


※本記事はプロジェクトの進行に合わせて継続アップデートされます。
「見て・判断して・動く」を設計する:Behavior CloningからSim2Real・Fine-tuningまでの技術原理【SO-101実装版】
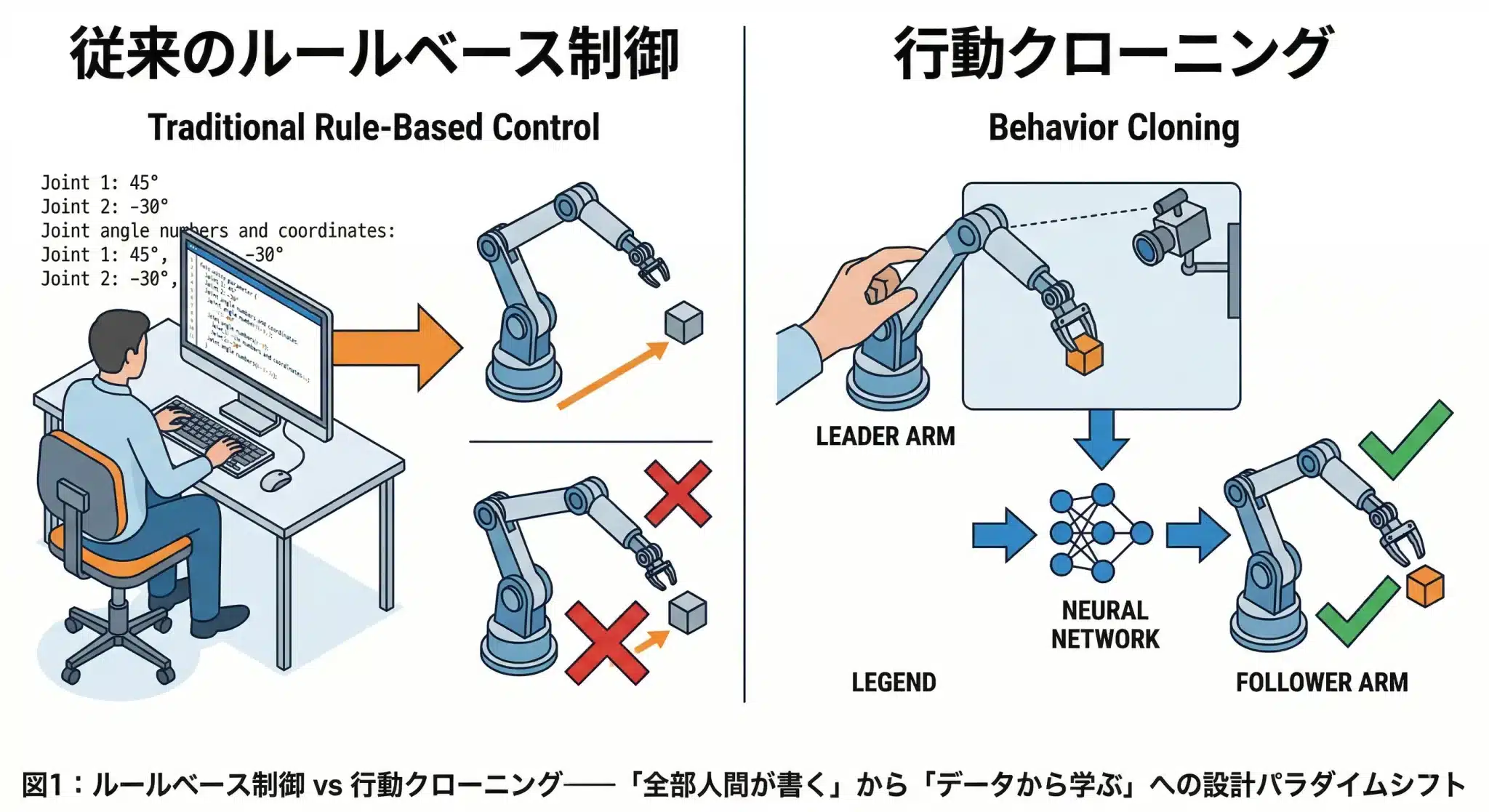
今回挑戦するAIロボットと従来のロボット制御との違いは何だろう?
従来は人間がすべての動作をコードで書いた。新しい設計パターンでは、ロボット自身がカメラ映像から動作を学ぶ。
この一行の意味を理解したとき、Physical AIが「大企業の研究所の話」から「自分たちが設計できる技術」に変わる。
本記事では、SO-101ロボットアームの実装を通じて、Behavior CloningからSim2Real・Fine-tuningに至る技術原理を、誤解ポイントを一つずつ潰しながら丁寧に解説していく。
✅ この記事の結論(TLDR)
- Behavior Cloningとは何か:人間がリーダーアームで動かした「お手本」を、カメラ映像と7軸状態のペアデータとして記録し、「このカメラ映像が来たらこう動く」という変換関数をAIに学習させる手法だ。強化学習とは根本的に異なる。
- Sim2Realへの接続で最大の誤解:Real-to-Realで学習したモデルをシミュレーターに「食わせる」わけではない。食わせるのはSO-101の物理情報(URDF)・タスク定義・成功基準の3つだ。
- Fine-tuningとは何か:Sim2Realで鍛えた「汎化性能の高いモデル」を実機に転送した後、実機で10〜30回だけ追加デモを収集してSim-to-Real Gapを補正する微調整作業だ。
- 2年間の設計原理:Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる。この3段階が「見て・判断して・動く」知能の設計原理だ。
この記事の著者・監修者 ケニー狩野(Kenny Kano)

役職:(株)アープ取締役。Society 5.0振興協会・AI社会実装推進委員長。中小企業診断士、PMP。著書『リアル・イノベーション・マインド』▶ 詳細はこちら
1. 従来設計と何が根本的に違うのか
従来はルールベースで「全部人間が書く」。新設計パターンは「データから学ぶ」。
この違いが設計コスト・汎化性能・開発速度のすべてを変える。
従来のロボットアーム制御を一言で表すと「全部人間が書く」だ。
物体をある位置から別の位置に移動させるだけでも、以下のようなコードを人間が手動で記述する必要がある。
# 従来のルールベース制御の例
IF object_position == (x=120, y=85, z=30):
move_joint(1, angle=35.0)
move_joint(2, angle=-12.3)
move_joint(3, angle=45.7)
move_joint(4, angle=3.1)
move_joint(5, angle=-1.2)
move_joint(6, angle=0.8)
gripper_close(force=0.73)
この設計には致命的な弱点がある。物体が1cmずれていたら、このコードは動かない。
照明が変わって影の出方が変わっても動かない。「想定外」に対して完全に無力だ。
新しい設計パターンの本質は「入力→出力のペアをそのまま学習する」ことだ。人間がお手本を見せ、AIがそのパターンを学ぶ。コードで動作を定義するのではなく、データから動作を導き出す。
2. SO-101の構造を理解する——リーダーとフォロワーの役割
SO-101は2本1セット。リーダーは「データ生成専用」、フォロワーは「学習・推論の実行機」。この役割分担が設計の出発点だ。
