


※本記事は、2025年9月公開記事をもとに、AI駆動開発ツールの実践ガイドとして大幅改版したものです。
AI駆動開発の本質は、AIにコードを書かせることではありません。エンジニアが目的、制約、品質基準、責任分界を設計し、AIを実装パートナーとして使いこなすことです。
ただし、現場は明日からいきなり「構想力だけ」で回るわけではありません。2026年時点では、GitHub Copilot、Cursor、Claude Code、Codex、Jules、Devin、Lovable、Bolt.new などのAI駆動開発ツールを使い分けながら、どこまでAIに任せ、どこで人間が確認するかを設計する段階にあります。
本記事では、AI駆動開発時代へ移行する現場が、主要ツールをどう使い、どの品質ゲートで守り、どこから実践を始めるべきかを整理します。
✅ 先に結論
- AI駆動開発ツールは、単なるコード補完から実行支援へ進化しています。Copilot、Claude Code、Codex、Jules、Devinなどは、既存コードの理解、修正、テスト、Pull Request作成まで支援する方向へ進んでいます。
- 重要なのは、どのツールを使うかだけではありません。AIに任せる範囲、人間のレビュー、テスト、セキュリティ、責任分界を設計できるかが、実務導入の成否を分けます。
- SWE-benchの高スコア化は、AIの実コード修正能力が急速に高まっていることを示しています。ただし、本番開発ではベンチマーク性能とは別に、品質ゲートと人間レビューが不可欠です。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
AI駆動開発・Vibe Codingシリーズにおける本記事の位置づけ
AI時代の開発は、コード補完から、AIコーディングエージェント、チーム型AI開発、そして構想力中心の開発へ広がっています。本記事は、AI駆動開発を現場で始めるための実践スポーク記事です。
- AI駆動開発とは?生成AI時代のソフトウェア開発完全ガイド = 生成AI時代の開発全体像
- バイブコーディングの先へ|AI駆動開発で問われるエンジニアの構想力 = 構想力への転換を扱う中ハブ
- AI駆動開発ツール実践ガイド = 主要ツール・テンプレート・品質ゲートを扱う実践編(本記事)
- AI開発支援ツール徹底比較ランキング = どのツールを選ぶべきか
AI駆動開発ツールを使う前に決めること
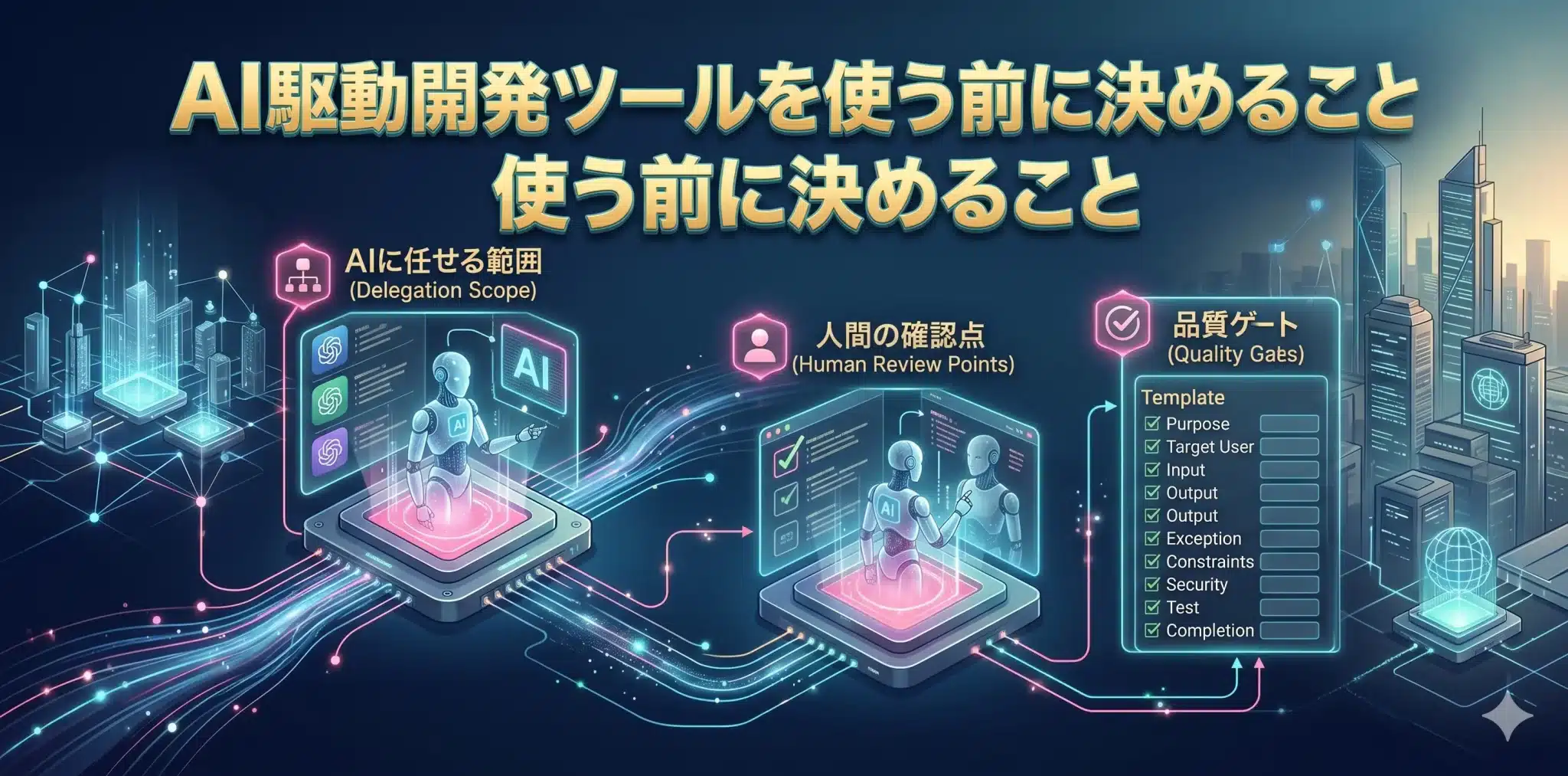
AI駆動開発ツールを導入する前に決めるべきことは、どのツールを使うかではなく、AIに任せる範囲、人間の確認ポイント、品質ゲートの置き方です。
AI駆動開発ツールは、コードを書く速度を上げるだけの道具ではありません。仕様を読み、既存コードを理解し、修正案を作り、テストを追加し、Pull Requestまで準備する方向へ進化しています。
しかし、AIが実装を進められるようになったからといって、すべてを任せてよいわけではありません。むしろ重要になるのは、AIに任せる対象を見極め、人間がどこで確認し、どの条件を満たしたら次へ進めるかを決めることです。
AI駆動開発の第一歩は、ツール選定ではなく「任せ方の設計」です。どのタスクをAIに任せるのか、どこから人間がレビューするのか、何をもって完了とするのか。この3点が曖昧なまま導入すると、短期的には速く見えても、後から品質問題や手戻りが増えます。
| 項目 | 決める内容 | なぜ重要か |
|---|---|---|
| 任せる範囲 | 補完、修正、テスト追加、PR作成など、AIに任せる作業範囲 | 任せすぎによる品質低下や責任不明確化を防ぐため |
