信・記録 │ ├─ リーダーの軸状態を受信・記録 │ └─ フォロワーへ同じ軸状態を送信(約30ms間隔) │ │ USB接続 ↓ フォロワーアーム(リーダーと同期して動作)
カメラは作業台を俯瞰または正面から撮影し続ける固定カメラです。重要な設計原則として、リーダーアームはカメラの視野に入れません。フォロワーアームと物体だけが映っている状態を維持します。これにより「カメラ映像→フォロワーの動作」という純粋なペアデータが生成されます。
Behavior Cloningのデータ収集――カメラ映像と6関節状態を記録する
人間がリーダーを動かすだけで、カメラ映像と6関節状態のペアデータが自動生成される。50回のデモが約10,000ペアの学習データになる。
データ収集の流れは以下の通りです。
Step 1: 人間がリーダーアームを手で動かす
(「物体を掴んで別の場所に置く」動作を1回実演)
↓
Step 2: LeRobotが約30ms間隔(1秒≒30コマ)で同時記録
├─ カメラ映像(640×480px、RGB画像)
└─ フォロワーの6関節状態
[軸1〜5の角度(度)+ グリッパー開閉率]
↓
Step 3: 1回のデモ(約7秒)で約200コマのペアデータが生成される想定です。
(本プロジェクトの設計上の目安値であり、実測値はクール2以降で計測・更新します)
↓
Step 4: これを50〜100回程度繰り返す
→ 合計 約10,000〜20,000ペアのデータセット完成(目安値)
実際に記録されるデータの実例
概念的には、1コマ分の対応関係は以下のように理解すると分かりやすいです。なお、実際のLeRobot Dataset v3では、低次元信号はParquet、映像はMP4シャードとして管理されます(以下のJSONは概念図であり、実ファイル構造とは異なります)。
{
"frame_id": "demo_012_frame_0047",
"timestamp_ms": 1567,
"camera_image": "frame_0047.png", // 640×480px RGB画像
"joint_states": {
"shoulder_pan": 12.3, // 軸1(度)
"shoulder_lift": -8.7, // 軸2(度)
"elbow_flex": 45.2, // 軸3(度)
"wrist_flex": 3.1, // 軸4(度)
"wrist_roll": -1.2, // 軸5(度)
"gripper": 73 // 軸6(0%=全閉〜100%=全開)
}
}
このデータが意味するのは「このカメラ映像の瞬間に、アームはこの状態だった」というペアです。AIはこのペアを大量に見ることで「このカメラ映像が来たら、このアーム状態にする」という変換パターンを学習します。
強化学習との決定的な違い
Behavior Cloningは強化学習ではありません。
| 比較軸 | Behavior Cloning | 強化学習 |
|---|---|---|
| 学習の方法 | 人間のお手本をコピーする | 試行錯誤して報酬を最大化する |
| 報酬設計 | 不要 | 人間が設計する必要あり |
| 実機での試行回数 | 50〜100回(人間のデモ) | 数万〜数百万回 |
| 小規模チームでの現実性 | ◎ 導入しやすい | △ 高い試行回数と設計負荷が必要 |
| 初期の汎化性能 | 低い(見たことのある状況のみ) | 高くなりうる |
| ※ 本プロジェクトではBehavior Cloningで基盤を作り、Sim2Realで汎化性能を補完する設計を採用 | ||
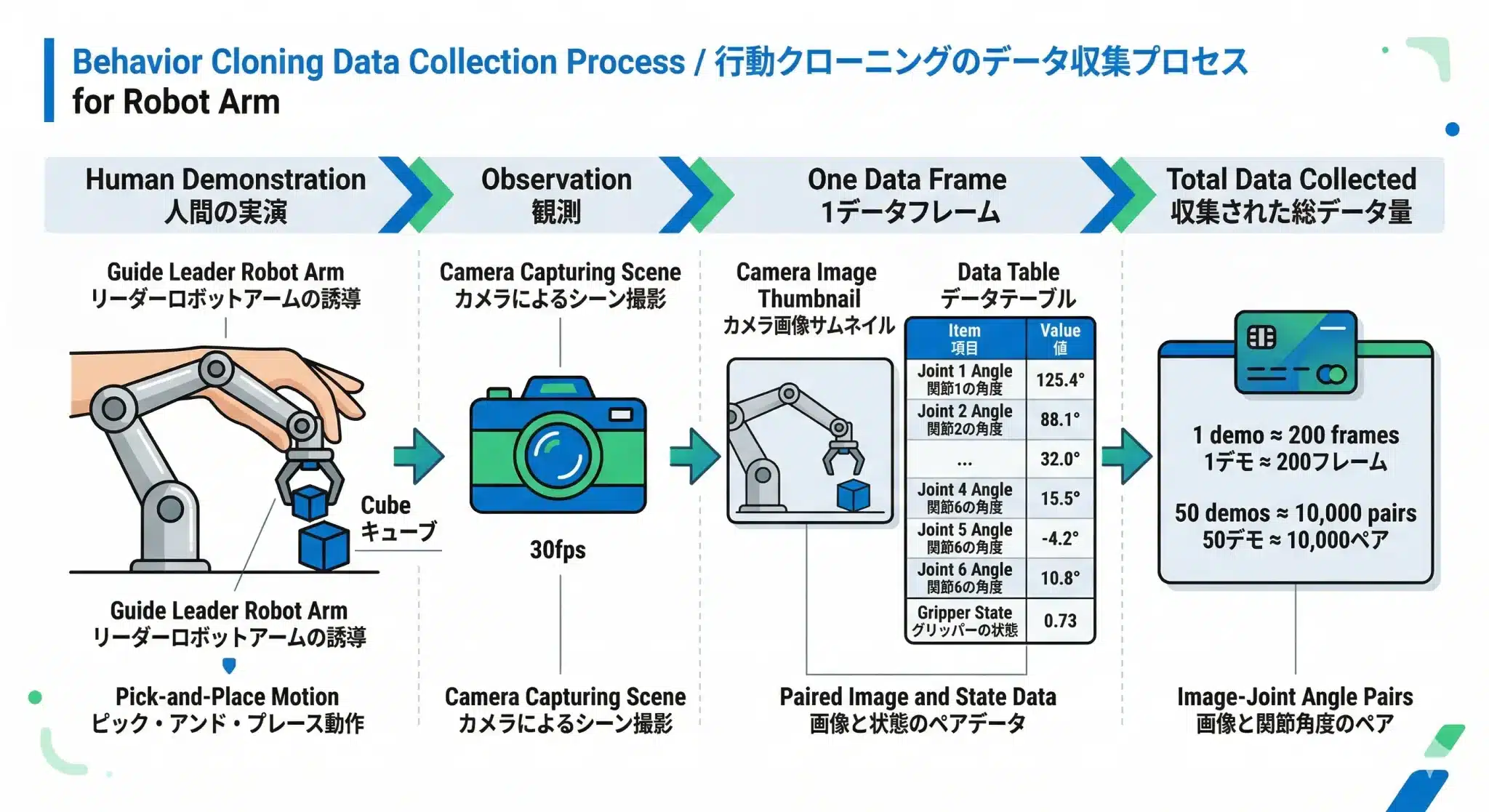 図:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かります
図:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かりますBehavior Cloning学習――カメラ映像から動作を覚える
学習とは「このカメラ映像が来たら、このアーム状態にする」という変換関数を作ることだ。学習完了後、リーダーアームは完全に不要になる。
実際の動きやデータ収集の雰囲気を動画で確認したい方は、YouTubeの実演動画もあわせてご覧ください。
図:SO-101のロボットアームを使ってReal-to-Realで学習する
図の解説:Behavior Cloning(模倣学習の1形態)用学習データ収集システム
- リーダーアーム(操作・データ入力側)を手動で動かすと、学習・推論実行機であるフォロワーアームがそれに追随して全く同じ動作をします。
- この動作中、固定カメラが作業環境を撮影し、同時に秒間30枚の速度で画像と、6つの関節軸(J1〜J5)の角度データ、およびグリッパー(J6)の開閉率等のデータペアを高速に生成します。
- このデータを用いてフォロワーアームに動作を学習させる手法をBehavior Cloningと呼びます。
学習フェーズでは、収集した10,000〜20,000ペアのデータをニューラルネットワークに与えます。ネットワークが学ぶのは一つの変換です。
「このカメラ映像(入力)が来たら、このアーム状態(出力)にする」
料理に例えるとこうです。食材の組み合わせ(カメラ映像)を見たとき、次にどの手順で動くか(軸の角度)を覚えるイメージです。レシピを言葉で読むのではなく、何千回もの「この食材→この手順」のペアを見て、身体で覚える。これがBehavior Cloningの本質です。
【発展】角度だけではない:データ構造がもたらす「身体知」の正体
「画像+関節角度」だけでも基本動作は学習できます。ただし、精度をさらに高めたい段階で追加できる情報があります。初回実装では読み飛ばして構いません。
自律動作の精度が飛躍的に高まるのは、学習データに「角度」以外の多角的な情報が含まれているからです。これらが「映像」とセットで学習されることで、結果として状況に応じた柔軟な次の一手(身体知)が導き出されます。
- 動的な制御の再現(プロプリオセプション):初期実装では現在の関節状態を中核に扱い、必要に応じて過去フレームから導かれる速度・加速度などを加えることで、目標直前での滑らかな減速や、重力の影響を考慮した姿勢維持といった動的な振る舞いを強化できます。
- 数値としての「手応え」(力覚・電流値):モーター電流値は、ロボットにとって接触や負荷の変化を知る重要な手がかりです。視覚だけでは分からない「触れた」「押しすぎた」といった情報を補い、より繊細な把持制御を支える拡張観測として有効です。
- 空間的な幾何学理解(座標データ):関節角度から算出される手先(グリッパー)の3次元位置(X, Y, Z)は、画像上の変化と空間上の移動を数学的に結びつける補助情報として有効です。より最短で正確な経路選択が必要な段階で段階的に追加する設計が現実的です。
初期実装ではまず「画像+関節状態」を中核にし、接触リッチな課題や高精度制御が必要な段階で、電流値・EE座標・速度などを追加していく設計が現実的です。
学習完了後の推論フロー
学習が完了した瞬間から、リーダーアームは不要になります。フォロワーアームはカメラ映像だけを入力として自律動作します。
【学習完了後の推論フロー】
カメラが作業台を撮影(継続)
↓
新しいフレームをPC(学習済みモデル)に入力
↓
モデルが推論(約30ms)
「この映像なら → 軸1: 12.3°, 軸2: -8.7°...」
↓
推論結果をPC(またはNVIDIA Jetson)経由でフォロワーにUSB送信
↓
フォロワーアームが自律動作
(リーダーは切り離し済み・不使用)
↓
次のフレームで同じサイクルを繰り返す
(1秒間に約30サイクル)
