


AIエージェント開発の次へ。なぜDatabricksが「AI時代のOracle」と呼ばれるのか
RAG(Retrieval-Augmented Generation)を活用したAIエージェント開発は、今や多くのシステム開発企業にとって中心的な事業となりつつあります。しかし、経験豊富な開発者であれば、現在のアプリケーション層での開発手法だけでは、いずれ限界が訪れることに既に気づかれているかもしれません。本当の競争優位性は、そのAIがどれだけ深く、速く、多様なデータと連携できるかにかかっています。
1970年代後半、Oracleがデータベースの標準を確立したように、今、AI時代の新たなデファクトスタンダードが生まれつつあります。その先頭を走っているのがDatabricksです。事実、2025年時点で年間収益は37億ドルに達する見込みで、Fortune 500企業の60%以上が導入済み。AWS、Azure、Google Cloudという主要クラウド全てが標準サービスとして採用しており、「まずDatabricksを検討する」という状況が、グローバル企業の技術選定において生まれています。
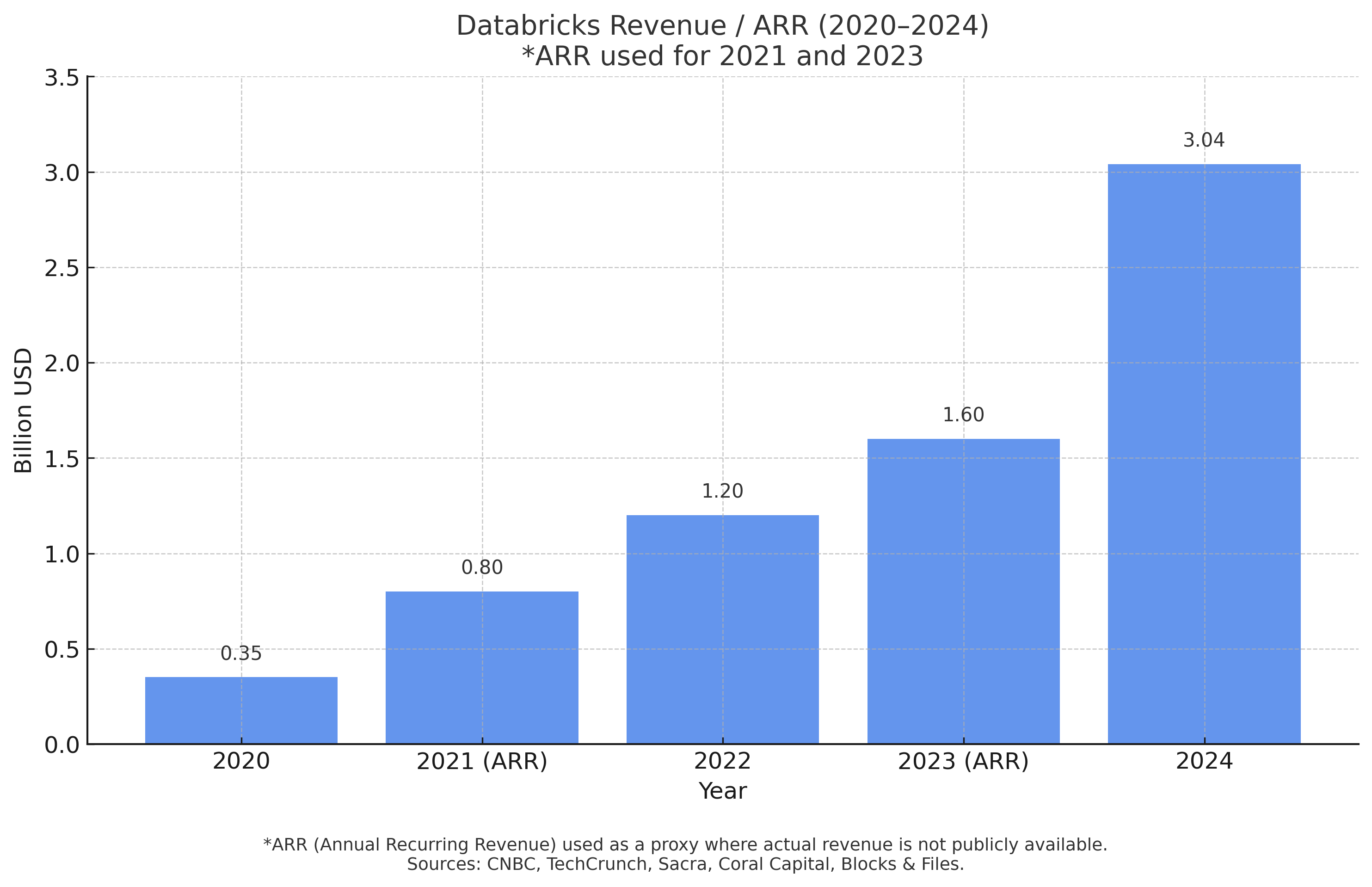
このグラフは、Databricks社の収益が近年、加速度的に増加している事実を示しています。エンタープライズビジネスにおけるこの急成長は、多くの大企業が同社の技術を一過性のブームとしてではなく、事業の根幹を支える「次世代の標準インフラ」として本格的に採用・投資していることの客観的な証拠と言えます。
Databricksの模倣困難性:なぜ他社は追随できないのか
優れたプラットフォームであれば、「なぜ他のIT大手がすぐに同様の製品を開発できないのか」という当然の疑問が湧きます。その答えは、企業の成り立ち(DNA)と、製品の根本的な設計思想の違いにあります。
多くの従来型データ基盤ベンダーは、「データを綺麗に保管し、後から集計・分析する」という目的、いわば「金庫番」としての役割から発展しました。
これに対し、Databricksは、「形式を問わないあらゆる生データを、リアルタイムに処理・加工する」という目的、すなわち「AI開発工場(ラボ)」としての役割から生まれました。
その心臓部となるのが「Apache Spark」です。この技術は、後にDatabricksを創設するマテイ・ザハリア氏らが、カリフォルニア大学バークレー校のAMPLabで開発し、2010年にオープンソース化したもので、MapReduceの10倍以上という処理速度を誇ります。
競合他社比較(定性的概要)
- Databricks: AI開発に特化した統合プラットフォーム。MLOps、リアルタイム処理、非構造化データ処理で圧倒的優位。
- Snowflake: データウェアハウス領域で強みを持ち、AI/ML機能も段階的に拡充している。
- BigQuery: Googleエコシステム内では強力だが、マルチクラウド対応とAI開発の統合度に課題。
- Redshift/Synapse: 各クラウドの従来型DWHがベース。AI時代の要件への対応が限定的。
既存スキルが最強の武器になる
Databricksは、SQLやPythonといった普遍的なスキルを最大限に活かせるよう設計されており、これまでに培った開発経験をそのまま価値として発揮できるプラットフォームです。
100%活用できる既存スキル
Databricksは、特定の言語やツールに閉じられた世界ではなく、皆さんがこれまで培ってきた幅広い技術資産を最大限に活用できるオープンプラットフォームです。
プログラミング言語
- SQL:
データ分析、変換、ETL処理の多くを、使い慣れたSQLで記述できます (Databricks SQL)。 - Python:
