※本記事は継続的に最新情報にアップデート、読者支援機能の強化を実施しています。
CUDAという「密結合の堀」は崩れるか?Vera Rubinが引き寄せる逆説
CUDAの強さは「速い言語」ではなく、GPUの理論性能を“現場の速さ”に変える仕組みが、道具から最適化まで一体で揃っている点にあります。では、その“堀”は互換技術や新しい開発手法の登場で本当に崩れるのか?本記事では、崩れる層/残る層を整理し、最後にVera Rubinが“むしろ強くなる”理由まで結論を引きます。
この記事の結論:
- 密結合のモート(堀):CUDAの強さは、20年にわたりGPU内部の物理構造に数学カーネルをミリ単位で最適化し続けてきた「4層のエコシステム」にあり、単なる「速いチップ」では到達できない領域である。
- 崩れる層/残る層:脱CUDAは「CUDAという方言を、どの層で翻訳するか」で勝敗が決まる。互換・新規開発・基盤刷新という“崩しにいく層が違う”3つの武器が登場し、自由度は増した。
- 逆説のVera Rubin:ソフトの壁が薄い世界ほど、最後は純粋な「1円・1ワットあたりの知能生成量(物理効率)」で選別が起きる。だからVera Rubinは「囲い込み」ではなく、あらゆる資産を引き寄せる“インフラの磁石”としてむしろ強くなる可能性がある。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
1. 王者の絶対基準:Vera Rubinのラック最適化が成し遂げた「整合性」の快挙
Vera Rubinアーキテクチャとは、
NVIDIAが掲げる「ラックこそが最小単位のコンピュータ」という思想の実装です。
GPU単体の馬力競争ではなく、演算・通信・制御を“ひとつの装置”として協調設計し、AIインフラ全体を止めないことを狙います。
図解:なぜ「GPUを速くするだけ」では勝てないのか
AIのボトルネックは、計算そのものよりもデータ移動(メモリ/通信/I/O)へ寄っています。だから勝敗を分けるのは「主演(GPU)」ではなく、劇場(ラック)全体の待ち時間を消す設計です。
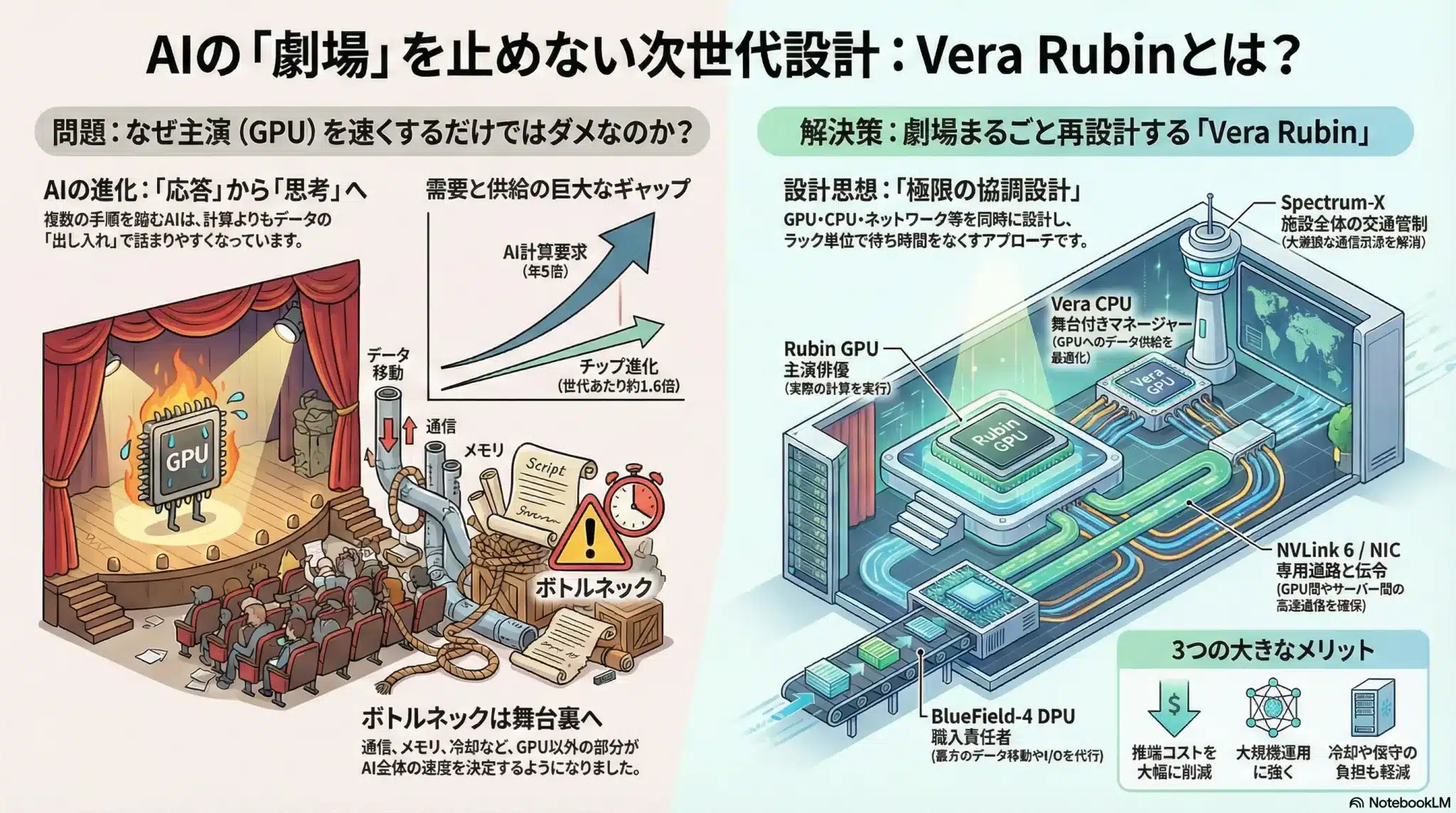
設計思想:極限の協調設計(=待ち時間の根絶)
Vera Rubinの強さは、単体スペックの足し算ではありません。GPU・CPU・ネットワーク・I/Oを別々に最適化するのではなく、最初から「同じ舞台で噛み合う前提」で設計する。その“整合性”が、AIファクトリーの実効性能を決めます。
Vera Rubinの構成要素(NVL72/SuperPOD、NVLink、DPU、CPO等)の整理は別稿に集約しています。
Vera Rubin AIデータセンター完全ガイド
