


AI開発の未来:水平型(協調) vs 垂直型(自律)の分岐点
Devin AIのSWE-benchスコアは、SOTAモデルに大きく劣後しています。しかし、これは単なる優劣の物語ではありません。AIと人間の「共進化」の未来を占う、二つの異なる開発思想が描く未来の地図を、解き明かす試みです。本稿では、SWE-benchという基準を確立した水平型と、その基準では正しく評価できない価値を問う垂直型の思想の違いを、最新データから解き明します。
- ✅ 要点1:OpenAI GPT-5等がSWE-benchで実用域のスコアを達成し、「水平型」が確立した基準での優位性を示しました。
- ✅ 要点2:市場の対立軸は、開発の全工程を支配する「水平的エコシステム」と、特定の高価値な仕事を独占する「垂直的自動化」の思想の分岐として現れています。
- ✅ 要点3:Cognition社はWindsurf買収により、「垂直的自動化」の実現を加速化させる道を選択しました。
この記事の著者・監修者

📉 色褪せるベンチマーク:SWE-benchにおけるDevinの現在地
要約:Devinが発表当初に示したベンチマーク性能は当時としては画期的でしたが、現在は「水平型」思想が定めた基準上では決定的に凌駕されています。本章では、その事実を厳密な定義とタイムラインで読み解きます。
2024年3月12日、Cognition AIはDevinがSWE-benchの旧基準(Full 25% subset)において13.86%を達成したと発表し、業界に衝撃を与えました。しかし競争は加速し、約14カ月後の2025年5月にはAnthropic社のClaude Sonnet 4が72.7%を記録して初めて70%の壁を突破。さらに同年8月にはGPT-5が「477問換算で74.9%(500問換算では約71.45%)」という参考値を提示しました。公開条件の違いから公式リーダーボードには未掲載ですが、いずれにせよDevinの優位性は完全に過去のものとなりました。
| エージェント/モデル | 解決率 (%) | 報告日 |
|---|---|---|
| OpenAI GPT-5 | 74.9% (社内参考値) | 2025年8月 |