データ処理、API開発、AIモデル構築など、あらゆる場面で中心的な役割を果たします。 - Java / Scala:
Apache SparkはJVM上で動作するため、パフォーマンスが求められる大規模なデータ処理ジョブや、既存のJava資産と連携する機能を開発する際に、これらの言語の知見を直接活かせます。 - R:
統計解析やデータ可視化の分野で標準的に使われるRも、Databricks Notebook上でネイティブにサポートされており、RStudioとの連携も可能です。
フレームワーク・ライブラリ
- AI / 機械学習フレームワーク (TensorFlow, PyTorch, scikit-learnなど):
これらの標準的なライブラリはDatabricks Runtimeにプリインストールされており、追加の設定なしでモデルの学習や推論を実行できます。MLflowとの連携もスムーズです。 - Web開発 (フロントエンド / バックエンド):
ReactやNext.js、Flutter等で作成したフロントエンドに対し、そのバックエンド(Spring Boot, Django等)からDatabricksに接続してデータを返すAPIを構築します。この一連のWeb API開発の知識や作法は、Databricks利用時でも全く同じです。
プラットフォーム・ツール
- データベース設計・運用:
正規化やテーブル設計、インデックスの考え方といったRDBMSの基本概念は、Delta Lakeのパフォーマンスチューニングにおいても同様に重要です。 - BIツール (Tableau, Power BIなど):
各社BIツールとは最適化されたコネクタで接続可能です。使い慣れたツールで、Databricks上の大規模データに対する高速な可視化・分析を実現できます。 - CI/CDツール (Jenkins, GitHub Actionsなど):
Databricksの各種設定(ジョブ、クラスタ等)はコードで管理(IaC)できるため、既存のCI/CDパイプラインに組み込んで、開発・デプロイのプロセスを自動化できます。 - クラウドプラットフォーム (AWS, Azure, GCP):
現在お使いのクラウドに関する知識(ストレージ、ネットワーク、IAM管理など)は、Databricks環境の運用にそのまま活かすことができます。
Databricks習得の勘所:新たに学ぶべき3つのコンセプト
- Sparkの基本概念:大規模データを分散処理するという目的はMapReduceと同様です。ただし、メモリ内処理を最大限活用することで、MapReduce比で10倍以上高速に動作すると理解すれば十分です。
- Delta Lake:信頼性と高速性を両立した次世代のデータ保存形式。ACIDトランザクションやタイムトラベル(過去のデータ復元)といった強力な機能を持ちます。
- MLflow:AIモデルのバージョン管理ツール。誰が、どのデータで、どのコードを実行し、どんな性能のモデルができたかを自動で記録する、「AI版Git/GitHub」です。
このように、Databricksは「全く新しい異質な技術」ではなく、「既存技術の正統進化版」という位置づけとなります。
RAG開発の課題と、Databricksによる解決策
RAG開発の本当のボトルネック:データパイプライン
RAG開発が直面する、データに関する2つの大きな壁は以下の通りです。
- 課題① 多様なデータの前処理:
PDF、Word、ログ、音声といった形式の異なる膨大な非構造化データを、AIが読めるように整理し、ベクトル化するパイプラインの構築は非常に複雑で、多くの開発リソースを消費します。 - 課題② 継続的なメンテナンス:
新しい情報の追加や既存情報の更新のたびに、手動でベクトルDBを同期させる運用は非現実的です。この差分管理と自動更新の仕組みがないと、システムはすぐに陳腐化します。