SO-101はアームが2本セットで構成されている。それぞれに明確な役割がある。
| アーム | 役割 | 使用フェーズ |
|---|---|---|
| リーダーアーム | 人間が手で動かす「お手本側」。学習データを生成するためだけに存在する。 | データ収集時のみ(学習完了後は不要) |
| フォロワーアーム | 学習・推論の実行機。データ収集時はリーダーを模倣し、学習後は自律動作する。 | 全フェーズで使用 |
SO-101の7軸構成
SO-101は7つの軸(関節)を持つ。各軸が記録・制御の対象になる。
| 軸番号 | 関節名 | 動作 | 記録されるデータ |
|---|---|---|---|
| 軸1 | ショルダーパン | 左右旋回 | 角度(度) |
| 軸2 | ショルダーリフト | 前後傾き | 角度(度) |
| 軸3 | エルボー | 肘の屈伸 | 角度(度) |
| 軸4 | リスト垂直 | 手首の上下 | 角度(度) |
| 軸5 | リスト水平 | 手首の左右 | 角度(度) |
| 軸6 | リストロール | 手首の回転 | 角度(度) |
| 軸7 | グリッパー | 開閉(把持力) | 開閉率(0=全閉〜1=全開) |
リーダーとフォロワーはどう繋がっているか
2本のアームは物理的には独立しているが、PCを介してUSBで電気的に接続・同期されている。リーダーを動かした瞬間にフォロワーが追従するのはこの仕組みによる。
リーダーアーム │ │ USB接続 ↓ PC(LeRobotが動作中) │ ├─ カメラ映像を受信・記録 │ ├─ リーダーの軸状態を受信・記録 │ └─ フォロワーへ同じ軸状態を送信(約30ms間隔) │ │ USB接続 ↓ フォロワーアーム(リーダーと同期して動作)
カメラは作業台を俯瞰または正面から撮影し続ける固定カメラだ。重要な設計原則として、リーダーアームはカメラの視野に入れない。フォロワーアームと物体だけが映っている状態を維持する。これにより「カメラ映像→フォロワーの動作」という純粋なペアデータが生成される。
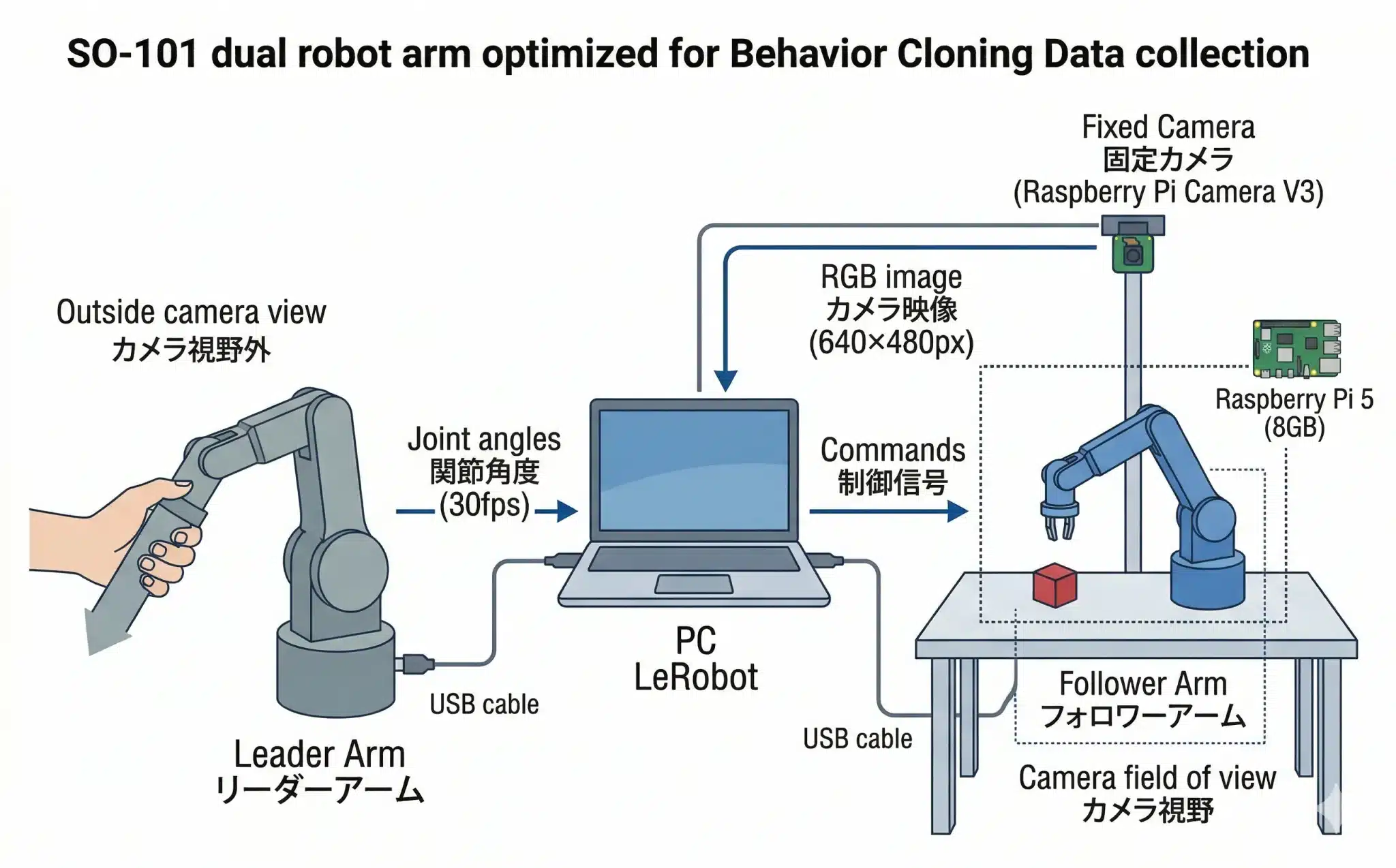 図2:SO-101システム接続構造図——リーダー・フォロワー・カメラ・PCの関係と、カメラ視野の設計原則
図2:SO-101システム接続構造図——リーダー・フォロワー・カメラ・PCの関係と、カメラ視野の設計原則3. データ収集フェーズ——「お手本」を記録する
人間がリーダーを動かすだけで、カメラ映像と7軸状態のペアデータが自動生成される。50回のデモが約10,000ペアの学習データになる。
データ収集の流れは以下の通りだ。
Step 1: 人間がリーダーアームを手で動かす
(「物体を掴んで別の場所に置く」動作を1回実演)
↓
Step 2: LeRobotが約30ms間隔(1秒≒30コマ)で同時記録
├─ カメラ映像(640×480px、RGB画像)
└─ フォロワーの7軸状態
[軸1〜6の角度(度)+ グリッパー開閉率]
↓
Step 3: 1回のデモ(約7秒)で約200コマのペアデータが生成される
↓
Step 4: これを50〜100回繰り返す
→ 合計 約10,000〜20,000ペアのデータセット完成
実際に記録されるデータの実例
1コマ分のデータは以下のような構造だ。
{
"frame_id": "demo_012_frame_0047",
"timestamp_ms": 1567,
"camera_image": "frame_0047.png", // 640×480px RGB画像
"joint_states": {
"shoulder_pan": 12.3, // 軸1(度)
"shoulder_lift": -8.7, // 軸2(度)