Real-to-Realの最終確認:3回連続成功
Real-to-Realフェーズの最終確認は、本プロジェクト独自の運用基準として「リーダーアームを完全に切り離した状態で、フォロワーが同一タスクを3回連続で成功するか」を採用しています。
この3回連続成功が意味するものは「AIが賢くなった」ことではありません。「カメラ→推論→アーム制御」というパイプライン全体が安定して動作する神経系が完成したことの証明です。この基盤があって初めて、2年目のSim2Realが成立します。
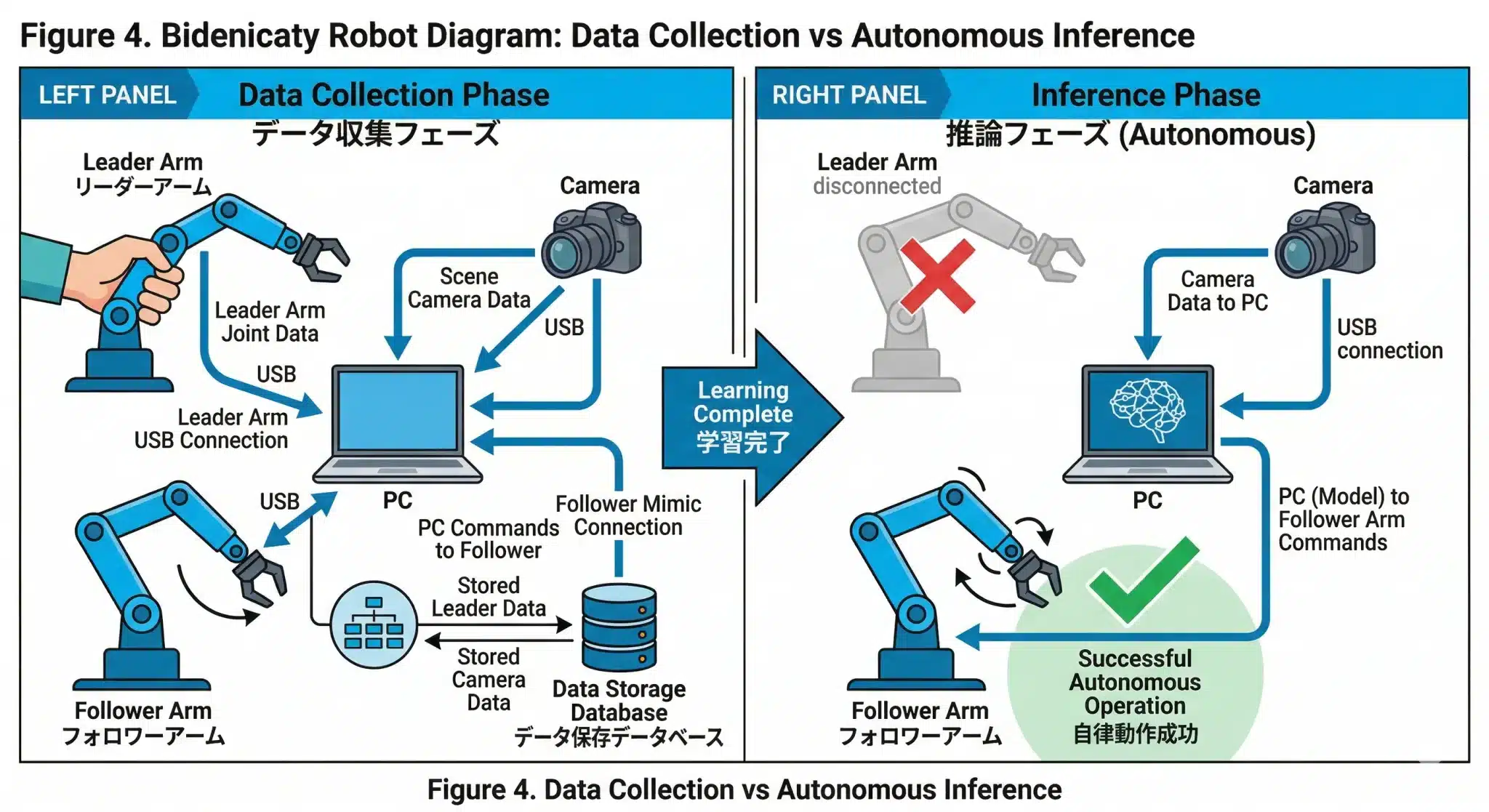 図:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かります
図:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かりますReal-to-Realの限界――なぜSim2Realが必要になるのか
Behavior Cloningは「見たことのある状況しか対応できない」。物体が2cmずれたら失敗する。この限界を突破するためにSim2Realが必要になる。
Real-to-Realで学習したモデルには明確な限界があります。
例えばデータ収集時に物体が常に座標(x=120, y=85)に置かれていたとします。推論時に物体が(x=122, y=85)——わずか2cmずれた位置にあったとき、このモデルは高確率で失敗します。
理由はシンプルです。「座標(x=122)の物体を掴む映像」をモデルは一度も見たことがないからです。
「もっとデモを収集すれば解決するか?」——答えはNoだ
1,000回のデモを収集しても、根本的には解決しません。
物体の位置・照明・テクスチャ・背景の組み合わせは事実上無限大です。しかも現実での収集には、何より人間の時間という絶対的な天井があります。仮に1日10回ずつデモを増やしても、1万通りの状況を網羅するには約3年かかる計算です。
この壁を前にして、ロボット学習が辿り着いた逆転の発想があります。
「現実で無限に試行できないなら、シミュレーターで無限に試行する。」
この発想転換が、小規模チームでも汎化性能に挑戦できる道を開きます。
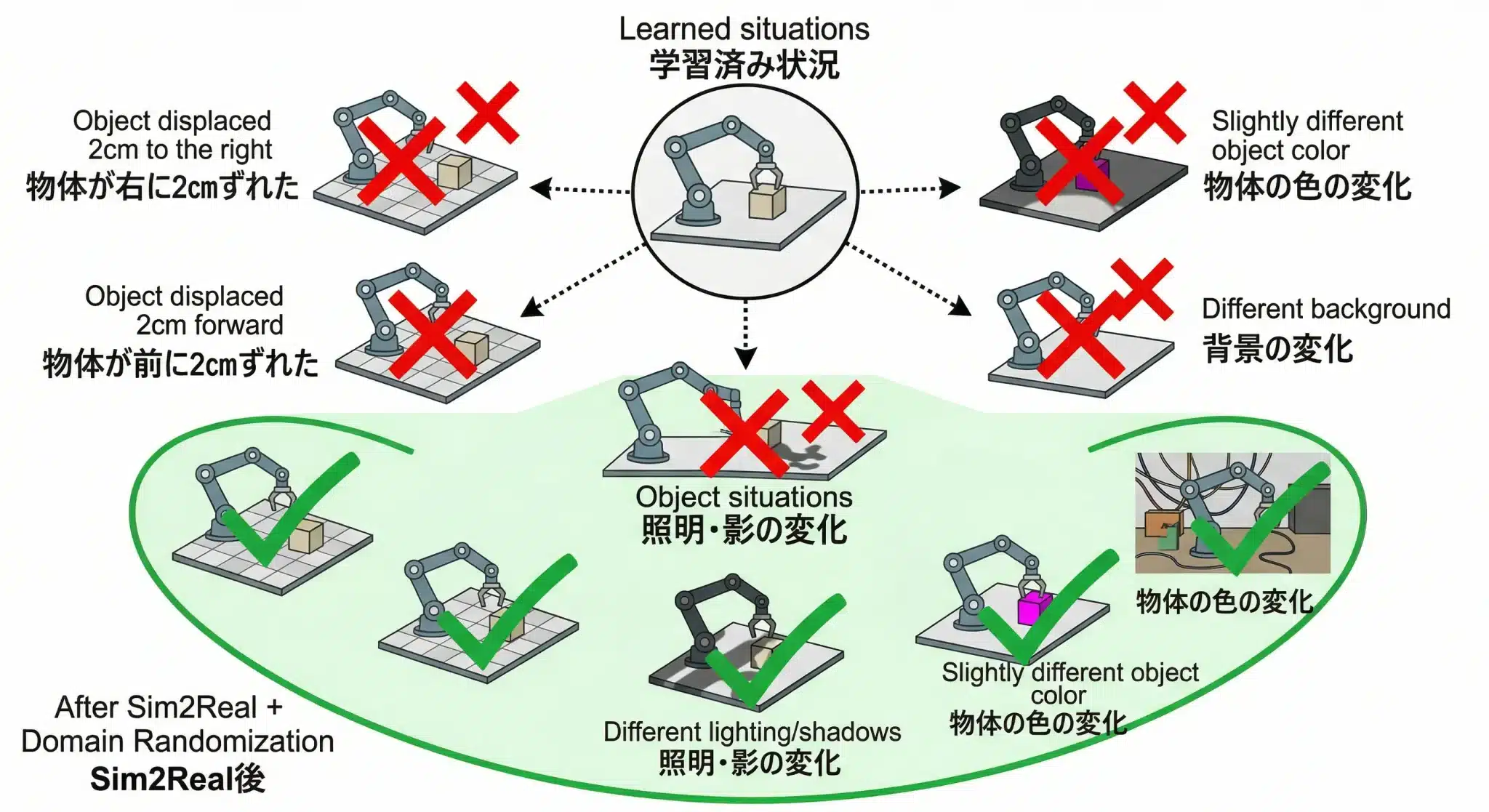 図:Real-to-Realモデルの「対応可能範囲」の狭さ——Sim2Real適用前後での汎化性能の変化
図:Real-to-Realモデルの「対応可能範囲」の狭さ——Sim2Real適用前後での汎化性能の変化Sim2Realへの接続――SO-101の物理情報・タスク・成功基準をどう渡すか
本プロジェクトのSim2Real設計では、最初に固めるのは学習済みモデルそのものではなく、SO-101の物理情報・タスク定義・成功基準だ。
ここが最も誤解されやすいポイントです。
先に結論をお伝えします。
Real-to-Realで育てた学習済みモデルや軌跡を、そのまま「エージェントとして」シミュレーターに移植するのが本筋ではありません。本プロジェクトでは、まず SO-101 の物理情報・タスク定義・成功基準の3つを固め、そのうえで Isaac Lab 側の模倣学習や強化学習の設計に接続する方針です。
そのうえで、2026年時点のLeIsaac × LeRobotやIsaac Labが示すように、シミュレーション内で模倣学習や評価を回す設計、あるいはRLやLearning from Demonstrationsを組み合わせる設計も存在します。
食わせるもの①:URDFファイル(SO-101の物理情報)
URDFはロボットの形状・重量・重心・関節の可動域・摩擦係数を記述したXMLファイルです。これをまずIsaac Sim側で読み込むことで、「物理的に意味のある仮想SO-101」をシミュレーション基盤上に構築できます。