Databricksは、これらの課題をプラットフォームレベルで解決します。
Auto LoaderとDelta Live Tables (DLT) が連携し、ストレージ内の新規・更新ファイルを検知して、データを自動的に引き込み、前処理、ベクトル化までを一気通貫で実行。
開発者は一度パイプラインを「宣言」するだけで、あとはデータの発生に応じて自動で処理が実行されるため、複雑なスクリプト開発や運用管理から解放されます。
開発フローの比較:手作業の連鎖から、自動化されたパイプラインへ
では、これらの課題を解決するため、従来の手法と新しいアプローチでは開発フローがどのように変わるのでしょうか。具体的な手順を並べて比較し、その本質的な違いを見ていきましょう。
| 従来の手法(スクリプトの連鎖) | Databricksの手法(自動化パイプライン) |
|---|---|
| 1. 手動でファイルをアップロード 2. Cron等でPythonスクリプトを定期実行 3. スクリプト内でファイル読込、チャンク分割、ベクトル化 4. ベクトルDBへAPIで書き込み 5. 更新・削除は別途考慮が必要 6. エラー処理、リトライも自前で実装 |
1. 指定フォルダにファイルが追加されるのを自動検知 (Auto Loader) 2. データの追加をトリガーに、チャンク分割、ベクトル化、インデックス更新までを一気通貫で自動実行 (Delta Live Tables) 3. エラー処理、品質チェックも宣言的に定義するだけ |
実装コードの比較:数十行のスクリプト vs 宣言的なパイプライン定義
このフローの違いは、実装コードに如実に表れます。
▼一般的なRAGの実装(LangChain等)
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
# 1. ドキュメント読み込み
loader = PyPDFLoader("manual.pdf")
documents = loader.load()
# 2. テキスト分割
text_splitter = CharacterTextSplitter(chunk_size=1000)
docs = text_splitter.split_documents(documents)
# 3. ベクトル化してローカルに保存
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
db.save_local("faiss_index")
# これを定期実行する仕組みが別途必要
▼DatabricksでのRAG実装(DLT + Vector Search)
-- DLTパイプラインとして一度定義するだけ
CREATE OR REFRESH STREAMING LIVE TABLE documents
AS SELECT * FROM cloud_files("/path/to/raw_pdfs", "pdf");
@dlt.table
def chunks():
return (
dlt.read_stream("documents")
.select(split_text("content").alias("chunk"))
);
-- Vector Search Indexは作成すれば自動で同期
CREATE VECTOR SEARCH INDEX my_index
ON chunks (chunk)
USING DELTA_SYNC;
DataBricksのチャンキングの部分の逐次解説
@dlt.table:
これはPythonのデコレータと呼ばれる目印です。「このPython関数(chunks)は、データパイプラインを構成する一つのテーブル(データセット)を定義します」とDatabricksに宣言しています。dlt.read_stream("documents"):