| 人間の確認点 | レビュー、テスト、セキュリティ確認、リリース判断 | AI生成コードの副作用や仕様誤解を防ぐため |
| 品質ゲート | 次の工程へ進める条件、止める条件、差し戻す条件 | 「動くが危ないコード」を本番に入れないため |
| 責任分界 | AIの提案を誰が採用し、誰が最終責任を持つか | 障害・不具合・セキュリティ事故時の判断を明確にするため |
主要ツールの3分類:補助型・ワークフロー支援型・自律実行型
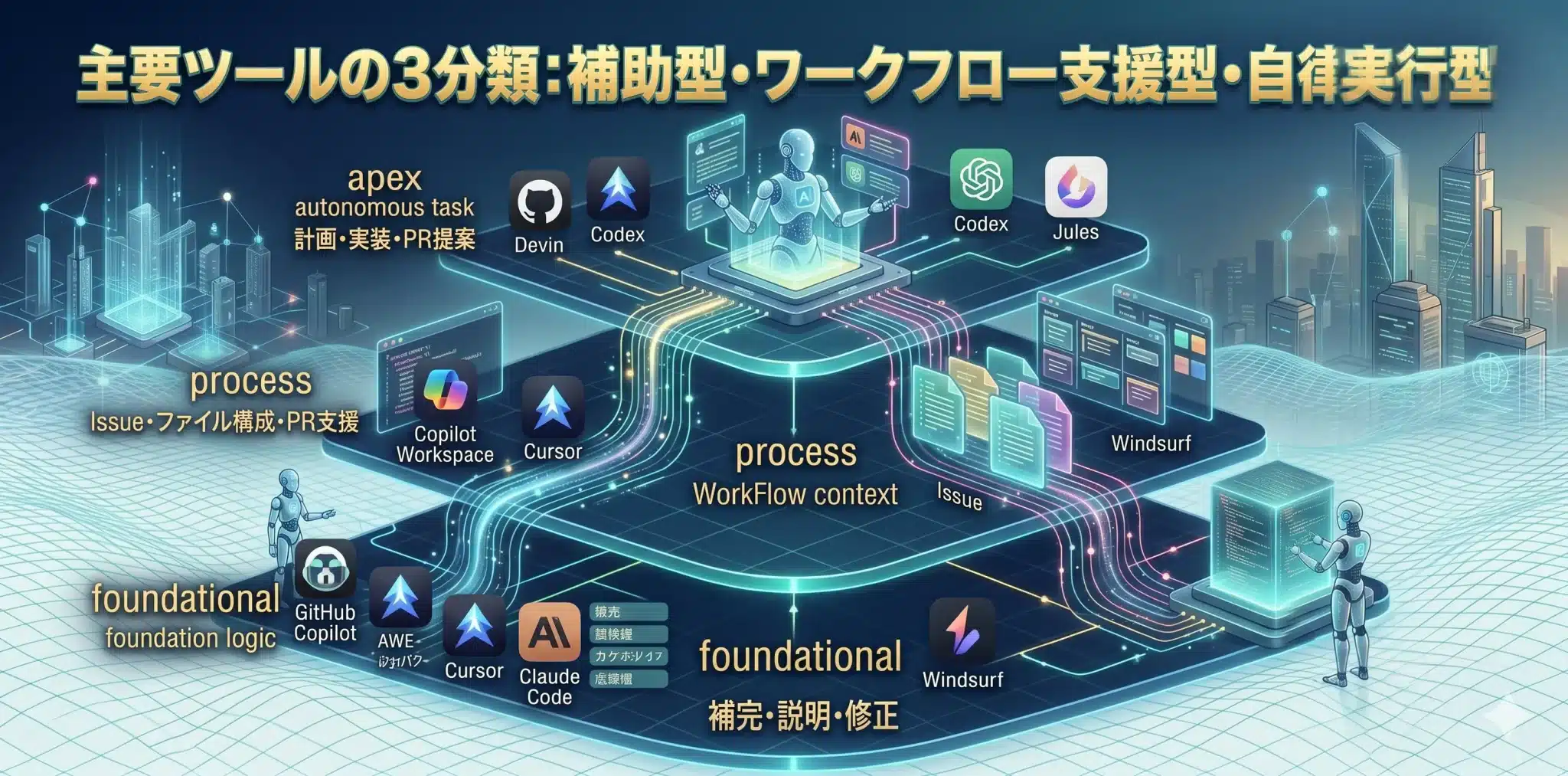
AI開発ツールは、補助型、ワークフロー支援型、自律実行型の3つに分けると、自社でどこから導入すべきか判断しやすくなります。
AI開発ツールを比較するとき、単に「どのツールが賢いか」だけを見ると判断を誤ります。重要なのは、自社の開発現場で、AIをどの位置に置くかです。

1. 補助型AI開発ツール
補助型は、人間が主導し、AIがコード補完、説明、修正案、テスト作成を支援するタイプです。GitHub Copilot、Cursor、Claude Codeの一部利用などが該当します。
このタイプは、既存開発フローに入れやすく、導入リスクも比較的低いです。一方で、要件定義、設計、レビュー、リリース判断は人間が主導します。
2. ワークフロー支援型AI開発ツール
ワークフロー支援型は、Issue、設計メモ、ファイル構成、実装計画、Pull Request など、開発フロー全体を支援するタイプです。Copilot Workspace、Cursor、Windsurf などがこの方向に進んでいます。
人間は細かなコードだけでなく、作業単位、レビュー観点、完了条件を設計する役割へ移ります。個人の作業支援から、チーム開発の進め方そのものへ影響する点が特徴です。
3. 自律実行型AI開発エージェント
自律実行型は、AIが計画、実装、テスト、実行、修正、PR作成までをまとめて進めるタイプです。Devin、Codex、Jules などは、この方向を代表するツールです。
ただし、自律実行型であっても、最終判断までAIに任せるわけではありません。人間は、依頼内容、受け入れ条件、テスト、レビュー、セキュリティ、リリース判断を担う必要があります。
| 分類 | 主な役割 | 代表例 | 人間の役割 |
|---|---|---|---|
| 補助型 | コード補完、説明、修正案、テスト作成 | GitHub Copilot、Cursor、Claude Code | 実装主導、レビュー、判断 |
| ワークフロー支援型 | Issue、設計、ファイル構成、PR支援 | Copilot Workspace、Cursor、Windsurf | 作業単位と完了条件の設計 |
| 自律実行型 | 計画、実装、テスト、PR作成 | Devin、Codex、Jules | 依頼設計、品質ゲート、最終判断 |
GitHub Copilot / Copilot Workspace:個人開発からチーム開発へ
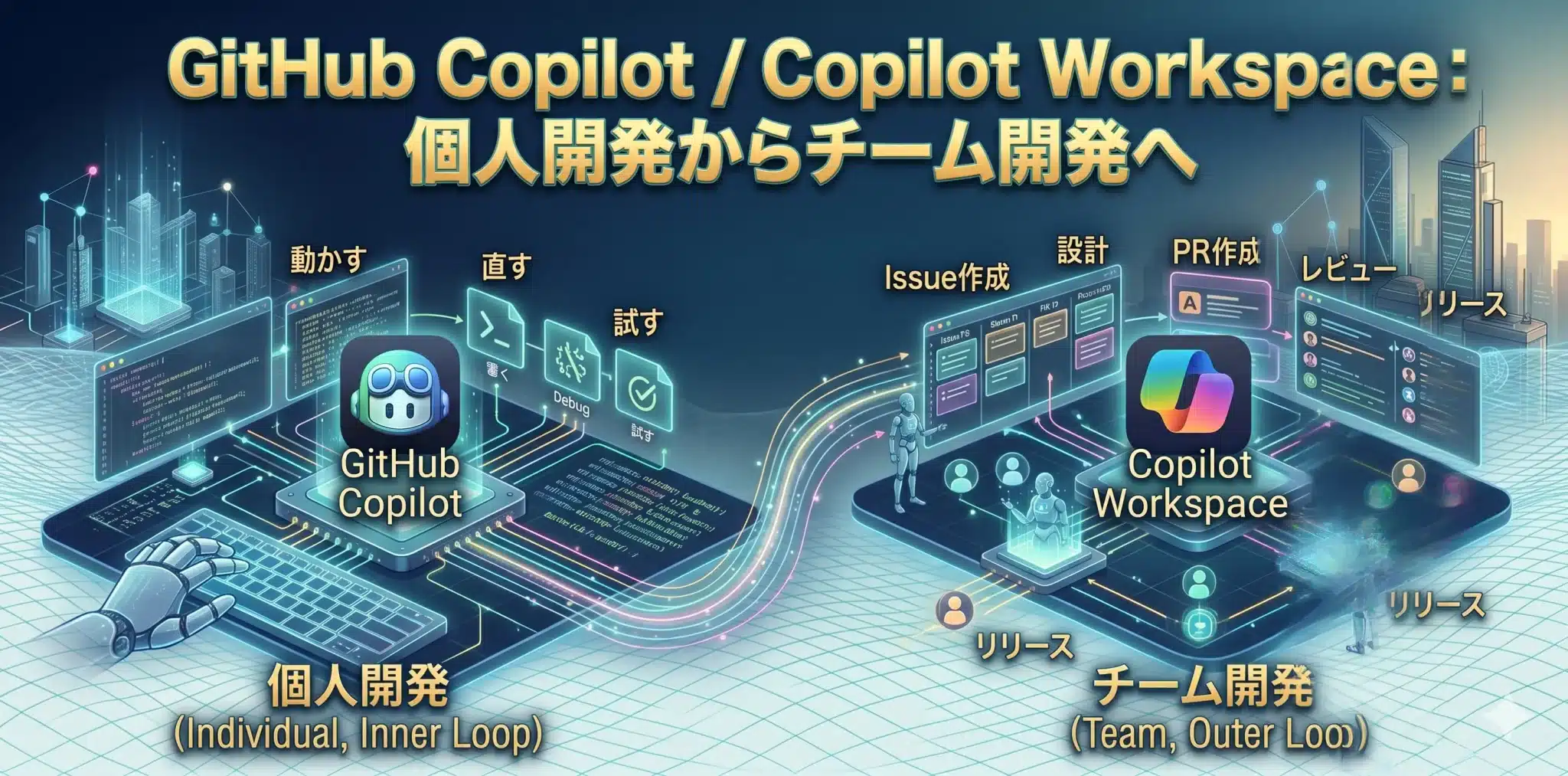
GitHub Copilotは、単なるコード補完ツールから、個人作業とチーム開発の両方を支援する開発基盤へ広がっています。
GitHub Copilotは、AI開発支援ツールの代表格です。従来は、エディタ内でコード補完や説明を行う「AIペアプログラマー」として使われることが多くありました。しかし現在は、Agent mode、コードレビュー支援、クラウドエージェントなど、開発フロー全体へ関与する機能が広がっています。
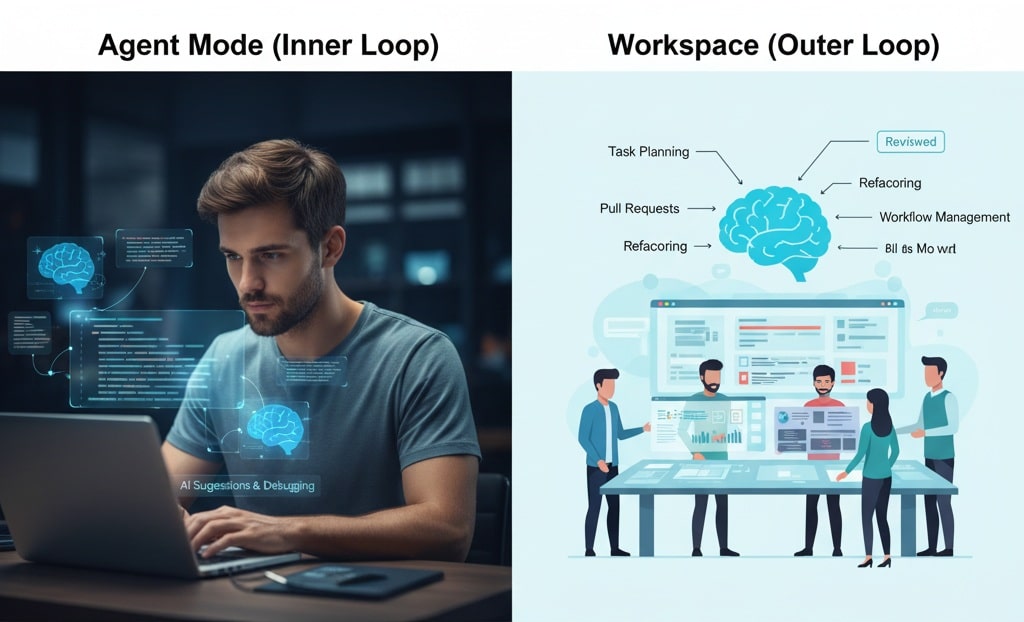
インナーループ:手元の開発作業を支援する
