


※本記事は継続的に「最新情報にアップデート」を実施しています。
Databricks対Snowflake、AI時代のデータ基盤を比較
📢 2026年最新情報
Databricksは2025年11月末〜12月にかけて、評価額1,340億ドル規模での資金調達が報じられ(報道ベース)、AI需要を追い風に存在感を強めています。
IPOは有力候補として取り沙汰される一方、実施時期は市場環境や資本政策の影響を受けるため、ここでは「候補」として捉えるのが適切です。
※)約20兆円は1ドル=150円換算で為替で変動します。
- 評価額:1,340億ドル規模での資金調達が報じられた(報道ベース)
- 売上指標:年換算売上(revenue run-rate)は数十億ドル規模として報じられ(詳細は本文の財務章で整理)
- IPO:有力候補(ただし時期は固定せず「市場環境次第」を前提に整理)
「データとAIをどのプラットフォームで管理すべきか?」
この問いに、DatabricksとSnowflakeという2つの巨大プレイヤーが異なる答えを提示しています。
Databricksが提唱する「レイクハウス」とは何か?Snowflakeとの決定的な違いは?
この記事では、AI時代のデータ基盤選択に必要な知識を、技術的背景から将来展望まで体系的に解説します。
本記事は2026年2月時点の公開情報(AI機能、財務トピック、クラウド連携トレンド)を反映し、継続的にアップデートしています。
🧭 CxO・投資家向け 3行サマリ
- Databricksは「Lakehouse+AI/ML」、Snowflakeは「DWH+BI/SQL」が主戦場。
- 2026年は“二者択一”より、共存を前提に役割分担を設計する流れが強い。
- 自社の人材・データ戦略・投資余力で、主軸(主戦場)と補完(補助線)を決めるのが近道。
✅ この記事の結論(TLDR)
Databricksは「レイクハウス」アーキテクチャでデータの所有権を顧客に残し、AI・機械学習に強みを持つ一方、Snowflakeは管理型データウェアハウスでBI・SQL分析に最適化。選択基準は、AI活用の本気度と技術人材の有無です。
- Databricks: オープンレイクハウス、AI/ML特化、技術者向け、データ所有権は顧客
- Snowflake: 管理型DWH、BI/SQL特化、ビジネスユーザー向け、Snowflake内管理
- 選択基準: AI戦略の本気度(独自LLM/RAGの運用コストも含む)、マルチクラウド方針、ベンダーロックイン許容度
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』
Databricksとは何か?
まず基本概念の関係性を理解してから、Databricksの使命と成り立ち、そして現在の市場でのポジションを概観します。Apache Sparkの開発者たちが創業し、今や急拡大する評価を受けるに至った背景を探ります。
まず理解しておきたい:基本概念の関係性
「Databricks」について語る前に、4つの重要な概念とその関係性を整理しましょう。これらが混同されがちですが、それぞれ異なる層で役割を果たしています。
「Databricks」という名前の二重の意味
- ①会社名:2013年に設立されたアメリカの企業(Databricks Inc.)
- ②クラウドサービス名:その会社が提供するデータ・AIプラットフォーム
この記事では主にクラウドサービスとしてのDatabricksについて解説します。
技術・概念の発展ステップ
以下の図は、データレイクからDatabricksまでの技術発展を4段階で示しています。各段階で新しい機能が追加され、最終的に包括的なデータ・AIプラットフォームとして完成しています。
