


身体性AIロボット実装ガイド:LLMとVLAが拓く脳・反射神経の統合設計【2026年版】
身体性AIの本質は、LLMの高次計画とVLAの低遅延な行動制御を、Jetson Thor・micro-ROS・TensorRT・Isaac Simといった実装基盤でつなぐことにあります。
自社ロボットにLLMやVLAを入れたいが、「どこまでをクラウドに任せ、どこからをロボット内で完結させるべきか」で止まっている方も多いはずです。AIがチャットボットや画像生成という「画面の中」に留まる時代は終わり、この記事では2026年の実務レベルで、脳・反射・神経網・シミュレーション・安全制御をどう設計すればよいかを具体的に整理します。
✅ この記事の結論
- 実装の核心:LLMを上位計画、VLAを低遅延な行動制御として組み合わせる二層構造が、身体性AIロボットの中核になっています。
- 基盤技術:Jetson Thor、micro-ROS、TensorRT、Isaac Simのような実装基盤が、ロボットの脳・反射・学習ループを支えています。
- 実務上の壁:遅延、安全制御、データ収集、Sim-to-Realの橋渡しが、社会実装の成否を左右します。
※システム1/2は、人間で言えば「反射的に動く回路」と「考えてから動く回路」の二層構造です。FP4/FP8の数値は理論ピーク値であり、実効性能はモデルや設定に依存します。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

まず全体像から入りたい方は生成AIロボット革命:フィジカルAIは「真のパートナー」へ進化する、技術全体を俯瞰したい方はAI×ロボット革命:3つの核心技術と未来展望、現実のロボット事例を見たい方はフィジカルAIのビジネス最前線:常識を覆す最新ロボット5選も先に押さえておくと理解が深まります。
AIは「肉体」を手にして初めて、世界を理解する
身体性AIの出発点は、言葉を現実の感覚と結びつけることにあります。
「これは従来の“工場ロボット”とは別次元の話だ」。私たちがこの分野の研究を深める中で、最初に行き着いた確信がこれです。
かつてのロボットは、あらかじめ決められた座標へ、決められた速度で動く「正確な操り人形」に過ぎませんでした。しかし、今私たちが追い求めているのは、ロボットが自ら見て、考えて、未知の環境でも行動するための「自律的な知能体系」です。
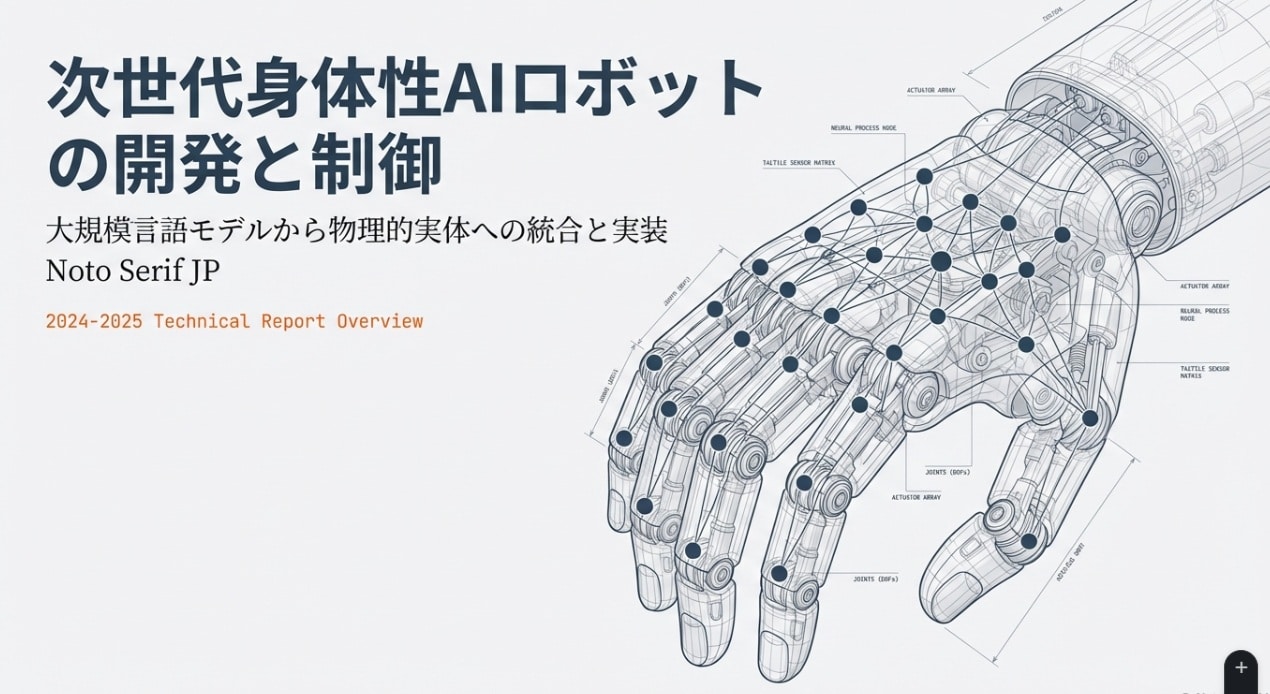
多くの研究者が、身体性AIをAGI(人工汎用知能)への有望な道筋と見なしている理由は、AI界の難問「記号接地問題」に正面から向き合えるからです。
※記号接地問題とは、言葉(記号)が“現実の感覚や経験”と結びつかないと、理解が空回りするという問題です。
例えば、AIに「リンゴ」という言葉を100万回学習させても、重力で手が沈み込む感覚や、皮の滑りやすさを知らなければ、それは空虚な「記号」でしかありません。物理世界との生々しい相互作用を通じてこそ、知能は真の意味を獲得します。「身体を伴って初めて賢くなる」。この思想こそが、デジタル空間の天才を、現実世界の相棒へと変えるエンジンなのです。
驚くべきは、その情報密度です。物理世界からのフィードバックは、テキスト情報の比ではありません。視覚・触覚・力覚が同時に流れ込む身体性AIでは、テキスト中心のAIよりもはるかに高密度な実世界データがSoCへ流れ込みます。これは、ロボット知能が「単語」ではなく「現実との相互作用」から学ぶことを意味します。
