


効率的なAIの時代 – 学習から推論へのパラダイムシフト
はじめに:AIは「学習」から「瞬時の判断」の時代へ
これまで、ChatGPTに代表される大規模言語モデル(LLM)など、AI技術の進化は「学習」を中心に、莫大なデータを使い、計算資源への大きな投資によって支えられてきました。「規模のメリット」を最大限に活かし、AIは驚異的な「賢さ」を獲得してきたのです。
しかし今、AI活用の流れは確実に変わりつつあります。学習によって賢くなったAIを、実際に「使う」フェーズ、つまり「推論」に注目が集まっているのです。特に、私たちの身近にあるスマートフォンやスマートウォッチ、工場や家庭で活躍するIoT機器、さらには自律的に動く人型ロボットなどが、その場で状況を瞬時に判断し、最適解を導き出すといった応用が強く求められるようになってきました。
クラウドにデータを送って処理を待つのではなく、デバイス上でリアルタイムに答えを出す「推論」をいかに速く、効率的に行うかが、今後のAI活用の鍵となります。
この流れを受け、推論処理に特化したAIチップの開発競争も激化しています。
このような大きな変化の中で、AIモデルそのものを、より小さく、速く、省エネにする「モデル最適化」の技術が、かつてないほど重要になっています。
本記事では、AIの新たな潮流を支える「効率的なAI」の考え方と、その核心となる「モデル最適化」の最新技術について、分かりやすくご紹介していきます。
「瞬時の判断」が求められる時代:AI効率化の必要性

上図は、クラウド中心の大規模学習から、エッジデバイスでの効率的な推論への移行に関する技術変化の全体像を示してます。
なぜ今、AIの「効率化」、特に「推論」の効率化がこれほど重要なのでしょうか?
それは、AIが活躍する舞台が私たちの生活空間や産業現場へと広がっているからです。
1. リアルタイム性の要求⏱️
自動運転車🚗が障害物を避ける、工場のロボットアーム🤖が製品を正確につかむ、スマートグラスが目の前の景色に関する情報を瞬時に表示する・・・これらの事例では、一瞬の遅れも許されません。クラウドとの通信時間はボトルネックとなり、デバイス上での高速な「推論」が不可欠です。
2. エッジデバイスの制約🏕️
スマートフォン📱、ウェアラブル端末⌚、IoTセンサー、ロボットなどの「エッジデバイス」は、クラウドのサーバーと比較して、計算能力、メモリ容量、そして何よりバッテリー(消費電力)🔋に厳しい制約があります。
つまり、高性能であり且つ「燃費の悪い」AIモデルのニーズが急速に高まっているわけです。
3. プライバシーとセキュリティ🔐
個人の顔情報、健康データ、あるいは企業の機密情報などを扱う場合、データを外部のクラウドに送信することには抵抗があります。デバイス内部でAI処理を完結させる「エッジAI」は、プライバシー保護の観点からも強く求められています。
4. 通信環境への非依存🌐
インターネット接続が不安定な場所や、そもそも接続がない環境(トンネル内の監視、災害現場など)でも、デバイス上でAIが動作すれば、その活用範囲は大きく広がります。
5. コスト効率💰
クラウド利用料や通信費を抑え、より多くのデバイスにAI機能を搭載するためにも、AIモデル自体の「燃費」を良くすることが重要です。
このように、AIが社会のあらゆる場面で「瞬時の判断」を担う未来を実現するためには、AIをより軽量・高速・省電力にする「効率化」が避けて通れない課題となっているのです。
パラダイムシフト:AIは「特化・効率」重視へ
かつてAIの進化は、より多くのデータで学習し、より多くのパラメータを持つ巨大なモデルを構築するという「規模の追求」によって牽引されてきました。計算能力の向上が、そのままAIの「賢さ」に直結すると考えられていたのです。
しかし、その潮流は今、明確な転換点を迎えています。現実社会の多様な課題解決や、実用的なビジネス展開を見据えたとき、単なるモデルの巨大化だけではコストや運用面での限界が見えてきました。開発コストの増大、消費電力の問題、そして特定の現場ニーズへの最適化不足などが顕在化してきたのです。
この状況を受け、AI活用の最前線では新たな方向性が強く求められています。それが、「効率」を最重要視する考え方へのシフトです。特に2025年以降を見据えると、汎用的な超巨大モデルだけでなく、特定の業界やタスクに合わせて精度と効率を両立させた「特化型AIモデル」が主流になると予測されています。
これらのモデルは、工場での異常検知、自動運転における瞬時の判断、あるいはスマートフォン上での高度な機能提供など、それぞれの現場で「即時に」「賢く」意思決定を下す能力が不可欠となります。
AI効率化の核心技術:「モデル最適化」とは?
