


※本記事は継続的に最新情報へアップデートしています。
AIエージェント評価とは?成功率・誤実行・再現性をどう測るか【2026年版】
2026年、AI評価は「答え合わせ」から「行動監査」へ進みました。 チャットAIなら、最終回答の自然さや正確さを見るだけでもよかったかもしれません。けれど、ツールを呼び、状態を変え、複数ターンにまたがって働くAIエージェントでは、それでは足りません。今、本番導入の分かれ目になっているのは、そのエージェントが何を答えたかではなく、どう動き、どこで止まり、どんな失敗をしたかを測れるかどうかです。
✅ 先に結論
- ポイント1:AIエージェント評価の本質は、最終回答ではなく途中の行動品質を測ることです。
- ポイント2:見るべきは成功率だけではありません。誤実行、停止判断、再現性、コスト、時間まで含めて評価する必要があります。
- ポイント3:本番運用に耐えるかどうかは、モデル単体よりもハーネス(エージェントを動かす実行基盤――ツール接続、状態管理、再試行ロジック、停止条件などを含む周辺実装の総体)を含むシステム全体で決まります。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

AIエージェント統制シリーズにおける本記事の位置づけ
AIエージェントを本番運用するには、接続・セキュリティ・評価・評価設計・監視・異常検知・停止・再開までを、1つの流れとして設計する必要があります。本記事は、その中で「成功率・誤実行・再現性をどう測るか」を扱います。
- A2A / MCP = 何をどうつなぐか
- AIエージェントセキュリティ = なぜ危ないか、何を守るか
- ゼロトラスト設計 = どんな原理で守るか
- AIエージェント評価 = 成功率・誤実行・再現性をどう測るか(本記事)
- AI Evals = 評価基準・評価データ・採点ロジックをどう設計するか
- Observability = 本番で何を見続けるか
- Failure Detection = 何を異常と判断するか
- Guardrails / Human Review = どこで止め、どこで人に渡すか
