


AIエージェントの異常検知とは?止める基準・アラート設計・エスカレーションの実務【2026年版】
AIエージェントは、壊れたときに「壊れた顔」をしてくれるとは限りません。 エラーを吐いて止まるなら、まだ対処しやすい部類です。厄介なのは、もっともらしく動き続けながら、静かに間違えるケースです。不要なツールを呼び続ける。承認待ちを飛ばす。コストだけが積み上がる。表面上は正常に見えるのに、実態はじわじわ壊れていく。
国内外のプロジェクト現場で何度も痛感してきたのは、問題そのものよりも、問題を問題として早く認識できないことのほうが、後で大きな損失になるという事実です。
AIエージェント運用でも同じです。AIエージェントの異常検知(Failure Detection)の本質は、エラーログを集めることではありません。異常として扱うべき逸脱を定義し、アラートやエスカレーションにつなげることにあります。
✅ 先に結論
- ポイント1:異常検知とは、「失敗したかどうか」を後から採点することではなく、「いま対応すべき逸脱かどうか」を運用中に判定することです。
- ポイント2:見るべき対象はエラーだけではありません。誤実行、承認フロー逸脱、コスト急増、ループ、挙動変化まで含めて設計する必要があります。
- ポイント3:アラート設計で重要なのは通知の数ではなく、誰が何を引き取るかが決まっていることです。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』▶ 詳細はこちら
AIエージェント統制シリーズにおける本記事の位置づけ
AIエージェントを本番運用するには、接続・セキュリティ・評価・評価設計・監視・異常検知・停止・再開までを、1つの流れとして設計する必要があります。本記事は、その中で「何を異常と判断するか」を扱います。
- A2A / MCP = 何をどうつなぐか
- AIエージェントセキュリティ = なぜ危ないか、何を守るか
- ゼロトラスト設計 = どんな原理で守るか
- AIエージェント評価 = 成功率・誤実行・再現性をどう測るか
- AI Evals = 評価基準・評価データ・採点ロジックをどう設計するか
- Observability = 本番で何を見続けるか
- Failure Detection = 何を異常と判断するか(本記事)
- Guardrails / Human Review = どこで止め、どこで人に渡すか
- Approval Policy / Runbook = 止めた後、誰が裁定し、どう再開するか
何が問題なのか
 AIエージェントの失敗は、派手な障害よりも「静かな逸脱」として現れやすいということです。