2. なぜNVIDIAの「堀」は崩れないのか:20年の密結合が生んだ芸術
NVIDIAには、20年かけて育て上げたCUDAエコシステムという「城壁(モート)」があるからです。
そしてCUDAの強さは、単なる「GPUを動かすためのソフトウェア」ではありません。
エンジニアがNVIDIAを離れられないのは、物理回路を100%使い切るための仕組みが、道具から最適化まで一気通貫で揃っているからなのです。
1. GPUが圧倒的になる条件:行列演算を“実効性能”まで引き上げる設計
GPUは、行列演算(GEMM)のような同じ計算を大量データに繰り返し適用する処理で圧倒的です。
一方でCPUは多様な処理を器用に捌くのが得意で、GPUはデータ並列な計算を超大量に流し切るのが得意です。
ただし、GPUの圧倒的な理論性能は、放っておけば自動的に実効性能にはなりません。最大の敵は「メモリ待ち」です。
資料が突きつける現実は鋭く、GPU計算のボトルネックの多くは、演算そのものではなくメモリからのデータ供給待ちだと言います。
たとえばLLM推論では、行列積そのものよりも、KVキャッシュの読み書きやAttentionのメモリアクセスで演算器が遊ぶ瞬間が生まれます。
いくらエンジンが速くても、燃料がうまく供給されなければ意味がない――まさにこの「燃料供給」を最適化するノウハウの塊がCUDAです。
ここで勝敗を分けるのは、並列化の粒度と階層メモリの使い方、そしてSIMT(Single Instruction, Multiple Threads)の実行モデルに合わせて、
計算とデータ配置を「GPUが喜ぶ形」に整えることです。
要点:FLOPSは「馬力」、勝敗は「段取り」
GPU性能は「馬力(FLOPS)」だけでは決まりません。
馬力をラップタイムに変える段取り──メモリ配置、アクセスの揃え方、カーネル融合、並列実行の設計──で決まります。
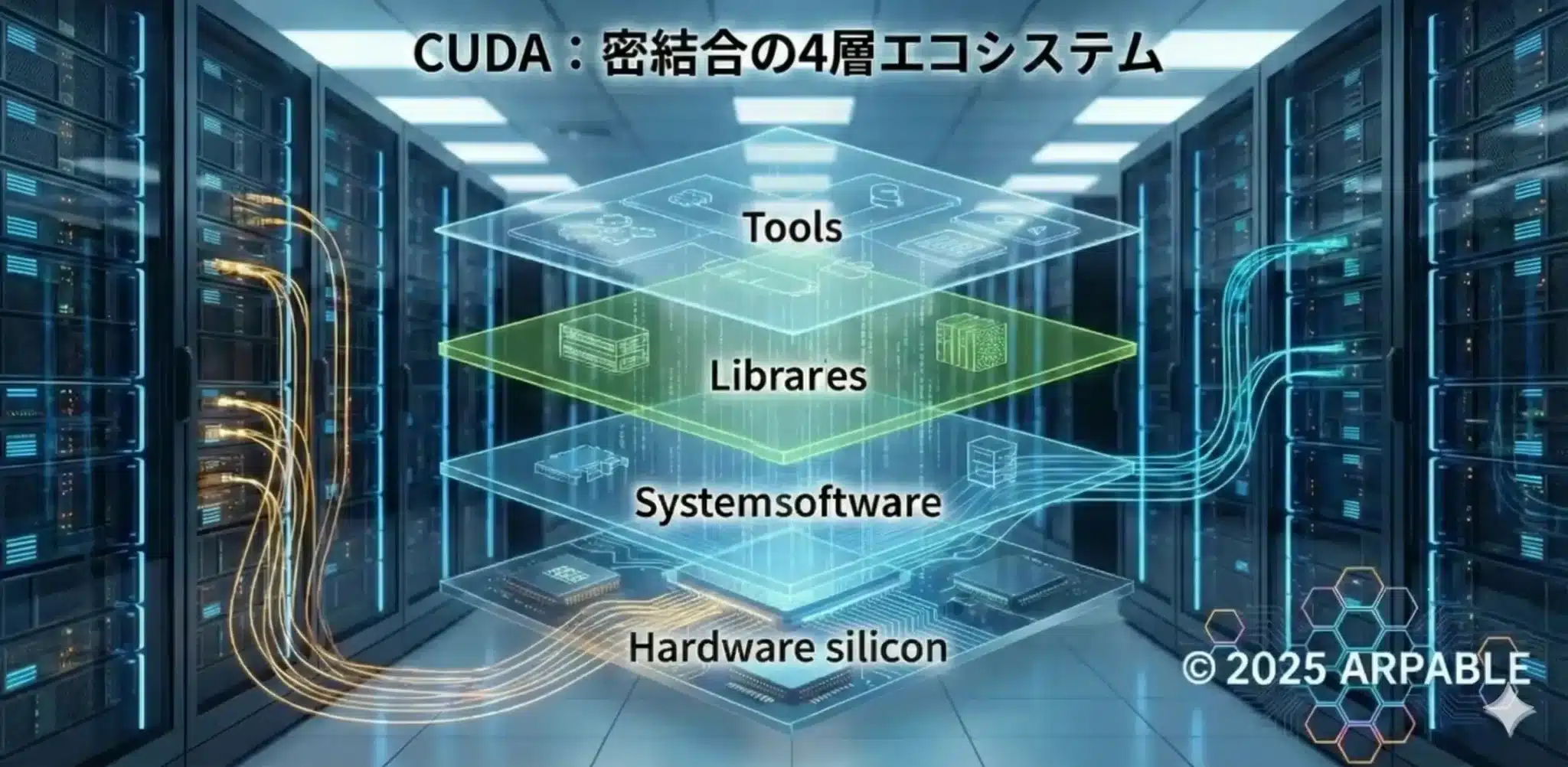
CUDAという「城」を構成する4つの階層
CUDA依存の実態は、以下の4層が密接に絡み合った重層構造です。
他社チップが苦戦するのは、単に「コードが動かない」からではありません。
理論性能を実効性能へ変換する“歯車”が、層ごとに長年磨き込まれているため、この階層ごとの最適化レベルに差が生まれ、
結果としてCUDAは“堀”として機能します。
ここでの「堀」の定義
本章で言う「第1〜第4の堀」とは、CUDAエコシステムの4層構造そのものを指します。
第1の堀=API/ランタイム(城の門)、第2の堀=実行・生成(城壁)、第3の堀=最適化ライブラリ(本丸)、第4の堀=ツール(診断の瞳)です。
| 階層 | 具体的な内容 | 脱CUDAにおける「鬼門」 |