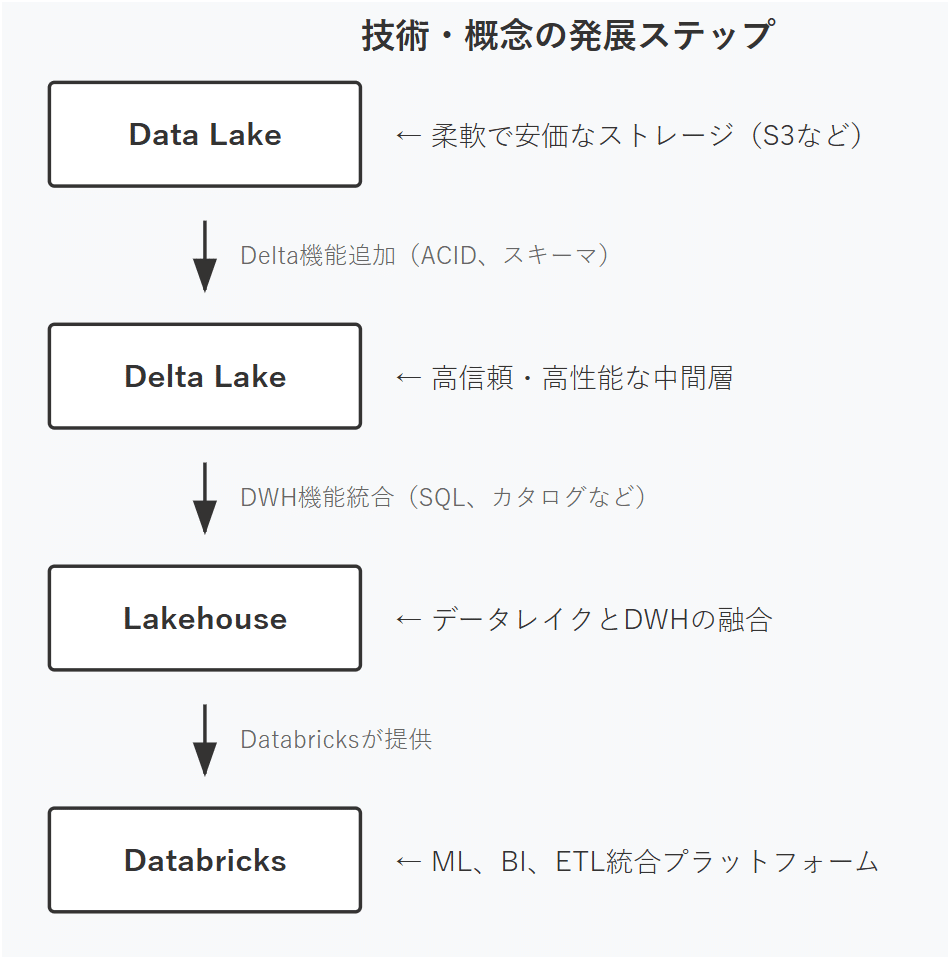
各概念の詳しい説明:
- Data Lake(データレイク):
2010年代初頭から普及した、従来の高額なデータウェアハウスに代わる、AWS S3やAzure Blobなどのクラウドストレージを活用した安価で柔軟なデータ保存方法。様々な形式のデータをそのまま保存できるが、データ品質の管理が課題でした。 - Delta Lake(デルタレイク):
Databricks社が2019年にオープンソースとして公開した技術で、データレイクに「ACID特性」や「スキーマ管理」といった信頼性機能を追加。これにより、データレイクでもデータウェアハウス並みの安全性を実現しました。 - Lakehouse(レイクハウス):
2020年にDatabricksが提唱したデータレイクの「柔軟性・低コスト」とデータウェアハウスの「高性能・高信頼性」を融合した新しいアーキテクチャの概念。業界に大きな影響を与えた設計思想です。 - Databricks(データブリックス):
レイクハウス技術を基盤として、機械学習(ML)、ビジネスインテリジェンス(BI)、データエンジニアリング(ETL)を統合した包括的なクラウドプラットフォーム。データ分析からAI開発まで、全てのワークロードを単一環境で実行できます。
Databricksの使命と成り立ち
Databricksは、2013年に設立されたアメリカの企業で、企業が持つ大量のデータを簡単に活用できるようにするクラウドサービスを提供しています。「データとAIの民主化」をコアビジョンに掲げ、これまで専門家しか扱えなかった複雑なデータ分析やAI開発を、普通のビジネスパーソンでも使えるようにすることを目指しています。
同社の技術的な信頼性は、その学術的な出自に深く根ざしています。カリフォルニア大学バークレー校のAMPLabでApache Sparkを開発した研究者チームが創業し、このApache Sparkという革新的なデータ処理技術を商業的に発展させたのがDatabricksの始まりです。(出典: Databricks公式サイト)
市場での驚異的な評価
2024年12月のシリーズJラウンドでは、会社の評価額が620億ドル(約9兆円)に達しました。(出典: Databricks公式発表)
その後も資本政策は継続しており、2025年末には評価額が1,340億ドル水準に到達したとの報道もあります(発表・報道ベース)。こうした評価額は市場環境で変動しうるため、「時点を揃えて比較する」のがフェアです。
なお、時価総額は時点で変動しますが、Snowflake社の時価総額と比較する場合も、同一時点で揃えた上で判断するのが適切です。[出典]
また、売上指標は年換算売上(revenue run-rate)として語られることが多く、2024年6月時点で3.7B規模に達する見込みと報じられました。こうした数値は、その後の公式発表・開示によって順次アップデートされていきます。(出典: CNBC)
Apache Sparkとは
Apache Sparkは、従来のHadoop MapReduceに代わる高速なビッグデータ処理エンジンです。特に、メモリ上でデータを処理する「インメモリ・コンピューティング」により、MapReduceに比べて最大100倍の速度向上が可能とされています。
たとえば、100TBのデータ処理を行う場合、MapReduceでは数時間かかっていた処理が、Sparkでは数分で完了することもあります。
