


※本記事は継続的に最新情報へアップデートしています。
NVIDIAは2025年5月、「接続の主導権」を取りにいった。
名前はNVLink Fusion。GPUの王者が次に狙ったのは、他社チップを排除することではなく、他社CPU・カスタムASIC・XPUを自陣営のAIファクトリーへ取り込むことだった。
2026年3月にはMarvellへの20億ドル出資も発表され、この戦略は一段と鮮明になった。AIチップ競争の主戦場は、演算性能だけでなく「接続基盤」へ移り始めている。
✅ 先に結論
- NVLink Fusionとは、NVIDIAが発表した「新しいシリコン」であり、ラックスケールAIインフラプラットフォームです。 他社CPU・カスタムASIC・XPUを、NVLinkエコシステムとOCP MGXラック設計へ統合する接続基盤です。
- 主役はQualcomm提携だけではありません。 Intel、Arm、Fujitsu、Qualcomm、SiFive、Samsung Foundry、Marvell、MediaTek、Alchip、Astera Labs、Synopsys、Cadenceなどを巻き込むAIファクトリー連合です。
- NVLink Fusionは、完全なオープン標準ではなく「管理された統合」です。 他社チップに門戸を開きながら、接続基盤とラックスケール設計の主導権はNVIDIAが握る構図です。
- UALinkとの対立軸が重要です。 オープン標準を目指すUALinkに対し、NVIDIAはNVLink Fusionで自社の重力圏を広げています。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
NVLink Fusionとは何か
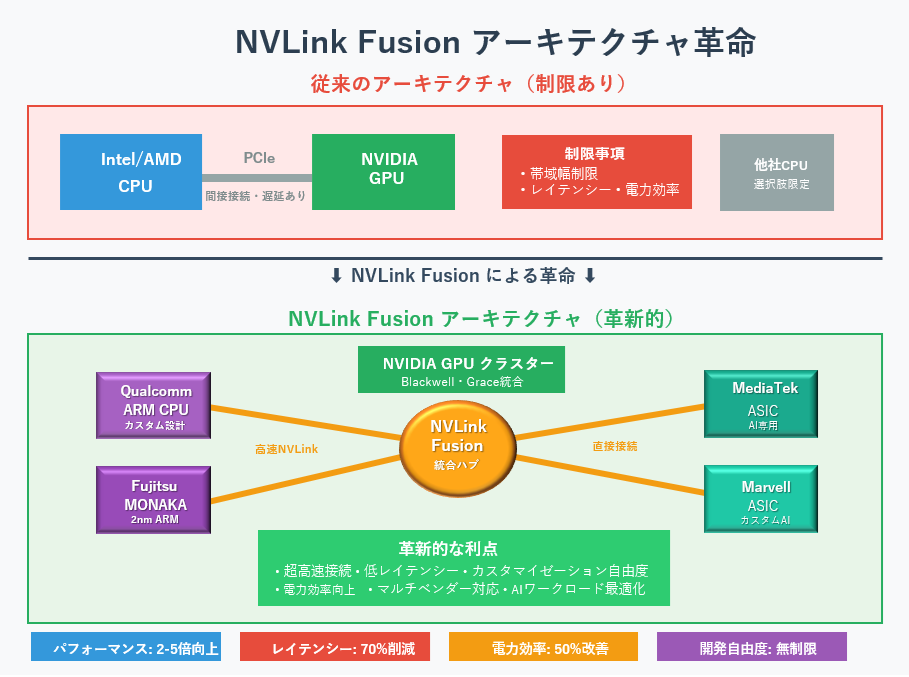
NVLink Fusionとは、他社CPU・カスタムASIC・XPUをNVIDIAのNVLinkエコシステムへ統合する、ラックスケールAIインフラプラットフォームである。
NVLink Fusionとは、NVIDIAが発表した「新しいシリコン」であり、ラックスケールAIインフラプラットフォームです。ハイパースケーラーやカスタムASIC設計者が、自社CPU・XPU・カスタムAIチップを、NVIDIAのNVLinkスケールアップ接続とOCP MGXラックスケール設計へ統合しやすくするための接続基盤です。
ポイントは、NVLink Fusionが単なる高速ケーブルや新しいI/O規格ではないことです。NVIDIAの狙いは、GPU、CPU、DPU、NIC、スイッチ、カスタムASICをラック単位でつなぎ、AIデータセンター全体を「AIファクトリー」として運用することにあります。
従来のAIサーバーでは、CPUとGPUの間はPCIe接続が中心でした。PCIeは汎用性が高い一方で、巨大モデルの学習やエージェントAI推論では、CPU、GPU、メモリ、ネットワーク間のデータ移動がボトルネックになりやすくなります。
NVLink Fusionは、このボトルネックを、NVIDIAの得意とするNVLinkの高帯域・低遅延接続へ引き寄せる戦略です。つまり、他社チップをNVIDIAの外側に置くのではなく、NVIDIAのAIファクトリーの内側へ接続するための技術と言えます。
なぜNVIDIAは他社チップをつなぐのか
NVIDIAがNVLink Fusionを打ち出した背景には、AIファクトリーの巨大化と、顧客ごとのセミカスタム需要の高まりがある。
一見すると、NVLink Fusionは不思議な戦略に見えます。NVIDIAはGPU市場で圧倒的に強く、自社CPUであるGraceやVera CPUも持っています。それにもかかわらず、なぜIntel、Arm、Qualcomm、Fujitsu、Samsung、Marvell、MediaTekなどを巻き込むのでしょうか。
理由は、AIデータセンターの需要があまりにも大きく、あまりにも多様になったからです。
ハイパースケーラーや大規模AI企業は、汎用サーバーを買って並べるだけでは満足しなくなっています。モデルの種類、推論パターン、電力制約、冷却方式、ネットワーク構成、調達方針に合わせて、自社向けのセミカスタムAIインフラを作りたいという需要が増えています。