インナーループとは、開発者が日々繰り返す「書く、動かす、直す、試す」という作業サイクルです。Copilotの補完、チャット、Agent mode は、この手元作業を高速化します。
たとえば、既存コードの意図を説明させる、関数を修正させる、テストケースを追加させる、エラー原因を調べさせる、といった使い方です。ここでは人間が主導し、AIは実装の加速役として機能します。
アウターループ:チーム開発の流れを支援する
アウターループとは、Issue作成、設計、レビュー、Pull Request、リリースといったチーム開発の流れです。Copilot Workspaceやクラウドエージェントの方向性は、AIがこの流れにも関与することを示しています。
ここで重要なのは、AIがチームの代わりに意思決定するわけではないということです。AIが計画や差分を作っても、優先順位、仕様判断、レビュー、リリース判断は人間が担います。
Cursor / Windsurf:AIネイティブIDEの実務活用
CursorやWindsurfのようなAIネイティブIDEは、コードを書く場所ではなく、AIと仕様・修正・レビューを往復する作業環境として見るべきです。
AI駆動開発では、エディタの役割も変わります。従来のIDEは、人間がコードを書くための環境でした。AIネイティブIDEでは、既存コードを読み、変更案を作り、複数ファイルを横断して修正し、差分を確認する作業が中心になります。
Cursor:既存開発環境に近い形でAIを組み込む
Cursorは、VS Codeに近い操作感を持ちながら、コードベース理解、チャット、補完、エージェント的な修正を統合したAIネイティブIDEです。既存のVS Code文化に慣れたチームにとっては、比較的移行しやすい選択肢です。
実務では、コード説明、リファクタリング、テスト追加、軽微な機能追加、複数ファイルの修正案作成などに向きます。ただし、大規模変更では、AIが意図を誤解したまま広範囲に差分を作る可能性があるため、必ずPR単位でレビューする必要があります。
Windsurf:エージェントIDEとしての流れ
Windsurfは、エージェント型IDEの流れを象徴するツールです。Windsurfは2025年7月、複雑な経緯を経てCognition傘下に入りました。OpenAIによる買収交渉が崩れた後、GoogleがWindsurfの主要人材と技術ライセンスを確保し、残るIP、製品ライン、ブランド、事業運営、チームをCognitionが取得する形になりました。
現在のWindsurfは、IDE上からDevinへタスクを委任し、CascadeとDevinの作業セッションを統合的に扱う方向へ進んでいます。この一連の動きは、AI開発ツール市場が「単体エディタの競争」から、「エージェントとIDEを組み合わせた開発環境の競争」へ本格的にシフトしていることを示しています。
| 観点 | Cursor | Windsurf |
|---|---|---|
| 向いている使い方 | 既存コードの理解、補完、修正、リファクタリング | エージェント前提の開発フロー、AI中心の作業環境 |
| 導入しやすさ | VS Codeに近い体験で導入しやすい | エージェント型開発に寄せた運用設計が必要 |
| 注意点 | 複数ファイル修正時の差分レビューが必須 | IDEとエージェントの統合が進むほど、権限・ログ・レビュー設計が重要になる |
Claude Code / Codex / Jules:エージェント型開発の現在地
Claude Code、Codex、Julesは、AIが既存コードを読み、修正し、テストし、Pull Requestに近い形で成果物を出す方向へ進んでいます。