AIエージェントの失敗は、派手な障害よりも「静かな逸脱」として現れやすいということです。
従来の監視では、HTTP 500やタイムアウトのように、壊れたことが明確に分かる障害を捉えるのが中心でした。ところがAIエージェントでは、エラーを出さずに失敗することが珍しくありません。検索結果は返しているのに、毎回無関係なソースに寄り道している。更新処理は成功しているように見えるのに、本来必要だった承認を飛ばしている。返答は自然でも、不要な tool call が増えてコストだけが積み上がる。こうした失敗は、正常なログとして現れるのが厄介です。
2026年2月には、MetaのAIアライメント研究者が実験していたオープンソースエージェント「OpenClaw」は、停止指示の後も受信トレイのメール削除を続け、最終的に手動停止が必要になったと報じられました。こうした事例は、異常な継続動作を早期に検知し、制御レイヤーへ渡す条件を事前に設計しておくことの意味を端的に示しています。
OpenAIの tracing は model calls、tool calls、handoffs、guardrails を structured record として残せるため、こうした「一見正常な失敗」の切り分けに向いています。Anthropicも、agent evals の文脈で「最終発話」ではなく、環境が最終的にどう変化したかという、検証可能な最終状態を見る必要性を強調しています。つまり、異常検知で見るべきなのは「きれいに返したか」ではなく、期待された状態に到達したか、そこまでの過程に危険な逸脱がなかったかです。
静かな失敗とは何か
静かな失敗とは、エラーを吐かず、表面上は正常に見えながら起きる失敗です。たとえば、不要なツールを繰り返し呼ぶ、承認待ちを飛ばす、遠回りを続けて応答時間だけが伸びる、といったケースです。人間が見れば「何か変だ」と感じられても、通常のインフラ監視だけでは異常として扱われないことがあります。
なぜ通常の監視だけでは足りないのか
CPU使用率やレスポンス時間の監視は、インフラ障害には有効です。しかし、エージェントの失敗はしばしば「処理は終わっているが、中身が危ない」という形で現れます。だから、AIエージェント運用では、システム監視に加えて、行動の逸脱監視が必要になります。
前提となるObservabilityの考え方は、「デモで動く」から「本番で稼ぐ」へ。LLMOps完全ガイドや、シリーズ前編のObservability記事とつなげて理解すると整理しやすくなります。
異常とは何か
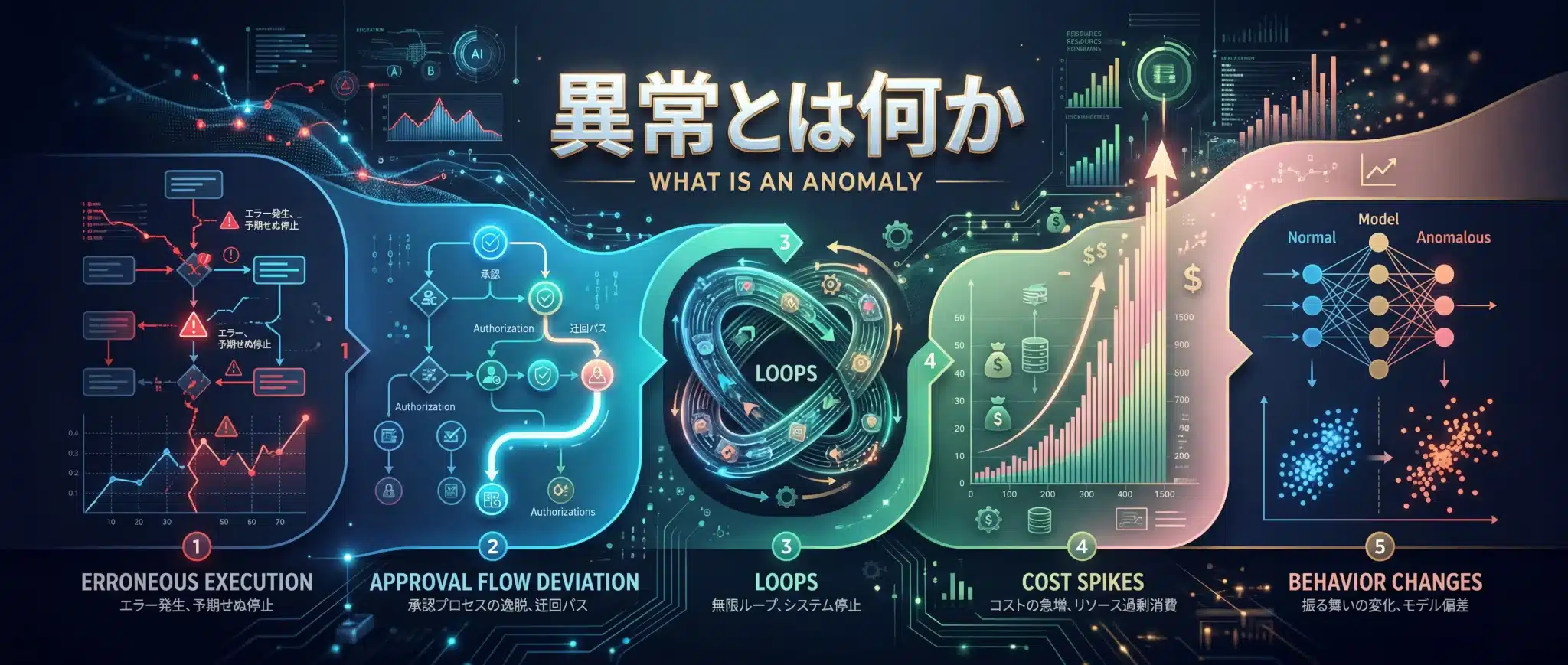 異常とは、単なるシステム障害ではなく、運用上許容できない逸脱です。