|---|---|---|
| 1. API/ランタイム層(第1の堀:門) | cuda runtime / driver | メモリ確保、カーネル起動。置換は比較的容易な「城の門」。 |
| 2. 実行・生成層(第2の堀:城壁) | PTX、NVCC、JIT | 高い。物理チップの世代更新への追随能力。 |
| 3. 最適化ライブラリ層(第3の堀:本丸) | cuBLAS / cuDNN / NCCL | 絶望的に高い。20年分の職人芸が製品化されている「本丸」。 |
| 4. ツール層(第4の堀:診断の瞳) | Nsight / profilers | 高い。ボトルネックを可視化する「診断の瞳」。 |
特に第3層(ライブラリ)は、NVIDIAのエンジニアが回路設計の段階から並行して書き上げた「最適化の集大成」です。
cuBLASによる行列演算や、NCCLによる分散通信の効率は、単にコードを他社チップへ移植しただけでは再現できない、
物理層と阿吽の呼吸で動く「フルスタックの整合性」の結果なのです。
2. F1マシンの比喩で解く「実効性能」の正体

なぜこの4層構造がそれほど重要なのか。F1マシンの比喩を使うと、エンジニアの苦労とNVIDIAの凄みが浮き彫りになります。
- NVIDIA GPU = F1マシン:圧倒的なエンジンの馬力を持つが、乗りこなしが極めて難しい。
- CUDA = 専属のピットクルー + テレメトリ解析 + レース戦略:マシンの限界性能を引き出すための総合力。
F1はエンジンが強いだけでは勝てません。タイヤの温度管理、ミリ秒を争うピット作業(タイヤ交換)、燃料戦略……。
GPU計算において性能を左右するのは、演算器そのものよりも「メモリとの戦い」です。
「エンジンの回転(演算)」を止めるのは、常に「燃料補給やタイヤ交換(メモリからのデータ供給)」です。
CUDAは、タイヤを並べる順番(Coalescing)や、チップ内の高速作業台の使いこなし(共有メモリ)を、20年分の職人芸としてライブラリ化しています。
不都合な真実:FLOPSが高いのに遅い、が起きる理由
どんなに馬力のある他社製エンジン(チップ)を持ってきても、ピットクルー(ソフトウェア)がマシンの物理構造を熟知していなければ、タイヤ交換(メモリアクセス)に時間がかかり、ラップタイム(AI応答速度)で完敗します。
これが「FLOPS値は高いのに、推論が遅い」という現象の正体です。
3. 深層解説:CUDAが「理論性能」を“現場の速さ”に変える理由
1. 勝敗を分けるのは「メモリ待ち」を消す段取り
GPUが遅くなる原因の多くは、計算が遅いからではなくデータが届くのを待つ時間です。CUDAが強いのは、この“待ち”を減らすための段取り(設計パターン)が、道具として手元に揃っているからです。