この「効率化」の要求に応える中核技術が「モデル最適化」です。
これは、学習済みの高性能なAIモデルの「賢さ」(精度)をできるだけ維持しながら、推論時の計算量やモデルサイズ、メモリ使用量を削減するための技術群です。
これにより、リソースの限られたエッジデバイス上でも高速かつ省電力な推論が可能になります。
ここでは、主要なモデル最適化の手法をいくつかご紹介します。
量子化 (Quantization): AIの計算をシンプルに
AIモデル内部では、膨大な数値を非常に細かい精度(例:32ビット浮動小数点数)で扱っています。量子化は、これらの数値をより粗い、シンプルな精度(例:8ビットや16ビット整数)に変換する技術です。高解像度の写真をJPEGにするように、多少の精度低下と引き換えに、モデルサイズを劇的に縮小し、計算速度を大幅に向上させます。
特に、スマートフォン搭載のAIチップ(NPU)などは、この量子化されたモデルを高速に処理できるように設計されていることが多いです。
実際、Google Pixelシリーズで用いられるTensor Processing Unit(TPU)は8ビット整数演算に最適化されており、量子化モデルで最大4倍の処理速度向上を実現しています。最近では、2ビットや3ビットといった「極低ビット量子化」など、さらなる効率化を目指す研究も活発です。例えばMeta AIの研究チームはLLaMaモデルを4ビットに量子化し、精度をわずか2%低下させるだけでモデルサイズを8分の1にすることに成功しています。
註:NPU (Neural Processing Unit):ニューラルネットワーク処理に特化した専用プロセッサで、AI計算を高速かつ省電力で実行できるよう設計されています。
参考URL:
- Google AI Blog: https://ai.googleblog.com/2020/03/quantization-aware-training-with.html
- Meta AI Research (arXiv): https://arxiv.org/abs/2306.06965
プルーニング/剪定 (Pruning): AIモデルの「贅肉」を削ぎ落とす
大規模なAIモデルには、推論の精度にあまり寄与しない、冗長な部分が含まれていることが分かっています。プルーニングは、そのような不要な接続や重みを「枝刈り」のように削除し、モデルをスリム化する技術です。
例えば、重要度の低いニューロン間の結合(重み)を特定し、その値をゼロに設定することで、モデルの疎性(スパーシティ)を高めます。
典型的には、大規模言語モデルの30-40%の重みをプルーニングしても、精度はほとんど低下しないことが実証されています。
OpenAIのGPT-2モデルでは、適切なプルーニング手法により、パラメータ数を50%削減しながら、元のモデルの精度の95%以上を維持することに成功しました。これにより、モデルサイズと計算量が削減され、推論の高速化と省メモリ化に繋がります。量子化と組み合わせることで、相乗効果も期待できます。
註:疎性(スパーシティ):分かりやすく言うと、モデル内の多くの数値がゼロになっている状態のことです。例えば、100個の数値があるうち80個がゼロで、実際に情報を持つのは20個だけという状態です。これは本の中で重要な部分だけにマーカーを引いて、それ以外は読み飛ばせるようにするのに似ています。ゼロの部分は計算する必要がなく、また保存する際にも特別な圧縮方法を使えるため、処理を速くしたりメモリを節約したりできるのです。
参考URL:
- The Lottery Ticket Hypothesis (MIT CSAIL): https://arxiv.org/abs/1803.03635
知識蒸留 (Knowledge Distillation): 巨大AIのエッセンスを小型AIへ
知識蒸留では、まず、非常に高性能だが巨大な「教師モデル」を用意します。そして、その教師モデルの出力や内部的な振る舞いを「お手本」として、より小型で軽量な「生徒モデル」を学習させます。
具体的には、教師モデルの出力を単なる「正解/不正解」のハードラベルではなく、確率分布(ソフトラベル)として使用します。例えば、画像認識タスクにおいて教師モデルが「この画像は犬(80%)、狼(15%)、キツネ(5%)である」と予測した場合、この確率分布全体を生徒モデルの学習目標とします。
註:ソフトラベル:単一のカテゴリだけでなく、複数のカテゴリに対する確率値として表現されたラベル。教師モデルの「迷い」や「微妙な判断」も含む豊かな情報を伝達できます。
温度パラメータ(典型的には2~4)を調整することで、この確率分布を「滑らかに」し、教師モデルの知識をより効果的に転移できます。
GoogleのBERTモデル(3億4千万パラメータ)からDistilBERT(6600万パラメータ)への蒸留では、モデルサイズを約5分の1に削減しながら、元の性能の97%を維持することに成功しました。
生徒モデルは、単独で学習するよりも効率的に、教師モデルの持つ「知識」や「判断のコツ」を吸収し、小さいながらも高い性能を発揮できるようになります。この方法により、生徒モデルは教師モデルに匹敵する精度を持ちながら、はるかに小さな計算資源で動作することが可能になるのです。推論効率の良い小型モデルを作るための強力な手法として注目されています。
参考URL:
- HuggingFace DistilBERT: https://huggingface.co/docs/transformers/model_doc/distilbert
効率的なアーキテクチャ: 最初から「燃費の良い設計」で
既存モデルの「後加工」だけでなく、AIモデルの構造(アーキテクチャ)そのものを、最初から推論効率が良いように設計する研究も進んでいます。例えば、複数の小さな専門家モデル(Experts)を状況に応じて使い分ける「Mixture-of-Experts (MoE)」構造や、計算量の多いAttention機構を工夫したモデルなどが登場しています。
註:Attention機構:自然言語処理などで使われる仕組みで、入力データの各部分に「注意」を払う重み付けを学習することで、関連性の高い情報に焦点を当てる技術です。高性能ですが計算コストが高いという特徴があります。
GoogleのSwitchトランスフォーマーでは、入力に応じて最適な「専門家」サブネットワークだけを活性化させることで、全体の1~10%程度のパラメータのみを使用して推論を行います。これにより、1兆パラメータ以上の超大規模モデルでありながら、実際の計算量は従来の数十分の一に抑えられています。
また、MetaのLLaMaシリーズでは、標準的なTransformerアーキテクチャの計算効率を改善するために、RMSノーム正規化や回転位置埋め込みなどの技術が導入され、GPT-3と同等の性能を10分の1のパラメータ数で実現しています。
これらは、特定のタスクにおいて、少ない計算量で高い性能を達成することを目指しています。
註:Mixture-of-Experts (MoE):入力に応じて異なる「専門家」ネットワークを選択的に活性化させる構造で、全てのパラメータを常に使用するのではなく、必要な部分のみを使うことで計算効率を高めます。
参考URL:
- Google AI Blog (Switch Transformers): https://ai.googleblog.com/2021/01/scaling-deep-learning-with-switch.html
- Meta AI Research (LLaMA): https://ai.meta.com/blog/large-language-model-llama-meta-ai/
これらの最適化技術は、AI推論のボトルネックを解消し、様々なデバイスへのAI搭載を加速させる鍵となります。
| 最適化技術 | 概要 | メリット | デメリット | 主な適用例 |
| 量子化 (Quantization) | 32ビット浮動小数点数を8/16ビット整数などに変換 | モデルサイズの大幅削減(最大75%)<br>推論速度の向上(2〜4倍) | わずかな精度低下の可能性 | スマートフォンAI処理<br>画像認識モデル |
| プルーニング (Pruning) | 重要度の低いニューロン接続を削除 | モデルの軽量化(30〜90%)<br>メモリ使用量削減 | 過剰削除で精度低下の可能性 | 自然言語処理モデル<br>IoTデバイス |
| 知識蒸留 (Knowledge Distillation) | 大型教師モデルから小型生徒モデルへの知識移転 | 小型モデルで高精度実現<br>アーキテクチャの自由度高 | 教師モデルの準備が必要<br>学習プロセスが複雑 | モバイルアプリAI<br>音声認識 |
| 効率的アーキテクチャ | 初めから効率を考慮したモデル設計 | 特定タスクに最適化<br>計算資源効率の最大化 | 汎用性が低下する可能性<br>設計難度が高い | 特定業界向けAI<br>MoEモデル |
出典:上記記事の中に記載されたサイトを参照して作成した。
「モデル最適化技術比較表」は、量子化、プルーニング、知識蒸留、効率的アーキテクチャの4つの主要技術を整理し、それぞれの特徴と用途を一覧で把握できるようにしています。
「推論」特化型AIチップ市場の急成長
AIの”頭脳”であるチップも大きな転換期を迎えています。従来はNvidiaのGPUが市場を席巻してきましたが、今やGoogleのTPUやGroq、Cerebrasなど新興企業が、推論専用の高速・低消費電力チップで急速にシェアを伸ばしています。
推論専用チップは、同じタスクでGPUの数倍の速度や効率を実現し、コスト削減やリアルタイム処理の要求に応えています。AI推論チップ市場は今後10年で飛躍的に拡大し、用途やニーズごとに最適なソリューションが選ばれる時代へと移行しています。
Nvidia、Intel、Google、AMDなどの大手はもちろん、QualcommやMediaTek、Graphcore、Groqなど多様なプレイヤーが推論・エッジAIチップでしのぎを削っています。今後は、用途や現場ごとに最適なAIチップと最適化技術が選ばれる「群雄割拠」の時代となるでしょう。
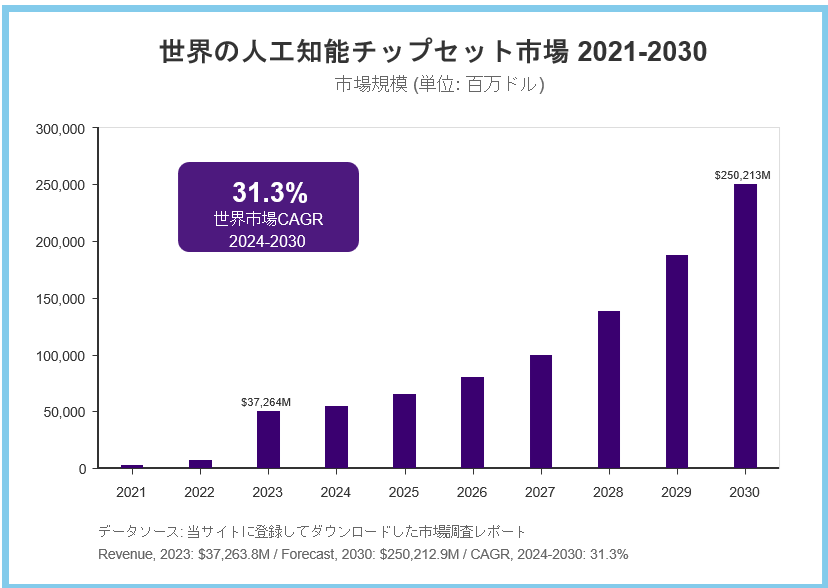 図2 世界の人工知能チップセット市場 2021-2030
図2 世界の人工知能チップセット市場 2021-2030Nvidia、Google、Qualcommなど主要プレイヤーのシェアを含めた市場予測を示し、2023年から2030年にかけての急成長を視覚化しています。
参考サイト名:Grand View Research “Artificial Intelligence Chipset Market Trends”
推論をデバイスへ:「エッジAI」が実現する世界