異常とは、単なるシステム障害ではなく、運用上許容できない逸脱です。
ここを曖昧にすると、アラートはただの騒音になります。Arpableとしての実務整理では、AIエージェントの異常は少なくとも5つに分けて考えると設計しやすくなります。
第一に誤実行。本来呼ぶべきでない tool を呼ぶ、不要な書き込みを行う、といったケースです。
第二に承認フロー逸脱。人間確認が必要な処理を、自律的に進めてしまうケースです。
第三にループや過剰再試行。結果が改善しないのに、同じ探索や tool call を繰り返すケースです。
第四にコスト急増や遅延悪化。回答は返るが、実務では受け入れられない費用や時間になっているケースです。
第五に挙動変化。モデルや prompt を変えた後に、似た条件でも以前と違う遠回りや失敗が増えるケースです。
OpenAIの trace grading は、こうした workflow-level issues を、「どのツールを選んだか」「どこで handoff や guardrail が発火したか」を含む実行履歴にスコアを付けることで見つける用途に向いているとされています。
ここで大事なのは、異常を「モデルの誤り」だけに閉じないことです。OpenAIは tool surface、handoff、guardrails、approval policy の違いを agent 設計の重要要素として扱っています。つまり異常は、モデル単体ではなく、モデル・ツール・ガードレール・承認ポリシーを含む実装全体の問題として見たほうが実態に即しています。
| 異常分類 | 何が起きるか | 具体例 | 実務上の注意点 |
|---|---|---|---|
| 誤実行 | 本来不要な操作を行う | 不要な更新、誤送信、余計な検索 | 最終回答が自然でも副作用が深刻な場合がある |
| 承認フロー逸脱 | 確認なしに先へ進む | 顧客データ更新、金額確定、権限変更 | 高リスク業務では即エスカレーション対象にする |
| ループ / 過剰再試行 | 改善しない試行を繰り返す | 同じ検索の連打、同一tool callの反復 | コストと遅延が静かに膨らむ |
| コスト急増 / 遅延悪化 | 品質は見かけ上保つが費用や時間が悪化する | API費用の急増、応答時間の長期化 | 精度だけで判断すると見落としやすい |
| 挙動変化 | 変更後に以前と違う振る舞いが増える | 遠回りの増加、失敗率の悪化 | prompt変更やモデル更新後は重点監視が必要 |
| ※ 重要なのは「エラーが出たか」ではなく、「運用上許容できない逸脱が起きたか」で線を引くこと | |||