この技術は、カリフォルニア大学バークレー校のAMPLabで開発され、Databricks社によって商用化されました。現在ではNetflix、Uber、Facebookなど、世界中の企業で活用されています。
出典: Databricks公式「About Spark」
これらの基本的な理解を踏まえて、次章ではなぜDatabricksがこれほど高く評価され、業界の注目を集めているのかについて、その革新的な技術とビジネスアプローチを詳しく解説していきます。
なぜDatabricksが注目されているのか
Databricksの評価を決定づけた革新的な「レイクハウス」アーキテクチャと、業界標準を確立したオープンソース戦略、そして顧客にデータの所有権を残すという画期的なビジネスモデルを解説します。
革新的な技術「レイクハウス」の開発
従来、企業はデータを保存・活用する際に2つの選択肢しかありませんでした:
- データウェアハウス:決まった形式の構造化データを高速で分析できるが、コストが高く、決められた用途にしか使えない
- データレイク:あらゆる形式のデータを安く保存できるが、データの品質管理が難しく、使いこなすのが困難
Databricksが「Lakehouse」として提唱・普及させたレイクハウスは、この2つの良いところを組み合わせた次世代の設計思想です。安いコストで大量のデータを保存しながら、高品質で高速な分析も可能にします。
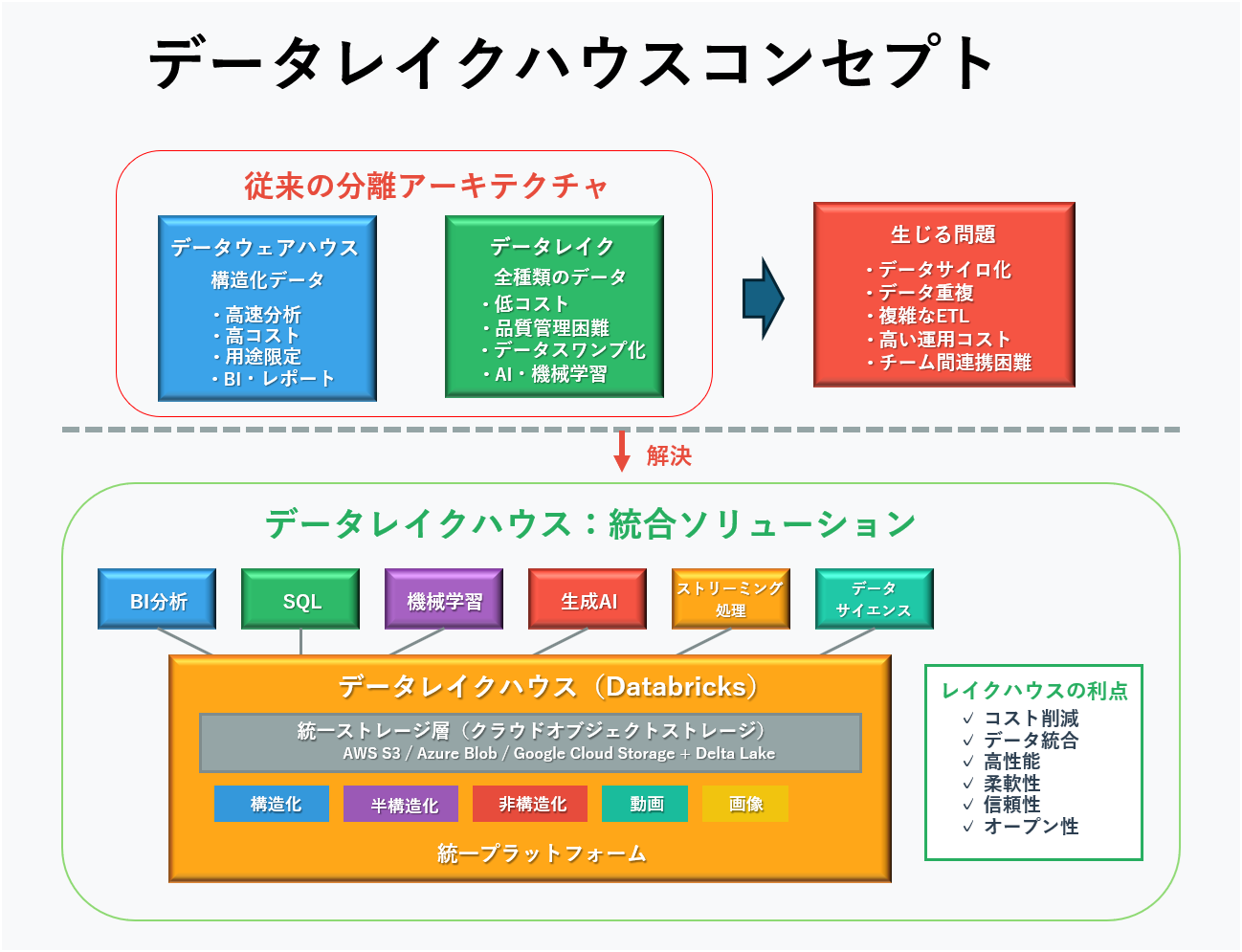
レイクハウスが解決する根本的な問題
従来の企業では、BIやレポーティング用のデータとAI・機械学習用のデータが別々のシステムに保管されていました。この分離により深刻なデータサイロが生まれ、以下のような問題が起きていました:
- データの重複による保存コストの無駄
- ETL処理の複雑化によるシステム構築・運用コストの増大
- チーム間でのデータ共有困難による同じ分析の重複実施
- 分析対象データの陳腐化による意思決定の精度低下
レイクハウスは、構造化・半構造化・非構造化といったあらゆる種類のデータを単一のプラットフォームで管理し、SQL分析、BI、データサイエンス、機械学習、ストリーミング処理といった全てのワークロードを同じデータ上で実行できるようにしました。
| 項目 | データウェアハウス | データレイク | レイクハウス |
|---|---|---|---|
| 対応データタイプ | 構造化データのみ | 全種類(品質管理困難) | 全種類(品質管理可能) |
| 処理速度 | 高速 | 低速 | 高速 |
| コスト | 高い | 安い | 安い |
| 主な用途 | BI・レポート | AI・機械学習 | 全ワークロード統合 |
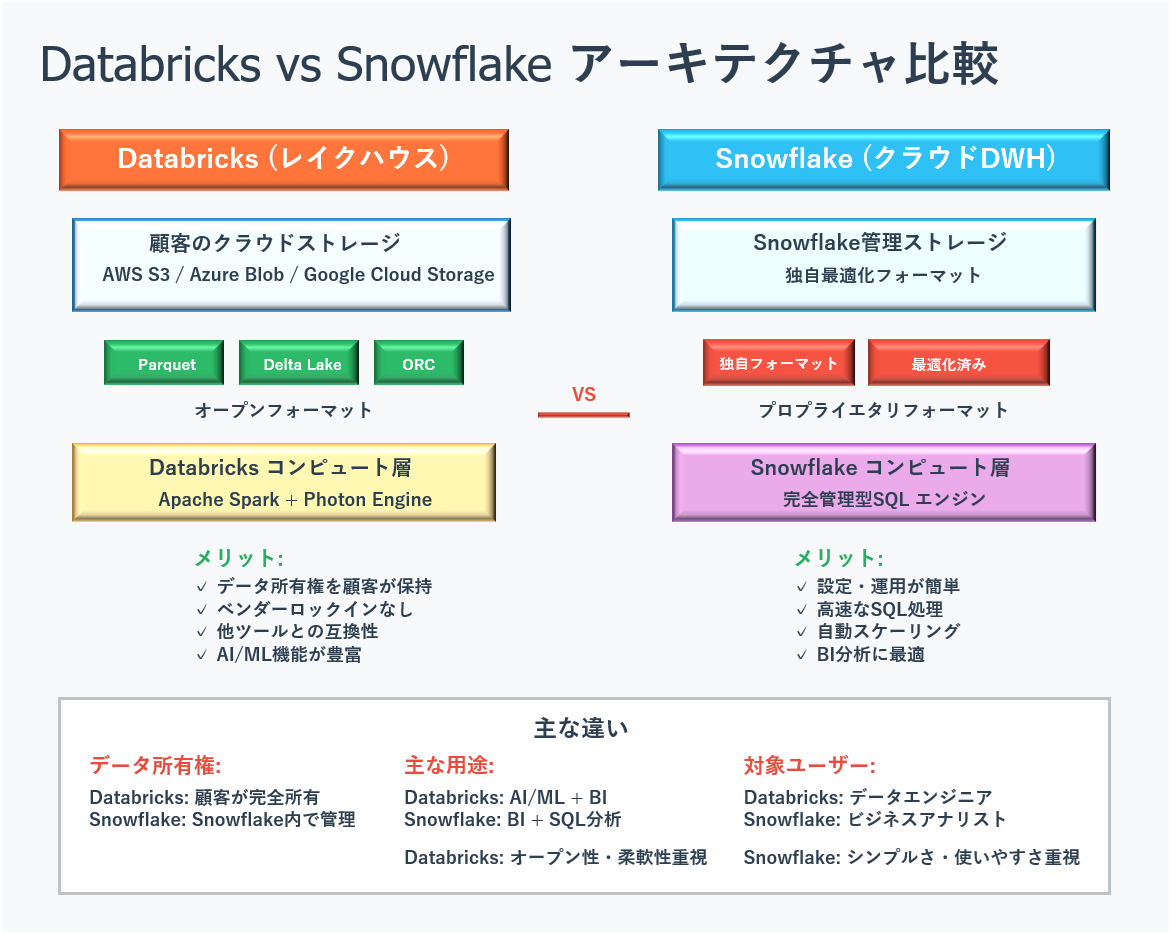
オープンソース戦略による業界標準の確立
Databricksは自社の技術をオープンソースとして公開し、世界中の開発者コミュニティと協力して技術を発展させています。Apache Spark、Delta Lake、MLflowといった基盤技術を開発・公開することで、有料顧客になる前の段階から多くの開発者がDatabricksの技術に習熟し、巨大なコミュニティが形成されます。
その結果、これらの技術は業界のデファクトスタンダードとしての地位を確立し、企業が本格導入を検討する際には、最も自然で信頼性の高い選択肢となります。この「コミュニティ主導の成長」モデルは、強力かつ自己強化的なセールスファネルを構築すると同時に、プロプライエタリな技術に依存する競合他社に対する強力な堀(moat)となっています。
データの所有権を顧客に残す画期的なアプローチ