AI駆動開発の大きな変化は、AIが単に「コードを提案する」段階から、実際の開発タスクを進める段階へ移っていることです。Claude Code、OpenAI Codex、Google Jules は、この変化を示す代表的なツールです。
Claude Code:コードベースを読み、作業を進めるagentic coding tool
Claude Codeは、コードベースを読み、ファイルを編集し、コマンドを実行し、開発ツールと連携するagentic coding toolとして位置づけられています。ターミナル、IDE、デスクトップアプリ、ブラウザで利用できる点も特徴です。
実務では、既存コードの理解、複数ファイルの修正、テスト追加、Gitワークフロー支援などに向きます。ただし、AIが行った変更の意図、差分、テスト結果を人間が確認することが前提です。
Codex:クラウドで複数タスクを並列に進める
OpenAI Codexは、機能追加、コードベースに関する質問、バグ修正、Pull Request提案などを行うコーディングエージェントです。重要なのは、AIが単にコードを補完するだけでなく、開発タスクを一つの作業単位として進める方向へ進化している点です。
重要なのは、AIが「作業を完了させる」方向へ進んでいる点です。単なるコード補完を超え、開発タスクを一つの作業単位として自律的に進める段階へと進化しています。
Jules:GitHub連携の非同期coding agent
Google Julesは、2025年8月にpublic betaを終了した非同期coding agentです。GitHubリポジトリと連携し、バグ修正、テスト修正、依存関係更新、機能追加などを別環境で進め、結果をレビュー可能な形で提示します。
Google AI Pro / Ultraでは、より高いタスク上限や同時実行数が提供されており、Julesは個人の試用段階から、より本格的なエージェント型開発ワークフローへ広がっています。このような非同期エージェントは、開発者がすべての作業を手元で進める前提を変えます。人間は、AIが進める作業を設計し、結果を確認し、採用するかどうかを判断する役割になります。
| ツール | 主な特徴 | 実務での使いどころ | 注意点 |
|---|---|---|---|
| Claude Code | コードベース理解、ファイル編集、コマンド実行 | 既存コードの理解、修正、テスト追加 | 差分・実行結果・権限の確認が必要 |
| Codex | クラウドで複数タスクを並列実行 | 機能追加、バグ修正、PR提案 | 完了条件とレビュー観点を明確にする必要 |
| Jules | GitHub連携、非同期タスク実行 | 依存関係更新、テスト修正、軽微な機能追加 | 非同期結果の確認と採否判断が必要 |
SWE-benchが示す「実コード修正能力」の進化
SWE-benchの高スコア化は、AIが既存リポジトリの文脈を読み、未解決Issueに近い実コード課題へ修正差分を作れる段階に近づいていることを示しています。
SWE-benchは、実際のGitHubリポジトリに由来するソフトウェア修正タスクを使い、AIが既存コードの文脈を読み、Issueに対して修正差分を作れるかを測るベンチマークです。単なるアルゴリズム問題ではなく、現実の開発に近い「バグ修正」「仕様理解」「テスト適合」を含む点に意味があります。
近年、SWE-bench VerifiedではClaude Opus系、Gemini系、Codex系などが高いスコアを示しており、AIが既存リポジトリの文脈を読み、実コード修正に近いタスクへ対応する能力は大きく高まっています。AnthropicのProject Glasswingでは、限定提供モデルであるClaude Mythos PreviewがSWE-bench Verifiedで93.9%、SWE-bench Proで77.8%を記録したことも公表されています。