このとき、NVIDIAがすべての部品を自社で抱え込むと、顧客の個別要求に応えにくくなります。一方で、接続基盤まで手放すと、AIファクトリー全体の主導権を失います。
そこで出てきたのがNVLink Fusionです。NVIDIAは、他社CPUや他社ASICの採用余地を残しながら、それらをNVLink、OCP MGX、Spectrum-X、BlueField、ConnectX、CUDAエコシステムと結びつけることで、AIファクトリー全体の主導権を維持しようとしています。
これは単純な「オープン化」ではありません。自社の重力圏を広げるための選択的な開放です。
NVLink FusionとPCIeの違い
NVLink Fusionの本質は、PCIe中心の汎用接続から、AIファクトリー向けの高帯域・低遅延接続へ重心を移すことにある。
NVLink Fusionを理解するには、まずPCIeとの違いを押さえる必要があります。
PCIeは、CPU、GPU、SSD、NICなどを接続する汎用I/O規格です。非常に広く普及しており、柔軟性も高い一方で、AIファクトリーのように数十〜数百個のGPUやカスタムアクセラレータを束ねる用途では、帯域・遅延・スケールの面で限界が出やすくなります。
一方、NVLinkはNVIDIAがGPU間接続のために育ててきた高帯域・低遅延ファブリックです。特に大規模AIでは、GPU同士の通信、CPUとGPUの協調、メモリ共有、推論時のデータ移動が性能を左右します。
| 項目 | PCIe中心の接続 | NVLink Fusion |
|---|---|---|
| 主な目的 | 汎用I/O接続 | AIファクトリー向けの高帯域接続 |
| 得意領域 | 幅広いデバイス接続 | GPU・CPU・ASICのラックスケール統合 |
| 設計思想 | 汎用性重視 | AIワークロードのデータ移動最適化 |
| エコシステム | 業界標準として広く普及 | NVIDIA AIファクトリーの中核接続 |
| 実務上の意味 | 柔軟だがAI特化性能に限界が出やすい | AI基盤全体をNVIDIAラック設計へ寄せやすい |
PCIeは今後も汎用接続として残ります。しかし、AIファクトリーの中核部分、つまりGPU・CPU・ASICを密に連携させる領域では、NVLink Fusionのような専用接続が重要になります。
NVLink Fusionエコシステムの拡張
NVLink Fusionは、CPU、IP、Foundry、Custom Silicon、EDAを巻き込む多層的なエコシステムへ拡大している。
NVIDIAはNVLink Fusion発表時点で、FujitsuとQualcommをCPUパートナーとして指名し、MediaTek、Marvell、Alchip、Astera Labs、Synopsys、Cadenceをデザインサービスやソリューションパートナーとして位置づけました。
その後、Intel、Samsung Foundry、Arm、SiFive、GUC、Marvellとの協業拡大により、NVLink Fusionは「2025年5月の発表技術」から、AIファクトリーをめぐる接続エコシステムへと広がっています。
| 区分 | 企業 | 主な役割 | 意味 |
|---|---|---|---|
| CPU / IP | Intel | x86 CPUとNVIDIA AI基盤のNVLink連携 | x86陣営もNVIDIA接続圏へ入り始めた |
| CPU / IP | Arm / SiFive | Arm・RISC-V系プラットフォームとNVIDIA GPUの接続 | CPUアーキテクチャの選択肢が広がる |
| CPU | Fujitsu / Qualcomm | MONAKA-XやArmベースCPUとNVIDIA GPUの接続 | HPC・AIデータセンター向けCPU多様化 |
| Foundry | Samsung Foundry | カスタムCPU / XPUの設計から製造までを支援 | NVLink Fusion対応シリコンの製造選択肢が広がる |
| Custom Silicon | Marvell | カスタムXPU、スケールアップネットワーク、シリコンフォトニクス | NVIDIAが20億ドルを投資した中核パートナー |