※SoC(System-on-a-Chip)は、CPU/GPU/AIアクセラレータなどを1つのチップに統合した「頭脳そのもの」です。
意思決定の二重奏:LLMによる「熟考」とVLAによる「反射」
最新の身体性AIは、LLMの計画力とVLAの即応性を組み合わせる二層構造へ向かっています。
ロボットはどうやって“次に何をするか”を決めるのか。最新のアーキテクチャでは、人間と同様に「二つの思考回路」を使い分けています。──“考えてから動く脳”と、“見た瞬間に動く反射”。ここが身体性AIの核心です。
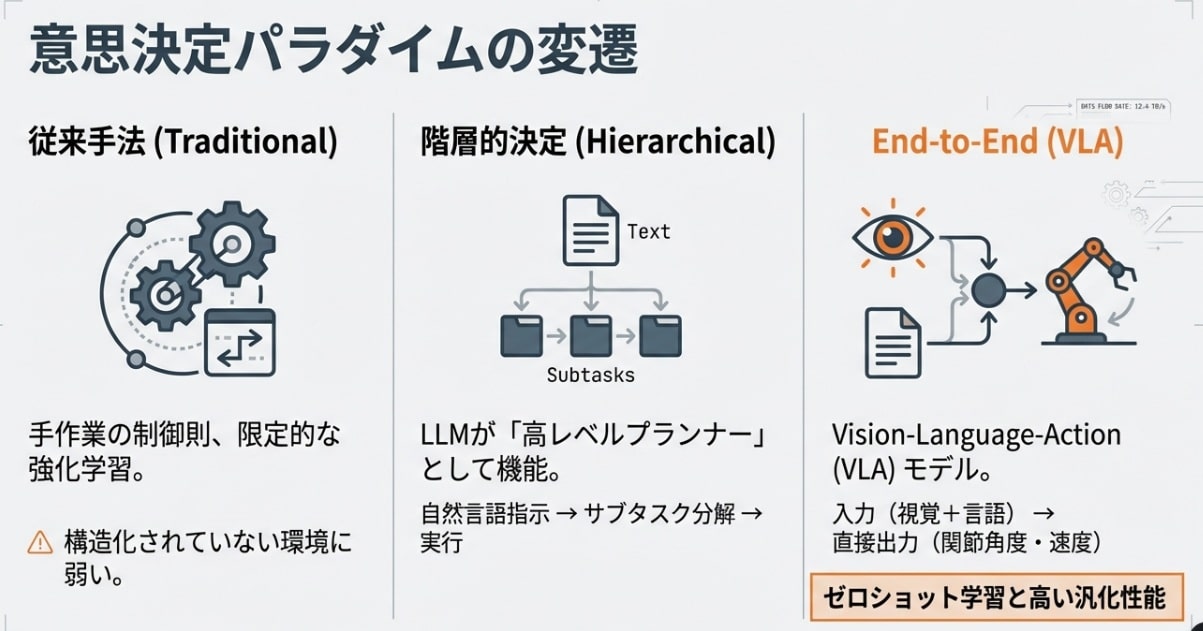
階層的決定:LLMが“プロジェクトマネージャー”になる
これは、LLMを「上位のプランナー(脳)」として据える方式です。
例えば、人間が「朝食の準備をして」と曖昧な指示を出す。するとLLMがその意図を汲み取り、「冷蔵庫へ行く」「卵を取り出す」「コンロに火をつける」といった具体的なサブタスクへ分解します。
高度な推論と常識を持つLLMが、複雑な工程をマネジメントし、現場の実行ユニットへ指示を下す。このアプローチにより、ロボットは初めて「言葉の裏側にある目的」を理解し始めました。
エンドツーエンド決定:VLAが“アスリートの反応”を実現する
そのための技術がVLA(Vision-Language-Action)モデルです。カメラ映像(Vision)と言葉(Language)を直接入力し、そのままロボットの筋肉である「関節角度(Action)」を出力します。
これは、飛んできたボールに対して「腕を何度にして…」などと考えずに反応する、熟練アスリートの反射神経に似ています。例えば、キッチンでカメラ付きモバイルロボットが「倒れかけた鍋を支える」シーンでは、LLMに相談している暇はありません。VLAが「視覚と言葉」から直接「関節角度の連続値」を出力し、「見た瞬間に身体が最適解を選んで動く」ことで、初めて事故を防げます。
「見た瞬間に、身体が最適解を選んで動く」。この直感こそが、不確実な現実世界で滑らかな動きを実現する鍵となります。一方でLLMは、その直感が迷わないように「目的と段取り(作戦)」を組み立てる役です。
しかし、エンジニアには深刻な悩みがあります。それが説明可能性(Explainability)です。「なぜロボットは突然右に動いたのか?」
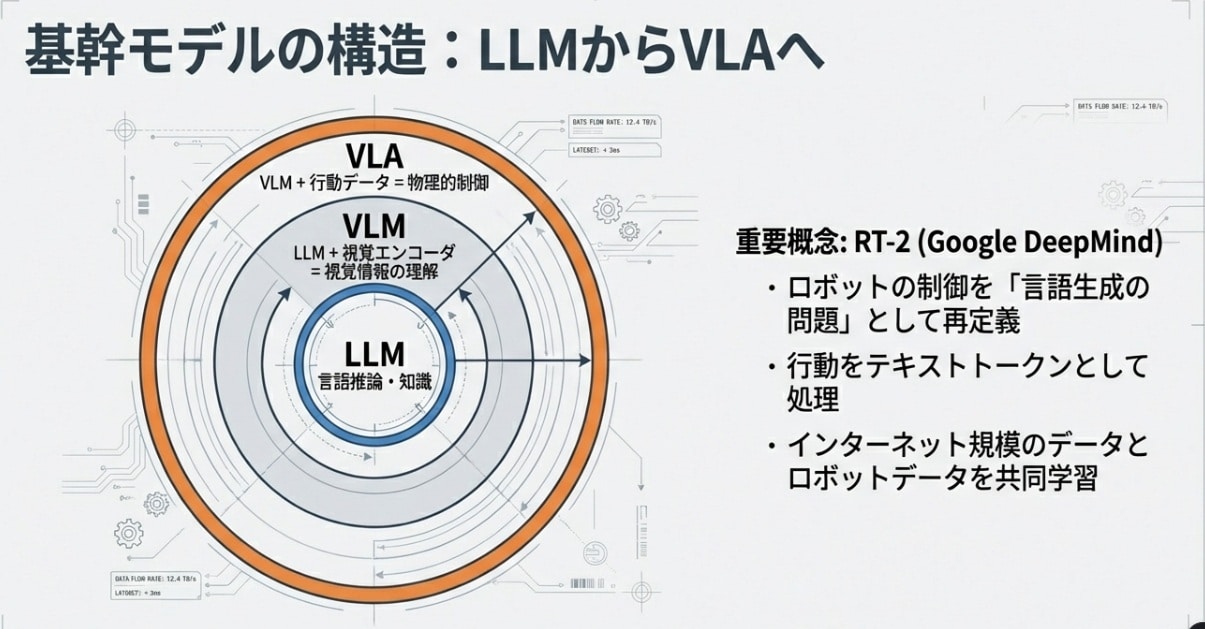
階層型ならログを辿れますが、VLAは巨大なニューラルネットワークのブラックボックスです。そこでGoogleのRT-2のように、行動を「トークン列」として扱い、物理制御を言語生成に近い枠組みで学習させることで、汎用性と説明可能性を両立させる試みが進んできました。現在は、この流れがより統合度の高いロボティクス基盤モデルへと発展しています。
※最新のVLAの多くは、ロボットの関節角度などの連続値を離散化し、言語トークンと同じ空間で扱うことで、「言語を理解するモデルがそのまま行動を生成する」統合的な推論を実現します。RT-2はその代表的な先駆けであり、以降のVLA研究の基礎となっています。
怪物の心臓部:Jetson Thorが変えるエッジ演算の限界
身体性AIでは、クラウドではなくロボット自身の頭部SoCで推論を完結させることが決定的に重要です。
