


※本記事は継続的に最新情報へアップデートしています。
AIエージェントObservabilityとは?予見可能性を高めるトレース・ログ・失敗監査の設計【2026年版】
本番に出したAIエージェントは、そこで初めて本性を見せます。
オフライン評価では優秀に見えたのに、実運用では急に遠回りを始める。不要なツールを呼ぶ。長いやり取りの末に、どこで逸れたのかも分からない。
国内案件からインド、中国、オーストラリアを含むオフショア案件まで、現場でプロジェクトを回し、時に修羅場をくぐってきた立場から、私は一つのことを痛感してきました。それは、プロジェクト成功の鍵が「予見可能性」だということです。どれほど優れたマネジメントでも、予想外の事態が繰り返し発生し、それを早く捉えられなければ、やがて破綻します。
AIエージェント運用におけるObservability(オブザーバビリティ。一般に「可観測性」と訳され、ここでは「何が起きたか」だけでなく「なぜそうなったか」まで追える状態を指します)の本質も同じです。トレースやログは、単なる監視のためだけではなく、予見可能性を取り戻すためにあるのです。
✅ 先に結論
- ポイント1:Observabilityとは、AIエージェントの本番挙動を継続的に見える化し、判断過程や挙動の背景まで追える状態をつくる運用基盤です。
- ポイント2:見るべきは最終回答だけではありません。トレース、ツール呼び出し、遅延、コスト、実行経路、挙動変化まで観測する必要があります。
- ポイント3:PMBOKの言葉でいえば、Observabilityは品質管理・リスク監視・監視とコントロールをAI運用向けに具体化したものです。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

AIエージェント統制シリーズにおける本記事の位置づけ
AIエージェントを本番運用するには、接続・セキュリティ・評価・評価設計・監視・異常検知・停止・再開までを、1つの流れとして設計する必要があります。本記事は、その中で「本番で何を見続けるか」を扱います。
- A2A / MCP = 何をどうつなぐか
- AIエージェントセキュリティ = なぜ危ないか、何を守るか
- ゼロトラスト設計 = どんな原理で守るか
- AIエージェント評価 = 成功率・誤実行・再現性をどう測るか
- AI Evals = 評価基準・評価データ・採点ロジックをどう設計するか
- Observability = 本番で何を見続けるか(本記事)
- Failure Detection = 何を異常と判断するか
- Guardrails / Human Review = どこで止め、どこで人に渡すか
- Approval Policy / Runbook = 止めた後、誰が裁定し、どう再開するか
何が変わったのか
 変わったのは、品質問題が「答え」ではなく「過程」で起きるようになったことです。
変わったのは、品質問題が「答え」ではなく「過程」で起きるようになったことです。
従来のシステム監視では、APIエラー率や応答時間のような指標が主役でした。もちろん今でも重要です。ですが、AIエージェントではそれだけでは足りません。なぜなら、失敗の原因が途中の判断に潜むからです。
たとえば、どのツールを選んだのか。なぜその順番で処理したのか。どこで余計な再試行をしたのか。本来確認が必要な場面で、どの経路を通ったのか。こうした「過程の逸脱」は、最終回答だけ見ても分かりません。OpenAIのTrace Grading Guideを見ると、trace grading は agent の trace、つまり最終回答までの実行履歴に structured scores や labels を与え、workflow-level issue を特定するための仕組みとして整理されています。