その上で、学習ワークフロー自体はIsaac Labのようなロボット学習フレームワークで構成する、という役割分担で理解すると分かりやすいです。
<!-- URDFファイルの例(概念的な抜粋) -->
<joint name="shoulder_pan" type="revolute">
<limit lower="-3.14" upper="3.14"
effort="10.0" velocity="2.0"/>
<dynamics damping="0.1" friction="0.05"/>
</joint>
シミュレーション精度はURDFや物理パラメータ設定の精度に直結します。現実のSO-101の物理特性を正確に測定・記述することが、Sim2Real成功の最初の関門です。
食わせるもの②:タスク定義
「この位置にある物体を掴んで、この位置に置く」という成功条件を定義します。具体的には以下の要素が含まれます。
- 物体の初期位置の範囲
- 目標配置位置の定義
- 成功判定の条件(物体が目標位置±Xcmに置かれたら成功)
- 失敗判定の条件(物体を落とした・制限時間超過など)
食わせるもの③:Ground Truth設計の参照基準
Real-to-RealのBehavior Cloningで達成した「3回連続成功」の実績——どの軌跡でタスクを完了できるか——が、シミュレーション内のタスク定義と成功判定条件を設計するための参照基準になります。
つまりReal-to-Realで確立した基本動作パイプラインは、Sim2Realで「何を達成できれば成功か」を定義するための参照基準として機能します。軌跡データをそのまま投入するのではなく、成功条件を設計する根拠として使う点が重要です。
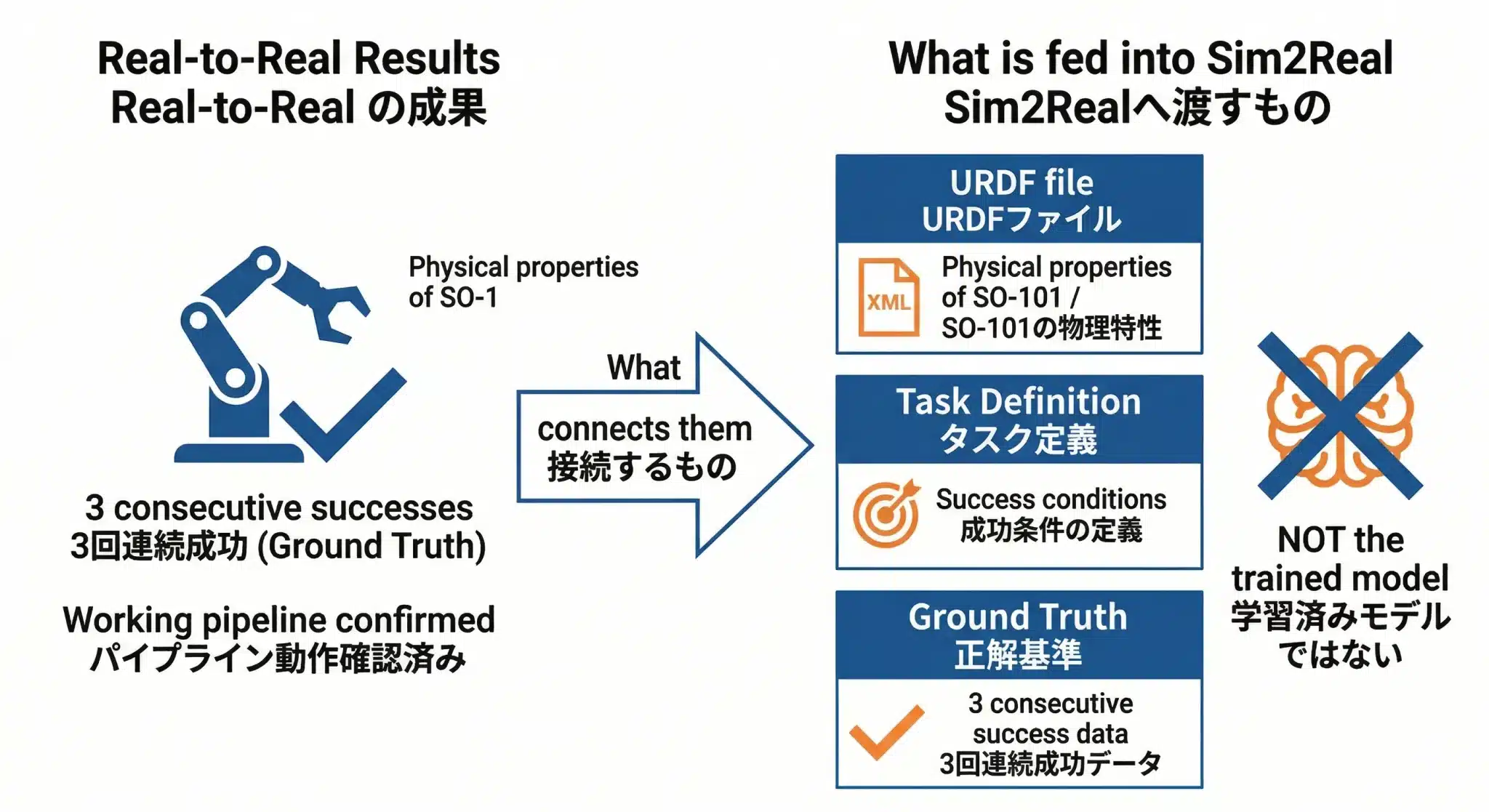 図:Real-to-RealからSim2Realへの接続——渡すのはモデルではなく「物理情報・タスク定義・成功基準」の3つ
図:Real-to-RealからSim2Realへの接続——渡すのはモデルではなく「物理情報・タスク定義・成功基準」の3つDomain Randomization――想定外に強いSO-101モデルを育てる
シミュレーター内で物体位置・照明・摩擦係数をランダムに変化させながら学習させることで、「多少ずれていても掴める」汎化性能が生まれる。
Isaac Sim上に仮想SO-101を構築し、その上で本プロジェクトではIsaac Labを用いたRL+Domain Randomizationを主軸に、汎化性能の学習を進める想定です。
ただし2026年時点では、シミュレーション内での模倣学習やLearning from Demonstrationsを組み合わせる設計も一般的になりつつあります。
Domain Randomizationとは「シミュレーション内のあらゆる条件をランダムに変化させながら学習させる手法」です。
ランダム変化させるパラメータの実例
| パラメータ | 変化の範囲 | 目的 |
|---|---|---|
| 物体の位置 | ±5cmのランダムオフセット(例) | 位置ずれへの対応力 |
| 照明の方向・強さ | 方向360°・強さ0.5〜2.0倍(例) | 照明変化への対応力 |
| 物体のテクスチャ・色 | ランダム素材・ランダム色(例) | 見た目の変化への対応力 |
| 関節の摩擦係数 | ±20%のランダム変動(例) | 実機個体差への対応力 |
| カメラ取付角度 | ±3度のランダム傾き(例) | カメラ設置誤差への対応力 |
| 背景のテクスチャ | ランダム背景(例) | 環境変化への対応力 |
並列学習の圧倒的なコスト優位
Domain Randomizationを支えるのが並列学習です。
【現実での学習】 1台のSO-101が1回ずつ試行 1日に収集できるデモ:人間の作業時間内(数十回) 1年間の総試行回数:数千回 【シミュレーターでの並列学習】 仮想SO-101が数千台同時に動作 24時間休まず試行継続 1日あたりの試行回数:数百万回