「LLMが上位計画、VLAが反射を担う二層構造はわかった。では、その膨大な計算をロボットのどこで回すのか?」──ここからがハードウェアとインフラの話です。クラウド任せではレイテンシが致命的になるため、「LLM+VLAの二層構造をロボットの頭の中で回し切る」心臓部として、Jetson Thorが登場します。
身体性AIにおいて、クラウドへの通信遅延(レイテンシ)は致命傷となります。ロボットが転倒しそうなとき、数秒後のクラウドからの回答を待つわけにはいきません。すべての演算は、ロボットの「頭の中」で完結しなければならないのです。
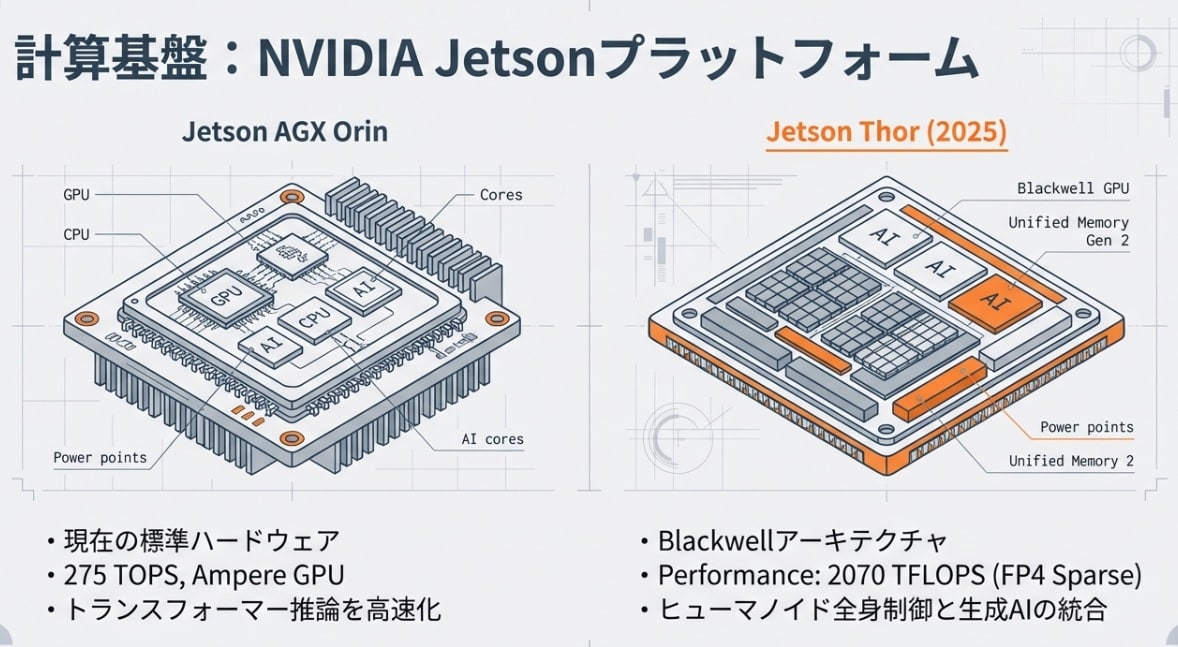
2070 TFLOPSという異次元のパワー
現在、業界の地図を塗り替えているのがNVIDIA Jetson Thorです。前世代のJetson Orin(275 TOPS)でも驚異的でしたが、Thorは最大 2070 FP4 TFLOPS(スパース)/1035 FP8 TFLOPS級のAI演算という、文字通り桁違いの性能を叩き出します。
※“スパース”は、計算のムダを省いて性能を引き上げる最適化(疎な演算)です。
AI推論に特化したFP4演算において2070 TFLOPSという数値は、かつてデータセンターにしか存在しなかった計算資源を、わずか130Wの手のひらサイズのSoCで実現したことを意味します。家庭用ゲーム機(PS5等)の公称性能はグラフィックス描画向けの高精度(FP32)演算であり、AI推論専用のFP4演算とは性質が異なるため直接比較はできません。重要なのは、「認識・判断・行動決定」というAI推論の全工程を、ロボットの頭の中で低遅延で回し切れる水準に初めて到達したという点です。
この「怪物」の登場により、これまでクラウド前提だった大規模生成AIや高度なマルチモーダル推論を、ロボットのエッジ側で現実的に扱える水準へ近づけました。重要なのは、単に演算性能が高いことではなく、ロボットの現場で「認識し、判断し、行動する」一連の推論を低遅延で回しやすくした点です。
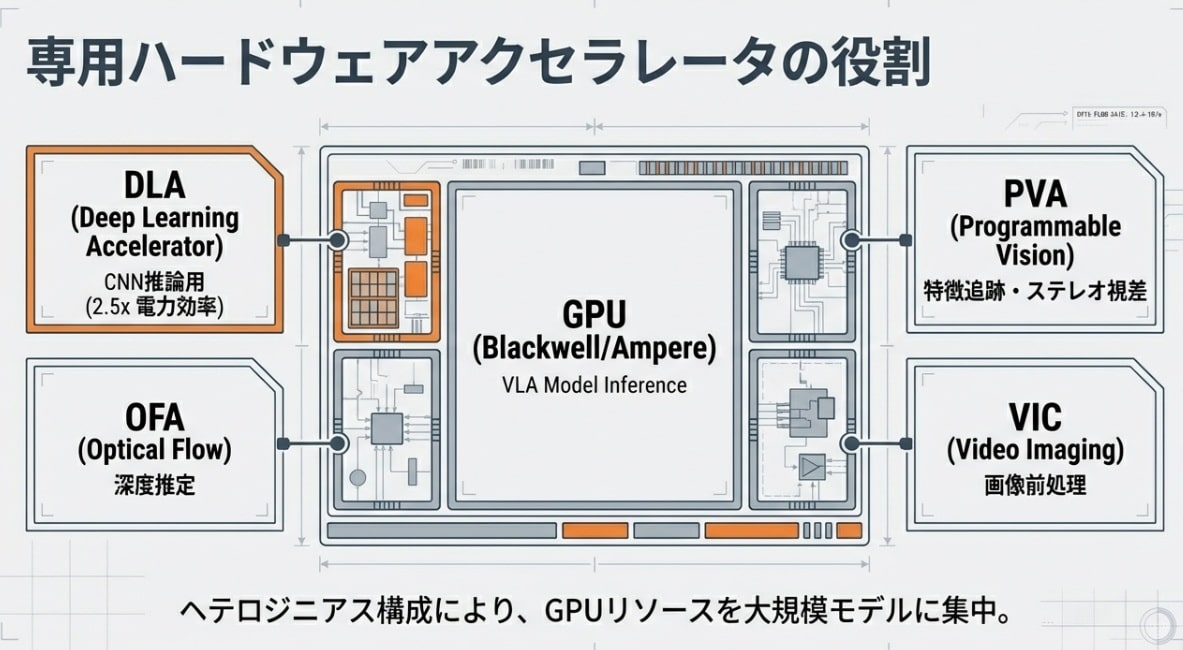
GPU一辺倒ではない「専門アクセラレータ」の設計思想
ロボットには電力と発熱の厳しい制約があります。ただGPUをフル回転させるだけでは、すぐにバッテリーが尽き、機体はオーバーヒートしてしまいます。Jetsonの真の凄さは、脳の中に視覚野や運動野があるように、「得意分野で分担する」インフラ設計にあります。
| エンジン名 | 役割(ミッション) | 技術的メリット |
|---|---|---|
| GPU (Blackwell) | LLM / VLMの推論、高次計画 | 2000TFLOPS超の並列演算能力 |
| DLA (Deep Learning Accelerator) | CNN系処理(物体検出・セグメンテーション) | GPUより高い電力効率で推論を実行(効果はタスクや設定に依存) |
| PVA (Programmable Vision Accelerator) | 画像処理、特徴点抽出、ワーピング | メインプロセッサの負荷を下げ、遅延を最小化 |
| OFA (Optical Flow Accelerator) | 動体の動き検知、オプティカルフロー計算 | ハードウェアによる高速な動的環境理解 |