ただし、Verifiedの高スコアだけで実務能力を判断するのは危険です。OpenAIは、SWE-bench Verifiedについて、評価データの汚染やゴールドパッチの記憶再現の可能性を指摘し、フロンティアモデルの評価にはSWE-bench Proのような、より厳密な評価を使うべきだとしています。Scale LabsのSWE-Bench Proは、1,865件のタスクを41の実務寄りリポジトリから構成した、より大規模で厳しいベンチマークです。
| 観点 | 意味 | 実務での注意点 |
|---|---|---|
| 実コード課題 | 既存リポジトリのIssueに近い課題を対象にする | 競技プログラミングの点数とは性質が違う |
| 高スコア化 | AIが既存コードを読み、修正差分を作る能力を高めている | 実務ではレビューとテストが別途必要 |
| 評価限界 | Verifiedには汚染やテスト条件の限界があり、Proのような厳密な評価が必要になる | 数字だけで導入判断しない |
| 本記事での位置づけ | AI駆動開発が実務に近づいているシグナル | 品質ゲート設計の必要性を補強する材料 |
Devin:自律型AIエンジニアの可能性と限界
Devinは自律実行型AIエージェントの代表例ですが、実務では「任せきり」ではなく、タスク設計、レビュー、品質ゲートと組み合わせて使う必要があります。
CognitionのDevinは、自律型AIソフトウェアエンジニアとして注目を集めたツールです。人間がタスクを依頼すると、AIが作業計画を立て、コードを書き、実行し、エラーを修正し、成果物を提示するという方向を示しました。

Devinの価値は、単にコードを書くことではありません。タスクを分解し、実装し、実行し、失敗を修正し、結果を提示するという一連の流れをAIが担おうとしている点にあります。さらにCognitionは、Devinが大きなタスクを分解し、複数のmanaged Devinsへ並列委任できる機能も発表しています。
一方で、自律型エージェントはブラックボックス化しやすい側面があります。AIがどの前提で判断したのか、どのファイルを変更したのか、テストは十分か、既存仕様に副作用はないか。これらを人間が確認できなければ、実務では安心して使えません。
実践テンプレート:AIに依頼する前に書くべき仕様
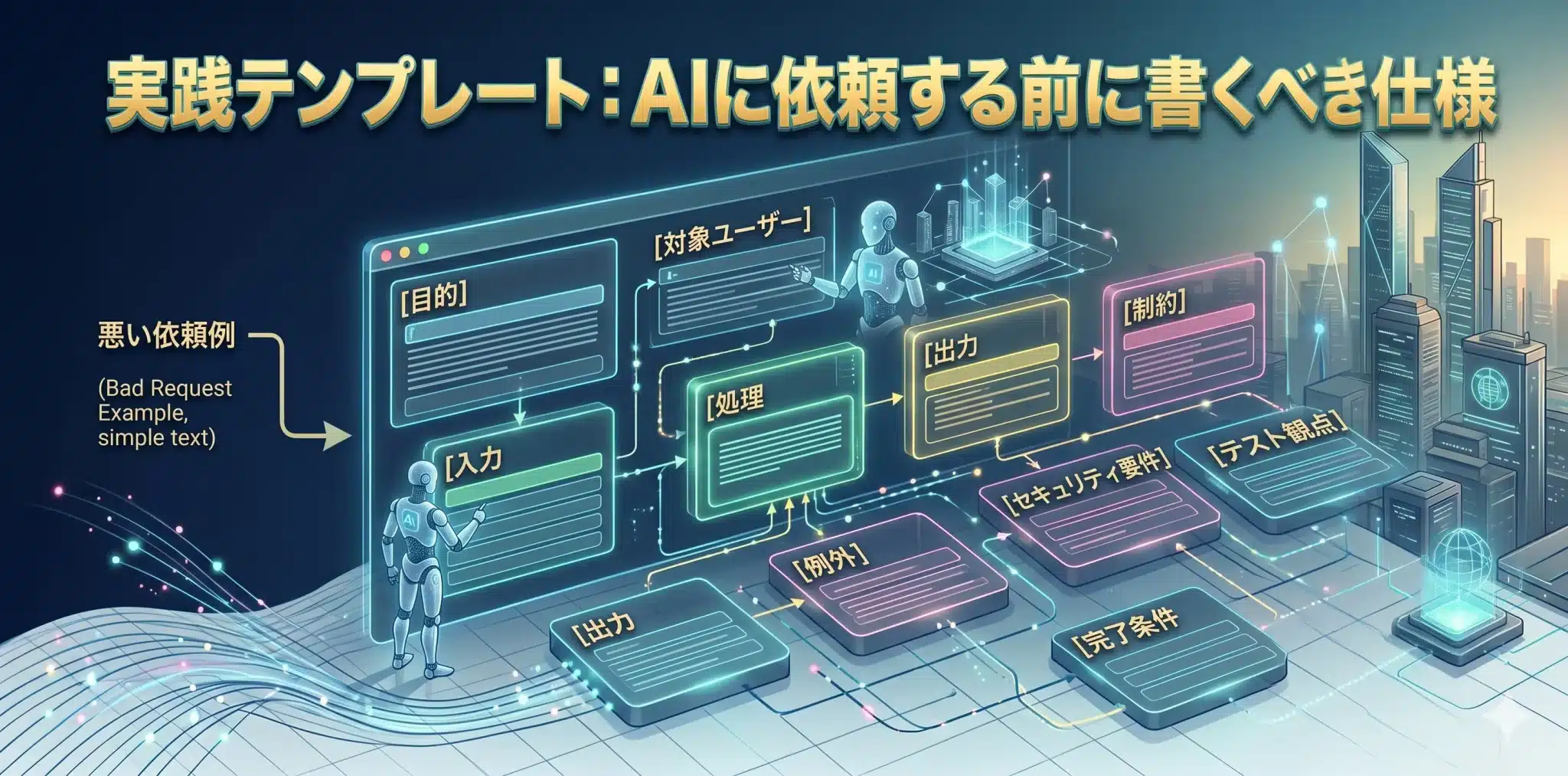
AI駆動開発で重要なのは、うまいプロンプトを書くことではなく、AIが迷わない仕様、制約、完了条件を先に定義することです。
AIに開発作業を依頼するとき、「ログイン画面を作って」「バグを直して」とだけ伝えると、AIは不足した前提を推測して作業します。その推測が当たれば速く進みますが、外れれば手戻りが増えます。
実務では、プロンプトを工夫する前に、AIに渡す仕様を整える必要があります。以下のテンプレートは、補助型、ワークフロー支援型、自律実行型のいずれでも使える基本形です。
【目的】 この機能・修正で何を実現したいか: 【対象ユーザー】 誰が使う機能か: 【入力】 ユーザーまたはシステムから受け取る情報: 【処理】 内部で行う処理・分岐・計算: 【出力】 画面表示、APIレスポンス、保存データなど: 【例外】 空データ、不正入力、権限不足、外部API失敗時の挙動: 【制約】 既存設計、利用ライブラリ、パフォーマンス、UI方針: 【セキュリティ要件】 認証、認可、入力検証、ログ、秘密情報の扱い: 【テスト観点】 正常系、異常系、境界値、回帰テスト: 【完了条件】 何を確認できれば完了とみなすか:
悪い依頼例