止める基準をどう作るか
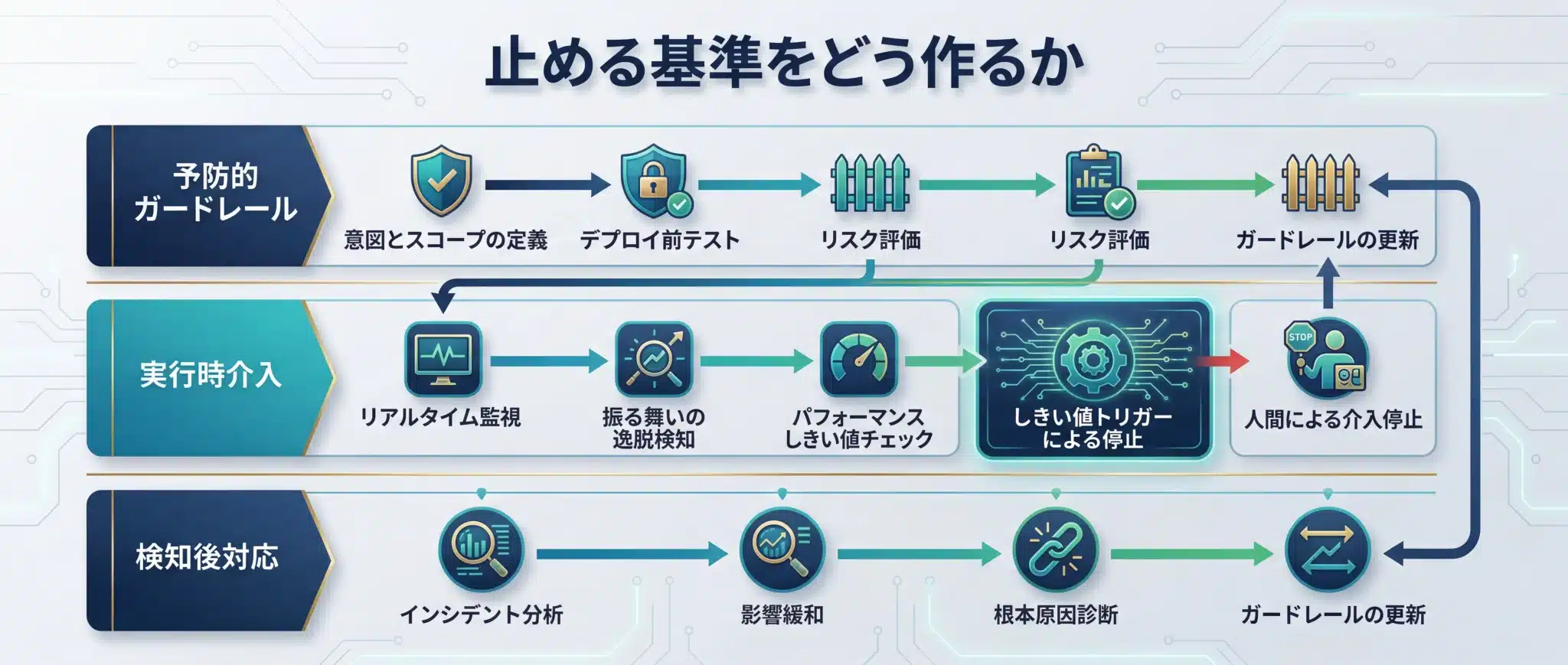 異常検知で最も大事なのは、「止める前に、何を異常として扱うか」を事前に決めることです。
異常検知で最も大事なのは、「止める前に、何を異常として扱うか」を事前に決めることです。
問題が起きてから異常条件を考える運用は、結局いつも後手に回ります。OpenAIは guardrails を input / output / tool behavior の自動検証に使い、human review を sensitive action の approval に使う設計を示しています。ただし本記事で扱う中心は、それらをどう実装するかではなく、どの兆候を検知したら、自動制御や人間判断へ渡すべきかという判定条件です。
なお、異常検知のタイミングという軸で整理すると、運用設計は時間軸で3層に分かれます。
第一に事前条件の検査。禁止された入力や不適切な tool 選択につながる兆候を、実行前に検知する層です。
第二に実行中の逸脱検知。高額決済や外部送信などの不可逆な操作に進む前に、リスク条件へ該当していないかを判定する層です。
第三に事後検知。完了した trace を grading し、逸脱があれば次回のプロンプト改善や eval に戻す層です。
たとえば、形式が崩れた出力や明らかなポリシー違反は guardrail で自動停止に向いています。いっぽう、顧客データ変更、外部送信、支払い確定のような side-effecting action は human review に回したほうが安全です。
ここで問われるのは、どの異常を自動制御へ渡し、どの異常を人間判断へ回すかという線引きです。PMBOKの考え方に引き寄せると、これは閾値管理と例外管理の設計にあたります。何を自動制御へ渡すか。何を要エスカレーションにするか。何を許容して学習材料に回すか。この線引きがないと、異常検知は「何でも拾うが、何も決められない」仕組みになります。
自動制御へ渡す異常と、人間判断へ渡す異常の分け方
自動制御へ渡しやすいのは、ポリシー違反や明確な形式崩れ、禁止された tool call のように、判定条件が明確なものです。人間判断へ渡すべきなのは、業務インパクトや例外事情を見ないと決めにくいものです。たとえば、ある顧客対応で本来の承認フローを一時的に省略してよいかどうかは、異常として検知したうえで、運用責任者の判断に渡す必要があります。
guardrails はどこに効くのか