他の多くのサービスでは、データを使うために専用のシステムにデータを移す必要があります。一度移すと、他のシステムに移行するのが困難になるベンダーロックインという問題が起きます。
Databricksのアプローチはこれと対照的です。顧客のデータは顧客自身のクラウドストレージ(AWS S3、Azure Blob Storage、Google Cloud Storage)にApache ParquetやORCといったオープンなファイルフォーマットで保存され、Databricksはその上でコンピュート処理やガバナンス機能を提供します。
このデータとコンピュートの分離アーキテクチャにより、以下のメリットが生まれます:
Databricksの技術的特徴を詳しく解説
プラットフォームの強さを支える「メダリオンアーキテクチャ」「Delta Lake」「Unity Catalog」、そしてAI開発機能「Mosaic AI & MLflow」といった核心技術の仕組みと利点を解説します。
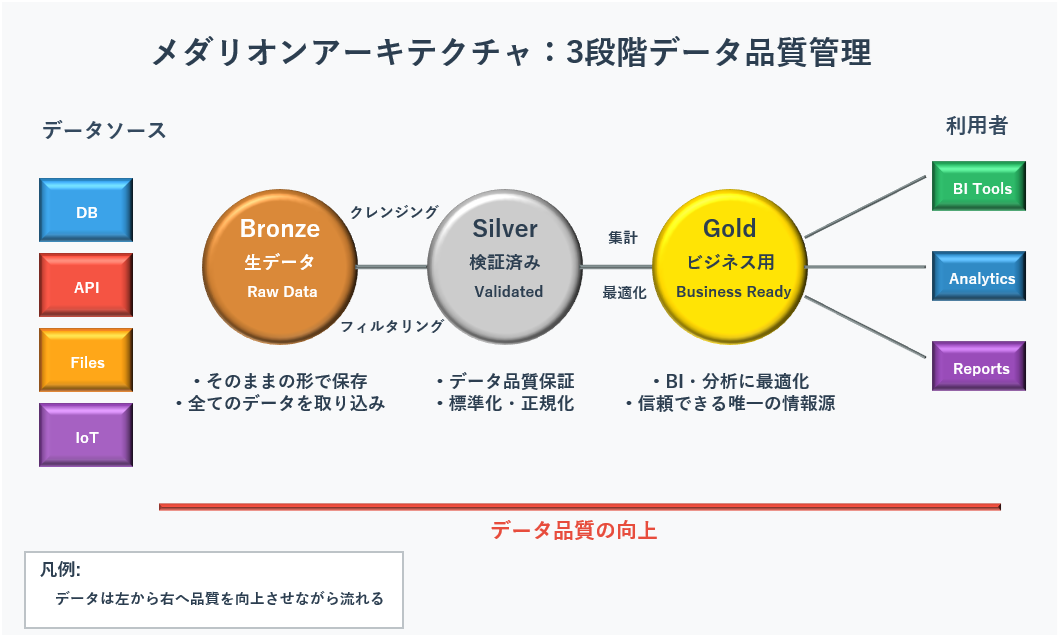
メダリオンアーキテクチャ:データ品質の3段階管理
Databricksでは、データを品質に応じて3段階で管理するメダリオンアーキテクチャという仕組みを採用しています。これは、レイクハウスを実践的に実装するための設計パターンとして広く採用されています。
- ブロンズテーブル:様々なソースから集めた生データをそのまま保存する層
- シルバーテーブル:ブロンズのデータをクレンジング、フィルタリング、エンリッチメントして、検証済みの状態に加工した層
- ゴールドテーブル:シルバーのデータをビジネス要件に合わせて集計し、BIや分析レポートに最適化した層
この多段階のアーキテクチャにより、データはパイプラインを通過する過程で段階的に品質が向上し、最終的にはSingle Source of Truthが提供されます。
Delta Lake:データレイクに信頼性をもたらす革新技術
Delta Lakeは、データレイクハウスを実現する核心的な技術で、データレイクにデータウェアハウスのような信頼性をもたらすオープンソースのストレージレイヤーです。
Delta Lakeの主要機能
- ACIDトランザクション:複数のユーザーやプロセスが同時にデータの読み書きを行う際に、データの完全性と一貫性を保証
- スキーマエンフォースメント:データ書き込み時にスキーマを強制し、意図しないデータの混入を防止
- スキーマエボリューション:ビジネスの変化に合わせてスキーマを柔軟に変更することが可能
- タイムトラベル機能:テーブルへの全ての変更履歴が自動的にバージョン管理され、過去の任意の時点のデータを照会可能
これらの機能により、従来はデータウェアハウスでしか実現できなかったエンタープライズグレードの信頼性を、低コストなデータレイク上で実現できます。
| 機能 | 従来のデータレイク | Delta Lake | ビジネス価値 |
|---|---|---|---|
| データ品質保証 | なし | スキーマ強制 | 分析結果の信頼性向上 |
| 同時アクセス | データ破損リスク | ACID保証 | チーム協業の安全性 |
| 履歴管理 | 手動実装が必要 | 自動バージョン管理 | 監査・コンプライアンス対応 |
| エラー対応 | 復旧困難 | タイムトラベル機能 | 迅速な問題解決 |
プラットフォームの主要機能
Databricks SQL:BIワークロードへの本格参入
Databricks SQLは、BIや分析レポート作成といった従来のデータウェアハウス系ワークロードを、レイクハウス上で本格的に回すために設計されたサーバーレスのSQL実行基盤です。