"elbow": 45.2, // 軸3(度)
"wrist_vertical": 3.1, // 軸4(度)
"wrist_horizontal": -1.2, // 軸5(度)
"wrist_roll": 0.8, // 軸6(度)
"gripper": 0.73 // 軸7(0=全閉〜1=全開)
}
}
このデータが意味するのは「このカメラ映像の瞬間に、アームはこの状態だった」というペアだ。AIはこのペアを大量に見ることで「このカメラ映像が来たら、このアーム状態にする」という変換パターンを学ぶ。
強化学習との決定的な違い
Behavior Cloningは強化学習ではない。
| 比較軸 | Behavior Cloning | 強化学習 |
|---|---|---|
| 学習の方法 | 人間のお手本をコピーする | 試行錯誤して報酬を最大化する |
| 報酬設計 | 不要 | 人間が設計する必要あり |
| 実機での試行回数 | 50〜100回(人間のデモ) | 数万〜数百万回 |
| 週4時間チームでの現実性 | ◎ 現実的 | ✕ 現実的でない |
| 初期の汎化性能 | 低い(見たことのある状況のみ) | 高くなりうる |
| ※ 本プロジェクトではBehavior Cloningで基盤を作り、Sim2Realで汎化性能を補完する設計を採用 | ||
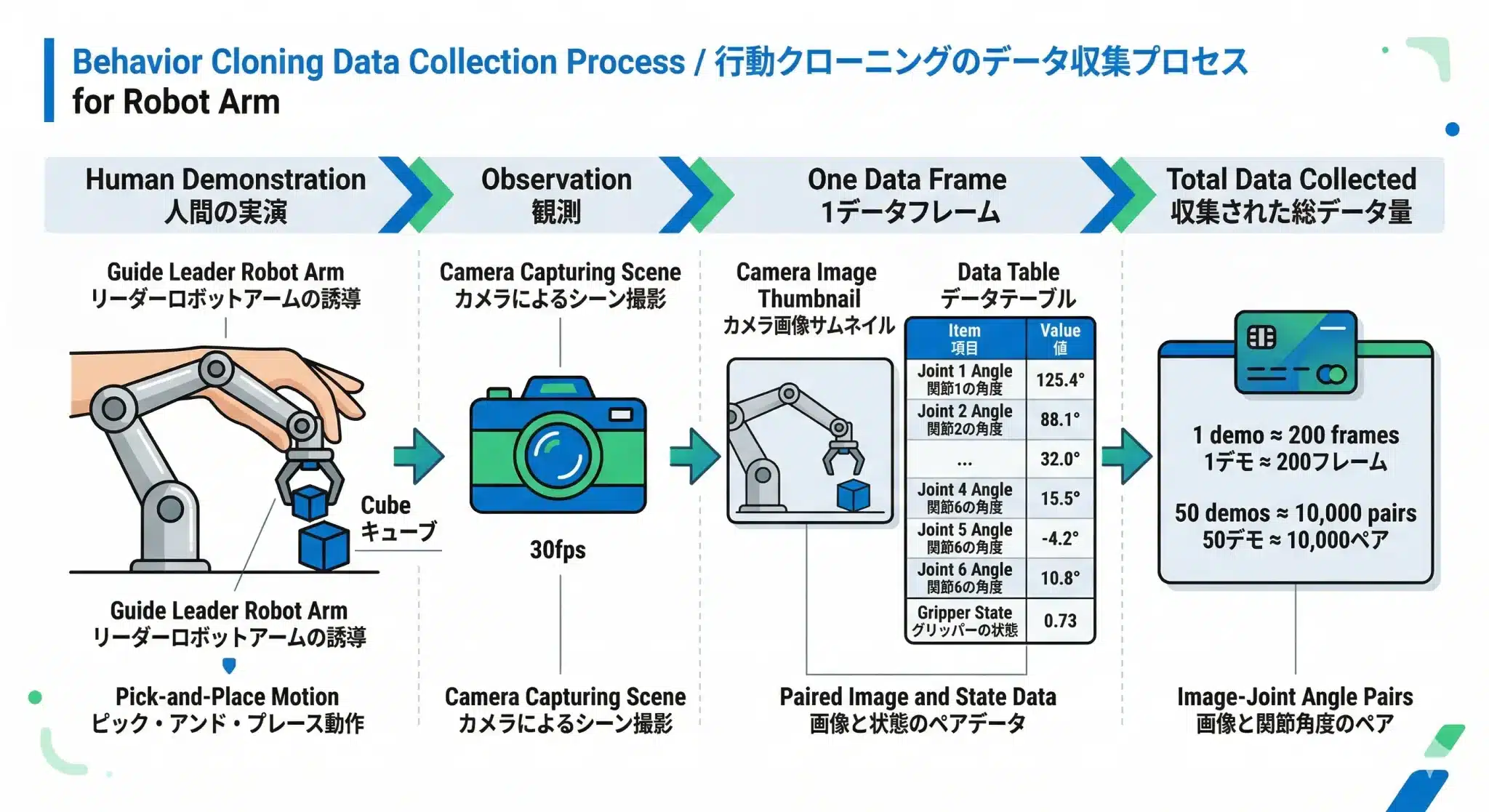 図4:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かる
図4:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かる4. Behavior Cloning学習——カメラ映像から動作を覚える
学習とは「このカメラ映像が来たら、このアーム状態にする」という変換関数を作ることだ。学習完了後、リーダーアームは完全に不要になる。
学習フェーズでは、収集した10,000〜20,000ペアのデータをニューラルネットワークに与える。ネットワークが学ぶのは一つの変換だ。
「このカメラ映像(入力)が来たら、このアーム状態(出力)にする」
料理に例えるとこうだ。食材の組み合わせ(カメラ映像)を見たとき、次にどの手順で動くか(軸の角度)を覚える。レシピを言語で理解するのではなく、何千回もの「この食材→この手順」のペアを見て、身体で覚える。これがBehavior Cloningの本質だ。
学習完了後の推論フロー
学習が完了した瞬間から、リーダーアームは不要になる。フォロワーアームはカメラ映像だけを入力として自律動作する。
【学習完了後の推論フロー】
カメラが作業台を撮影(継続)
↓
新しいフレームをPC(学習済みモデル)に入力
↓
モデルが推論(約30ms)
「この映像なら → 軸1: 12.3°, 軸2: -8.7°...」
↓
推論結果をRaspberry Pi 5経由でフォロワーに送信
↓
フォロワーアームが自律動作
(リーダーは切り離し済み・不使用)
↓
次のフレームで同じサイクルを繰り返す
(1秒間に約30サイクル)
Real-to-Realの最終確認:3回連続成功
Real-to-Realフェーズの最終確認は「リーダーアームを完全に切り離した状態で、フォロワーが同一タスクを3回連続で成功するか」だ。
この3回連続成功が意味するものは「AIが賢くなった」ことではない。「カメラ→推論→アーム制御」というパイプライン全体が安定して動作する神経系が完成したことの証明だ。この基盤があって初めて、2年目のSim2Realが成立する。