| Anthropic Claude Opus 4.1 | 74.5% | 2025年8月 |
| Anthropic Claude Sonnet 4 | 72.7% | 2025年5月 |
| Google Gemini 2.5 Pro | 63.8% (custom agent setup) | 2025年3月 |
| Devin AI | (13.86% / 旧基準) | 2024年3月 |
※OpenAI 74.9%は477/500問での社内参考値(23問除外)であり、公式リーダーボードの数値とは評価条件が異なります。
※Devin 13.86%はFull(25%サブセット)での旧基準スコアであり、上記モデルとは直接比較できません。
👨🏫 AI専門家が解説:ベンチマークスコアの「裏側」を読み解く
各社のスコアを正しく比較するには「どのテストセットで、どのような条件下で測定されたか」まで見ることが不可欠です。
ポイント1:Devinのスコアは「直接比較できない」
Devinの13.86%は「品質が保証されていない、古い基準のテスト」での結果であり、現在のSOTAモデルが評価されている「人間が解決可能だと検証済みの、信頼性が高いテスト(Verified)」とは、測定の土俵そのものが異なります。
- Full (25% subset): Devinが受けた初期のテスト。設定が不完全な問題も混在。
- Verified: 現在の標準テスト。人間が検証した問題だけを集めた高信頼性セット。
ポイント2:OpenAIのスコアは「条件付きの参考値」
AnthropicやGoogleはVerifiedでの評価を公表していますが、OpenAIが発表した74.9%というトップスコアは、厳密には「公式記録」ではなく「自社測定の参考値」です。
- OpenAIは、500問のうち自社環境で安定しなかった23問を除外した、477問でテストを実施。
- このため、単純なスコア比較には注意が必要です。
[補足] 2025年3月のプレプリント研究では、テストに合格しても実装差分に仕様逸脱が残る例があり、報告解決率が条件により平均+6.2pt過大評価になり得ると示唆されています(査読前)。