高性能クエリエンジン「Photon」などの高速化により、DatabricksはAI/MLだけの基盤から、分析(BI/SQL)も含めた総合データ基盤へと守備範囲を広げました。TableauやPower BIなど主要BIツールとの連携が可能な点も、意思決定の現場での採用を後押しします。
Unity Catalog:統一ガバナンスの実現
Unity Catalogは、テーブル、ファイル、機械学習モデル、ダッシュボードといった、あらゆるデータとAI資産を複数のクラウドにまたがって一元的に管理するための統一ガバナンスレイヤーです。
主な機能:
- きめ細かなアクセス制御:行レベル・列レベルでの権限設定
- データリネージの自動追跡:データの流れと依存関係を可視化
- 監査ログ:全てのデータアクセスを記録・追跡
- クロスクラウド対応:AWS、Azure、GCP間でのデータ共有
Mosaic AI & MLflow:エンドツーエンドのAI開発支援
DatabricksのAI・機械学習における能力は、競合他社に対する大きな差別化要因です:
- MLflow:実験の追跡からモデルのパッケージング、本番環境へのデプロイ、運用監視まで、機械学習のライフサイクル全体を管理するオープンソースプラットフォーム
- Mosaic AI:MosaicMLの買収(出典)によって強化された生成AI関連機能の統合ブランド。企業データを前提に、LLM/RAGの構築〜運用(学習・評価・デプロイ・ガバナンス)を一体で進めやすくする方向へ機能が拡張されています
- DBRX:自社開発したオープンソースLLM。公開ベンチマークではGPT-3.5クラスに近い水準とされ、タスクによっては上回る例も報告されています(評価軸はベンチマークに依存します)。(出典: Databricks公式ブログ)
驚異的な成長を遂げる財務状況
急成長を続ける売上と、巨大テック企業も認める高い評価額を解説。市場の注目を集めるIPO(株式公開)への道筋と、その資金戦略に迫ります。
急成長する売上と投資家からの高い評価
Databricksの財務成長は、その技術力を裏付ける説得力のある数字を示しています。
Microsoft、Google、AWS、NVIDIAといった巨大テック企業からの戦略的投資も受けており、業界全体での重要性が認められています。特に、NVIDIAが参加したシリーズIや、Thrive Capitalが主導したシリーズJは、AIブームの中心で同社が果たす役割への高い期待を反映しています。
IPOへの道筋
市場では、DatabricksがIPO候補として有力視されており、2025〜2026年にかけてタイミングが取り沙汰されています。もっとも、上場時期は市場環境や資本政策の影響を受けるため、ここでは「候補」として捉えるのが適切です。
CEOのアリ・ゴディシは、市場の不確実性を理由に2024年のIPOを見送ったと公言しており(出典: Bloomberg)、これは同社が最適なタイミングを慎重に見計らっていることを示しています。
2024年のシリーズJラウンドには従業員が保有株を売却できるセカンダリー取引が含まれており、これはIPOを待たずに従業員に流動性を提供する「プライベートIPO」としての機能を持っていました。同時に、調達した巨額の資金は、Tabularのような戦略的買収(出典)の原資となり、競争力をさらに強化するための「軍資金」となっています。
競合他社との比較:DatabricksとSnowflakeの違い
データ基盤市場の2大巨頭、DatabricksとSnowflake。両社の思想的な違いから、得意分野、適用シーン、そしてどのような企業がどちらを選ぶべきかまでを、機能比較表を交えて詳しく解説します。
基本的なアプローチの違い