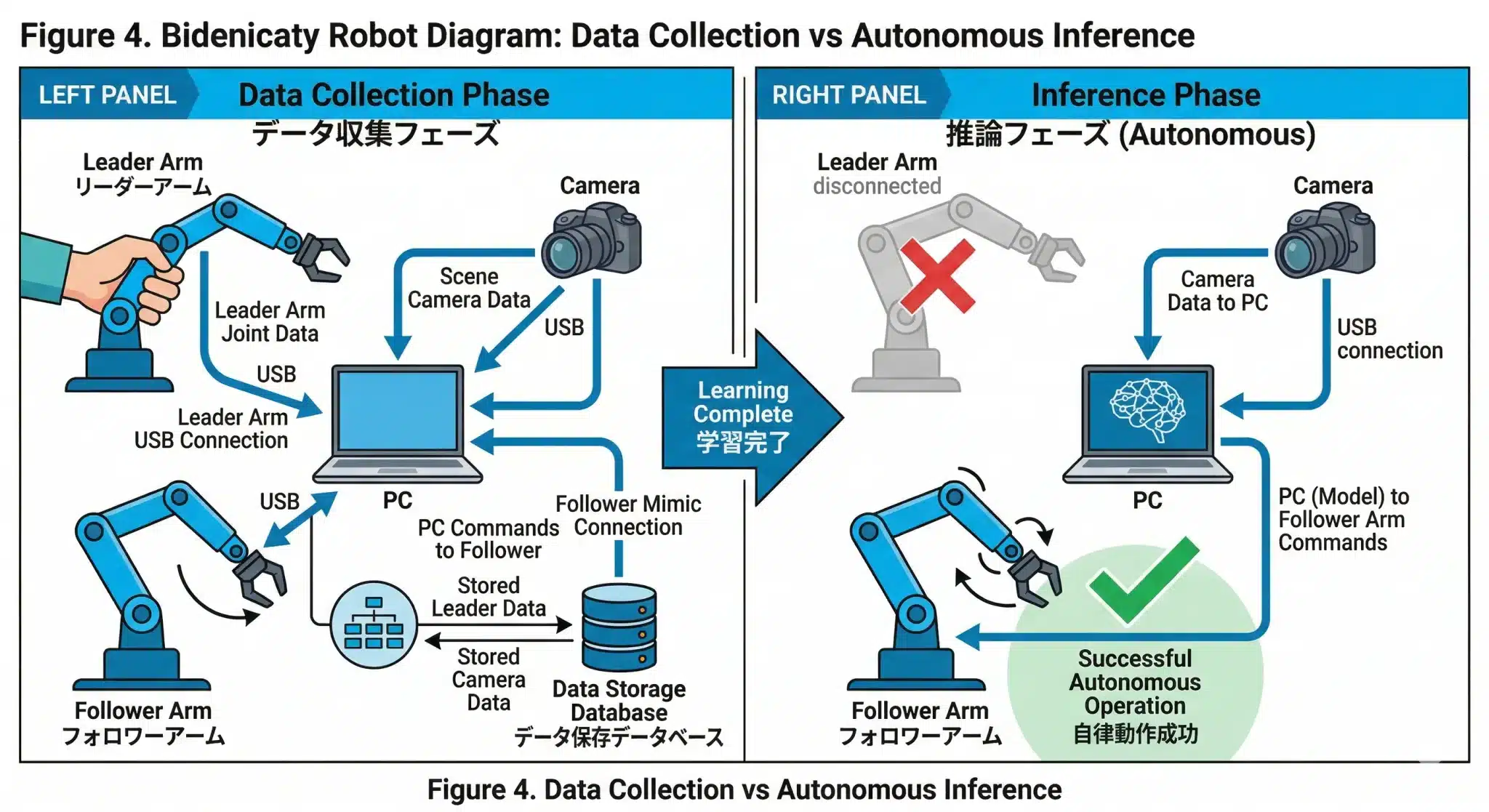 図4:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かる
図4:学習前(データ収集)と学習後(自律推論)のデータフロー対比——リーダーアームが「学習データ生成専用」であることが分かる5. Real-to-Realの限界——なぜSim2Realが必要か
Behavior Cloningは「見たことのある状況しか対応できない」。物体が2cmずれたら失敗する。この限界を突破するためにSim2Realが必要になる。
Real-to-Realで学習したモデルには明確な限界がある。
例えばデータ収集時に物体が常に座標(x=120, y=85)に置かれていたとする。推論時に物体が(x=122, y=85)——わずか2cmずれた位置にあったとき、このモデルは高確率で失敗する。
理由はシンプルだ。「座標(x=122)の物体を掴む映像」をモデルは一度も見たことがないからだ。
「もっとデモを収集すれば解決するか?」——答えはNoだ
1,000回のデモを収集しても、根本的には解決しない。
物体の位置・照明・テクスチャ・背景の組み合わせは事実上無限大だ。現実世界でのデータ収集には、人間の時間という絶対的な上限がある。
ここでSim2Realの発想が登場する。
「現実で無限に試行できないなら、シミュレーターで無限に試行する。」
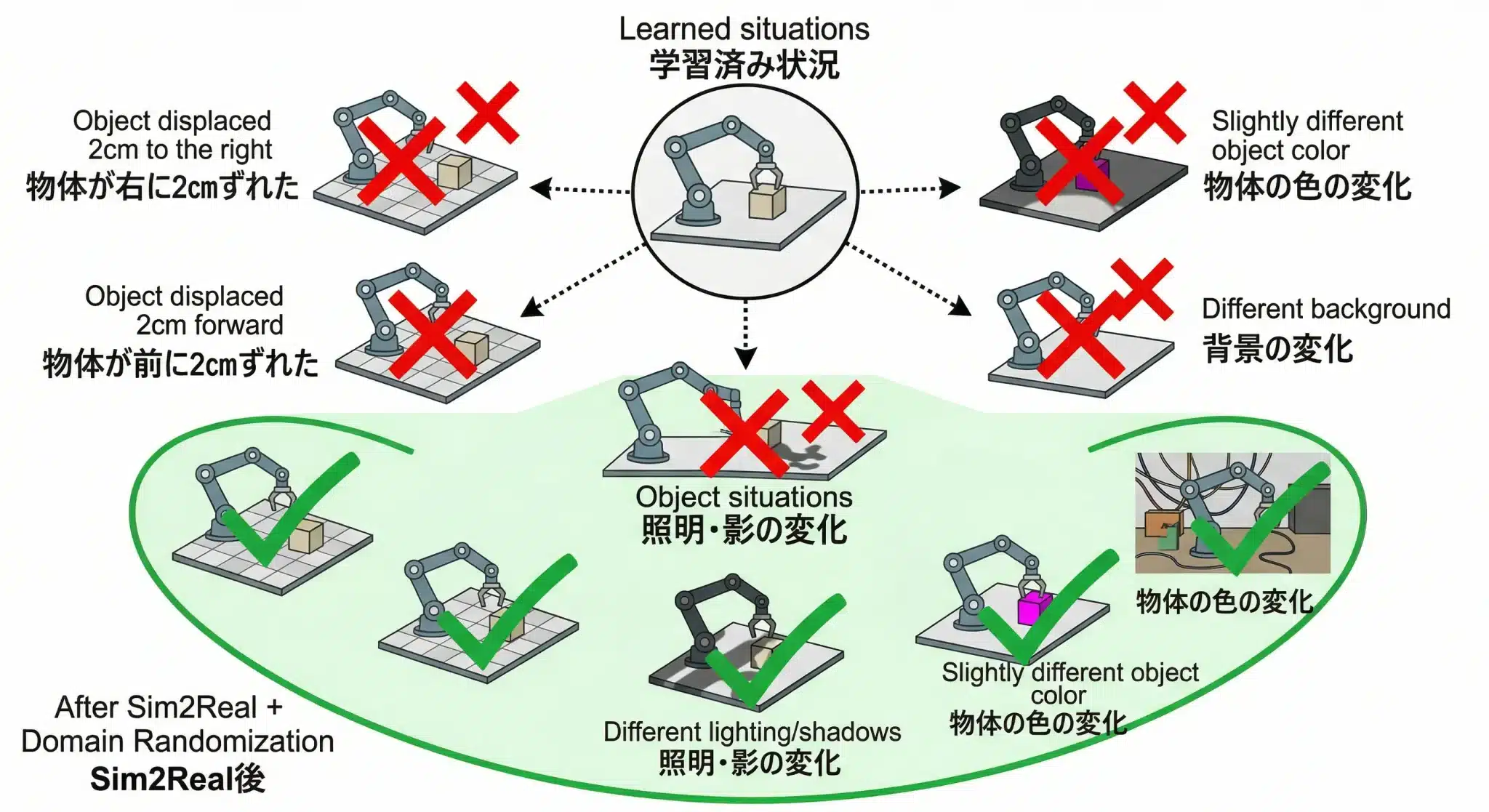 図5:Real-to-Realモデルの「対応可能範囲」の狭さ——Sim2Real適用前後での汎化性能の変化
図5:Real-to-Realモデルの「対応可能範囲」の狭さ——Sim2Real適用前後での汎化性能の変化6. Sim2Realへの接続——何を「食わせる」のか
Sim2Realに「食わせる」のはReal-to-Realで学習したモデルではない。SO-101の物理情報・タスク定義・成功基準の3つだ。
ここが最も誤解されやすいポイントだ。先に結論を言う。
Real-to-Realで育てた学習済みモデルを、そのままシミュレーターに直接投入するわけではない。Sim2Realが必要とするのはモデルではなく、SO-101の物理情報・タスク定義・成功基準の3つだ。
食わせるもの①:URDFファイル(SO-101の物理情報)
URDFはロボットの形状・重量・重心・関節の可動域・摩擦係数を記述したXMLファイルだ。これをIsaac Simに読み込ませることで、「物理的に正しい仮想SO-101」がシミュレーター内に生まれる。
<!-- URDFファイルの例(概念的な抜粋) -->
<joint name="shoulder_pan" type="revolute">
<limit lower="-3.14" upper="3.14"
effort="10.0" velocity="2.0"/>
<dynamics damping="0.1" friction="0.05"/>
</joint>
シミュレーション精度はURDFの精度に直結する。現実のSO-101の物理特性を正確に測定・記述することが、Sim2Real成功の最初の関門だ。
食わせるもの②:タスク定義
「この位置にある物体を掴んで、この位置に置く」という成功条件を定義する。具体的には以下の要素が含まれる。
- 物体の初期位置の範囲
- 目標配置位置の定義
- 成功判定の条件(物体が目標位置±Xcmに置かれたら成功)
- 失敗判定の条件(物体を落とした・制限時間超過など)
食わせるもの③:Ground Truth(Real-to-Realの3回連続成功データ)
Real-to-RealのBehavior Cloningで達成した「3回連続成功」のデータが、シミュレーション内での「正解」の基準になる。