ここで注意したいのは、OpenAIの agent-level guardrails はチェーン全体に自動で効くわけではないことです。input guardrails は最初の agent にだけ、output guardrails は最終出力を返す agent にだけ適用されます。
途中の function tool call にも一律に適用したい場合は、agent-level guardrails だけに頼らず、副作用を起こす tool の近くに validation を置く設計が必要です。
なぜ基準の事前定義が必要か
「問題が起きたら考える」では、アラートは大量に来るのに誰も決められない、という状態になりがちです。止める基準を先に決めておけば、paused run を使って止め、人に見せ、必要に応じて再開する運用へつなげやすくなります。
アラート設計の原則
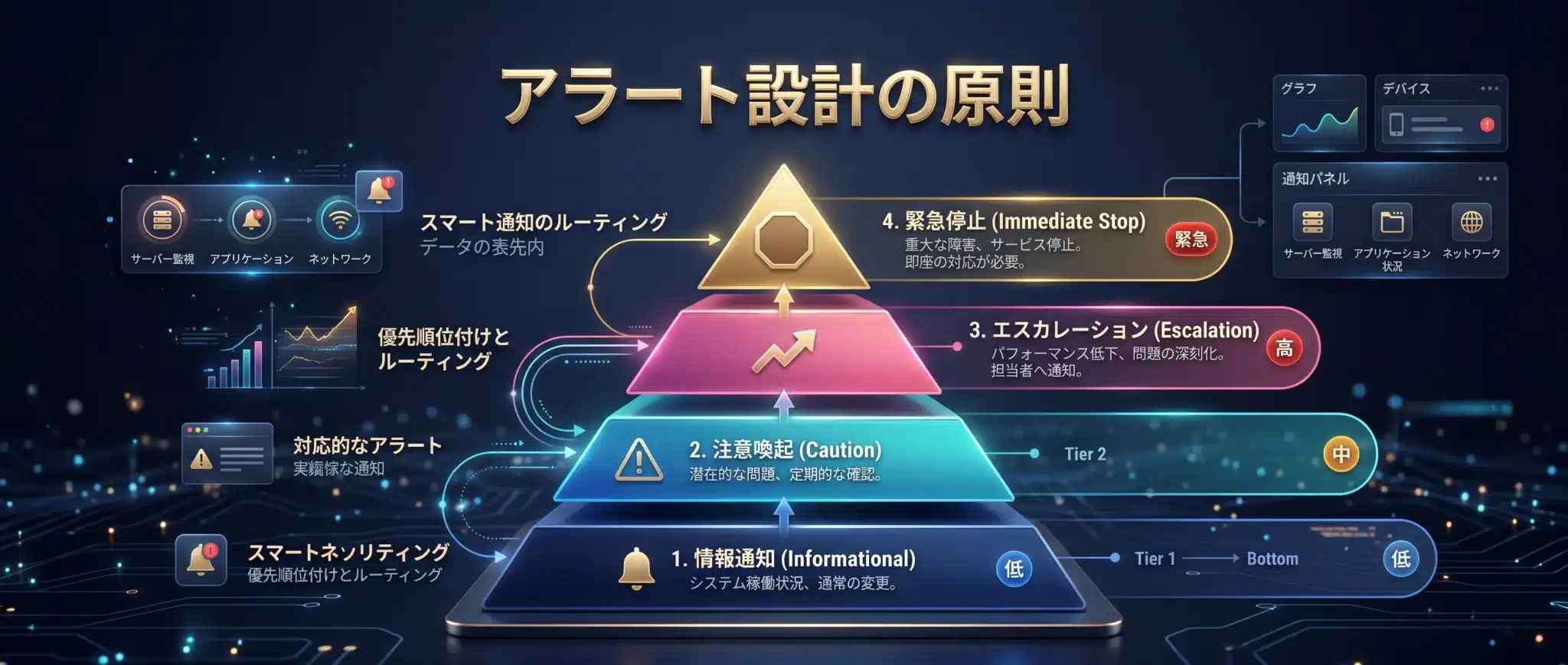 全部を知らせると、何も守れません。
全部を知らせると、何も守れません。
AI運用でも、人間側のアラート疲れはすぐ起きます。だから通知は、少なくとも4段階に分けたほうが実務で機能します。
弊社では、①情報通知、②要注意、③要エスカレーション、④即停止の4段階を推奨します。
情報通知は、軽微な遠回りや trace 上の揺らぎを観測するものです。
要注意は、コスト上振れや遅延悪化のように、すぐ止めるほどではないが悪化傾向を見たいものです。
要エスカレーションは、承認付き操作や高影響な tool call が絡むケースです。
即停止は、誤送信、権限逸脱、危険な書き込みなど、続行コストが高すぎるケースです。
重要なのは、アラート文言よりも受け手の次の行動が定義されていることです。誰が見るのか。何分以内に判断するのか。差し戻すのか、再実行するのか、手動処理に切り替えるのか。ここまで決まって初めて、アラートは監視ではなくコントロールになります。
4段階で分ける理由
全部を即停止にすると、現場は運用できません。逆に全部を情報通知にすると、重大事故を見逃します。だからこそ、影響度と緊急度で段階を分けることが重要です。
重要なのは、異常の重要度に応じて、誰に・どのタイミングで知らせるかを決めておくことです。プロジェクトマネジメントの観点から言えば、これはインシデント管理とエスカレーション基準の整理です。
アラート疲れを防ぐには
アラートが多すぎると、人はすぐ慣れてしまいます。最初は「高リスク操作に関わる異常」だけを通知対象に絞るのが現実的です。コストや遅延の揺れは、即アラートではなく日次レビューで見るほうが運用しやすいケースもあります。
エスカレーション条件をどう設計するか