| Custom Silicon / Technology | MediaTek / Alchip / GUC / Astera Labs / Synopsys / Cadence | カスタムAIシリコン設計、接続、検証、EDA | NVLink Fusion対応チップを設計・実装する実務基盤 |
この顔ぶれを見ると、NVLink Fusionの意味がはっきりします。これはQualcomm CPU連携という個別案件ではありません。NVIDIAがカスタムAIシリコン市場の接続標準を取りにいく動きです。
CPU多様化とカスタムASICを取り込む戦略
NVLink Fusionは、x86、Arm、RISC-V、カスタムXPUをNVIDIA AIファクトリーへ接続する門になりつつある。
NVLink Fusionの初期発表で注目されたのが、QualcommとFujitsuです。QualcommはNuvia買収で得たArm CPU技術を背景にデータセンター市場へ再挑戦し、FujitsuはFUJITSU-MONAKA-X CPUとNVIDIA GPUを接続する構成をFugakuNEXTで採用します。
さらに、Arm NeoverseプラットフォームのNVLink Fusion統合により、ArmライセンシーがNVIDIA GPUへ接続する道も広がっています。SiFiveの参加は、RISC-V系の高性能データセンターCPUもNVIDIA AI基盤へ接続できる可能性を示します。
一方で、AIインフラ市場ではカスタムASICの存在感も急速に増しています。Google TPU、AWS Trainium、Microsoft Maia、OpenAI/Broadcom ASICのように、AIモデルやクラウド運用に合わせて専用チップを作る動きが強まっています。
Marvellとの2026年3月31日の戦略的パートナーシップは、その象徴です。NVIDIAはMarvellへ20億ドルを投資し、MarvellはカスタムXPU、NVLink Fusion対応スケールアップネットワーク、シリコンフォトニクスを提供します。
この構図は重要です。NVIDIAは、カスタムASICの波を単に防ぐのではなく、カスタムASICをNVLinkとNVIDIAラック設計の中へ取り込む方向へ動いています。
Vera RubinとNVLink Fusionの関係
Vera RubinはNVIDIA純正のラックスケールAI基盤、NVLink Fusionはそこへ他社シリコンを接続する拡張戦略と捉えると理解しやすい。
2026年のNVIDIA戦略を理解するうえで、Vera RubinとNVLink Fusionの関係は重要です。
Vera Rubinは、Rubin GPU、Vera CPU、NVLink 6、ConnectX-9、BlueField-4、Spectrum-6といったNVIDIAコンポーネントを中核にした、純正ラックスケールAI基盤です。
その上で、MarvellのカスタムXPU、FujitsuやQualcommのCPU、ArmライセンシーのCPU、SiFiveのRISC-V系プラットフォーム、Samsung Foundryが製造を支援するカスタムCPU / XPUなどを、NVLink Fusionや周辺エコシステムを通じて組み合わせる選択肢が広がりつつあります。
つまり、Vera Rubinが「NVIDIA純正の本丸」だとすれば、NVLink Fusionは「本丸に他社部隊を接続する門」です。
- 純正AIファクトリーの強化:Vera RubinやNVL72、PODといったラックスケール基盤を中心に据える。
- 他社シリコンの取り込み:Intel、Arm、Qualcomm、Fujitsu、SiFive、Marvell、Samsung、MediaTekなどのCPU・ASIC・XPUをNVLink圏へ接続する。
この二段構えにより、NVIDIAは「すべてを自社チップで閉じる」よりも広い市場を取れる可能性があります。自社チップでAIファクトリーを作り、他社チップもそのAIファクトリーへ接続させる。これがNVLink Fusionの戦略的な意味です。
CUDA圏を外へ伸ばす門:UALinkとの対立軸