エージェントの解剖学:性能格差の分析
DevinがSOTAモデルに大きく水をあけられた背景には、技術的・アーキテクチャ的な要因が存在します。
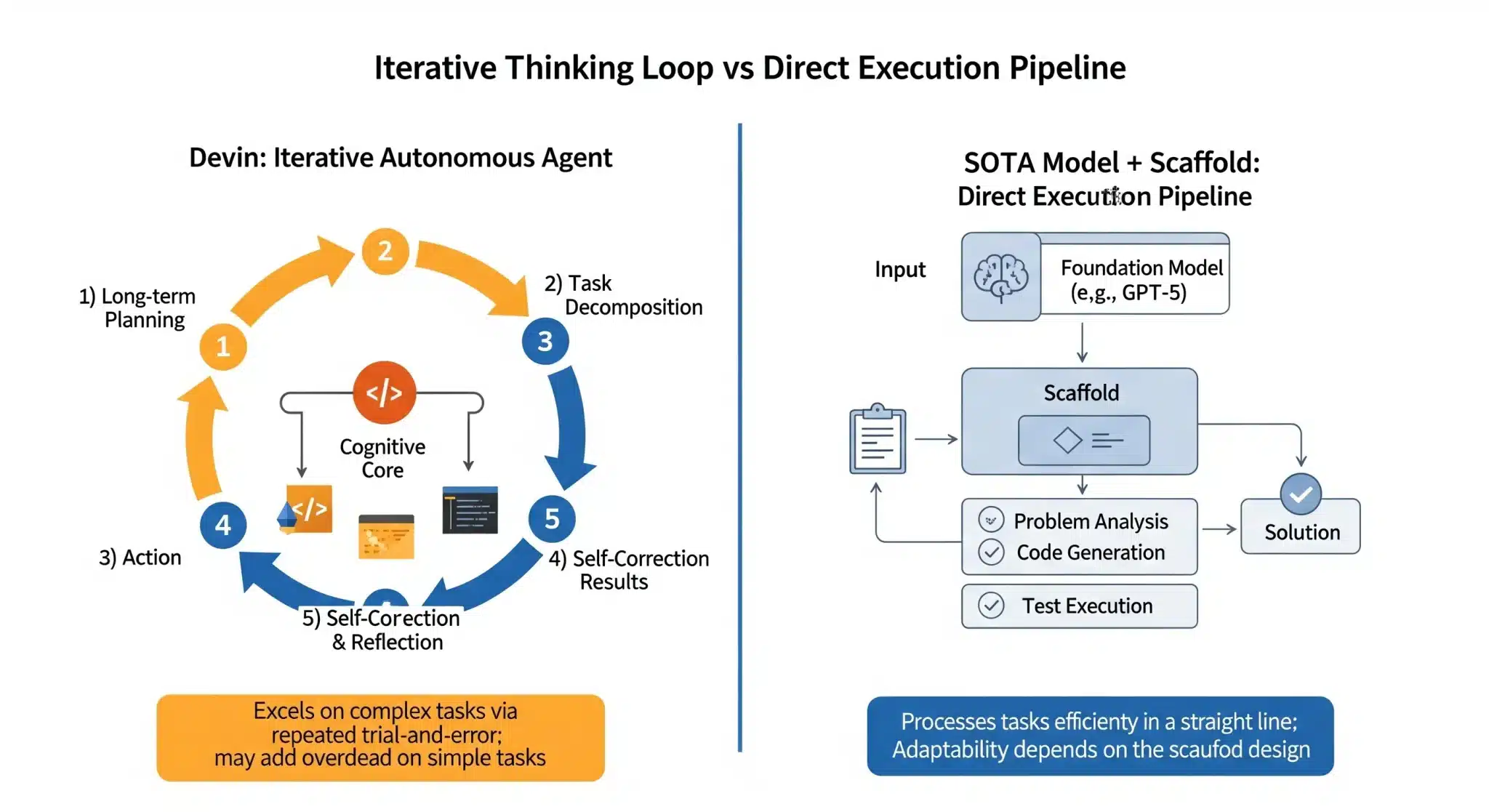 図1:Devinの複雑なアーキテクチャと、SOTAモデルのシンプルな構成
図1:Devinの複雑なアーキテクチャと、SOTAモデルのシンプルな構成アーキテクチャのオーバーヘッド
Devinは、長期的な推論と計画を主眼に設計された、複雑で自律的なエージェントです。しかし、SWE-benchのような制約された問題に適用されると、このアーキテクチャが大きなオーバーヘッドとなり、過度に複雑で実用的でない解決策を生成する傾向が指摘されています。(出典: Cognition公式レポート)
エージェント vs. モデル+Scaffold
OpenAIやAnthropicが達成したSOTAスコアは、Devinのような完全自律型エージェントではなく、強力な基盤モデル(GPT-5, Claude 4)をタスク特化の軽量Scaffold(足場)でラップする構成によって得られています。少なくともバグ修正というタスクにおいては、複雑な長期計画アーキテクチャよりも、基礎となるLLMの推論・コーディング能力+薄い制御ロジックの方が、現時点では高い信頼性とスループットを示します。
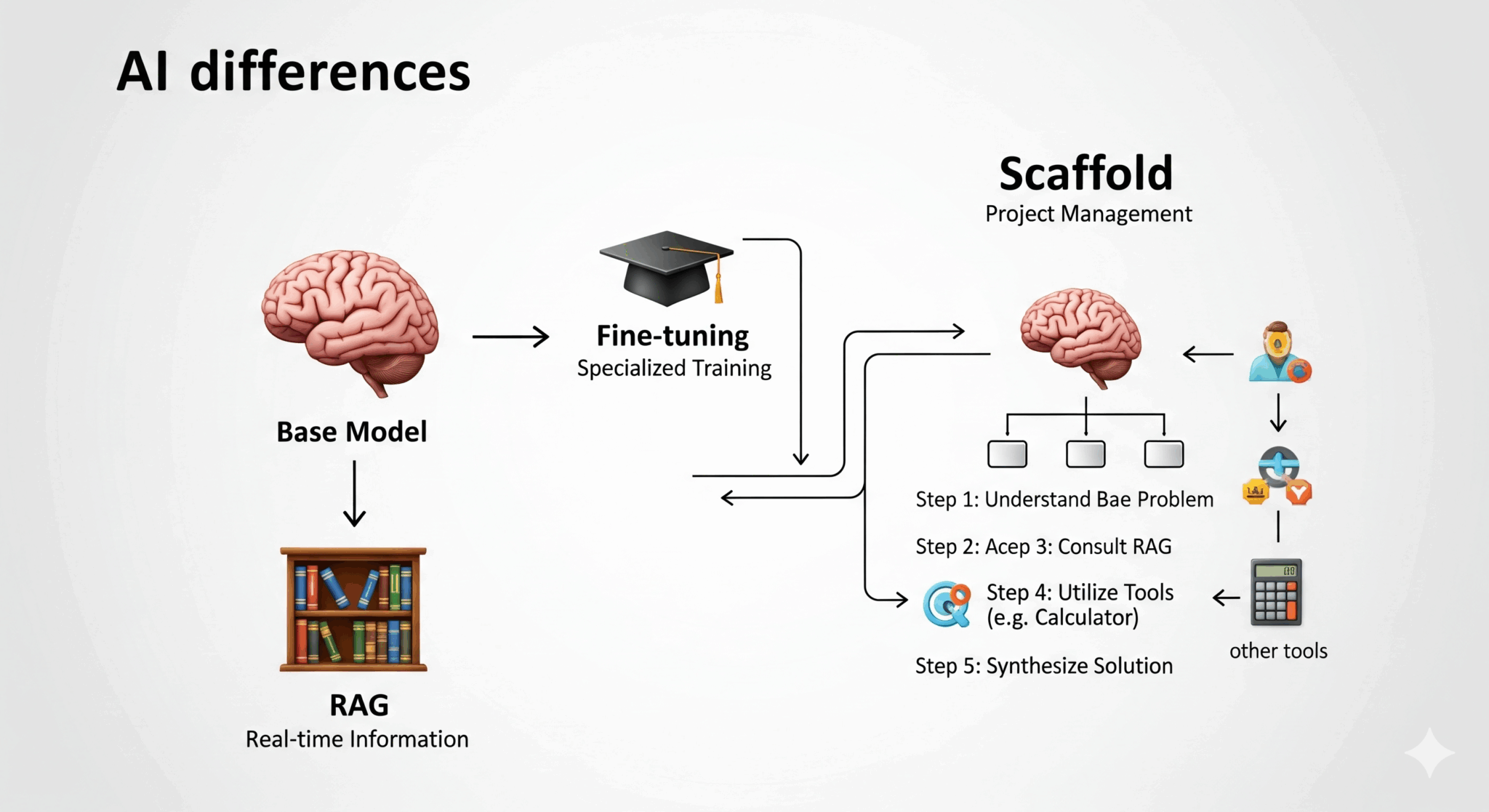
図2:AI開発における主要技術の違い(概念図/編集部作成)
👨🏫 AI専門家が解説:「モデル」「ファインチューニング」「RAG」「Scaffold」の違い
プロジェクトチームにたとえると理解が速くなります。
- 🧠 基盤モデル (GPT-5など):指示待ちだが圧倒的能力を持つ「天才プログラマー」。
- 🎓 ファインチューニング:特定分野に最適化する「特別研修」。
- 📚 RAG:必要な資料を最新で供給する「情報参謀」。
- 📋 Scaffold:タスク分解と順序制御を担う「優秀なPM」。
現在の勝ち筋:天才(基盤モデル)+優秀なPM(Scaffold)を最小限で組み合わせる。
👨🏫 かみ砕きポイント