トレースとは何か
ここでいうトレースとは、AIがタスクを完了するまでの足跡です。ログが点としての記録だとすれば、トレースはそれらをつないだ一連の流れです。平たく言えば、AIが途中で何を調べ、どのツールを呼び出し、どう判断を積み重ねたかの記録です。Langfuseも hierarchical traces によって、すべての LLM call、tool invocation、retrieval step を追えると説明しています。つまり現在のAI運用では、最終回答だけを見るのではなく、途中経路まで見えることが前提になりつつあります。
なぜ従来の監視では足りないのか
CPU使用率やHTTP 500エラーの監視は、インフラ障害には効きます。しかし、エージェントが「間違ったが一見もっともらしい」動きをした場合、その種の監視だけでは判断過程や実行経路を追いきれません。AIエージェント運用では、出力品質だけでなく、途中の行動品質も観測対象に入れる必要があります。
この変化は、Arpableでこれまで扱ってきたA2Aとは?MCPとの違いや2026年、AIエージェント「実装元年」への続きとして捉えると分かりやすくなります。接続が整い、実装の現実味が増したからこそ、次に問われるのは「そのエージェントを、どこまで信じてよいか」なのです。
なぜ今重要なのか
 重要なのは、予想外が増えたからではありません。予想外を早く検知できなければ、どんな運用も破綻するからです。
重要なのは、予想外が増えたからではありません。予想外を早く検知できなければ、どんな運用も破綻するからです。
この問いは、プロジェクトマネジメントの視点から考えると理解しやすくなります。
プロジェクト成功の鍵は、突き詰めると予見可能性です。予見可能性が高いなら、計画を固定しやすく、ウォーターフォール的な進め方も成立します。予見可能性が下がれば、その時点で見えている情報から最善手を打つアジャイル型が必要になります。さらに不確実性が高く予見が難しければ、段階的に検証しながら進むスパイラル型で回すしかありません。
AIエージェント運用は、多くの場合この後者寄りです。なぜなら、同じ入力でも挙動が揺れる。外部ツールやデータの状態によっても結果が変わる。つまり、最初から全部を読み切る前提が置きにくいからです。OpenAIのAgent EvalsやTrace Grading関連ドキュメントを総合すると、anomalies の兆候把握や挙動変化の追跡、失敗を引き起こした prompt や system change の特定が、運用設計上の中心テーマになっていることが分かります。
プロジェクトマネジメント視点で見るObservability
PMBOKの言葉でいえば、これは新しい理論ではありません。品質管理、リスク監視、監視とコントロールという骨格を、AI運用向けに具体化しただけです。違うのは、対象が「確率的に揺れ、途中で判断し、ツールも使う実行主体」になったことです。だからこそ、監視対象も trace、tool call、state transition のように、より行動寄りになります。
本番でしか見えない失敗がある
Anthropicも、自社の multi-agent research system で full production tracing を導入したことで、bad search queries、poor sources、tool failures といった失敗原因を具体的に切り分けられるようになったと述べています。これは、Observabilityが単なる監視ではなく、本番で初めて現れる失敗を説明可能にする仕組みであることを示しています。