ユーザー管理画面を作ってください。
改善した依頼例
管理者向けのユーザー管理画面を作成してください。 目的: 管理者がユーザー一覧を確認し、権限変更と無効化を行えるようにする。 対象ユーザー: 管理者ロールを持つ社内ユーザー。 入力: ユーザーID、検索条件、権限変更内容、有効/無効ステータス。 処理: ユーザー一覧表示、検索、権限変更、無効化処理。 一般ユーザーはこの画面にアクセスできない。 出力: 一覧画面、更新成功メッセージ、エラーメッセージ。 例外: 存在しないユーザーID、権限不足、DB更新失敗時は安全側に倒す。 セキュリティ要件: 管理者ロール確認、CSRF対策、入力検証、操作ログ出力。 テスト観点: 管理者のみ更新可能であること。 一般ユーザーはアクセスできないこと。 無効化後のユーザーがログインできないこと。
このように、AIに渡す情報を具体化すると、生成されるコードの品質だけでなく、レビューのしやすさも大きく変わります。
チームで事故らない運用ルール
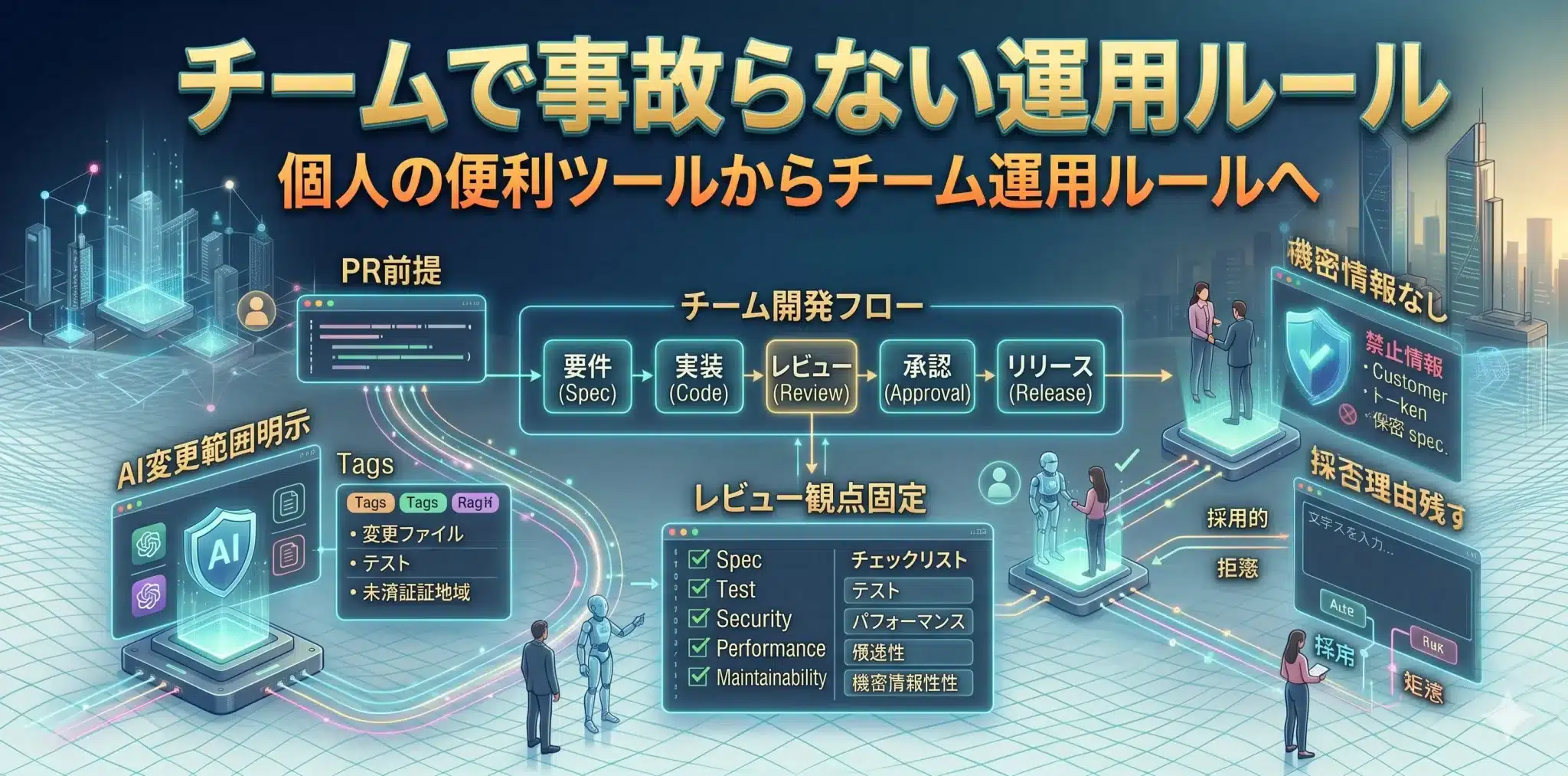
AI駆動開発をチームで使うなら、個人の便利ツールとしてではなく、レビュー、ログ、承認、責任分界を含む運用ルールとして設計する必要があります。
AI開発ツールは、個人で使うだけならすぐに効果が出ます。しかし、チームで使う場合は、誰がどのAIを使い、どの範囲まで自動生成を許し、どの差分を誰がレビューするかを決めておく必要があります。
| ルール | 内容 | 目的 |
|---|---|---|
| PR前提にする | AI生成コードも必ずPull Requestで確認する | 差分とレビュー履歴を残すため |
| AI変更範囲を明示する | AIが変更したファイル、生成したテスト、未確認箇所を記録する | レビュー漏れを防ぐため |
| レビュー観点を固定する | 仕様、テスト、セキュリティ、パフォーマンス、保守性を確認する | レビュー品質を属人化させないため |
| 機密情報を入れない | 顧客情報、認証情報、秘密鍵、未公開情報をプロンプトに入れない | 情報漏えいを防ぐため |
| 採否理由を残す | AI提案を採用・却下した理由をPRやIssueに残す | 後から判断を追跡できるようにするため |
AIが作業を進めるほど、人間は「どこで止めるか」「どこで人に戻すか」を決める必要があります。この論点は、Guardrails / Human Reviewでも詳しく解説しています。
本番投入チェックリスト
AI生成コードを本番に近づけるには、動くことではなく、レビュー、テスト、セキュリティ、ロールバック、監視まで確認する必要があります。
AI生成コードは、見た目には完成しているように見えることがあります。しかし、本番投入で重要なのは「動いたか」ではなく、「安全に運用できるか」です。
| # | チェック項目 | 確認内容 |
|---|---|---|
| 1 | 要件が文章で残っている | 目的、対象ユーザー、入力、出力、例外が明確か |
| 2 | 差分レビュー済み | AIが変更したファイルを人間が確認したか |
| 3 | 主要機能のテストがある | 正常系のテストが追加・更新されているか |
| 4 | 異常系を確認した | 不正入力、権限不足、外部サービス失敗時の挙動を確認したか |
| 5 | 入力検証がある | 型、長さ、形式、許容範囲を検証しているか |
| 6 | 認可が正しい | 他人のデータや管理機能へアクセスできないか |
| 7 | 秘密情報が含まれていない | APIキー、トークン、個人情報がコードやログに出ていないか |
| 8 | 依存関係を確認した | 脆弱なライブラリや不要な依存が追加されていないか |