この性能差の本質は「複雑さ vs. 効率性」。Devinは「AIが独立して働く未来」を先取りしましたが、現実の現場では「AIが人間の作業を効率的に補助する現在」の方が費用対効果に優れます。強力な基盤モデルに薄い自律性を付与するだけでも、テスト安定性・再現性・速度のバランスを取りやすいのです。
🏰 2つの未来:水平的エコシステムと垂直的自動化
要約:Devinの性能差は、より大きな市場構造の変化を映す鏡です。AIと人間の協業像をめぐる二つの思想、すなわち「水平的エコシステム」と「垂直的自動化」への分岐です。
水平的エコシステム:開発者の「能力を拡張」する思想
MicrosoftやGoogleが狙うのは、開発者の日常業務の“すべて”にAIを行き渡らせる広くて軽い支配です。設計→コーディング→テスト→デプロイ→運用まで、IDEやクラウド、CI/CDの各所でAIに触れさせ、開発者を自社エコシステムに粘着的にロックインします。
- OpenAI / Microsoft:GPT-5をGitHub Copilot、VS Code、Azure AIへ深く統合し、アイデア構想からPR作成までをAIが背後で補助。
- Anthropic:Claude 4を中核に、CLIベースのClaude CodeでTDDやレビューなど既存ワークフローに寄り添う。
- Google:Gemini Code AssistをFirebase、BigQueryなどGCP全体と結合し、クラウド運用まで含めたフルループを加速。
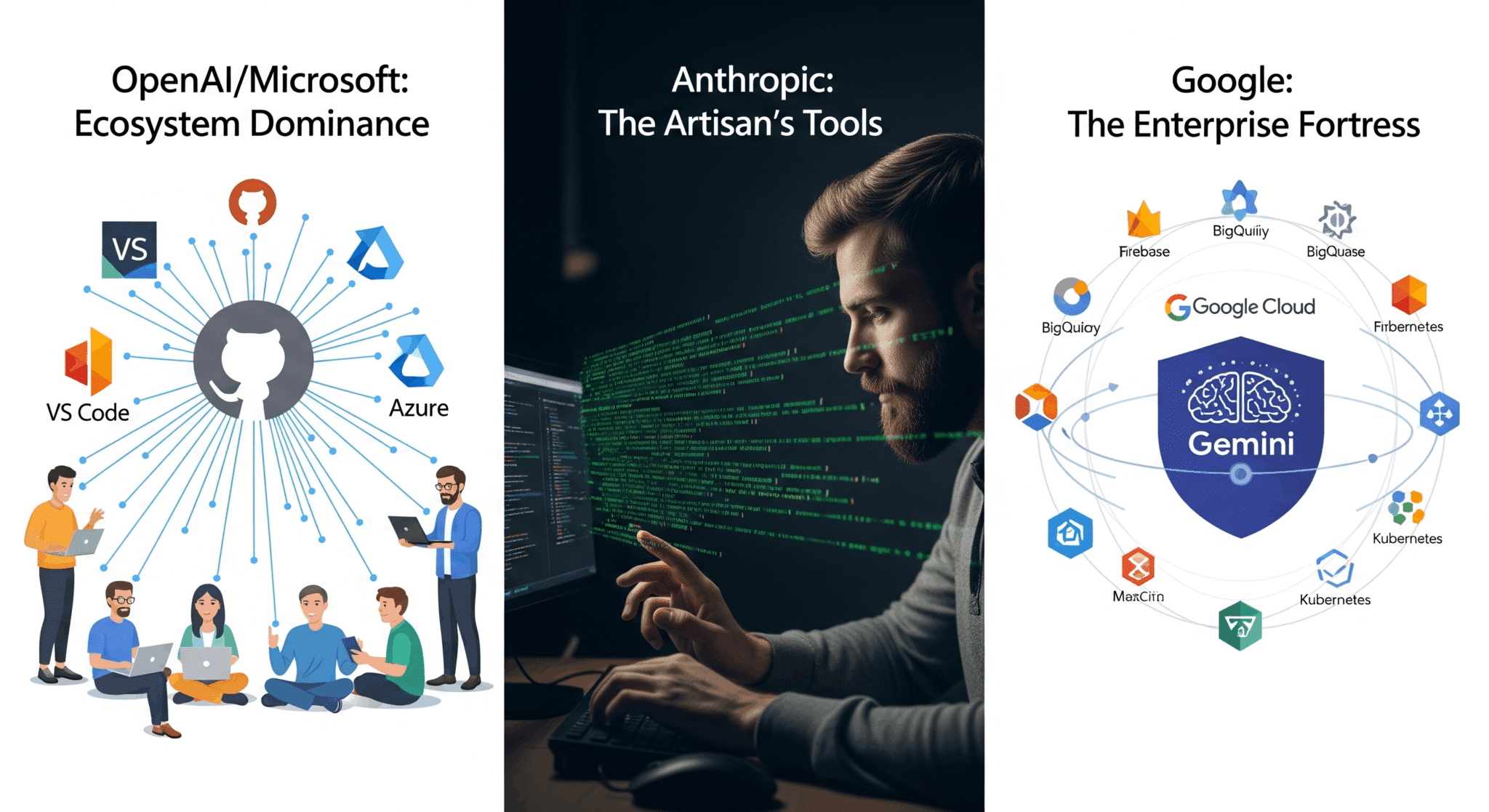
垂直的自動化:開発者の「タスクを代替」する思想
一方Cognitionは、特定の“高価値な仕事”—たとえば大規模レガシー移行や複雑な新機能の実装—を丸ごと任せられる深くて狭い支援を志向します。すべてを支配するのではなく、「このタイプの仕事はDevinにしか頼めない」という代替の独占を狙うのです。
Cognitionの顧客事例では、**Nubank**が「600万行超のETL移行を数週間で完了、従来比12倍の効率化」、**Eight Sleep**が「データ分析業務の出荷・調査を3倍に加速」と報告しています。**ただし、いずれも顧客自身の自己報告であり、第三者監査による検証値ではありません。**