つまりReal-to-Realで確立した基本動作パイプラインは、「Sim2Realで何を目指すかの答え合わせ基準」として機能する。これがReal-to-Realが単なる練習台ではなく、Sim2Real全体の土台になる理由だ。
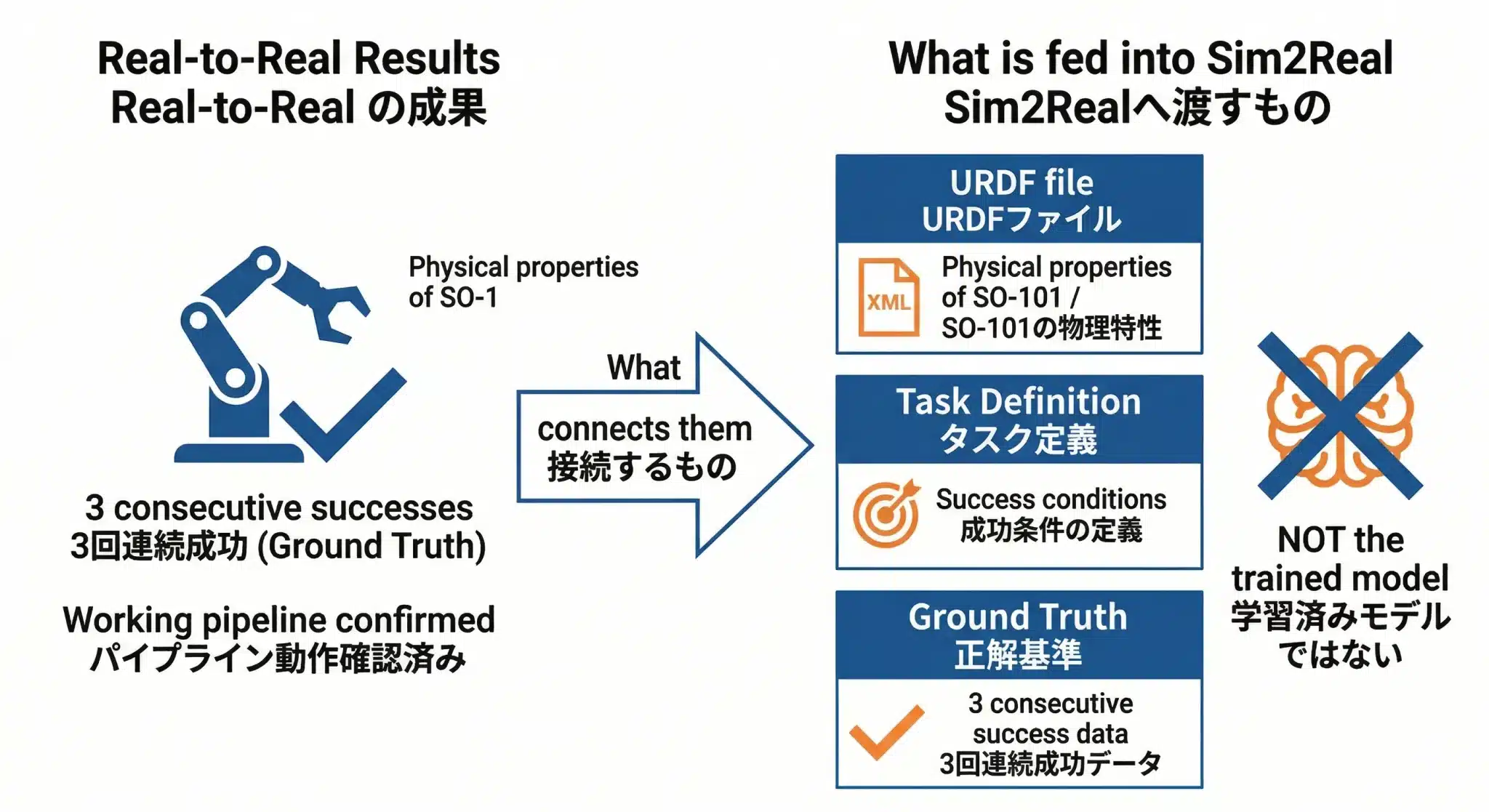 図6:Real-to-RealからSim2Realへの接続——渡すのはモデルではなく「物理情報・タスク定義・成功基準」の3つ
図6:Real-to-RealからSim2Realへの接続——渡すのはモデルではなく「物理情報・タスク定義・成功基準」の3つ7. Domain Randomization——「想定外に強い知能」の育て方
シミュレーター内で物体位置・照明・摩擦係数をランダムに変化させながら数百万回学習させることで、「多少ずれていても掴める」汎化性能が生まれる。
Isaac Sim上に仮想SO-101が構築されたら、Domain Randomizationをかけながら学習を開始する。
Domain Randomizationとは「シミュレーション内のあらゆる条件をランダムに変化させながら学習させる手法」だ。
ランダム変化させるパラメータの実例
| パラメータ | 変化の範囲 | 目的 |
|---|---|---|
| 物体の位置 | ±5cmのランダムオフセット | 位置ずれへの対応力 |
| 照明の方向・強さ | 方向360°・強さ0.5〜2.0倍 | 照明変化への対応力 |
| 物体のテクスチャ・色 | ランダム素材・ランダム色 | 見た目の変化への対応力 |
| 関節の摩擦係数 | ±20%のランダム変動 | 実機個体差への対応力 |
| カメラ取付角度 | ±3度のランダム傾き | カメラ設置誤差への対応力 |
| 背景のテクスチャ | ランダム背景 | 環境変化への対応力 |
並列学習の圧倒的なコスト優位
Domain Randomizationを支えるのが並列学習だ。
【現実での学習】 1台のSO-101が1回ずつ試行 1日に収集できるデモ:人間の作業時間内(数十回) 1年間の総試行回数:数千回 【シミュレーターでの並列学習】 仮想SO-101が数千台同時に動作 24時間休まず試行継続 1日あたりの試行回数:数百万回
現実で1年かかる試行回数を、シミュレーターは数時間で完了させる。これがSim2Realの最大の優位点だ。「あらゆる状況を経験させる」ことで「想定外がなくなる」モデルが生まれる。
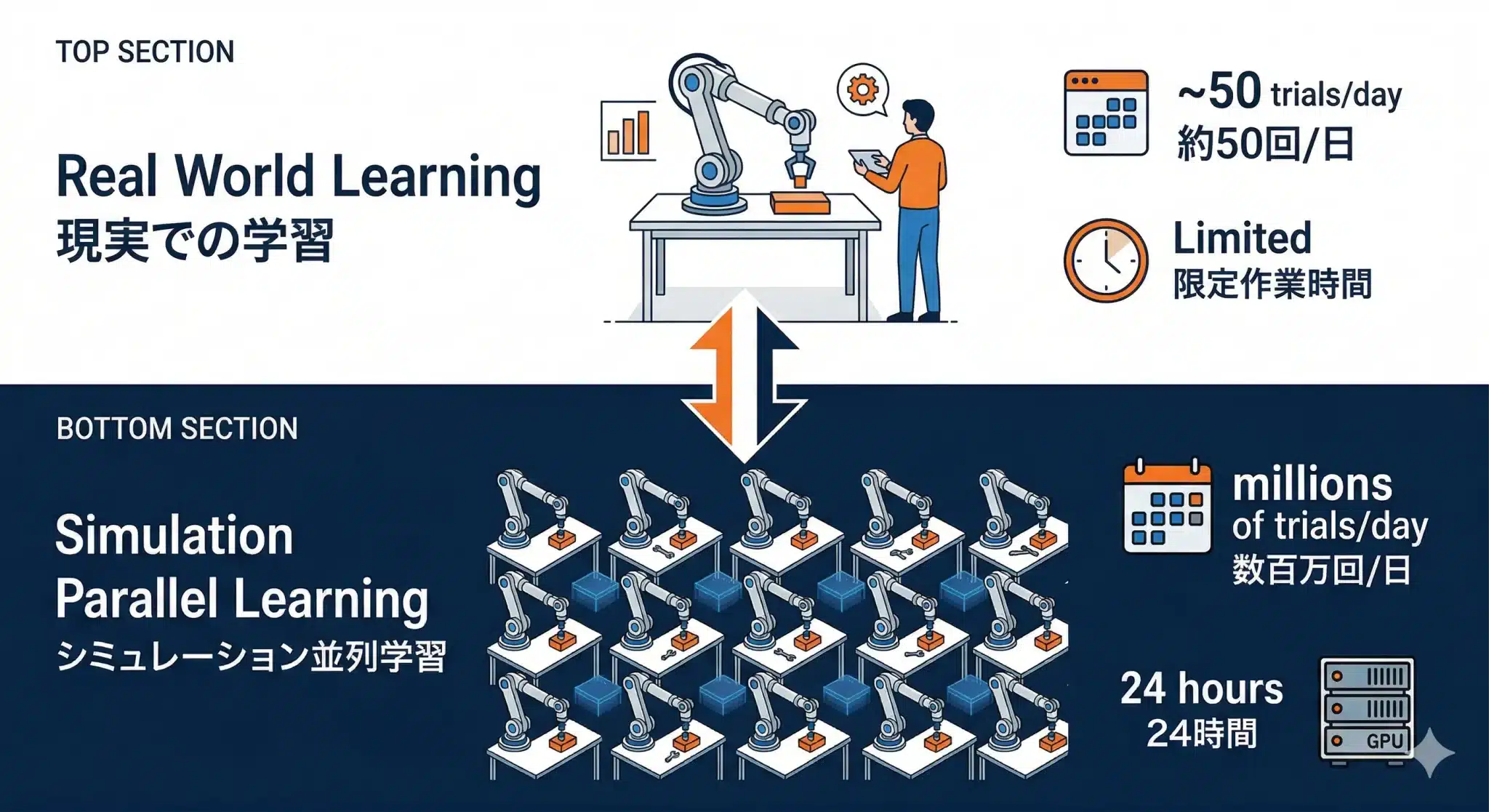 図7:並列学習の圧倒的なコスト優位——シミュレーターは現実の数万倍の試行速度でDomain Randomizationを実行できる
図7:並列学習の圧倒的なコスト優位——シミュレーターは現実の数万倍の試行速度でDomain Randomizationを実行できる8. Fine-tuning——シミュレーションと現実のズレを埋める
Sim2Realで鍛えたモデルをそのまま実機に載せても動かない。10〜30回の追加デモで「現実の物理・視覚特性」に適応させるのがFine-tuningだ。
Sim2Realで数百万回学習したモデルを実機のフォロワーアームに転送すると、ほぼ確実に次の現象が起きる。
「シミュレーションではうまく動いていたのに、実機では微妙にズレて失敗する。」
これがSim-to-Real Gapだ。原因は2つある。
Sim-to-Real Gapの2つの原因
原因①:物理のズレ
URDFでどれだけ正確に記述しても、シミュレーションの物理演算は「近似値」だ。現実の関節には微妙なガタつき・個体差・経年変化による摩擦の変化がある。シミュレーターではこれを完全に再現できない。
原因②:視覚のズレ