- Coalescing(合体アクセス):スレッドがバラバラに読みに行くと帯域が死ぬ。だから「まとめて読める形」に並べ替える。
- 共有メモリ(SM内の作業台):VRAMへ何度も往復しないよう、必要なものを一時置きして“まとめて処理”する。
2. なぜNsightは“武器”になるのか(結論だけ)
他社にも計測器はありますが、CUDAの強さは「どこが詰まっているか」を短時間で特定し、次の一手を示せる点です。現場では、ここで差がつきます。
- ハードが吐く“状況報告”(カウンタ)を、
- Nsightが人間の言葉に翻訳し、
- 改善の方向性まで提示する。
だからCUDAは「速い」だけでなく、速くするまでの時間(チューニング工数)も短い。これがエンジニアが離れにくい最大の理由です。
4. バベルの塔を崩す「3つの武器」:脱CUDAは“どの層を崩すか”で決まる
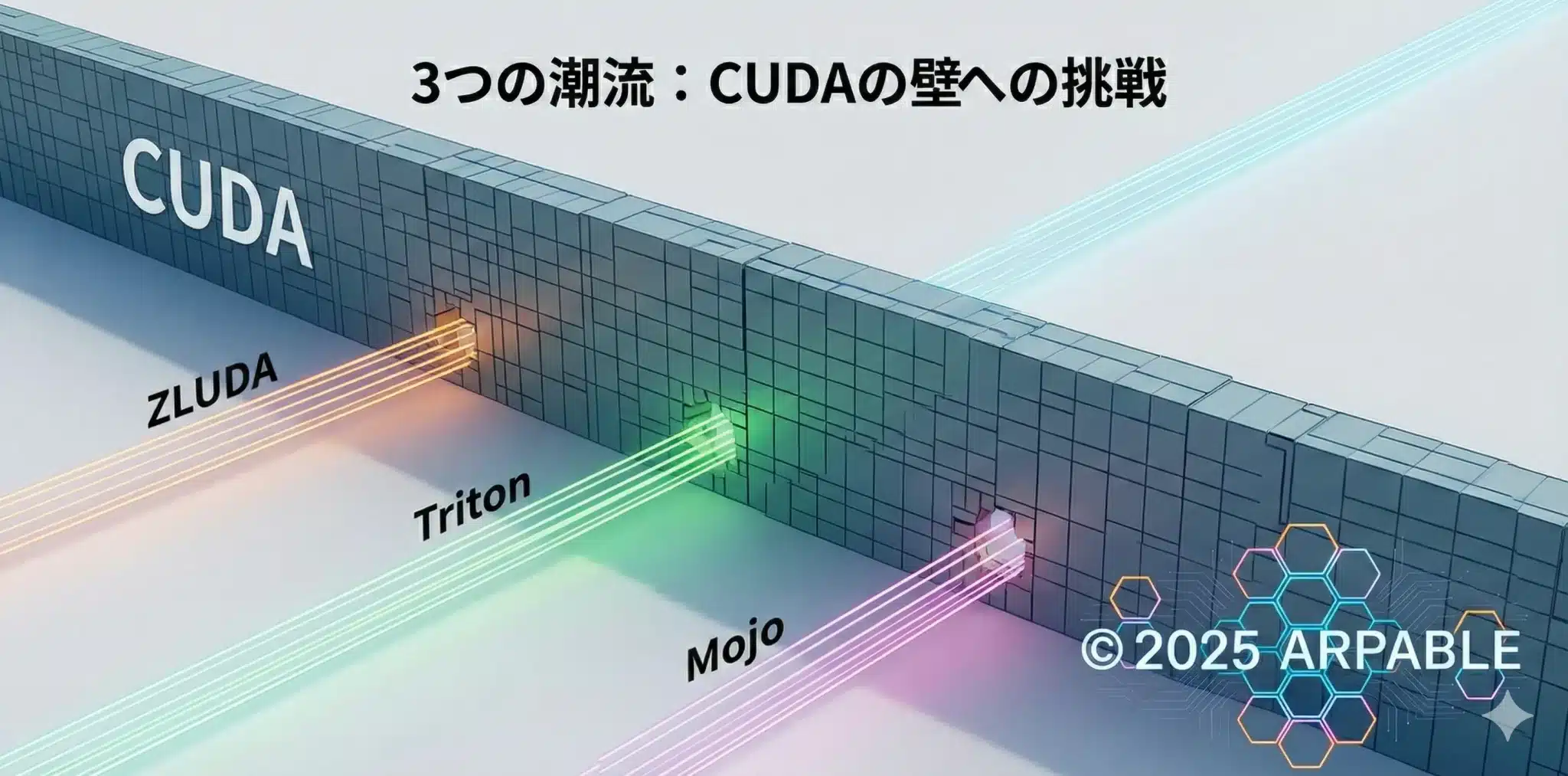
結論:脱CUDAは「CUDAという方言を、どの層で翻訳するか」で勝敗が決まります。
CUDAを崩すアプローチは無数に見えますが、要点は単純で、どの層を置き換えるかの一点に収束します。
翻訳する層を間違えると、次のどちらかに落ちます。
- 動いたのに速くない(=本丸が残っている)
- 速いのに運用できない(=計測・デバッグ・再現が弱い)
CUDA代替の三潮流とは、
① 互換実行型(まず動かす)/
② 新規開発型(CUDAを書かない)/
③ 基盤刷新型(言語から変える)
という、“崩しにいく層が違う”3つの攻め筋です。
脱CUDAの選択肢はZLUDA/Triton/Mojo以外にも多数あります。
本章では「どの層を翻訳するか」という軸が最もクリアに出る代表3例として選びました。
30秒で把握:3行まとめ(ここだけ覚えればOK)
- ZLUDA:既存CUDA資産を通訳して「まず動かす」=移植コストを下げる
- Triton:CUDAを書かずに速いカーネルを作る=融合カーネルで“待ち”を減らす
- Mojo:言語・基盤から性能可搬性を内蔵=中長期でマルチベンダー化
②は「速いパーツを量産する工作機械」、
③は「次のレギュレーションに合わせて設計思想ごと作り替える」。
この対応表だけ押さえれば、以降は迷子になりません。
一枚で選ぶ:3潮流の「使い分け」早見表
| 武器 | まず得すること | 向く状況(1行) | 落とし穴(1行) |
|---|---|---|---|
| ① ZLUDA | 既存CUDA資産を「まず動かす」 | 資産が重い/PoCを急ぐ | GEMM/通信の“本丸”は別途最適化が残りやすい |