安全設計の前提は、AIエージェントセキュリティやAIエージェントのゼロトラスト設計でも整理しています。本記事は、その次の論点である「見続ける」を扱います。
どう捉えるべきか
 ObservabilityはAI版PMBOKではありません。しかし、PMBOKの原理をAI運用へ再実装するための基盤です。
ObservabilityはAI版PMBOKではありません。しかし、PMBOKの原理をAI運用へ再実装するための基盤です。
AIのために新しいPMBOKをゼロから作る必要はありません。品質管理なら「どの回答・どのtool callを合格とみなすか」、リスク監視なら「誤実行の兆候やコスト急増をどの指標で追うか」、コミュニケーション管理なら「どの指標を誰にどの頻度で共有するか」といった具合に、既存の骨格はAI案件でもそのまま機能します。PMBOKの考え方自体を押さえたい方は、PMBOK第6版と第7版の比較解説も合わせて確認してください。
PMBOKの原理をどう対応づけるか
品質管理に相当するのは、最終回答の自然さだけでなく、途中のツール呼び出しや plan の妥当性まで見ることです。リスク監視に相当するのは、誤実行、停止判断ミス、コスト急増、挙動変化を継続的に追うことです。監視とコントロールに相当するのは、トレースとログを継続的に見て、挙動の変化や問題の兆候を把握し、必要に応じて異常検知・制御・再評価の各プロセスへつなげることです。
Observabilityは監視ではなく管理基盤
Langfuse も observability を、trace、latency、cost、evaluation scores を含む LLM向けの可視化基盤として整理しています。つまり Observability は、新しい流行語ではなく、既存の管理原理をAIの現実に合わせて再実装する仕組みです。ここを見失うと、ダッシュボードが増えただけで運用は改善しません。
何を観測すべきか
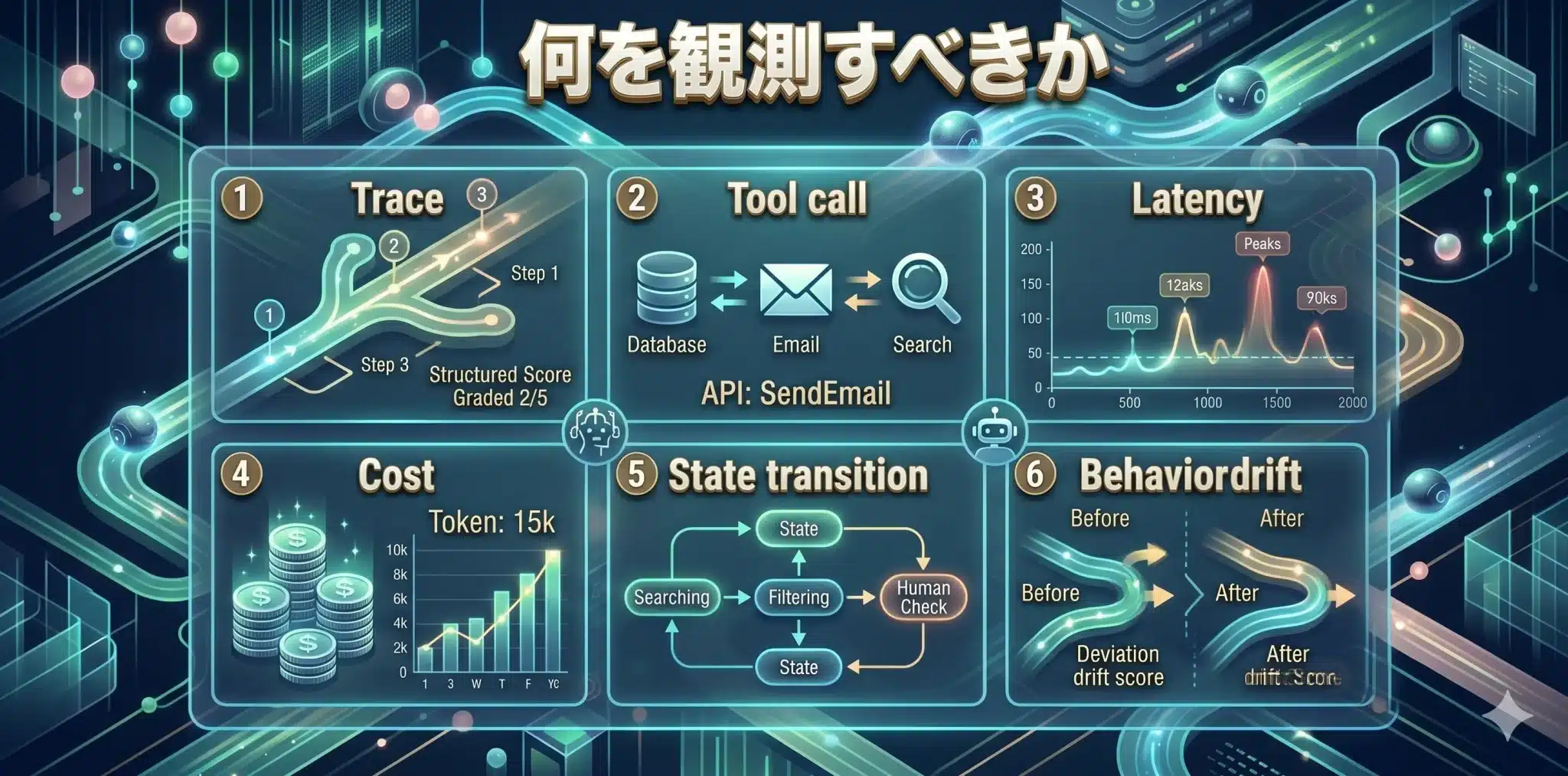 観測対象は、最終回答ではなく、trace・tool call・latency・cost・state transition・behavior drift です。 従来の「監視」がメトリクスやログを前提に「何が起きたか」を捉える仕組みだとすれば、ここでいうObservabilityは「なぜそうなったか」までを追うための設計だと考えてください。
観測対象は、最終回答ではなく、trace・tool call・latency・cost・state transition・behavior drift です。 従来の「監視」がメトリクスやログを前提に「何が起きたか」を捉える仕組みだとすれば、ここでいうObservabilityは「なぜそうなったか」までを追うための設計だと考えてください。
聞き慣れない用語が多いので、ここでは一つずつ整理します。
Trace(トレース)
AIが最終回答に至るまでの実行履歴です。OpenAIのTrace Grading Guideは、trace に structured scores や labels を付けて workflow-level issue を見つける考え方を示しています。つまり「最終回答が正しかったか」だけではなく、「途中でどう動いたか」まで追える状態をつくる発想です。
Tool call(ツール呼び出し)