| 9 | ロールバック手順がある | 問題発生時に戻せる手順があるか |
| 10 | 監視・ログ・アラートがある | 本番投入後に異常を検知できるか |
セキュリティ・ライセンス・機密情報の注意点
AI駆動開発では、生成コードの品質だけでなく、機密情報、ライセンス、依存関係、脆弱性を最初から確認する必要があります。
AI開発ツールは便利ですが、セキュリティ上のリスクもあります。AIが提案したコードが動くとしても、安全とは限りません。Veracodeの2025年レポートでは、AI生成コードが一定割合でOWASP Top 10に該当する脆弱性を含むことが報告されています。
企業でAI駆動開発を進める場合、次の観点は最低限確認すべきです。
- 機密情報:顧客情報、秘密鍵、アクセストークン、未公開仕様をプロンプトに含めない
- ライセンス:AIが提案したライブラリやコード片のライセンスを確認する
- 依存関係:不要なパッケージや脆弱なバージョンが追加されていないか確認する
- SAST / DAST:静的解析・動的解析をCI/CDへ組み込む
- シークレット検知:APIキーやトークンの混入を自動検知する
- ログ:個人情報や認証情報がログに出ていないか確認する
この領域は、AIエージェントが外部ツールや社内データへ接続するほど重要になります。詳しくは、AIエージェントセキュリティも参考にしてください。
まとめ:小さく始め、品質ゲートで守る
AI駆動開発ツールは、構想力の時代へ移行するための実践環境です。ただし、品質ゲートなしに使えば、速さはそのままリスクになります。
AI駆動開発ツールは、ソフトウェア開発の現場を大きく変えています。Copilotは手元の開発作業を支援し、CursorやWindsurfはAIネイティブなIDE体験を広げ、Claude Code、Codex、Jules、Devinは、既存コードを読み、タスクを進め、修正案を作る方向へ進んでいます。
SWE-benchの高スコア化は、AIが実コード修正能力を急速に高めていることを示しています。しかし、ベンチマーク性能と本番品質は別物です。実務では、仕様、レビュー、テスト、セキュリティ、責任分界を人間が設計する必要があります。
AI駆動開発で重要なのは、AIにすべてを任せることではなく、小さく始め、差分を確認し、品質ゲートで守りながら、構想を実装へ変換する力をチームに定着させることです。
今日のお持ち帰り3ポイント
- AI駆動開発ツールは、コード補完から実行支援・PR提案へ進化しています。
- SWE-benchの高スコア化は、AIが既存コードを読み、未解決Issueに近い実務課題へ対応し始めたことを示しています。
- 本番導入では、ツール選定より先に、仕様、レビュー、テスト、セキュリティ、責任分界の品質ゲートが重要です。
専門用語まとめ
- AI駆動開発
- AIをコード補完だけでなく、要件整理、設計、実装、テスト、レビュー支援、本番投入前確認まで開発プロセス全体に組み込む開発スタイル。
- AIコーディングエージェント
- コードベースを読み、タスクを計画し、ファイル編集、テスト、修正、Pull Request提案までを行うAI。Claude Code、Codex、Jules、Devinなどが該当する。
- SWE-bench
- 実際のGitHubリポジトリに由来するソフトウェア修正タスクを使い、AIが既存コードの文脈を理解してIssueを解決できるかを測るベンチマーク。
- SWE-bench Pro
- SWE-bench Verifiedよりも大規模で実務寄りの評価を目指すベンチマーク。1,865件のタスクと41のリポジトリを含み、Verifiedの汚染問題を踏まえたより厳しい評価として注目されている。