現実で1年かかる試行回数を、シミュレーターなら数時間で完了させることも可能です。 人間に換算すれば、1年分の経験を眠っている間に積んで朝目覚めるようなものです。もちろんこれは、仮想ロボットを多数並列で動かし、十分な計算資源を使える場合の話です。それでも、現実世界だけで試行を積み上げるより、はるかに速く多様な経験を与えられることがSim2Realの大きな優位点です。
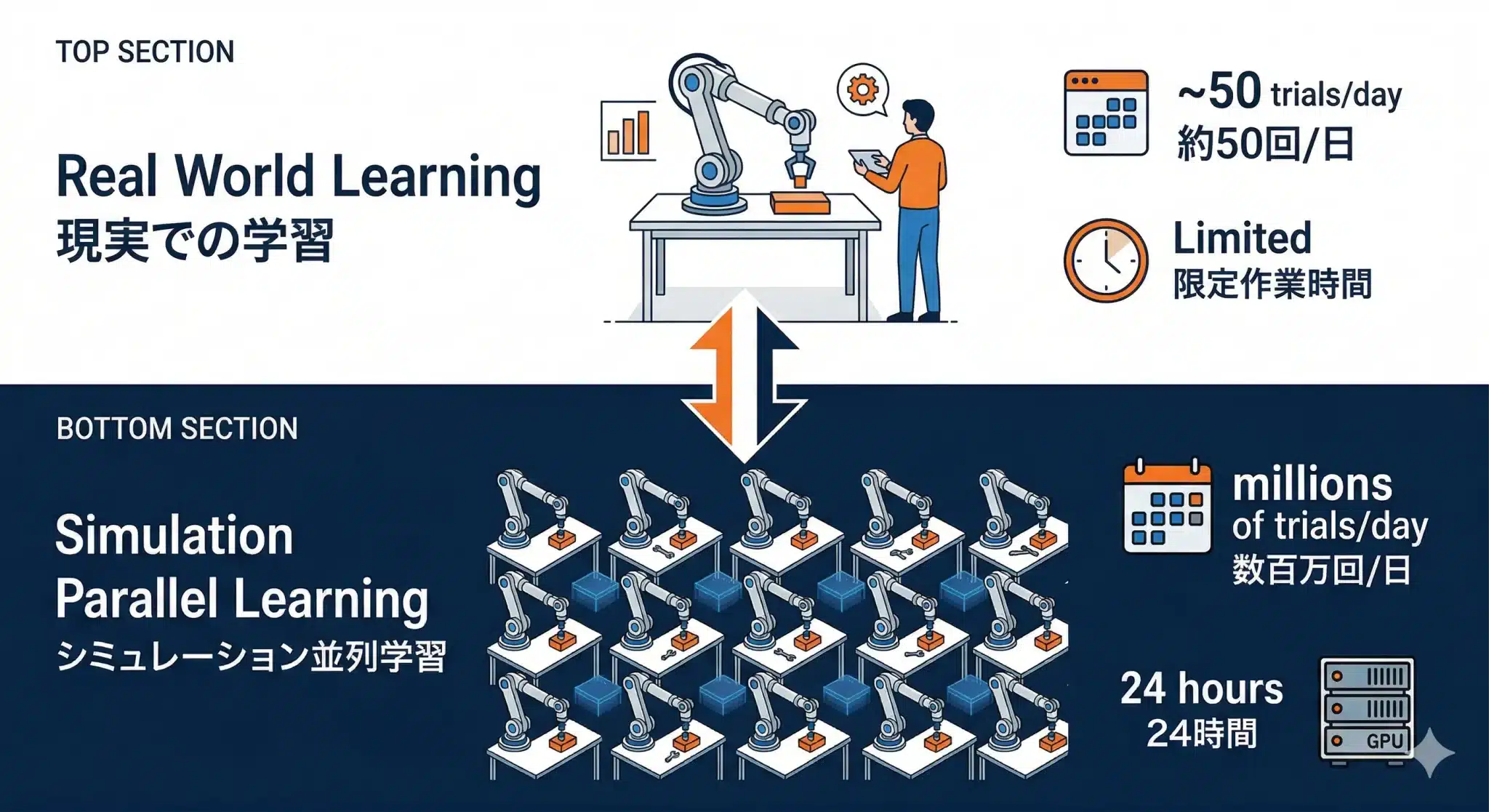 図:並列学習の圧倒的なコスト優位——シミュレーターは現実の数万倍の試行速度でDomain Randomizationを実行できる
図:並列学習の圧倒的なコスト優位——シミュレーターは現実の数万倍の試行速度でDomain Randomizationを実行できるFine-tuning――Sim-to-Real Gapを少量の実機データで埋める
Sim2Realで鍛えたモデルをそのまま実機に載せても動かない。10〜30回の追加デモで「現実の物理・視覚特性」に適応させるのがFine-tuningだ。
数百万回のシミュレーション学習を終えたモデルが、初めて実機の物理と視覚に適応する工程がFine-tuningです。わずか10〜30回程度の追加デモでも、現実環境に合わせた重要な補正が可能になります。
数百万回の訓練を終えたモデルを、初めて実機に載せた瞬間——アームは、ほんの少しずれた場所に手を伸ばします。
シミュレーションでは完璧だったのに、現実では微妙にずれる。
この「ほんの少し」が、Sim-to-Real Gapです。原因は2つあります。
Sim-to-Real Gapの2つの原因
原因①:物理のズレ
URDFでどれだけ正確に記述しても、シミュレーションの物理演算は「近似値」です。現実の関節には微妙なガタつき・個体差・経年変化による摩擦の変化があります。シミュレーターではこれを完全に再現できません。
原因②:視覚のズレ
シミュレーションのテクスチャ・照明はどれだけリアルに作っても、現実のカメラが捉える光の反射・レンズのボケ・センサーノイズとは異なります。モデルの「目」が現実の映像を見たことがない状態で転送されるため、視覚的なズレが生じます。
Fine-tuningの手順
Step 1: Sim2Realで学習済みの「汎化性能の高いモデル」を
実機フォロワーアームに転送
Step 2: 再びリーダーアームを使って
実機で10〜30回のデモを追加収集
(この「本物データ」は少量でよい)
Step 3: 少量の本物データで追加学習(Fine-tuning)
「この現実の映像→この軸状態」の
補正パターンをモデルに上書きする
Step 4: Sim-to-Real Gapが補正される
Step 5: 実機成功率85%達成
なぜ10〜30回の少量デモで足りるのか
Fine-tuningがなぜ少量データで機能するのかを理解することが重要です。
Sim2Realで数百万回学習したモデルは「汎化性能の骨格」はすでに完成しています。物体がずれていても、照明が変わっても対応できる能力は既に備わっています。
Fine-tuningで補正するのは「骨格」ではなく「現実の物理・視覚特性への微調整」です。
| フェーズ | 役割 | 必要なデータ量 | 期待される成功率 |
|---|---|---|---|
| Real-to-Real(Behavior Cloning) | 神経系の確立・基本動作の習得 | 50〜100回程度のデモ(本プロジェクトが設計上おいている目安) | 固定条件で〜95%(本プロジェクトが現時点で設定している目標値。実測値はクール2以降で計測予定) |