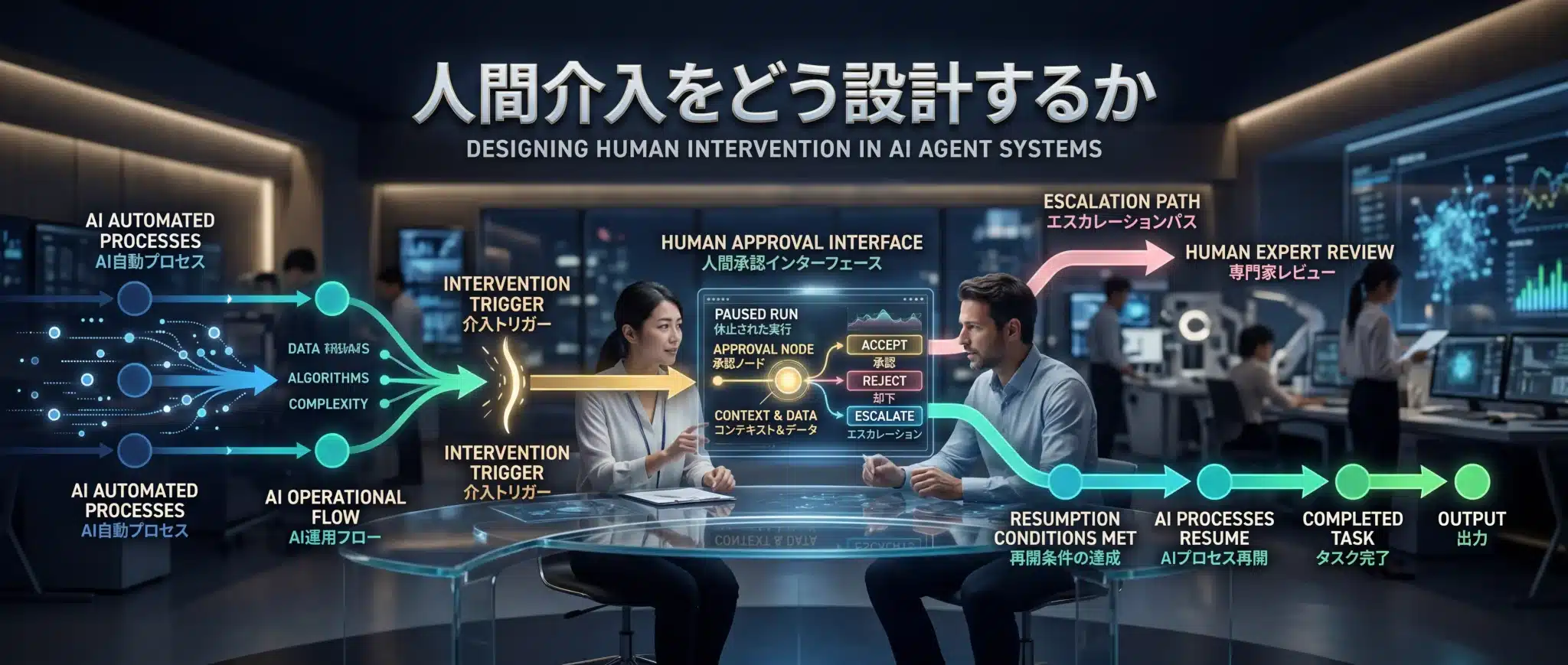 アラートは、誰に渡すべき異常かが決まって初めて意味を持ちます。
アラートは、誰に渡すべき異常かが決まって初めて意味を持ちます。
この論点は、プロジェクトマネジメントの視点から捉えると理解しやすくなります。技術的に検知できても、誰が引き取り、どこで止め、どう再開するかが決まっていなければ、運用は回らないからです。
OpenAIの human review は、run を pause し、承認・却下の判断を人に委ねる仕組みです。
ただし本記事で重視するのは、pause や resume の詳細手順ではありません。Failure Detectionの観点では、どの異常を検知したら、人間判断へ渡すべきかを明確にすることが重要です。停止後の再開条件や運用手順は、Approval Policy / Runbook の領域として切り分けると整理しやすくなります。
実務では、少なくとも3つを決めると運用が安定します。
第一に、一次受けは誰か。PMなのか、運用担当なのか、業務責任者なのか。
第二に、どの条件で上位判断へ上げるか。顧客影響、金額影響、法務・セキュリティ影響があるときです。
第三に、次の判断レーンへどう渡すか。承認判断へ回すのか、人手処理へ切り替えるのか、設定変更後の再試行候補にするのか。ここが決まっていないと、異常検知は「通知する」だけで終わってしまいます。
一次受けは誰にするべきか
技術的な異常だからといって、すべてエンジニアが一次受けするとは限りません。顧客対応や社内承認のように業務判断が中心になるケースでは、業務責任者や運用担当が一次受けしたほうが速いこともあります。大切なのは、役職名ではなく「誰が最初に意思決定できるか」です。
判断レーンへ渡すか、手動処理へ切り替えるか
すべての異常を同じ担当者や同じ手順に流せばよいわけではありません。ケースによっては、そのまま人手処理へ切り替えたほうが安全です。異常検知は「通知する仕組み」ではなく、次に誰が判断すべきかを切り分ける仕組みでもあります。
Observabilityとの違い
 Observabilityは「見続ける基盤」、Failure Detectionは「今すぐ対処すべき異常を抽出する設計」です。
Observabilityは「見続ける基盤」、Failure Detectionは「今すぐ対処すべき異常を抽出する設計」です。
この両者を区別しないと、可視化だけして安心する状態に陥ります。OpenAIの Integrations and observability は、traces を使って runtime で何が起きたかを inspect するための基盤を説明しています。そこには model calls、tool calls、handoffs、guardrails、custom spans が含まれます。つまり Observability は、見えるようにすることが主役です。