検索、DB参照、メール送信、チケット更新などの外部操作です。本番事故は、最終回答よりもこの tool call で起きやすいです。OpenAIの関連ドキュメントを総合すると、reasoning traces と並んで tool calls の確認が、実行経路の把握や問題切り分けの重要要素になっていることが分かります。
Latency(遅延)と Cost(コスト)
Latency は応答にかかった時間、Cost は推論や再試行、ツール利用にかかる費用です。Langfuse は observability の主要項目として latency と cost を明示し、token / cost tracking の機能も提供しています。精度が高くても、遅すぎる・コストが高すぎるシステムは、現場には受け入れられません。
State transition(状態遷移)
エージェントが途中でどの状態からどの状態へ進んだかです。たとえば「検索中→候補絞り込み→人間確認待ち→更新実行」のような流れです。Anthropicは、agent evals では transcript の最後の発話よりも、環境の最終状態を見るべきだと説明しています。つまり、何を言ったかより、何を変えたかが重要です。
Behavior drift(挙動変化)
似た条件なのに、以前と違う振る舞いをし始めることです。OpenAIのTrace Grading Guideは、agent の実行履歴に structured scores を与えることで、どの workflow-level issue が生じているかを特定できると説明しています。これは、prompt 変更やシステム改修後に、どこで挙動が変わったのかを追うための基盤として機能します。
| 観測項目 | 何を見るか | 具体例 | 実務上の注意点 |
|---|---|---|---|
| Trace | 途中の判断と実行履歴 | どの順序でツールを呼び、どこで再試行したか | 最終回答だけでは失敗原因を特定できない |
| Tool call | 外部操作の内容と回数 | 検索、DB更新、メール送信、チケット変更 | 一見自然な回答でも副作用が重大な場合がある |
| Latency | 応答にかかった時間 | 長時間処理、再試行による遅延 | 精度が高くても遅すぎると業務で使われない |
| Cost | 推論・再試行・ツール利用の費用 | API利用料、不要な再実行、過剰なtool call | 改善しているつもりで静かにコストが膨らむことがある |
| State transition | 状態の移り変わり | 確認待ちを飛ばして更新実行へ進む | 環境の最終状態を見ないと事故を見逃す |
| Behavior drift | 以前との挙動差 | 同条件で遠回りが増える、失敗パターンが変わる | モデル更新やプロンプト変更後は特に注意が必要 |
| ※ 重要なのは「何が出たか」だけでなく、「どう進み、どこで逸れたか」を見続けること | |||
加えて、2026年の実務では、Observability のアウトプットを Evals に戻すフィードバックループが重要です。本番で再現性の高い failure や挙動変化が見つかったら、それを eval dataset に追加し、次の評価ケースへ戻す。この流れがないと、ダッシュボードだけが増えて改善が進まない、という状態に陥りやすくなります。
Evalsとの違い
 Evalsは「出す前に測る仕組み」、Observabilityは「出した後に見続ける仕組み」です。