- Approval Policy / Runbook = 止めた後、誰が裁定し、どう再開するか
何が変わったのか
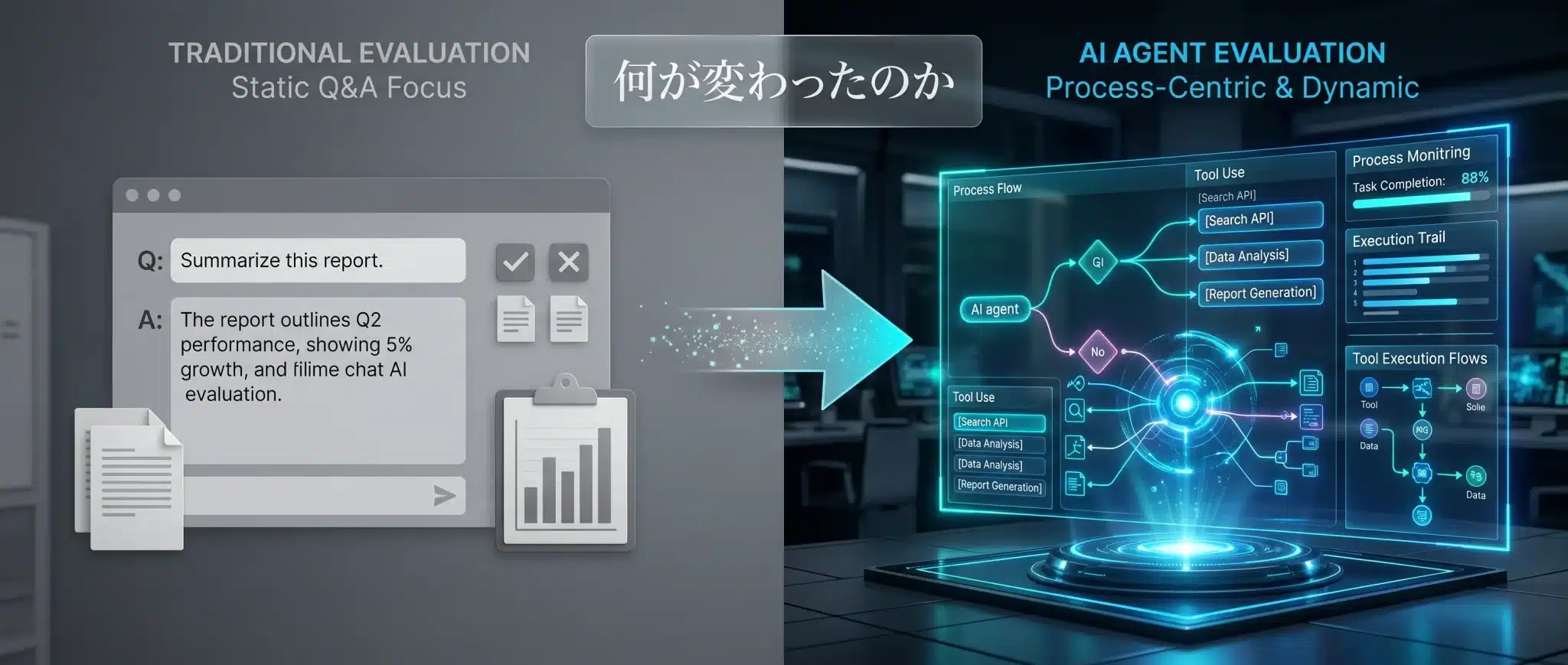 変わったのは評価対象である。最終回答ではなく、途中の行動そのものが評価対象になった。
変わったのは評価対象である。最終回答ではなく、途中の行動そのものが評価対象になった。
従来のLLM評価では、質問に対してどれだけ妥当な答えを返せるかが中心でした。ところがAIエージェントは、途中でツールを選び、必要に応じて再計画し、環境の状態を変えながらタスクを進めます。つまり、評価の主語が「出力」から「行動」へ移ったのです。
この変化は、Arpableでこれまで扱ってきたA2Aとは?MCPとの違いや2026年、AIエージェント「実装元年」への続きとして捉えると分かりやすくなります。接続が整い、実装の現実味が増したからこそ、次に問われるのは「そのエージェントを、どこまで信じてよいか」です。
出力評価から行動評価へ
従来のチャットAIなら、最終回答の品質を見るだけでも一定の判断はできました。しかしエージェントは、途中で検索し、APIを呼び、ファイルを更新しながら、次の判断へと進みます。ここでは、回答そのものよりも、途中の行動が適切だったかが重要になります。
なぜ今、この変化が効いてくるのか
接続技術が整ったことで、エージェントは「説明するAI」から「働くAI」へ近づきました。そうなると、自然な文章を返せるだけでは不十分です。ツールの使い方、確認の入れ方、停止判断、状態変更の扱いまで含めて見なければ、本番品質は判断できません。
安全設計の前提は、AIエージェントセキュリティやAIエージェントのゼロトラスト設計でも整理しています。本記事は、その次の論点である「どう測るか」を扱います。
なぜ今重要なのか
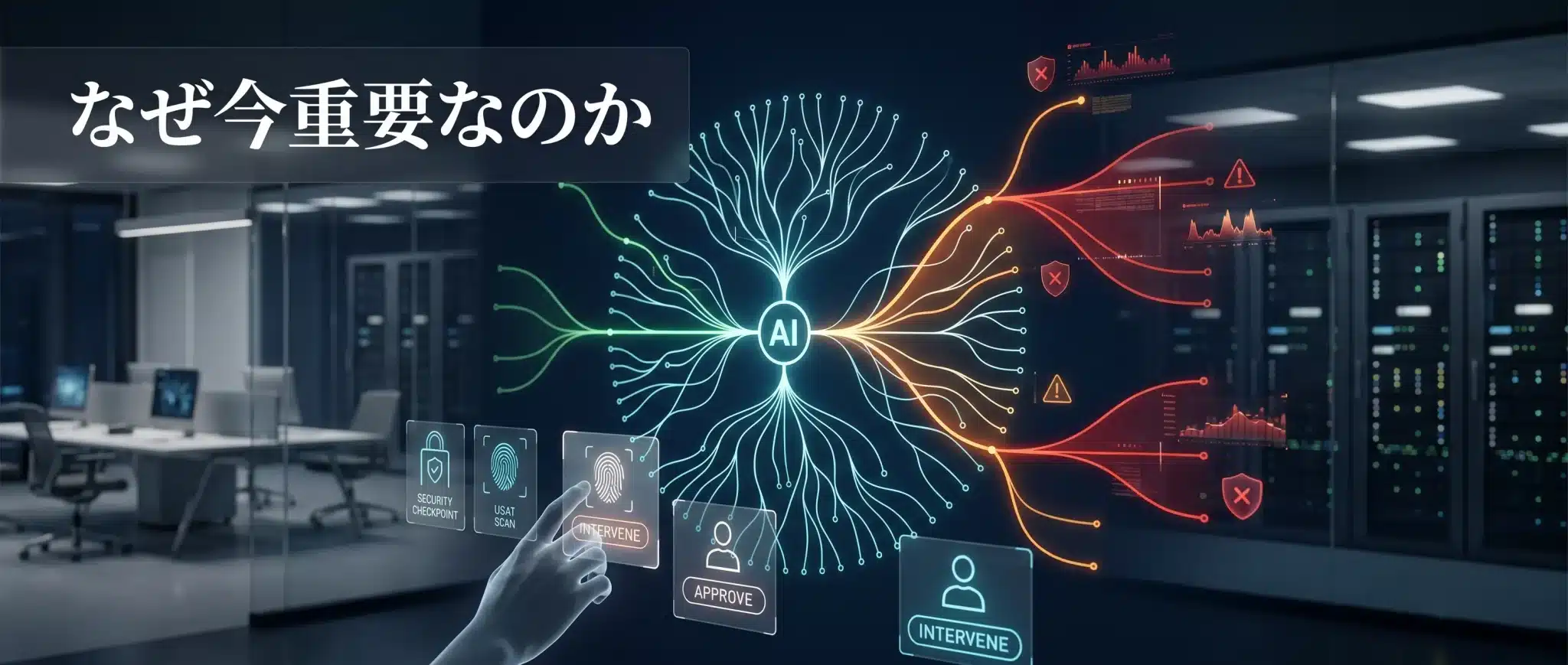 重要なのは、エージェントが「正しい答え」より先に「危ない行動」を起こしうるからである。