| ② Triton | 融合カーネルで“待ち”を削る | Attention最適化が主戦場 | 巨大ライブラリ一式・分散通信は別腹 |
| ③ Mojo | 中長期で性能可搬性を取りに行く | 3年スパンでマルチベンダー化 | 勝負は言語より運用(測る/直す/回す)の厚み |
① ZLUDA:既存資産を活かす「同時通訳」— 移植コスト最小の切り札

ひとことで:ZLUDAは、CUDAアプリが期待する呼び出しを別実装で受け止めることで、非NVIDIA GPUでも動作させる互換実行アプローチです。
- まず得すること:巨大なCUDA資産を抱えるほど、移植コスト(改修量)を強烈に圧縮できる
- 向く状況:PoCを急ぐ/「どこが詰まるか」を実測して差分を掴みたい
- 落とし穴:最後はGEMM/通信(最適化ライブラリ層)が残りやすい
使い方の型(おすすめ)
- まず動かす(機能互換の確立)
- 計測する(GEMM/Attention/通信のどこが支配的か切り分け)
- 勝ち筋を決める(必要ならTritonや別の最適化へ)
ZLUDAは「移植の壁」を下げる武器で、入口(現実を測るため)として使うと強いです。
② Triton:CUDAを書かせない「新規開発型」— 融合カーネルの覇道

ひとことで:Tritonは、CUDAに強く依存せずにGPUに効くカーネルを高水準に記述し、コンパイル側で最適化へ落とすアプローチです。
- まず得すること:融合カーネル(メモリ往復を減らす設計)を量産しやすい
- 向く状況:推論の主戦場がAttention/前後処理で、工夫で勝てる余地が大きい
- 落とし穴:巨大ライブラリ一式(GEMM/分散通信/周辺運用)を“Tritonだけ”で丸ごと置換はしにくい
使い方の型(おすすめ)
- FlashAttention系のように「往復をまとめる」領域から当てる
- 速度だけでなく再現性(ベンチ手順)もセットで固める
- GEMM/通信が支配的なら、別の勝ち筋(ライブラリ・通信最適化)も併用する
Tritonは“万能の置換”ではなく、局所を最速化する武器として使うと迷子になりません。
③ Mojo:言語基盤から「可搬性×速度」を再定義する — 長期戦の正攻法

ひとことで:MojoはAI向けに設計された言語・コンパイル基盤として、最初からマルチターゲットを見据えた性能と生産性の両立を狙うアプローチです。
- まず得すること:「移植前提」を設計に埋め込み、将来のベンダー選択を柔らかくできる
- 向く状況:3年スパンでマルチベンダー化したい/開発体験を“次の標準”へ寄せたい
- 落とし穴:勝負は言語仕様より、ツール・運用(測る/直す/回す)の厚み。ここが弱いと現場が定着しない
使い方の型(おすすめ)