Databricks(オープンレイクハウス方式)
- データは顧客のクラウドストレージに標準的なオープンフォーマットで保存
- 「オープン性」と「コントロール」を重視
- データエンジニアやデータサイエンティストなど技術的な専門家向け
Snowflake(管理型クラウドDWH方式)
- データをSnowflakeが管理するストレージ層(管理型)に取り込み、最適化して提供
- 「シンプルさ」と「使いやすさ」を重視
- データアナリストやビジネスユーザーなど、SQLスキルを持つ非技術者向け
機能別詳細比較
| 項目 | Databricks | Snowflake |
|---|---|---|
| コアアーキテクチャ | オープンレイクハウス(顧客のクラウドストレージにオープンフォーマットで保存) | クラウドネイティブDWH(Snowflake管理ストレージに独自フォーマットでロード) |
| 対応データタイプ | 構造化・半構造化・非構造化データをネイティブサポート | 主に構造化・半構造化データ(非構造化も対応拡大中) |
| 主要ワークロード | データエンジニアリング、ML、生成AI、ストリーミング処理、BI | BI、SQL分析、レポーティング(Snowparkでデータサイエンスにも対応) |
| ターゲットユーザー | データエンジニア、データサイエンティスト、MLエンジニア中心 | データアナリスト、ビジネスユーザー中心 |
| データ所有権 | 顧客が完全所有・管理(ベンダーロックインリスク低) | Snowflakeプラットフォーム内で管理(移行時の制約あり) |
| AI・ML機能 | MLflow、Mosaic AIなど統合ネイティブ機能 | Snowpark APIやサードパーティ連携 |
| データ共有 | Delta Sharing(オープンプロトコル、プラットフォーム問わず) | Snowflake Marketplace(主にSnowflakeアカウント間) |
| 価格モデル | クラスタ設定ベースの従量課金(柔軟だが管理複雑) | ストレージ・コンピュート使用量ベース(シンプル) |
得意分野と適用シーン
Databricksが優位な分野
- データサイエンス・機械学習:ネイティブなMLOps環境
- 大規模データ処理:ペタバイト級データの効率的処理
- 非構造化データ活用:画像、動画、テキストデータの統合処理
- ストリーミング処理:リアルタイムデータパイプライン
- 生成AI開発:LLMの構築・ファインチューニング
- 価格性能比:大規模処理でのコスト効率
Snowflakeが優位な分野
- BI・SQL分析:ビジネスユーザー向けの直感的操作
- インタラクティブクエリ:アドホック分析の高速実行
- 設定の簡単さ:すぐに使い始められる
- データ共有エコシステム:成熟したMarketplace
- 運用管理:自動チューニング・メンテナンス
選択の判断基準
Databricksを選ぶべき企業
- AI・機械学習を本格的に活用したい(独自LLM/RAGの運用コストも含めて最適化したい)
- マルチクラウド戦略を採用している
- ベンダーロックインを避けたい
- 高度なプラットフォームを管理できる技術的人材がいる
- 大量の非構造化データを扱う
- リアルタイムストリーミング処理が必要
Snowflakeを選ぶべき企業
- 主にBI・レポート作成が目的
- 設定や管理を簡単にしたい
- SQLに慣れたアナリストが多い
- 技術的な専門知識が限られている
- 構造化データ中心の分析
- すぐに成果を出したい
大手クラウド企業との関係