重要なのは、エージェントが「正しい答え」より先に「危ない行動」を起こしうるからである。
企業がいま直面している問題は、AIが賢いかどうかよりも、危ない失敗をどれだけ減らせるかです。誤ったツール呼び出し、確認漏れ、状態破壊、長時間処理の逸脱は、最終回答だけ見ても見つかりません。
事業への影響
現場が本当に怖いのは、多少賢さが足りないことではなく、勝手に処理を進めることです。たとえば顧客対応エージェントが誤ったステータス変更を行えば、後工程の人手が増えます。営業支援エージェントが誤った次アクションを提案すれば、商談の優先順位を誤るかもしれません。こうした失敗は、単なる誤回答以上に、事業への影響が深刻です。
開発への影響
開発現場でも、エージェント評価は「モデル比較」では終わりません。入出力の整形、ツール選択、状態保持、再試行、停止条件まで含めて、システムとしての振る舞いを見なければなりません。つまり、評価対象はモデル単体ではなく、モデルとハーネスを含む実装全体です。
運用への影響
本番運用に入ると、評価は一度きりでは終わりません。本番で生じた失敗をログから抽出し、評価ケースとして組み込み、改善後に再測定する。この循環がなければ、評価はすぐに形骸化します。ここはLLMOps完全ガイドと強くつながる論点です。
どう捉えるべきか
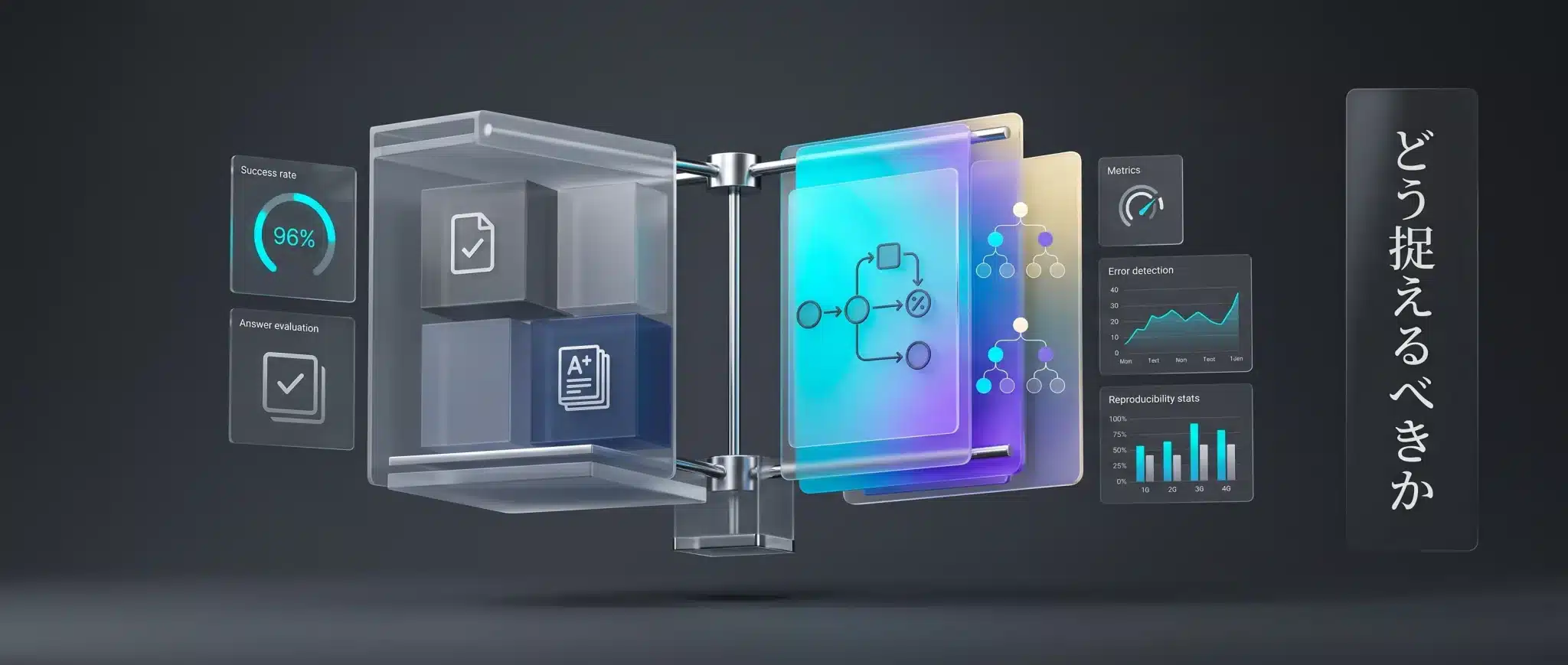 エージェント評価とは、答えの品質管理ではなく、委任可能性の監査である。
エージェント評価とは、答えの品質管理ではなく、委任可能性の監査である。
OpenAIが提案する Agent Evals のような具体的実装を含め、エージェント評価全体を単なる採点ツールと捉えると、本質を見誤ります。重要なのは、どれだけ賢いかよりも、どの条件下で、どこまで仕事を委ねてよいかを判断することです。
本質的な見方
人に仕事を任せるとき、私たちは完成物だけを見ません。報連相のタイミング、確認の入れ方、危険な場面での停止判断、失敗時の崩れ方まで見ます。AIエージェントも同じです。したがって、エージェント評価とは、最終回答の採点ではなく、行動の監査です。
限界と注意点