NVLink Fusionは、NVIDIAのCUDA・NVLink圏を他社CPU・ASIC・XPUへ広げる一方、UALinkのようなオープン標準との対立軸も生んでいる。
NVLink Fusionを「NVIDIAがオープン化した」と見ることはできます。しかし、ここで注意すべきなのは、NVLink FusionがNVIDIAの外へ出るための技術ではないという点です。
CUDAは、NVIDIA GPUを使うためのソフトウェア基盤です。AI開発者、研究者、クラウド事業者はCUDA、cuDNN、NCCL、TensorRT、Tritonなどの周辺エコシステムに大きく依存しています。
NVLink Fusionは、このCUDA圏の外に独立した別世界を作る技術ではありません。むしろ、他社CPUや他社ASICをNVIDIAのAI基盤へ接続することで、NVIDIAラックの中で使えるチップの範囲を広げる仕組みです。
一方で、AMD、Broadcom、Cisco、Google、HPE、Intel、Meta、Microsoftなどは、AIアクセラレータ間をつなぐオープン標準としてUALinkを推進してきました。UALinkは、NVIDIAのNVLinkに対する業界標準型の対抗軸と見ることができます。
戦略構図は明確です。NVLink FusionはNVIDIA圏の拡張、UALinkはオープン接続圏の形成。この対立軸を理解すると、AIインフラ競争の見え方が一段深くなります。
NVLink Fusionは「管理された統合」である
NVLink Fusionは開かれたように見えるが、完全なオープン標準ではなく、NVIDIAが接続基盤を管理する統合モデルである。
NVLink Fusionを評価するうえで、必ず押さえておきたい注意点があります。それは、NVLink Fusionが「誰でも自由に組み合わせられる完全なオープン標準」ではないという点です。
NVLink Fusionは、完全なオープン標準というより、NVIDIAが管理する接続エコシステムです。報道によれば、カスタムチップはNVIDIA製品と接続することが前提で、接続コントローラやPHYレイヤの管理、NVLink Switchチップの利用にはNVIDIA側のライセンスと管理が関わります。つまり、NVLink Fusionは「開放」ではなく、管理された統合として理解するのが現実的です。
この制限は、悪いことばかりではありません。NVIDIAが接続仕様やラックスケール設計を管理することで、性能、検証、サポート、導入スピードを高められる可能性があります。
一方で、AIインフラを長期運用する企業にとっては、ベンダー依存、ライセンス、調達交渉、将来の移行コストを慎重に評価する必要があります。
つまりNVLink Fusionは、自由度と統制のトレードオフです。高性能なNVIDIA AIファクトリーに乗る代わりに、NVIDIAの接続設計とライセンス体系の中で動くことになります。
実務ではどう読むべきか
NVLink Fusionは、AIインフラ選定において「チップ単体」ではなく「接続基盤」を評価すべき時代を示している。
企業がNVLink Fusionを見るとき、最初に考えるべきことは「Qualcomm CPUを使うべきか」ではありません。より重要なのは、自社のAI基盤がどの接続エコシステムに乗るのかです。
| 評価軸 | 見るべきポイント | 実務上の意味 |
|---|---|---|
| 接続基盤 | NVLink、PCIe、Ethernet、UALink、UCIeなど | AI基盤全体の性能と拡張性を左右する |
| ベンダー依存 | NVIDIA圏にどこまで寄るか | 性能と引き換えに調達・価格・運用の自由度が変わる |
| カスタムASIC活用 | 自社ASICやクラウドASICを接続できるか | 特定ワークロードでコスト/トークンを下げやすい |
| ソフトウェア資産 | CUDA、ROCm、XLA、独自SDK | 開発者の生産性と移行コストを決める |
| 長期ロードマップ | Vera Rubin、Rubin Ultra、次世代AIファクトリー | 一度選んだ基盤が数年後も拡張できるかを決める |
判断の起点は、「自社はNVIDIA純正AIファクトリーに寄せるのか」「他社CPU・ASICを組み合わせる必要があるのか」という問いです。