パイプライン内でのデータの流れを定義する部分です。ステップ1で定義したdocumentsテーブルから、新しく追加されたデータをストリームとして読み込みます。これにより、新しいPDFデータが到着すると、このチャンキング処理が自動的に開始される仕組みが作られます。.select(split_text("content").alias("chunk")):
実際のデータ処理を行っている部分です。documentsテーブルに含まれるPDFのテキスト内容(content列)を、split_textという関数を使って、AIが扱いやすい小さなテキストの塊(チャンク)に分割しています。そして、その分割されたチャンクをchunkという名前の新しい列として出力しています。
このように一般的な手法が、その場限りの手続き的なスクリプトの連なりであるのに対し、Databricksでは宣言的なパイプラインとして定義するだけで、データの追加・更新に自動で追従する、本番レベルの信頼性と拡張性を持つシステムが構築できます。
マルチテナントRAGにおけるセキュリティとデータガバナンス
クライアント向けのシステム開発では、「クライアントAのデータが、クライアントBの検索結果に絶対に混じらない」といった、厳格なデータ分離が求められます。従来は、DBインスタンスごと分離する、あるいはアプリケーション側で複雑なアクセス制御を実装する必要がありました。
Databricksでは、この課題をプラットフォームレベルで解決するUnity Catalogという強力なガバナンス機能を提供しています。
Unity Catalogを使えば、物理的には同じテーブルに全クライアントのデータを格納しつつ、
- 特定のユーザーやグループは、特定の行・列にしかアクセスできない(行/列レベルセキュリティ)
- ユーザーの属性(例:「クライアントA担当」)に基づき、データ(例:
client_id = 'A')へのアクセスを動的に制御する(属性ベースのアクセス制御)
といった緻密な制御が可能です。これにより、開発者は複雑なセキュリティロジックを自前で実装する負担から解放され、安全なマルチテナントアプリケーションの構築に専念できます。
次世代AIエージェントの適用事例
データ準備と運用の足枷から解放されたとき、AIエージェントは真の価値を発揮し始めます。静的な知識を応答するだけの存在から、動的なビジネス環境を理解し、自律的に判断する「エージェント」へと進化します。
事例❶:リアルタイム在庫最適化エージェント:
現在の在庫データ、過去の販売トレンド、外部の気象データをリアルタイムで統合分析し、「台風接近に伴い、本日15時にA商品の需要が急増します。近隣店舗の在庫と合わせて、自動で50ケースの移送手配を実行しますか?」と提案する。
事例❷:複合型リスク分析エージェント:
「A社との契約更新におけるリスクを分析せよ」という指示に対し、CRMの商談履歴、ERPの取引データ、サポートセンターの問い合わせ音声までを横断分析し、「先月のサポートコールで担当者B氏の声に不満のトーンが検知されており、解約リスクは75%です」といった人間では不可能なレベルの洞察を提供する。
導入へのロードマップ:今、行動すべき理由
この大きな変化の波に、どう乗るべきか。全社一斉の移行は不要です。以下の3ステップで、低リスクかつ着実に始めることをお勧めします。
ステップ1:小さく試す(~1ヶ月)
無料トライアルで、既存RAG案件の一部を再構築します。データ準備の工数が劇的に削減されることを、まず体感してください。
ステップ2:実案件で武器にする(~3ヶ月)
次の提案から、Databricksを標準スタックとしてください。「データ基盤の自動化により、開発期間を30%短縮し、高機能AIを実現します」という提案は、競合との明確な差別化要因となります。