- まずは限定領域(特定カーネル/特定サービス)で採用し、運用の型を作る
- 計測・デバッグ・回帰テストを“言語導入と同時”に整備する
- 最終目的は「置換」ではなく、選択肢を増やすことだと明確化する
注意:「動く」より難しいのは「現場で回る」です。性能だけでなく、観測性・再現性・標準手順をセットで設計してください。
CTO/技術選定者向け:3つの武器の「選び方」チェックリスト
- 最優先が移植コスト削減 → ①(ZLUDA)で“まず動かす”+計測して差分を掴む
- 推論最適化(特にAttention)が主戦場 → ②(Triton)で融合カーネルを量産する体制へ
- マルチベンダーを前提に中長期標準化 → ③(Mojo)で言語・基盤から主導権を取りに行く
まとめ:「どれが最強か」ではなく、どの層の壁を崩したいかで武器は決まります。最後に効くのは性能だけでなく、運用(測る・直す・回す)です。
5. LLM推論の実務:FlashAttentionで見える「脱CUDA」の境界線(たとえ話で理解する版)
第4章の接続:第4章で「崩す層」を整理しました。ここでは推論の現場で、どの工程が“中立化しやすく”、どこが“本丸として残るか”を、巨大なレストランに置き換えて見ていきます。
まず全体像:LLM推論=「料理を出すまでの流れ」
- GEMM(行列積)=仕込み担当(大量の下ごしらえ)
- Attention=盛り付け担当(料理をまとめて完成形にする)
- 分散通信=配膳・動線(厨房とホール、店同士をつなぐ物流)
境界線①:GEMM(行列積)— 仕込みは「職人の道具」が支配する
仕込みは、同じ作業を超高速で回し続ける世界です。
ここで効くのは、“誰でも使える包丁”ではなく、店の厨房に合わせて研ぎ澄まされた“専用の職人道具”。
だからGEMMは、「動かす」より「同じ速度で勝つ」が難しい領域になります。
境界線②:Attention — 盛り付けは「まとめて一回でやる」が最強
盛り付けは、実は「火力」より皿を取りに行く回数で遅くなります。
何度も冷蔵庫へ往復(VRAM往復)すると、そのたびに時間が溶ける。
FlashAttentionが強いのは、盛り付け工程を“まとめて一気に終わらせる”(融合カーネル)からです。
この領域は、やり方(設計)で勝てる余地が大きいので、CUDA一本足ではなくなりやすい=「中立化しやすい」ポイントです。
境界線③:分散通信 — 配膳は「道路と交通整理」がすべて
店が1店舗ならいい。でも店舗が増える(GPU・ラックが増える)と、最後は物流です。
いくら厨房が速くても、道路が細い/信号が下手/渋滞が見えないと料理は届きません。
分散通信は「コード」だけでなく、ネットワーク、観測(どこが詰まったか)、運用まで含めて勝負が決まるので、簡単には“置き換え”が起きにくい領域です。