例えば、エージェント型AIサービスを展開する企業が、学習はクラウドのマネージドGPUに任せつつ、推論は将来的に自社ASICへ寄せたいとします。この場合、NVLink Fusion対応のハードウェアベンダーを選んでおくことで、将来、自社ASICをNVIDIAラックと並走させる余地を残せます。
一方、フルマネージドなAIインフラを最速で立ち上げたい企業にとっては、Vera Rubin NVL72のような純正ラックに寄せる方が合理的です。そのうえで、必要に応じてNVLink Fusion経由の他社チップを組み込む、というシナリオが見えてきます。
まとめ:NVLink FusionはNVIDIAの“開放”ではなく“重力圏の拡張”である
NVLink Fusionは、他社チップを受け入れる技術であると同時に、他社チップをNVIDIA AIファクトリーへ接続するための戦略である。
NVLink Fusionは、Qualcommとの提携だけで語るには小さすぎるテーマです。実際には、Intel、Arm、Fujitsu、Qualcomm、SiFive、Samsung Foundry、Marvell、MediaTek、Alchip、Astera Labs、Synopsys、Cadenceなどを巻き込み、他社CPU・カスタムASIC・XPUをNVIDIAのラックスケール基盤へ接続するエコシステム戦略です。
これは、AIインフラの多様化に対応する動きでありながら、同時にNVIDIAのAIファクトリーを中心に据え続ける動きでもあります。特にMarvellへの20億ドル出資は、NVLink Fusionが単なる接続規格ではなく、NVIDIAの投資戦略そのものと結びついていることを示しました。
また、UALinkとの対立軸を見れば、AIインフラ競争の本丸が「どのチップが速いか」から「どの接続標準が支配的になるか」へ移りつつあることが分かります。
川の支流が本流へ合流するように、さまざまなCPUやASICがNVLinkを通じてNVIDIAのAIファクトリーへ流れ込む。
その構図を作るのが、NVLink Fusionです。
つまりNVLink Fusionの本質は、他社チップを開放することではなく、他社チップをNVIDIAの重力圏へ接続することにあります。
- NVLink Fusionは、NVIDIA GPUと他社CPU・カスタムASIC・XPUを接続するラックスケールAIインフラプラットフォームである。
- Intel、Arm、SiFive、Fujitsu、Qualcomm、Samsung Foundry、Marvellの参加により、NVLink Fusionは多層的なAIチップ接続エコシステムへ拡大している。
- UALinkとの対立軸は、AIインフラ競争が「演算チップ」から「接続標準」の戦いへ進んでいることを示す。
- 2026年以降のAIインフラ選定では、「どのチップを使うか」だけでなく「どの接続基盤に乗るか」が競争力を左右する。
専門用語まとめ
- NVLink Fusion
- NVIDIA GPUと他社CPU・カスタムASIC・XPUを接続し、セミカスタムAIインフラを構築するためのラックスケールAIインフラプラットフォーム。
- NVLink
- NVIDIAが開発した高帯域・低遅延のチップ間接続技術。GPU同士やCPU・GPU間のデータ移動を高速化する。
- UALink
- Ultra Accelerator Linkの略。AIアクセラレータ間をつなぐオープン標準を目指す接続技術。AMD、Intel、Broadcom、Google、Meta、Microsoftなどが推進する対抗軸である。
- AIファクトリー
- AIモデルを学習・推論し、トークンという価値を継続的に生産するデータセンターを、工場として捉えるNVIDIAの概念。
- カスタムASIC
- 特定用途に合わせて設計された専用チップ。AIモデルやクラウド事業者のワークロードに合わせて最適化される。
- XPU
- CPUやGPUに限定されない、AIアクセラレータや専用プロセッサを含む広い意味での計算チップの総称。
- Spectrum-X
- NVIDIAのAIデータセンター向けEthernetネットワーク基盤。ラック間のスケールアウト通信を支える。
よくある質問(FAQ)
Q1. NVLink Fusionとは何ですか?