AWS、Microsoft Azure、Google Cloud。巨大クラウド企業と競合しつつも、深く協業する「Coopetition(協争)」という独特な関係性と、その戦略的な価値を解説します。
「協争」(協力と競争の両立)
これらの企業は、AWS Redshift、Google BigQuery、Azure Synapse Analyticsといった自社でもデータ分析サービスを提供しているため、Databricksと競合関係にあります。同時に、Databricksが各社のクラウド基盤上で動作する重要なパートナーでもあります。
特にMicrosoft Azureとは深い協力関係にあり、「Azure Databricks」としてAzureのファーストパーティサービスに完全に統合されています。Google Cloudとも戦略的パートナーシップを結び、BigQueryやGoogle Kubernetes Engineとの連携を強化しています。
マルチクラウド対応の戦略的価値
Databricksの最大の価値提案は、どのクラウドでも一貫したデータ・AI戦略を展開できることです。企業は特定のクラウドプロバイダーのエコシステムにロックインされることを回避でき、柔軟性と将来の選択肢を保てます。
これは、データとAIが企業の戦略的資産となる中で、ベンダーの選択肢を維持したい大規模なエンタープライズにとって、非常に強力なメッセージとなっています。
まとめ: DatabricksとSnowflake、どちらを選ぶべきか
本記事では、DatabricksとSnowflakeの基本アーキテクチャ、機能比較、選定基準、コストまで包括的に解説しました。
結論:
- Databricksは、AI/ML開発、リアルタイム分析、非構造化データ処理に強く、オープンなLakehouse設計でマルチクラウド戦略に最適。データエンジニア・データサイエンティスト中心の組織に推奨。
- Snowflakeは、BI/SQL分析、レポート作成に特化し、管理が容易で非技術者にも使いやすい。ビジネスアナリスト中心の組織やクイックスタート重視の場合に推奨。
今後の展望:
- AI時代の加速: Databricksは生成AI(Mosaic AI)、Snowflakeは Cortex AI を強化中。AI統合が選定の重要ポイントに。
- ハイブリッド戦略: 両プラットフォームを併用し、用途別に使い分ける企業が増加中(例: BI/SQL→Snowflake、AI/ML→Databricks)。特に2026年は、最初から共存を前提に「データの置き方/ガバナンス/責任分界」まで設計するケースが目立ちます。
- オープンスタンダード: Delta Lake、Apache Iceberg等のオープンフォーマットがベンダーロックイン回避の鍵。
最終アドバイス: どちらか一方に固執せず、自社のデータ戦略・技術スタック・予算を総合的に評価し、柔軟に選択・組み合わせることが成功への近道です。
詳細な実装ガイドは、DatabricksでRAG実装ガイド および Databricks AI開発プラットフォーム完全ガイド をご参照ください。
💡 この記事の持ち帰りポイント(3つのアクション)
- 自社の用途を明確化: AI/ML開発 vs BI/SQL分析、どちらが中心かを整理する。
- 選定基準マトリクスを作成: コスト、マルチクラウド要件、技術チームのスキルセットを比較表にまとめる。
- スモールスタート: どちらか一方で小規模プロジェクトを試行し、フィードバックを基に本格導入を検討する。
次のステップ: DatabricksでRAG実装ガイド で実践的な構築手順をご覧ください。
よくある質問(FAQ)
Q1. DatabricksとSnowflakeの最大の違いは?