モデル最適化によって軽量化・高速化されたAIは、いよいよ「エッジAI」として、データが発生する現場、つまりスマートフォン、自動車、IoT機器、ロボットなどで活躍する道が開かれます。
エッジAIとは、データの発生現場(エッジ)でAI処理を完結させる技術です。エッジAIは、最適化されたモデルをデバイス上で直接実行することで、クラウドAIでは難しかった多くのメリットをもたらします。
真のリアルタイム性
クラウドとの通信遅延がなくなるため、自動運転の危険回避やロボット制御、AR/VRでのインタラクションなど、「瞬時の判断」が求められる応用が可能になります。これにより、通信遅延やプライバシーリスクを回避し、リアルタイムな意思決定が可能となります。
プライバシーとセキュリティの向上
データがデバイス外部に出ないため、ユーザーは安心してAI機能を利用できます。個人情報や機密データを外部に送信する必要がないので、情報漏洩リスクを大幅に低減できるのです。
通信コストの削減とオフライン動作
ネットワーク帯域を圧迫せず、インターネット接続がない場所でもAIが利用可能になります。これにより、トンネル内や山間部、災害現場など、通信インフラが整っていない場所でもAIの恩恵を受けることができるようになります。
まさに、冒頭で述べた「AI活用の流れの変化」——学習中心から推論中心へ、クラウド集中からエッジ分散へ——を体現するのがエッジAIです。そして、その実現には、モデル最適化が不可欠なピースとなります。
エッジAIチップ市場はIoTや5Gの普及に支えられ、今後も急成長が見込まれています。さらに、エッジデバイス上でこれらの最適化されたAIモデルを効率的に動かすための専用ハードウェア、つまり推論に特化したAIチップ(NPUなど)の開発も急速に進んでいます。ソフトウェア(モデル最適化)とハードウェア(専用チップ)の両輪が揃うことで、エッジAIはますます強力かつ身近な存在になっていくでしょう。
エッジAIの具体的な応用例
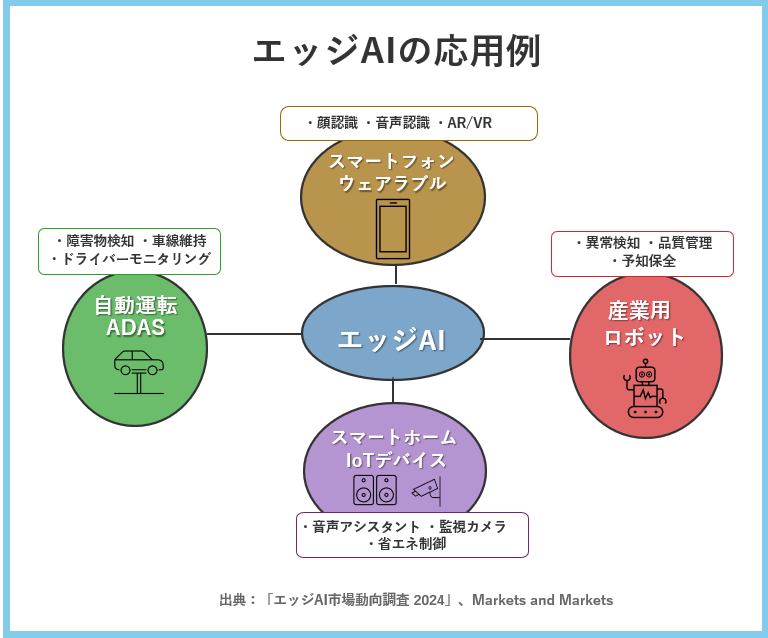
この図は「エッジAI応用例」では、スマートフォン、自動運転、産業ロボット、スマートホームという4つの主要応用分野を図示し、各分野での具体的活用例を示しています。エッジAIによって可能になる応用例を、いくつか具体的に見ていきましょう。
📱 スマートフォンとウェアラブルデバイス
最新のスマートフォンには、すでに専用のAIプロセッサ(NPU)が搭載され、顔認識ロック解除、リアルタイム翻訳、カメラの自動シーン認識など、プライバシーを保ちながら高速な処理を実現しています。
例えば、Apple社のA17 ProチップやQualcommのSnapdragon 8 Gen 3は、8ビット量子化された効率的なAIモデルを1秒あたり数十兆回の演算で処理し、バッテリー消費🔋を最小限に抑えながら高度なAI機能を提供しています。
また、スマートウォッチ⌚は心拍数の異常検知❤️や睡眠分析🛌など、健康データを端末内で処理することで、バッテリー持続時間を確保しつつ、敏感な個人健康情報を保護しています。
産業用ロボットと製造業
工場内の産業用ロボット🤖は、製品の欠陥をリアルタイムで検知し、即座に対応する必要があります。エッジAIにより、画像認識によるわずかな異常も見逃さず、生産ラインを止めることなく製品品質を確保できます。
また、予知保全の分野でも、機械の異常音🔊や振動パターンを現場で分析し、故障を未然に防ぐことが可能になります🛠️。
自動運転車と高度運転支援システム
自動運転車🚘は、周囲の歩行者や障害物を瞬時に認識し、判断・対応する必要があります。車両内のAIプロセッサで処理することで、通信遅延なく安全な運転が可能になります。