シミュレーションのテクスチャ・照明はどれだけリアルに作っても、現実のカメラが捉える光の反射・レンズのボケ・センサーノイズとは異なる。モデルの「目」が現実の映像を見たことがない状態で転送されるため、視覚的なズレが生じる。
Fine-tuningの手順
Step 1: Sim2Realで学習済みの「汎化性能の高いモデル」を
実機フォロワーアームに転送
Step 2: 再びリーダーアームを使って
実機で10〜30回のデモを追加収集
(この「本物データ」は少量でよい)
Step 3: 少量の本物データで追加学習(Fine-tuning)
「この現実の映像→この軸状態」の
補正パターンをモデルに上書きする
Step 4: Sim-to-Real Gapが補正される
Step 5: 実機成功率85%達成
なぜ10〜30回の少量デモで足りるのか
Fine-tuningがなぜ少量データで機能するかを理解することが重要だ。
Sim2Realで数百万回学習したモデルは「汎化性能の骨格」はすでに完成している。物体がずれていても、照明が変わっても対応できる能力は既に備わっている。
Fine-tuningで補正するのは「骨格」ではなく「現実の物理・視覚特性への微調整」だ。
| フェーズ | 役割 | 必要なデータ量 | 期待される成功率 |
|---|---|---|---|
| Real-to-Real(Behavior Cloning) | 神経系の確立・基本動作の習得 | 50〜100回のデモ | 固定条件で〜95% |
| Sim2Real(Domain Randomization) | 汎化性能の骨格を作る | 数百万回(自動・シミュレーター) | 転送直後〜60〜70% |
| Fine-tuning | Sim-to-Real Gapの補正 | 10〜30回のデモ(実機) | 85%以上(目標値) |
| ※ 成功率はプロジェクト目標値。実際の値はクール8〜9で計測・記録する。 | |||
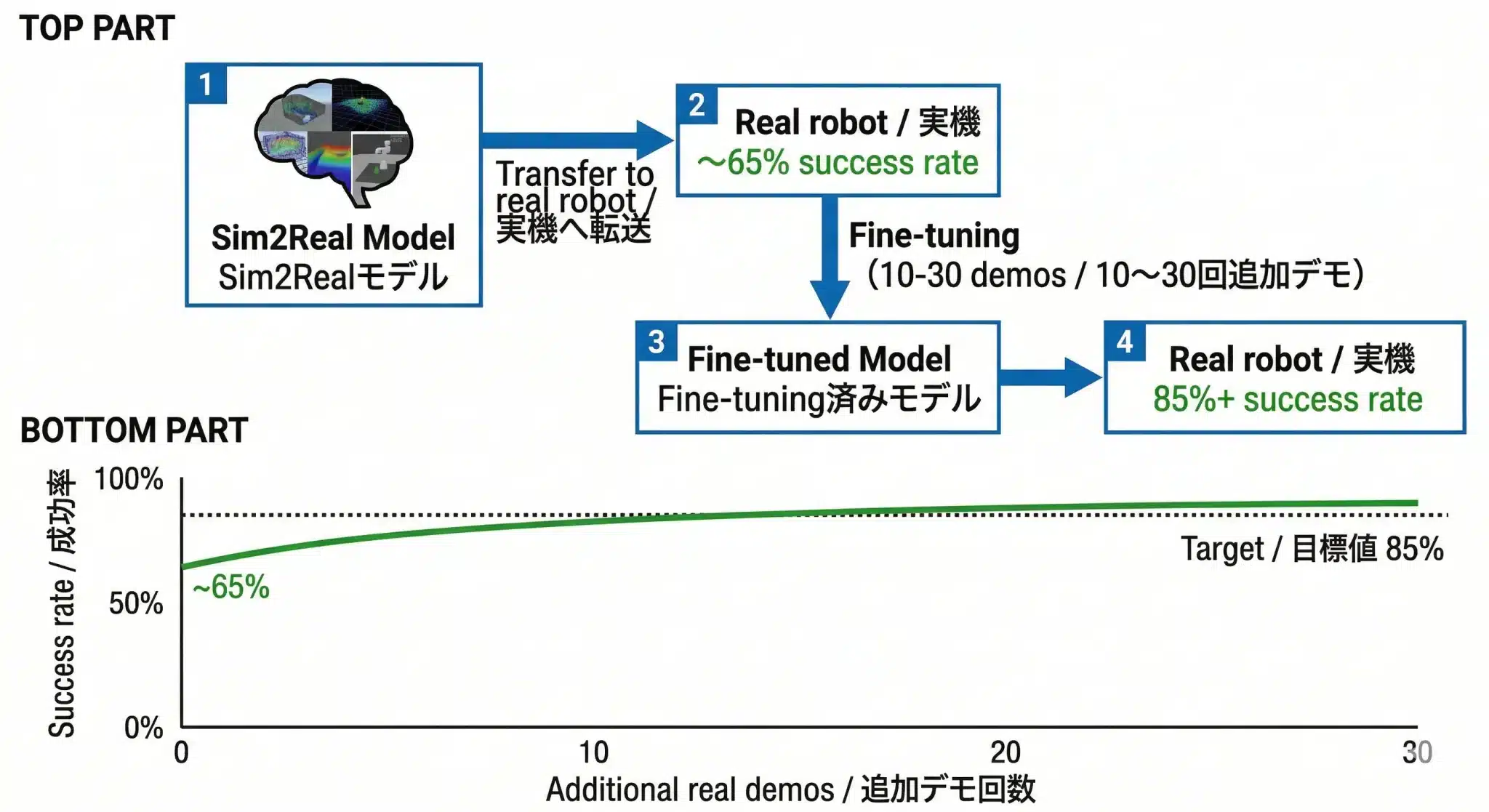 図8:Fine-tuning前後の成功率変化——少量の実機データがSim-to-Real Gapを補正し、目標値85%を達成する仕組み
図8:Fine-tuning前後の成功率変化——少量の実機データがSim-to-Real Gapを補正し、目標値85%を達成する仕組み9. 全体を一枚で理解する——2年間の設計原理の鳥瞰
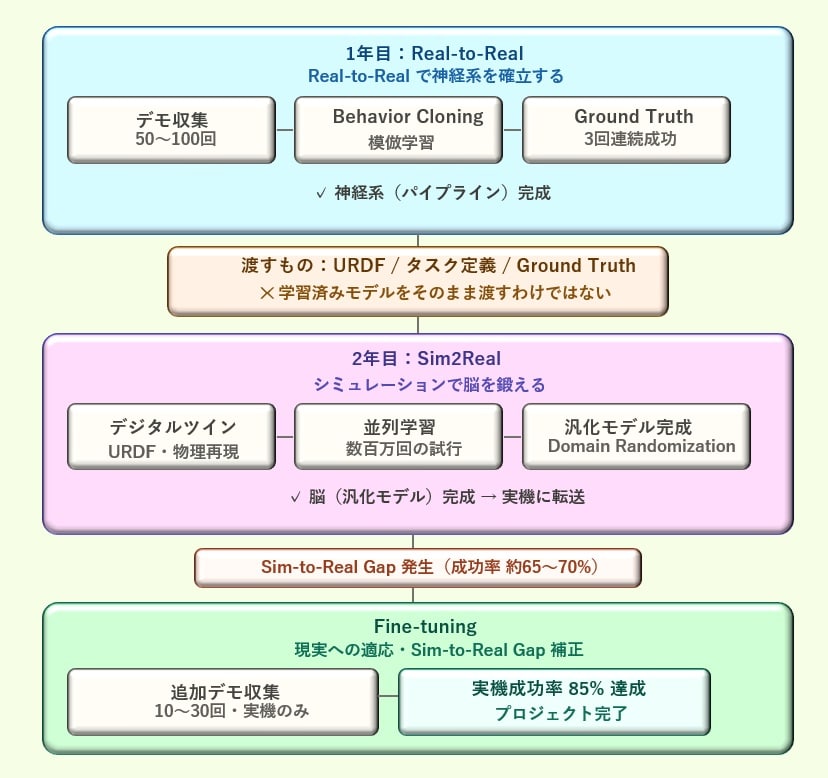
Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる。この3段階が「見て・判断して・動く」知能の設計原理だ。
ここまで解説してきた内容を一枚で整理する。
従来手法との比較:何が根本的に変わるか
| 比較軸 | 従来(ルールベース) | 新設計パターン |
|---|---|---|
| 動作の定義方法 | 人間がコードで全て記述 | データから自動学習 |
| 新しい位置への対応 | コードの追記が必要 | Domain Randomizationで自動対応 |
| 初期開発コスト | 高い(プログラミング工数) | 低い(デモ収集50〜100回) |
| 汎化性能 | 事前定義した状況のみ | 学習範囲内で高い汎化性能 |
| 週4時間チームでの現実性 | △ 動作定義の工数が重い | ◎ デモ収集中心で現実的 |
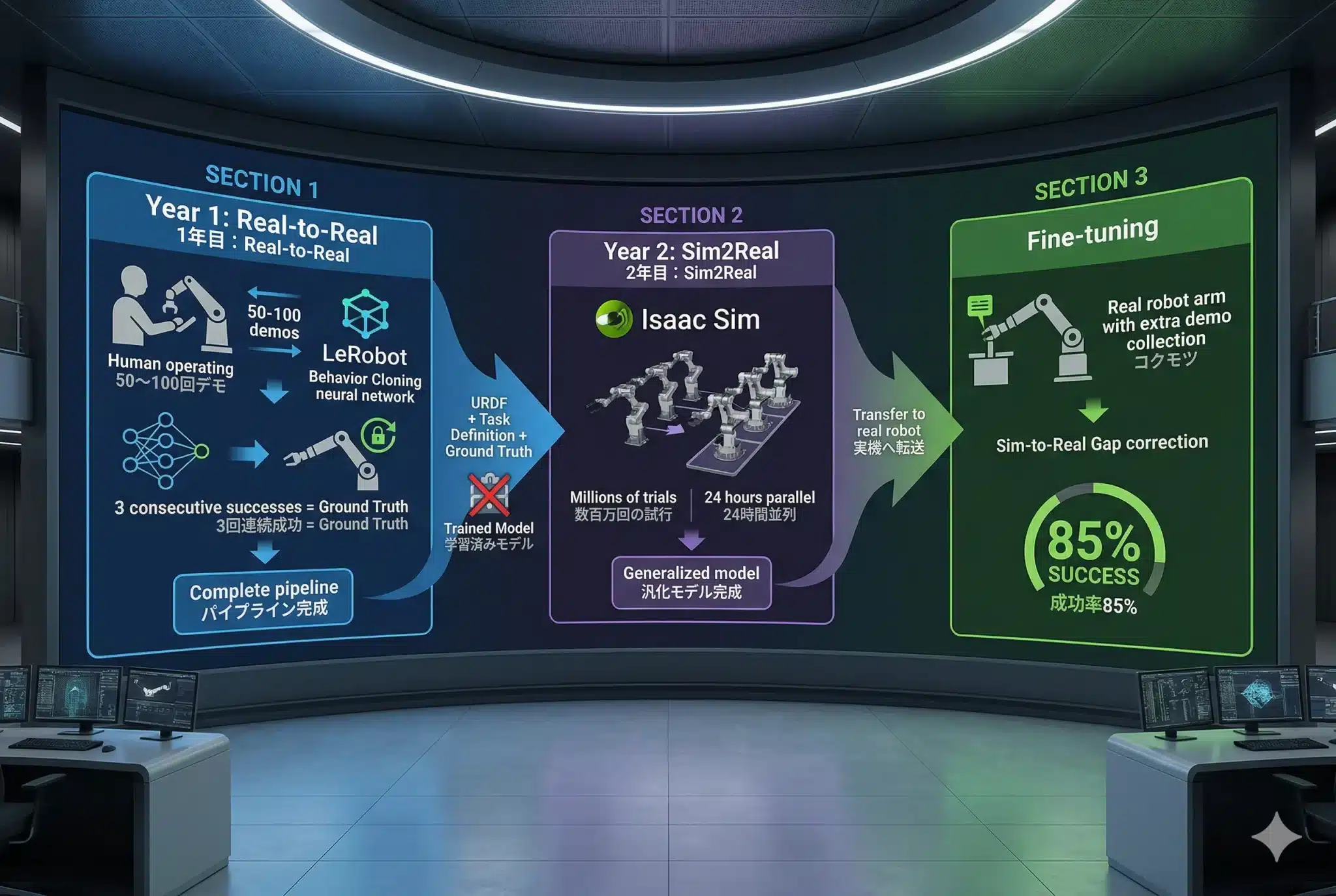 図9:2年間の設計原理の鳥瞰——Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる3段階の全体像