いっぽうAIエージェントの異常検知(Failure Detection)は、その可視化された情報の中から、何を異常とみなし、何をいま対処すべきかを決める設計です。Evals が「出す前に測る」、Observability が「出した後に見る」なら、Failure Detection は「見えた異常のうち、何をいま対処すべきか」を決める層です。Realtime Eval Guide の production flywheel が示すように、本番 failure は新しい tests へ戻されるべきですが、その前提として、failure を failure として検知できることが必要です。
Observabilityの整理は、LLMOps完全ガイドやObservability記事本編と合わせて読むと、位置づけがつかみやすくなります。
実務ではどこから始めるか
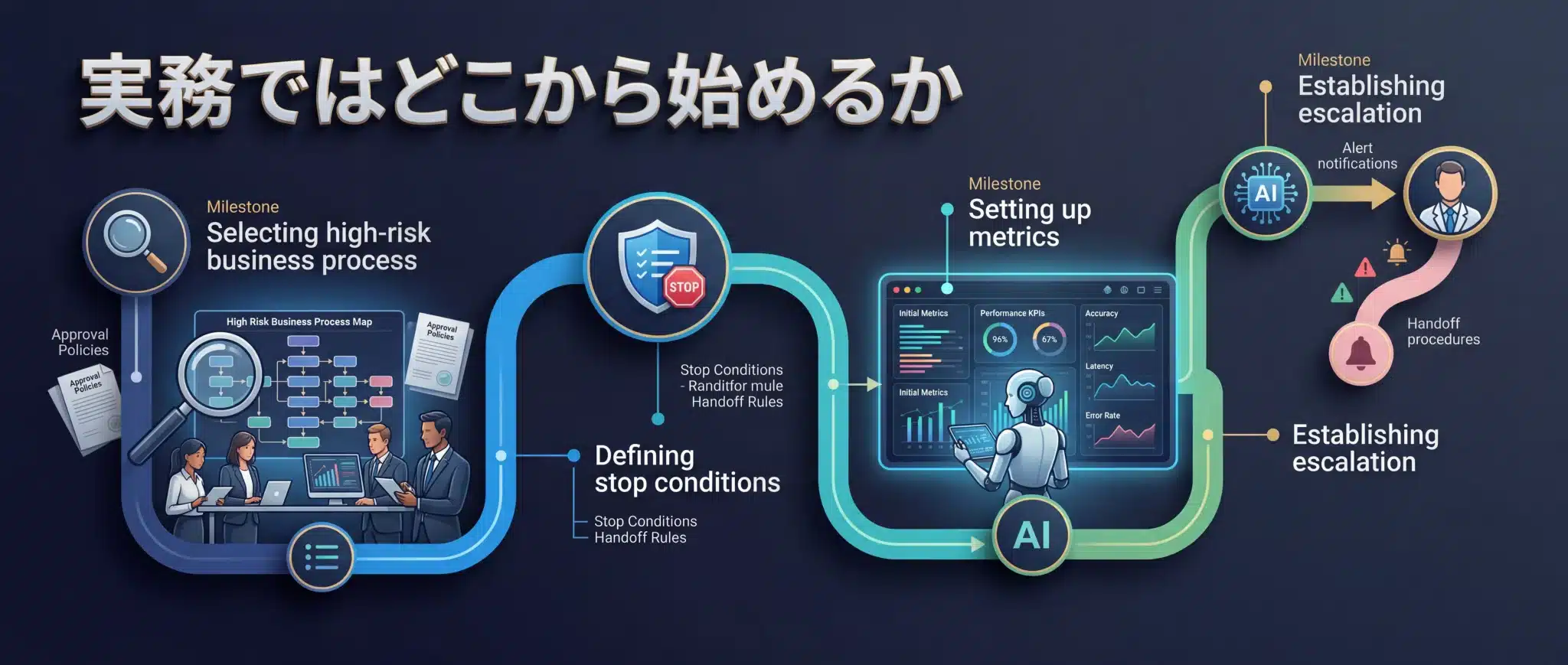 最初から全業務に広げない。高リスク業務を1つ選び、停止条件だけ先に決めることが現実的です。
最初から全業務に広げない。高リスク業務を1つ選び、停止条件だけ先に決めることが現実的です。
おすすめは、顧客データ更新、金額計算、承認付きワークフローのように、止める意味が明確な業務から始めることです。OpenAIの guide 群でも、最初は one focused agent から始め、必要になったら separate ownership、different tool surfaces、different approval policies へ分ける考え方が示されています。
つまり、最初から全部を賢くしようとするより、1つの責務と1つの承認ポリシーから始めたほうが運用設計はうまくいきます。たとえば「顧客属性更新APIへの書き込み回数」「承認ステップをスキップした割合」だけでも、最初の異常検知メトリクスとして十分に機能します。
そのうえで、最初に決めるべきは4つです。何を異常とみなすか。どこで止めるか。誰が引き取るか。どの failure を eval に戻すか。この4つが決まると、異常検知は「ログ監視」から制御可能な運用設計へ変わります。
異常検知設計のセルフチェック
- どの逸脱を異常とみなすか、定義が明文化されているか?
- 自動停止と人間判断の境界が決まっているか?
- 一次受け担当と上位エスカレーション条件が定義されているか?