A1. NVIDIA GPUと他社CPU・カスタムASIC・XPUを、NVLinkエコシステムとOCP MGXラックスケール設計へ統合するためのラックスケールAIインフラプラットフォームです。
Q2. NVLinkとは何ですか?
A2. NVLinkは、NVIDIAが開発した高帯域・低遅延のチップ間接続技術です。GPU同士、CPUとGPU、アクセラレータ間のデータ移動を高速化します。
Q3. NVLink FusionとNVLinkの違いは?
A3. NVLinkはNVIDIAの高速接続技術そのものです。NVLink Fusionは、そのNVLinkを使って他社CPUやカスタムASICをNVIDIA AIファクトリーへ接続するための拡張的な仕組みです。
Q4. NVLink Fusionは完全なオープン標準ですか?
A4. いいえ。NVLink Fusionは他社チップを受け入れる仕組みですが、完全なオープン標準ではありません。接続基盤やライセンスはNVIDIAが管理するため、「管理された統合」として理解するのが現実的です。
Q5. NVLink FusionとUALinkの違いは?
A5. NVLink FusionはNVIDIA主導の接続基盤で、NVIDIA AIファクトリーへ他社チップを統合する方向です。UALinkは、AIアクセラレータ間接続のオープン標準を目指す業界コンソーシアムです。
Q6. NVLink FusionはCUDA代替ですか?
A6. いいえ。NVLink FusionはCUDA代替ではなく、他社チップをNVIDIAのCUDA・NVLink圏へ接続する技術です。むしろNVIDIAのAIプラットフォームの重力圏を広げる戦略です。
Q7. NVLink Fusionのパートナー企業は?
A7. NVIDIA公式では、Arm、Intel、Fujitsu、Qualcomm、SiFive、Alchip、Astera Labs、GUC、Marvell、MediaTek、Samsung、Cadence、Synopsysなどが関連企業として示されています。
参考文献 / 出典
- NVIDIA — NVLink Fusion: Build Semi-Custom AI Infrastructure
- NVIDIA Newsroom — NVIDIA Unveils NVLink Fusion for Industry to Build Semi-Custom AI Infrastructure With NVIDIA Partner Ecosystem
- NVIDIA Japan Blog — NVIDIA、パートナー エコシステムとともに業界がセミカスタム AI インフラを構築できる NVLink Fusion を発表
- NVIDIA Investor Relations — NVIDIA AI Ecosystem Expands as Marvell Joins Forces Through NVLink Fusion
- Marvell — NVIDIA AI Ecosystem Expands as Marvell Joins Forces Through NVLink Fusion
- NVIDIA Blog — RIKEN, Japan’s Leading Science Institute, Taps Fujitsu and NVIDIA for Next Flagship Supercomputer
- Arm — Arm Neoverseプラットフォーム、NVIDIA NVLink Fusionの統合によりAIデータセンターでの採用を加速
- SiFive — SiFive to Power Next-Gen RISC-V AI Data Centers with NVIDIA NVLink Fusion
- TrendForce — NVIDIA Adds Samsung Foundry to NVLink Fusion Ecosystem for Custom Silicon Manufacturing
- GUC — GUC Joins NVIDIA NVLink Fusion Ecosystem to Drive Seamless XPU Integration
- Reuters — Qualcomm to make data center processors that connect to Nvidia chips
- Marvell — NVIDIA AI Ecosystem Expands as Marvell Joins Forces Through NVLink Fusion
- Alchip — Alchip Among the First with NVIDIA NVLink Fusion Design Ecosystem
- Tom’s Hardware — NVIDIA announces NVLink Fusion for custom CPUs and AI accelerators
- Business Wire — AMD, Broadcom, Cisco, Google, HPE, Intel, Meta and Microsoft Form UALink Promoter Group
- UALink Consortium — Introducing UALink 200G 1.0 Specification
合わせて読みたい
更新履歴
- :初版公開。NVIDIAとQualcommの技術的接近、NVLink Fusionの発表、AIデータセンター市場への影響を整理。
- :2026年版として全面改稿。記事主題をQualcomm提携からNVLink Fusionそのものへ再定義し、Intel、Arm、SiFive、Samsung Foundry、Marvell 20億ドル出資、FugakuNEXT、UALink対立軸、管理された統合としての制限条件を反映。