ステップ3:事業の核に据える(4ヶ月~)
成功事例を基に、「製造業向け予兆保全」「金融向け不正検知」といった業界特化ソリューションを確立します。この段階に至れば、Databricksは貴社の技術的優位性の象徴となります。
Databricks主要用語の解説
この記事で登場したDatabricks関連の用語について、その役割とメリットを簡単に解説します。
- Delta Live Tables (DLT):
データ処理の面倒な部分(処理順序、品質チェック、エラー対応)を、簡単なSQL/Pythonの宣言だけで自動化する、賢いパイプライン構築ツールです。 - Delta Lake:
通常のファイル群にデータベースのような信頼性と高速性を与える、次世代のデータ保存形式です。「ファイルの集まり」を「信頼できるテーブル」として扱えるようにします。 - MLflow:
AIモデル開発における実験記録、バージョン管理、デプロイまでを一元管理する機能です。「AI版のGit/GitHub」とも呼ばれ、開発効率と再現性を向上させます。 - Unity Catalog:
社内のデータやAIモデルに対して、「誰が」「何に」アクセスできるかを一元管理する統合ガバナンス機能です。セキュリティを担保した安全なデータ活用を実現します。 - Databricks SQL:
データ分析者向けに提供される、高速なSQL実行・BI環境です。SQLを知っていれば、誰でも簡単に大規模データ分析やダッシュボード作成が可能です。 - Photon:
Databricksの裏側で動作するクエリ実行エンジンです。ユーザーが意識することなく、SQLなどの処理を自動的に高速化してくれます。
価格・移行に関するよくある質問(FAQ)
▶ コストは本当に安くなりますか?
使用パターンによりますが、多くのAI開発や分析業務ではコスト削減に繋がります。Databricksは「DBU(Databricks Unit)」という処理能力に応じた単位で課金される従量課金制です。24時間稼働が前提のシステムと違い、「必要な時だけクラスターを起動して処理する」という特性に、この課金モデルが完璧にマッチするため無駄がありません。
もちろん、開発期間の大幅な短縮による人件費削減効果も非常に大きいです。
詳細な料金は利用するクラウドやプランによって異なりますので、以下の公式サイトで最新情報をご確認いただけます。
▶ Databricks公式サイト 料金ページ
▶ 既存のSQL Serverからの移行は難しいですか?
▶ 小規模なチームでも導入効果はありますか?
▶ セキュリティ面での懸念はありませんか?
▶ 他のクラウドサービス(AWS、Azure、GCP)との関係はどうなりますか?
主な参考資料
まとめ
この記事では、Databricksが単なるデータ基盤ではなく、AI開発の常識そのものを変える「AI時代のOracle」とも呼べる存在であることを解説しました。
あらゆるデータを一元的に扱い、面倒なデータパイプラインを自動化し、AI開発の全工程を一つの場所で完結させる。この統合された環境こそが、開発チームを本来の創造的な作業に集中させ、次世代のAIエージェントを生み出す原動力となります。
AI開発の主戦場は、もはやモデルの優劣だけではありません。いかに多様なデータをリアルタイムに活用し、ビジネス価値に繋げるかという「データとAIの融合」のステージに移っています。
本記事で解説したDatabricksの統合プラットフォームや思想は、開発チームが直面するデータパイプラインの課題に対する具体的な解決策となります。このような新しい標準技術を適切に評価し、採り入れることが、今後の技術的優位性を築く上で重要な鍵となるでしょう。
以上