Evalsは「出す前に測る仕組み」、Observabilityは「出した後に見続ける仕組み」です。
OpenAIのEvals Guideでは、Evaluations をモデル出力が期待に沿っているかをテストし、理解し、改善するための仕組みとして整理しています。Agent Evals では、それを traces、graders、datasets、eval runs で回します。つまり Evals は、事前の品質保証に近い役割です。
Observability は違います。これは、本番に出たあとに実際に何が起きているかを継続的に見る仕組みです。どんな失敗が増えているか。どの tool call で時間が伸びているか。どの変更以降、挙動が変わったか。これを見続けるのが Observability です。
なぜ両方必要なのか
ただし、分けるだけでは足りません。Realtime Eval Guide では、本番で起きた失敗をデータセット化し、次のテストに組み込んでいく「production flywheel」の回し方が示されています。すなわち、real failures become new tests という発想です。本番で見つかった失敗を次の eval dataset に戻して初めて、改善ループが閉じます。
実装と統制の全体像は2026年、AIエージェント「実装元年」へ、安全設計はAIエージェントセキュリティやAIエージェントのゼロトラスト設計と合わせて読むと、位置づけがつかみやすくなります。
実務ではどう設計するか
まずは完璧な監視を目指さない。1ユースケースで trace を残し、tool call と実行ログを見える化するところから始めるべきです。
ここで大事なのは、「見えること」と「管理できること」は違うという点です。ダッシュボードがある。ログが取れている。トレースが見られる。それだけでは、まだ不十分です。本当に必要なのは、その情報を見て、誰が、何を、いつ確認し、次の判断プロセスへ渡すかが決まっていることです。
最初に決めるべき4つ
最初に決めるべきなのは4つだけです。どの実行経路を記録するか。どの tool call を重点的に見るか。どの挙動変化を継続的に追うか。どの failure を再評価対象へ戻すか。この4つが定まっていなければ、Observability は「見えるだけ」で終わります。
具体的な決め方の例
たとえば、どの tool call を記録するか。顧客データ更新の前後でどの state transition を残すか。頻度が高い failure を eval dataset に戻せる形で保存するか。コストや遅延をどの粒度で可視化するか。ここまで決めて初めて、Observability はPMBOKでいう監視とコントロールとして意味を持ってきます。
最初から全部やらない
実装上も、最初から全部をやる必要はありません。Langfuse は、まず trace を取り込み、そこから sessions、metrics、cost、evaluation へ広げる導線を用意しています。つまり、最初に必要なのは完璧さではなく、観測できる最低限の土台です。
Observability設計のセルフチェック
- 最終回答だけでなく、trace と tool call を見られる状態になっているか?
- latency、cost、state transition、behavior drift を継続的に追える状態になっているか?
- 高リスクな tool call や外部操作を、後から確認できる粒度で記録しているか?
- 本番で見つかった failure や挙動変化を、次の評価ケースへ戻す流れがあるか?