- 本番で見つかった failure を、次の評価ケースへ戻す流れがあるか?
実装と統制の全体像は2026年、AIエージェント「実装元年」へ、安全設計の前提はAIエージェントセキュリティやAIエージェントのゼロトラスト設計と合わせて読むと、設計の位置づけがつかみやすくなります。
一次情報からどこまで言えるか
事実として言えるのは、異常検知が「ログ収集」ではなく、trace inspection・判定条件・エスカレーション設計を通じた運用統制として位置づけられることです。
このテーマでは、一次情報が重要です。なぜなら、異常検知や人間介入の設計はツール実装と不可分であり、OpenAIやAnthropicがどう定義し、どこで自動停止し、どこで human review に回すかを直接確認しなければ、現場の実態とずれた理解になりやすいからです。
一次情報
OpenAIの guardrails / approvals ガイドでは、guardrails が自動検証、human review が承認判断を担い、run を continue / pause / stop に振り分ける設計が示されています。Integrations and observability では、traces に model calls、tool calls、handoffs、guardrails、custom spans が含まれることが示されています。Trace Grading Guide では、agent の実行履歴に structured scores を与え、workflow-level issue を見つける考え方が説明されています。
Anthropicは、agent evals において transcript の最後の発話ではなく、環境が最終的にどう変化したかという、検証可能な最終状態や途中過程を見る必要性を強調しています。Realtime Eval Guide では、本番で起きた失敗をデータセット化し、次のテストに戻す production flywheel の考え方が示されています。これらを総合すると、異常検知は「何が壊れたか」を記録するだけでなく、検知する・判定する・改善へ戻すための設計だと位置づけられます。
解釈
ここから言えるのは、AIエージェントの異常検知では「エラーが出たら通知する」だけでは不十分だということです。重要なのは、どの逸脱を異常とみなし、誰に・どの優先度で渡すかまで事前に定義することです。Arpableとしては、Failure Detection を「監視の延長」ではなく、異常判定とエスカレーション条件を定義する運用設計として捉えるのが適切だと考えます。
まとめ
読者が持ち帰るべきなのは、異常検知が壊れたことを記録する仕組みではなく、壊れそうな逸脱を異常として判定し、次の対応へつなげる仕組みだという視点です。
結論を再整理すると、AIエージェントは派手に落ちるより、静かに逸脱するほうが危険です。だから異常検知で見るべきなのは、エラー率だけではありません。誤実行、承認フロー逸脱、コスト急増、ループ、挙動変化まで含める必要があります。
要するに、監視の話ではなく、異常判定とエスカレーション条件の設計の話です。プロジェクトマネジメントの観点から言えば、誰が異常を引き取り、どの優先度で判断し、どの制御レイヤーへ渡すかを定義することそのものです。そこが決まって初めて、AIエージェントは「便利そうな機能」から「任せられる仕組み」へ変わります。
参考文献 / 出典
一次情報
- OpenAI – Guardrails and approvals
- OpenAI – Integrations and observability
- OpenAI – Trace Grading Guide
- OpenAI – Results and state
- OpenAI – Define agents
- OpenAI – Safety best practices
- OpenAI – Realtime Eval Guide
- Anthropic – Demystifying evals for AI agents
- TechCrunch – OpenClaw incident report
二次情報
次に読むならこの3本
補足Q&A
Q1. AIエージェントの異常検知とは何ですか?
A1. AIエージェントの異常検知とは、失敗したかどうかを後から採点することではなく、運用中に止めるべき逸脱が起きていないかを見張る仕組みです。エラーだけでなく、誤実行、承認フロー逸脱、コスト急増、ループ、挙動変化まで含めて設計する必要があります。
Q2. ガードレールと人間介入はどう使い分けるのですか?
A2. ガードレールは、形式崩れや明確なポリシー違反のように自動で弾けるものに向いています。人間介入は、顧客データ更新や外部送信のように業務影響が大きく、状況判断が必要な処理に向いています。重要なのは、自動停止と人間判断の境界を事前に決めておくことです。
Q3. Observabilityとの違いは何ですか?
A3. Observabilityは本番で何が起きているかを見続ける基盤で、Failure Detectionはその中から今すぐ対応すべき異常を抽出する設計です。見えるようにするだけでは足りず、何を異常とみなし、どの優先度でアラート化し、誰にエスカレーションするかまで決めて初めて運用が安定します。
Q4. 最初はどのメトリクスから監視すべきですか?
A4. 最初は「高リスクなtool callの回数」「承認ステップをスキップした割合」「同一toolの連続呼び出し回数」の3つだけで十分です。 これだけでも、誤実行・承認フロー逸脱・ループという代表的な異常を検知しやすくなります。
更新履歴
- 2026年4月30日:初版公開