また、カメラによるドライバーモニタリング📷で、居眠り運転😴などの危険な状態をリアルタイムで検知し、事故を防止することができます。
スマートホームとIoTデバイス
家庭内のカメラ📹や音声デバイス🎤は、クラウドに送信せずに端末内で顔認識や音声認識を行うことで、プライバシーを保ちながら、より自然な操作体験を提供できます。
また、低消費電力のIoTセンサー📡が、バッテリー駆動で長期間動作しながら異常検知や状況判断を行い、必要な場合のみデータを送信する「エッジコンピューティング」の実現も可能になります⚙️。
よくある質問(Q&A)
Q1. 推論(Inference)とは何ですか?
A1. 推論とは、学習済みのAIモデルが現実のデータに基づいて瞬時に判断や予測を行う処理のことです。クラウドに頼らず、デバイス上でリアルタイムに結果を出す技術として注目されています。
Q2. モデル最適化とは何を指しますか?
A2. モデル最適化とは、AIモデルのサイズや計算負荷を削減しつつ、精度を維持する技術の総称です。量子化、プルーニング、知識蒸留などが代表的な手法です。
Q3. エッジAIが重要視される理由は?
A3. エッジAIは、スマートフォンやIoT機器などでAI処理を完結させることで、低遅延・高セキュリティ・オフライン動作を実現できるため、リアルタイム性やプライバシー保護が求められる場面で非常に重要です。
まとめ:効率的なAIが拓く、AI活用の新たな地平 🌐
AI技術は、「大規模化による賢さの追求」という段階を経て、今まさに「効率化による実用化と普及」という新たなステージへと移行しつつあります。その中心にあるのが、AI推論をデバイス上で瞬時に行うための「効率的なAI」という考え方です。
モデル最適化技術(量子化、プルーニング、知識蒸留、効率的アーキテクチャ)⚙️は、AIをスリムで高速にし、スマートフォン、IoT機器、ロボットといったリソースの限られたエッジデバイスへの搭載を可能にします。
そして、最適化されたAIがエッジAIとしてデバイス上で動作することで、低遅延、高プライバシー🔐、オフライン動作といった特性が活かされ、リアルタイム制御や高度なパーソナライゼーションなど、これまでにない価値を生み出すことが期待されます。
この流れは、単に技術的な変化にとどまりません。AIを開発・利用するためのコストを引き下げ、「AIの民主化」をさらに推し進めます。また、省エネルギー化は、AI技術の持続可能性🌱を高める上でも重要です。
AIの進化は「大きさ」から「賢さ」、そして「効率」へと軸足を移しています。モデル最適化や推論特化チップ、エッジAIの進化は、私たちの生活やビジネスの現場でAIをより身近で実用的なものに変えていくでしょう。
学習から推論へ、クラウドからエッジへ——この大きなパラダイムシフトは、あなたのビジネスや日々の生活にどのような変化をもたらすでしょうか? 本記事で解説した「効率的なAI」の技術動向、特にモデル最適化やエッジAIの進展は、その変化の核心です。この潮流を理解し、自社の戦略や自身のスキルセットにどう活かせるかを考えることが、AIを真の力とするための第一歩となるでしょう。効率化の先に拓かれる、AIが社会基盤となる未来に、ぜひご注目ください。🚀
参考文献 / 参考情報
- Grand View Research (AI Chipset Market Analysis):
- NVIDIA Developer (TensorRT – AI Inference Optimization):
- Qualcomm (On-Device AI Technology):
以上