| Sim2Real(Domain Randomization) | 汎化性能の骨格を作る | 数百万回規模(シミュレーター内で想定している試行回数の目安) | 転送直後〜60〜70%(本プロジェクトが現時点で想定している目安値であり、タスクやロボット個体によって上下します) |
| Fine-tuning | Sim-to-Real Gapの補正 | 10〜30回程度のデモ(本プロジェクトが想定している追加デモ数の目安) | 85%以上(本プロジェクトが設定している目標値であり、実測値はクール8〜9で計測・記録します) |
| ※ 成功率は本プロジェクトにおける目安値・目標値です。実測値はクール8〜9で計測・記録します。 | |||
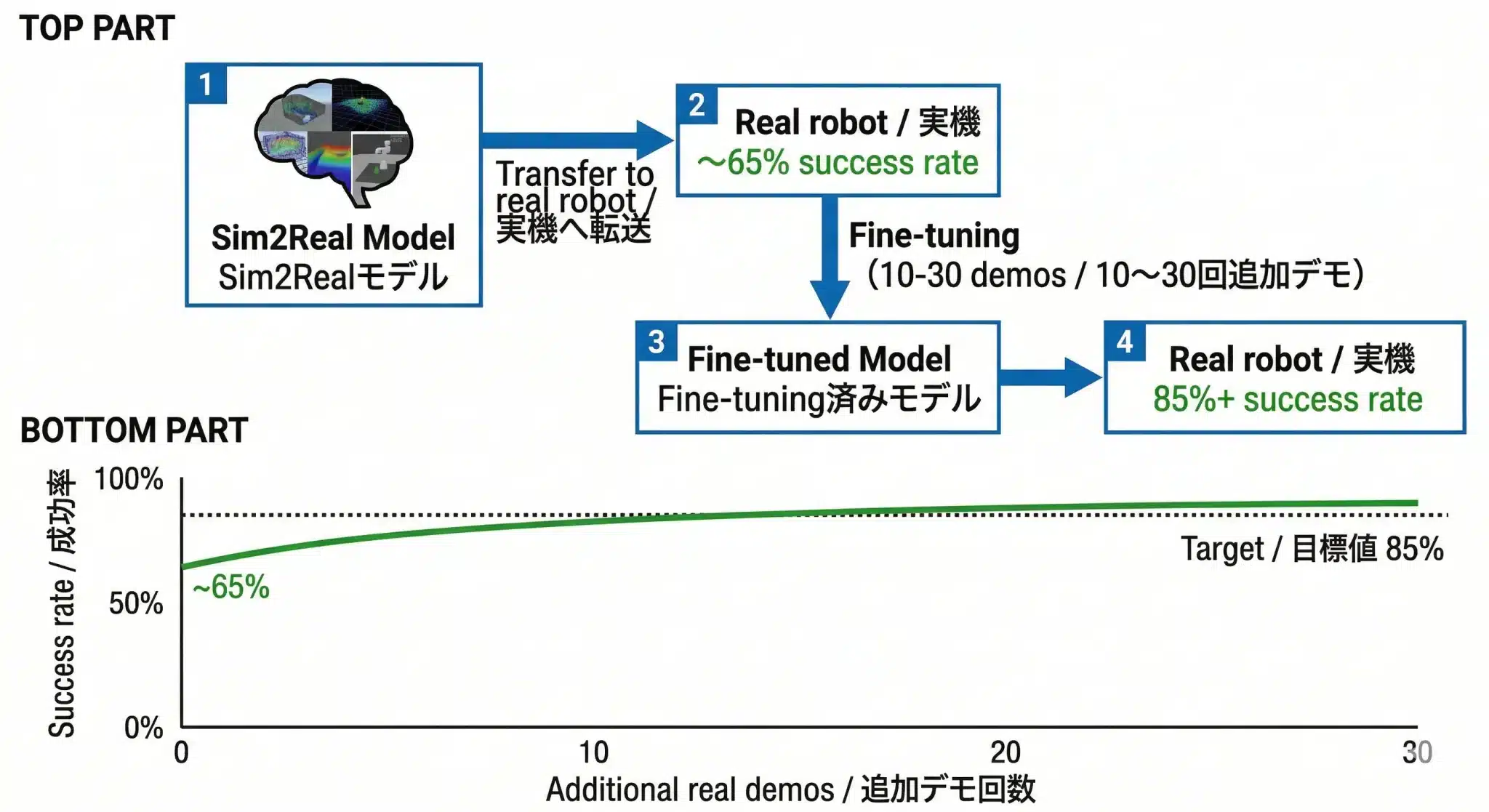 図:Fine-tuning前後の成功率変化——少量の実機データがSim-to-Real Gapを補正し、目標値85%を達成する仕組み
図:Fine-tuning前後の成功率変化——少量の実機データがSim-to-Real Gapを補正し、目標値85%を達成する仕組みSO-101実践の全体像――Behavior CloningからFine-tuningまで
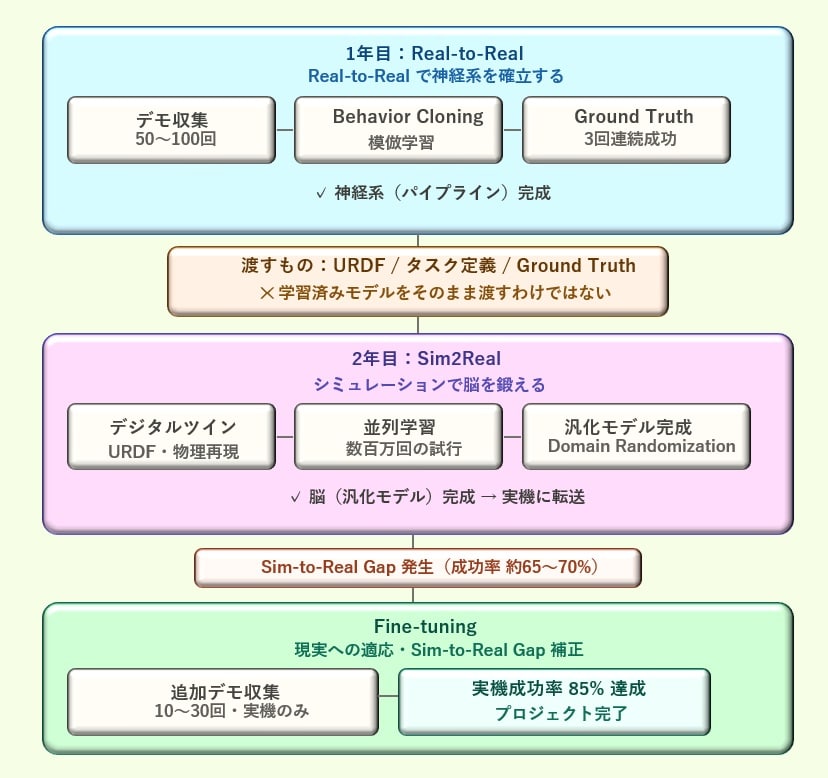
Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる。この3段階が「見て・判断して・動く」知能の設計原理だ。
ここまで解説してきた内容を一枚で整理します。
従来手法との比較:何が根本的に変わるか
| 比較軸 | 従来(ルールベース) | 新設計パターン |
|---|---|---|
| 動作の定義方法 | 人間がコードで全て記述 | データから自動学習 |
| 新しい位置への対応 | コードの追記が必要 | Domain Randomizationなどで対応力を広げる |
| 初期開発コスト | 高い(プログラミング工数) | 比較的低い(本プロジェクトではデモ収集50〜100回程度を想定) |
| 汎化性能 | 事前定義した状況のみ | 学習設計次第で高い汎化性能を狙える |
| 小規模チームでの現実性 | △ 動作定義の工数が重い | ◎ デモ収集中心で試しやすい |
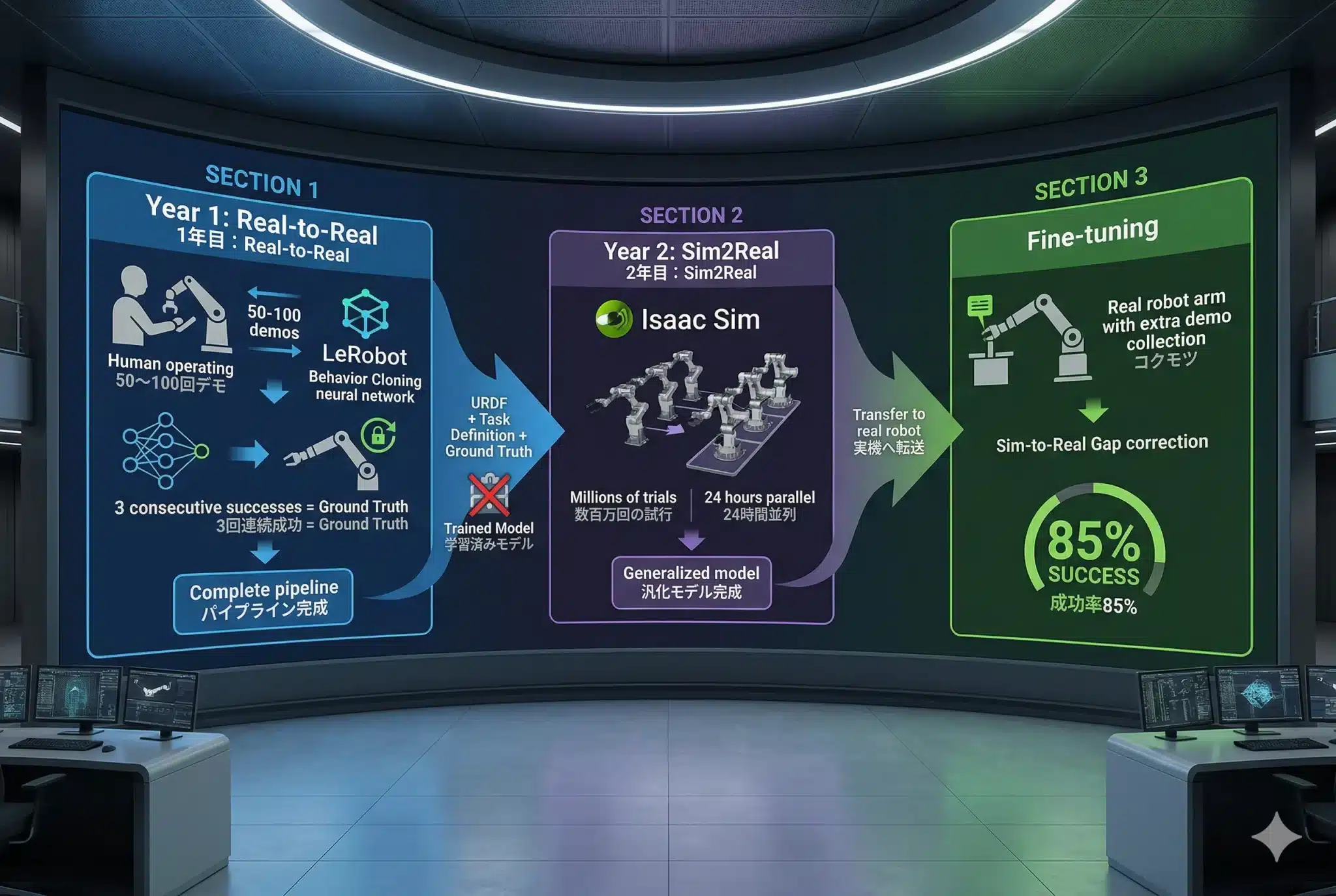 図:2年間の設計原理の鳥瞰——Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる3段階の全体像
図:2年間の設計原理の鳥瞰——Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる3段階の全体像まとめ:「見て・判断して・動く」設計原理の3行まとめ
Real-to-Realで土台を作り、Sim2Realで限界を突破し、Fine-tuningで現実に着地する。
本記事で解説した設計原理を3行に圧縮します。
第一に、Behavior Cloningはルールを書きません。カメラ映像とアーム状態のペアデータから、AIが自分で動作パターンを学習します。リーダーアームは学習データを生成するためだけに存在し、学習完了後は不要になります。
第二に、本プロジェクトのSim2Real接続は「まず物理情報を固める」設計です。URDF等の物理情報・タスク定義・成功判定の参照基準をシミュレーター設計に反映し、並列学習やDomain Randomizationを通じて「想定外に強い知能」を育てます。
第三に、Fine-tuningは再学習ではなく微調整です。Sim2Realで汎化の骨格が完成しているため、実機での10〜30回程度の追加デモだけでSim-to-Real Gapを補正できる、というのが本プロジェクトの狙いです。この設計が、小規模チームや限られた実装条件でも現実的に前進しやすい根拠になります。