さらに2025年7月、GoogleがWindsurfの技術ライセンスと主要人材を取得した直後、CognitionはWindsurfのIP・製品基盤に加え、公式発表で**年間経常収益(ARR)8,200万ドル、350社超の顧客基盤**を含む事業を取得。これは「垂直的自動化」を体現するための専用プラットフォーム確立へ向けた決定打でした。
2つの思想の比較
| 次元 | 水平的エコシステム(協調) | 垂直的自動化(自律) |
|---|---|---|
| 中核哲学 | 能力の拡張:AIは道具。人間中心の意思決定。 | タスクの代替:AIに委任。人間は監督・承認。 |
| 対象範囲 | SDLC全域(設計〜運用)を広くカバー。 | 特定の高価値タスクを深く最適化・自動化。 |
| ユーザー役割 | 運転手/職人(ハンドルは人間が握る)。 | 建築家/監督(高レベル指示とレビュー)。 |
| ワークフロー | 同期・対話:IDE/CLIで逐次協調。 | 非同期・委任:依頼→完了通知→検収。 |
| 価値提供 | 生産性と品質の底上げ、広い採用性。 | 大量作業の短期圧縮、ROIの明確化。 |
| 成功指標 | 採用率、開発速度、バグ率、デプロイ頻度。 | 完了工数削減、スループット、コスト回収期間。 |
| 主要リスク | 強いエコシステムロックイン、データ密着度。 | 失敗時のリカバリコスト、監督負荷、説明可能性。 |
Windsurf買収の意味:データとプラットフォーム
エージェントの強化には、高粒度の開発者行動データが不可欠です。AIネイティブIDEは、編集・コンパイル・テスト・リリースといった操作の時系列を失敗含めて捉えます。学習データの枯渇が話題となる中、こうした一等地のデータはモデル改善の循環(data → model → UX → more data)を回すフライホイールです。Windsurfの取得は、Cognitionが「垂直」思想を製品として落とし込むための土台を手にしたことを意味します。
実践ガイド:あなたのプロジェクトは、水平か?垂直か?