この章の結論(超要約):
- GEMM(仕込み):専用道具の厚みが効く → 置換が最難関
- Attention(盛り付け):往復回数を減らせば勝てる → “中立化”が進みやすい突破口
- 分散通信(配膳):道路と交通整理の総合戦 → 置換が起きにくい最後の壁
6. 【新潮流】逆説のVera Rubin ― 互換性が招く「ハブ」への回帰

前編から積み上げてきた議論の果てに、2026年の市場は一つの「驚異的な逆説」に直面しています。
それは、ソフトウェアの壁が下がり「どこでも動く」自由が確立されるほど、最後に選ばれるのは再びNVIDIA(Vera Rubin)になるのではないか、という仮説です。
他社資産が「最高の舞台」を求めて流入する戦略的シナリオ
これまで「NVIDIAという城からどう脱出するか(脱NVIDIA)」ばかりが議論されてきました。しかし、ソフトウェアがポータブル(移植可能)になるということは、逆のベクトルも生みます。
すなわち、
「これまでROCmやoneAPI向けに独自に磨き上げられてきた、他社チップ用の優れたライブラリやアプリケーションを、Vera Rubinという史上最高の器で動かしてみたい」
というニーズの顕在化です。
ここで重要になる「中立資産」とは?
中立資産とは、特定ベンダー(CUDA専用、ROCm専用など)に“縛られない形”で蓄積でき、どのハードでも再利用・移植・再コンパイルしやすい資産のことです。
互換レイヤーや共通コンパイル基盤が育つほど、この中立資産は「持ち運べる価値」になります。
- 例1:モデル/重み/量子化済みチェックポイント
「どのGPUで動かすか」と切り離された成果物(重み・量子化・蒸留成果)。最終的に速い舞台へ乗せ替えやすい。 - 例2:グラフ/IR/コンパイル可能な表現
ONNXやMLIR系のように、バックエンド差を吸収しやすい中間表現。最適化を“移植可能な形”で蓄えられる。 - 例3:アルゴリズム設計・タイル化・融合の知見
FlashAttention的な「メモリ往復を減らす設計思想」は、実装先が変わっても価値が残りやすい(=ノウハウ資産の中立化)。 - 例4:運用資産(計測/再現/ベンチ手順)
“測る・直す・回す”の手順、再現性あるベンチ、性能回帰テストはベンダーを跨いで効く。
重要なのは、中立資産が増えるほど「囲い込み(方言)」の価値が相対的に下がり、
最終的に“物理効率が最も高い舞台”へ資産が集まる力が強まる点です。
もし、ZLUDAやTriton、Mojo、そしてSYCLといった「共通言語」が完全に普及し、ソフトウェアの縛りが消滅した世界が訪れたら、ユーザーは何を基準にインフラを選ぶでしょうか?