この設計により、メインのGPUはLLM/VLMという「最も重い思考」にリソースを集中させ、他の「地味だが重要な視覚処理」は専門のアクセラレータに逃がす。このインフラの最適化こそが、身体性AIを現実的に動かすための絶対条件なのです。
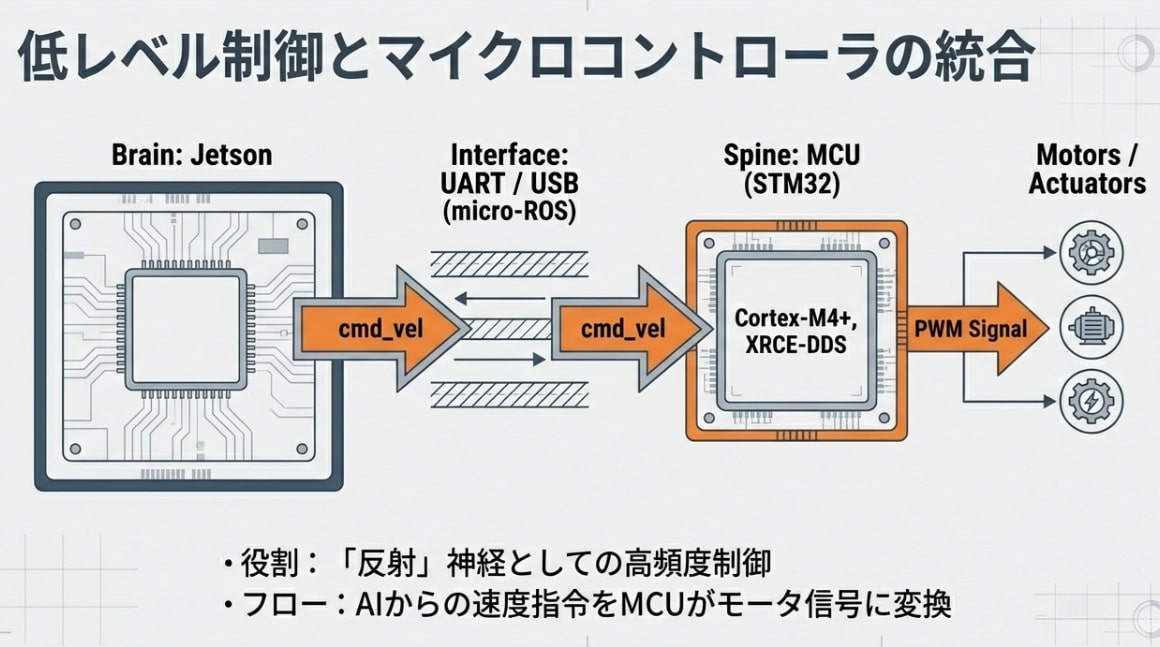
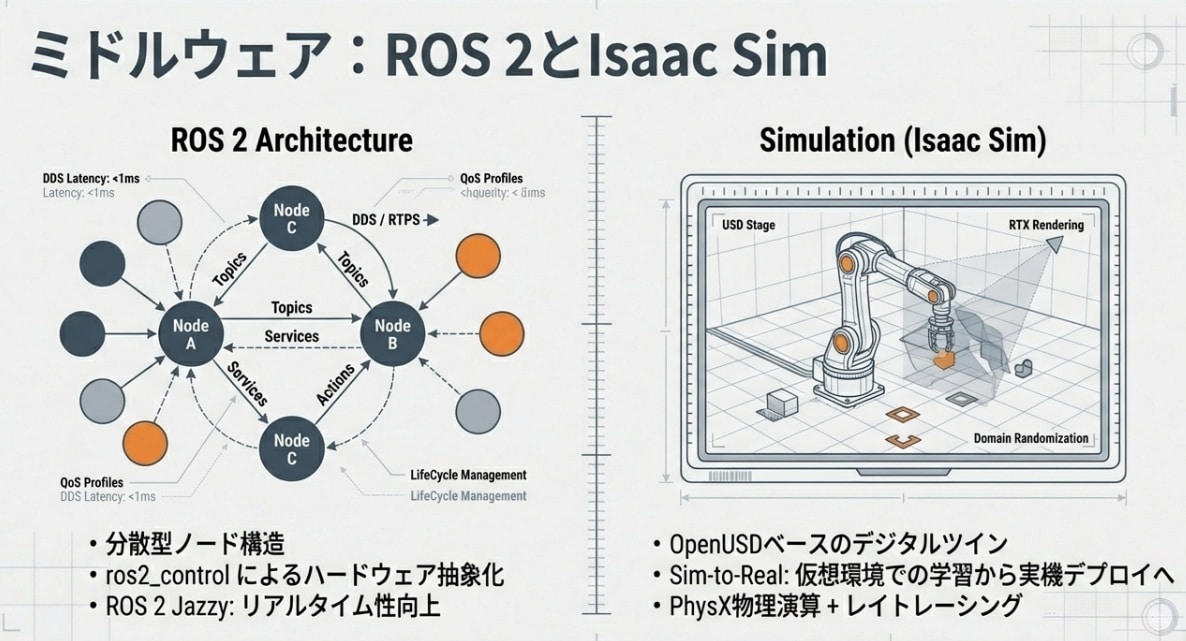
神経網の構築:SoCとMCUを繋ぐ「micro-ROS」の衝撃
ロボットの知能を実際の動作へ変えるには、SoCの高次判断とMCUの1kHz級制御をつなぐ神経網が必要です。
強力な脳(Jetson Thor)だけでは、ロボットは動きません。LLMやVLAがどれだけ賢く計画しても、その指令が1kHz級のモーター制御ループまで届かなければ、現実世界では「もたつくロボット」にしかなりません。ここで登場するのが、SoCの高次判断とMCUの反射制御を結ぶmicro-ROSという神経網です。
人間が「熱い」と感じて手を引くとき、脳まで信号が届く前に脊髄で反射が起きるように、ロボットにもミリ秒単位の「反射神経」が必要です。この「高次の思考(SoC)」と「物理的な駆動(MCU)」をどう同期させるか。ここに、ロボティクス・インフラの真髄があります。
なぜmicro-ROSが「インフラの救世主」なのか
これまで、ロボットのメインPC(SoC)と各関節のモーター制御マイコン(MCU)の間には、深い溝がありました。OSを搭載した強力なPCと、限られたリソースしかないマイコンでは、共通の言語で話すことが難しかったのです。
そこで登場したのがmicro-ROSです。これは、リソースの少ないMCU上でも動作するよう最適化されたROS 2のクライアントライブラリです。
- シームレスな通信:Jetson上のAIプロセスと、STM32等のマイコンが「同じROS 2トピック」で直接対話できる。
- 決定論的制御:1kHz(1ミリ秒周期)以上の超高速モーター制御ループを維持しながら、上位のAI指令を柔軟に反映。※この周期が必要なのは、手足のブレや遅れが“そのまま危険”になるからです。
- リソース効率:わずか数十KBのRAMでも動作し、DDS(Data Distribution Service)(ROS 2で使われる標準的な通信基盤)プロトコルを用いて安定した通信を実現。
「右手を5.2cm前へ、速度30%で」というJetsonからの抽象的な指示を、micro-ROSという神経網を通じてMCUが受け取り、瞬時にモーターの電流値へと変換する。この垂直統合インフラこそが、ロボットに「アスリートのようなキレ」をもたらすのです。
(実装の要点は「脳=方針」「脊髄=瞬発」。役割分担で遅延を殺します。)
“` “`html
デジタルツインが「数万年の経験」を1日で授ける
身体性AIの学習速度を引き上げる鍵は、高精度シミュレーションによる並列学習にあります。
ハードウェアを1台作り、1から学習させていては、AIの進化スピードには追いつけません。そこで不可欠なインフラが、NVIDIA Isaac Simに代表される超高精度シミュレーターです。
これは単なるゲームのような画面ではありません。重力、摩擦係数、剛性、光学的なカメラ特性までを再現した「物理的な写し鏡」です。
仮想空間で1,000台のロボットを並列稼働させれば、現実世界の数万時間分に相当する「失敗と成功の経験」をわずか数時間で積み上げることができます。ここで磨かれたAIの重み(Weights)を実機のJetsonへ転送する。これが、2026年現在の開発スタンダードです。※Weights(重み)は、学習で獲得した「知識の中身(学習済みパラメータ)」のことです。