クール2以降のBehavior Cloning実装から、クール5〜9でのSim2Real・Fine-tuningの実機記録まで、Arpableの連載とYouTube動画でリアルタイムに公開していきます。現時点(2026年6月)ではReal-to-Realの基盤づくりが主軸ですが、それはゴールではなく、次のステージへの助走です。
「自分たちのチームでも、これができるだろうか」——そう思った方に、この記事は届いています。 小さなチームが、現実のロボットを「見て・判断して・動く」知能へと育てていく過程を、ぜひ一緒に追ってください。次の記録は、すぐそこにあります。
専門用語まとめ
主要概念を短く整理。理解のための用語集。
- Behavior Cloning(模倣学習)
- 人間がリーダーアームを操作して見せた「お手本」の映像と関節状態をペアデータとして記録し、AIに「このカメラ映像→この関節状態」の変換パターンを学習させる手法です。強化学習と異なり、報酬設計や無数の試行錯誤が不要なため、小規模チームでも現実的に導入しやすい手法です。
- リーダーアーム / フォロワーアーム
- SO-101を構成する2本1セットのアームです。リーダーアームは人間が手で動かす「お手本側」で、学習データ生成専用です。フォロワーアームはデータ収集時はリーダーを模倣し、学習完了後はカメラ映像だけを入力として自律動作する実行機です。
- Ground Truth(成功判定の参照基準)
- Real-to-Realフェーズで達成した「3回連続成功」の実績をもとに整理する参照基準です。軌跡データをそのまま投入するのではなく、Sim2Realで「何を達成できれば成功か」を定義するための根拠として使われます。シミュレーター内のタスク定義と成功条件の設定に用います。
- URDF(Unified Robot Description Format)
- ロボットの形状・重量・重心・関節の可動域・摩擦係数を記述するXMLファイルです。Isaac SimにURDFを読み込ませることで「物理的に意味のある仮想SO-101」が生成されます。URDFや物理パラメータの精度がSim2Real成功率に直結します。
- Domain Randomization(領域ランダム化)
- シミュレーション内の物体位置・照明・テクスチャ・摩擦係数などをランダムに変化させながら学習させる手法です。「あらゆる状況を経験させる」ことで「想定外に強い汎化性能」を持つモデルが生まれます。
- Sim-to-Real Gap
- シミュレーションで学習したモデルを実機に転送した際に生じる「物理特性のズレ」と「視覚特性のズレ」の総称です。物理のズレは関節の個体差・ガタつき、視覚のズレはカメラのノイズ・光の反射の差異から生じます。Fine-tuningで補正します。
- Fine-tuning(微調整)
- Sim2Realで学習済みのモデルを実機に転送した後、実機で10〜30回の追加デモを収集して少量の本物データで追加学習する工程です。Sim-to-Real Gapを補正し、実機成功率85%達成を目指します。「再学習」ではなく「微調整」であり、少量データで足ります。
よくある質問(FAQ)
実装時に迷いやすい論点を先回りして整理。補足と確認の章。
Q1.
Behavior Cloningと強化学習は、どう使い分ければよいですか?
A1.
優劣ではなく、使う場面が違います。Behavior Cloningは人間のお手本を短時間で学ばせたい場面に向き、強化学習はシミュレーション内で大量に試行錯誤させ、汎化性能を高めたい場面に向きます。
- Behavior Cloningは報酬設計が不要で、少量データで学習できる反面、汎化性能が低いです。
- 強化学習は汎化性能が高くなりうる反面、報酬設計の難しさと膨大な試行回数が必要です。
- 本プロジェクトの解決策は、Behavior Cloningで基盤を作り、Sim2Real(Domain Randomization)で汎化性能を後から補完することです。