実装前提の理解は、2026年、AIエージェント「実装元年」へ、安全設計の前提はAIエージェントセキュリティ、運用全体の見取り図は「デモで動く」から「本番で稼ぐ」へ。LLMOps完全ガイドと合わせて読むと、全体像がつかみやすくなります。
一次情報からどこまで言えるか
事実として言えるのは、Observabilityが単なるログ収集ではなく、トレース・メトリクス・実行履歴を通じて本番挙動を説明可能にする基盤として位置づけられていることです。
このテーマでは、一次情報が重要です。なぜなら、Observability の設計思想はツールやフレームワークの実装と不可分であり、OpenAIやAnthropicがどう定義し、どう使っているかを直接確認しなければ、現場の実態とずれた理解になりやすいからです。
一次情報
OpenAIのTrace Grading Guideを見ると、agent の実行履歴に structured scores や labels を与えることで、mistakes や workflow-level issue を特定できると説明しています。これは、最終回答だけでなく途中の振る舞いまで評価対象に含める考え方です。
また、OpenAIのAgent Evalsや関連ドキュメントを総合すると、traces、graders、datasets、eval runs を使って、エージェント品質を継続的に測定・改善する考え方が中核にあることが分かります。Realtime Eval Guide では、本番で起きた失敗をデータセット化し、次のテストに組み込んでいく「production flywheel」の回し方も示されています。
さらに One Year of the Responses API では、Responses API を用いたエージェント実装事例の中で、挙動監視や運用上の問題把握に関する実例が紹介されています。Anthropicは production tracing によって、bad search queries、poor sources、tool failures といった失敗要因を切り分けやすくなったと述べています。Langfuse も observability を、traces、latency、cost、evaluation を継続的に見る仕組みとして整理しています。
解釈
ここから言えるのは、AIエージェント運用では「とりあえずログを取る」だけでは不十分だということです。重要なのは、予見しにくい挙動を、あとからでも説明可能にし、次の改善へ戻せることです。Arpableとしては、Observability を「監視」ではなく、予見可能性を高める管理基盤として捉えることが適切だと考えます。
まとめ
読者が持ち帰るべきなのは、ObservabilityがAIを監視する仕組みではなく、予見可能性を取り戻す管理基盤だという視点です。
結論を再整理すると、AIエージェント運用では、予想外そのものをゼロにはできません。けれど、予想外を早く検知する。原因を切り分ける。再発防止の策へつなげる。この流れを作ることはできます。PMBOKの言葉でいえば、これは品質管理、リスク監視、監視とコントロールを、AI運用へ再実装することです。Evals が「出す前に測る仕組み」なら、Observability は「出した後に見続ける仕組み」です。この両輪があって初めて、AIエージェントは面白い機能から、任せられる仕組みへ変わります。
参考文献 / 出典
一次情報
- OpenAI – Trace Grading Guide
- OpenAI – Evals Guide
- OpenAI – Agent Evals Guide
- OpenAI – Realtime Eval Guide(production flywheelの設計参照)
- OpenAI – One Year of the Responses API(Responses APIを用いたエージェント実装事例集、異常検知・挙動監視の実例を含む)
- Anthropic – Demystifying evals for AI agents
- Langfuse – Observability Overview
- Langfuse – Token and Cost Tracking
二次情報
次に読むならこの3本
補足Q&A
Q1.
Observabilityとは何ですか?
A1.
Observabilityとは、AIエージェントの本番挙動を継続的に見える化し、判断過程や実行経路まで追える状態をつくる仕組みです。単なるログ収集ではなく、トレース、tool call、遅延、コスト、挙動変化まで見て、運用上の確認や改善につなげることが目的です。
Q2.
トレースとログは何が違うのですか?
A2.
ログが個々の出来事の記録だとすれば、トレースはそれらをつないだ一連の実行の流れです。AIエージェントでは、どこで判断し、どのツールを呼び、どこで逸脱したかを見るために、単発ログだけでなくトレースが重要になります。
Q3.
EvalsとObservabilityはどう違うのですか?
A3.
Evalsは「出す前に測る仕組み」、Observabilityは「出した後に見続ける仕組み」です。Evalsで基準を作り、Observabilityで本番の挙動変化や実行経路を確認し、再現性のある failure をまたEvalsに戻す。この循環ができて初めて、AIエージェント運用は安定します。
更新履歴
- 2026年4月29日:初版公開