図9:2年間の設計原理の鳥瞰——Real-to-Realで神経系を作り、Sim2Realで脳を鍛え、Fine-tuningで現実に適応させる3段階の全体像まとめ:「見て・判断して・動く」設計原理の3行まとめ
Real-to-Realで土台を作り、Sim2Realで限界を突破し、Fine-tuningで現実に着地する。
本記事で解説した設計原理を3行に圧縮する。
第一に、Behavior Cloningはルールを書かない。カメラ映像とアーム状態のペアデータから、AIが自分で動作パターンを学ぶ。リーダーアームは学習データを生成するためだけに存在し、学習完了後は不要になる。
第二に、Sim2Realへの接続はモデルではなく物理情報だ。URDFファイル・タスク定義・Ground Truthの3つをシミュレーターに渡し、数百万回の並列学習で「想定外に強い知能」を育てる。
第三に、Fine-tuningは再学習ではなく微調整だ。Sim2Realで汎化の骨格が完成しているため、実機での10〜30回の追加デモだけでSim-to-Real Gapを補正できる。この設計が「週4時間チームでも現実的に実装できる」根拠になる。
このプロジェクトにおけるクール2以降のBehavior Cloning実装、およびクール5〜9でのSim2Real・Fine-tuning実装の記録は、Arpableの連載とYouTube動画でリアルタイムに公開していく。
📚 シリーズ3本の読み方
- この記事(記事C):何を学ぶのか——Behavior CloningからSim2Real・Fine-tuningまでの技術原理
- 記事A(キックオフ):なぜやるか・誰がやるか・どう運営するか——9クール制実行設計の全容
- 記事B(ロードマップ):何の機材が必要か——SO-101・LeRobot・Isaac Lab 2カ年環境構築ガイド
専門用語まとめ
- Behavior Cloning(模倣学習)
- 人間がリーダーアームを操作して見せた「お手本」の映像と関節状態をペアデータとして記録し、AIに「このカメラ映像→この関節状態」の変換パターンを学習させる手法。強化学習と異なり、報酬設計や無数の試行錯誤が不要なため、週4時間チームでも現実的に実装できる。
- リーダーアーム / フォロワーアーム
- SO-101を構成する2本1セットのアーム。リーダーアームは人間が手で動かす「お手本側」で学習データ生成専用。フォロワーアームはデータ収集時はリーダーを模倣し、学習完了後はカメラ映像だけを入力として自律動作する実行機。
- Ground Truth(正解データ)
- Real-to-Realフェーズで達成した「3回連続成功」の実績データ。Sim2Realにおける「何を目指すかの答え合わせ基準」として機能する。シミュレーター内のタスク定義と成功条件の設定に使われる。
- URDF(Unified Robot Description Format)
- ロボットの形状・重量・重心・関節の可動域・摩擦係数を記述するXMLファイル。Isaac SimにURDFを読み込ませることで「物理的に正しい仮想SO-101」が生成される。URDFの精度がSim2Real成功率に直結する。
- Domain Randomization(領域ランダム化)
- シミュレーション内の物体位置・照明・テクスチャ・摩擦係数などをランダムに変化させながら学習させる手法。「あらゆる状況を経験させる」ことで「想定外に強い汎化性能」を持つモデルが生まれる。
- Sim-to-Real Gap
- シミュレーションで学習したモデルを実機に転送した際に生じる「物理特性のズレ」と「視覚特性のズレ」の総称。物理のズレは関節の個体差・ガタつき、視覚のズレはカメラのノイズ・光の反射の差異から生じる。Fine-tuningで補正する。