関連:データ収集フェーズへ
Q2.
リーダーアームはSim2RealフェーズやFine-tuningでも使いますか?
A2.
Sim2Realフェーズではリーダーアームは使いません。Fine-tuningでは再び使います。
- Sim2Realフェーズはシミュレーター内で完結するため、物理的なリーダーアームは不要です。
- Fine-tuningでは実機での追加デモ収集が必要なため、リーダーアームを再使用して10〜30回のデモを収集します。
- リーダーアームの役割は一貫して「学習データの生成専用」です。
関連:Fine-tuningへ
Q3.
URDFファイルはどうやって作るのですか?
A3.
SO-101の実装では、まずHugging FaceのLeRobotドキュメントとGitHub上の公式手順を参照し、必要に応じてSO-ARM100/101系の実装資産やSeeed Studio Wikiも確認します。本プロジェクトでは、これらの公式リソースをベースにしつつ、自分たちの個体・環境に合わせて調整していきます。ゼロからURDFや設定一式を自作する前提ではありません。
- LeRobotの公式ドキュメントやGitHub手順を起点に、SO-101向けの実装資産を確認します。
- 必要に応じて、SO-ARM100/101系リポジトリやSeeed Studio Wikiも参照し、実機個体差(関節の摩擦・ガタつきなど)を反映した調整を行います。
- この調整作業がクール5(デジタルツイン構築)の主要タスクの一つです。
Q4.
Fine-tuningはなぜ10〜30回という少量のデモで足りるのですか?
A4.
Sim2Realで「汎化の骨格」がすでに完成しているため、Fine-tuningは骨格の微調整だけで済むからです。
- Sim2Realの数百万回学習で「様々な状況に対応する能力」は既に獲得されています。
- Fine-tuningで補正するのは「現実の物理特性・視覚特性へのわずかな適応」だけです。
- ゼロから学習するのではなく、強いモデルに「現実の感覚」を少しだけ上書きするイメージです。
関連:Fine-tuningへ
Q5.
このプロジェクトの実装結果はどこで確認できますか?
A5.
Arpableの連載記事・YouTube動画・X(旧Twitter)・LinkedInでリアルタイムに公開します。
- 各クール終了時にクールALT(社内LT)を開催し、成果と失敗の全記録をArpable記事として公開します。
- 制作過程の動画をYouTubeで公開します(失敗シーンも含みます)。
- 2026年11月:THE PACKAGE v1.0(Real-to-Real完結版)公開予定。
- 2027年11月:THE PACKAGE最終版(Sim2Real完結版)公開予定。
参考サイト・出典
本文の理解を支える一次情報と関連記事。確認用の参照先。
一次情報
あわせて読みたい
SO-101実践ハブから次に進むための3本。機材準備、Sim2Real設計、Isaac Sim実装へ接続する。
更新履歴
- GSCデータをもとに、SO-101実践ハブとして冒頭定義、TLDR、内部リンク導線、H2見出しを再設計。SO-101系6本+Physical AIハブ+プロジェクト起点記事を含む最大8本の回遊導線を追加。
- 「Behavior Cloning学習」の重複削除、成功条件・数値表現の整理、Sim2Real/Isaac Labまわりの記述を最新構成に合わせて調整。
- 「Behavior Cloning学習」の動画導線を改善。
- 初版公開。Behavior Cloning、Real-to-Real、Sim2Real、Domain Randomization、Fine-tuningの設計原理を整理。


-640x360.jpg.webp)