要約:では、あなたのチームはどちらの思想を選ぶべきか?ここでは、要件の性質やリスク許容度から最適なAI開発スタイルを判断するための、5つの判定軸と具体的なROIの考え方を提示する。
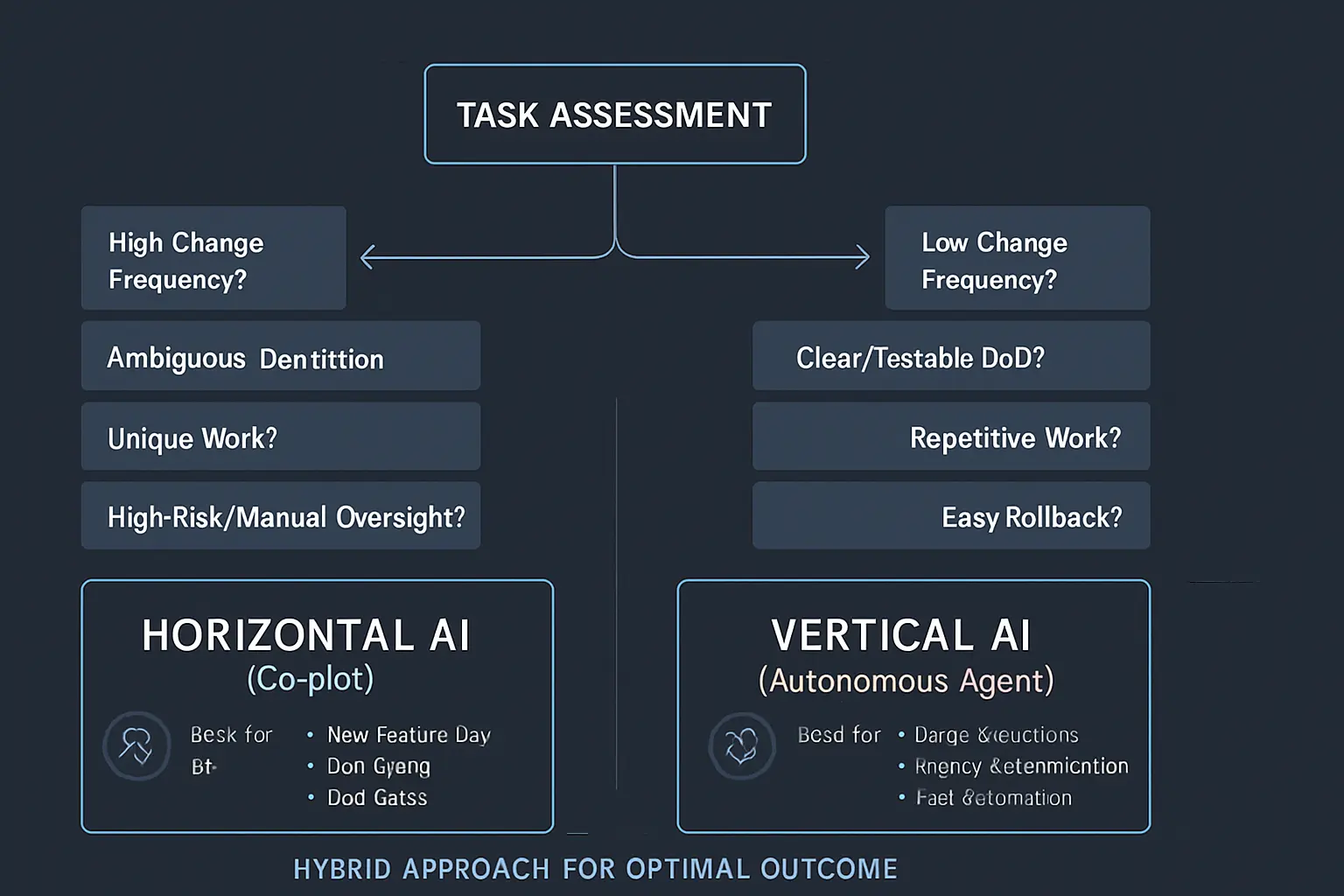
どの開発に向くか(超要約)
- 水平(協調)=「変化対応を最大化」日々の機能開発/レビュー/小~中規模改修/運用・調査/試作。開発者がハンドルを握り、AIが全工程で補助。
- 垂直(自律)=「スループットを最大化」大量リファクタ・API移行・テスト自動生成→修復・レガシー置換・一括バグ修正。人は監督と検収に集中。
選定フレーム(5つの判定軸)
| 判定軸 | 指標の目安 | 水平(協調)が優勢 | 垂直(自律)が優勢 |
|---|---|---|---|
| 要件の揮発度 | 仕様変更/週 | 高い(≥2回/週) | 低い(≤1回/週) |
| 完了の定義(DoD) | 定量指標の有無 | 合意が曖昧/多面的 | 明確(合否テスト・差分基準) |
| 作業の同型性 | 類似チケット率 | 低(都度ユニーク) | 高(同パターン連続) |
| リスクと監督 | ロールバック容易性 | ユーザ影響大・戻し難い | ロールバック戦略明確 |
| テスト/観測性 | カバレッジ/SLIs | 手動依存・人判断多 | 自動テスト/SLIsで判定可能 |
実務ルール:3/5以上で左(右)に振れたら、その陣営を第一選択に。真ん中ならハイブリッド(後述)で“分割統治”。
具体ユースケース
水平(協調)に最適
- 新機能開発(0→1/1→n):要件が動く、探索が多い、レビューで品質が決まる。
- デバッグ/調査:仮説検証→コードリーディング→最小修正の連鎖。
- 運用タスク:アラート分析、オンコール支援、SRE改善の反復対話。
- ドキュメント整備:設計意図の可視化、コードコメント、リリースノート。
- KPI例:PR作成までのリードタイム↓、レビューループ数↓、手戻り率↓、開発者満足度↑。
垂直(自律)に最適