Sim-to-Realをさらに深く理解したい方は、データが知能を育てる。Physical AI 2026:仮想と現実の双方向ループもあわせて読むと、学習ループの全体像がつかみやすくなります。
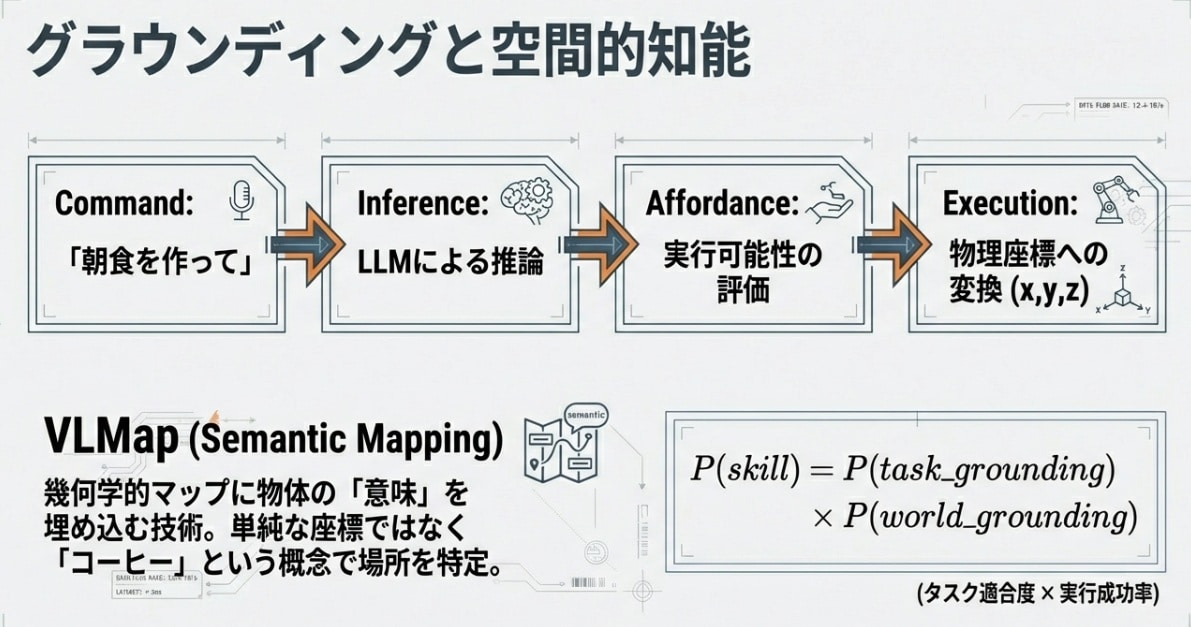
「意味」の地図:VLマップが空間認識を再定義する
最新のロボットは、幾何学的な地図だけでなく、意味ラベル付きの空間理解へ進みつつあります。
ロボットが現実世界を移動するとき、これまでは「ここに壁がある(点群)」という幾何学的な地図しか持っていませんでした。しかし、それでは「キッチンに行って、青いカップを持ってきて」という指示には答えられません。
セマンティック(意味的)な世界理解
最新の身体性AIは、VLマップ(Vision-Language Map)(意味ラベル付き3D地図)を構築します。これは、カメラで捉えた映像にVLM(視覚言語モデル)をリアルタイムで適用し、「ここはコーヒーを淹れる場所」「これは割れやすい陶器」といった意味ラベルを3D空間の座標に紐づけて保存する技術です。
これにより、ロボットの脳内地図は単なる障害物マップから、人間と共通の概念で記述された「意味の宝地図」へと進化しました。指示された単語と、地図上の意味情報をマッチングさせることで、未踏の場所でも「あそこにカップがありそうだ」という推論が可能になるのです。
アフォーダンス評価:ロボットが己の「限界」を知る瞬間
身体性AIにおける安全性の核心は、「意味的に正しい」だけでなく「物理的に可能か」を必ず検証することです。
AIが物理的な身体を持つ上で、最も重要な能力。それが「自分に何ができるか(アフォーダンス)」を正しく自己評価することです。

チャットAIなら「空を飛ぶ方法」を嘘(ハルシネーション)で答えても笑い話で済みますが、ロボットが「自分ならこの崖を飛び越えられる」と誤認すれば大事故になります。
最新の制御モデルでは、AIの「やりたいこと(意図)」に、物理的な「できる確率(実現性)」を掛け合わせる、いわば「物理的な検閲」をリアルタイムで行っています。数式で書くと以下のようになります。
![\[P(\\text{Action}) = P(\\text{Intent} | \\text{Instruction}) \\times P(\\text{Feasibility} | \\text{Environment}, \\text{Body})\]](https://arpable.com/wp-content/ql-cache/quicklatex.com-eb0fffb5dbc6e491e6303cc675af9a5d_l3.png "Rendered by QuickLaTeX.com")
「指示に対する意味的な正しさ(Intent)」と、「現在の環境と自身のスペックで物理的に可能か(Feasibility)」。この二つの確率を掛け合わせ、一定の閾値を超えたときのみ、モーターへ電流が流れます。実装レベルでは、LLMやVLAからの候補行動ごとにこのスコアを算出し、「しきい値未満の行動はそもそも制御系に送らない」というフィルタを挟むイメージです。このアフォーダンス評価という安全弁こそが、AIを信頼できる「相棒」へと昇華させるのです。(要するに「言葉として正しい」だけでは動かさず、「身体として可能」までチェックしてから動かす、という話です。)