答えは、純粋な「1円、および1ワットあたりの知能生成量(物理的な実効効率)」です。
ソフトウェアの壁が消えた瞬間、インフラ選定は「情緒」から「冷徹な算盤勘定」へと移行するのです。
補足(1行だけ):もちろん現実には価格・供給・規制が絡みます。しかし、壁が薄いほど最終的に“物理効率”へ収束する力そのものは消えません。
Vera Rubinは6つの主要コンポーネントが完璧に整合した最高密度の計算機です。
ソフトウェアの「檻」が消えた世界では、皮肉にもVera Rubinの圧倒的な物理性能が、他社のソフトウェア資産をも吸い寄せる「インフラの磁石(ブラックホール)」として機能する可能性があります。
これはCUDAという方言の強さというより、システム整合性が生む“物理効率”の勝利です。
特にVera Rubin世代では、ソフトウェアの壁が十分に薄れたとき、NVIDIAは「囲い込みのメーカー」から、あらゆる知能を最も低コストで精製する「エネルギーインフラ」へと脱皮を遂げるのかもしれません。
まとめ
2026年、AIの戦場は「チップを何枚持っているか」という物理の争いから、「どこのチップでも動かせる知力」というソフトウェア抽象化の道の可能性を秘め始めました。
少なくともCUDAという見えない壁は、今や崩れ去るのではなく、より高度な「インフラ選択の自由」へと昇華されていくのではないでしょうか?
CTO・技術選定者向け
- 「CUDAか非CUDAか」という古い二元論を捨て、抽象化レイヤーを使いこなしながら、Vera Rubinという最強のインフラを「あらゆるエコシステムの恩恵を享受しながら使い倒す」戦略へ舵を切ってください。
エンジニア向け
- 「CUDAが書ける」ことは依然として価値がありますが、それ以上に「ソフトウェアでハードウェアの物理的な限界を超える」抽象化のスキルを磨くことが、これからの最強の武器になる可能性があることをご認識いただければ幸いです。
落とし穴(1行):ソフトウェアのポータビリティを単なる「脱NVIDIA」の手段と見誤ると、「あらゆる資産を飲み込むVera Rubinの真の引力」を見失います。
今日のお持ち帰り3ポイント
- CUDAの強さは、20年の密結合が生んだ「ハードとソフトの物理的な整合性」という唯一無二の職人芸にある。
- ZLUDA、Triton、Mojoはそれぞれ異なるレイヤーで「城壁」を無力化し、開発者にインフラ選択の自由を提案している。
- ソフトの壁が消えた世界では、皮肉にもVera Rubinという「物理的に最も優れたインフラ」へ、他社の資産すら流入する可能性がある。
専門用語まとめ
- PTX (Parallel Thread Execution)
- NVIDIA GPU向けの低レベル中間命令。ZLUDAなどの互換アプローチは、これを変換・解釈することで、他社GPU上でCUDA資産を動かす方向へ近づけます。
- MLIR (Multi-Level Intermediate Representation)
- TritonやMojoが採用する次世代コンパイラ技術。異なるチップへの最適化を一貫して行う鍵です。
- Blocked Algorithms (タイル化アルゴリズム)
- 巨大なデータを小さなブロック(タイル)に分割して処理する手法。GPUのメモリ階層を100%活用するために不可欠な設計思想です。
- ABI (Application Binary Interface)
- プログラムがOSやライブラリとやり取りするためのバイナリレベルの規約。互換レイヤーは、この境界(呼び出し規約)を吸収することで、アプリ改修を最小化する方向を狙います。
よくある質問(FAQ)
Q1. ZLUDAやTritonを使えば、NVIDIAは不要になりますか?
A1. むしろ逆の可能性があります。ソフトウェアの壁が下がることで、他社製チップ用に書かれた優れた資産が、Vera Rubinという「最高効率のインフラ」へ流入し、NVIDIAの優位性がさらに際立つ可能性があります。
Q2. TritonやMojoを使えば、CUDAエンジニアは不要になりますか?
A2. いいえ。抽象化レイヤーの背後で性能を絞り出すには、ハードの深部を理解したCUDAの知識が依然として不可欠です。職人の役割が「筆」から「設計図」へ変わっただけです。
Q3. 2026年、結局どのメーカーのチップが「買い」ですか?
A3. 「究極のインフラ整合性」を求めるなら、現時点ではRubinが最有力候補と言えます。しかし、特定モデル(Llama等)を極限まで低コストで回したいなら、Etched Sohu等の特化ASICが有力な選択肢になりつつあります(2026年後半以降の量産動向に注目)。
主な参考サイト
- ZLUDA: CUDA on Non-NVIDIA GPUs (GitHub)
- OpenAI Triton: An intermediate language for AI compilers
- Modular: Mojo Programming Language for AI Developers
- NVIDIA Newsroom: Rubin Platform Overview(2026)
合わせて読みたい
更新履歴
- 初版公開