- API/SDKの大規模移行:呼び出し点の一括変換+回帰テストで合否判定。
- レガシー→モダン化:パターン化しやすい置換(例:ORM/ログ/認証基盤)。
- テスト拡充→自動修復:スナップショット生成、失敗テストに対するパッチ生成。
- バグ修正の一括適用:同種欠陥(NPE、境界条件等)を全リポ横断で処置。
- KPI例:完了件数/日↑、自動適用率↑、再現バグ率↓、コスト回収期間(月)↓。
ROIの考え方(簡易式)
- 水平(協調)の主効果=人の時短ROI ≈ (平均PRリードタイム短縮 × PR本数 × 人件費) − 導入/運用コスト→ 価値が分散。導入障壁は低いが、定量の見せ方を工夫。
- 垂直(自律)の主効果=大量処理の一括短縮ROI ≈ (置換/修復件数 × 1件あたりの従来工数 × 人件費) − 監督/検収コスト→ 成果が塊で出る。DoDと監督プロセスを固めるほど、ブレずに回収。
反パターン(失敗例)
- 水平の過信:大規模移行を日常の対話フローに埋め込み、終わらないスプリント化。→ 自律ジョブに切り出して一括処理へ。
- 垂直の早すぎる投入:仕様が毎週変わる機能群を自律化して、修正コストが雪だるま。→ 協調で要件を固めてから自律へ。
- 評価の混線:ベンチマークの数値だけで導入判断。→ 自社データでのパイロット+SLIs/SLAsで合否を定義。
ハイブリッド設計(実務のおすすめ)
- “協調で設計→自律で実装”:ストーリーマップ/変更計画は水平で作る。具体パターンに落ちた時点で、自律ジョブ(垂直)に委任。
- “自律で下ごしらえ→協調で仕上げ”:一括置換・テスト生成は垂直で実行。クリティカルな最終判断(API設計、UX)は人+協調で。
導入判断チェックリスト
- ✅ 変更頻度(揮発度)は高いか、低いか?
- ✅ DoDは数式/テストで表現できるか?
- ✅ 作業は同型(パターン化)できるか?
- ✅ テストと計測で自動判定できるか?
- ✅ 失敗時のロールバックは用意済みか?
- ✅ 期待KPIと回収計画は事前に定義したか?