開発現場のリアリティ:Python(脳)とC++(筋肉)の共生
身体性AIの現場では、脳と筋肉に相当する処理を言語レベルでも役割分担する設計が現実的です。
「AIロボットをどう書くか?」という問いに対し、報告書は非常に実践的な答えを示しています。それは、脳と反射の構造をプログラミング言語の使い分けにそのまま投影することです。身体性AIの現場では、単一の言語に固執するのではなく、役割ごとに言語を使い分ける設計が現実的です。
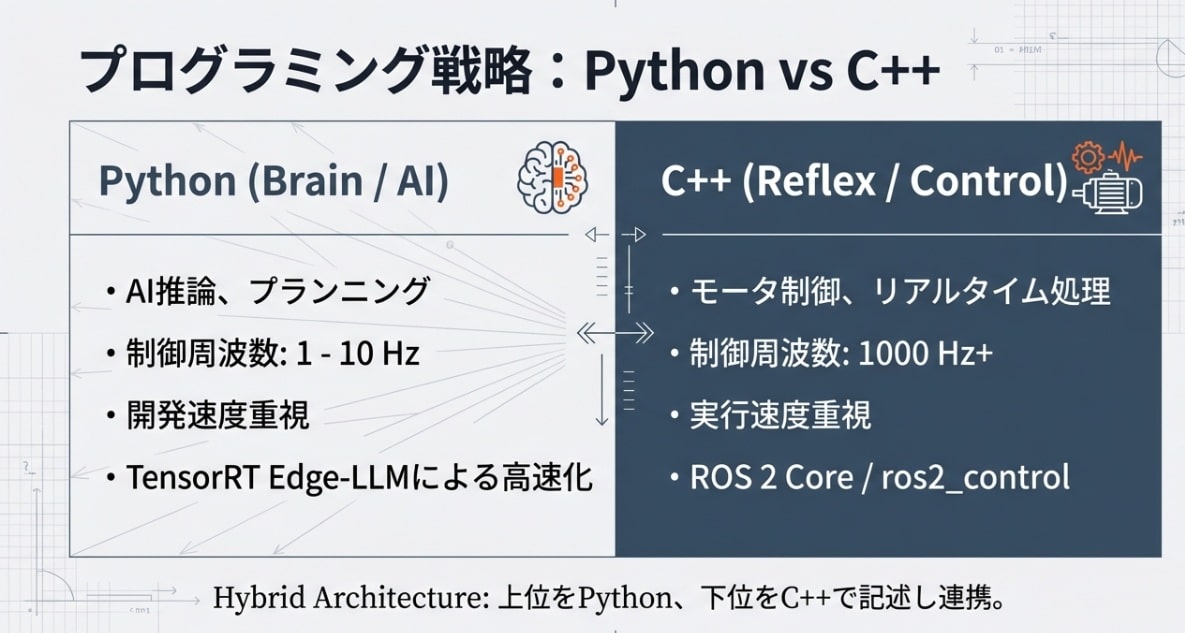
- Python(高次思考):開発スピードが速く、PyTorchやTensorFlowといったAIエコシステムをフル活用できる。LLMの推論、VLMによる意味理解、上位のプランニングなど、「高度だが柔軟性が求められる思考」を担います。
- C++(俊敏な実行):実行速度とリソース管理が命。1kHzを超えるモーター制御ループ、LiDAR点群の高速フィルタリング、SoCとMCU間の低遅延通信など、「一瞬の遅れも許されない物理実行」を担います。
この二つの世界を繋ぐのがROS 2の通信基盤です。Pythonで生成された「知的な戦略」を、C++が「強靭な筋力」へ変換する。この二重奏こそが、複雑なタスクを難なくこなすロボットの生存条件なのです。
「遅延」という死神との戦い:TensorRTによる極限のダイエット
身体性AIにおいて、推論の遅延は性能問題ではなく安全性の問題です。
身体性AIにおいて、最大の敵はハッカーでもバグでもありません。それは「レイテンシ(遅延)」です。
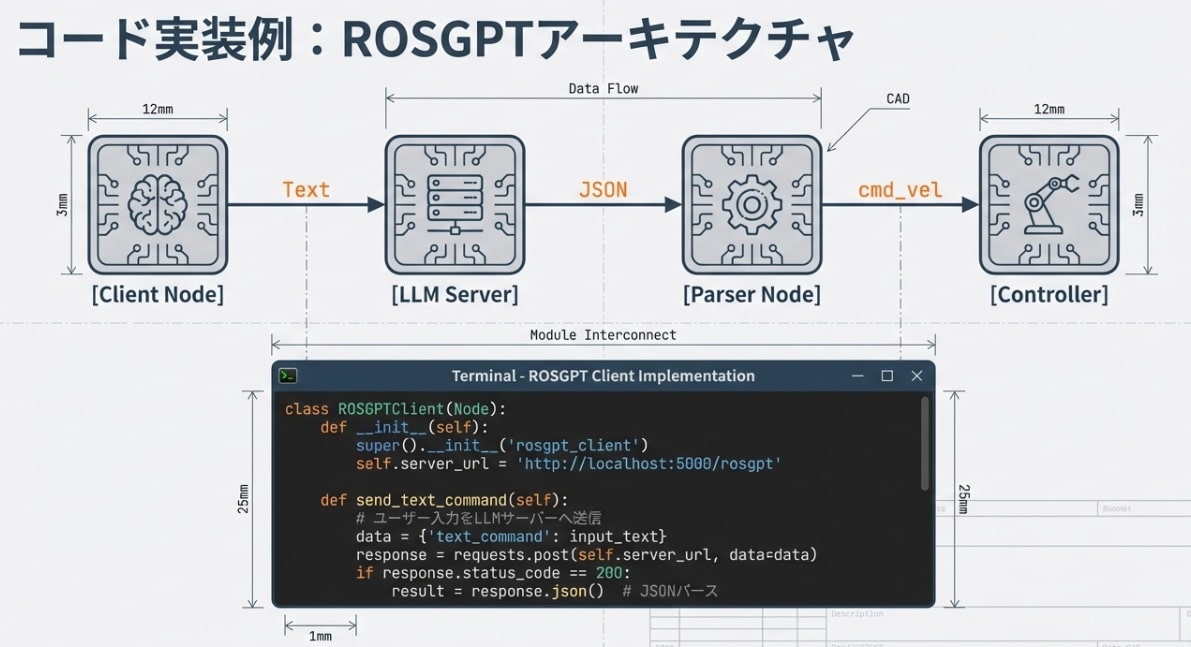
報告書によれば、70億パラメータ(7B)級のLLMを未最適化の状態でロボット上で動かすと、推論に数秒を要することがあります。ナイフや重い資材を扱うロボットが数秒間「フリーズ」する。これはもはやホラーです。
TensorRT Edge-LLMによる魔法
この致命的な遅延をミリ秒単位まで削り落とすのが、NVIDIA TensorRTです。これはAIモデルに「ダイエットと筋トレ」を施す、極限の最適化エンジンです。
- 量子化 (FP16/INT8): 演算の精度をあえて落とすことで、計算速度を劇的に向上。
- レイヤー融合: 複数の計算ステップを一つにまとめ、メモリアクセスの無駄を排除。
- カーネル自動チューニング: 搭載されたGPU(Blackwell等)に最適な計算手法を自動選択。
さらに、最新のTensorRT Edge-LMは、C++から直接AIモデルを呼び出すことを可能にします。Pythonのオーバーヘッドすら削ぎ落とした「思考の純粋化」。これにより、ロボットは初めて人間と等身大のレスポンス速度を手に入れるのです。
社会実装への“3つの巨大な壁”
研究室で動くロボットを社会で使えるロボットに変えるには、データ・遅延・安全制御の壁を越える必要があります。
研究レベルでは、「現場で初めて遭遇した物体をその場で学習し、短時間で適応する」オンデバイス学習の実現が目指されており、Jetson ThorとmicROSの垂直統合はその土台となる可能性を秘めています。しかし研究室ではSFのような動きを見せるロボットも、社会という荒野へ出れば多くの壁にぶつかります。