ただし、エージェント評価は万能ではありません。評価ケースが現実を映していなければ意味は薄れますし、採点基準が曖昧なら改善も曖昧になります。そこでOpenAIやAnthropicは、コードベースの決定的な採点(たとえばツール引数・状態変更の検証)と、LLM-as-judge による主観的評価(回答品質やプラン妥当性)を組み合わせる考え方を採っています。また、複数の正解経路があるタスクでは、「この手順だけが正しい」と決めつけるのではなく、結果と過程を分けて採点する必要があります。
| 評価項目 | 何を見るか | 具体例 | 実務上の注意点 |
|---|---|---|---|
| 成功率 | タスクを完遂できたか | 問い合わせ分類、要約、検索完了 | 成功率だけでは危ない失敗を見逃す |
| 誤実行率 | 誤ったツールや不要操作の有無 | 不要なAPI呼び出し、誤更新 | 最終回答が自然でも副作用が深刻な場合がある |
| 停止判断 | 確認すべき場面で止まれるか | 権限外処理の前に人へ確認 | 自律性を上げるほど停止設計が重要になる |
| 再現性 | 同条件で同程度の品質を保てるか | 同一ケースで結果が大きくぶれないか | 揺らぎが大きいと本番運用で信頼を失う |
| 時間 | 現場運用に耐える速度か | 長時間処理、再試行回数、応答遅延 | 精度が高くても遅すぎると業務に乗らない |
| コスト | 現場運用に耐える費用か | API利用料、ツール呼び出し回数、再実行費用 | 精度が高くても高すぎると継続運用に耐えない |
| ※ エージェント評価は「最終回答」ではなく「行動と結果の組み合わせ」で見ることが重要 | |||
実務ではどう判断するか
 成功率だけでなく、誤実行、停止判断、再現性、時間、コストまで含めて判断すべきである。
成功率だけでなく、誤実行、停止判断、再現性、時間、コストまで含めて判断すべきである。
エージェント評価をどこから始めるかは、理想論ではなく、どの業務で失敗コストが高いかを逆算して決めるのが現実的です。ここでありがちな誤解は、「成功率だけ見ればよい」という発想です。実務では、それでは足りません。少なくとも次の6つの軸を見ておく必要があります。