アーキテクチャの違いが最も顕著です。
- Databricks: オープンなLakehouse(Delta Lake)でストレージとコンピューティングを分離。Spark/MLベースでAI/ML開発に強い。
- Snowflake: 管理型のData Warehouse。SQL/BI分析に最適化。運用が容易な一方、移行時には設計・運用上の制約が発生する場合がある。
詳細は基本アーキテクチャセクションをご覧ください。
Q2. どちらを選ぶべき?選定基準は?
| 選定基準 | Databricks推奨 | Snowflake推奨 |
|---|---|---|
| 主な用途 | AI/ML開発、リアルタイム分析、非構造化データ処理 | BI/SQL分析、レポート作成、構造化データ中心 |
| 技術チーム | データサイエンティスト、ML Engineerが多い | BIアナリスト、SQLユーザーが中心 |
| マルチクラウド | AWS/Azure/GCP全対応、オープン標準 | 管理型アーキテクチャ(対応は進むが、設計上のロックイン要因は要確認) |
| コスト | 初期コスト高め、運用チューニングで最適化可能 | 従量課金でシンプル、管理コスト低い |
詳しくは選定基準をご参照ください。
Q3. コストはどちらが安い?
用途とスケールによって異なります。
- 小規模・SQL中心 → Snowflake が割安(管理コスト込み)
- 大規模・AI/ML中心 → Databricks がコンピュート効率で優位
- 注意点: Snowflakeは従量課金が明瞭だが大規模になると高額。Databricksはチューニング次第でコスト削減可能。
Q4. Databricks Unity CatalogとSnowflake Data Governanceの違いは?
どちらも企業レベルのデータガバナンス機能を提供しますが、アプローチが異なります。
- Databricks Unity Catalog: マルチクラウド対応、Delta Sharingでセキュアなデータ共有。オープン標準で拡張性高い。
- Snowflake Data Governance: Snowflake内で統合的に管理しやすく、UI/UXが洗練されており、非技術者にも扱いやすい。
詳しくはUnity Catalogセクションで解説しています。
Q5. マイグレーションは可能?リスクは?
技術的には可能ですが、コスト・工数・リスクを慎重に評価すべきです。
| 移行方向 | 難易度 | 主なリスク |
|---|---|---|
| Snowflake → Databricks | 中〜高 | SQLクエリの書き換え、Spark学習コスト、パイプライン再構築 |
| Databricks → Snowflake | 中 | Sparkジョブの再実装、ML機能の代替ツール選定 |
推奨アプローチ: ハイブリッド運用でリスク分散 → 段階的移行 → 最終統合。
参考サイト・出典
- Databricks公式サイト
- Snowflake公式サイト
- Delta Lake公式ドキュメント
- Apache Spark公式サイト
- CNBC: Databricks annualized revenue (2024-06)
- Companies Market Cap: Snowflake時価総額データ
- Azure Databricks: Unity Catalog 概要(公式ドキュメント)
- Snowflake Blog: Cortex AI発表 (2024)
- Gartner: Cloud Database Management Systems Magic Quadrant
- AWS: Data Lakes and Analytics
あわせて読みたい
更新履歴
- 2026-02-17: 最新市場データ(評価額・時価総額の比較)を追加。Unity Catalogに関するセクションの出典整合を実施。FAQ 5問を追加。「評価額(2025年12月報道)/run-rate(同時点報道)を追記」など “どの数字を、どの時点の報道で” を明記。
- 2025-07-04: Databricks v2024.7リリースに対応。Mosaic AI、Unity Catalog機能強化を反映。コスト比較セクションを更新。
- 2025-01-01: 初版公開。Databricks vs Snowflakeの基本比較、アーキテクチャ解説、選定基準、コスト分析を網羅。
以上