報告書が最後に突きつける現実は、極めて冷静です。
1. データ収集の「地獄」
インターネットのテキストデータと違い、ロボットの行動データは「実際に動かして」集めるしかありません。成功データだけでなく「失敗データ」も重要です。数百万時間の高品質なデータをどう集めるか。「データスケーリング」の壁が立ちはだかっています。
2. リアルタイム性の呪縛
前述の通り、遅延は命取りです。複雑な推論を維持しながら、如何に100ms以下のレスポンスを維持し続けるか。ハードウェアの進化とソフトウェアの軽量化、その果てしない追いかけっこが続きます。
3. ハルシネーション(幻覚)の物理的代償
AIが「そこにドアがある」と誤認して壁に激突する。あるいは、人間を物体と誤認して接触する。デジタル空間での誤変換は笑えますが、物理空間での誤認は「事故」になります。物理的安全層(Safe Control Layer)の確立が、社会実装の最低条件です。具体的には「危険なら停止/速度制限/再計画」を強制する“最後の関所”です。
エピローグ:システム1とシステム2の統合が描く未来
今後の主戦場は、反射的な制御と熟考型の推論を、ひとつの身体の中でどう統合するかに移ります。
今後主流になるのは、反射的な制御(システム1)と熟考型(システム2)を完全に融合させた「ハイブリッド・フィジカル・エージェント」です。
それはまさに、私たち人間が自然に行っている「無意識の動作」と「論理的な思考」の連携を、シリコンとモーターで再現する試みに他なりません。
2026年、身体性AIは「特定の作業をこなす機械」から、私たちの意図を汲み取り、物理的な制約を自ら乗り越えて目的を達成する「真のパートナー」へと変貌を遂げようとしています。
「知能は、冷たいサーバーラックの中ではなく、生暖かい現実世界の摩擦の中に宿る。」
私たちArpableは、この「脳と肉体の統合」が生む熱狂の最前線を、これからも追い続けます。
専門用語解説(Glossary)
- 1. Jetson Thor(ロボット向け次世代SoC)
- NVIDIAが発表した、ヒューマノイドロボット向け次世代SoC。最大 2,070 FP4 TFLOPS(スパース)/1035 FP8 TFLOPS級のAI演算を備え、エッジでのLLM/VLA推論を可能にする。※SoC(System-on-a-Chip)は、CPU/GPU/AIアクセラレータなどを1つのチップに統合した「計算中枢」です(ロボットの頭脳に相当)。
- 2. VLA(Vision-Language-Action)モデル
- 視覚情報と言語指示を一つのネットワークで統合し、ロボットの具体的な物理行動(関節トルク等)を直接出力する基盤モデル。ロボットにおける「直感的な反射」を司る。
- 3. micro-ROS
- リソース制約の厳しいマイコン(MCU)をROS 2ネットワークに参加させるためのミドルウェア。Jetson等のメイン脳(SoC)と、手足の末梢神経(MCU)を繋ぐ決定論的な通信路を提供する。
- 4. アフォーダンス評価(Affordance Evaluation)
- 環境が提供する「行動の可能性」をAIが自己評価するプロセス。「その物体は今の腕の長さで掴めるか」といった物理的整合性を判定し、ハルシネーションによる危険行動を抑制する。
- 5. VLマップ(Vision-Language Map)