実際の評価フローとしては、①オフラインでのケース別評価 → ②ステージング環境でのトレース・誤実行チェック → ③本番トラフィックの一部を使った継続的なログ監査という三段階で回すのが、2026年時点での標準的な進め方の一つになりつつあります。特にオフライン評価では、本番やPoCで実際に起きた失敗ケースを20〜50件ほどピックアップし、評価データセットに落とし込むところから始めると、現場に響く指標になりやすくなります。
判断基準
判断軸はこの6つです。成功率、誤実行率、停止判断、再現性、時間、コストです。最終回答が自然でも、途中で危ない行動を起こすなら本番投入には向きません。
向いているケース
問い合わせ分類、社内ナレッジ検索、営業要約、RAG応答、エージェントによる定型ワークフローなど、成功条件を比較的定義しやすい業務から始めるのが現実的です。特に本番導入後の誤りコストが高い業務では、エージェント評価の価値が見えやすくなります。
向いていないケース
何をもって成功とするかを言語化できない状態で、いきなり全社展開するのは危険です。また、現場ログが取れない、ユースケースが広すぎる、責任分界が曖昧といった場合も、評価サイクルを回しても、改善に結びつきにくいです。
よくある失敗
失敗パターンは、最終回答が自然なら問題ないと錯覚することです。 実務では、もっともらしい誤回答よりも、誤ったツール実行や確認抜けのほうが深刻です。たとえば、ツール呼び出しが一つ余分に走るだけで、後工程のデータが汚染されることもあります。最終回答の見た目が自然なだけに、こうした副作用は見つかりにくいのです。
もう一つの失敗は、モデル性能だけを見て、ハーネス設計や確認ポイントを軽視することです。たとえば停止条件の設計が甘ければ、成功率が高いエージェントでも本番で予期しない副作用を起こします。評価スコアが改善しても現場の失敗が減らない場合、まず疑うべきはハーネス側の設計です。
AIエージェント評価のセルフチェック
- 最終回答だけでなく、途中のツール利用や状態変更を評価対象に入れているか?