- 品質ゲート
- AI生成コードを次の工程へ進める前に確認する条件。レビュー、テスト、セキュリティ、認可、ロールバック、監視などを含む。
- Human Review
- AIが生成・修正した成果物について、人間が最終判断する工程。AI駆動開発では、品質保証と責任分界の中核になる。
よくある質問(FAQ)
Q1. AI駆動開発ツールは何から試すべきですか?
A1. まずは、GitHub CopilotやCursorなどの補助型ツールで、コード説明、軽微な修正、テスト追加から始めるのが安全です。いきなり大きな機能を自律型エージェントに任せるのではなく、小さな差分をレビューできる形で始めることを推奨します。
Q2. AIに任せてよい作業と、任せにくい作業は何ですか?
A2. テスト追加、リファクタリング、ドキュメント生成、軽微なバグ修正は任せやすい領域です。一方、認証・認可、決済、個人情報、権限設計、セキュリティ境界に関わる作業は、人間が主導し、AIは補助として使うのが安全です。
Q3. GitHub Copilot、Cursor、Devinはどう使い分ければよいですか?
A3. GitHub Copilotは既存開発環境での補助、CursorはAIネイティブなIDE体験、Devinは自律実行型タスクの検証に向きます。実務では、補助型から始め、レビュー体制が整ってからワークフロー支援型や自律実行型へ広げるのが現実的です。
Q4. AI生成コードを本番投入する前に確認すべきことは?
A4. 要件、差分レビュー、テスト、異常系、入力検証、認可、秘密情報、依存関係、ロールバック、監視を確認します。動作確認だけで本番投入するのは危険です。
Q5. 企業で使う場合、最初に決めるべきルールは何ですか?
A5. まず、機密情報をプロンプトに入れないこと、AI生成コードを必ずPRでレビューすること、採用・却下の判断理由を残すこと、セキュリティ確認を品質ゲートに含めることを決めるべきです。
主な参考サイト
本記事は一次情報を軸に執筆しています。公式発表・仕様・標準化団体・公式ドキュメントを優先し、検証可能性を担保します。
- GitHub Copilot documentation
- About GitHub Copilot cloud agent
- OpenAI – Introducing Codex
- OpenAI Developers – Codex cloud
- Claude Code overview
- Google Jules – Jules is out of beta
- Google – Jules is now available
- Reuters – Cognition AI to buy Windsurf
- Reuters – Google / Windsurf technology licensing report
- SWE-bench official leaderboards
- OpenAI – Why we no longer evaluate SWE-bench Verified
- Scale Labs – SWE-Bench Pro
- Anthropic – Project Glasswing
- Cognition – Devin can now Manage Devins
- Veracode – 2025 GenAI Code Security Report
あわせて読みたい
AI駆動開発ツールを実務で使うには、構想力、ツール選定、チーム型開発、セキュリティ統制をあわせて理解する必要があります。
更新履歴
- 初稿公開
- AI駆動開発ツール実践ガイドとして、主要ツール・品質ゲート・実践テンプレート中心に改版。