- Fine-tuning(微調整)
- Sim2Realで学習済みのモデルを実機に転送した後、実機で10〜30回の追加デモを収集して少量の本物データで追加学習する工程。Sim-to-Real Gapを補正し、実機成功率85%達成を目指す。「再学習」ではなく「微調整」であるため少量データで足りる。
よくある質問(FAQ)
Q1.
Behavior Cloningと強化学習はどちらが優れていますか?
A1.
優劣ではなく「使う場面が違う」です。本プロジェクトではBehavior Cloningで基盤を作り、Sim2Realで汎化性能を補完する組み合わせを採用しています。
- Behavior Cloningは報酬設計が不要・少量データで学習できる反面、汎化性能が低い。
- 強化学習は汎化性能が高くなりうる反面、報酬設計の難しさと膨大な試行回数が必要。
- 本プロジェクトの解決策:Behavior Cloningで基盤を作り、Sim2Real(Domain Randomization)で汎化性能を後から補完する。
関連:データ収集フェーズへ
Q2.
リーダーアームはSim2RealフェーズやFine-tuningでも使いますか?
A2.
Sim2Realフェーズではリーダーアームは使いません。Fine-tuningでは再び使います。
- Sim2Realフェーズはシミュレーター内で完結するため、物理的なリーダーアームは不要です。
- Fine-tuningでは実機での追加デモ収集が必要なため、リーダーアームを再使用して10〜30回のデモを収集します。
- リーダーアームの役割は一貫して「学習データの生成専用」です。
関連:Fine-tuningへ
Q3.
URDFファイルはどうやって作るのですか?
A3.
SO-101は現時点ではHugging FaceのLeRobotリポジトリにURDFファイルが公開されています。プロジェクトではこれをベースにしつつ、自分たちの個体・環境に合わせて調整していきます。ゼロからURDFを自作する必要はありません。
- LeRobotの公式リポジトリからSO-101のURDFをダウンロードして使用します。
- ただし実機の個体差(関節の摩擦・ガタつきなど)を反映した微調整が必要になる場合があります。
- この調整作業がクール5(デジタルツイン構築)の主要タスクの一つです。
Q4.
Fine-tuningはなぜ10〜30回という少量のデモで足りるのですか?
A4.
Sim2Realで「汎化の骨格」がすでに完成しているため、Fine-tuningは骨格の微調整だけで済むからです。
- Sim2Realの数百万回学習で「様々な状況に対応する能力」は既に獲得されています。
- Fine-tuningで補正するのは「現実の物理特性・視覚特性へのわずかな適応」だけです。
- ゼロから学習するのではなく、強いモデルに「現実の感覚」を少しだけ上書きするイメージです。
関連:Fine-tuningへ
Q5.
このプロジェクトの実装結果はどこで確認できますか?
A5.
Arpableの連載記事・YouTube動画・X(旧Twitter)・LinkedInでリアルタイムに公開します。
- 各クール終了時にクールALT(社内LT)を開催し、成果と失敗の全記録をArpable記事として公開します。
- 制作過程の動画をYouTubeで公開します(失敗シーンも含む)。
- 2026年11月:THE PACKAGE v1.0(Real-to-Real完結版)公開予定。
- 2027年11月:THE PACKAGE最終版(Sim2Real完結版)公開予定。
参考サイト・出典
一次情報
シリーズ関連記事
あわせて読みたい
更新履歴
- 2026年4月7日:初版公開
以上