- 止まるべき場面で人に確認を求める設計になっているか?
- 成功率以外に、誤実行、再現性、時間、コストを見ているか?
RAGやAgentic RAG文脈の評価詳細は、RAG完全ガイド、RAGチャンキング最適化と評価、Agentic RAGも合わせて確認すると、より立体的に理解できます。
一次情報からどこまで言えるか
事実として言えるのは、エージェント評価の難しさがモデル性能だけではなくハーネス設計に強く依存することです。
このテーマでは、一次情報が重要です。なぜなら、エージェント評価の設計思想はツールやフレームワークの実装と不可分であり、OpenAIやAnthropicがどう定義し、どう実装しているかを直接確認しなければ、現場の実態と乖離した評価基準になるからです。
一次情報
OpenAIは agent evals を、traces(実行ログ)、graders(採点ロジック)、datasets(評価データ)、eval runs(実行結果)を組み合わせて、エージェント品質を継続的に測定・改善する仕組みとして案内しています。Anthropicは agent evals を「AIシステムに入力を与え、grading logic(採点ロジック)で成功を測るテスト」と定義し、さらにモデルとハーネスを一体として評価すべきだと説明しています(Demystifying evals)。同社はさらに、コーディングエージェントの事例でも、ハーネス設計が評価精度の鍵を握ることを実証的に示しています(Harness design for long-running application development)。
解釈
ここから言えるのは、2026年のエージェント評価では「モデル性能が高いか」だけでは不十分だということです。重要なのは、どの条件で、どこまで安全に任せられるかを継続的に証明できることです。Arpableとしては、これを「賢さの証明」ではなく、委任可能性の監査として捉えるのが自然だと考えます。
まとめ
読者が持ち帰るべきなのは、AIエージェント評価が最終回答の採点ではなく、委任可能性の監査だという視点です。
結論を再整理すると、AIエージェント評価は、最終回答の採点ではありません。成功率だけでなく、誤実行、停止判断、再現性、時間、コストまで見る必要があります。そして本番運用に耐えるかどうかは、モデル単体ではなく、ハーネスを含むシステム全体で決まります。2026年の差は、どれだけ賢いモデルを選ぶかではなく、そのエージェントをどこまで信じてよいかを、継続的に測り続けられるかどうかで決まります。
参考文献 / 出典
一次情報
- OpenAI – Agent Evals Guide
- OpenAI – Eval Skills
- OpenAI – Evaluation Best Practices
- OpenAI – Evaluating Agents
- Anthropic – Demystifying evals for AI agents
- Anthropic – Harness design for long-running application development(コーディングエージェント事例)
二次情報
次に読むならこの3本
補足Q&A
Q1.
AIエージェント評価とは何ですか?
A1.
AIエージェント評価とは、最終回答だけでなく、途中のツール利用や状態変更を含めて、エージェント全体の成功を測る評価です。人間でいえば完成物の採点ではなく、仕事の進め方そのものを監査するイメージに近いです。だからこそ、回答の自然さだけでなく、誤実行や停止判断まで含めて見る必要があります。
Q2.
成功率だけではなぜ不十分なのですか?
A2.
成功率だけでは、誤実行、確認漏れ、停止判断ミス、コスト増といった危ない失敗を見逃すからです。たとえ最終結果が正しく見えても、途中で不要なAPIを呼んだり、止まるべき場面で進んだりしていれば、本番では大きな事故につながります。エージェント評価では、結果だけでなく過程も含めて見る必要があります。
Q3.
AIエージェントの評価はなぜ難しいのですか?
A3.
AIエージェントの評価が難しい理由は三つあります。第一に、最終回答だけでなく途中のツール利用・状態変更・停止判断まで評価対象が広い点。第二に、同じ入力でもモデルの確率的な性質から出力が毎回揺れる点。第三に、タスクの達成経路が一つとは限らず、「このステップだけが正解」と決め打ちできない点です。これらが重なるため、固定的な期待値によるテストでは、実力を正確に測れません。
更新履歴
- 2026年4月28日:初版公開