- 幾何学的な3D地図に、VLM(視覚言語モデル)による意味情報を埋め込んだ次世代の地図。ロボットは点群ではなく「コーヒーメーカーがあるエリア」といった概念で空間を認識できる。
よくある質問(FAQ)
Q1. なぜロボットにLLM(大規模言語モデル)が必要なのですか?
A1. 曖昧な人間の指示を、具体的な行動計画へ分解できる汎用性が得られるからです。
- 従来の固定プログラム型ロボットでは難しかった目的理解が可能になります。
- 身体性AIでは、LLMが上位計画、VLAが即応行動を担う構成が有力です。
関連:LLMとVLAの統合へ
Q2. Jetson Thorの推論速度は、従来の産業用PCと何が違うのですか?
A2. 最大の差は「電力効率」と「専門アクセラレータを含む垂直統合設計」にあります。
- 単に速いだけでなく、DLAやPVAなどの専用回路で処理を分担できます。
- ロボット内部で低遅延な推論を回しやすい点が重要です。
Q3. micro-ROSを使わずにROS 2だけで制御はできませんか?
A3. 高機能SoC側だけなら可能でも、末端MCUまで含めた低遅延制御ではmicro-ROSのような仕組みが重要になります。
- 標準のROS 2はLinuxなどのリッチなOSを前提としています。
- micro-ROSは、マイコン側でROS 2通信モデルを扱うための有力な標準実装です。
関連:micro-ROS節へ
Q4. VLAモデルにおける「ハルシネーション(幻覚)」はどう防ぐのですか?
A4. 「意味的に正しいか」に加えて、「身体的に実行可能か」を判定する安全層を入れます。
- 本記事で解説したアフォーダンス評価が代表例です。
- 危険なら停止・速度制限・再計画を強制するSafe Control Layerが重要です。
関連:アフォーダンス評価へ
Q5. 開発にはPythonとC++のどちらを学ぶべきですか?
A5. 身体性AIの開発では、両方が必要です。
- Pythonは推論やプランニング、C++はリアルタイム制御や高速処理に向きます。
- ROS 2を軸に両者をつなげる設計力が重要です。
関連:開発現場のリアリティへ
Q6. 自社で身体性AIロボットのPoCを始めるなら、どこから着手すべきですか?
A6. まずは既存ロボット+Isaac Sim+LLMプランナーという「頭脳のPoC」から着手するのがおすすめです。
- いきなり新規ハードから始めるより、既存機体にLLMプランナーとVLA相当の制御層を被せ、「どのタスクなら価値が出るか」を見極めます。
- その上で、レイテンシや安全性のボトルネックが見えたタイミングで、Jetson Thorやmicro-ROSへの移行を検討するのが現実的なステップです。
関連:Jetson Thor節へ / micro-ROS節へ
参考サイト・出典
一次情報
- NVIDIA Jetson Thor: ヒューマノイドロボットの計算基盤
- micro-ROS: マイクロコントローラ向けの標準ミドルウェア
- Google DeepMind: RT-2 (Vision-Language-Action) 技術詳細
- NVIDIA Isaac Sim: 高精度ロボットシミュレーション環境
- ROS 2 Jazzy Jalisco 公式ドキュメント
二次情報
あわせて読みたい
更新履歴
- 2026年2月12日:初版公開。
- 2026年3月16日:実装深掘りスポークとして再整理し、導入・章要約・内部リンク・FAQ・関連記事導線を更新。
以上