⚔️ 結論:人類とAIの共進化の始まり
もちろん、SWE-benchのスコア差は単なる現象です。ベンチマークには常に設計思想のバイアスが織り込まれ、そこで優位に立つ者は自らの思想を標準に昇格させようとします。水平型は「比較可能性」を武器に基準を普及させ、垂直型は「実務でしか測れない価値」を提示して別の勝利条件を構築しようとする。いま市場は、二つの基準が併存する局面へ入りました。
真の論点は、どちらが「正しいか」ではありません。人間とAIの関係をどう設計するかです。日々の開発体験に寄り添う協調(水平)か、面倒で危険な大工事を肩代わりする自律(垂直)か。いずれも、人類の創造活動を前へ押し出す異なる力学を持っています。
そして将来、水平型はより高度な自律性を内包し、垂直型は協調のUXを獲得していくでしょう。しかし、真の戦場は両陣営のどちらかが勝利する世界ではありません。現実のソフトウェア開発の現場では、すでに両者の『ハイブリッド化』が始まっています。
例えば、日々のコーディングはGitHub Copilotのような水平型アシスタントと「協調」しつつ、CI/CDパイプラインの中では、特定フレームワークの脆弱性診断やリファクタリングを垂直型エージェントに「委任」する。一つの開発フローの中に、思想の異なるAIが混在し、それぞれが得意な領域で価値を提供するのです。
両陣営は収束と分岐を繰り返しながら、最終的には私たちのワークフローに溶け込んだ、多様でハイブリッドな生態系を形成していく。それこそが、人類とAIの共進化の、最も現実的な軌跡なのかもしれません。
📝 まとめ:私たちは、どの未来を選ぶべきか
選ぶのは「方式」ではなく、「仕分け」です。
変わりやすい作業は人とAIが協調して素早く合意し、反復と量のある作業は自律エージェントに任せて一気に進めます。
最初のチケットで役割と完了条件を決め、設計レビューで検証可能性を整え、実装後は変更をテストで確かめ、戻せる導線を用意します。
迷ったら――”変化は協調、量は自律“。
次のプロジェクトから静かに始めましょう。未来はその一手から動き出します。
📚 専門用語まとめ
- SWE-bench Verified
- 人間による解決可能性が検証された500問から成る評価セット。再現性と安定実行を重視し、現行SOTAの比較標準として用いられる。
- 統合アシスタント戦略(水平)
- IDE/クラウド/CIなど開発の全工程にAIを統合し、開発者の能力を拡張する方針。エコシステムによる体験のシームレス化とロックインが鍵。
- 自律型エージェント(垂直)
- 高レベル指示の委任を前提に、計画から実装・検証までを自律的に遂行するシステム。特定タスクの深い自動化でROIを狙う。
🙋 よくある質問(FAQ)
❓ Q1. Devin AIが当初注目された理由と現在の状況は?
💡 A1. 2024年3月、旧基準のSWE-benchで13.86%という画期的なスコアを達成し注目されました。現在は、SOTAモデルが現行基準のSWE-bench Verifiedで70%台を記録しており、ベンチマークの土俵が異なりますが、その上では劣勢です。
❓ Q2. 自律型エージェントと統合アシスタント、どちらが優れているのですか?
💡 A2. 用途次第です。日常の反復作業を素早く・安全に進めるなら統合アシスタントが現実的。一方で、大規模移行など「丸投げで価値が出る」領域は自律型の独壇場になり得ます。
❓ Q3. Windsurf買収の戦略的意味は?
💡 A3. AIネイティブIDEと顧客基盤、そして公式発表された高粒度の開発者行動データを獲得し、垂直的自動化の実装と学習サイクル(data→model→UX→data)を加速させるための土台を得たことにあります。
❓ Q4. SWE-benchのスコアはどの程度信頼できますか?
💡 A4. Verifiedは現行標準ですが、2025年3月の査読前研究では合格でも仕様逸脱が残るケースがあり、+6.2pt程度の過大評価の可能性が示唆されています。スコアは必要条件であって、実務妥当性の十分条件ではありません。
❓ Q5. 導入判断のフレームは?
💡 A5. ①既存ワークフローとの統合性、②実務での安定性・エラー率、③学習コストと展開速度、④ロックイン・ガバナンスの許容度、をチームで数値化。委任(垂直)と協調(水平)の責務境界を先に決めると失敗しにくいです。
🔗 主な参考サイト
- Cognition Labs – Introducing Devin(公式発表)
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
- SWE-bench公式サイト(詳細・最新スコア)
- OpenAI – GPT-5公式発表
- Anthropic – Claude 4ファミリー
📖 合わせて読みたい
- 生成AIは開発スタイルをどう変えるか? CopilotからDevinまで、最新ツールの現在地
- Anthropic MCPで拓く!AI連携とビジネス活用の第一歩
- 【最新調査】国内 AI 市場の未来予測 ─ PoC の壁を乗り越えるエージェンティック戦略3選
- 【2025 年最新版】AI 開発支援ツール徹底比較ランキング TOP 8
- 【2025年版】Vibe Coding革命:話すだけ開発の最前線
- MetaGPT完全ガイド|MGX商用版と企業導入ROI・事例【2025年版】
- AutoGen完全ガイド:AIマルチエージェントの未来と活用法【2025年最新版】
🗓️ 更新履歴
- 初版公開








